链表基础知识详解
- 一、链表是什么?
- 1.链表的定义
- 2.链表的组成
- 3.链表的优缺点
- 4.链表的特点
- 二、链表的基本操作
- 1.链表的建立
- 2.链表的删除
- 3.链表的查找
- 4.链表函数
一、链表是什么?
1.链表的定义
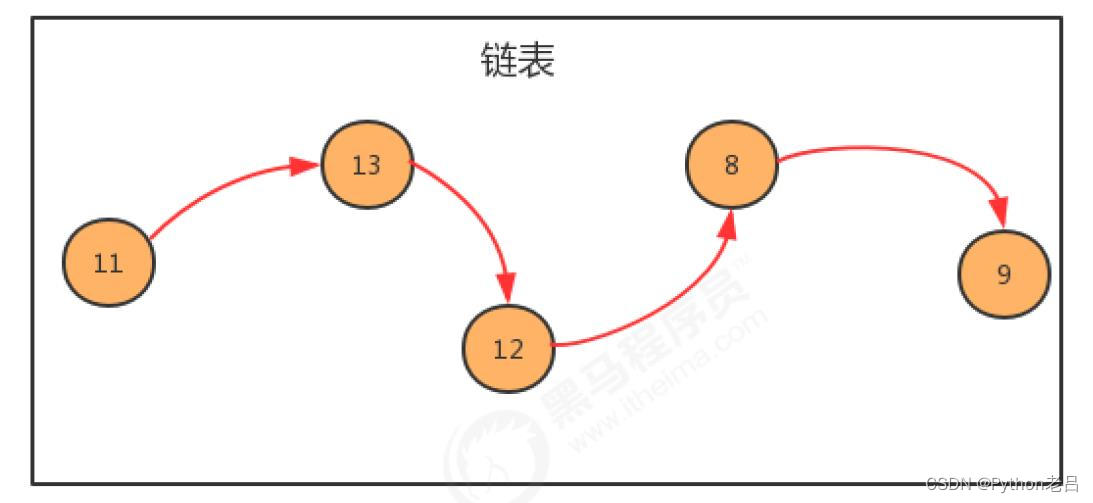
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
2.链表的组成
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
3.链表的优缺点
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。链表可以在多种编程语言中实现。像Lisp和Scheme这样的语言的内建数据类型中就包含了链表的存取和操作。程序语言或面向对象语言,如C,C++和Java依靠易变工具来生成链表。
4.链表的特点
线性表的链式存储表示的特点是用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。因此,为了表示每个数据元素 与其直接后继数据元素 之间的逻辑关系,对数据元素 来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。由这两部分信息组成一个"结点"(如概述旁的图所示),表示线性表中一个数据元素。线性表的链式存储表示,有一个缺点就是要找一个数,必须要从头开始找起,十分麻烦。
根据情况,也可以自己设计链表的其它扩展。但是一般不会在边上附加数据,因为链表的点和边基本上是一一对应的(除了第一个或者最后一个节点,但是也不会产生特殊情况)。不过有一个特例是如果链表支持在链表的一段中把前和后指针反向,反向标记加在边上可能会更方便。
对于非线性的链表,可以参见相关的其他数据结构,例如树、图。另外有一种基于多个线性链表的数据结构:跳表,插入、删除和查找等基本操作的速度可以达到O(平衡二叉树一样。
其中存储数据元素信息的域称作数据域(设域名为data),存储直接后继存储位置的域称为指针域(设域名为next)。指针域中存储的信息又称做指针或链。
由分别表示,,…,的N 个结点依次相链构成的链表,称为线性表的链式存储表示,由于此类链表的每个结点中只包含一个指针域,故又称单链表或线性链表。
二、链表的基本操作
1.链表的建立
第一行读入n,表示n个数
第二行包括n个数
以链表的形式存储输出这些数
program project1;
type
point=^node;
node=record
data:longint;
next:point;
end;
var
i,n,e:longint;
p,q,head,last:point;
begin
write('Input the number count:');
readln(n);
i:=1;
new(head);
read(e);
head^.data:=e;
head^.next:=nil;
last:=head;
q:=head;
while i<n do
begin
inc(i);
read(e);
new(p);
q^.next:=p;
p^.data:=e;
p^.next:=nil;
last:=p;
q:=last
end;
//建立链表
q:=head;
while q^.next<>nil do
begin
write(q^.data,'');
q:=q^.next;
end;
write(q^.data);
//输出
readln;
readln
end.
2.链表的删除
在以z为头的链表中搜索第一个n,如果找到则删去,返回值为1,否则返回0
function delete(n:longint;var z:point):longint;
var
t,s:point;
begin
t:=z;
while(t^.next<>nil)and(t^.data<>n)do
begin
s:=t;
t:=t^.next;
end;
if t^.data<> nthen exit(0);
s^.next:=t^.next;
dispose(t);
exit⑴
end;
3.链表的查找
类似于删除,只需要找到不删即可
插入
插入,在以zz为头的链表第w个的前面插入nn元素,函数返回值正常是0,如果w超过了链表的长度,函数返回链表的长度
function insert(w,nn:longint;var zz:point):longint;
var d:longint;v,vp,vs:point;
begin
v:=zz;
for d:=1 to w do
if v^.next=nil
then exit(d)
else
begin
vp:=v;
v:=v^.next;
end;
new(vs);
vs^.data:=nn;
vp^.next:=vs;
vs^.next:=v;
exit(0)
end;
4.链表函数
#include<stdio.h>
#include<stdlib.h>
#include<iostream.h>
usingnamespacestd;
structNode
{
intdata;//数据域
structNode*next;//指针域
};
/*
Create
*函数功能:创建链表.
