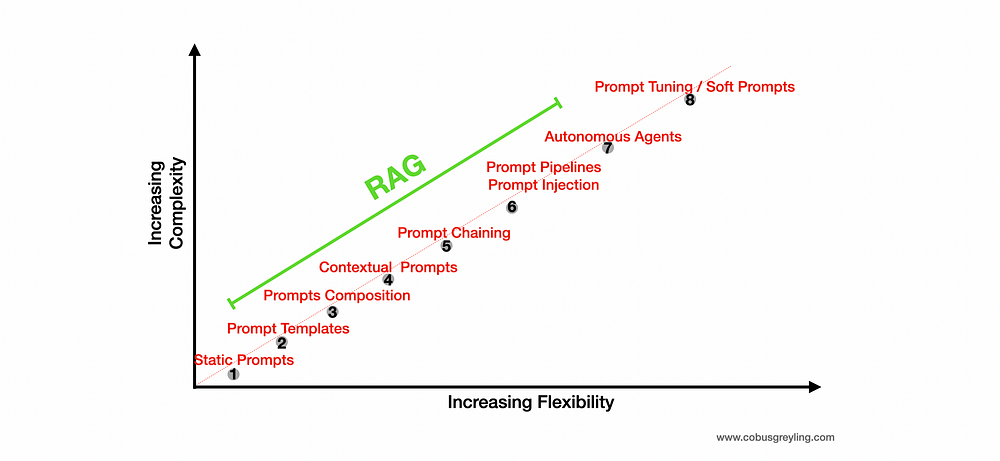
在开始使用像黑盒子一样的深度学习模型解决温度预测问题之前,我们先尝试一种基于常识的简单方法。
它可以作为一种合理性检查,还可以建立一个基准,更高级的机器学习模型需要超越这个基准才能证明其有效性。对于一个尚没有已知解决方案的新问题,这种基于常识的基准很有用。
对于一个尚没有已知解决方案的新问题,这种基于常识的基准很有用。
一个经典的例子是不平衡分类任务,其中某些类别比其他类别更常见。如果数据集中包含90%的类别A样本和10%的类别B样本,那么对于分类任务,一种基于常识的方法就是对新样本始终预测类别A。这种分类器的总体精度为90%,因此任何基于机器学习的方法的精度都应该高于90%,才能证明其有效性。有时候,这样的简单基准可能很难超越。
在本例中,我们可以放心地假设:温度时间序列是连续的(明天的温度很可能接近今天的温度),并且具有每天的周期性变化。因此,一种基于常识的方法是,始终预测24小时之后的温度等于现在的温度。我们用平均绝对误差(MAE)指标来评估这种方法,这一指标的定义如下:
np.mean(np.abs(preds - targets))政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
我们这篇文章是接着上一篇文章来进行演绎示例:
政安晨:【深度学习处理实践】(三)—— 处理时间序列的数据准备![]() https://blog.csdn.net/snowdenkeke/article/details/136570679评估循环如下代码所示:
https://blog.csdn.net/snowdenkeke/article/details/136570679评估循环如下代码所示:
(计算基于常识的基准的MAE)
def evaluate_naive_method(dataset):
total_abs_err = 0.
