sizeof和strlen的对比

sizeof不是函数

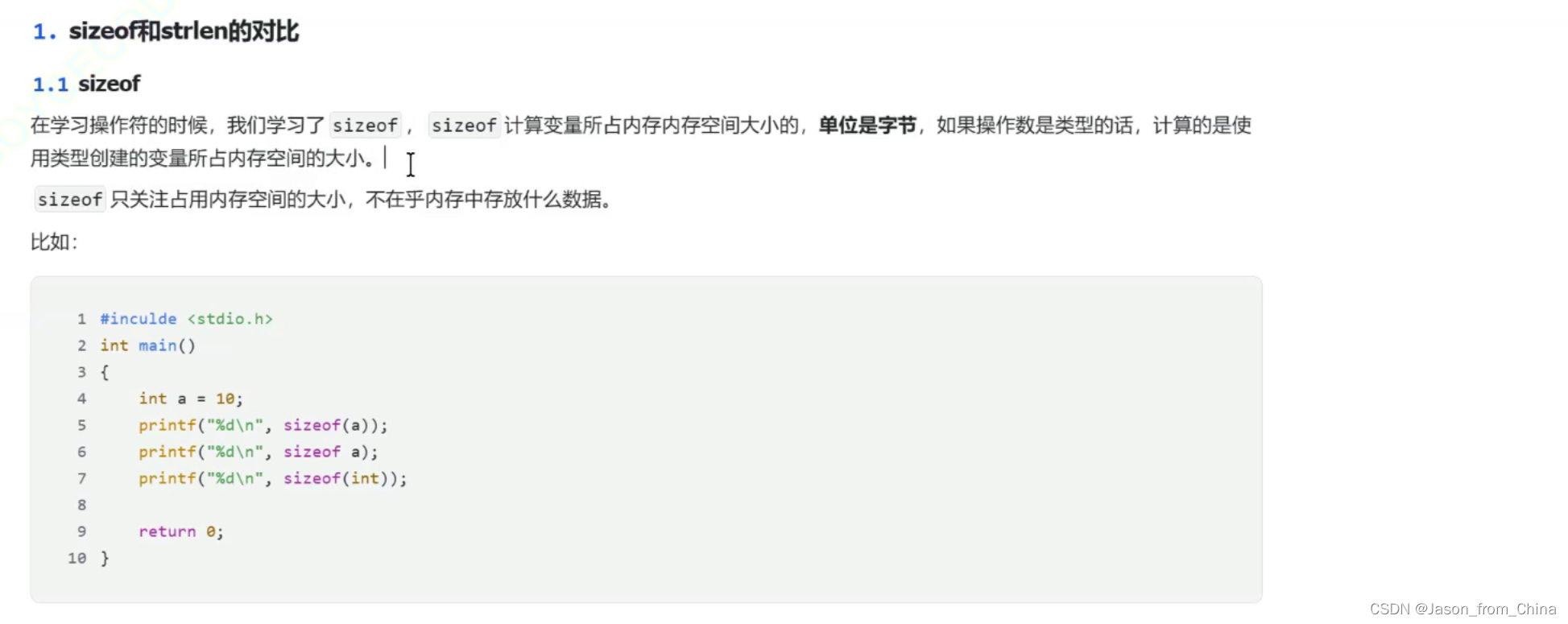
侧面证明sizeof不是函数

如果是函数 应该需要有括号 不能落下来

strlen
只针对字符串 包含头文件
string.h
并且这个是个函数


随机数值


sizeof里面有表达式的话 表达式里面是不参与计算的
下面的s求出的是4 就是因为是不参与计算的

不参与计算的原因
上面的表达式是在编译的时候进行计算的


四个字节或者八个字节
什么是四个字节或者八个字节
意思就是,在计算机编译环境里面,
当计算机编译环境是32位的时候此时地址的大小也就是4个字节
当计算机编译环境是64位的时候,此时地址的大小也就是8个字节
指针类型和编译环境是有关系的
当指向数组首元素的时候 此时如果数组是char类型的 那么就是一个字节 这个首元素占据的空间是一个字节
当指向数组首元素的时候 此时如果数组是int类型的 那么就是四个字节 这个首元素占据的空间是四个字节
下面会举例
————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
数组和指针笔试题的解析
一维数组
sizeof一维数组(整形数组)

原因
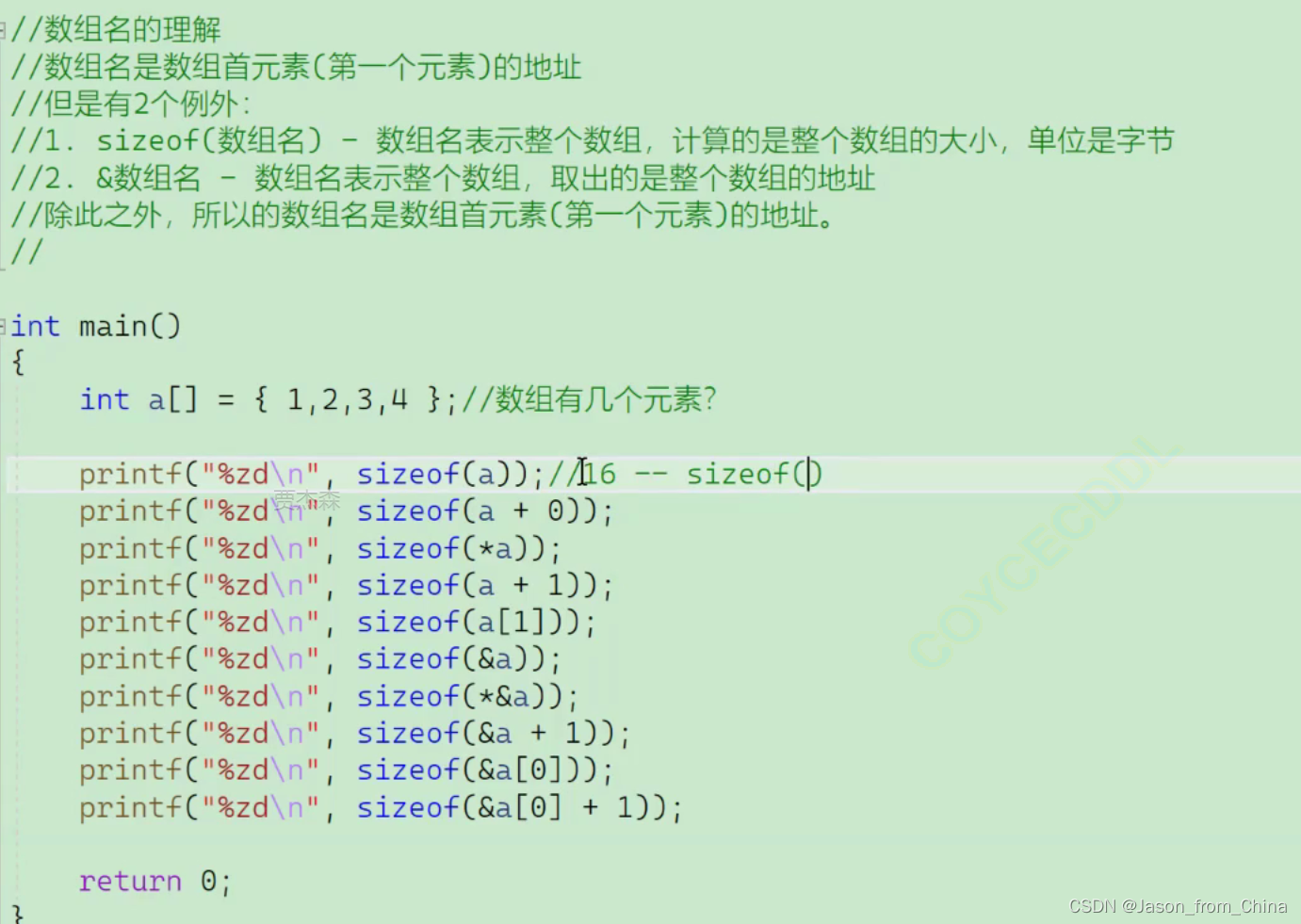
第一个
所以这里表示的整个数组的大小

第二个+0
数学上是加了没加一样
但是实际上是 不一样的
这个时候数组名表示的首元素的地址
这个时候作为表达式的时候 是首元素的地址 不进行计算

第三个

也就是等价于

第四个



a的地址跳过一个地址
就变成第二个元素的地址
所以也就是4或者8个字节
因为是32位 或者是64位
第五个
a【1】就是第二个元素大小就是4个字节

第六个
&a是地址
是地址也就是 4或者8个字节
他爸是市长他也是人
所以数组的地址也是地址 数组首元素的地址也是地址

数值一样 但是类型不一样
类型不一样决定是 a+1 跳过几个字节
a+1 跳过一个字节
但是&a+1跳过是一个数组
但是从字节本身长度来说的话 他本身也就是4或者8个字节