*输入:各节点的data
*返回值:指针head
*/
Node*Create()
{
intn=0;
Node*head,*p1,*p2;
p1=p2=newNode;
cin>>p1->data;
head=NULL;
while(p1->data!=0)
{
if(n==0)
{
head=p1;
}
else
p2->next=p1;
p2=p1;
p1=newNode;
cin>>p1->data;
n++;
}
p2->next=NULL;
returnhead;
}
/*
insert
*函数功能:在链表中插入元素.
*输入:head链表头指针,p新元素插入位置,x新元素中的数据域内容
*返回值:无
*/
voidinsert(Node*head,intp,intx)
{
Node*tmp=head;//for循环是为了防止插入位置超出了链表长度
for(inti=0;i<p;i++)
{
if(tmp==NULL)
return;
if(i<p-1)
tmp=tmp->next;
}
Node*tmp2=newNode;
tmp2->data=x;
tmp2->next=tmp->next;
tmp->next=tmp2;
}
/*
del
*函数功能:删除链表中的元素
*输入:head链表头指针,p被删除元素位置
*返回值:被删除元素中的数据域.如果删除失败返回-1
*/
intdel(Node*head,intp)
{
Node*tmp=head;
for(inti=0;i<p;i++)
{
if(tmp==NULL)
return-1;
if(i<p-1)
tmp=tmp->next;
}
intret=tmp->next->data;
tmp->next=tmp->next->next;
returnret;
}
voidprint(Node*head)
{
for(Node*tmp=head;tmp!=NULL;tmp=tmp->next)
printf("%d",tmp->data);
printf("\n");
}
intmain()
{
Node*head;
head=newNode;
head->data=-1;
head->next=NULL;
return0;
}
例子
#include<iostream>
#defineNULL0
structstudent
{
longnum;
structstudent*next;
};
intmain()
{
inti,n;
student*p=(structstudent*)malloc(sizeof(structstudent));
student*q=p;
printf("输入几个值");
scanf("%d",&n);
for(i=1;i<=n;i++)
{
scanf("%d",&(q->num));
q->next=(structstudent*)malloc(sizeof(structstudent));
q=q->next;
}
printf("值第几个");
intrank;
scanf("%d%d",&(q->num),&rank);
student*w=p;
for(i=1;i<rank-1;i++)
{
w=w->next;
}
q->next=w->next;
w->next=q;
for(i=1;i<=n+1;i++)
{
printf("%d",p->num);
p=p->next;
}
return0;
}//指针后移麻烦链表形式循环链表
循环链表是与单链表一样,是一种链式的存储结构,所不同的是,循环链表的最后一个结点的指针是指向该循环链表的第一个结点或者表头结点,从而构成一个环形的链。
循环链表的运算与单链表的运算基本一致。所不同的有以下几点:
1、在建立一个循环链表时,必须使其最后一个结点的指针指向表头结点,而不是象单链表那样置为NULL。此种情况还使用于在最后一个结点后插入一个新的结点。
2、在判断是否到表尾时,是判断该结点链域的值是否是表头结点,当链域值等于表头指针时,说明已到表尾。而非象单链表那样判断链域值是否为NULL。
双向链表
双向链表其实是单链表的改进。
当我们对单链表进行操作时,有时你要对某个结点的直接前驱进行操作时,又必须从表头开始查找。这是由单链表结点的结构所限制的。因为单链表每个结点只有一个存储直接后继结点地址的链域,那么能不能定义一个既有存储直接后继结点地址的链域,又有存储直接前驱结点地址的链域的这样一个双链域结点结构呢?这就是双向链表。
在双向链表中,结点除含有数据域外,还有两个链域,一个存储直接后继结点地址,一般称之为右链域;一个存储直接前驱结点地址,一般称之为左链域。
应用举例概述
约瑟夫环问题:已知n个人(以编号1,2,3…n分别表示)围坐在一张圆桌周围。从编号为k的人开始报数,数到m的那个人出列;他的下一个人又从1开始报数,数到m的那个人又出列;依此规律重复下去,直到圆桌周围的人全部出列。例如:n = 9,k = 1,m = 5
参考代码
#include<stdio.h>
#include<malloc.h>
#defineN41
#defineM5
typedefstructnode*link;
structnode
{
intitem;
linknext;
};
linkNODE(intitem,linknext)
{
linkt=malloc(sizeof*t);
t->item=item;
t->next=next;
returnt;
}
intmain(void)
{
inti;
linkt=NODE(1,NULL);
t->next=t;
for(i=2;i<=N;i++)
t=t->next=NODE(i,t->next);
while(t!=t->next)
{
for(i=1;i<M;i++)
t=t->next;
t->next=t->next->next;
}
printf("%d\n",t->item);
return0;
}
如若本文能帮您, 希望您能关注Python老吕的CSDN博客 ;
您可以在本文进行评论,老吕将努力快速回复,和您近距离交流各种问题;
博主ID:Python老吕,希望大家点赞、评论、收藏。