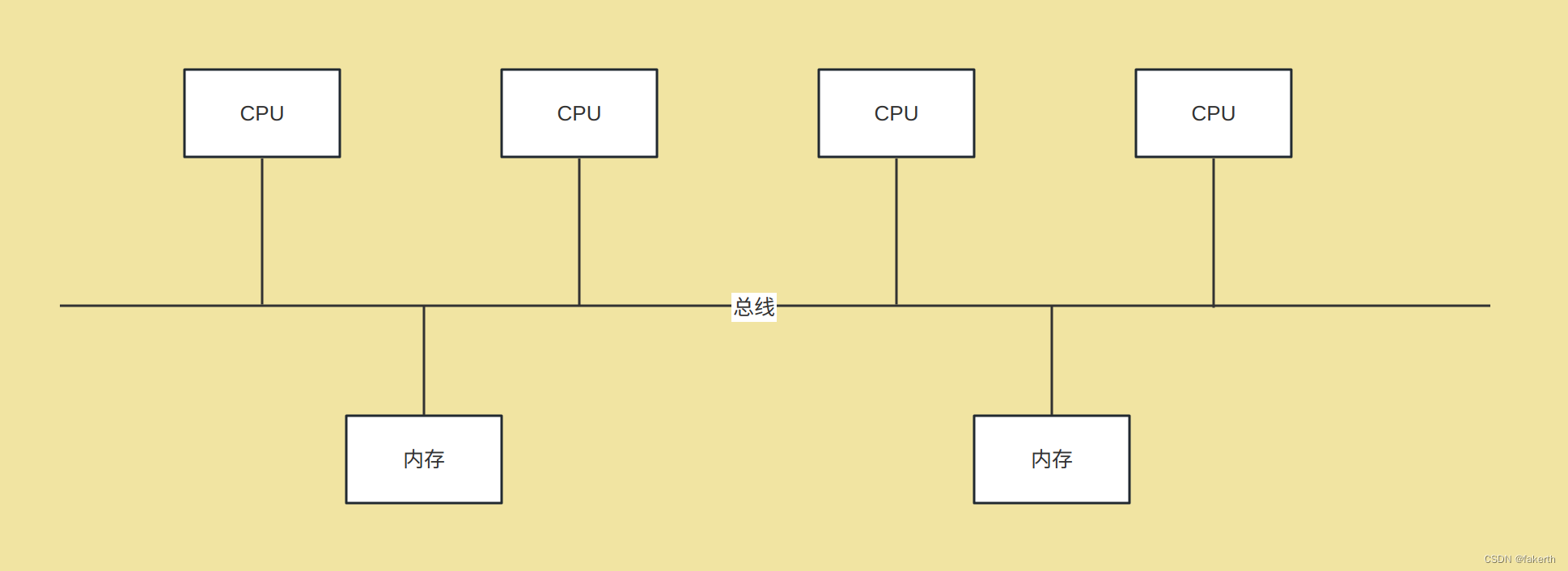
UMA架构
在单cpu的时代,cpu与内存的交互需要通过北桥芯片来完成。cpu通过前端总线(FSB, front Side Bus)连接到北桥芯片,由北桥芯片连接到内存(内存控制器是集成在北桥芯片里的)。为了提升性能,cpu的频率不断提高,后又向多核发展。多核也是共享一个北桥来读取内存。在多处理器的系统里,多个cpu共享相同的物理内存,每个cpu访问内存的任何时间所需时间相同,这种架构被称为一致性内存访问模型(Uniform-memory-Access, 简称UMA)。
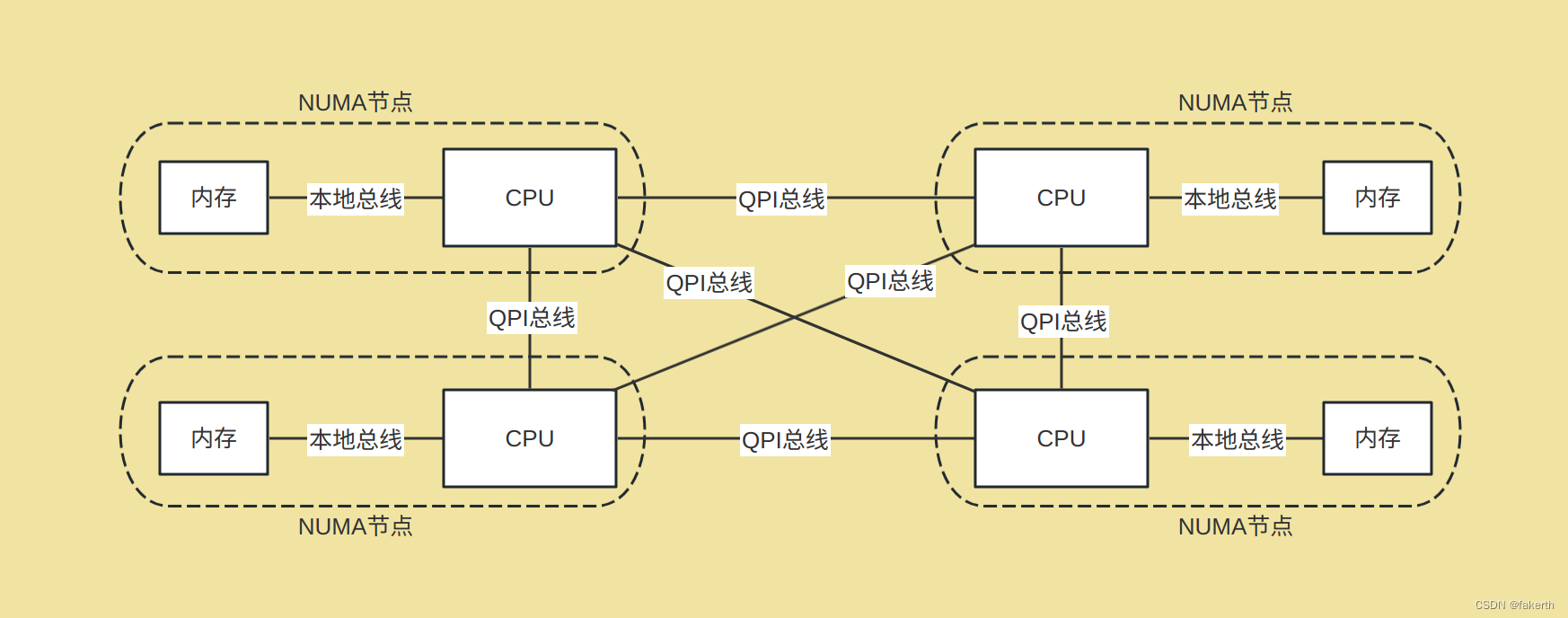
NUMA架构
UMA的主要特征是共享,系统中的资源cpu、内存、io等都是共享的,这就导致了它的扩展能力是有限的,对它而言,每一个共享的环节都是造成其扩展的瓶颈。尤其是,随着核数的增多,cpu对总线、北桥(内存控制器)的争用越来越激烈,它们在响应时间上的性能瓶颈越来越明显。