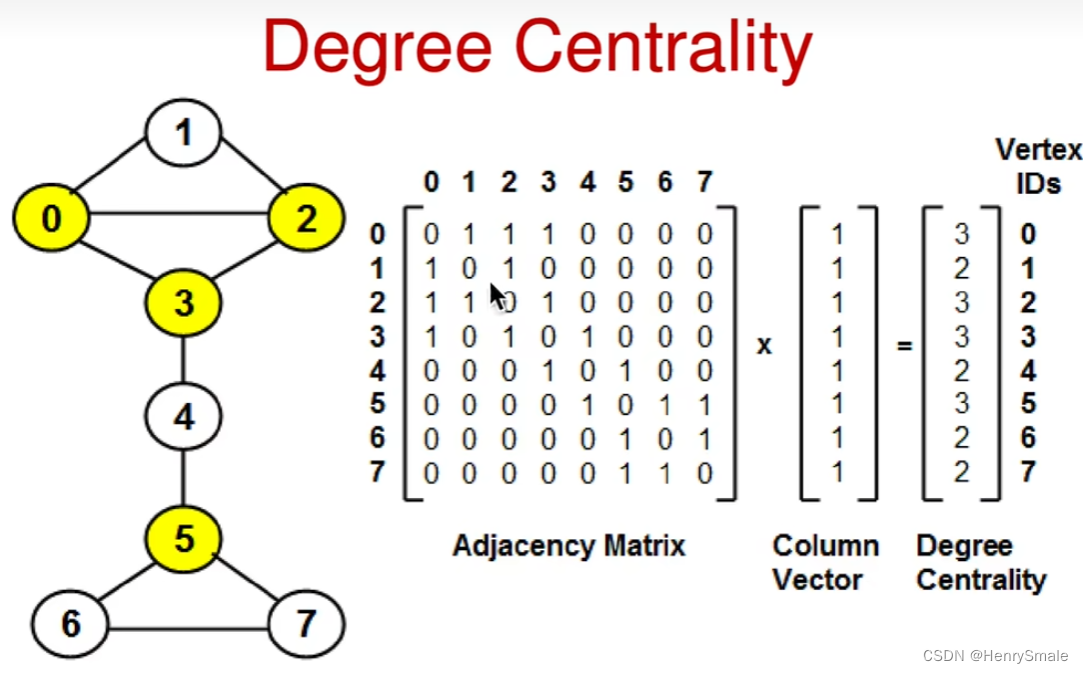
前面博文【opencv dnn模块 示例(23) 目标检测 object_detection 之 yolov8】 已经已经详细介绍了yolov8网络和测试。本文继续说明使用yolov8 进行 人体姿态估计 pose 和 旋转目标检测 OBB 。
文章目录
- 1、Yolov8-pose 简单使用
- 2、Yolov8-OBB
- 2.1、python 命令行测试
- 2.2、opencv dnn测试
- 2.2.1、onnx导出
- 2.2.2、opencv dnn 中的预处理
- 2.2.3、opencv dnn 中的后处理
- 2.2.4、完整代码
1、Yolov8-pose 简单使用
人体姿态估计,使用coco数据集标注格式,17个关键点。
对 yolov8m-pose.pt 转换得到onnx如下,
(yolo_pytorch) E:\DeepLearning\yolov8-ultralytics>yolo pose export model=yolov8m-pose.pt format=onnx batch=1 imgsz=640
Ultralytics YOLOv8.0.154 Python-3.9.16 torch-1.13.1+cu117 CPU (Intel Core(TM) i7-7700K 4.20GHz)
YOLOv8m-pose summary (fused): 237 layers, 26447596 parameters, 0 gradients, 81.0 GFLOPs
PyTorch: starting from 'yolov8m-pose.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 56, 8400) (50.8 MB)
ONNX: starting export with onnx 1.14.0 opset 16...
