前文:
【知识图谱导论-浙大】第一章:知识图谱概论
【知识图谱导论-浙大】第二章:知识图谱的表示
说明:原视频中的第三章主要介绍了图数据库相关的内容,有兴趣的可以查看相关课件或者对应的视频:
【知识图谱理论】(浙大2022知识图谱课程)第三讲-知识图谱的存储与查询
本文对应的视频链接如下:
【知识图谱理论】(浙大2022知识图谱课程)第四讲-知识图谱的抽取与构建
背景
在传统的知识工程中,知识获取遇到了瓶颈。成年人脑包含近1000亿神经元,每个神经元都可能有近
1000的连接。模拟这样的人脑需要约100TB的参数。假设这100TB的参数能完整的存储人脑中的知识,靠人工编码可以获取这样规模的知识吗?单个人脑中的知识仍然是有限的,如果需要获取全体人类知识,靠人工编码是无法完成的。
深度学习的一个重大贡献是在感知层面,实现了事物和对象的准确识别,但仅仅识别是远远不够的。当人们看到一张图片(画面),不仅要识别其中包含的对象,还需要理解图片中的事物之间的关联关系,并进一步从感知产生知识,再进一步到认知层面。
通过识别世间万物,形成关于万物的知识,进而形成关于万物的概念,并发明了语言来描述这些概念。概念相互组合进而产生逻辑,依赖这些逻辑来完成推理。更为复杂的知识来源人们对事物关系更为深层次的把握。例如使用数学符号描述的模型,就是依赖概念符号进一步抽象出来的更为深层次的关于世界的知识。
让机器自动地从识别、感知出发去构建概念,进而产生逻辑和生成模型还是有很长的道路要走。既然利用机器来表示和自动化获取全部人类知识是很艰难的,知识图谱也就没有必要再陷入传统知识工程的困境中了。于是,知识图谱把知识获取的内容限定于比较清晰的任务,如:概念抽取、实体识别、关系抽取、事件抽取等。
知识图谱构建的数据主要来源:
- 结构化数据,如数据库等
- 半结构化数据,如表格,列表等
- 纯文本
- 多媒体数据等
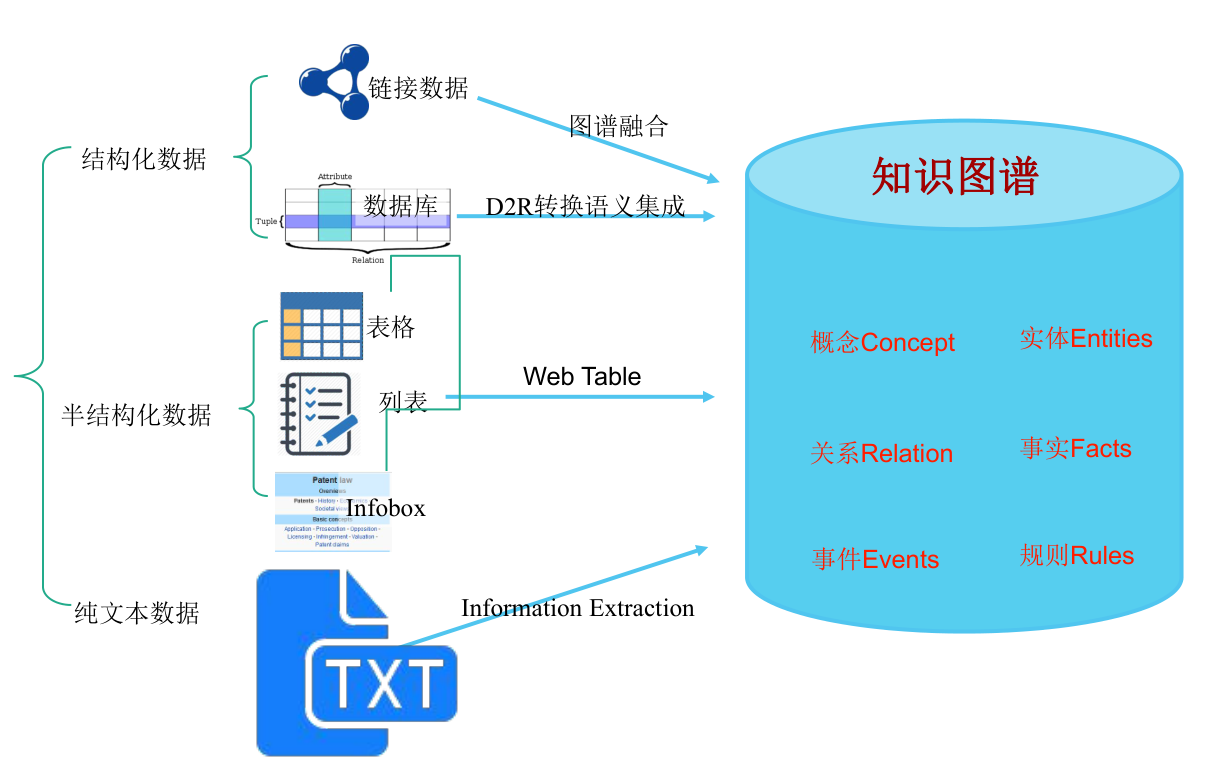
从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱。
通常情况下,知识图谱工程项目是通过已有的结构化数据完成能启动,再进一步利用文本图谱等数据来补全知识图谱。
最为直接快速地获取知识图谱数据的方法是从已有的关系数据库中抽取,通常的做法是先定义一个common schema或本体,然后通过映射语言将关系模型映射到本体语言。
当前大部分任务还是从文本中获取知识图谱数据。于是就将任务分解为如下几个任务:
- 命名实体识别,主要完成从文本中识别出实体