samples_seen = 0
for samples, targets in dataset:
# 温度特征在第1列,所以samples[:, -1, 1]是输入序列最后一个温度测量值。
# 之前我们对特征做了规范化,所以要得到以摄氏度为单位的温度值,
# 还需要乘以标准差并加上均值,以实现规范化的逆操作
preds = samples[:, -1, 1] * std[1] + mean[1]
total_abs_err += np.sum(np.abs(preds - targets))
samples_seen += samples.shape[0]
return total_abs_err / samples_seen
print(f"Validation MAE: {evaluate_naive_method(val_dataset):.2f}")
print(f"Test MAE: {evaluate_naive_method(test_dataset):.2f}")大家可以尝试下,看看评估结果:

对于这个基于常识的基准,验证MAE为2.44摄氏度,测试MAE为2.62摄氏度。
因此,如果假设24小时之后的温度总是与现在相同,那么平均会偏差约2.5摄氏度。
这个结果不算太差,但你可能不会基于这种启发式方法来推出天气预报服务。
接下来,我们将利用深度学习知识来得到更好的结果。
基本的机器学习模型
在尝试机器学习方法之前,建立一个基于常识的基准是很有用的。
同样,在开始研究复杂且计算代价很大的模型(如RNN)之前,尝试简单且计算代价很小的机器学习模型(比如小型的密集连接网络)也是很有用的。
这样做可以保证进一步增加问题复杂度是合理的,能够带来真正的好处。
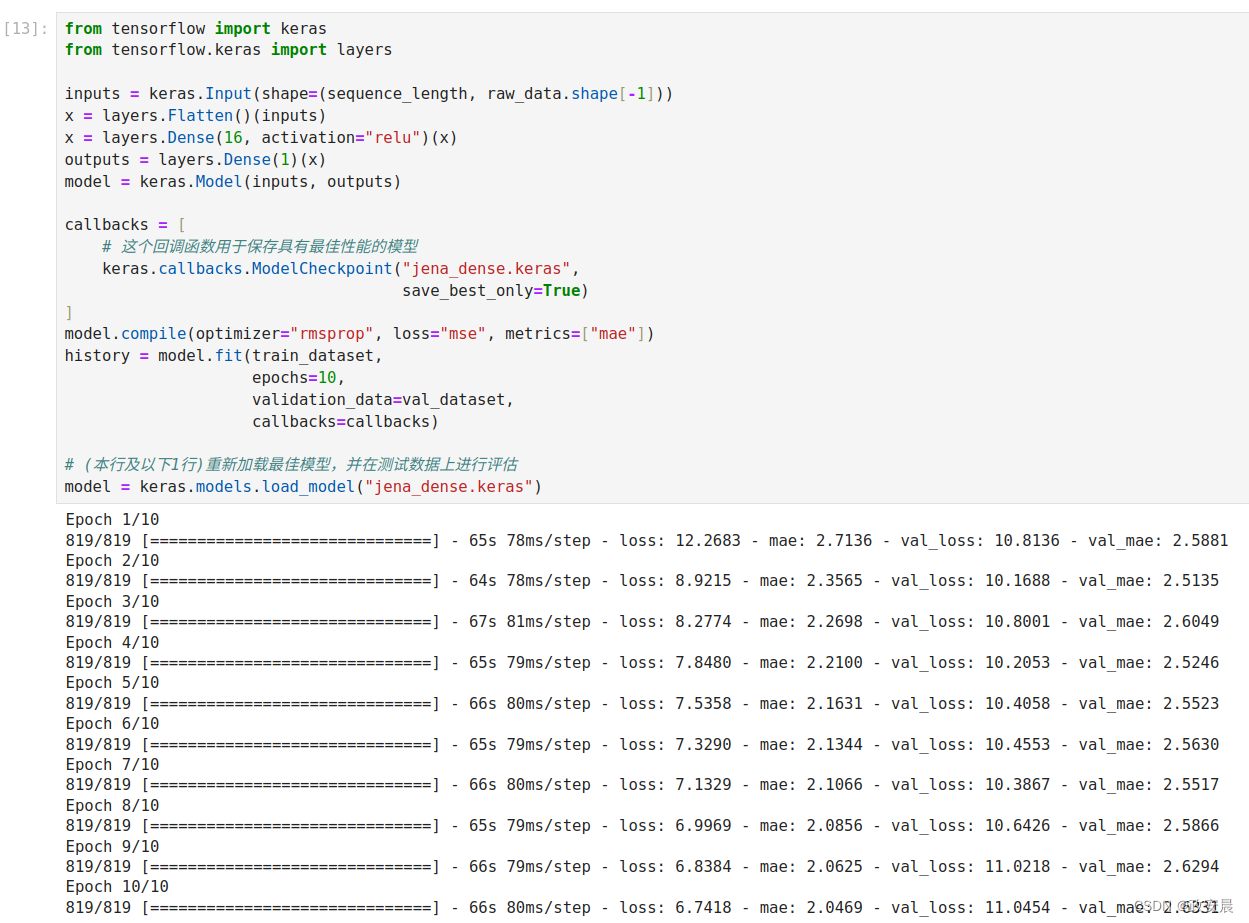
如下代码给出了一个全连接模型:首先将数据展平,然后是两个Dense层。请注意,最后一个Dense层没有激活函数,这是回归问题的典型特征。我们使用均方误差(MSE)作为损失,而不是平均绝对误差(MAE),因为MSE在0附近是光滑的(而MAE不是),这对梯度下降来说是一个有用的属性。我们在compile()中监控MAE这项指标。
(训练并评估一个密集连接模型)
