文章目录
- 一、线程池
- 标准库提供的线程池
- ThreadPoolExecutor
- 自定义线程池
一、线程池
为什么要引入线程池?
这个原因我们需要追溯到线程,我们线程存在的意义在于,使用进程进行并发编程太重了,所以引入了线程,因为线程又称为 “轻量级进程”,创建线程比创建进程更加有效,调度线程更加的高效。
但当我们的并发程度的提高,我们线程应该不太满足我们的要求,线程显得也不是那么的轻,那么想要提升效率,有两个解决方案:
- 引入"更轻量的线程",是存在这个东西的,那就是"协程/纤程",但是我们的java并没有引入这个概念,所以我们这个方案就泡汤了,相比之下Go语言在并发编程这一块就更香了,因为Go内置了协程。
- 使用线程池,来降低创建和销毁线程的开销。
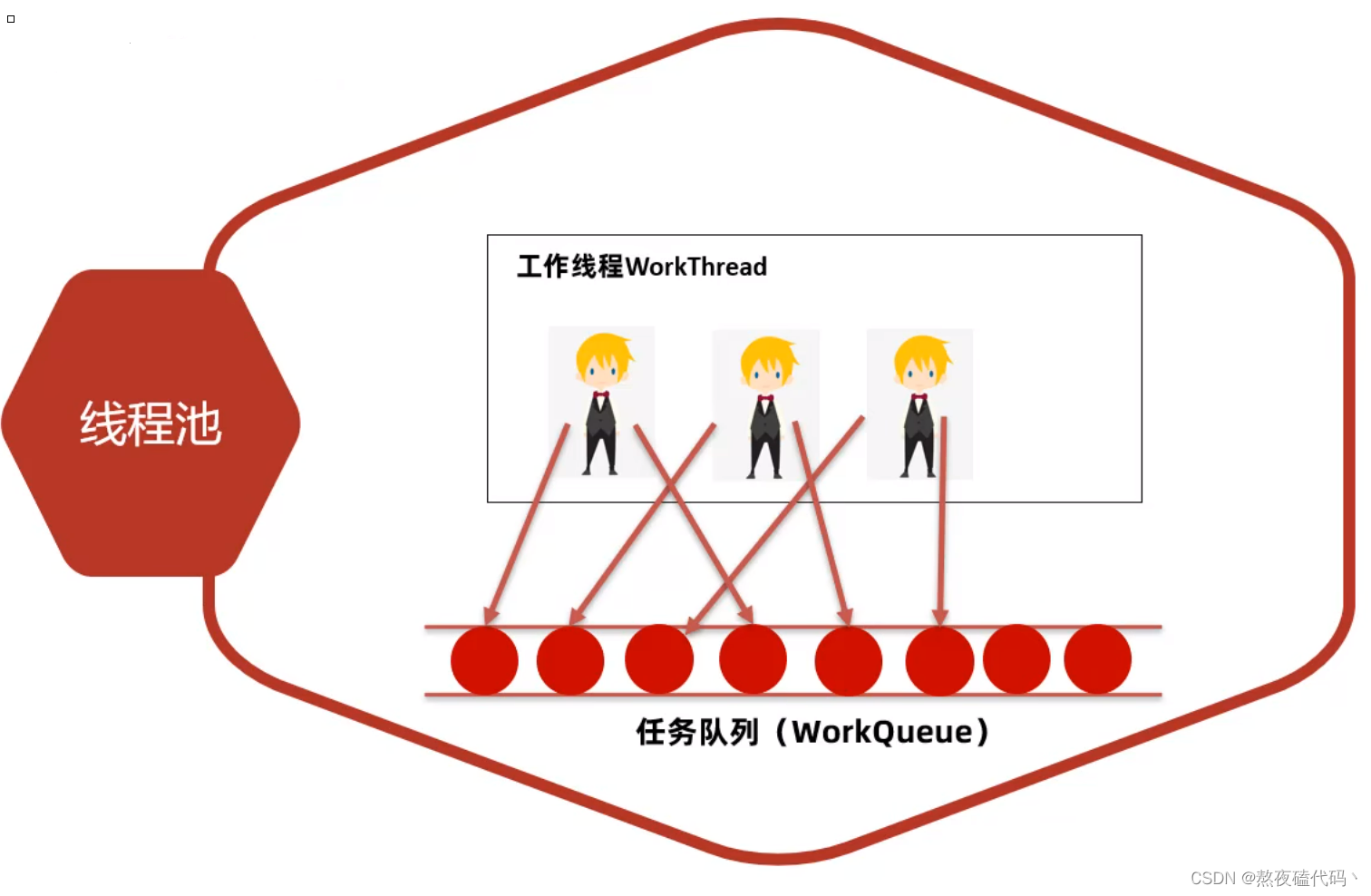
肯定会有同学问,为什么引入线程池就会降低开销?