- 概念抽取,主要完成怎么从大量的语料中发现多个词组成的相关术语
- 关系抽取,主要完成怎样从句子中抽取一组实体之间的关系
- 事件抽取,主要完成如何从文本中抽取事件,任务更加复杂(触发词,事件发生的时间、地点、涉及的对象等等)
实体识别与分类
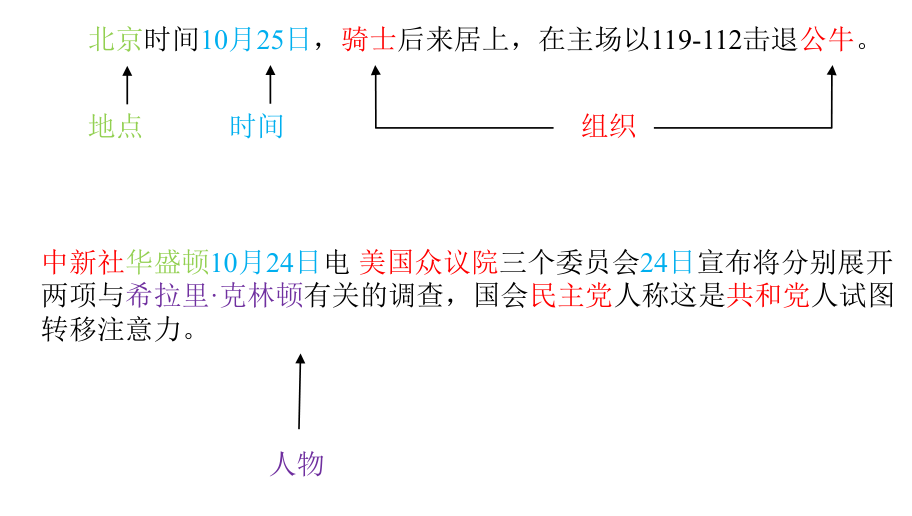
实体识别与分类主要目标是从文本中识别实体的边界及其类型。例如:
基于规则和模板的命名实体识别
该方法就是构建模板,然后在文本中进行匹配。例如:

基于序列标注的方法
基于规则的方式优点、缺点都很明显。所以更为常用的做法就是利用机器学习的算法。实体识别任务可以转换为序列标注的问题,例如:
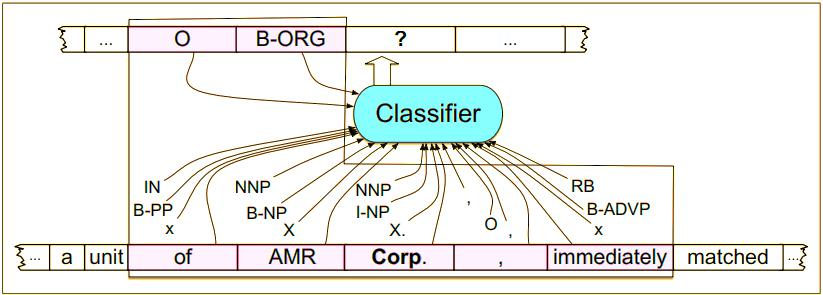
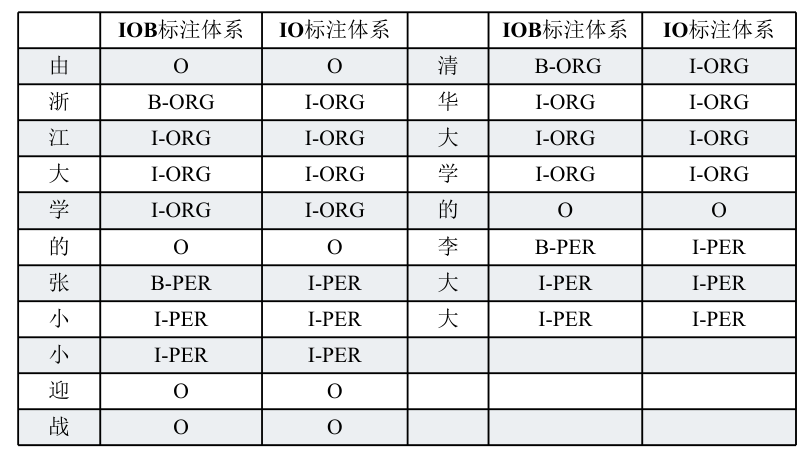
在做序列标注之前,则是需要确定实体识别的序列标签体系,例如:
常见的序列标注模型有:
- 隐马尔可夫模型(HMM)
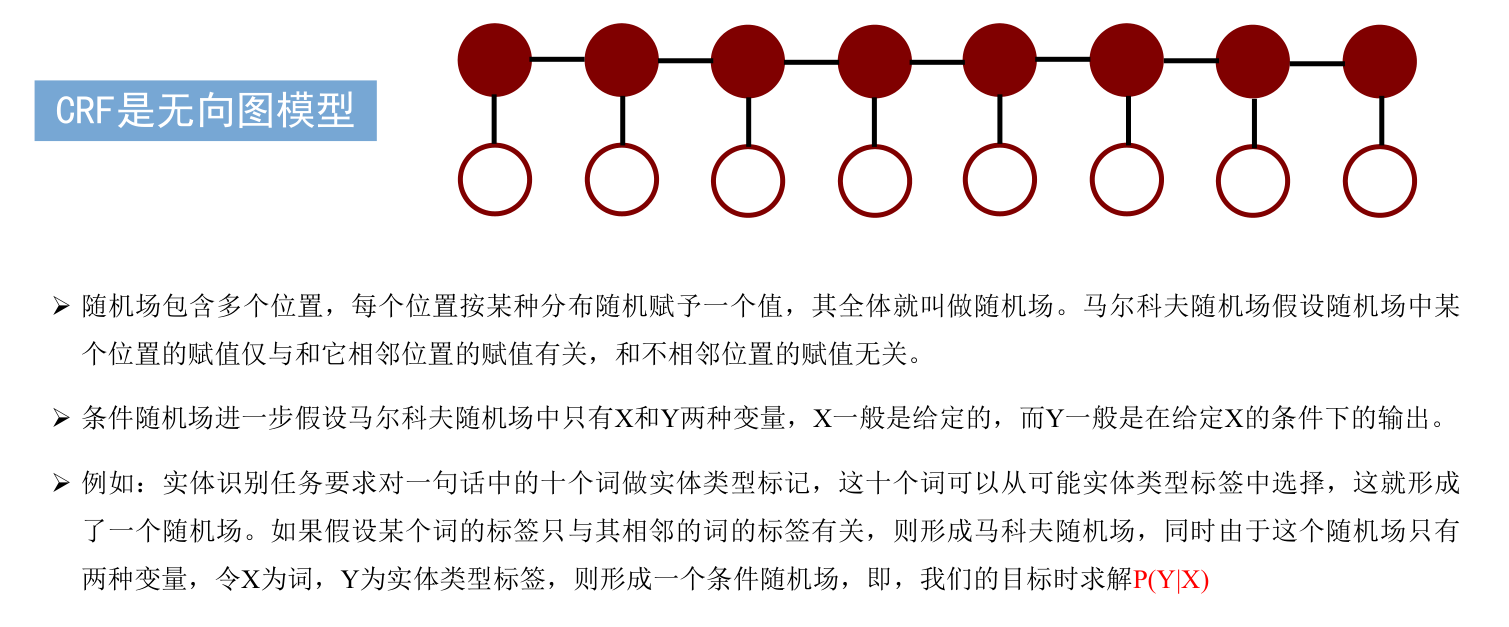
- CRF条件随机场
- 基于深度学习的实体识别方法
HMM在序列标注上的简单使用
HMM是一个有向图模型,基于马尔可夫性,假设特征之间是独立的。例如:
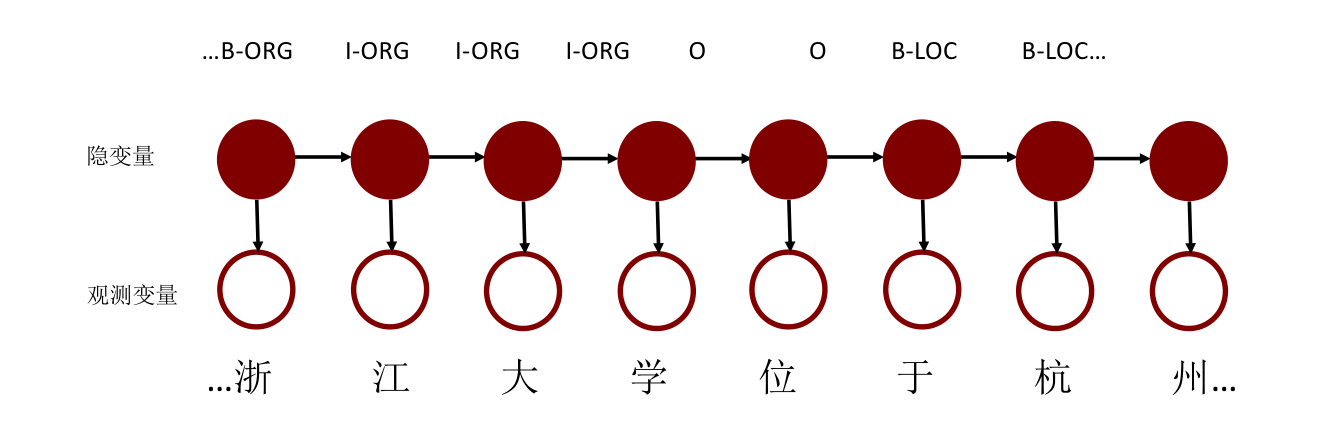
待识别的文本作为观测变量,文本对应的标签作为隐变量。
HMM要素定义
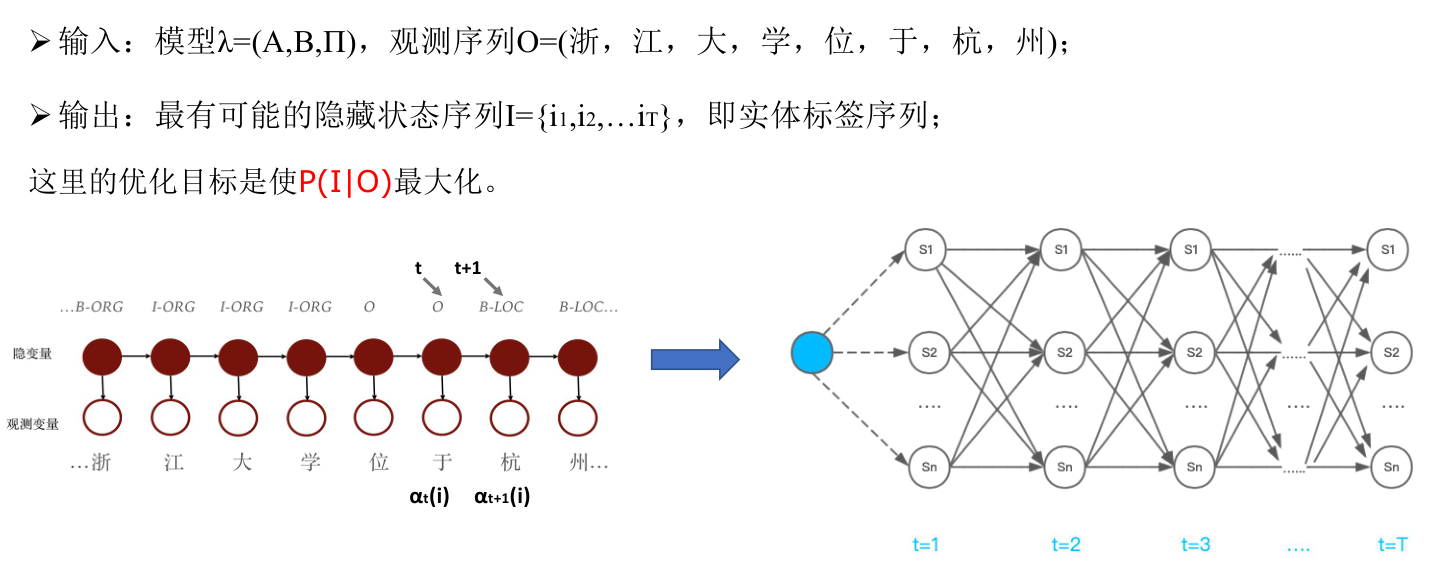
使用隐马尔可夫模型进行序列标注的描述如下:
- 隐藏状态集合Q,对应所有可能的标签集合,大小为N;观测状态集合V,对应所有可能的词的集合,大小为M;
- 对于一个长度为T的序列,I对应状态序列(即标签序列),O对应观测序列(即词组成的句子);
- 状态转移概率矩阵 A = [ a i j ] N ∗ N A=[a_{ij}]_{N*N} A=[aij]N∗N:转移概率是指某一个隐藏状态(如标签“B-Per”)转移到下一个隐藏状态(如标签“I-Per” )的概率。例如,B-ORG标签的下一个标签大概率是I-ORG,但一定不可能是I-Per;
- 发射概率矩阵 B = [ b j ( k ) ] N ∗ M B=[b_j(k)]_{N*M} B=[bj(k)]N∗M:指在某个隐藏状态(如标签“B-Per”)下,生成某个观测状态(如词“陈”)的概率;
- 隐藏状态的初始分布 Π = [ π ( i ) ] N \Pi = [\pi(i)]_N Π=[π(i)]N,这里指的是标签的先验概率分布。