第七个
第一种理解方式(相互抵消了)
sizeof(a)16个字节
![]()
第二种理解方式(理解成函数指针)

第八个
还是4个或者8个字节
所以此时可以理解为野指针了 只要不用 就是没事的


第九个
首元素的地址 大小4或者8个字节‘
![]()
第十个
数组第二个元素的地址 本质上还是地址 地址 那就是4或者8个字节

总结

代码总结
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<string.h>
//一维数组
int main()
{
//sizeof字节的大小
//32位的编译环境决定的地址的大小是4个字节
//64位的编译环境决定的地址的大小是8个字节
printf("sizeof一维数组(整形)\n");
int a[] = { 1,2,3,4};
printf("%zd\n", sizeof(a));//第1. 16 16个字节 a代表的是整个数组的大小 一个整形是4个字节 4个数值 4*4=16
printf("%zd\n", sizeof(a + 0));//第2. 8 4/8个字节 因为a是首元素——int*类型 a+0还是首元素的地址 是地址就是4/8
printf("%zd\n", sizeof(*a));//第3. 4 *a 是指向首元素 首元素是int*类型的 根据指针的类型 int*类型占据四个字节 所以是4
printf("%zd\n", sizeof(a + 1));//第4, 8 4/8 类型是int*a + 1跳过1个整型,a + 1就是第二个元素的地址
printf("%zd\n", sizeof(a[1]));//第5. 4 4/8 第二个元素 第二个元素的大小就是四个字节
printf("%zd\n", sizeof(&a));//第6. 8 4/8 整个数组的地址 是地址也就是4/8个字节
printf("%zd\n", sizeof(*&a));//第7. 16 16
//第一种理解方式 也就是*和&相互抵消了 最后也就是只是(a)相当于第一个
//第二种理解方式是这个就是函数指针 简单的说也就是int(*)[4]取出四个地址 然后计算字节大小 也就是16
printf("%zd\n", sizeof(&a + 1));//第8. 8 4/8 这里虽然存在越界行为 但是他本质还是一个地址 也就是四个或则八个字节 至于为什么越界还能计算出字节大小 是因为这里是编译器自动计算出来的 按照编译器的推理 是可以推理出这个占据的字节大小 但是需要知道的是他本质还是地址
printf("%zd\n", sizeof(&a[0]));//第9. 8 4/8这里是取地址 取地址 那么就是地址 这里是取出首元素的地址 是地址 那就是四个或者八个字节
printf("%zd\n", sizeof(&a[0] + 1));//第10. 8 4/8 这里是取出首元素+1 也就是第二个元素的地址
return 0;
}这里声明一下 这里是用的是64位的环境 代码上面的图解是42位的环境 形成一个对比 目的就是有一个清晰的对比

——————————————————————————————————————————————————————————————————————————————————————
一维数组(字符数组)

需要知道 是地址就是4或者8个字节
首元素也就是类型本身的大小 地址就是4或者8个字节
上半部分

下半部分
地址就是4或者8个字节
这里是地址
所以

第六个
跳过整个数组 指向后面的空间 本质也是地址

第七个
第二个元素的地址

代码
//一维数组的字符指针
void test()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("sizeof一维数组(字符)\n");
printf("%d\n", sizeof(arr));//第一个: 6 这里是数组名放到数组里面 计算的是数组的大小6个字节(数组单独放到数组名里面计算的是数组的大小)
printf("%d\n", sizeof(arr + 0));//第二个: 4/8 这里代表的是首元素的地址加上0个元素 也就是还是第一个元素的地址
printf("%d\n", sizeof(*arr));//第三个: 1 这里代表的是第一个元素的大小 也就char* 也就是一个字节
//当然也可以理解为 *arr-->arr[0]-->*(arr+0)-->所以此时是也就是*(首元素地址)-->首元素地址解应用-->所以此时也就是第一个元素 第一个元素的大小也就是指针类型的大小
printf("%d\n", sizeof(arr[1]));//第四个: 1 这里代表的是第二个元素的大小
//当然也可以理解为arr[1]-->*(arr+1)-->所以此时是也就是*(首元素地址+1)-->*(第二个元素)-->第二个元素地址解应用-->所以此时也就是第二个元素 第二个元素的大小也就是指针类型的大小
printf("%d\n", sizeof(&arr));//第五个: 4/8 这里是取出整个地址的大小 是地址那地址就是根据环境来决定的 不是四个字节 就是八个字节
//第二种理解方式
// 这里也可以理解为&arr-->函数指针->char(*)[6]
// ->char(*)[6]是一个函数指针类型,它指向一个函数,这个函数接受一个 char 类型的指针参数,并返回一个 char 类型的数组指针,该数组有6个元素。
// 函数指针本身是一个变量,它存储的是另一个函数的地址。 是地址那就是四个或者八个字节
printf("%d\n", sizeof(&arr + 1));//第六个: 4/8 这里是取出整个地址+1 理论上也就是产生了越界的行为的发生 但是本质还是地址 是地址就是四个或者八个字节
printf("%d\n", sizeof(&arr[0]+1));//第七个: 4/8 这里是取出第一个元素的地址加上+1 也就是第二个元素的地址 是地址 也就是四个或者八个字节
} 这里声明一下 这里是用的是64位的环境 代码上面的图解是42位的环境 形成一个对比 目的就是有一个清晰的对比
——————————————————————————————————————————————————————————————————————————————————————
strlen的计算

第一个
strlen数字符是遇到\0才停止的 数组里面是没有\0的就会导致月结访问 导致结果就变成随机值
![]()
第二个
原因和第一个一样
strlen数字符是遇到\0才停止的 数组里面是没有\0的就会导致月结访问 导致结果就变成随机值
![]()
第三个
相当于把字符a传过去 a的ASCII码值是97 也就是 把97传过去了
但是97 这样的地址是不允许访问的
读取位置 0x00000061访问冲突


也是不合法访问

第四个
同理 等于传参98 b的ASCII码值是98
所以也错误的

第五个
同理 也是随机值
因为没有'\0'

第六个
同理 也是随机值
因为没有'\0'

第七个
同理 也是随机值
因为没有'\0'

代码
void test2()
{
//strlen计算字符
char arr[] = { 'a','b','c','d','e','f' };
printf("strlen的计算(字符)\n");
printf("%d\n", strlen(arr));//第一个: 这里产生越界的行为 因为strlen的计算方式是遇见'\0'才停止计算 在数组里面 这个是没有遇见'\0'的
printf("%d\n", strlen(arr + 0));//第二个: strlen是计算字符串的 同理是遇见'\0'才停止计算 这里也是没有'\0',所以也是越界访问 所以导致是随机数值
printf("错误代码\n");
//printf("%d\n", strlen(*arr));//第三个:
//这里计算的是数组首元素的地址,但是需要知道,strlen是计算长度的 不是计算其他的 这里a是第一个元素 等于把a的ASCII码值传过去
//a的ASCII码值是97 这里等于把97 传参到strlen里面进行计算 导致无法运行 所以产生错误
//所以需要注释这一段代码 才能让程序正常运行
printf("错误代码\n");
//printf("%d\n", strlen(arr[1]));//第四个:
//这里计算的是数组第二个元素的地址,但是需要知道,strlen是计算长度的 不是计算其他的 这里b是第二个元素 等于把b的ASCII码值传过去
//b的ASCII码值是98 这里等于把98 传参到strlen里面进行计算 导致无法运行 所以产生错误
//所以需要注释这一段代码 才能让程序正常运行
printf("%d\n", strlen(&arr));//第五个:
printf("%d\n", strlen(&arr + 1));//第六个:
printf("%d\n", strlen(&arr[0] + 1));//第七个:
}我把这两段代码给注释 后面才能继续 运行 并且用换行符代替