ONNX: export success 3.3s, saved as 'yolov8m-pose.onnx' (101.2 MB)
Export complete (7.1s)
Results saved to E:\DeepLearning\yolov8-ultralytics
Predict: yolo predict task=pose model=yolov8m-pose.onnx imgsz=640
Validate: yolo val task=pose model=yolov8m-pose.onnx imgsz=640 data=/usr/src/app/ultralytics/datasets/coco-pose.yaml
Visualize: https://netron.app
输入为640时输出纬度为 (56,8400),56维数据格式定义为 4 + 1 + 17*3:
矩形框box[x,y,w,h],目标置信度conf, 17组关键点 (x, y, conf)。
在后处理中,添加一个保存关键点的数据,一个显示关键点的函数
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{
// yolov8-pose has an output of shape (batchSize, 56, 8400) ( box[x,y,w,h] + conf + 17*(x,y,conf) )
...
std::vector<cv::Mat> keypoints;
for(int i = 0; i < rows; ++i) {
float confidence = data[4];
if(confidence >= confThreshold) {
...
boxes.push_back(cv::Rect(left, top, width, height));
cv::Mat keypoint(1, dimensions - 5, CV_32F, tmp.ptr<float>(i, 5));
for(int i = 0; i < 17; i++) {
keypoint.at<float>(i * 3 + 0) *= x_factor;
keypoint.at<float>(i * 3 + 1) *= y_factor;
}
keypoints.push_back(keypoint);
}
data += dimensions;
}
std::vector<int> indices;
NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);
for(size_t i = 0; i < indices.size(); ++i) {
...
drawSkelton(keypoints[idx], frame);
}
}
std::vector<cv::Scalar> kptcolors = {
{255, 0, 0}, {255, 85, 0}, {255, 170, 0}, {255, 255, 0}, {170, 255, 0}, {85, 255, 0},
{0, 255, 0}, {0, 255, 85}, {0, 255, 170}, {0, 255, 255}, {0, 170, 255}, {0, 85, 255},
{0, 0, 255}, {255, 0, 170}, {170, 0, 255}, {255, 0, 255}, {85, 0, 255},
};
std::vector<std::vector<int>> keypairs = {
{15, 13},{13, 11},{16, 14},{14, 12},{11, 12},{5, 11},
{6, 12},{5, 6},{5, 7},{6, 8},{7, 9},{8, 10},{1, 2},
{0, 1},{0, 2},{1, 3},{2, 4},{3, 5},{4, 6}
};
std::vector<std::vector<int>> keypairs = {
{15, 13},{13, 11},{16, 14},{14, 12},{11, 12},{5, 11},
{6, 12},{5, 6},{5, 7},{6, 8},{7, 9},{8, 10},{1, 2},
{0, 1},{0, 2},{1, 3},{2, 4},{3, 5},{4, 6}
};
void drawSkelton(const Mat& keypoints , Mat& frame)
{
for(auto& pair : keypairs) {
auto& pt1 = keypoints.at<cv::Point3f>(pair[0]);
auto& pt2 = keypoints.at<cv::Point3f>(pair[1]);
if(pt1.z > 0.5 && pt2.z > 0.5) {
cv::line(frame, cv::Point(pt1.x, pt1.y), cv::Point(pt2.x, pt2.y), {255,255,0}, 2);
}
}
for(int i = 0; i < 17; i++) {
Point3f pt = keypoints.at<cv::Point3f>(i);
if(pt.z < 0.5)
continue;
cv::circle(frame, cv::Point(pt.x, pt.y), 3, kptcolors[i], -1);
cv::putText(frame, cv::format("%d", i), cv::Point(pt.x, pt.y), 1, 1, {255,0,0});
}
}
结果如下:

2、Yolov8-OBB
2024年1月10号ultralytics发布了 v8.1.0 - YOLOv8 Oriented Bounding Boxes (OBB)。
