1.索引知识图框
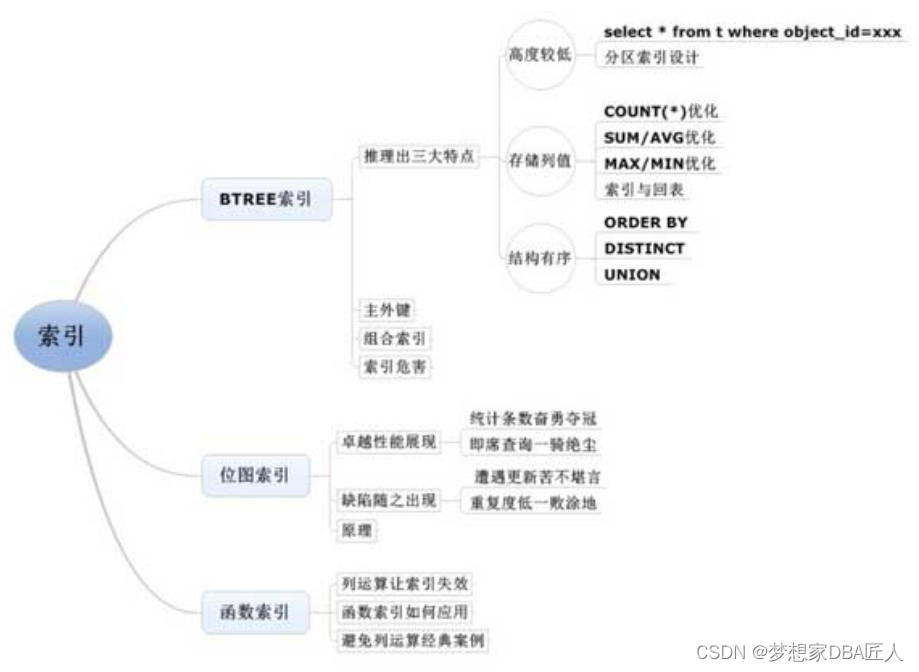
2.索引探秘
2.1 BTREE索引
索引是建在表的具体列上的,其存在的目的是让表的查询变得更快,效率更高。表记录丢失关乎生死,而索引丢失只需重建即可。
索引却是数据库学习中最实用的技术之一。谁能深刻地理解和掌握索引的知识,谁就能在数据库相关工作中事半功倍。在了解索引之前,我们需要先了解索引结构长什么样。
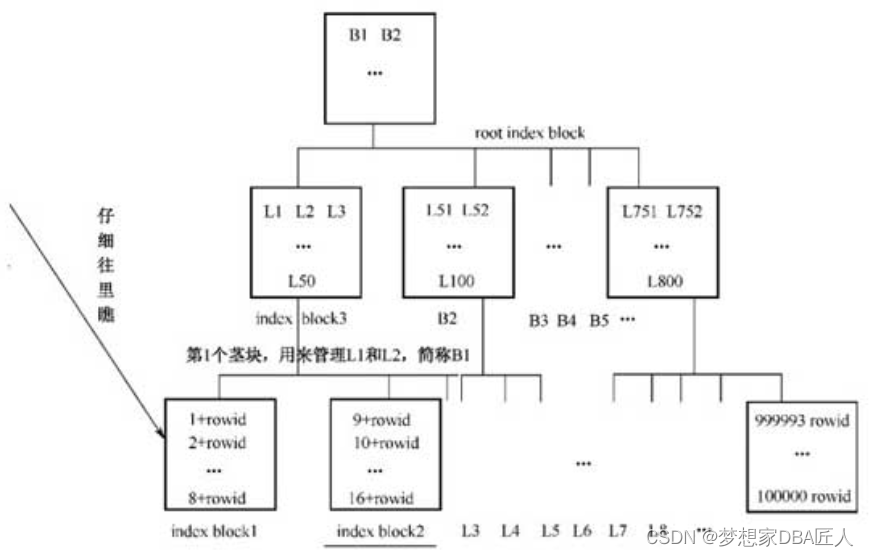
索引结构图
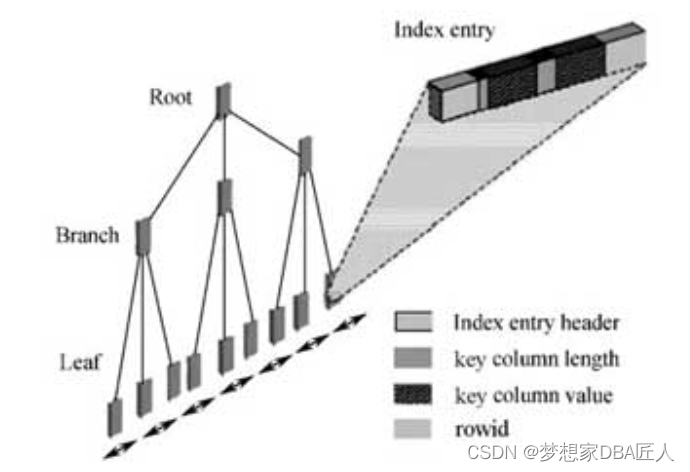