HMM的计算问题
- 评估观察序列概率:给定模型 λ = ( A , B , Π ) \lambda =(A,B,\Pi) λ=(A,B,Π) 和观测序列O(如一句话“浙江大学位于杭州”),计算在模型 λ \lambda λ下观测序列O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ),这需要用到前向后向算法。
- 模型参数学习问题:即给定观测序列O,估计模型 λ \lambda λ的参数,使该模型下观测序列的条件概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)最大。这个问题的求解需要用到基于EM算法的鲍姆-韦尔奇算法。
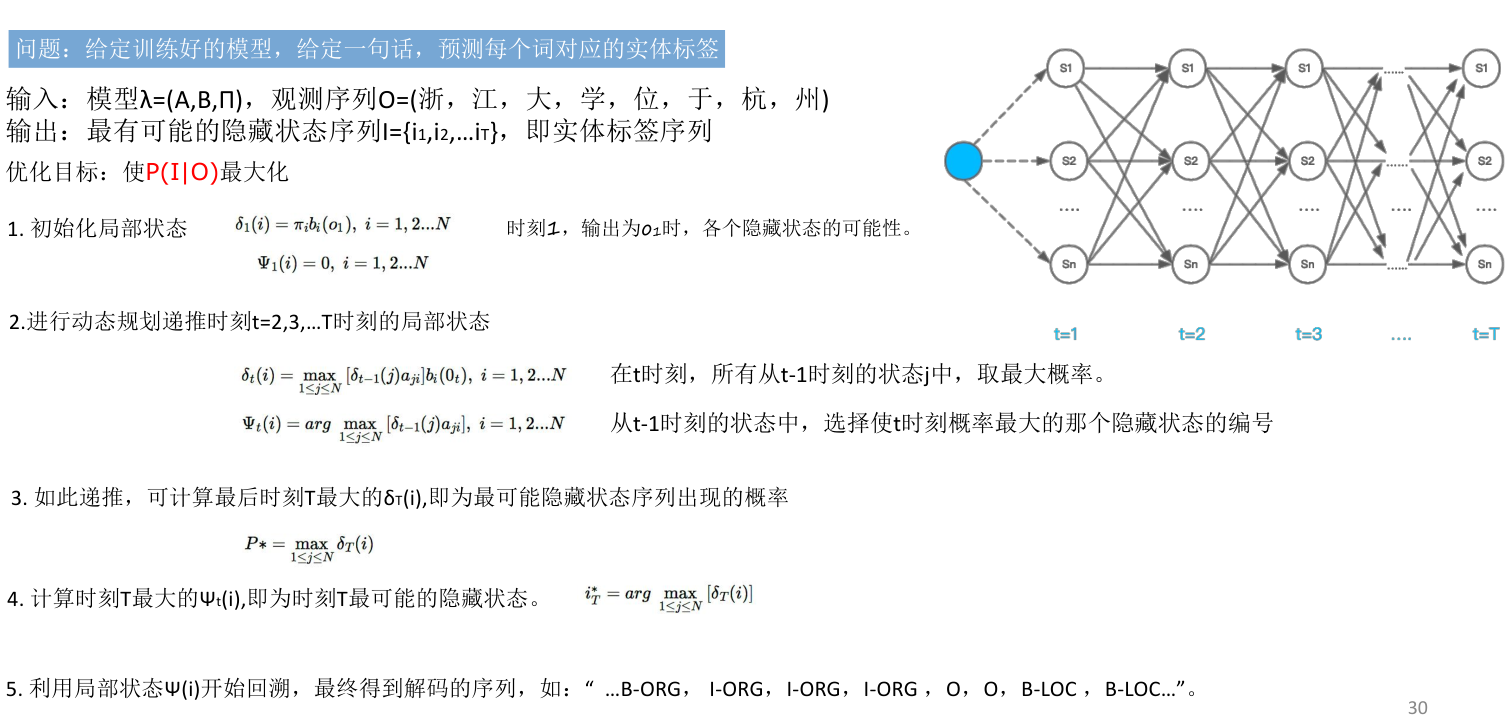
- 预测问题:也称为解码问题,即给定模型 λ \lambda λ和观测序列O,求最可能出现的对应的隐藏状态序列(标签序列),这个问题的求解需要用到基于动态规划的维特比算法。
求观测序列的概率:前向后向算法
问题:假设模型参数全知,要求推断某个句子出现的概率,处理过程如下:

模型参数的估计与学习

使用鲍姆韦尔奇算法-EM算法进行模型参数的估计与学习,如下:

解码隐藏状态序列:维特比算法
问题:给定训练好的模型,给定一句话,预测每个词对应的实体标签
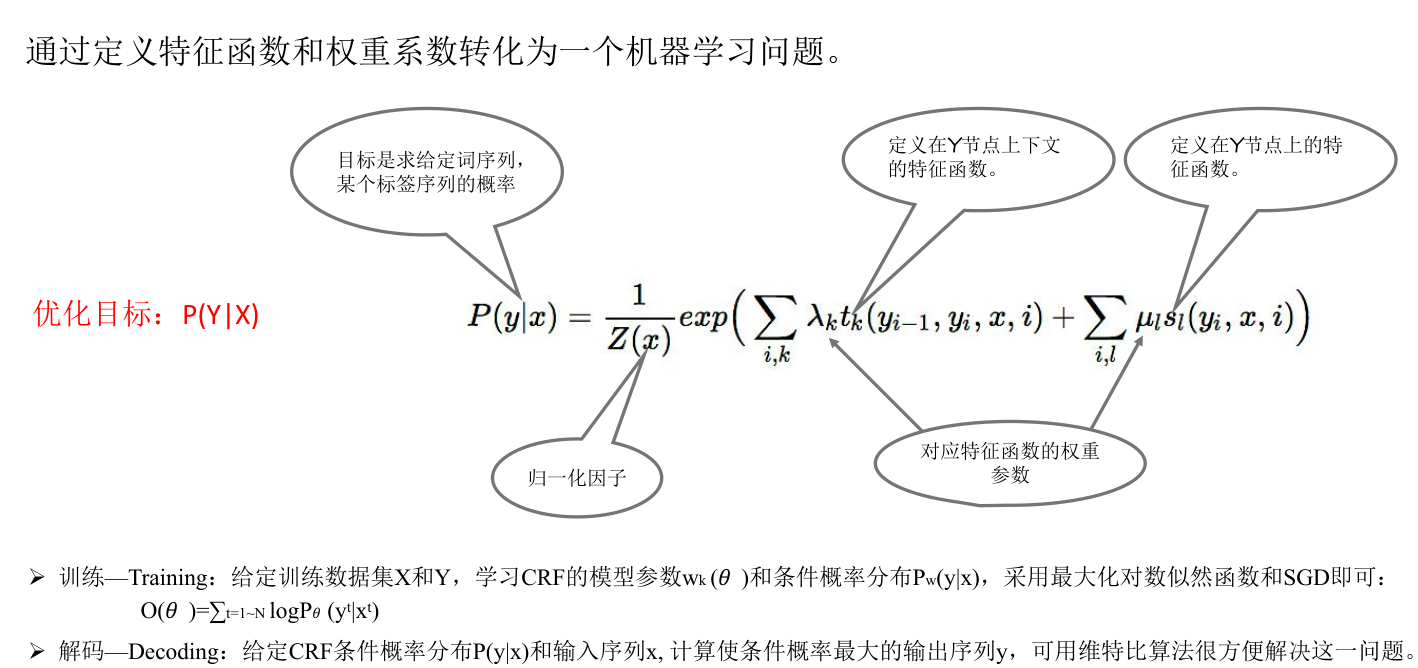
CRF条件随机场
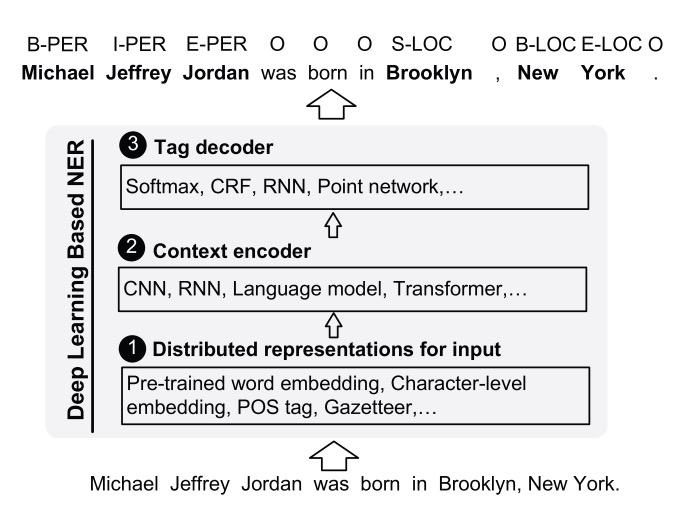
基于深度学习的实体识别方法
随着人工神经网络的发展,深度学习模型可以做到自动产生实体识别任务所需的特征。基于深度学习的实体识别主要流程如下(A Survey on Deep Learning for Named Entity Recognition. (TKDE2020)):
BiLSTM+CRF模型
主要流程如下:
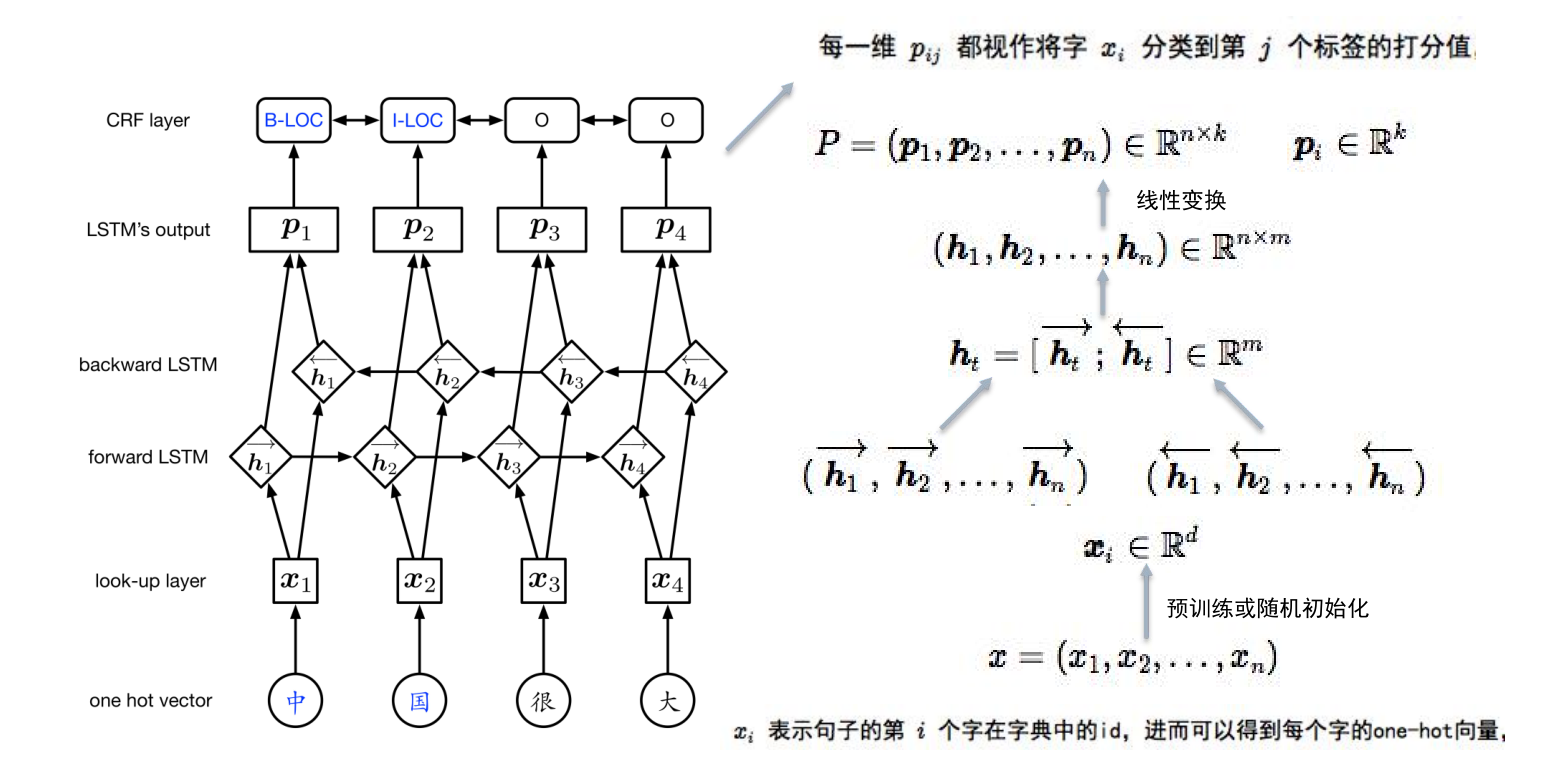
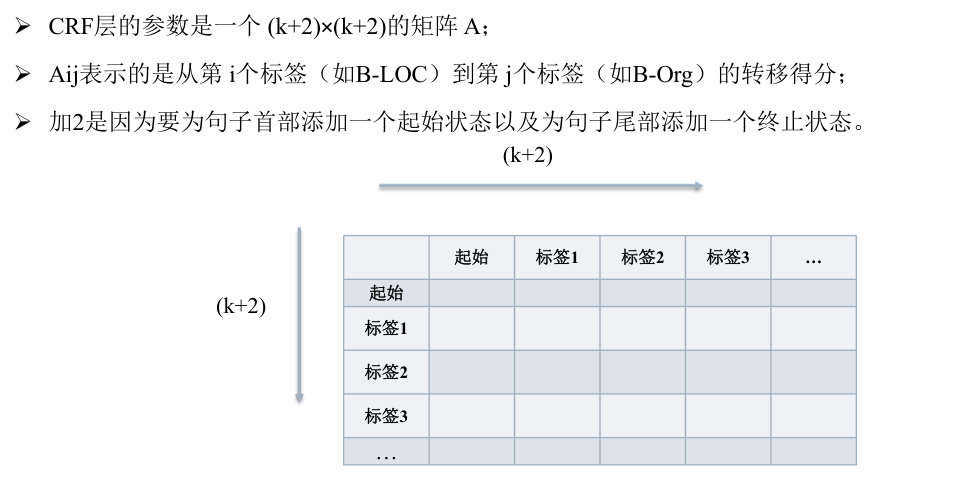

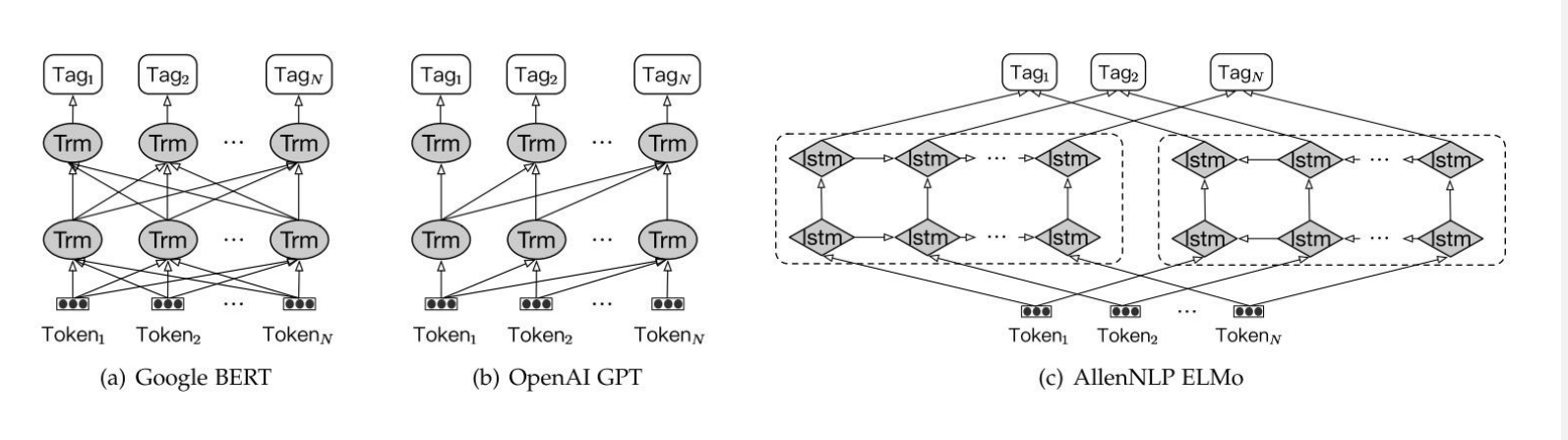
基于预训练语言模型的实体识别
A Survey on Deep Learning for Named Entity Recognition. (TKDE2020)
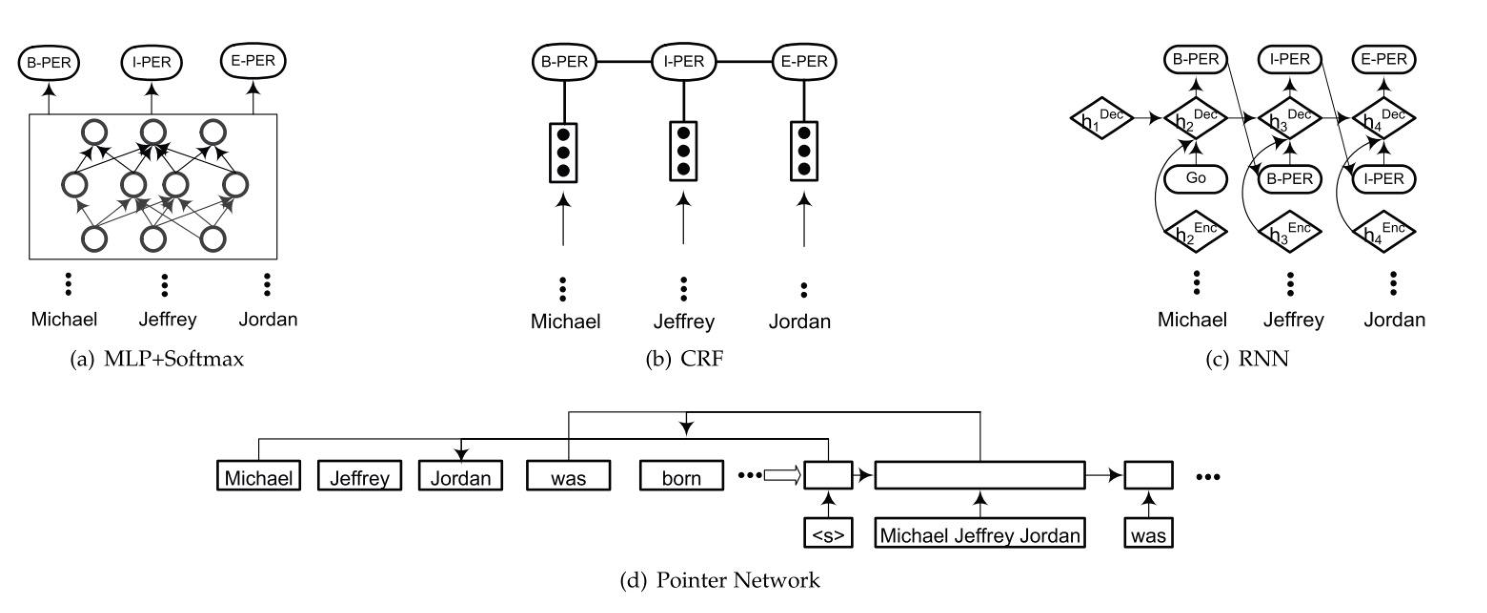