首先我们创建线程和销毁线程是由操作系统内核来控制的,我们人为无法干涉。但是如果引入线程池,我们事先就可以将线程创建好放入"线程池"中,后面需要的时候,直接从池子中取,用完归还到池子中,这样就省去了频繁的创建和销毁线程的开销。
标准库提供的线程池
JDK5.0开始,提供了代表线程池的接口: ExecutorService
如何得到线程池对象?
方式一: 使用Executors(线程池的工具类)调用方法,返回不同类型的线程池。
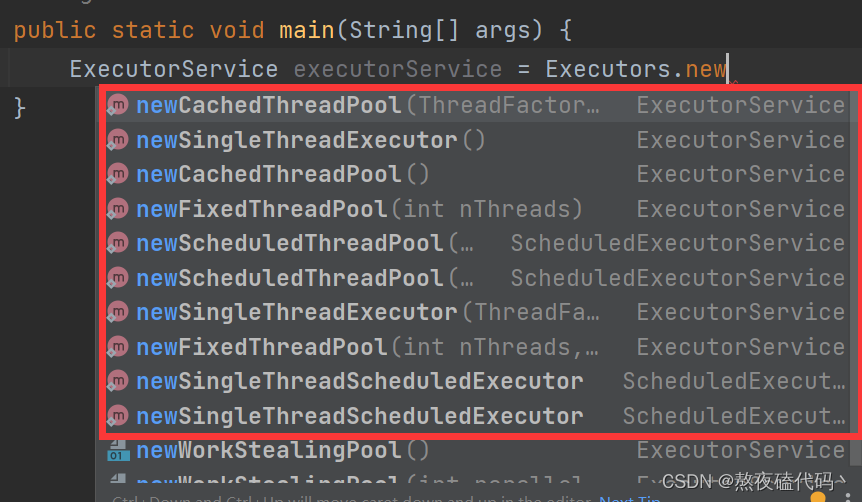

我们可以发现我们Executors线程池的工具类下面为我们提供了很多不同应用场景的线程池。
细心的同学可以发现,我们这里并不是直接去new 一个线程池,而是调用Executors的一个方法返回一个对象。
我们使用某个类的静态方法,直接构造出来一个对象(相当于我们的new操作隐藏在了方法里面),我们称这样的方法为 “工厂方法“,提供这个工厂方法的类,称为"工厂类”,我们这种思想就是"工厂模式” 的一种 “设计模式”.我们后面会详细介绍。
| 方法 | 作用 |
|---|---|
| Future<?> submit(Runnable task) | 向线程池提交任务 |