完全的代码
void test2()
{
//strlen计算字符
char arr[] = { 'a','b','c','d','e','f' };
printf("strlen的计算(字符)\n");
printf("%d\n", strlen(arr));//第一个: 这里产生越界的行为 因为strlen的计算方式是遇见'\0'才停止计算 在数组里面 这个是没有遇见'\0'的
printf("%d\n", strlen(arr + 0));//第二个: strlen是计算字符串的 同理是遇见'\0'才停止计算 这里也是没有'\0',所以也是越界访问 所以导致是随机数值
printf("错误代码\n");
//printf("%d\n", strlen(*arr));//第三个:
//这里计算的是数组首元素的地址,但是需要知道,strlen是计算长度的 不是计算其他的 这里a是第一个元素 等于把a的ASCII码值传过去
//a的ASCII码值是97 这里等于把97 传参到strlen里面进行计算 导致无法运行 所以产生错误
//所以需要注释这一段代码 才能让程序正常运行
printf("错误代码\n");
//printf("%d\n", strlen(arr[1]));//第四个:
//这里计算的是数组第二个元素的地址,但是需要知道,strlen是计算长度的 不是计算其他的 这里b是第二个元素 等于把b的ASCII码值传过去
//b的ASCII码值是98 这里等于把98 传参到strlen里面进行计算 导致无法运行 所以产生错误
//所以需要注释这一段代码 才能让程序正常运行
printf("%d\n", strlen(&arr));//第五个:
//这里是取出arr整个数组的地址 但是需要知道 strlen是计算数组长度的 也就是说 取出arr整个数组之后 开始从arr最后+1个字符开始计算 所以还是越界 所以还是随机值
printf("%d\n", strlen(&arr + 1));//第六个:
//这里是取出arr整个数组的地址 但是需要知道 strlen是计算数组长度的 也就是说 取出arr整个数组之后 开始从arr最后+1+1个字符开始计算 所以还是越界 所以还是随机值
printf("%d\n", strlen(&arr[0] + 1));//第七个:
//这里就有坑了 虽然取地址的时候还没有越界 但是strlen的计算方式是遇见'\0'才停止计算 在数组里面 这个是没有遇见'\0'的
//所以本质还是会导致越界行为的产生
}这里声明一下 这里是用的是64位的环境 代码上面的图解是42位的环境 形成一个对比 目的就是有一个清晰的对比

——————————————————————————————————————————————————————————————————————————————————————
sizeof计算数组字符的的大小

第一个
因为最后还有一个’\0‘也算里面 所以是7个字节
![]()
第二个
![]()
第三个

第四个
![]()
第五个

第六个

第七个
第二个元素的地址 还是 只要是地址 那就是 4\8个字节

代码
void test3()
{
//sizeof计算数组字符的的大小
printf("sizeof计算数组字符的的大小\n");
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));//第一个: 这个是7个字符 因为按照这个数组来说 是 abcdef'\0' 这里暗含一个字符0 所以 也就是计算下来 也就是7
printf("%d\n", sizeof(arr + 0));//第二个:arr表示首元素的地址 首元素的地址加上0 也就是首元素的地址 是地址 那么就是四个或者八个字节
//如果是解应用 也就变成了解应用第一个元素地址 就变成了第一个元素 但是此时是第一个元素的地址 因为arr代表的是首元素
printf("%d\n", sizeof(*arr));//第三个: 这个之前讲过 依旧是两个版本 也就是第一个是指向首元素 那么指向的首元素的类型是char*类型 占据一个字节
//第二个是可以理解为arr[0] 也就是第一个首元素 第一个首元素的字节和类型有关 和编译器的环境没有特别大的关系 所以此时也就是占据一个字节
printf("%d\n", sizeof(arr[1]));//第四个:此时也就*(arr+1)所以也就是第二个元素 所以是 1
//或者直接理解为 第二个元素 所以是一个字节
printf("%d\n", sizeof(&arr));//第五个: 取地址 取出整个地址 此时记住 也就是地址 是地址 那不是四个字节 就是八个字节 这里是64位环境 所以 是8个字节
printf("%d\n", sizeof(&arr + 1));//第六个:
//这里是取出首元素的数组的地址 +1 这里的+1是加上整个数组 所以此时是越界访问 也就是跳过整个数组 访问最后一个数组再多一个字符
//但是我们需要知道 这里是地址 当然 只要是地址 那么不是四个字节就是八个字节
printf("%d\n", sizeof(&arr[0] + 1));//第七个:这里是取出首元素的地址进行+1 也就是第二个元素的地址 所以此时也就是地址 是地址所以是四个或者八个字符
}这里声明一下 这里是用的是64位的环境 代码上面的图解是42位的环境 形成一个对比 目的就是有一个清晰的对比

——————————————————————————————————————————————————————————————————————————————————————
strlen计算字符串长度和大小


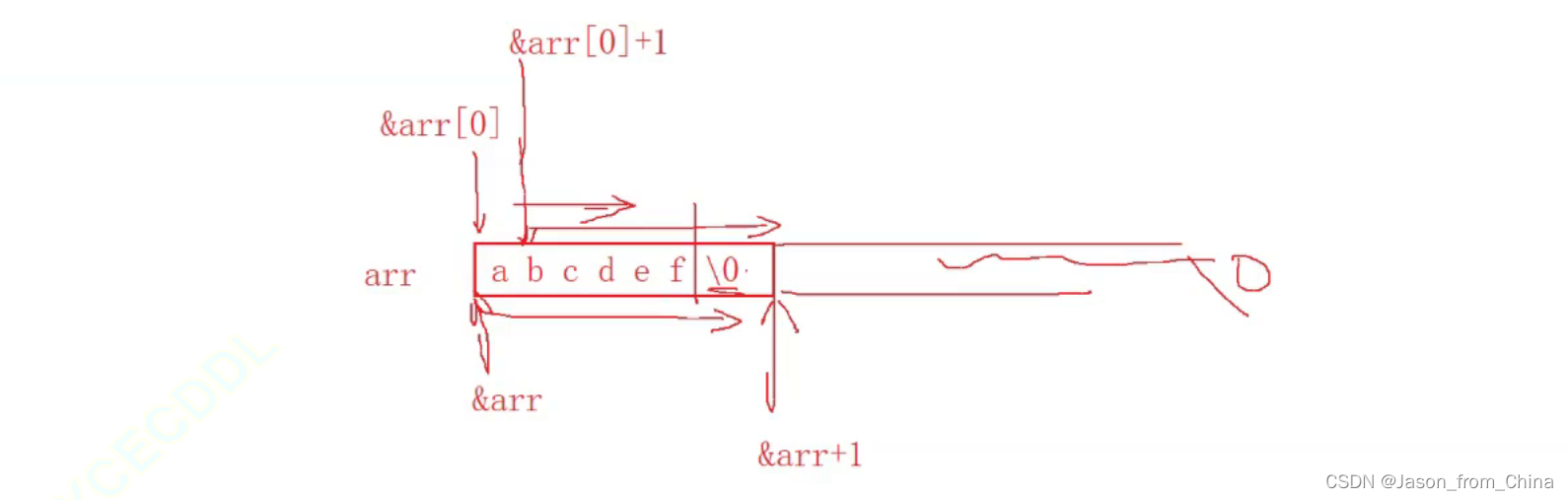
第一个
这里面是包含'\0'的 所以计算的时候是6个字节

第二个
arr+0首元素的地址
首元素的地址 向后数
也就是6个字符

第三个
传参还是97 也就是报错
因为有些地址是不能访问的

第四个
同理
传参还是98 也就是报错
因为有些地址是不能访问的

第五个
数组的首元素的地址 也是重数组第一个元素从后面找
也就是第一个是不寻找的

强制类型转化 但是是会导致出错

第六个


所以是随机值 导致 越界访问 也就变成野指针

第七个


代码
void test4()
{
//strlen计算字符串长度和大小
printf("strlen计算字符串长度和大小\n");
char arr[] = "abcdef";
printf("%d\n", strlen(arr));//第一个: 因为strlen的计算方式是遇见'\0'才停止计算 在数组里面 这个是遇见'\0'的 所以是6
printf("%d\n", strlen(arr + 0));//第二个: 这里是计算的是首元素地址+0 所以还是首元素地址开始往后计算 所以还是6
printf("%d\n", strlen(*arr));//第三个:
//这个就有点套路了 这里是和之前的strlen的计算方式是很像的 简单的说就是此时传过去的arr[0]
//也就是第一个元素 第一个元素是a也就是 97 这里需要知道 97 这地址是不能访问的 在编译器里面 有些地址是设计好的 如果访问会造成访问冲突
printf("%d\n", strlen(arr[1]));//第四个:同理 b这个地址也是不能进行访问的 如果进行访问 也是会产生冲突
printf("%d\n", strlen(&arr));//第五个:
printf("%d\n", strlen(&arr + 1));//第六个:
printf("%d\n", strlen(&arr[0] + 1));//第七个:
}所以需要注释到这两行 代码才能正常运行

