原文地址:Five Stages Of LLM Implementation
大型语言模型显着提高了对话式人工智能系统的能力,实现了更自然和上下文感知的交互。这导致各个行业越来越多地采用人工智能驱动的聊天机器人和虚拟助手。
2024 年 2 月 20 日
介绍
从LLMs的市场采用情况可以清楚地看出,LLMs工具的开发远远领先于LLMs的实施;由于显而易见的原因,现实世界中的客户面临执行滞后。
从工具的角度来看,大部分关注和考虑都集中在LLMs第 4 阶段,但很快组织就会了解到,任何成功的人工智能实施都需要成功的数据策略。因此,LLMs第 5 阶段将受到更多关注。
当LLM实现从第一阶段转移到第二阶段,从设计时使用转移到运行时使用时,人们认识到数据需要在推理时传递给LLM 。
大量研究强调了情境学习 (ICL)的重要性,因此注入高度简洁、简明且情境相关的数据提示的重要性。
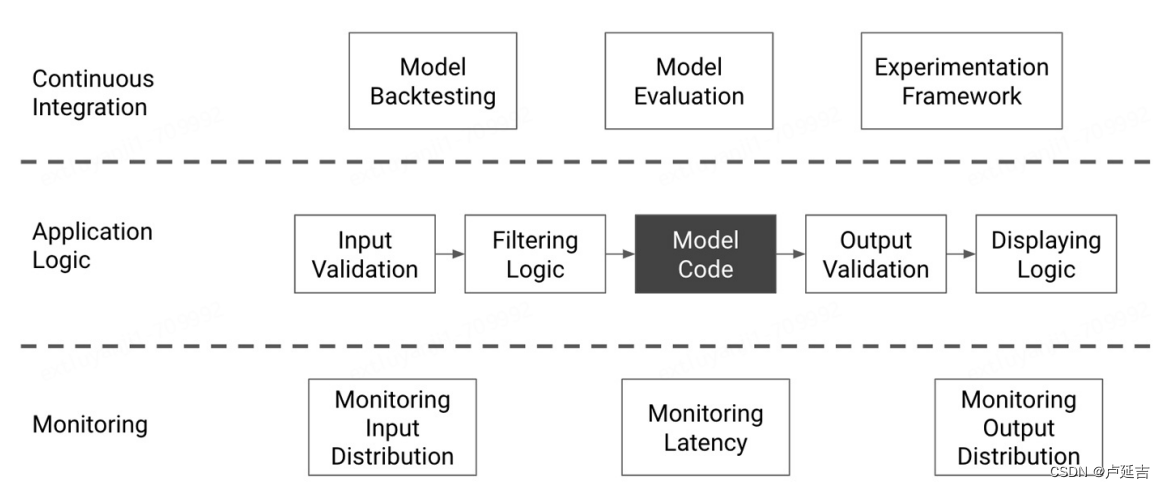
将LLMs投入生产
我最近在 LinkedIn 上询问将LLMs投入生产面临的挑战是什么,以下是提出的前五个问题。这些担忧之所以存在,是因为 LLM 主要由 LLM 提供商托管并通过 API 提供。
使用商用 API 引入了几乎无法管理的操作组件。
理想的情况是组织在本地安装了可以使用的LLMs。但这带来了大多数组织无法解决的挑战,例如托管、处理能力和其他技术需求。
是的,有“原始”开源模型可用,但这里的障碍又是托管、微调、技术专业知识等。

这些问题可以通过使用小语言模型来解决,在大多数情况下,这对于对话式人工智能的实现来说已经足够了。
LLM 颠覆:第一阶段
AI 辅助和加速 NLU 开发
LLM 实施的第一阶段侧重于机器人开发过程,特别是加速 NLU开发。
真正导致LLM 第一阶段 中断的原因是 LLM 功能是在设计时而不是运行时引入的。
这意味着推理延迟、大量使用、成本和 LLM 响应偏差等元素可能仅限于开发,而不会在生产环境中暴露给客户。
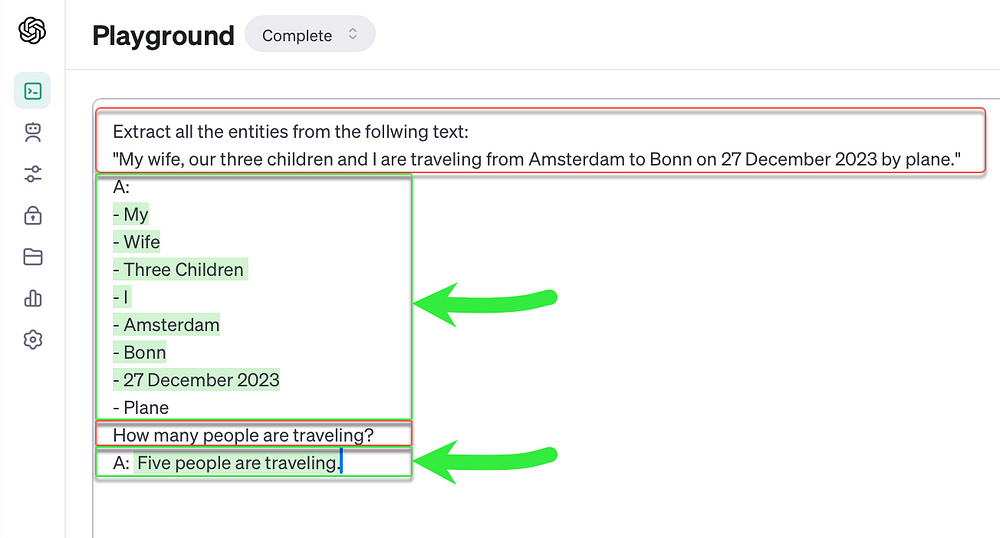
在上面的例子中,一个复杂的句子被提交给LLM,LLM能够从句子中提取所有相关实体并计算出行的总人数。
引入LLMs是为了协助 NLU 的开发,其形式是将现有客户话语聚类到语义相似的分组中以进行意图检测。一旦定义了意图标签和描述,就可以定义意图训练话语。