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Flatten()(inputs)
x = layers.Dense(16, activation="relu")(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
# 这个回调函数用于保存具有最佳性能的模型
keras.callbacks.ModelCheckpoint("jena_dense.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
# (本行及以下1行)重新加载最佳模型,并在测试数据上进行评估
model = keras.models.load_model("jena_dense.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")演绎如下:
打印出来:

我们来绘制训练和验证的损失曲线,代码和画的图如下所示:
import matplotlib.pyplot as plt
loss = history.history["mae"]
val_loss = history.history["val_mae"]
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, "bo", label="Training MAE")
plt.plot(epochs, val_loss, "b", label="Validation MAE")
plt.title("Training and validation MAE")
plt.legend()
plt.show()画图如下:
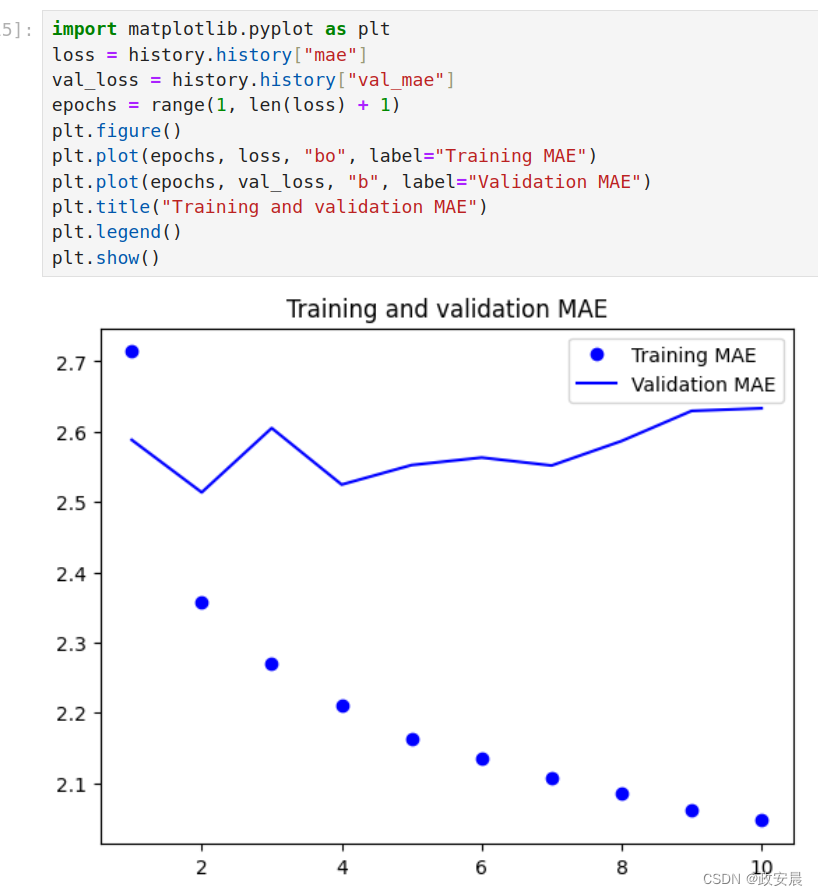
(上图为:一个简单的密集连接网络在耶拿温度预测任务上的训练MAE和验证MAE)
部分验证损失接近不使用机器学习的基准方法,但并不稳定。这也展示了首先建立基准的优点,事实证明,要超越这个基准并不容易。我们的常识中包含大量有价值的信息,而机器学习模型并不知道这些信息。
你可能会问,如果从数据到目标之间存在一个简单且表现良好的模型(基于常识的基准),那么我们训练的模型为什么没有找到它并进一步改进呢?