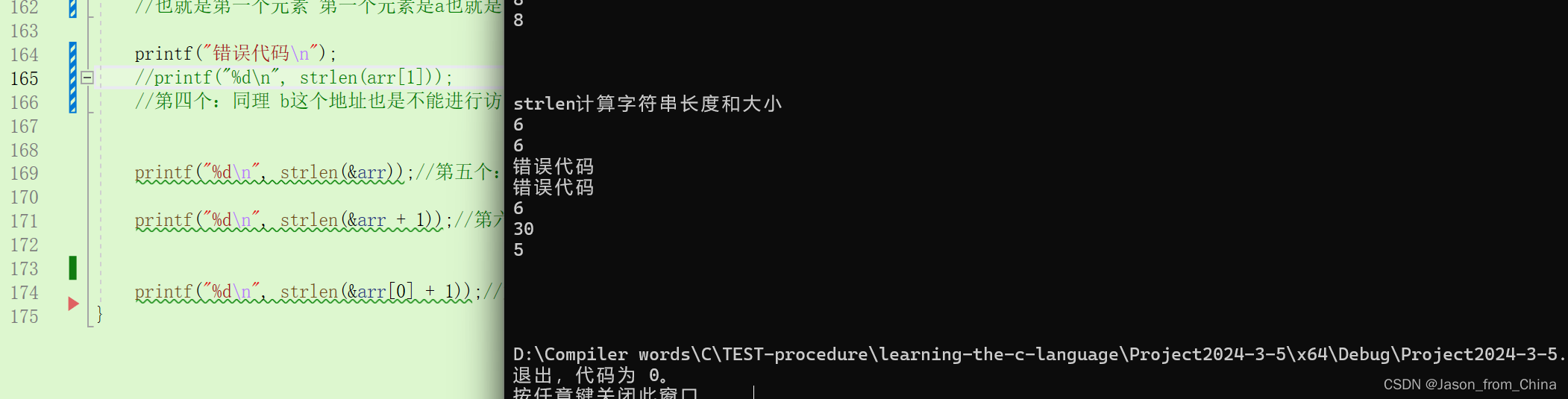
完整代码
void test4()
{
//strlen计算字符串长度和大小
printf("strlen计算字符串长度和大小\n");
char arr[] = "abcdef";
printf("%d\n", strlen(arr));//第一个: 因为strlen的计算方式是遇见'\0'才停止计算 在数组里面 这个是遇见'\0'的 所以是6
printf("%d\n", strlen(arr + 0));//第二个: 这里是计算的是首元素地址+0 所以还是首元素地址开始往后计算 所以还是6
printf("错误代码\n");
//printf("%d\n", strlen(*arr));//第三个:
//这个就有点套路了 这里是和之前的strlen的计算方式是很像的 简单的说就是此时传过去的arr[0]
//也就是第一个元素 第一个元素是a也就是 97 这里需要知道 97 这地址是不能访问的 在编译器里面 有些地址是设计好的 如果访问会造成访问冲突
printf("错误代码\n");
//printf("%d\n", strlen(arr[1]));
//第四个:同理 b这个地址也是不能进行访问的 如果进行访问 也是会产生冲突
printf("%d\n", strlen(&arr));//第五个: 这里是从首元素地址开始计算的 也就从第一个元素开始计算的 直到遇见字符串0 才开始停止 所以是6
printf("%d\n", strlen(&arr + 1));//第六个:
//这里产生了越界访问 此时是&arr这个是首元素的地址 但是+1之后 此时也就是跳过整个数组 也就是包括字符串0也跳过
//所以此时就变成了越界访问 所以此时是随机值
printf("%d\n", strlen(&arr[0] + 1));//第七个:这个数值是5 因为这里是从第二个数值开始计算的 因为&arr[0]+1这是首元素的地址加上1
//也就是从第二个元素开始进行计算的 所以也就是5
}这里声明一下 这里是用的是64位的环境 代码上面的图解是42位的环境 形成一个对比 目的就是有一个清晰的对比
—————————————————————————————————————————————————————————————————————————————————————
指针的计算
const修饰的字符指针,用sizeof求出数值

第一个
p指针变量
所以这里求的是指针变量的大小

第二个
本质上p的大小是取决于这个平台环境的
但是这个时候p进行; +1
所以此时p+1之后就是b的地址
是地址 那么就是4或者8个字节大小


第三个

第四个
两种理解方式
第一种理解思路
![]()

第二种理解思路

第五个
![]()
第六个
这里加一 就吧p自己给跳过去了
但是依旧指向的是地址 是地址 那就还是4或者是8个字节
简单的说 二级指针的位量其实是*p


第七个
p【0】其实就是首元素
这里就是取出首元素的地址 +1就是第二个字符的字节

代码
const char* arr[] = {"abcdef"};
const char* p = arr[0]; // p 指向数组的第一个元素 'a'
const char* q = arr[0] + 1; // q 指向数组的第二个元素 'b'const char* arr[] = "abcdef";
const char* p = arr; // p 指向数组的第一个元素 'a'
const char* q = arr + 1; // q 越界const char* arr = "abcdef";
const char* p = arr; // p 指向数组的第一个元素 'a'
const char* q = arr + 1; // q 指向数组的第二个元素 'b'
完整代码
void test5()
{
//const修饰的字符指针,用sizeof求出数值
printf("const修饰的字符指针,用sizeof求出数值\n");
const char* arr = "abcdef";
//这里需要了解到 arr是指针变量 那么需要知道 指针变量指向的是地址
printf("%d\n", sizeof(arr));//第一个: 这里的arr之昂的是地址 arr是指针变量 我们计算的是指针变量的大小 所以是四个或者八个字节
printf("%d\n", sizeof(arr + 1));//第二个:
//这里我们已经知晓 arr是指针变量 那么需要知道 指针变量指向的是地址 那么这里依旧是地址 所以是四个或者八个字节
//const char* arr = "abcdef";
//const char* p = arr; // p 指向数组的第一个元素 'a'
//const char* q = arr + 1; // q 指向数组的第二个元素 'b'的地址
//
//
//const char* arr[] = "abcdef";
//const char* p = arr; // p 指向数组的第一个元素 'a'
//const char* q = arr + 1; // q 越界行为产生
//本质上p的大小是取决于这个平台环境的,但是这个时候arr进行; + 1,所以此时arr + 1之后就是b b可以理解为新开辟的地址的地址,
// 简单的说就是此时数组已经越界了 指向的另外一个空间的地址 但是 他是地址
// 是地址 那么就是4或者8个字节大小
printf("%d\n", sizeof(*arr));//第三个:
//这里计算的是首元素地址的解应用 那么此时也就是*(arr+0)->*(第一个元素)->arr[0]所以第一个元素的字节大小是char* 所以是1个字节
printf("%d\n", sizeof(arr[0]));//第四个:一个字节 同理
//这里计算的是首元素地址的解应用 那么此时也就是*(arr+0)->*(第一个元素地址)->所以此时的意思就是第一个元素的解应用 所以此时的字节大小和类型有关 字节大小是char* 所以是1个字节
//arr[0]-> *(arr+0)-> *(arr)-> *arr->'a' 字符串a的大小是一个字节
printf("%d\n", sizeof(&arr));//第五个: 这里是取地址 取出的是地址 只要是地址 那么就是四个或者八个字节
printf("%d\n", sizeof(&arr + 1));//第六个:
//这里是取地址 取出的是地址 只要是地址 那么就是四个或者八个字节
printf("%d\n", sizeof(&arr[0] + 1));//第七个:等于&arr+1 等于第二个字符的地址
}这里声明一下 这里是用的是64位的环境 代码上面的图解是42位的环境 形成一个对比 目的就是有一个清晰的对比

——————————————————————————————————————————————————————————————————————————————————————
指针里面 strlen的计算