LLMs还可以用于实体检测等。
考虑下图,对话式人工智能实际上只需要如下所示的五个元素。传统的 NLU 引擎可以与 SLM 结合使用。
自从聊天机器人出现以来,我们的梦想就是拥有可靠、简洁、连贯且经济实惠的 NLG 功能。加上基本的内置逻辑和常识推理能力。
除此之外,还提供了管理对话上下文和状态的灵活途径,以及比 NLU 更知识密集的解决方案,SLM 似乎是完美的选择。
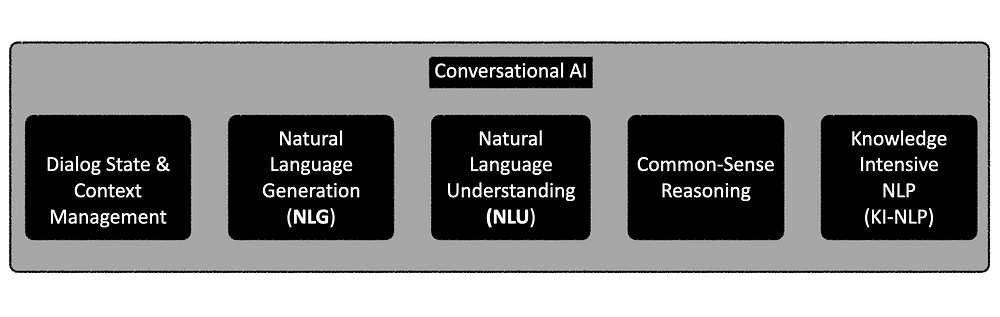
小语言模型 (SLM) 是 NLU 的良好配套技术。SLM 可以在本地运行,开源模型可用于执行自然语言生成 (NLG)、对话和上下文管理、常识推理、闲聊等任务。
将 NLU 与 SLM 结合使用来支持聊天机器人开发框架是非常可行的。
在本地运行 SLM 并使用增强生成方法和上下文学习可以解决推理延迟、令牌成本、模型漂移、数据隐私、数据治理等障碍。
人工智能辅助和加速聊天机器人开发
文案写作和人物角色
LLMs颠覆的下一阶段是使用LLMs/生成式人工智能进行聊天机器人和语音机器人文案写作,并改进机器人响应消息。
这种方法再次在设计时而不是运行时引入,充当机器人开发人员制作和改进机器人响应副本的助手。
设计师还可以向LLMs描述机器人的角色、语气和其他个性特征,以便制作一致且简洁的用户界面。
这是LLMs协助从设计时间扩展到运行时间的转折点。
LLM 用于动态生成响应并将其呈现给用户。第一个实现使用 LLM 来回答域外问题,或根据文档搜索和 QnA 制作简洁的响应。
LLMs首次用于:
- 数据和上下文增强响应。
- 自然语言生成(NLG)
- 对话管理;即使只有一两个对话回合。
第一阶段非常注重在设计时利用 LLM 和 Gen-AI,这在减轻不良用户体验、成本、延迟和任何推理异常方面具有许多优势。
就客户面临畸变或用户体验失败的风险而言,在设计时引入LLMs是一种安全的途径。这也是一种降低成本且无需面对客户和 PII 数据发送到云端的挑战的方法。
Flow Generation
接下来是LLMs和生成人工智能 (Gen-AI) 的更高级实现,开发人员向机器人描述如何开发 UI 以及特定功能的要求。
随后,开发 UI 启动,利用LLMs和生成式人工智能,它生成了流程,其中包含 API 占位符、所需的变量和 NLU 组件。
LLMs颠覆:第二阶段
文本编辑