实体识别解码策略
A Survey on Deep Learning for Named Entity Recognition. (TKDE2020)
实体关系抽取与属性补全
实体关系抽取主要是从文本中抽取出两个或者多个实体之间的语义关系;是从文本中获取图谱三元组的主要技术手段,通常被用于知识图谱的补全。例如:
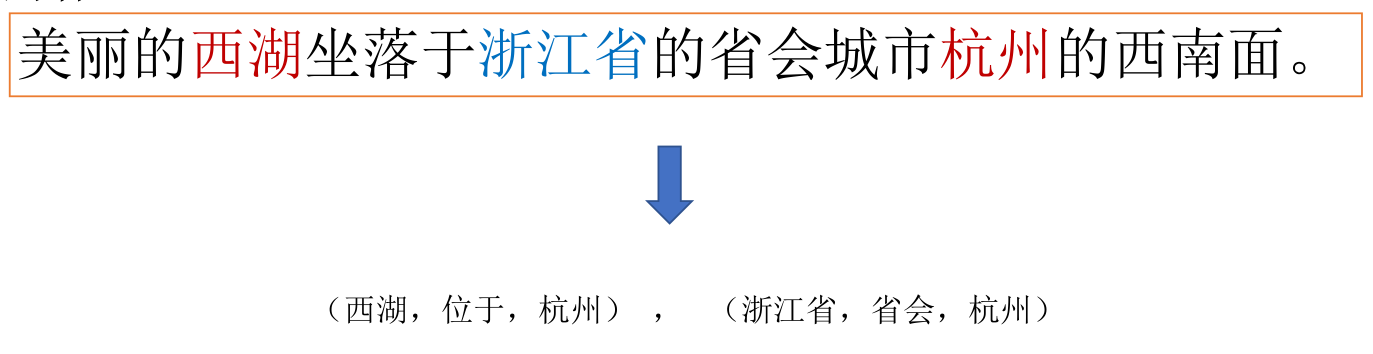
实体关系抽取有多种方法,如下:
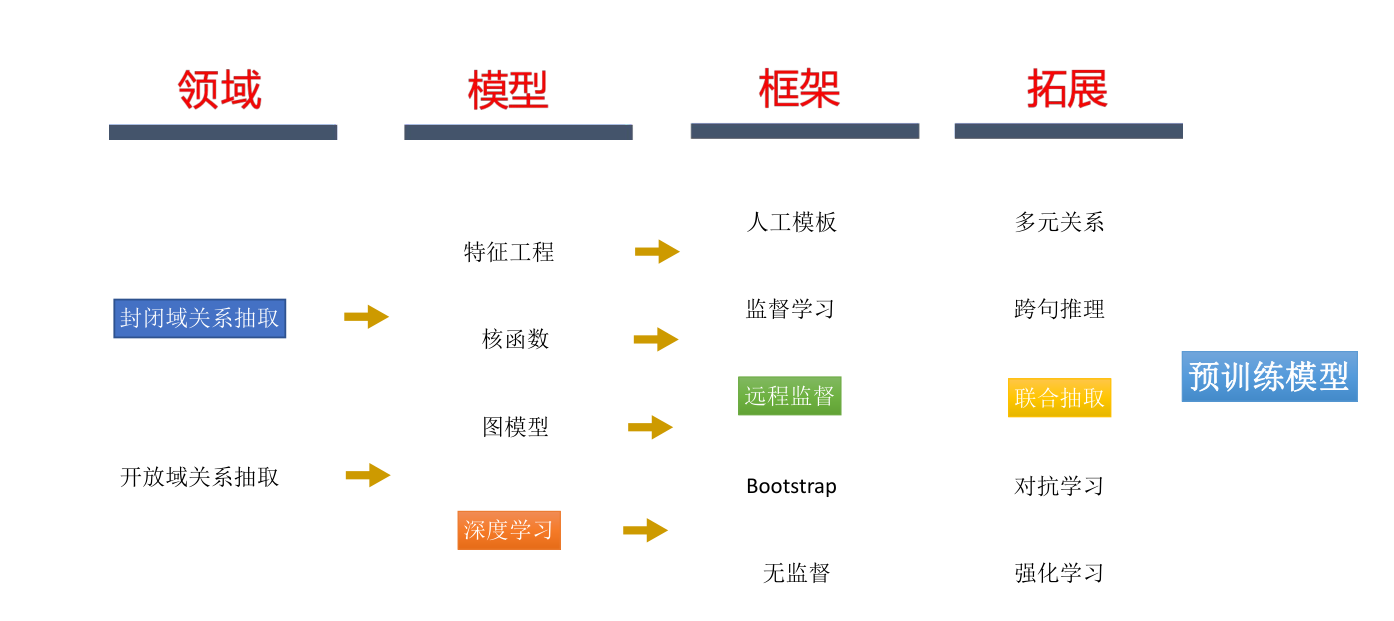
当前深度学习技术不断发展,端到端的抽取方法能大幅减少特征工程,并减少对词性标注等预处理模块的依赖,成为当前关系抽取的主流技术路线。
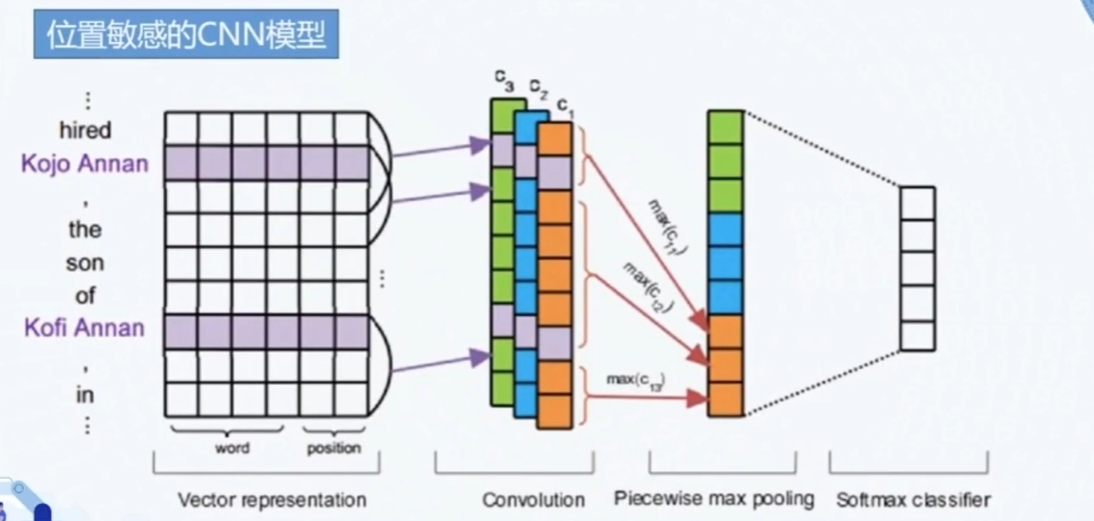
Piece-wise CNN Model——PCN
一种位置敏感的CNN关系抽取模型。
基于BiLSTM的关系抽取
为了解决CNN不能处理长线依赖,RNN有梯度消失的问题,有学者提出了如下模型:
Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification(ACL 2016)
模型结构如下:
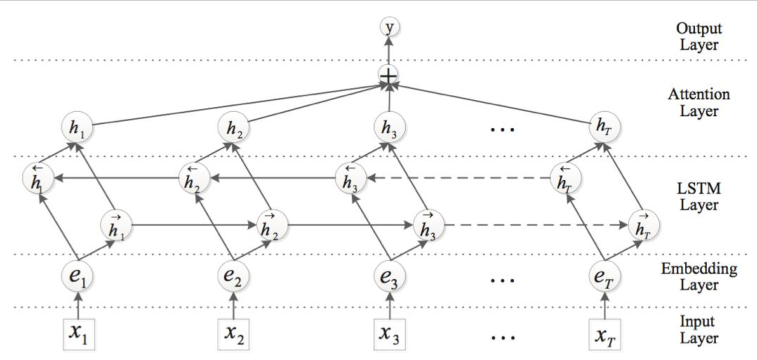
其中LSTM用来编码语句:
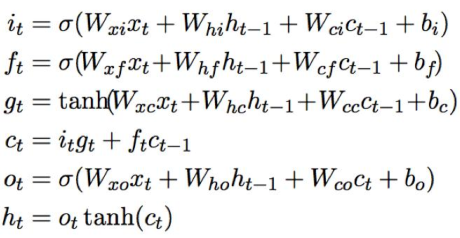
Attention层学习权重:
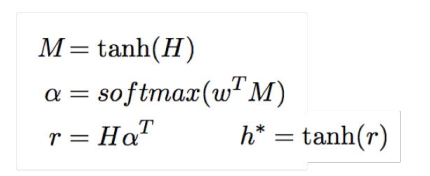
基于图神经网络的关系抽取
图神经网络在图像领域的成功应用证明了以节点为中心的局部信息聚合同样可以有效的提取图像信息。
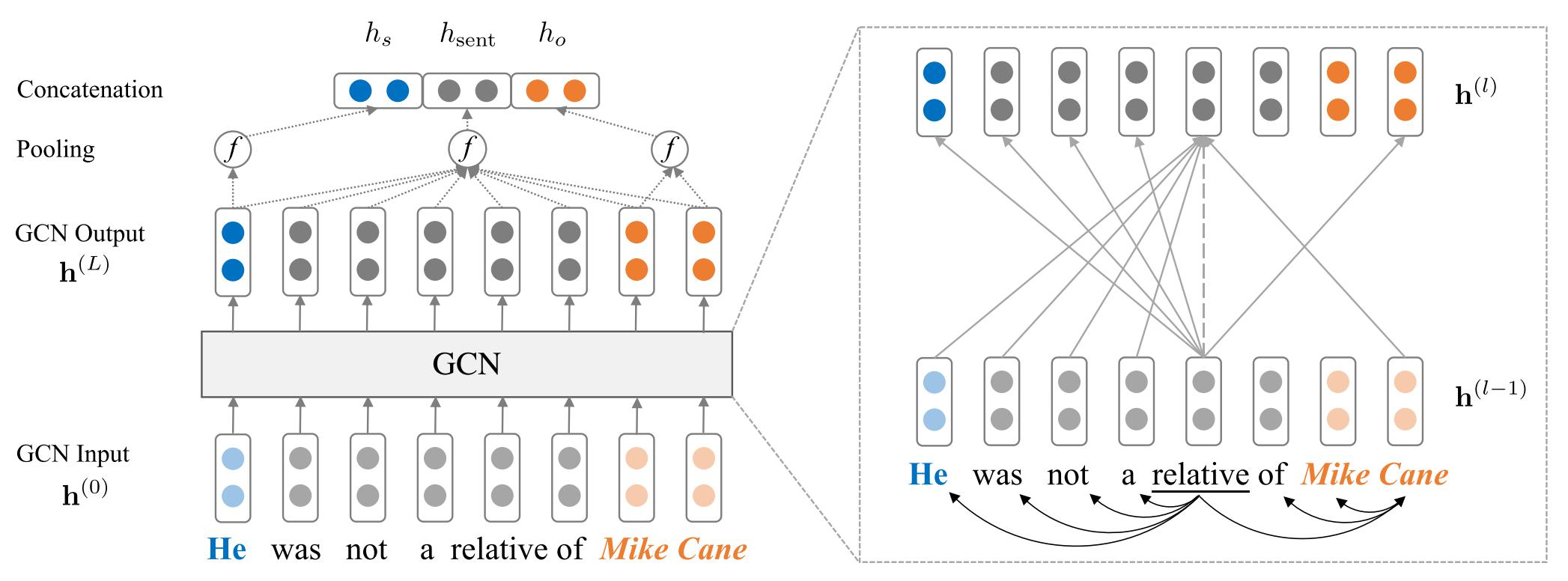
利用句子的依赖解析树构成图卷积中的邻接矩阵,以句子中的每个单词为节点做图卷积操作。如此就可以抽取句子信息,再经过池化层和全连接层即可做关系抽取的任务。
相关论文:Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. (EMNLP2018)
模型结构如下:
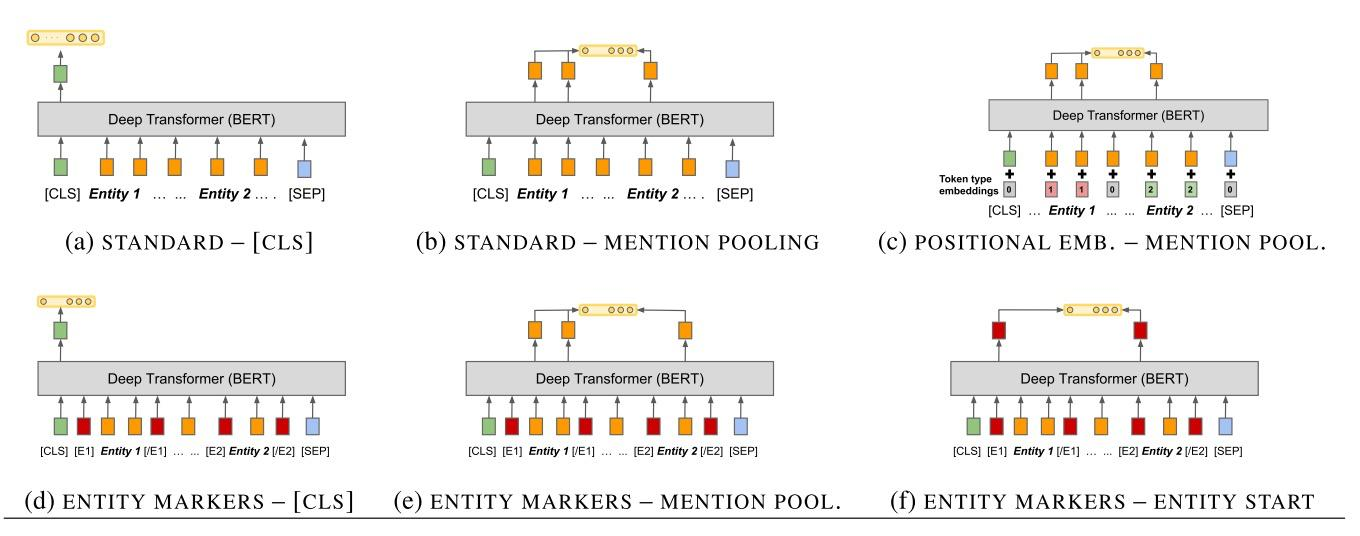
基于预训练语言模型的关系抽取
使用预训练语言模型做关系抽取的一些论文如下:
- Simple BERT Models for Relation Extraction and Semantic Role Labeling[J], 2019.