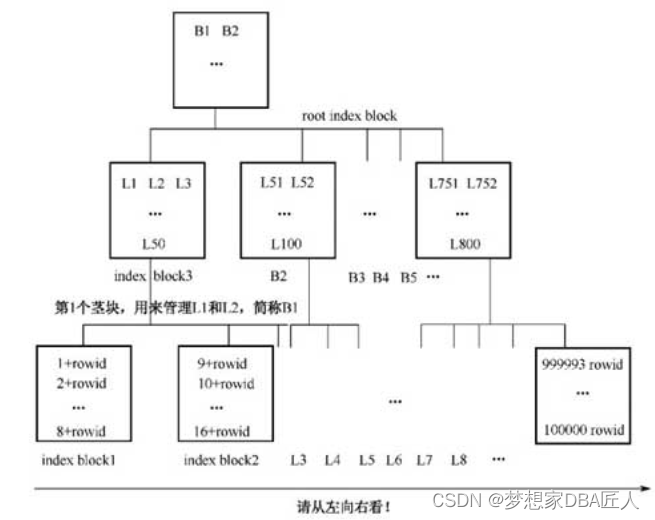
索引结构图说明索引是由Root(根块)、Branch(茎块)和Leaf(叶子块)三部分组成的,其中Leaf(叶子块)主要存储了key column value(索引列具体值),以及能具体定位到数据块所在位置的rowid(注意区分索引块和数据块)。
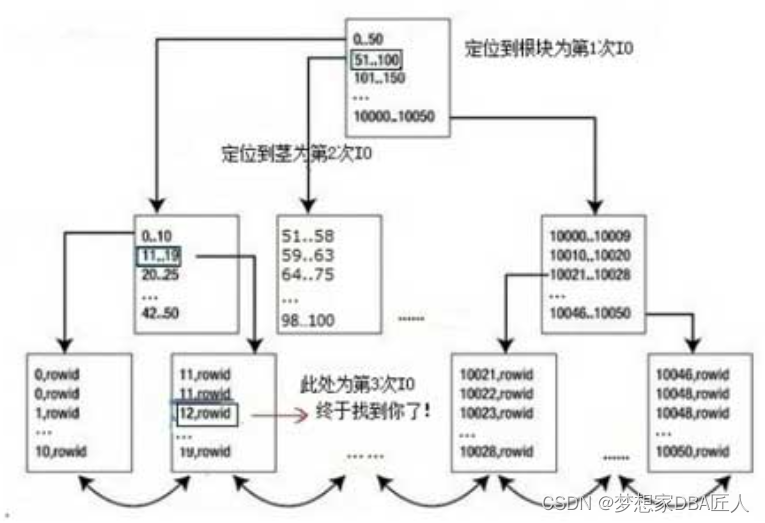
具体说说某个Oracle的索引查询吧,如:select * from t where id=12;,该t表的记录有10 050条,而id=12仅返回1条,在t表的id列上创建了一个索引,索引是如何快速检索到数据的呢?
