愿你千山暮雪
海棠依旧
不为岁月惊扰平添忧愁
🎥前期回顾-二叉树
🔥数据结构专栏
期待小伙伴们的支持与关注!!!
目录
前期回顾
二叉堆的概念及结构
二叉堆的创建
顺序表的结构声明
顺序表的创建与销毁
二叉堆的插入
二叉堆显示堆顶元素
二叉堆的删除
二叉堆的判空
整体代码实现

前期回顾
二叉树的顺序结构
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。而我们今天学的 堆 总是一棵 完全二叉树
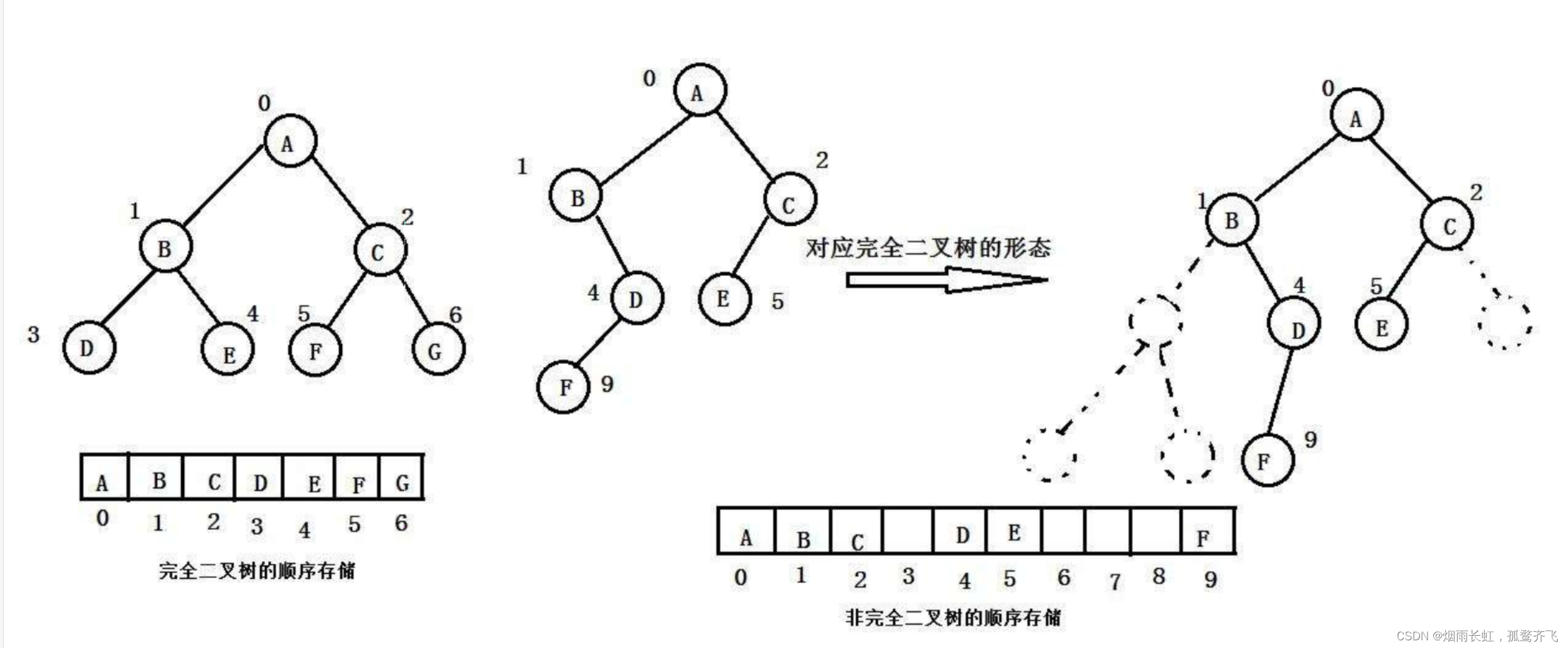
作为一棵完全二叉树,二叉堆可以用一个1-n 的数组来存储
对于双亲节点p,p*2+1即为左孩子,p*2+2即为右孩子
对于孩子节点 child 求双亲结点 parent 即 parent = (child - 1) / 2
同时,用size记录当前二叉堆中节点的个数
顺序存储的结论
| 如果 i 为0,则 i 表示的节点为根节点,否则 i 节点的双亲节点为 (i - 1)/2 |
| 如果 2 * i + 1 小于节点个数,则节点 i 的左孩子下标为 2 * i + 1,否则没有左孩子 |
| 如果 2 * i + 2 小于节点个数,则节点 i 的右孩子下标为 2 * i + 2,否则没有右孩子 |
二叉堆(Binary Heap)是最简单、常用的堆,是一棵符合堆的性质的 完全二叉树
它可以实现 O(logn) 的 插入 或 删除 某个值,并且 O(1) 地查询 最大(或最小)值
二叉堆的概念及结构
概念#
堆在运用范围上:用来在一组变化频繁(发生增删查改的频率较高)的数据集中查找最值
堆在物理层面上:表现为一组连续的数组区间 long[ ] array 将整个数组看作是堆
堆在逻辑结构上:一般被视为是一颗完全二叉树
结构#
如果有一个关键码的集合K = {K0 ,K1 ,K2 ,…,Kn-1 },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中并满足:Ki <=K2*i+1 且 Ki<=K2*i+2 ( Ki >=K2*i+1 且Ki>=K2*i+2 ) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质#
小根堆#
堆中某个节点的值总是不大于或不小于其双亲节点的值 堆总是一棵完全二叉树
<1>双亲节点的值 小于或等于 子节点的值 大根堆#
<2>双亲节点的值 大于或等于 子节点的值