YOLOv8框架在在支持分类、对象检测、实例分割、姿态评估的基础上更近一步,现支持旋转对象检测(OBB),基于DOTA数据集,支持航拍图像的15个类别对象检测,包括车辆、船只、典型各种场地等。包含2800多张图像、18W个实例对象。
0: plane
1: baseball-diamond
2: bridge
3: ground-track-field
4: small-vehicle
5: large-vehicle
6: ship
7: tennis-court
8: basketball-court
9: storage-tank
10: soccer-ball-field
11: roundabout
12: harbor
13: swimming-pool
Obb模型在含有15个类别的 DOTAv1 上训练,不同尺度的YOLOv8 OBB模型的精度与输入格式列表如下:
| Model | size (pixels) | mAPtest 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
官方的船体、车辆检测示例图如下

2.1、python 命令行测试
例如,使用yolov8m-obb模型进行测试
yolo obb predict model=yolov8m-obb.pt source=t.jpg
Ultralytics YOLOv8.1.19 🚀 Python-3.9.16 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce GTX 1080 Ti, 11264MiB)
YOLOv8m-obb summary (fused): 237 layers, 26408752 parameters, 0 gradients, 80.9 GFLOPs
image 1/1 E:\DeepLearning\yolov8-ultralytics\DJI_0390.JPG: 768x1024 36.0ms
Speed: 6.0ms preprocess, 36.0ms inference, 130.5ms postprocess per image at shape (1, 3, 768, 1024)
Results saved to runs\obb\predict2
💡 Learn more at https://docs.ultralytics.com/modes/predict
网络图片 测试如下

2.2、opencv dnn测试
2.2.1、onnx导出
yolo export model=yolov8s-obb.pt format=onnx
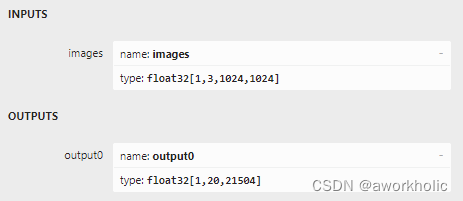
使用netron查看输入输出
2.2.2、opencv dnn 中的预处理
预处理和yolov5之后基本一致,letterbox处理,
cv::Mat formatToSquare(const cv::Mat &source)
{
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat(_max, _max, CV_8UC3, {114,114,114});
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
之后就是将WHC的图片frame转换为NCWH的blob数据,使用函数 dnn::blobFromImages,完整如下
float scale = 1 / 255.0; //0.00392
Scalar mean = {0,0,0};
bool swapRB = true;
inpWidth = 1024;
inpHeight = 1024;
Mat blob;
// Create a 4D blob from a frame.
cv::Mat modelInput = frame;
if(letterBoxForSquare && inpWidth == inpHeight)
modelInput = formatToSquare(modelInput);
blobFromImages(std::vector<cv::Mat>{modelInput}, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);
2.2.3、opencv dnn 中的后处理
前面通过可视化看到YOLOv8-OBB 网络输入为 1024x1024, 输出为 1x20x21504,也就是预测框为21504个(三个尺度128x128、64x64、32x32),每个预测框的纬度是 20(针对DOTAv1的数据集15个类别)。详细可以表示为如下公式
21504
×
20
=
128
×
128
×
20
+
64
×
64
×
20
+
32
×
32
×
20
=
128
×
128
×
(
1
+
15
+
4
)
+
128
×
64
×
(
1
+
15
+
4
)
+
32
×
32
×
(
1
+
15
+
4
)
\begin{aligned} 21504\times 20 &= 128\times 128\times 20+64\times 64\times 20+32\times 32\times 20 \\ &= 128\times 128\times (1+15+4) + 128\times 64\times (1+15+4) + 32\times 32\times (1+15+4) \end{aligned}
21504×20=128×128×20+64×64×20+32×32×20=128×128×(1+15+4)+128×64×(1+15+4)+32×32×(1+15+4)