我们在模型空间(假设空间)中搜索解决方案,这个模型空间是具有我们所定义架构的所有双层网络组成的空间。基于常识的启发式方法只是这个空间所表示的数百万个模型中的一个。
这就好比大海捞针。从技术上说,假设空间中存在一个好的解决方案,但这并不意味着你可以通过梯度下降找到它。
总体来说,这是机器学习的一个重要限制:如果学习算法没有被硬编码为寻找某种特定类型的简单模型,那么有时候算法无法找到简单问题的简单解决方案。这就是好的特征工程和架构预设非常重要的原因:你需要准确告诉模型它要寻找什么。
一维卷积模型
说到利用正确的架构预设,由于输入序列具有每日周期性的特征,或许卷积模型可能有效。时间卷积神经网络可以在不同日期重复使用相同的表示,就像空间卷积神经网络可以在图像的不同位置重复使用相同的表示。
你已经学过Conv2D层和SeparableConv2D层,它们通过在二维网格上滑动的小窗口来查看输入。这些层也有一维甚至三维的版本:Conv1D层、SeparableConv1D层和Conv3D层。Conv1D层是在输入序列上滑动一维窗口,Conv3D层则是在三维输入物体上滑动三维窗口。
请注意,Keras中没有SeparableConv3D层。
这并不是因为任何理论上的原因,只是因为我还没有实现它。
因此,你可以构建一维卷积神经网络,它非常类似于二维卷积神经网络。它适用于遵循平移不变性假设的序列数据。这个假设的含义是,如果沿着序列滑动一个窗口,那么窗口的内容应该遵循相同的属性,而与窗口位置无关。
我们在温度预测问题上试一下一维卷积神经网络。