首先查询定位到索引的根部,这是第1次IO;接下来根据根块的数据分布,定位到索引的茎部(查询到12的值的大致范围,在11..19的部分),这是第2次IO;然后定位到叶子块,找到 id=12的部分,此处为第3次 IO。假设 Oracle 在全表扫描记录,遍历所有的数据块,IO的数量必然将大大超过3次。有了这个索引,Oracle只会去扫描部分索引块,而非全部,少做事,必然能大大提升性能。
Leaf(叶子块)主要存储key column value(索引列具体值)以及能具体定位到数据块所在位置的rowid(注意区分索引块和数据块)。
2.2 到底是物理结构还是逻辑结构
物理结构可以理解为真正存在根、茎、叶的块。而逻辑结构可以理解为并没有存在根、茎的块,只是一种指针或者说一种内部算法。
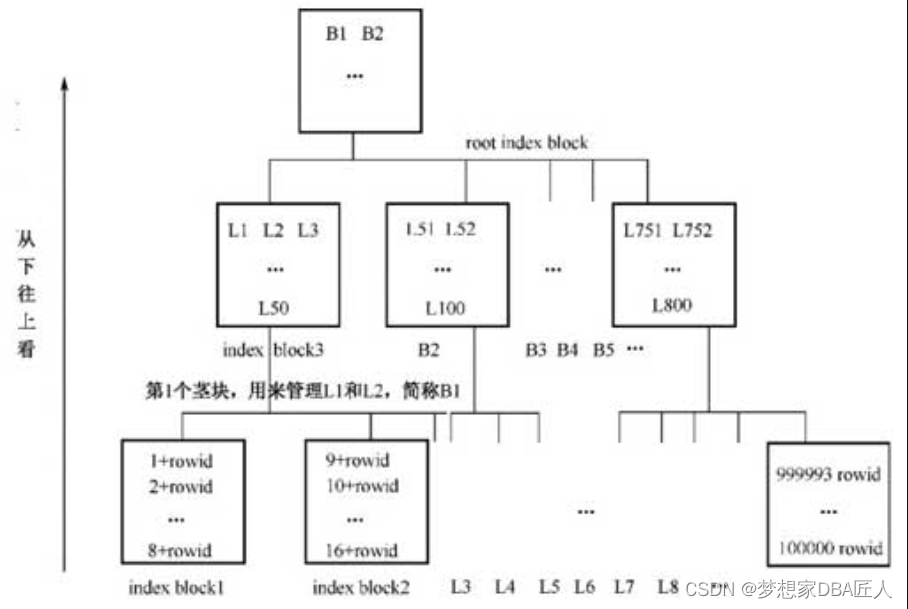
1.要建索引先排序
未建索引的test表中的记录大致如图5-4所示,NULL表示该字段为空值,此外省略号表示略去不显示内容。注意rowid伪列,这是每一行的唯一标记,每一行的rowid 值绝对不重复,它可将行的记录定位到数据库中的位置。建索引后,将test表中id列的值按顺序取出放在内存中(这里需注意,除了id列的值外,还要注意取该列的值的同时,该行的rowid也被一并取出)。
2.列值入块成索引
依次将内存中顺序存放的列值和对应的rowid存进Oracle空闲的块中,形成索引块。
3.填满一块接一块
随着索引列的值的不断插入,index block1(L1)很快就被插满了。比如接下来取出的 id=9的记录无法插入index block1(L1)中,就只能插入新的块中,插入如图5-7所示的index block2(L2)。
4.同级两块需人管
随着叶子块的不断增加,B1块中虽然仅是存放叶子块的标记,但也挡不住量大,最终也容纳不下了。怎么办?接着装呗,到下一个块B2中去寻找空间容纳。
2.3 索引结构的三大重要特点
2.3.1.索引高度较低
2.3.2.索引存储列值
2.3.3.索引本身有序
索引的三大特点:
① 索引树的高度一般都比较低。
② 索引由索引列存储的值及rowid组成。
③ 索引本身是有序的。
索引从左向右看
2.4 妙用三特征之高度较低
2.4.1索引高度较低验证
① 构造一系列表t1到t6,记录数从5到50万依次以10倍的差额逐步增大
做索引高度较低试验前的构造表操作
SQL> show user
USER is "MAXWELLPAN"
SQL> drop table t1 purge;
drop table t1 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t2 purge;
drop table t2 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t3 purge;
drop table t3 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t4 purge;
drop table t4 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t5 purge;
drop table t5 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t6 purge;
drop table t6 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL>
SQL> create table t1 as select rownum as id,rownum+1 as id2 from dual connect by level<=5;
Table created.
SQL> create table t2 as select rownum as id,rownum+1 as id2 from dual connect by level<=50;
Table created.
SQL> create table t3 as select rownum as id,rownum+1 as id2 from dual connect by level<=500;
Table created.
SQL> create table t4 as select rownum as id,rownum+1 as id2 from dual connect by level<=5000;
Table created.