二叉堆的创建
下面以 小根堆 进行演示
顺序表的结构声明
#include<stdio.h> #include<stdlib.h> #include<assert.h> #include<stdbool.h> typedef int HeapDataType; typedef struct Heap { int size; int capacity; HeapDataType* data; }HP;

顺序表的创建与销毁
创建
void HPInit(HP* php) { assert(php); php->data = NULL; php->capacity = php->size = 0; }销毁
void HPDestroy(HP* php) { assert(php); free(php->data); php->data = NULL; php->capacity = 0; php->size = 0; }
二叉堆的插入
顺序表的基本结构
void HPPush(HP* php, HeapDataType x) { assert(php); if (php->capacity == php->size) { int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity; HeapDataType* newNode = (HeapDataType*)realloc(php->data, sizeof(HeapDataType) * newcapacity); if (newNode == NULL) { perror("realloc"); exit(-1); } php->data = newNode; php->capacity = newcapacity; } php->data[php->size] = x; php->size++; AdjustUp(php->data, php->size - 1); }交换函数 交换孩子与双亲之间的位置
void Swap(HeapDataType* n, HeapDataType* m) { HeapDataType tmp = *n; *n = *m; *m = tmp; }我们以下面这两颗树为例
如何 插入 元素,同时维护二叉堆的性质?
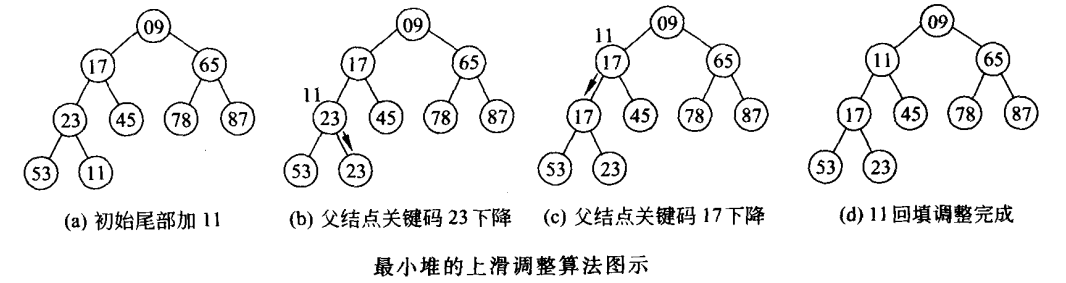
如果我们想在二叉堆中插入一个数 11 或者 10
我们可以采用上调算法:该子节点不断与双亲节点比较,如果比双亲节点 小 就与之交换
直到不大于双亲节点或成为根节点为止
上调算法
void AdjustUp(HeapDataType* data, int child) { // 找到child的双亲 int parent = (child - 1) / 2; while (child > 0) { if (data[child] < data[parent]) { // 如果孩子小于双亲就进行交换 Swap(&data[child], &data[parent]); // 关系转换 child = parent; // 需要继续向上调整 parent = (parent - 1) / 2; } else { break; } } }