- Matching the Blanks : Distributional Similarity for Relation Learning. (ACL2019)
半监督的关系抽取
众所周知,深度学习模型是需要很多标注数据的,标注成本比较高。因此也有研究人员提出了半监督的抽取模型。
基于远程监督的关系抽取
使用比较多的是:基于远程监督的关系抽取。
远程监督的基本假设:两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子
均可能表示出这种关系。
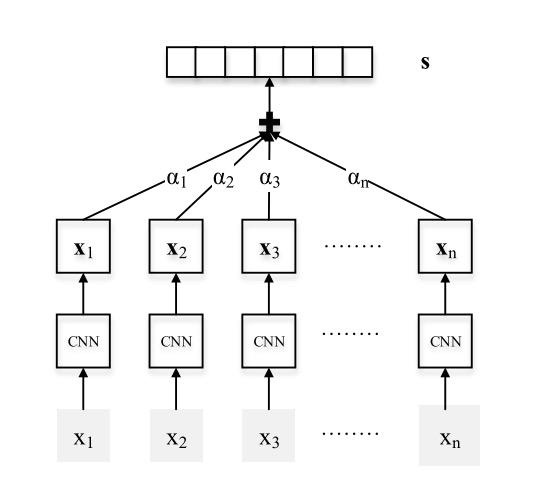
在进行基于远程监督的关系抽取中,会引入大量的噪声信息,基于这个问题有学者提出:基于多实例学习(降噪学习),Neural Relation Extraction with Selective Attention over Instances. (ACL2016),核心思想如下:
- 包含相同实体对的句子组成一个Bag
- 基于注意力机制选择样本
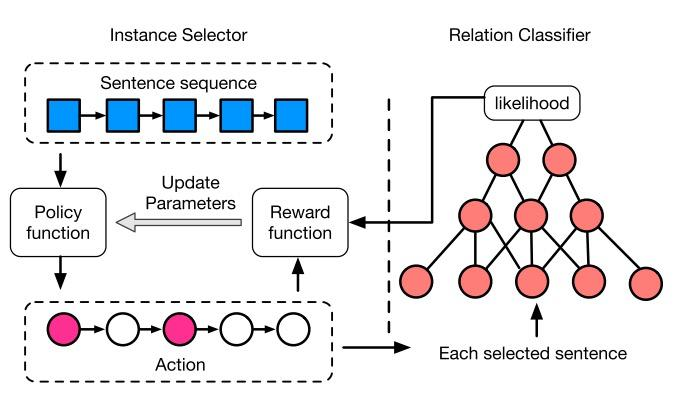
除此之外,还有基于强化学习(降噪学习)的方法,Reinforcement Learning for Relation Extraction from Noisy Data. (AAAI2018),
- 采取强化学习方式在考虑当前句子的选择状态下选择样例;
- 关系分类器向样例选择器反馈,改进选择策略
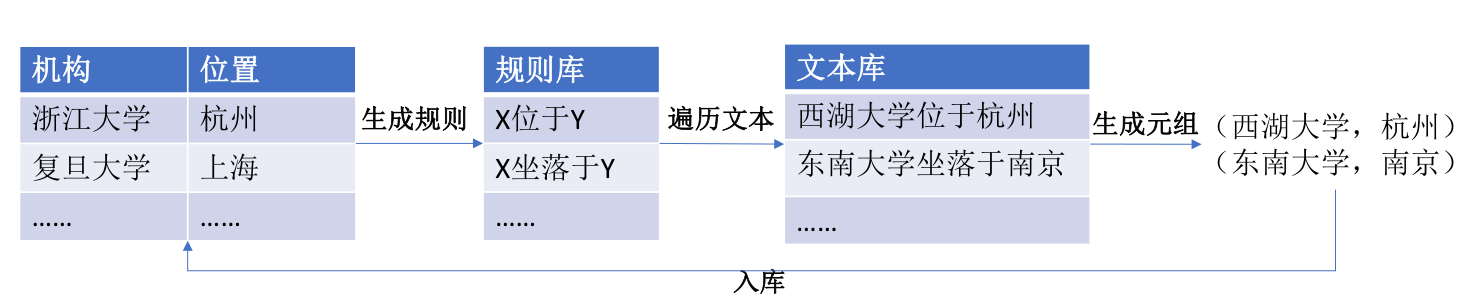
基于Boostsrapping的关系抽取
这种方法的主要思想是:使用少量实例作为初始种子集合,然后进行学习得到新的规则库,进而基于新老规则库抽取新的元组,并扩充种子集合,通过不断迭代从非结构化数据中寻找和发现新的潜在三元组。
基于bootstrap这种标注语料思想以及神经网络的学习能力,有学者提出了:Neural Snowball for Few-Shot Relation Learning. (AAAI2020),
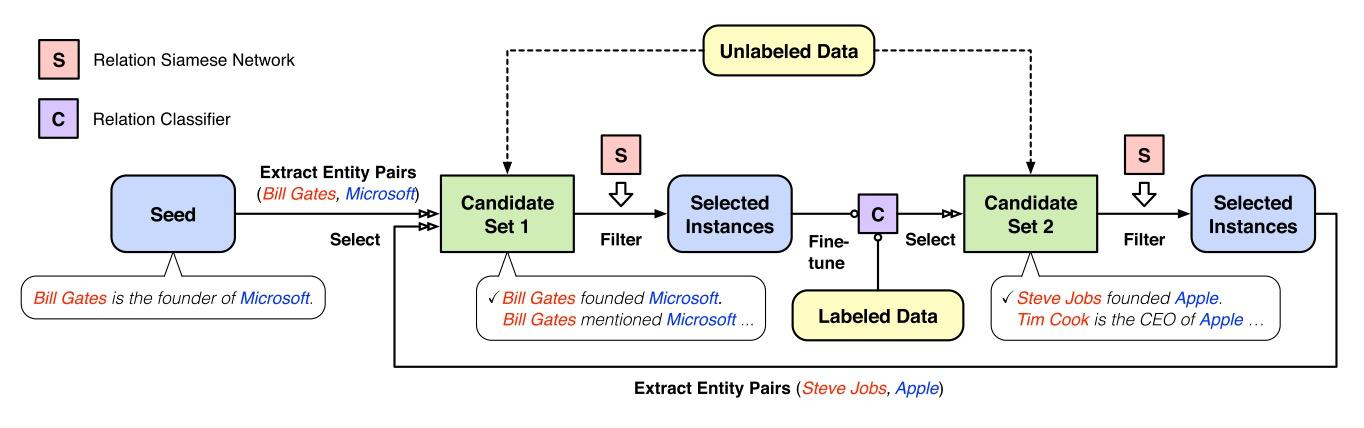
通过转移现有关系的语义知识来学习新关系。当然这种做法也不是尽善尽美的,其存在语义漂移问题:

新增加的实例与种子不相关。解决语义漂移的方法也有不少,例如:
- 限制迭代次数,迭代次数越多,漂移现象越严重
- 采用语义类型Semantic Type对样本进行过滤和约束
- 对抽取结果进行类型检查
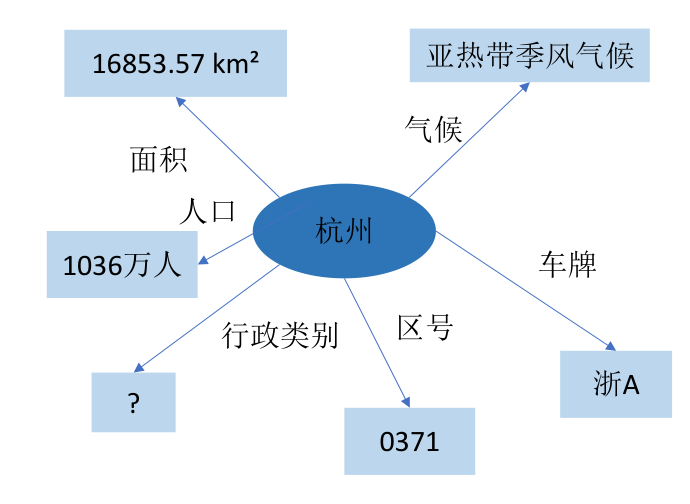
属性补全
属性补全是指:对实体拥有的属性及属性值进行补全。现实中的任何事物都需要若干属性进行描述。
主要的解决方案有:抽取式和生成式。
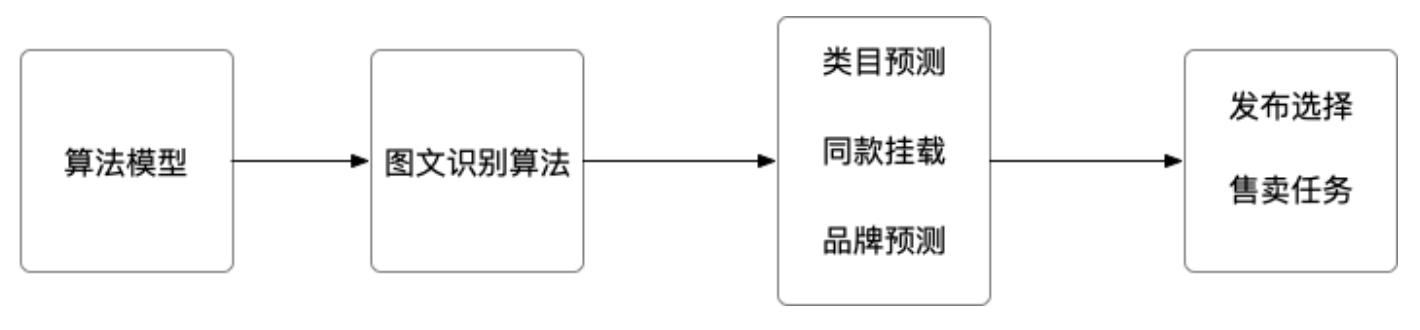