原理解析
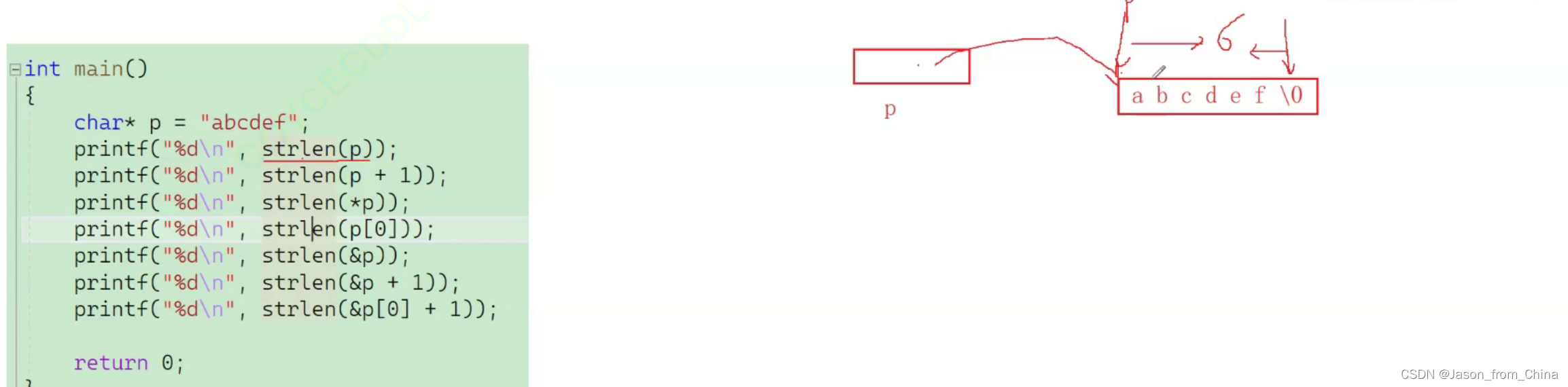
第一个
首元素地址往后计算

第二个
![]()
第三个 第四个

第五个
这个是一整块字符的空间 这个是指针变量p的地址和字符串之间的关系不大
p存放的地址是什么是不知道的


第六个

第七个
从第二个地址往后数

代码
void test6()
{
//指针里面 strlen的计算
printf("指针里面 strlen的计算\n");
char* arr = "abcdef";
//这里需要了解到 arr是指针变量 那么需要知道 指针变量指向的是地址
printf("%d\n", strlen(arr));//第一个: 这里是取出首元素的地址 进行计算 遇见字符串'\0'就停止计算 所以整体来说长度就是 6
printf("%d\n", strlen(arr + 1));//第二个: 这里是从第二个字符串地址开始计算 也就是是从b开始计算 所以整体来说长度就是 5
printf("错误代码\n");
//printf("%d\n", strlen(*arr));
// //第三个: 这里还是错误的
//因为这里可以理解为*(arr+0)也就是首元素地址的解应用 首元素地址的解应用也就是首元素 首元素的ASCII码值是 97
//之前我们说过 在C语言里面有些地址是不允许被访问的 也就是 这个地址依旧是不允许被访问的 既然如此 那么不仅会造成访问冲突 而且是无法计算的
// 所以导致是错误的
//这里依旧采取注释的方式进行代替
printf("错误代码\n");
//printf("%d\n", strlen(arr[0]));
// //第四个:这个代码也是错误的代码
//因为这个可以理解为 arr[0]->*(arr+0)->*arr所以等同于上面一个代码
// 但是这里错误无法运行不单单是访问冲突的问题 因为strlen是计算字符串长度的 你这里是传参一个ASCII码值 也就是数字过去了
//
//
printf("%d\n", strlen(&arr));//第五个: 这
printf("%d\n", strlen(&arr + 1));//第六个:
printf("%d\n", strlen(&arr[0] + 1));//第七个:
}
完整代码
void test6()
{
//指针里面 strlen的计算
printf("指针里面 strlen的计算\n");
char* arr = "abcdef";
//这里需要了解到 arr是指针变量 那么需要知道 指针变量指向的是地址
printf("%d\n", strlen(arr));//第一个: 这里是取出首元素的地址 进行计算 遇见字符串'\0'就停止计算 所以整体来说长度就是 6
printf("%d\n", strlen(arr + 1));//第二个: 这里是从第二个字符串地址开始计算 也就是是从b开始计算 所以整体来说长度就是 5
printf("错误代码\n");
//printf("%d\n", strlen(*arr));
// //第三个: 这里还是错误的
//因为这里可以理解为*(arr+0)也就是首元素地址的解应用 首元素地址的解应用也就是首元素 首元素的ASCII码值是 97
//之前我们说过 在C语言里面有些地址是不允许被访问的 也就是 这个地址依旧是不允许被访问的 既然如此 那么不仅会造成访问冲突 而且是无法计算的
// 所以导致是错误的
//这里依旧采取注释的方式进行代替
printf("错误代码\n");
//printf("%d\n", strlen(arr[0]));
// //第四个:这个代码也是错误的代码
//因为这个可以理解为 arr[0]->*(arr+0)->*arr所以等同于上面一个代码
// 但是这里错误无法运行不单单是访问冲突的问题 因为strlen是计算字符串长度的 你这里是传参一个ASCII码值 也就是数字过去了
// 当然这里也可以理解为 地址的解引用也就是数值
//
printf("%d\n", strlen(&arr));//第五个: 这里是取出首元素的地址
printf("%d\n", strlen(&arr + 1));//第六个:这里虽然还是取出首元素的地址 但是需要知道 当没【】的时候 取出的地址+1是加上整个数组的地址 所以
//此时会导致这个时候地址指向的 最后一个元素'\0' 的后一个元素
//strlen计算是按照'\0' 位结束标志的 越界行为的产生后 没有字符'\0' 所以这个是一个随机数值
printf("%d\n", strlen(&arr[0] + 1));//第七个:这里是取出首元素地址 首元素的地址+1 也就是第二个元素的地址开始计算 所以 遇见字符串'\0' 之前 一共是5个字符
}————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
二维数组
sizeof二维数组的计算

解析

第一个
三行四列 乘以一个元素的大小


第二个

第三个



第四个
解析





第五个
第二个元素的解应用


第六个
二维数组的首元素的地址
也就是第一行的地址+1 也就是第二行的地址

也就是指向整个第二行 也就是数组指针

是地址 是地址就是4 或者8个字节

第七个
第一种理解是思路

第二种理解的思路


第八个
·&arr[0]是第一行 的数组名
![]()
然后+1
就是第二行的地址
是地址 那就是4或者8个字节

第九个
也就是取出第一行的地址 +1解应用
就是第二行的地址解应用

所以是16个字节
![]()
第十个
第一种理解方式
二维数组首元素的地址 也就是第一行的地址
*a也就是第一行
所以计算的也就是第一行的大小

第二种理解方式

这里需要知道 二级指针和二维数组不要对比
这俩没有什么可比性
第十一个
a[3]正常理解的话此时是越界访问
但是你不能站在银行门口就说抢银行了
是越界访问了
但是不妨推荐类型
所以a[3]无需真实访问 放在sizeof内部 计算的是16 个字节