为了消除UMA架构的瓶颈,硬件工程师将原集成在北桥芯片中的内存控制器进行了拆分,将其集成到cpu中,一般一个cpu socket都有一个独立的内存控制器,每个cpu socket也独立连接到一部分对立的内存,这部分CPU直连的内存被称为本地内存。cpu之间通过QPI总线连接,CPU 可以通过QPI总线访问不和自己直连的“远程内存”。这种架构模型,cpu访问本地内存与远程内存所用的时间是不一样的,一般访问本地内存要比访问远程内存快,因此也被称做非一致或非均匀内存访问模型(Nonuniform-Memory-Access, 简称NUMA)。这种构架下,不同的内存器件和CPU核心从属不同的 Node,每个 Node 都有自己的集成内存控制器(IMC,Integrated Memory Controller)。在 Node 内部,架构类似SMP,使用 IMC Bus 进行不同核心间的通信;不同的 Node 间通过QPI(Quick Path Interconnect)进行通信,如下图所示:
UMA使用单内存控制器,占用内存带宽有限。而NUMA机器通过使用多个内存控制器来增强内存的可用带宽。
感受NUMA
NUMA Node
numactl --hardware
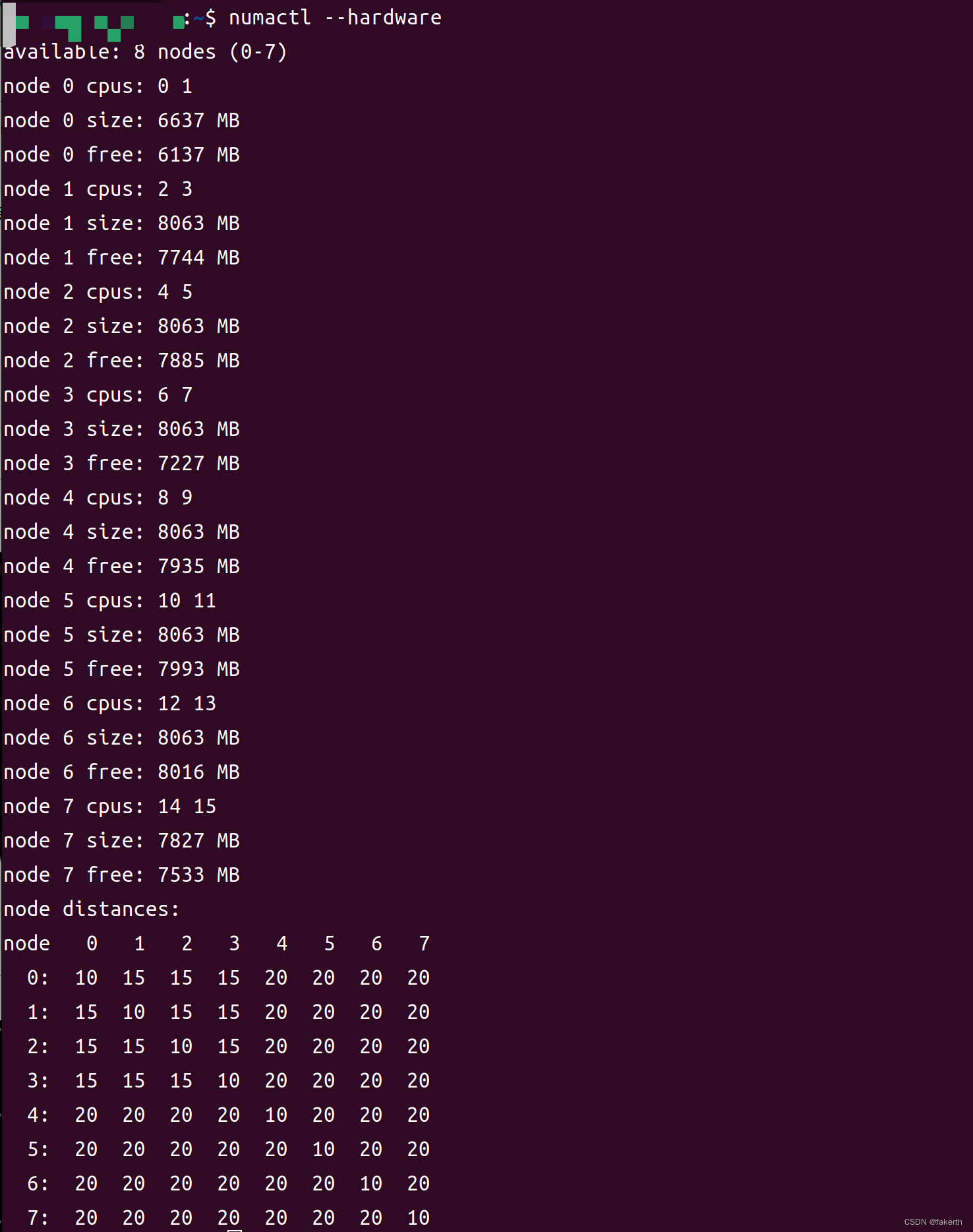
如图所示,系统中共有8个节点(0-7),每个节点都有一定数量的CPU和可用内存。以下是每个节点的一些信息:
节点0:具有CPU 0和1,拥有6637 MB的内存,其中6137 MB是可用的。
节点1:具有CPU 2和3,拥有8063 MB的内存,其中7744 MB是可用的。
节点2:具有CPU 4和5,拥有8063 MB的内存,其中7885 MB是可用的。
节点3:具有CPU 6和7,拥有8063 MB的内存,其中7227 MB是可用的。
节点4:具有CPU 8和9,拥有8063 MB的内存,其中7935 MB是可用的。
节点5:具有CPU 10和11,拥有8063 MB的内存,其中7993 MB是可用的。
节点6:具有CPU 12和13,拥有8063 MB的内存,其中8016 MB是可用的。
节点7:具有CPU 14和15,拥有7827 MB的内存,其中7533 MB是可用的。