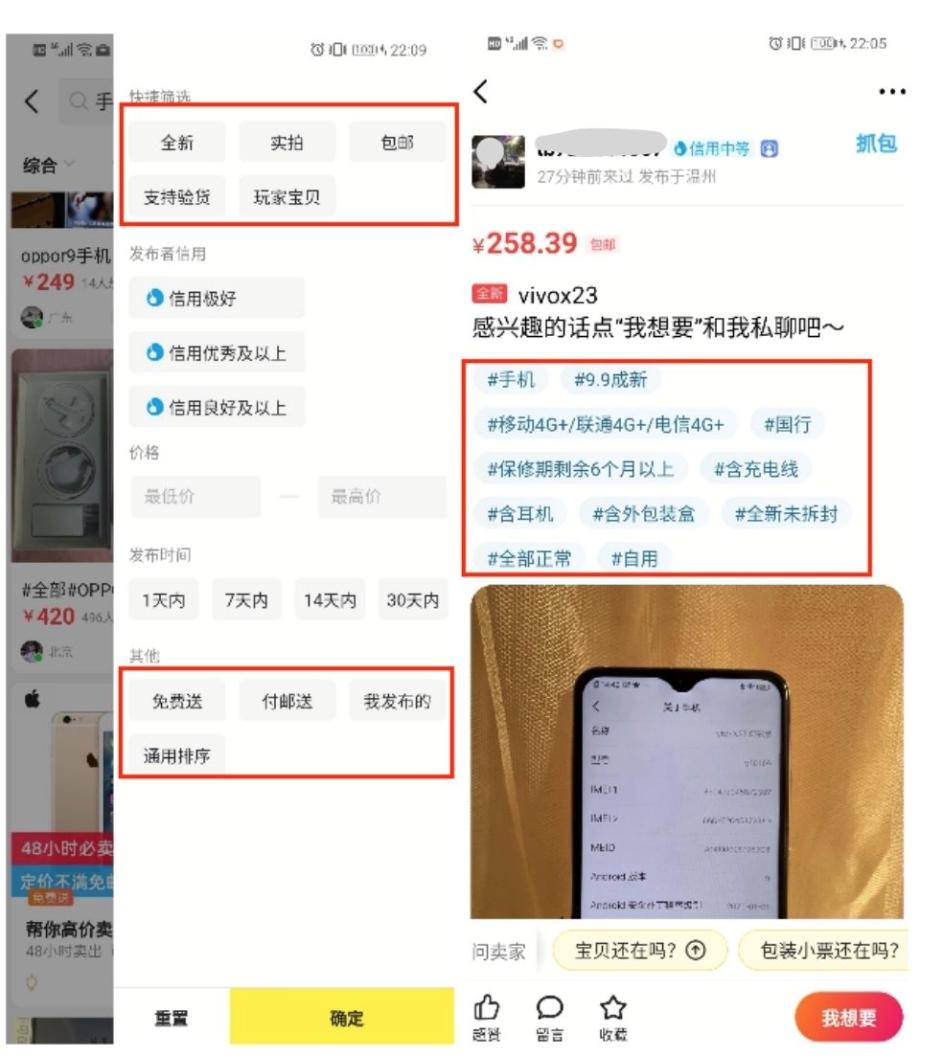
属性补全在商品属性补全得到了应用。在商品关键属性补全后,利于买家选择,利于提升导购,利于优质选品。解决方法:借助算法的图文识别能力,通过商品图片预测商品的类目、同款、品牌。
抽取式的属性补全
抽取输入文本中的字词,组成预测的属性值。预测出的属性值一定要在输入侧出现过。
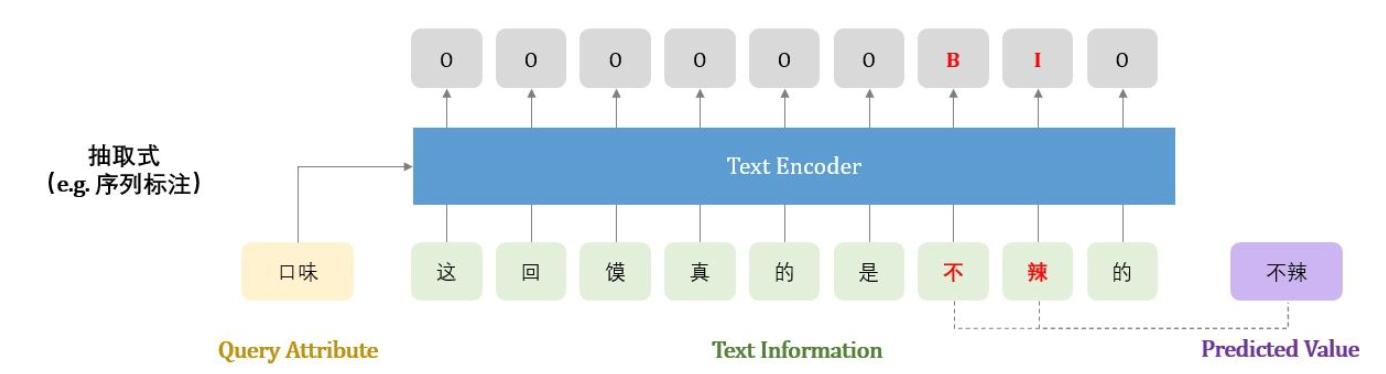
这里也可以使用序列标注的方式来进行属性的抽取。
该方法的特点只能抽取在输入文本中出现过的属性值预测属性值一定在输入中出现过,具有一定可解释性,准确性也更高。
生成式的属性补全
直接生成属性值,而这个属性值不一定在输入文本中出现,只要模型在训练数据中见过即可。
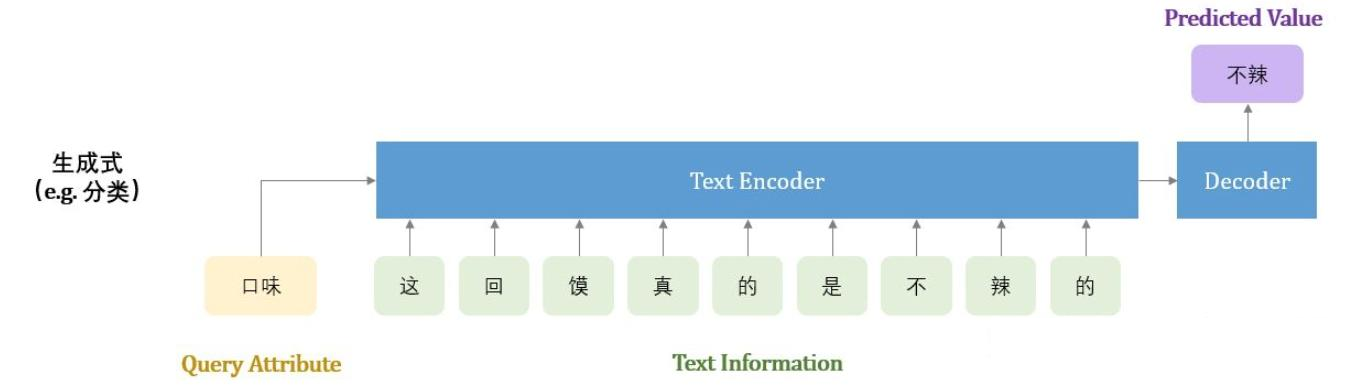
该方法的特点:可以预测不在文本中出现的属性值;只能预测可枚举的高频属性,导致很多属性值不可获取;预测出来的属性值没有可解释性。
拓展
关系抽取有pipline的解决方案,也有joint的方案。其中pipline的解决方法通常就是先抽取实体,然后再进行关系之间的抽取。而joint的方案则直接将实体以及实体之间的关系同时抽取处理。其中pipline的方式容易造成误差传播,实体识别的结果严重影响这关系抽取的结果。
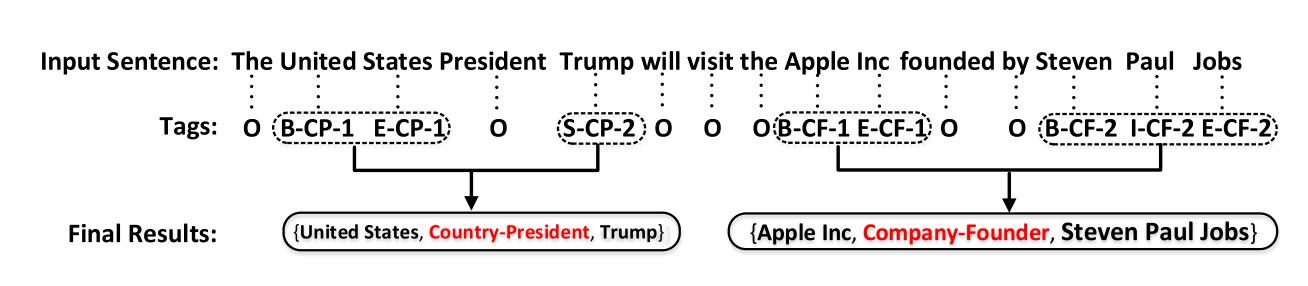
使用joint的实体、关系抽取也是可以使用序列标注的方法解决,这里需要关注如何设计标注的抽取的方式:Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. (ACL2017),该结构如下:
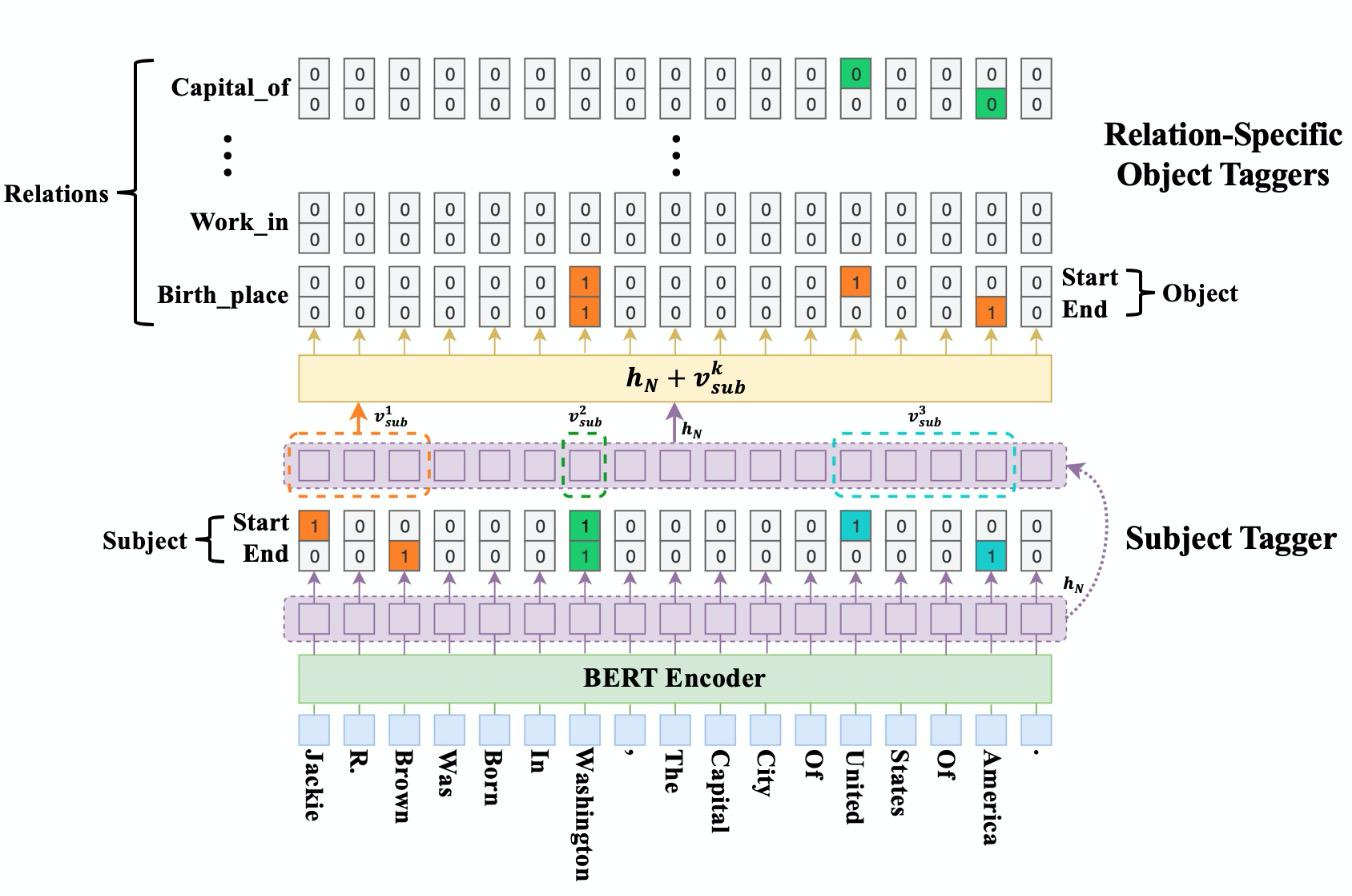
**现实的场景中还存在实体嵌套情况,那么针对这种情况该如何解决呢?**有学者提出级联三元组抽取的方法:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. (ACL2020),结构如下:
现实的场景中有些实体之间可能存在多种关系,传统的模型主要关注单标签的关系抽取,俺么该怎么办? 有学者提出了一种胶囊网络:Attention-based capsule networks with dynamic routing for relation extraction. (EMNLP2018),
结构如下:
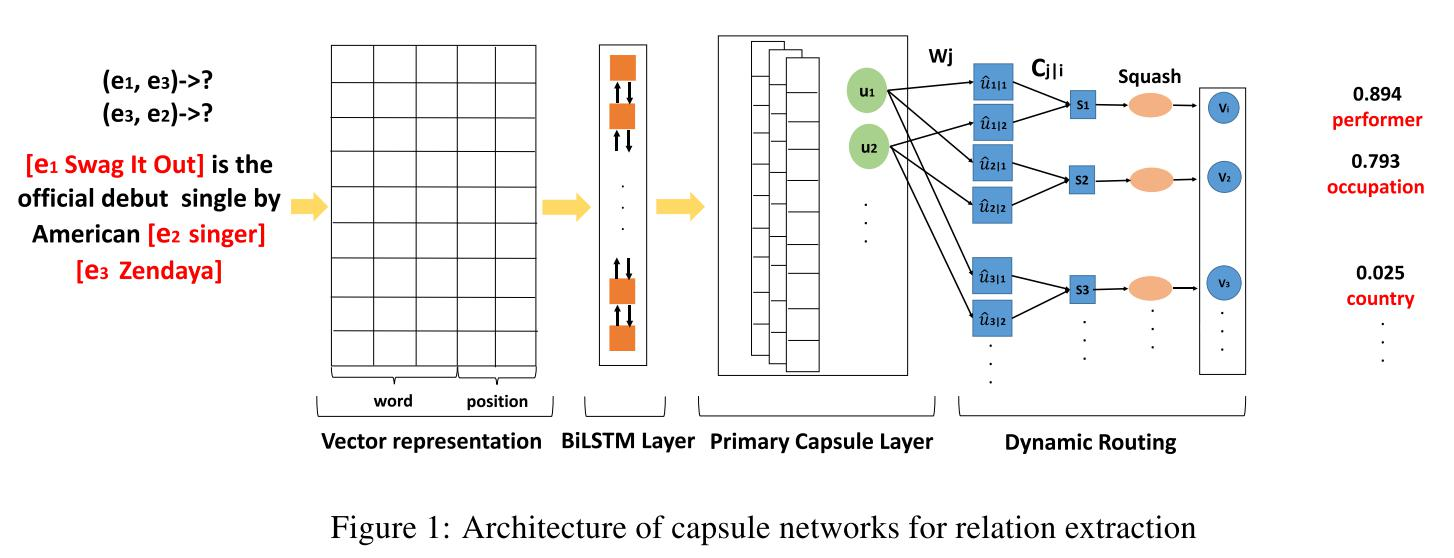
如图所示,模型首先通过预训练的 embedding 将句子中的词转化为词向量;随后使用BiLSTM 网络得到粗粒度的句子特征表示,再将所得结果输入到胶囊网络,首先构建出primary capsule,经由动态路由的方法得到与分类结果相匹配的输出胶囊。胶囊的模长代表分类结果的概率大小。