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("使用线程池执行的第一个任务");
}
});
}
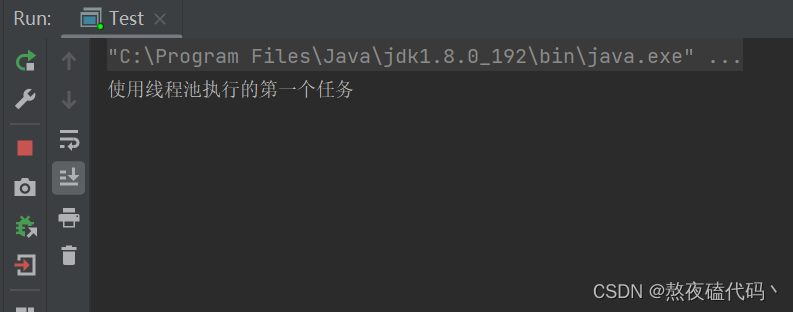
我们可以发现我们创建了一个5个线程的线程池,我们提交了一个任务,并且顺利执行,我们可以发现我们执行完这个任务之后,程序并没有结束,因为我们的线程池再继续等待提交任务。
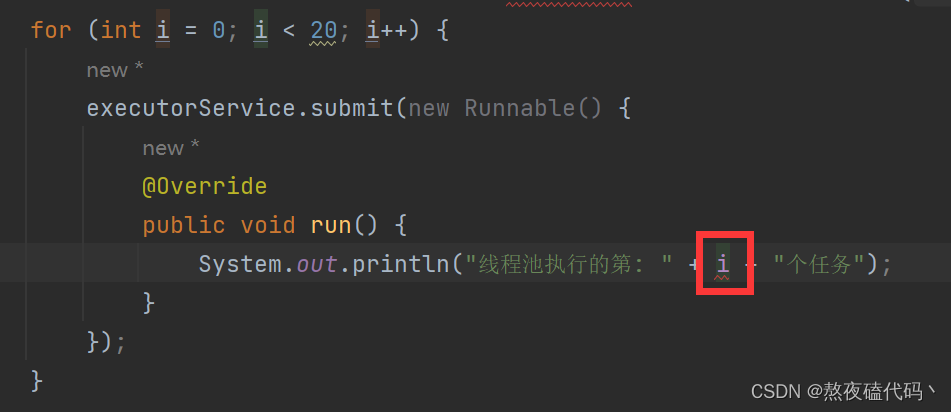
当我们想多提交几个任务并且记录是第几个任务的时候,发现程序报错了。

我们可以分析一下为什么我们的run方法中使用i变量会报错,因为我们的i是main方法的局部变量,而我们的run方法是属于Runnable,这个方法不是立马执行的(而是在线程池的队列中等待执行),因为有可能当我们执行到run方法的时候,循环已经执行完了,i已经被销毁了,所以我们这里的run方法无法使用i变量。
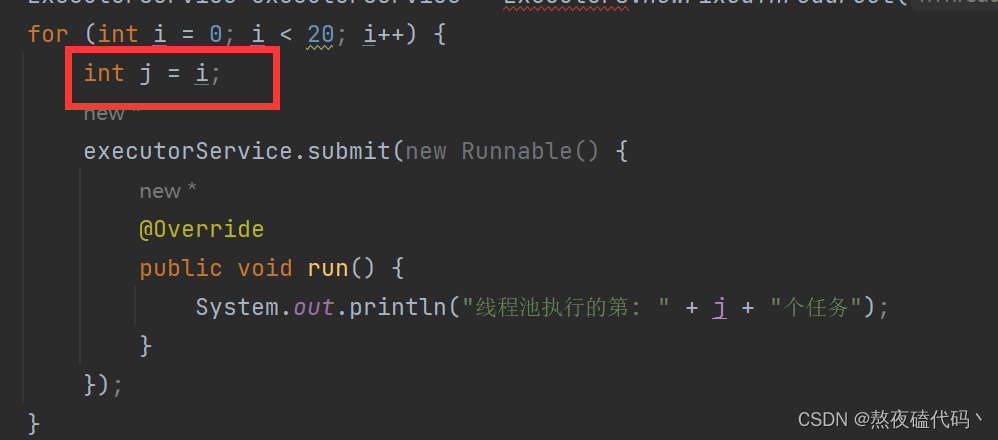
因为有这种作用域的差异,我们需要重新一个一个变量去记录下这个i,这个操作也称为变量捕获,也就是给run方法的栈上拷贝一份i(简单地说就是在定义run方法的时候,偷偷的把i记住,在后续执行run方法的时候,创建一个i的局部变量,并且把记录的这个值赋值过去).
