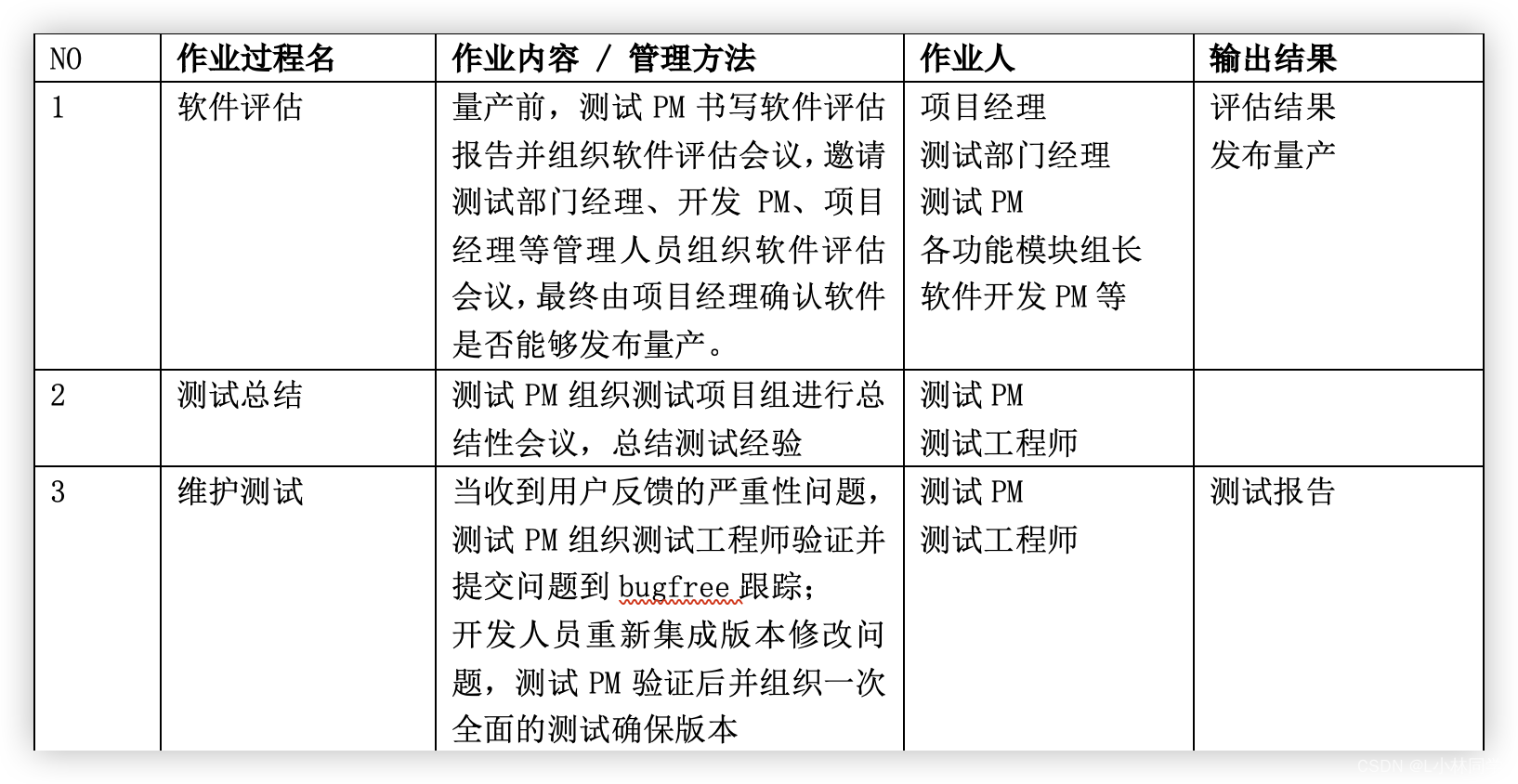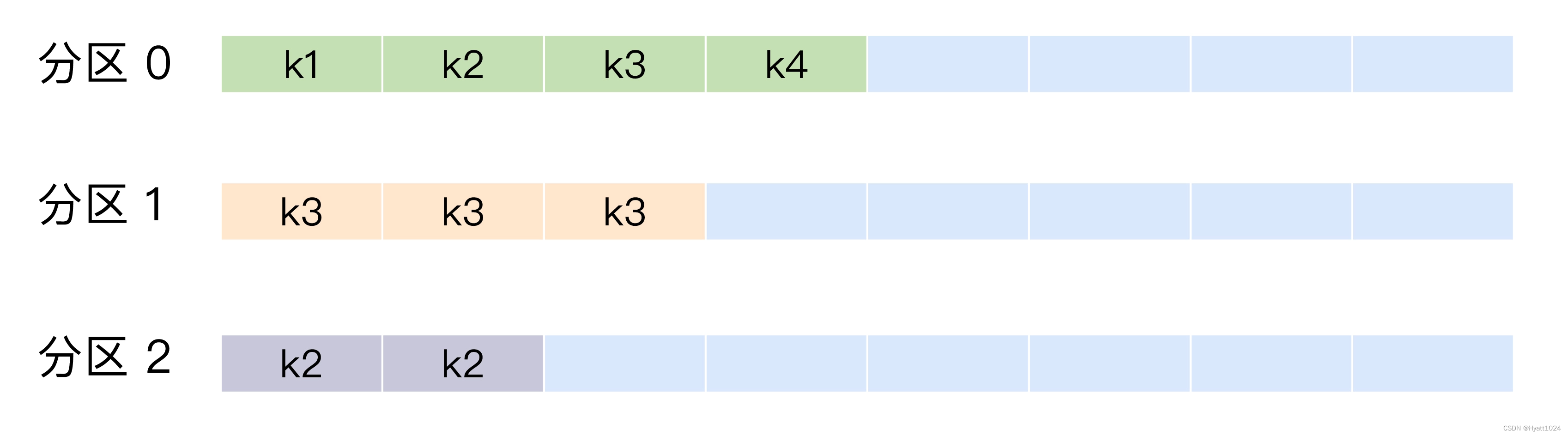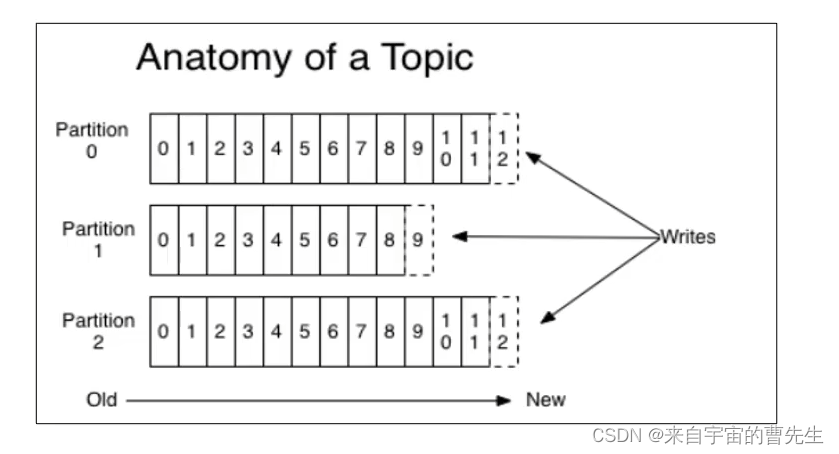
Kafka的分区机制是其核心功能之一,旨在提高可扩展性和并行处理能力。下面概述了Kafka分区的基本概念和工作原理:
Kafka分区基本概念
- 分区(Partition):Kafka中的主题(Topic)可以细分为多个分区。分区允许你将数据平行存储,每个分区都是一个有序的、不可变的消息序列。
- 并行性:通过分区,Kafka能够在多个消费者之间并行处理数据,增加吞吐量。每个分区只能由消费者组中的一个消费者消费,但一个消费者可以消费多个分区的数据。
- 高可用性:分区还允许Kafka复制数据到多个节点,以防单点故障,提高数据的可用性和耐久性。
Kafka分区工作原理
- 数据写入:生产者在发送消息到主题时,可以指定一个键(Key)。Kafka使用键通过哈希算法确定消息存储到哪个分区。如果不指定键,消息将被轮询分配到各个分区。
- 数据读取:消费者通过订阅主题并指定消费者组来消费数据。Kafka保证同一个消费者组内的每个消费者负责读取不同分区的数据,实现数据的负载均衡。
- 负载均衡:当消费者或分区发生变化时,Kafka会自动重新分配分区给消费者,确保负载均衡。
分区的优势
- 提高并发:分区使得Kafka可以在多个服务器上并行处理数据,显著提高了吞吐量。
- 容错能力:通过数据复制,即使在节点失败的情况下,Kafka也能保证数据的可用性和一致性。
- 灵活的消费:消费者可以灵活地订阅特定的分区,或根据需要调整消费策略。
通过合理地设计分区数量和消费者策略,你可以充分发挥Kafka的性能,实现高吞吐量的实时数据处理和分析。