SQL> create table t5 as select rownum as id,rownum+1 as id2 from dual connect by level<=50000;
Table created.
SQL> create table t6 as select rownum as id,rownum+1 as id2 from dual connect by level<=500000;
Table created.
SQL>
② 分别对ID列建索引
继续完成建索引的准备工作
SQL>
SQL> create index idx_id_t1 on t1(id);
Index created.
SQL> create index idx_id_t2 on t2(id);
Index created.
SQL> create index idx_id_t3 on t3(id);
Index created.
SQL> create index idx_id_t4 on t4(id);
Index created.
SQL> create index idx_id_t5 on t5(id);
Index created.
SQL> create index idx_id_t6 on t6(id);
Index created.
SQL> 观察比较各个索引的大小
SQL> column segment_name format a20
SQL> select segment_name,bytes/1024
2 from user_segments
3 where segment_name in ('IDX_ID_T1','IDX_ID_T2','IDX_ID_T3','IDX_ID_T4','IDX_ID_T5','IDX_ID_T6');
SEGMENT_NAME BYTES/1024
-------------------- ----------
IDX_ID_T1 64
IDX_ID_T2 64
IDX_ID_T3 64
IDX_ID_T4 128
IDX_ID_T5 1024
IDX_ID_T6 9216
6 rows selected.
SQL>但是在统计索引高度时,我们观察发现这些索引的高度相差无几,记录数最小是5条,最大是50万条,而高度最小的是BLEVEL=0,表示1层,高度最大的是BLEVEL=2,表示3层,也就差了2层而已!
观察比较各个索引的高度
SQL> column index_name format a20
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_statistics
8 where table_name in ('T1','T2','T3','T4','T5','T6')
9 order by index_name;
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
-------------------- ---------- ----------- ---------- ------------- -----------------
IDX_ID_T1 0 1 5 5 1
IDX_ID_T2 0 1 50 50 1
IDX_ID_T3 1 2 500 500 1
IDX_ID_T4 1 11 5000 5000 9
IDX_ID_T5 1 110 50000 50000 101
IDX_ID_T6 2 1113 500000 500000 1035
6 rows selected.
SQL> 注意一下:其中BLEVEL表示高度,0表示第一个块还没被索引装满,没产生管理的索引块,这个0可以理解为高度是1层,1则表示高度为2层,以此类推。
上面下面,为什么IDX_ID_T1、IDX_ID_T2、IDX_ID_T3三个索引一样大啊,都是64KB,它们的表记录可是5、50和500啊?
数据库的最小单位虽然是块,但是最小的空间分配单位却是区,要存在一个段至少需要一个区,你说的三个索引,就是三个索引段。
比如一个区含有8个块,一个块有8KB,段的最小空间就是64KB了,这是预分配的空间,即便是建一张空表,大小也是64KB。在空表上建一个索引,这个索引大小还是64KB,表和索引的实际大小只要不超过64KB,数据库查询都是64KB这么大,因为一次性已经分配给你一个区的大小了。但是一旦超过64KB,即便超过一点点,分配到的空间可能马上就是128KB这么大了。
2.4.2 妙用索引高度较低的特性
我们建了6张表,其中t5表有5万条记录,而t6表有50万条记录。大家说说这两条查询语句 select * from t5 where id=10 和select *from t6 where id=10,它们都是返回一条记录,但是t6表的记录数是t5表的10倍,它们的查询速度会不会差别很大?
观察上述与t5、t6 表相关的索引扫描的性能
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> set timing on
SQL> select * from t5 where id=10;
Elapsed: 00:00:00.12
Execution Plan
----------------------------------------------------------
Plan hash value: 2977381114
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T5 | 1 | 10 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ID_T5 | 1 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=10)
Statistics
----------------------------------------------------------
395 recursive calls
6 db block gets
462 consistent gets
1 physical reads
1064 redo size
624 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
43 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL>
SQL>
SQL> select * from t6 where id=10;
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 661597417
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T6 | 1 | 10 | 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ID_T6 | 1 | | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=10)
Statistics
----------------------------------------------------------
341 recursive calls
6 db block gets
380 consistent gets
3 physical reads
964 redo size
624 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
40 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>这两个试验表明虽然一张表是5万条记录,另一张表是50万条记录,但是利用索引来返回同样记录数的查询,效率居然差不多?