在JDK1.8之前,我们变量捕获只能捕获final修饰的变量,也就是我们定义j时必须定义为final修饰。
在JDK1.8开始,我们的变量捕获不一定需要final修饰,只需要保证代码中没有修改过该变量即可。
这也就是为啥i不能捕获,因为i存在修改,而我们的j不存在修改。
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 20; i++) {
int j = i;
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("线程池执行的第: " + j + "个任务");
}
});
}
}
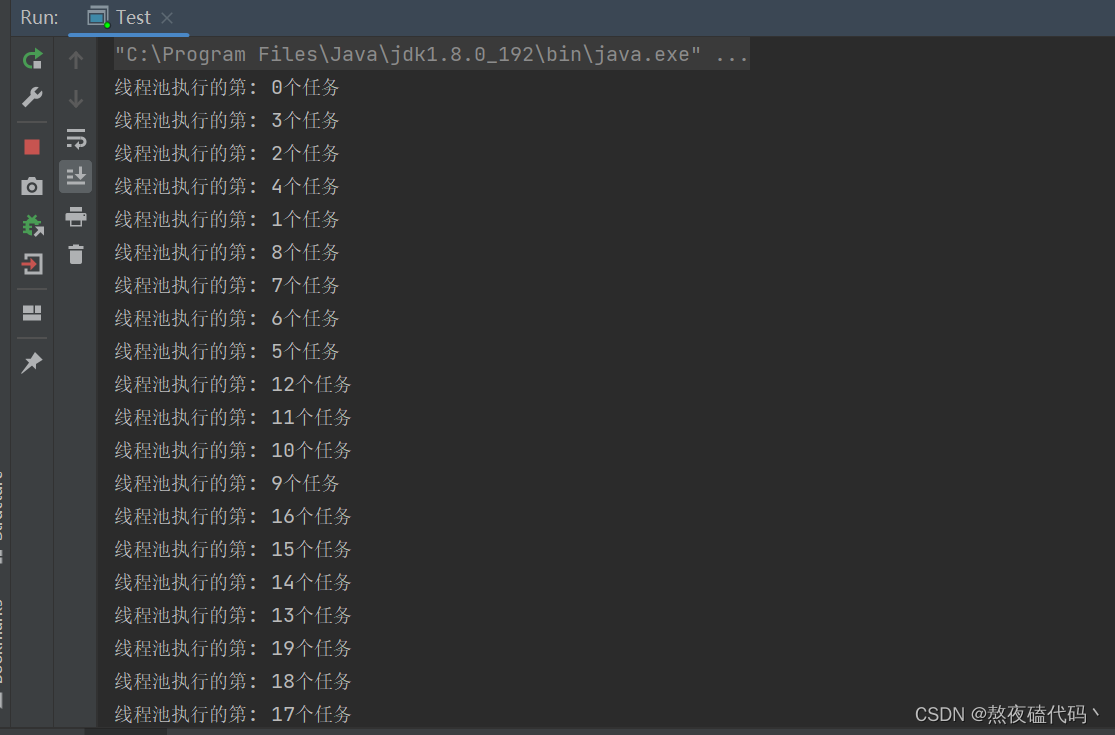
我们可以发现我们往线程池里放了20个任务,但因为我们的线程调度是随机的,所以我们这里的执行顺序不固定。
我们的20个任务由这5个线程分配一下,按道理来说是一人执行4个,但这里由于线程的调度是随机的,抢占式执行,所以这里有的多一个少一个都是很正常的。
ThreadPoolExecutor
方式二: 使用ExecutorService的实现类ThreadPoolExecutor自己创建一个线程池对象。
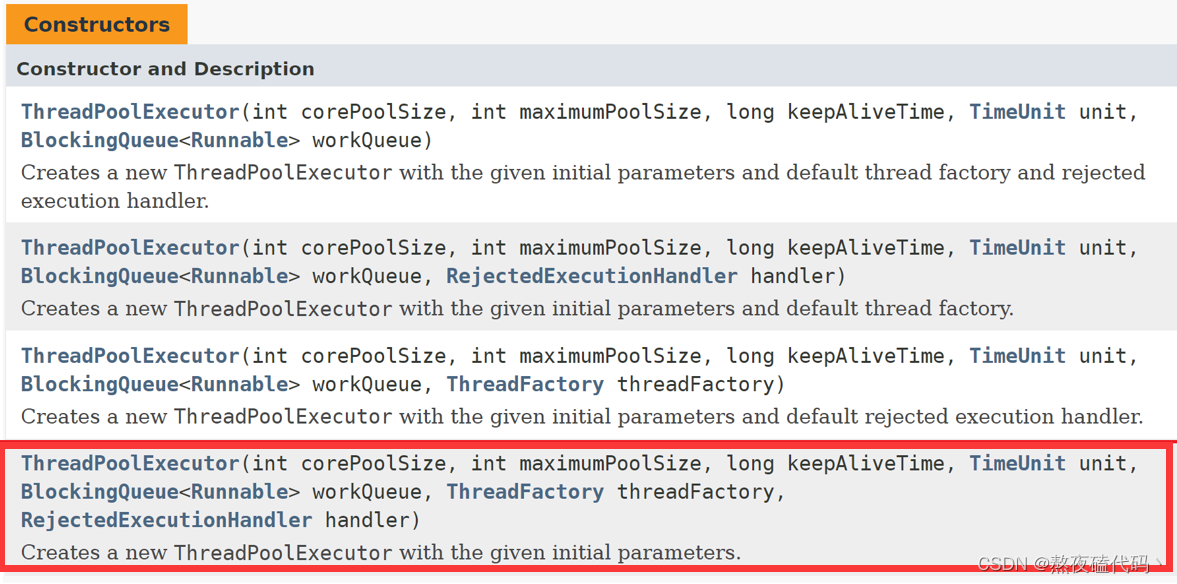
我们在API文档中查看一下ThreadPoolExecutor的构造方法,我们可以发现有不同参数的构造方法,我们这里介绍参数最多参数的构造方法,这个构造方法覆盖了前面几个。

我们再来详细的介绍一下这几个参数
1.corePoolSize(核心线程数)
我们举几个生活中的例子,我们现在创建一家公司,corePoolSize就相当于几个合伙人
2.maximumPoolSize(最大线程数)
我们的公司肯定不只是合伙人,肯定还需要一些员工,这里合伙人加员工的数量最多为最大线程数
3.keepAliveTime(最大存活时间)
我们公司肯定有活员工才有存在的价值,最大存活时间就是多长时间没有活就辞退员工
4.unit(时间单位)
最大存活时间的时间单位
5.BlockingQueue workQueue(任务队列)
我们向线程池submit的任务,就放入这个任务队列
6.ThreadFactory threadFactory(线程创建方式)
指定我们的线程池以什么方法创建线程。
7.RejectedExecutionHandler handler(拒绝策略)