现实的场景中还存在多元的关系抽取,传统的关系抽取是抽取两个实体之间的关系,对于多元的实体如何抽取关系呢?
例如订购关系,其中包含:买家,卖家,商品 三个实体。有学者提出Graph LSTM:Cross-Sentence N-ary Relation Extraction with Graph LSTMs(TACL 2017),模型如下:
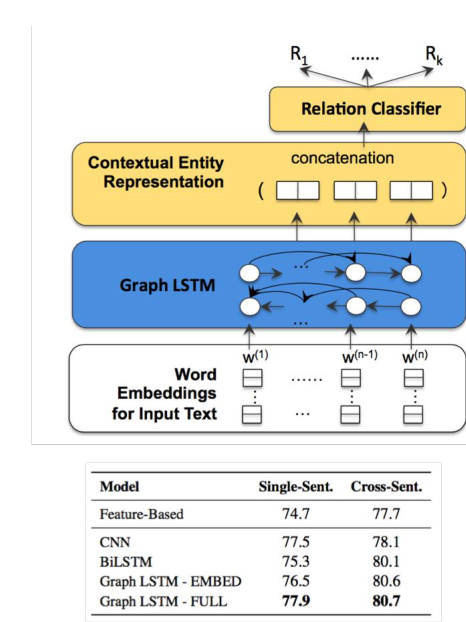
对于一些复杂的环境中,有些实体的关系是在多个句子中体现的,或者是在所篇章中体现的。这就引入了新的问题:跨句和篇章的关系抽取。有学者提出了对应的解决方案:Incorporating Relation Paths in Neural Relation Extraction(EMNLP 2017),如下:
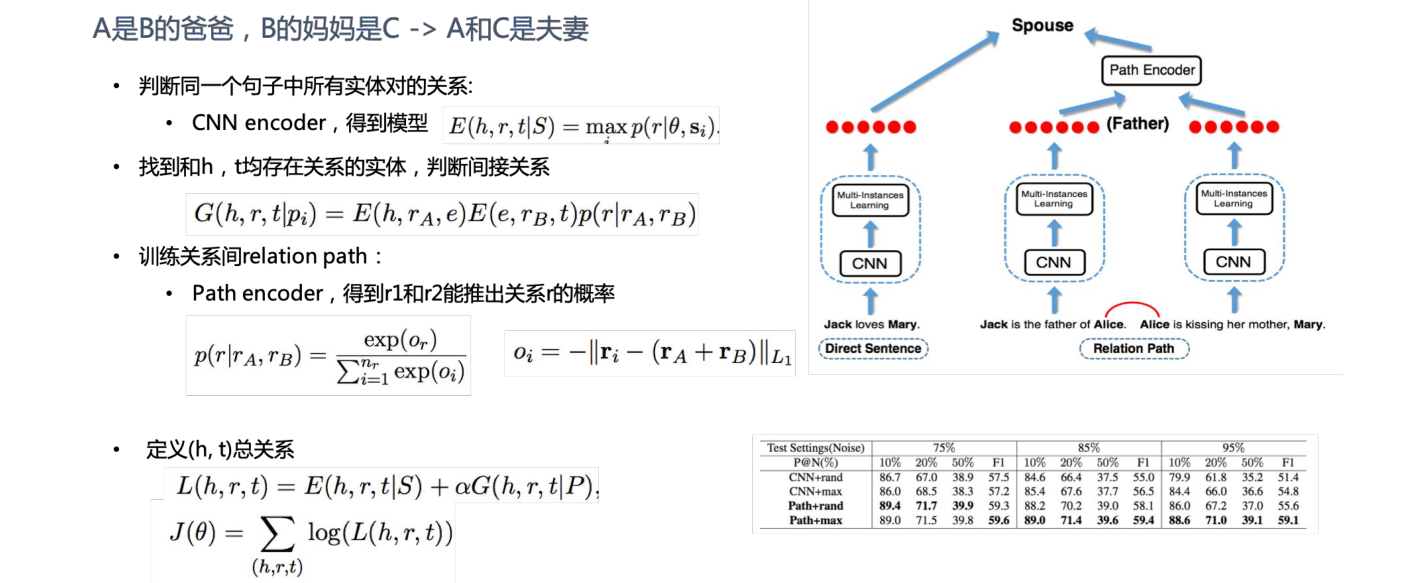
篇章级别的抽取问题相对复杂,难度也比较大。
概念抽取
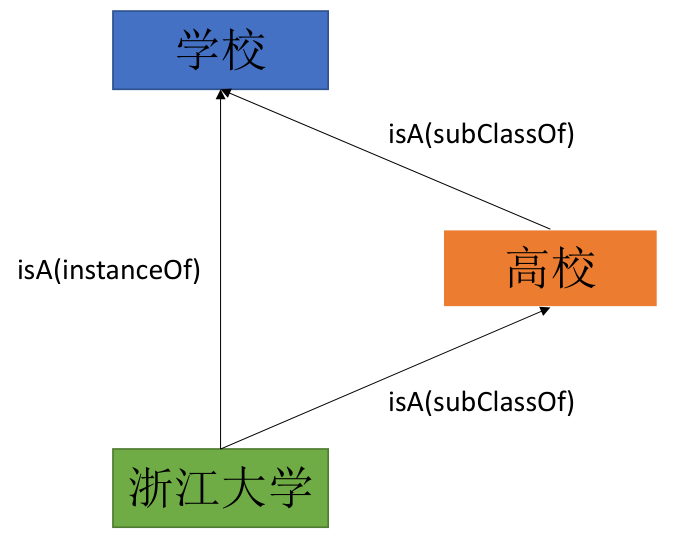
概念是人们把所感知的事物的共同本质特点抽象出来加一概括的表达。概念之间的关系有:isA关系、subclassOf。通常应用于本体构建。例如:
概念是认知的基石:人们可以通过概念认知同类实体,如昆虫这一概念使得我们能够认知各种各样的昆虫,无需纠缠细节的不同,概念也可以用于解释现象,如:遇到老虎为什么要跑?老虎是食肉动物。
实体与概念,概念与概念之间的关系属于自然语言处理中的语言上下位关系,如:A isA B,通常称A是B的下位词,B是A的上位词。
概念抽取并构建成无环图的过程又被称为Taxonomy。
概念抽取的几种方法

基于深度学习的方法通常将任务转换为序列标注任务进行解决。
概念知识的应用
概念知识可以帮助机器理解自然语言。如:
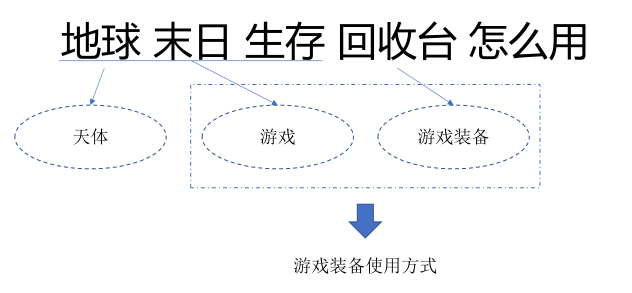
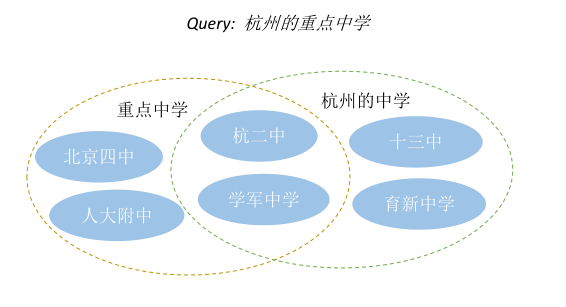
概念知识可以帮助理解搜索意图,获得更加准确的结果,如:
事件识别与抽取
事件又是一个哲学问题。在知识图谱中人们认为:事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。
其中:不同的动作或者状态的改变代表不同类型的事件;同一个类型的事件中不同的要素代表了不同的事件实例;同一个类型的事件中不同粒度的要素代表不同粒度的事件实例;

事件抽取。从无结构文本中自动抽取结构化事件知识:什么人/组织,什么时间,在什么地方,做了什么事。
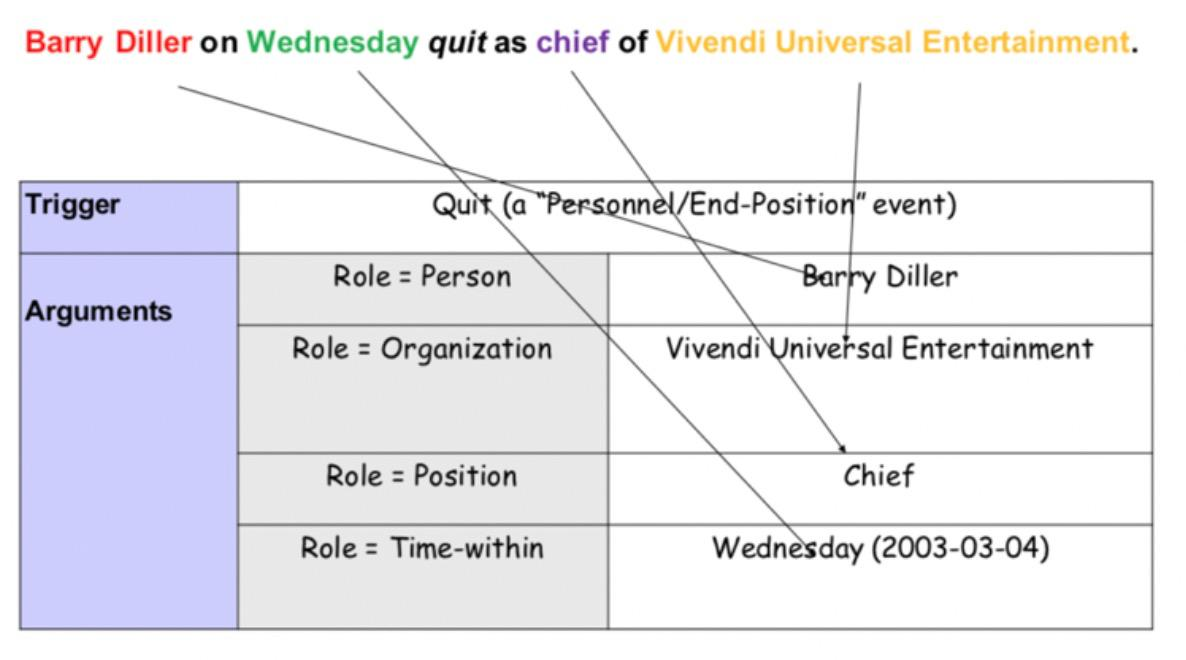
事件发现和分类。识别触发词(Trigger):体现发生事件的核心词语,比如这里的quit;分类事件类型(Event Type):比如“离职”事件。