我们选择初始窗口长度为24,这样就可以每次查看24小时的数据(一个周期)。我们对序列进行下采样时(通过MaxPooling1D层),也会相应地减小窗口尺寸。
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Conv1D(8, 24, activation="relu")(inputs)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 12, activation="relu")(x)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 6, activation="relu")(x)
x = layers.GlobalAveragePooling1D()(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_conv.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_conv.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")演绎执行如下:
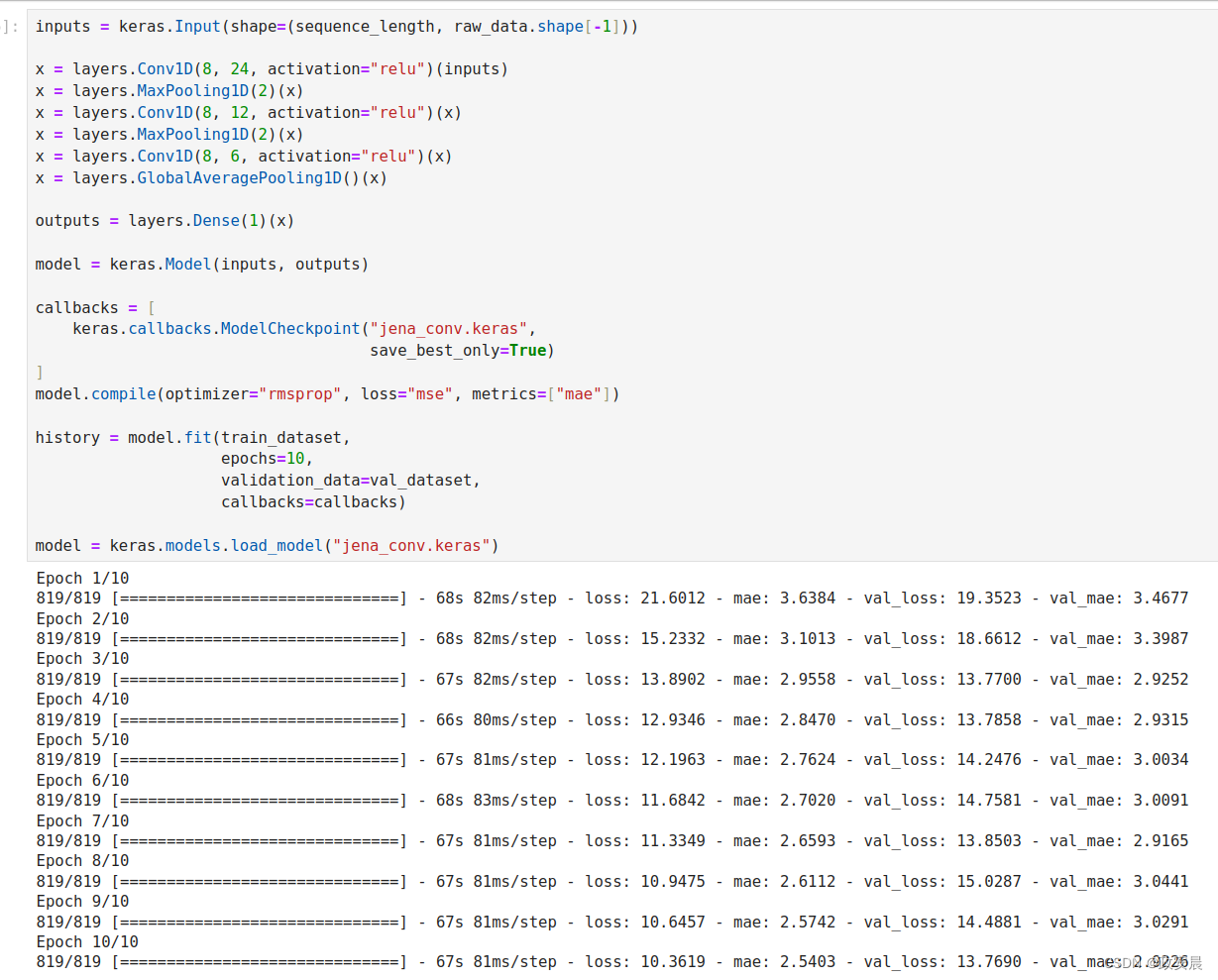
打印评估如下:

得到的训练曲线和验证曲线如下所示:
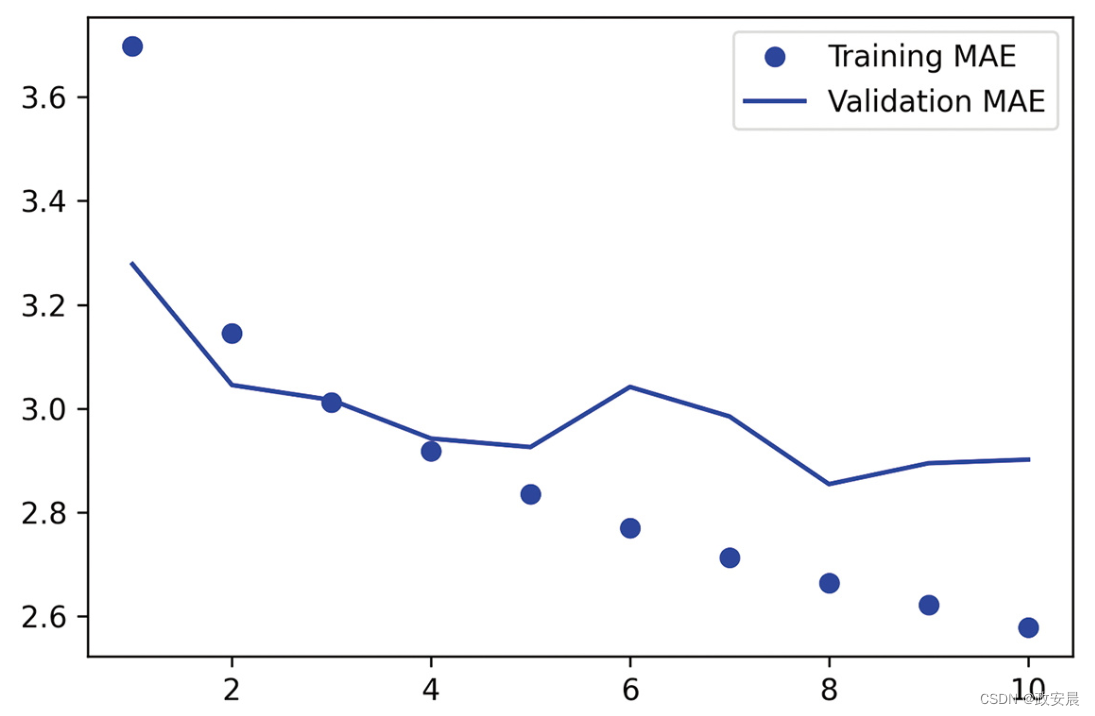
(一维卷积神经网络在耶拿温度预测任务上的训练MAE和验证MAE)
事实证明,这个模型的性能甚至比密集连接模型更差。它的验证MAE约为2.9摄氏度,比基于常识的基准差很多。出了什么问题?