最后,输出还提供了节点之间的距离矩阵。距离值表示从一个节点到另一个节点的访问延迟。距离值越低,访问延迟越小。在这个例子中,节点之间的距离矩阵以节点编号的形式给出,数值越低表示节点之间的距离越近。
查看指定进程NUMA使用情况
numastat -p `ps -aux | grep 'top' | grep -v 'grep' | awk '{print $2}'`
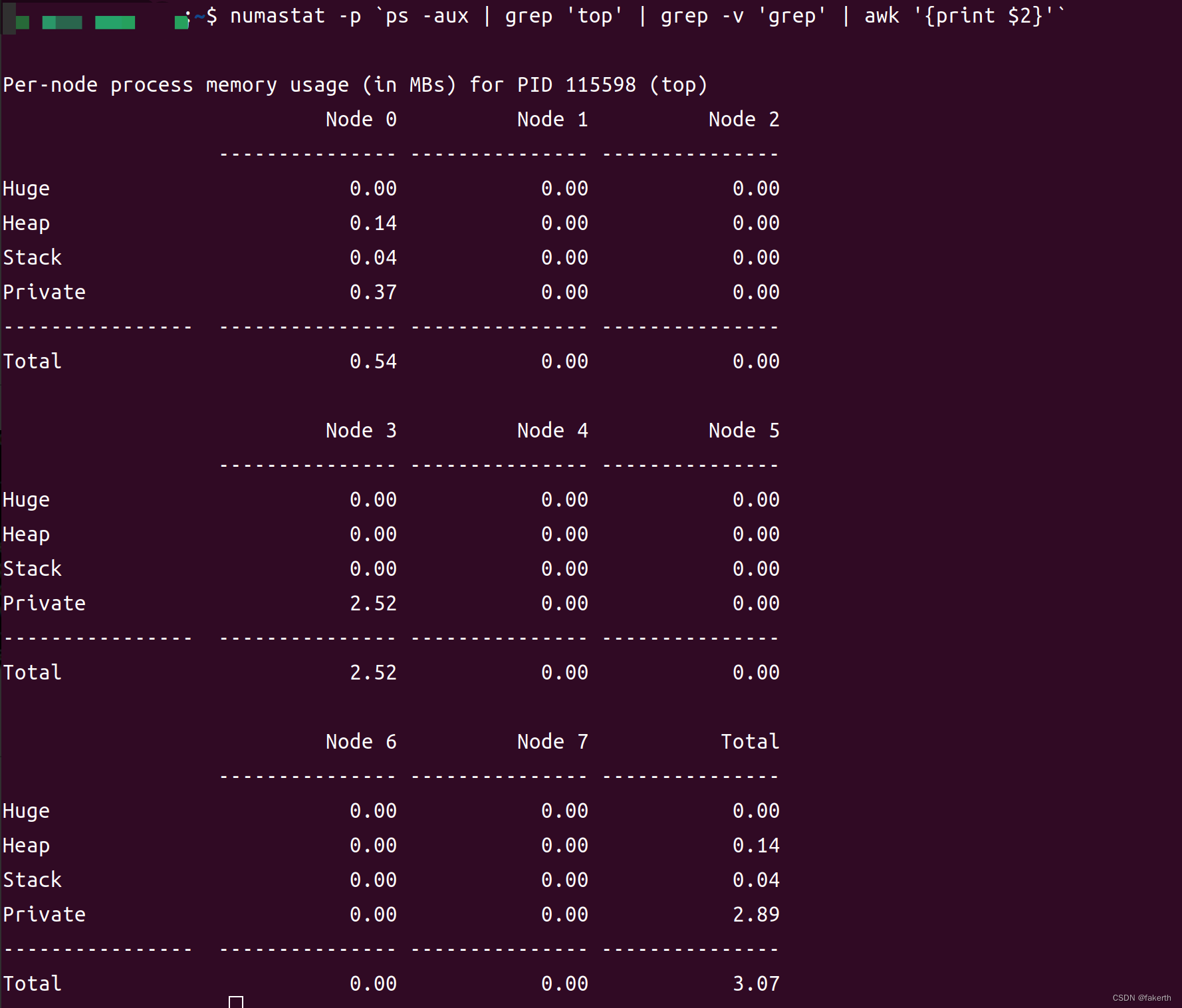
“Huge”、“Heap”、"Stack"和"Private"是描述进程在NUMA架构中使用的不同类型内存的术语。
-
Huge(巨大):指的是进程使用的大页面内存(通常为2MB或更大)。大页面内存可以提高内存访问性能,尤其对于大量数据的访问和处理。
-
Heap(堆):指的是进程使用的动态分配的堆内存。堆内存用于存储动态分配的对象、变量和数据结构。
-
Stack(栈):指的是进程使用的栈内存,用于存储函数调用、局部变量和函数参数等。栈内存是按照后进先出(LIFO)的原则进行管理。
-
Private(私有):指的是进程使用的私有内存,该内存只能由进程本身访问。私有内存包括进程的代码、堆栈和其他私有数据。