第二阶段是在将机器人响应发送给用户之前使用LLMs来编辑文本。例如,在不同的聊天机器人媒介上,适当的消息大小不同。因此,可以通过要求LLMs总结、提取关键点并根据用户情绪改变响应语气来轻松控制机器人响应。
这意味着消息抽象层的硬性要求在某种程度上被废弃。在任何聊天机器人/对话式人工智能开发框架中,消息抽象层的工作就是保存一整套机器人响应消息。
这些机器人响应消息具有占位符,需要填充上下文特定数据以响应用户。
必须为每种模式和媒介定义不同的响应集。LLMs让即时制定回复变得更加容易。这就是我们一直在等待的NLG(自然语言生成)工具。
文档搜索和文档聊天
聊天机器人可以在推理时获得一份文档、一条信息,这使得LLMs能够有一个对话的参考框架。
扩展这种方法有两个障碍,第一个是有限的 LLM 上下文窗口的障碍,以及扩展这种方法。
RAG
Rag解决了上述问题。请在此处阅读有关 RAG 的更多信息。

提示链接
提示链接已进入对话式 AI 开发 UI,能够创建由一个或多个传递给 LLM 的提示组成的流程节点。
较长的对话回合可以与一系列提示串在一起,其中一个提示的输出充当另一个提示的输入。
在这些提示节点之间是决策和数据处理节点……因此提示节点与传统的对话流创建非常相似,但具有长期以来渴望的灵活性。
LLMs颠覆:第三阶段
Custom Playgrounds
技术供应商开始创建自己的具有额外功能的定制游乐场,并充当 IDE 和协作空间。
这使得用户不再仅仅使用基于LLMs的游乐场。定制游乐场提供了对多个模型的访问,以进行实验、协作和各种起始代码生成选项。
The Vercel Playground
Prompt Hubs
Haystack和LangChain都推出了基于社区的开放提示中心。
提示中心有助于编码和聚合不同提示工程方法的最佳实践。Gen-Apps 的愿景是成为 LLM 不可知论者,在申请的不同阶段使用不同的模型。
无代码微调
虽然微调改变了 LLM 的行为,并且RAG为推理提供了上下文参考,但微调在最近并未受到应有的关注。有人可能会说这是由于几个原因造成的……在此处内容。
LLM 颠覆:第四阶段
即时管道
在机器学习中,管道可以被描述为端到端的构造,它编排事件和数据流。
管道由触发器启动或启动;并基于某些事件和参数,遵循产生输出的流程。
在提示管道的情况下,流程在大多数情况下是由用户请求启动的。该请求被定向到特定的提示模板。