我们的任务队列是有大小的,既然有大小就有存满的一刻,当我们存满时。在存入元素,会发生什么,由我们的拒绝策略决定。
这里我们举出这四种拒绝策略,以及做出的不同反应。

我们这里有两个比较重要的问题
1.临时线程什么时候创建?
当新任务提交时,发现核心线程都在忙,而且任务队列也满了,并且还可以创建临时线程,才会创建临时线程
2.什么时候会开始拒绝任务?
核心线程和临时线程都在忙,任务队列也满了,新的任务过来时,才会开始拒绝任务。
public static void main(String[] args) {
//创建线程池对象
ExecutorService pool = new ThreadPoolExecutor(3,5,6, TimeUnit.SECONDS,new ArrayBlockingQueue<>(5),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
}
这里我们简单创建一个线程池对象
自定义线程池
我们的线程池主要有两个部分
- 任务队列,存放我们提交的任务
- 若干个工作线程,负责执行任务
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class MyExecutorService {
//任务队列
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
//submit方法,向任务队列提交任务
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//创建工作线程,指定线程池中线程数量为n
public MyExecutorService(int n) {
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
while (true) {
try {
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}

![[Linux理论基础1]----手写和使用json完成[序列化和反序列化]](https://img-blog.csdnimg.cn/7c48388057d349b3b443568051f6f8e7.png)







![[ 数据结构 ] 查找算法--------线性、二分、插值、斐波那契查找](https://img-blog.csdnimg.cn/img_convert/10bb5ebed35220bdf74e2cbb24f7205e.png)