3 5 都是整形 sizeof是不会真实计算里面的东西的 所以计算不计算是无所谓的

数组名的意义


举例

强制类型转化并且赋给ptr
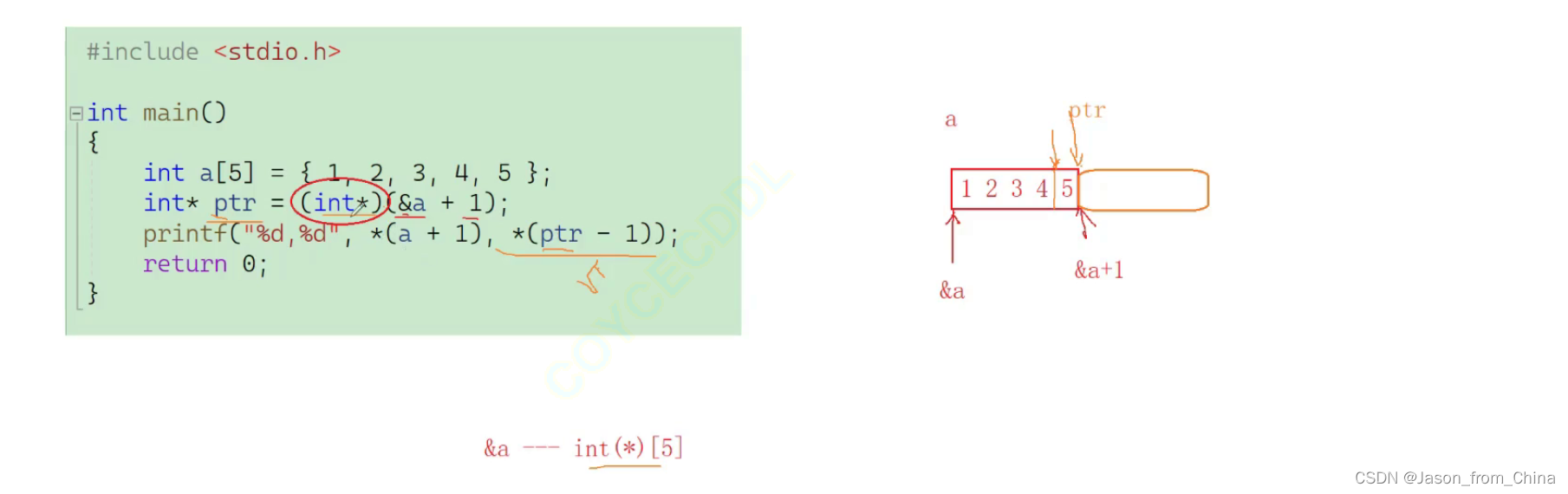
所以结果是2 5

代码
void test7()
{
//sizeof二维数组的计算
printf("sizeof二维数组的计算\n");
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));//第一种, sizeof计算的是字节的大小 a这里计算的是整个数组的大小 这里已经是3*4*4=48个字节
printf("%d\n", sizeof(a[0][0]));//第二种,** 4 这里是第一第一个元素 大小是四个字节
printf("%d\n", sizeof(a[0]));//第三种, 这里是a[0]->指的是首元素大小 这里的首元素是三行四列 这里是第一行 也就是4*4=16
printf("%d\n", sizeof(a[0] + 1));//第四种,** 8 这里可以理解为
//sizeof(a[0] + 1)==( *(a + O) + 1) == ( (第0行的数组名) + 1) == (地址 + 1)==(地址) == a[1][0]
printf("%d\n", sizeof(*(a[0] + 1)));//第五种, 这里代表的是 a[0][1] 也就是 第一行第二个元素 4个字节
printf("%d\n", sizeof(a + 1));//第六种, 这里首行的地址+1也就是第二行的地址 的地址 那么就是四个或者八个字节
printf("%d\n", sizeof(*(a + 1)));//第七种,** 16 这里是*(首元素地址+1)也就是第二行元素地址解应用 所以得到的是 4*4 是十六个字节
printf("%d\n", sizeof(&a[0] + 1));//第八种, 这里是取地址 取出的首行元素的地址 加一也就是第二行数值的地址 是地址也就是四个 或者八个字节
printf("%d\n", sizeof(*(&a[0] + 1)));//第九种, 这里可以理解为 *&相互抵消 也就是取出地址 指向该地址的元素 所以是第二行的元素大小 也就是16个字节
printf("%d\n", sizeof(*a));//第十种, ** 16
printf("%d\n", sizeof(a[3]));//第十一种,
//这里第一眼看 会认为应该是随意数值
//但是 需要知道的是 这里和之前讲的编译器自定推理出来的应该是差不多的
//虽然是越界行为的发生 但是根据系统编译器会自动推理
// 此时应该是第四行占据的字节大小 并且虽然是越界的行为的发生
// 但是 并没有使用它 只是进行计算 也就是 他是野狗睡着了 你没有吵醒它 所以计算是没有问题的 '
//所以字节大小是16
//第二种理解方式是*(a+3)也就是 *(首元素的地址+3)-> *(第三个元素的地址的解应用) 也就是第四行 所以是16个字节
代码
void test8()
{
int a[5] = { 1,2,3,4,5 };
int* ptr = (int*)(&a + 1);
printf("%d %d", *(a + 1), *(ptr - 1));
//这里是强制类型转化为,int类型 取出首元素的地址 然后-1 然后就是指向了最后一个元素
//
} 
———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
结构体
x86环境 结构体的举例
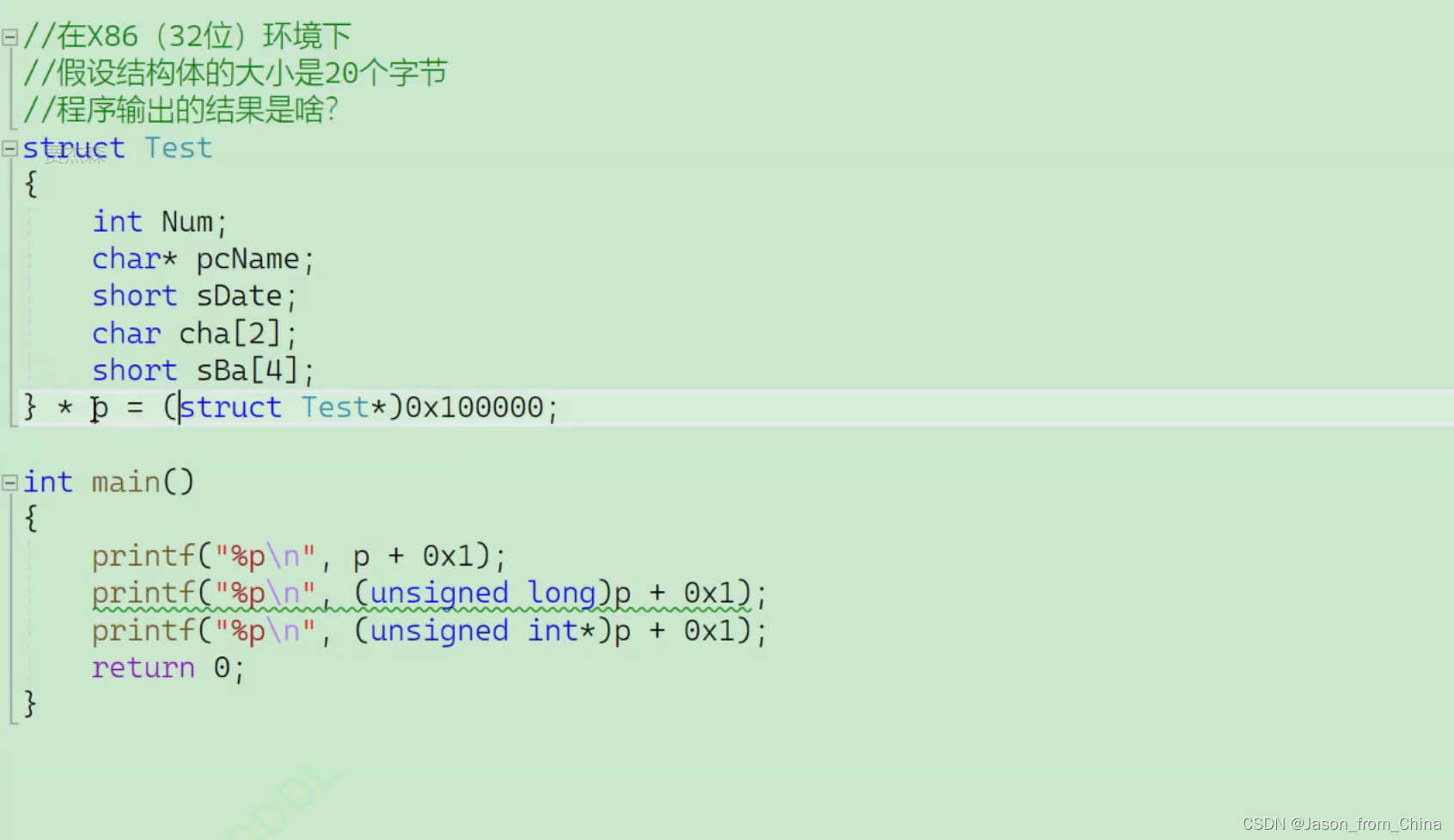
0x1=1
这个题目考察的是整数+-整数的问题
解析