NUMA状态
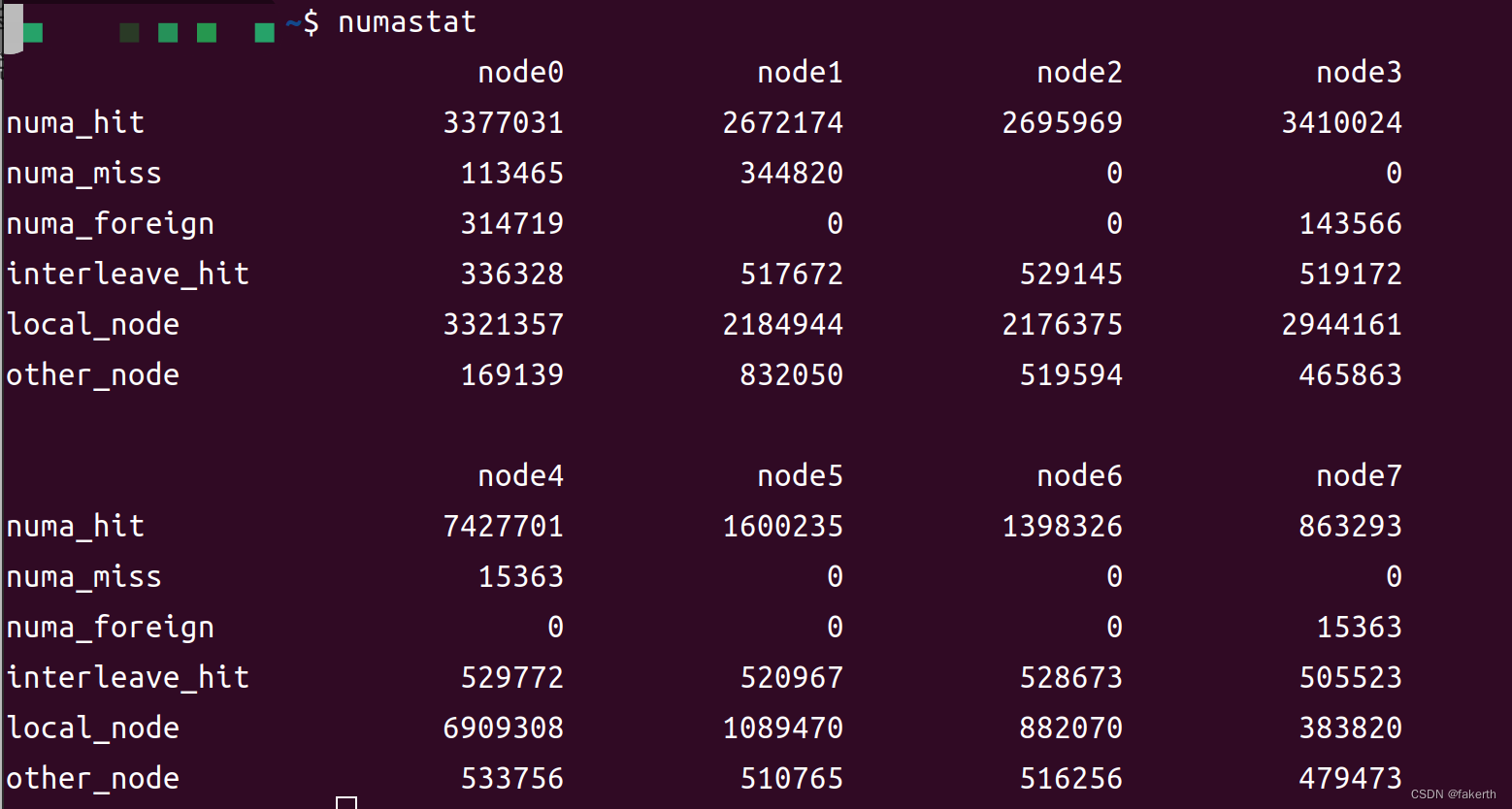
这是使用"numastat"命令获取的与NUMA架构相关的统计数据的输出。这些数据提供了关于NUMA节点之间内存访问的信息。
输出中的每个节点都显示了以下统计数据:
- numa_hit:表示在本地节点上成功访问的内存页数。
- numa_miss:表示在本地节点上无法找到的内存页数,需要从其他节点获取。
- numa_foreign:表示在其他节点上成功访问的内存页数。
- interleave_hit:表示在本地节点和其他节点之间成功交织(interleave)访问的内存页数。
- local_node:表示在本地节点上访问的总内存页数。
- other_node:表示在其他节点上访问的总内存页数。
设置进程在指定的CPU上运行
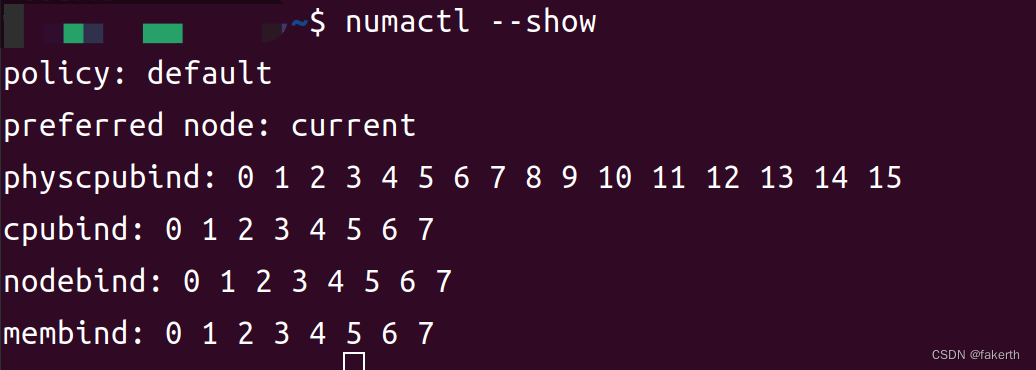
输出中的每个配置选项都表示以下内容:
-
policy:表示NUMA绑定的策略。在此输出中,策略设置为"default",表示使用系统的默认策略。
-
preferred node:表示首选节点。在此输出中,首选节点设置为"current",表示首选节点与当前执行进程所在的节点相同。
-
physcpubind:表示CPU绑定,即将进程绑定到特定的物理CPU上。在此输出中,进程绑定到了CPU 0到15上。
-
cpubind:表示CPU绑定,与上述的physcpubind相同,但只显示了绑定到的CPU列表。在此输出中,进程绑定到了CPU 0到7上。
-
nodebind:表示NUMA节点绑定,即将进程绑定到特定的NUMA节点上。在此输出中,进程绑定到了节点0到7上。
-
membind:表示NUMA内存绑定,即将进程的内存分配限制在特定的NUMA节点上。在此输出中,进程内存绑定到了节点0到7上。
nohup numactl --cpunodebind=0,1,2,3,4 --localalloc /gekkofs-port/deps_install/lib/bin/gkfs_daemon -P "ucx+all" -l $listen_ip -r /dev/shm/data -m /dev/shm/gkfs &