在这里内容。
自主代理
代理以自主方式使用预先分配的工具来执行一项或多项操作。代理遵循思想链推理方法。
自主代理的概念一开始可能会让人望而生畏,请在此处内容……
编排
从现在开始,市场还没有真正跟上……编排是指为一个应用程序编排多个LLMs。
LLMs托管
困扰 LLM 实施的大多数问题都与 LLM 不是自托管或托管在私有数据中心/云中有关。
如果LLMs是自托管和管理的,那么推理、模型 漂移、数据治理等方面的延迟响应都是可以解决的因素。
LLMs颠覆:第五阶段
数据发现
数据发现是识别企业内可用于 LLM 微调的任何数据的过程。最好的起点是联系中心的现有客户对话,可以是基于语音或文本的对话。其他值得发现的良好数据来源包括客户电子邮件、之前的聊天记录等。
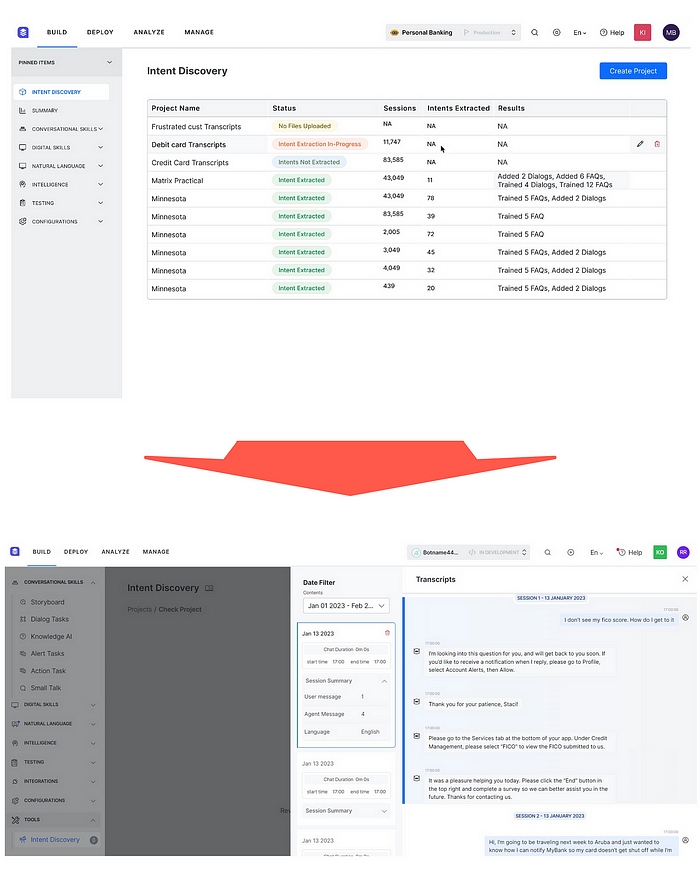
Kore XO 平台的这个示例展示了如何根据语义相似性导入和聚类不同的信息源。
这些数据应该通过人工智能加速数据生产力工具(潜在空间)发现,其中客户话语根据语义相似性进行分组,这些集群可以直观地表示如下所示,它们实际上是意图或分类;分类对于LLMs来说仍然很重要。
数据设计
数据设计是下一步,将发现的数据转换为 LLM 微调所需的格式。需要以特定方式对数据进行结构化和格式化,以用作可选的训练数据。设计阶段是对发现阶段的补充,在这个阶段,我们知道哪些数据是重要的,并且将对用户和客户产生最重大的影响。
因此,数据设计有两个方面,即数据的实际技术格式化以及训练数据的实际内容和语义。
数据开发
此步骤需要在运营方面持续监控和观察客户行为和数据性能。可以通过使用模型中观察到的漏洞来扩充训练数据来开发数据。
数据传输
数据交付可以最好地描述为向一个或多个模型注入与推理时的用例、行业和特定用户上下文相关的数据的过程。
LLMs会引用注入到提示中的上下文数据块,以在每个实例中提供准确的响应。
通常,各种数据传输方法被认为是相互排斥的,而一种方法被认为是最终的解决方案。
这种观点通常是由无知、缺乏理解、寻求权宜之计的组织或供应商将其特定产品作为灵丹妙药来推动的。
事实上,对于企业实施来说,灵活性和可管理性必然需要复杂性。

这适用于任何LLMs实施以及向LLMs交付数据所遵循的方法。答案不是一种特定的方法,例如RAG或Prompt Chaining;而是一种方法。而是一种平衡的多管齐下的方法。