第一个
14的原因是因为
是10进制转化成16进制

第二个
整型值+1,就是+1
printf("%p\n"p + @x1);printf("%pln"(unsigned long)p+ 0x1);printf("%pn".(unsianed int*)p + @x1)
0x100000+1--->0x100001
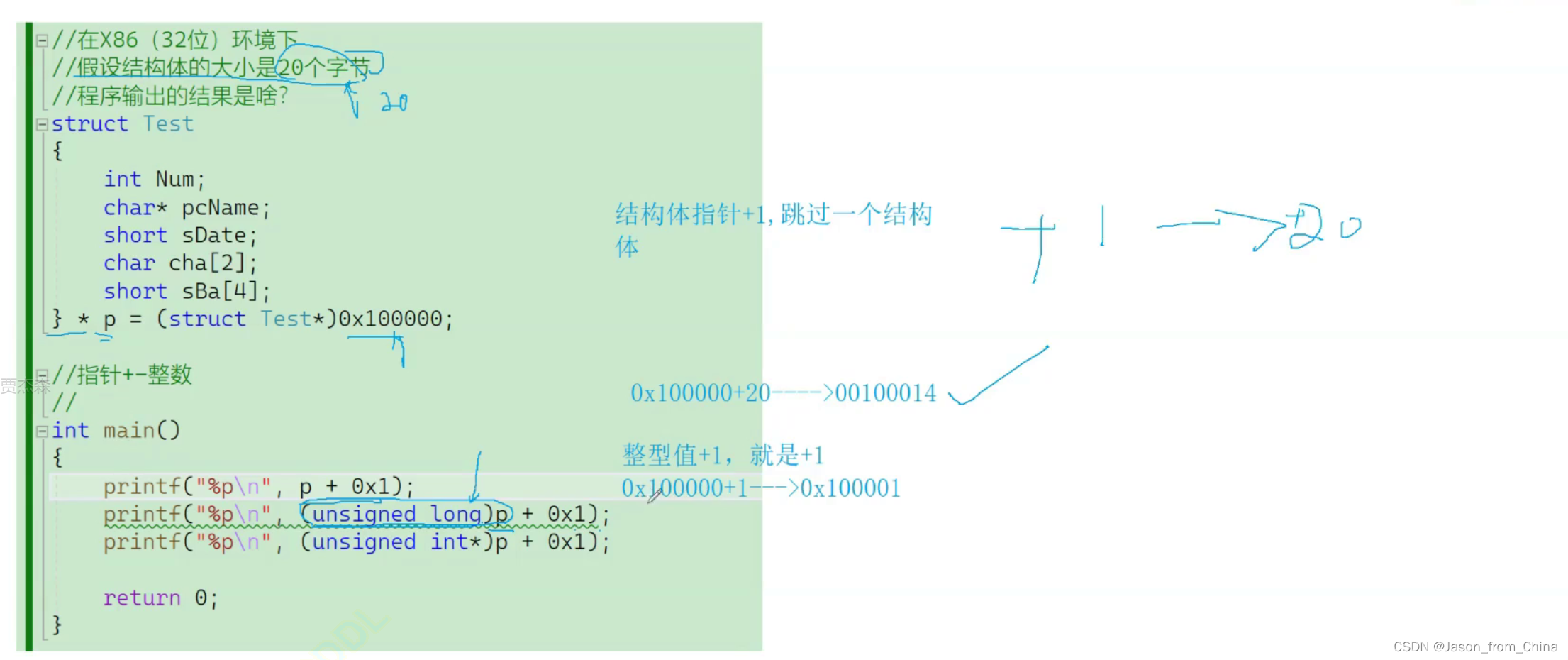
第三个
指针+1 等于实际上 是+4

解释
-
printf(“%p\n”, p + 1):这里打印的是指针p加1后的地址。假设p指向一个整型变量,每个整型变量占据4个字节。所以p+1实际上是将指针p向后移动4个字节,即指向下一个整型变量的地址。
-
printf(“%p\n”, (unsigned long)p + 0x1):这里进行了类型转换,将指针p转换为unsigned long类型,然后加上0x1。这里的0x1表示16进制数1,加上1后,实际上是将指针p的地址值加上1。
-
printf(“%p\n”, (unsigned int*)p + 0x1):这里进行了类型转换,将指针p转换为unsigned int类型的指针,然后加上0x1。同样地,0x1表示16进制数1,加上1后,实际上是将指针p的地址值加上1。
——————————————————————————————————————————————————————————————————————————————————————
x86环境 举例2


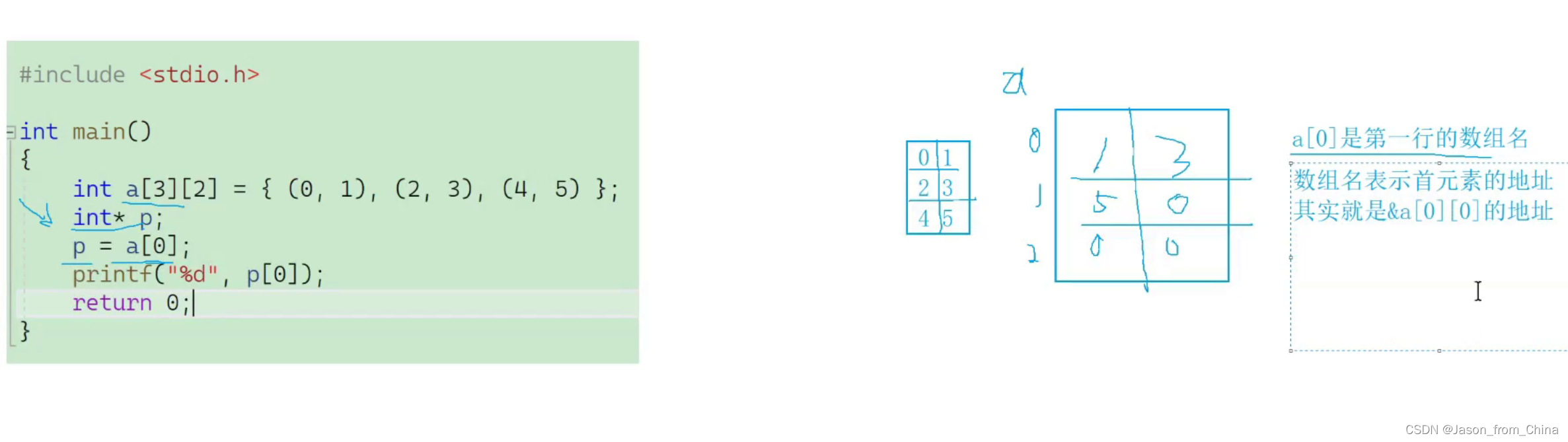
结果是1

代码
void test10()
{
int a[3][2] = { (0,1),(2,3),(4,5) };
int* p;
p = a[0];
for (int i = 0; i < 6; i++)
{
printf("%d ", p[i]);
}
在数组初始化中,(0,1)会先计算0,然后计算1,所以(0,1)的值为1;(2,3)的值为3;(4,5)的值为5。
//由于p指向了a,所以p[i]实际上是访问了a[i]的值。根据二维数组的存储方式,a、a、a、a、a、a在内存中是连续存储的。
// 所以循环打印出来的结果是1 3 5 0 0 0。
} 
————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
指针笔试题的解析
指针-指针的计算
假如是x86环境







数组是由高到低辩护的 也就是数组越小 地址越大

但是%p和%d是不一样的
这里是x86的环境


#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
int a[5][5];
int(*p)[4];//数组指针,p指向的的数组是4个整形数组
p = a;
printf("%p %d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}——————————————————————————————————————————————————————————————————————————————————————
二维数组的计算
此时aa代表的是整个二维数组


第二个打印
此时aa是首元素的地址
这里的强制类型转化是没有意义的



代码
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
int aa[2][5] = { 1,2,3,4 ,5,6,7,8,9,10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}

——————————————————————————————————————————————————————————————————————————————————————
一级指针的计算



#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
char* a[] = { "work" ,"at" ,"alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
} 运行
——————————————————————————————————————————————————————————————————————————————————————
一级指针和二级指针的计算