主要是BLEVEL有关,产生的IO次数有点差别。速度相对也会有差别。
再次测试与t5、t6表相关的全表扫描查询的性能
SQL>
SQL> drop index IDX_ID_T5;
Index dropped.
Elapsed: 00:00:00.25
SQL> select * from t5 where id=10;
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 2002323537
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 32 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T5 | 1 | 10 | 32 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=10)
Statistics
----------------------------------------------------------
30 recursive calls
0 db block gets
155 consistent gets
0 physical reads
0 redo size
620 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> drop index IDX_ID_T6;
Index dropped.
Elapsed: 00:00:00.13
SQL> select * from t6 where id=10;
Elapsed: 00:00:00.04
Execution Plan
----------------------------------------------------------
Plan hash value: 1930642322
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 293 (2)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T6 | 1 | 10 | 293 (2)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=10)
Statistics
----------------------------------------------------------
101 recursive calls
0 db block gets
1090 consistent gets
1034 physical reads
0 redo size
620 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 可以看出,由于删除了索引,针对t5、t6表的查询逻辑读差异明显。说明性能也是非常明显的。
由此得出结论,索引的这个高度不高的特性给查询带来了巨大的便利,但是请注意,我们的查询只返回1条记录。如果查询返回绝大部分的数据,那用索引反而要慢得多。
2.4.3 分区索引设计误区
分区表的索引分为两种,一种是局部索引,一种是全局索引。局部索引等同于为每个分区段建分区的索引,从user_segment 的数据字典中,我们可以观察到表有多少个分区,就有多少个分区索引的段。
先建分区表part_tab,插入数据,并分别在col2上建局部索引,在col3上建全局索引。
分区索引相关试验的准备工作
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table part_tab_purge;
drop table part_tab_purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.10
SQL>
SQL>
SQL> create table part_tab(id int,col2 int,col3 int)
2 partition by range(id)
3 (
4 partition p1 values less than (10000),
5 partition p2 values less than (20000),
6 partition p3 values less than (30000),
7 partition p4 values less than (40000),
8 partition p5 values less than (50000),
9 partition p6 values less than (60000),
10 partition p7 values less than (70000),
11 partition p8 values less than (80000),
12 partition p9 values less than (90000),
13 partition p10 values less than (100000),
14 partition p11 values less than(maxvalue)
15 )
16 ;
Table created.
Elapsed: 00:00:00.05
SQL>
SQL> insert into part_tab select rownum,rownum+1,rownum+2 from dual connect by rownum <= 110000;
110000 rows created.
Elapsed: 00:00:00.14
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL>
SQL> create index idx_par_tab_col2 on part_tab(col2) local;
Index created.
Elapsed: 00:00:00.15
SQL> create index idx_par_tab_col3 on part_tab(col3);
Index created.
Elapsed: 00:00:00.09
SQL>分区索引情况查看
SQL> col segment_name format a20
SQL> col partition_name format a20
SQL> col segment_type format a20
SQL> select segment_name,partition_name,segment_type
2 from user_segments
3 where segment_name = 'PART_TAB';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------------- -------------------- --------------------
PART_TAB P1 TABLE PARTITION
PART_TAB P10 TABLE PARTITION
PART_TAB P11 TABLE PARTITION
PART_TAB P2 TABLE PARTITION
PART_TAB P3 TABLE PARTITION
PART_TAB P4 TABLE PARTITION
PART_TAB P5 TABLE PARTITION
PART_TAB P6 TABLE PARTITION
PART_TAB P7 TABLE PARTITION
PART_TAB P8 TABLE PARTITION
PART_TAB P9 TABLE PARTITION
11 rows selected.
Elapsed: 00:00:00.06
SQL>
SQL>
SQL> select segment_name,partition_name,segment_type
2 from user_segments
3 where segment_name = 'IDX_PAR_TAB_COL2';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------------- -------------------- --------------------
IDX_PAR_TAB_COL2 P1 INDEX PARTITION
IDX_PAR_TAB_COL2 P10 INDEX PARTITION
IDX_PAR_TAB_COL2 P11 INDEX PARTITION
IDX_PAR_TAB_COL2 P2 INDEX PARTITION
IDX_PAR_TAB_COL2 P3 INDEX PARTITION
IDX_PAR_TAB_COL2 P4 INDEX PARTITION
IDX_PAR_TAB_COL2 P5 INDEX PARTITION
IDX_PAR_TAB_COL2 P6 INDEX PARTITION
IDX_PAR_TAB_COL2 P7 INDEX PARTITION
IDX_PAR_TAB_COL2 P8 INDEX PARTITION
IDX_PAR_TAB_COL2 P9 INDEX PARTITION
11 rows selected.