有以下两个原因:
首先,天气数据并不完全遵循平移不变性假设。虽然数据具有每日周期性,但早晨的数据与傍晚或午夜的数据具有不同的属性。天气数据只在某个时间尺度上具有平移不变性。
其次,数据的顺序很重要。要想预测第2天的温度,最新的数据比5天前的数据包含更多的信息。一维卷积神经网络无法利用这一点。特别是,最大汇聚层和全局平均汇聚层在很大程度上破坏了顺序信息。
第一个RNN基准
全连接网络和卷积神经网络的效果都不是很好,但这并不意味着机器学习不适用于这个问题。密集连接网络首先将时间序列展平,这从输入数据中去除了时间的概念。
卷积神经网络对每段数据都用同样的方式处理,甚至还应用了汇聚运算,这会破坏顺序信息。
我们来看一下数据本来的样子:它是一个序列,其中因果关系和顺序都很重要。
有一类专门处理这种数据的神经网络架构,那就是RNN,其中,长短期记忆(Long Short Term Memory,LSTM)层长期以来一直很受欢迎。
我们稍后会介绍这种模型的工作原理,但我们先来试用一下LSTM层,代码如下所示:
(基于LSTM的简单模型)
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(16)(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_lstm.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")如下图所示,该模型的结果比之前的模型好多了!
验证MAE低至2.36摄氏度,测试MAE为2.55摄氏度。
基于LSTM的模型终于超越了基于常识的基准(尽管目前只超越了一点点),这证明了机器学习在这项任务上的价值。
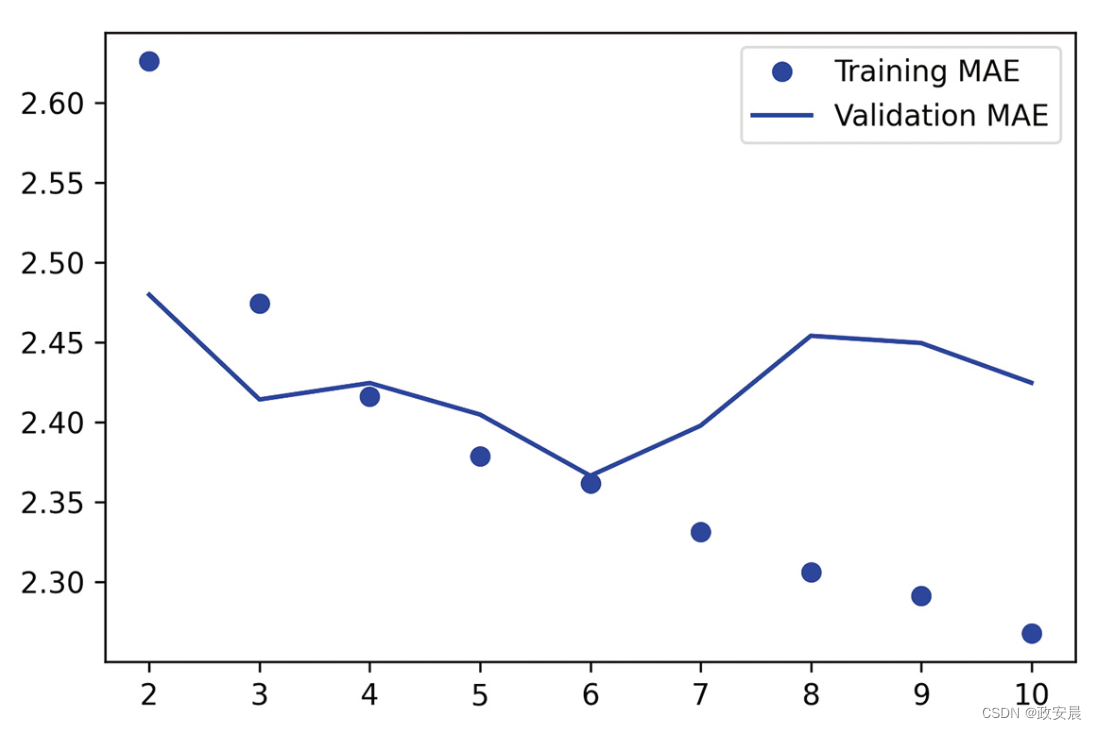
(基于LSTM的模型在耶拿温度预测任务上的训练MAE和验证MAE。
注意,图中没有显示第1轮,因为第1轮的训练MAE很大(7.75),会影响显示比例)
为什么LSTM模型的性能明显好于密集连接网络或卷积神经网络呢?我们又该如何进一步完善该模型呢?
以后的文章中,咱们会仔细看一下RNN。