++

然后这++解应用
po

第二个
这里需要知道 +的运算是最低的
++会有+1 的效果 但是也会使数值真的发生变化

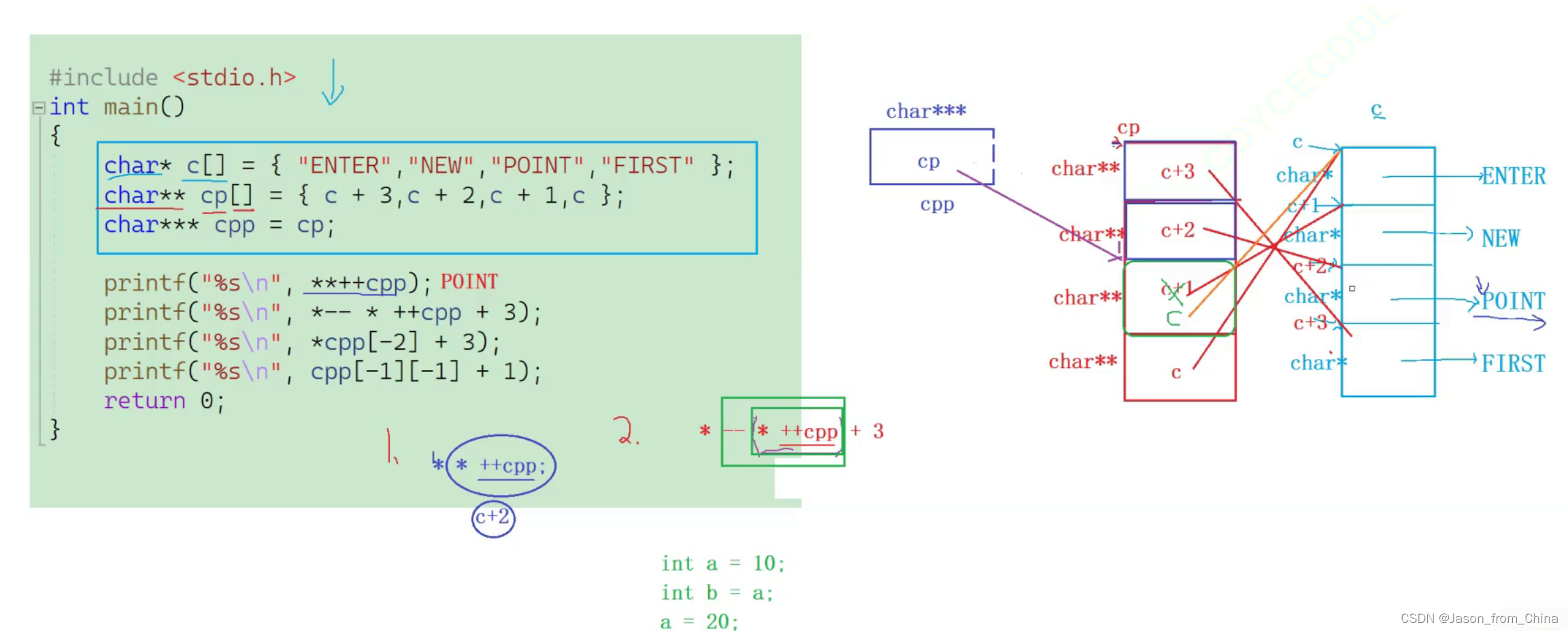
这里的解应用拿到的是这个空间的内容 也就是这个内容--

第三个

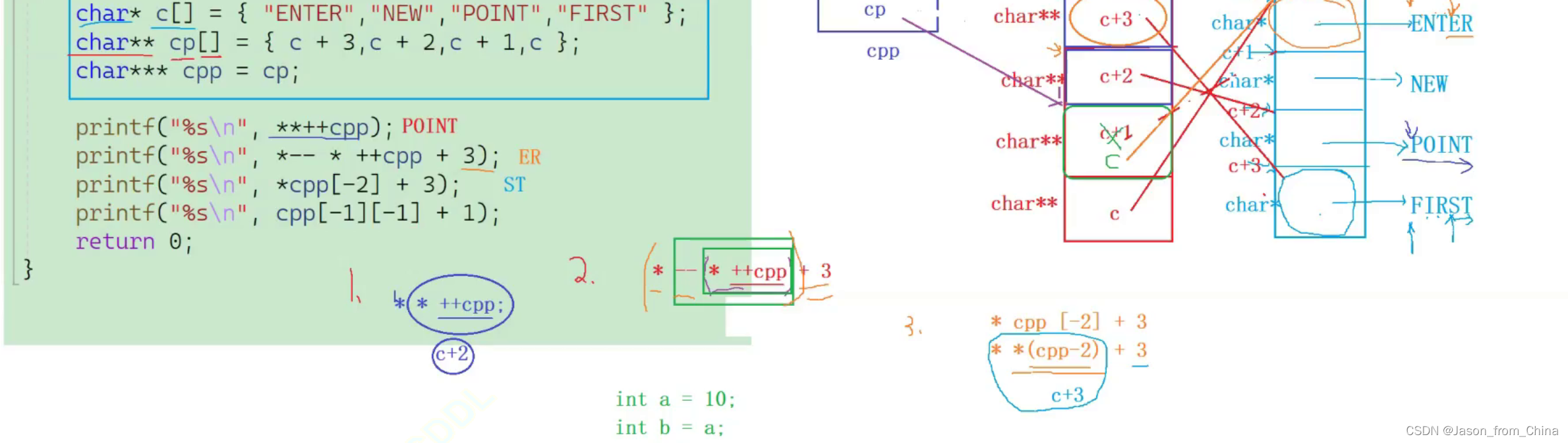
第四个


++会有+1 的效果 但是也会使数值真的发生变化

代码
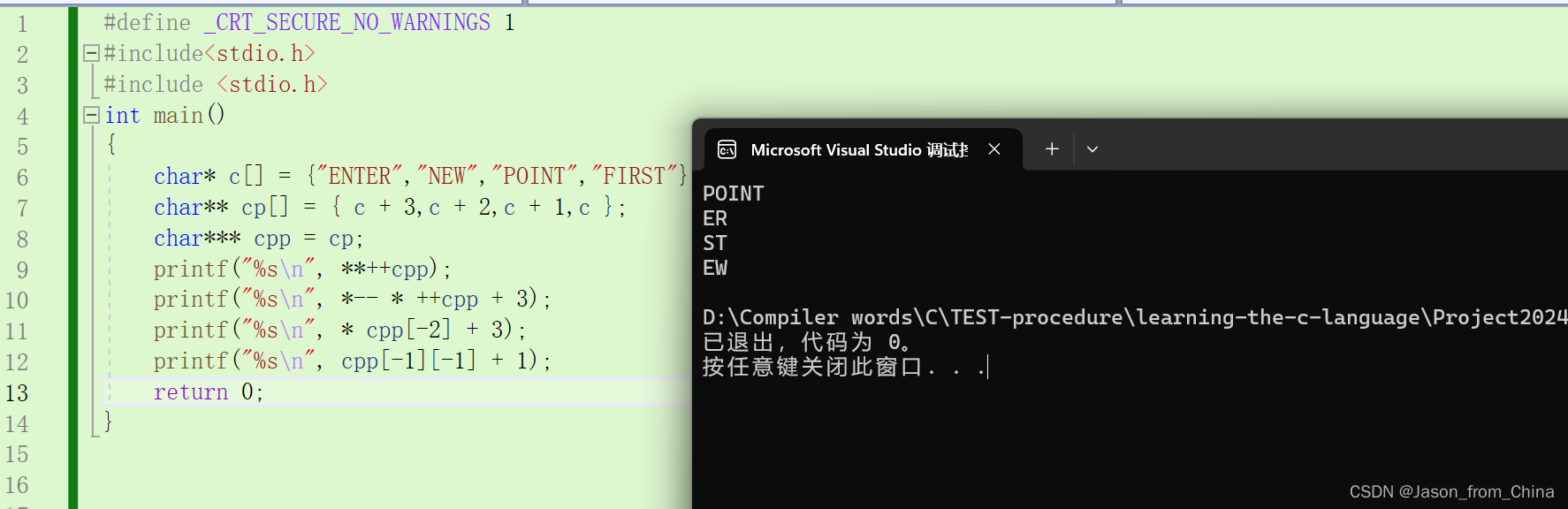
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include <stdio.h>
int main()
{
char* c[] = {"ENTER","NEW","POINT","FIRST"};
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", * cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}
————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
补充
在计算机编程中,区分首元素和首元素的地址通常涉及对内存和指针概念的理解。首元素指的是一个数组或数据结构中的第一个元素,而首元素的地址是指该元素在内存中的位置。以下是一些关于区分首元素和首元素地址的要点:
1. 值与位置的区别:
- 首元素是一个实际的数据值,比如 `arr` 的值可能是 `5`。
- 首元素的地址是指向这个数据的指针,比如 `*p` 的值将会是 `5`,而 `p` 本身是一个地址值,比如 `0x7ffee35cc204`。
2. 内存中的表示:
- 首元素在内存中占据一块特定的空间,比如 `arr` 位于数组 `arr` 的起始位置。
- 首元素的地址指向这块空间,它是一个可以被程序访问的内存地址。
3. 操作上的不同:
- 对首元素的操作通常是直接访问,如 `arr = 10;`。
- 对首元素地址的操作是通过指针进行的,如 `*p = 10;`,这实际上改变了首元素的值。
4. 表达式的结果:
- 表达式 `arr` 在大多数情况下会返回首元素的地址,因为它通常被解释为一个指向数组首元素的指针。
- 表达式 `*arr` 或 `arr` 会返回首元素的值,而不是地址。
5. 指针运算:
- 指针可以用来访问数组元素,如 `p` 或 `*(p+1)` 将访问第二个元素。
- 指针本身可以进行自增(`p++`)操作,这意味着它移动到下一个元素的地址。
在实际编程中,理解和正确使用首元素及其地址是非常重要的,尤其是在需要直接操作内存或进行性能敏感的操作时。