其中的 4 对应的是 cx, cy, w, h,分别代表的含义是边界框中心点坐标、宽高;15 对应的是 DOTAv1 数据集中的 15 个类别置信度;1 对应的是旋转框的旋转角度 angle,其取值范围是在 [-pi/4, 3pi/4] 之间。
在yolov8解码基础上修改,后处理主要改变2个地方,目标框从Rect 改变为 RotatedRect,nms的的对象也相应调整。
(1)RotatedRect 的解码
已知矩形框 cx, cy, w, h 和 角度 angle,首先需要计算旋转之后旋转矩形框的新的四个顶点坐标
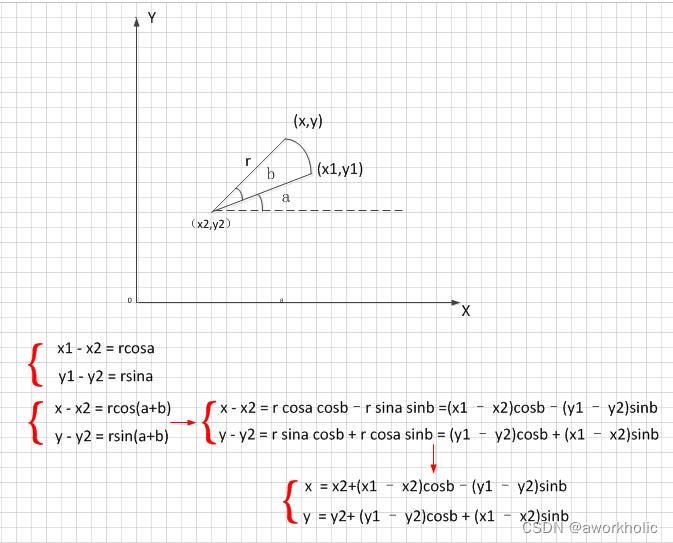
这里数学推导坐标系y轴线上,逆时针旋转。对比图像坐标系y轴线下,yolov8-OBB 角度为顺时针,两者其实是统一的。
参考上面原理,得到旋转目标框的4个顶点在原图上的坐标点计算如下
const float cos_value = cos(angle);
const float sin_value = sin(angle);
std::vector<Point2f> pts = { // 未旋转前顺时针四个点 左上、右上、右下、左下
Point2f(cx - w / 2,cy - h / 2),
Point2f(cx + w / 2,cy - h / 2),
Point2f(cx + w / 2,cy + h / 2),
Point2f(cx - w / 2,cy + h / 2),
};
for(auto& pt : pts) {
auto x = pt.x;
auto y = pt.y;
pt.x = cx + (x - cx) * cos_value - (y - cy) * sin_value;
pt.y = cy + (x - cx) * sin_value + (y - cy) * cos_value;
}
4个顶点的构造和最终变换结果可以简化为:
const cv::Point2f vec1 = { w / 2 * cos_value,w / 2 * sin_value};
const cv::Point2f vec2 = {-h / 2 * sin_value,h / 2 * cos_value};
std::vector<Point2f> pts{ // 按顺序即可
Point2f(cx,cy) + vec1 + vec2,
Point2f(cx,cy) + vec1 - vec2,
Point2f(cx,cy) - vec1 - vec2,
Point2f(cx,cy) - vec1 + vec2,
};
(2)RotatedRect 的nms
在前面解码基础上,使用参数为 cv::RotatedRect 的 NMSBoxes 重载版本
std::vector<int> class_ids;
std::vector<float> confidences;
//std::vector<cv::Rect> boxes
std::vector<cv::RotatedRect> boxes;
for(....) {
... 获取当前目标框数据
const cv::Point2f vec1 = { w / 2 * cos_value,w / 2 * sin_value};
const cv::Point2f vec2 = {-h / 2 * sin_value,h / 2 * cos_value};
std::vector<Point2f> pts{
Point2f(cx,cy) + vec1 + vec2,
Point2f(cx,cy) + vec1 - vec2,
Point2f(cx,cy) - vec1 - vec2,
Point2f(cx,cy) - vec1 + vec2,
};
boxes.emplace_back(pts[0], pts[1], pts[2]);
}
std::vector<int> indices;
NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);
注意:
这里cv::RotatedRect的构造使用了按顺序排列的3个顶点,实际内存保存的是 rect的中线、宽高和旋转角度。 从cv::RotatedRect对象中提取4个顶点需要重新计算。
(3)绘制代码
在前面绘制Rect可以直接使用 cv::retangle函数, 但是 RotatedRect 只能通过四个顶点进行连线绘制
cv::RotatedRect rrect = ...;
cv::Point2f pts[4];
rrect.points(&pts[0]);
for(int i = 0; i < 4; i++) {
cv::line(frame, pts[i] ,pts[(i+1)%4], color, 2);
}
//cv::circle(frame, pts[0], 3, {0,0,255}, -1); // 期望绘制解码后的第一个点顶
2.2.4、完整代码
#pragma once
#include "opencv2/opencv.hpp"
#include <fstream>
#include <sstream>
#include <random>
#include <numeric>
namespace YOLOv8_OBB {
using namespace cv;
using namespace dnn;
float inpWidth;
float inpHeight;
float confThreshold, scoreThreshold, nmsThreshold;
std::vector<std::string> classes;
std::vector<cv::Scalar> colors;
bool letterBoxForSquare = true;
cv::Mat formatToSquare(const cv::Mat &source);