二叉堆显示堆顶元素
HeapDataType HPTop(HP* php) { assert(php); return php->data[0]; }
二叉堆的删除
顺序表的基本结构
void HPPop(HP* php) { assert(php); assert(php->size > 0); // 堆顶元素与末尾元素进行交换,删除最后一个位置 Swap(&php->data[0], &php->data[php->size-1]); php->size--; // 针对堆顶位置,做向下调整 AdjustDown(php->data, php->size, 0); }如何 删除 堆顶端的元素,同时维护堆的性质?
实际的操作是将堆顶元素对堆中最后一个元素交换,堆的元素个数-1,然后再从根结点开始进行一次从上向下的调整。调整时先在左右孩子结点中找最小的,如果双亲结点比这个最小的子结点还小说明不需要调整了,反之将双亲结点和它交换后再考虑后面的结点。下调算法
确定目标子节点:
parent 从根节点开始,假设目标子节点为左孩子 child = parent*2+1 ,当左孩子在数组范围之内时进入循环
如果 child + 1 (即右孩子)没超过范围 且 data[child+1] < data[child],则说明右孩子为目标子节点,更新目标子节点 child = child + 1
更新目标亲子关系:
此时 child 为目标子节点,然后再与 parent 双亲结点比较判断是否交换
void AdjustDown(HeapDataType* data, int n, int parent) { int child = parent * 2 + 1; while (child < n) { // 兄弟比较,取小为child if (child + 1 < n && data[child+1] < data[child]) { child++; } if (data[child] < data[parent]) { // 父子比较,判断是否交换 Swap(&data[child], &data[parent]); parent = child; child = parent * 2 + 1; } else { break; } } }
<1>将堆顶元素对堆中最后一个元素交换 <2>将堆中有效数据个数减少一个 <3>对堆顶元素进行向下调整 

二叉堆的判空
bool HPEmpty(HP* php) { assert(php); return php->size == 0; }
整体代码实现
#include<stdio.h> #include<stdlib.h> #include<assert.h> #include<stdbool.h> typedef int HeapDataType; typedef struct Heap { int size; int capacity; HeapDataType* data; }HP; void HPInit(HP* php) { assert(php); php->data = NULL; php->capacity = php->size = 0; } void HPDestroy(HP* php) { assert(php); free(php->data); php->data = NULL; php->capacity = 0; php->size = 0; } void Swap(HeapDataType* n, HeapDataType* m) { HeapDataType tmp = *n; *n = *m; *m = tmp; } void AdjustUp(HeapDataType* data, int child) { int parent = (child - 1) / 2; while (child > 0) { if (data[child] < data[parent]) { Swap(&data[child], &data[parent]); child = parent; parent = (parent - 1) / 2; } else { break; } } } void HPPush(HP* php, HeapDataType x) { assert(php); if (php->capacity == php->size) { int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity; HeapDataType* newNode = (HeapDataType*)realloc(php->data, sizeof(HeapDataType) * newcapacity); if (newNode == NULL) { perror("realloc"); exit(-1); } php->data = newNode; php->capacity = newcapacity; } php->data[php->size] = x; php->size++; AdjustUp(php->data, php->size - 1); } HeapDataType HPTop(HP* php) { assert(php); return php->data[0]; } void AdjustDown(HeapDataType* data, int n, int parent) { int child = parent * 2 + 1; while (child < n) { if (child + 1 < n && data[child+1] < data[child]) { child++; } if (data[child] < data[parent]) { Swap(&data[child], &data[parent]); parent = child; child = parent * 2 + 1; } else { break; } } } void HPPop(HP* php) { assert(php); assert(php->size > 0); Swap(&php->data[0], &php->data[php->size-1]); php->size--; AdjustDown(php->data, php->size, 0); } bool HPEmpty(HP* php) { assert(php); return php->size == 0; } int main() { int a[] = { 60,70,65,50,32,100 }; HP hp; HPInit(&hp); for (int i = 0; i < sizeof(a) / sizeof(int); i++) { HPPush(&hp, a[i]); } while (!HPEmpty(&hp)) { printf("%d ", HPTop(&hp)); HPPop(&hp); } HPDestroy(&hp); return 0; }代码测试
二叉堆性能:堆是为了实现排序而实现的一种数据结构,它并不是面向查找操作的,因为在堆中查找一个节点需要进行遍历,其平均时间复杂度是O(n)
不过在 插入 或 删除 某个值 和求二叉树中最值 往往具有很强的高效性