Elapsed: 00:00:00.09
SQL>
SQL> select segment_name,partition_name,segment_type
2 from user_segments
3 where segment_name = 'IDX_PAR_TAB_COL3';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------------- -------------------- --------------------
IDX_PAR_TAB_COL3 INDEX
Elapsed: 00:00:00.03
SQL>
建一张普通表norm_tab,字段和记录数与part_tab一样,并且同样在col2和col3上分别建索引.
继续做准备工作,构建普通表及索引
SQL>
SQL> drop table norm_tab purge;
drop table norm_tab purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.08
SQL> create table norm_tab(id int,col2 int,col3 int);
Table created.
Elapsed: 00:00:00.03
SQL> insert into norm_tab select rownum,rownum+1,rownum+2 from dual connect by rownum <= 110000;
110000 rows created.
Elapsed: 00:00:00.16
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL> create index idx_nor_tab_col2 on norm_tab(col2);
Index created.
Elapsed: 00:00:00.11
SQL> create index idx_nor_tab_col3 on norm_tab(col3);
Index created.
Elapsed: 00:00:00.07
SQL>我们来看看分别针对part_tab和norm_tab两表的col2列的查询效率如何,语句分别是select* from part_tab where col2=8;和select * from norm_tab where col2=8;,依然采用set autotrace 的跟踪方式。先查看针对part_tab的查询结果,发现索引扫描遍历了全部11个分区,在执行计划中我们可以观察到,Pstart和Pstop是从1到11。
全分区索引扫描产生大量逻辑读
SQL>
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> set timing on
SQL> select * from part_tab where col2=8;
Elapsed: 00:00:00.05
Execution Plan
----------------------------------------------------------
Plan hash value: 3980401122
-------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 11 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE ALL | | 1 | 39 | 11 (0)| 00:00:01 | 1 | 11 |
| 2 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| PART_TAB | 1 | 39 | 11 (0)| 00:00:01 | 1 | 11 |
|* 3 | INDEX RANGE SCAN | IDX_PAR_TAB_COL2 | 1 | | 11 (0)| 00:00:01 | 1 | 11 |
-------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("COL2"=8)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
972 recursive calls
6 db block gets
1464 consistent gets
11 physical reads
1020 redo size
698 bytes sent via SQL*Net to client
618 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
102 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 普通表索引扫描逻辑读少得多
SQL>
SQL> select * from norm_tab where col2=8;
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 2321776653
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| NORM_TAB | 1 | 39 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_NOR_TAB_COL2 | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("COL2"=8)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
57 recursive calls
6 db block gets
164 consistent gets
2 physical reads
1008 redo size
702 bytes sent via SQL*Net to client
397 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 分别观察分区表和普通表的索引高度
SQL>
SQL> set autotrace off
SQL>
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_partitions
8 where index_name='IDX_PAR_TAB_COL2';
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
-------------------- ---------- ----------- ---------- ------------- -----------------
IDX_PAR_TAB_COL2 1 21 9999 9999 24
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10001 10001 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
11 rows selected.
Elapsed: 00:00:00.10
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_statistics
8 where index_name='IDX_NOR_TAB_COL2';
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
-------------------- ---------- ----------- ---------- ------------- -----------------
IDX_NOR_TAB_COL2 1 244 110000 110000 299
Elapsed: 00:00:00.21
SQL>分区索引扫描仅落在某一分区,性能大幅提升
SQL>
SQL> set autotrace traceonly
SQL> select * from part_tab where col2=8 and id=7;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2640417554
-------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 4 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE SINGLE | | 1 | 39 | 4 (0)| 00:00:01 | 1 | 1 |
|* 2 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| PART_TAB | 1 | 39 | 4 (0)| 00:00:01 | 1 | 1 |
|* 3 | INDEX RANGE SCAN | IDX_PAR_TAB_COL2 | 11 | | 3 (0)| 00:00:01 | 1 | 1 |
-------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("ID"=7)
3 - access("COL2"=8)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
698 bytes sent via SQL*Net to client
406 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>5.2.6 巧用三特征之存储列值