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& out, Net& net);
// void drawPred(int classId, float conf, const cv::Rect& rect, Mat& frame);
void drawPred(int classId, float conf, const std::vector<cv::Point2f>& pts, Mat& frame);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);
int test()
{
// 根据选择的检测模型文件进行配置
confThreshold = 0.25;
scoreThreshold = 0.45;
nmsThreshold = 0.5;
float scale = 1 / 255.0; //0.00392
Scalar mean = {0,0,0};
bool swapRB = true;
inpWidth = 1024;
inpHeight = 1024;
String modelPath = R"(E:\DeepLearning\yolov8-ultralytics\yolov8m-obb.onnx)";
String configPath;
String framework = "";
//int backendId = cv::dnn::DNN_BACKEND_OPENCV;
//int targetId = cv::dnn::DNN_TARGET_CPU;
//int backendId = cv::dnn::DNN_BACKEND_OPENCV;
//int targetId = cv::dnn::DNN_TARGET_OPENCL;
int backendId = cv::dnn::DNN_BACKEND_CUDA;
int targetId = cv::dnn::DNN_TARGET_CUDA;
// Open file with classes names.
//if(!classesFile.empty()) {
// const std::string& file = classesFile;
// std::ifstream ifs(file.c_str());
// if(!ifs.is_open())
// CV_Error(Error::StsError, "File " + file + " not found");
// std::string line;
// while(std::getline(ifs, line)) {
// classes.push_back(line);
// colors.push_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));
// }
//}
for(int i = 0; i< 15; i++){
classes.push_back(std::to_string(i));
colors.push_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));
}
// Load a model.
Net net = readNet(modelPath, configPath, framework);
net.setPreferableBackend(backendId);
net.setPreferableTarget(targetId);
std::vector<String> outNames = net.getUnconnectedOutLayersNames();
//std::vector<String> outNames{"output"};
if(backendId == cv::dnn::DNN_BACKEND_CUDA) {
int dims[] = {1,3,inpHeight,inpWidth};
cv::Mat tmp = cv::Mat::zeros(4, dims, CV_32F);
std::vector<cv::Mat> outs;
net.setInput(tmp);
for(int i = 0; i < 10; i++)
net.forward(outs, outNames); // warmup
}
// Create a window
static const std::string kWinName = "Deep learning object detection in OpenCV";
//cv::namedWindow(kWinName, 0);
// Open a video file or an image file or a camera stream.
VideoCapture cap;
//cap.open(0);
//cap.open(R"(E:\DeepLearning\darknet-yolo3-master\build\darknet\x64\dog.jpg)");
//cap.open("http://live.cooltv.top/tv/aishang.php?id=cctv1hd");
//cap.open(R"(F:\测试视频\路口俯拍\snap1.mkv)");
//cap.open(R"(E:\DeepLearning\yolov5\data\images\bus.jpg)");
//cap.open(R"(F:\1、交通事故素材\筛选后素材1\DJI_0014.JPG)");
cap.open(R"(C:\Users\wanggao\Desktop\aa.jpg)"); // t.jpeg aaa.jpeg
cv::TickMeter tk;
// Process frames.
Mat frame, blob;
while(waitKey(1) < 0) {
cap >> frame;
if(frame.empty()) {
waitKey();
break;
}
// Create a 4D blob from a frame.
cv::Mat modelInput = frame;
if(letterBoxForSquare && inpWidth == inpHeight)
modelInput = formatToSquare(modelInput);
blobFromImages(std::vector<cv::Mat>{modelInput}, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);
// Run a model.
net.setInput(blob);
std::vector<Mat> outs;
auto tt1 = cv::getTickCount();
net.forward(outs, outNames);
auto tt2 = cv::getTickCount();
postprocess(frame, modelInput.size(), outs, net);
std::string label = format("Inference time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);
cv::putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
cv::imshow(kWinName, frame);
}
return 0;
}
cv::Mat formatToSquare(const cv::Mat &source)
{
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat(_max, _max, CV_8UC3, {114,114,114});
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{
// yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h] + confidence[c])
// yolov8-obb has an output of shape (batchSize, 20, 2150) (box[x,y,w,h] + confidence[c] + angle)
auto tt1 = cv::getTickCount();
float x_factor = inputSz.width / inpWidth;
float y_factor = inputSz.height / inpHeight;
std::vector<int> class_ids;
std::vector<float> confidences;
//std::vector<cv::Rect> boxes; // 2150
std::vector<cv::RotatedRect> boxes;
std::vector<std::vector<Point2f>> boxesPoints; // 减少计算量
// [1, 84, 8400] -> [8400,84]
int rows = outs[0].size[2];
int dimensions = outs[0].size[1];
auto tmp = outs[0].reshape(1, dimensions);
cv::transpose(tmp, tmp);
float *data = (float *)tmp.data;
for(int i = 0; i < rows; ++i) {
float *classes_scores = data + 4;
cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);
cv::Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if(max_class_score > scoreThreshold) {
confidences.push_back(max_class_score);
class_ids.push_back(class_id.x);
//float x = data[0];
//float y = data[1];
//float w = data[2];
//float h = data[3];
//int left = int((x - 0.5 * w) * x_factor);
//int top = int((y - 0.5 * h) * y_factor);
//int width = int(w * x_factor);
//int height = int(h * y_factor);
//boxes.push_back(cv::Rect(left, top, width, height));
const float cx = data[0] * x_factor;
const float cy = data[1] * y_factor;
const float w = data[2] * x_factor;
const float h = data[3] * y_factor;
const float angle = data[19];
const float cos_value = cos(angle);
const float sin_value = sin(angle);
const cv::Point2f vec1 = { w / 2 * cos_value,w / 2 * sin_value};
const cv::Point2f vec2 = {-h / 2 * sin_value,h / 2 * cos_value};
std::vector<Point2f> pts{
Point2f(cx,cy) + vec1 + vec2,
Point2f(cx,cy) + vec1 - vec2,
Point2f(cx,cy) - vec1 - vec2,
Point2f(cx,cy) - vec1 + vec2,
};
boxes.emplace_back(pts[0], pts[1], pts[2]);
boxesPoints.emplace_back(pts);
}
data += dimensions;
}
std::vector<int> indices;
NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);
auto tt2 = cv::getTickCount();
std::string label = format("NMS time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);
cv::putText(frame, label, Point(0, 30), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
for(size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
//drawPred(class_ids[idx], confidences[idx], boxes[idx], frame);
drawPred(class_ids[idx], confidences[idx], boxesPoints[idx], frame);
}
}
void drawPred(int classId, float conf, const std::vector<cv::Point2f>& pts, Mat& frame)
{
std::string label = format("%.2f", conf);
Scalar color = Scalar::all(255);
if(!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ": " + label;
color = colors[classId];
}
/*rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));*/
for(int i = 0; i < 4; i++) {
cv::line(frame, pts[i], pts[(i + 1) % 4], color, 2);
}
cv::circle(frame, pts[0], 3, {0,0,255}, -1);
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int left = pts[0].x;
int top = std::max((int)pts[0].y, labelSize.height);
rectangle(frame, Point(left, top - labelSize.height),
Point(left + labelSize.width, top + baseLine), color, FILLED);
cv::putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}