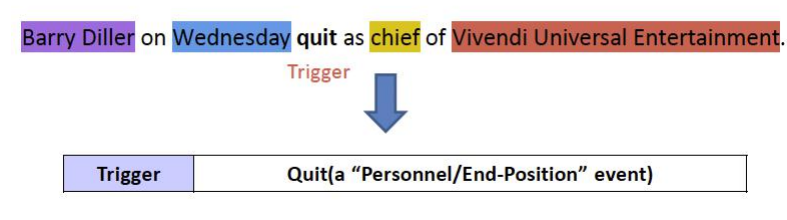
事件要素抽取。识别事件要素(Event Argument):参与事件的实体;分类要素的角色(Argument Role):参与事件的实体在事件所扮演的角色。
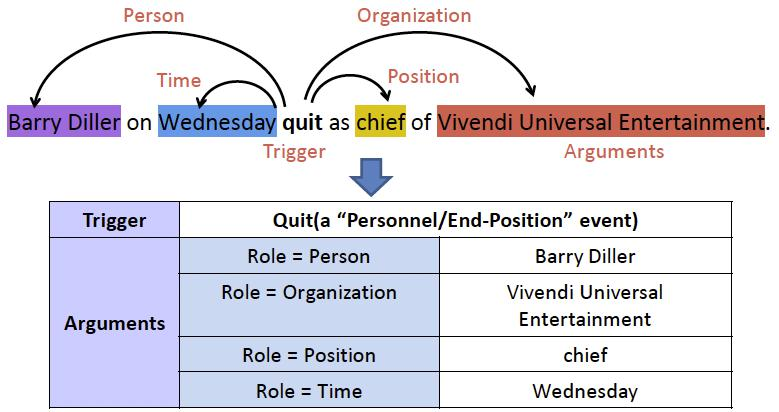
事件抽取方法
基于模式匹配的抽取方法
基于模式匹配的抽取方法是指对于某种类型的事件的识别和抽取是在一些模式的指导下进行的。模式匹配的过程就是事件识别和抽取的过程。一般可以分为两个步骤,以AutoSlog这个抽取系统为例:
首先包含两个假设:
- 事件元素首次提及之处即可确定该元素与事件间的关系
- 事件元素周围的语句中包含了事件元素在事件中的角色描述
然后通过句法分析和人工标注规则匹配的方式实现事件抽取。

基于人工标注语料的模式匹配:模板的产生完全基于人工标注语料,学习效果高度依赖于人工标注质量。为了进一步提升效果,人们提出基于弱监督的模式匹配。
基于弱监督的模式匹配:人工标注耗时耗力,且存在一致性问题;弱监督方法不需要对语料进行完全标注,只需要人工对语料进行一定的预分类或者知道种子模板,由机器根据分类语料或种子模板,自动进行模式学习。
以AutoSlog-TS系统为例,它不需要进行文本的标注,只需要一个预先分类的训练语料,类别是与该语料相关还是不相关,在抽取的过程中首先会过一遍语料库。对每一个名词短语根据句法分析产生抽取规则,然后再整体过一下语料库,产生每个规则的统计数据。根据在相关文本中更长出现的抽取规则,更有可能是最好的抽取规则,根据这一假设将规则进行筛选。基于弱监督的方法可以解决标注标准不一致的问题。同时也降低了模式获取的工作量。
其核心思想:在相关文本中更常出现的抽取规则更有可能是好的抽取规则

基于模式匹配的方法在特定领域中性能较好,便于理解和后续应用,但对于语言、领域和文档形式都有不同程度的依赖,覆盖度和可移植性较差;模式匹配的方法中,模板准确性是影响整个方法性能的重要因素,主要特点是高准确率低召回率。
基于机器学习的抽取方法
这里主要了解一下基于神经网络的事件抽取方法:DMCNN。模型结构如下:
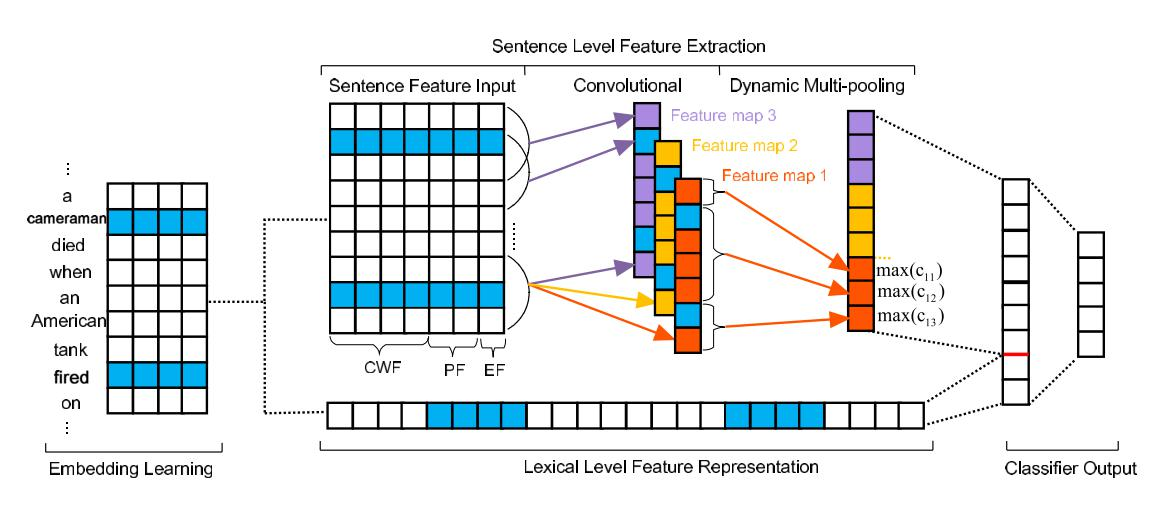
对应的论文是:Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. (ACL2015)。
它把事件抽取过程看作两阶段多分类任务。第一步是触发子分类,利用dmcnn对句子中的每个词进行分类,判断是否为触发词,如果句子中存在触发词则进行第二步的要素分类,同样是用dmcnn给触发词分配要素,同时匹配要素到角色。
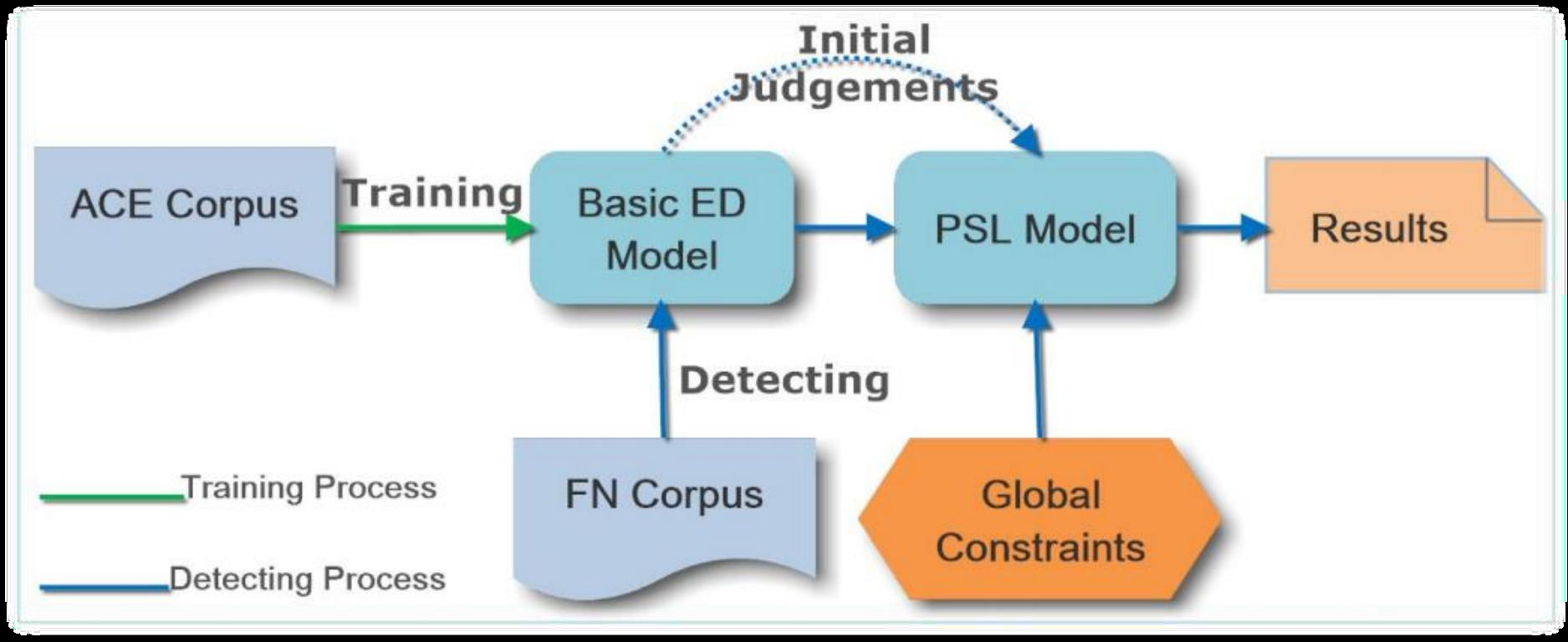
基于深度学的方法都有一个通病,就是需要大量的标注语料。于是有学者提出基于深度学习和弱监督的方法。例如:基于外部知识库的弱监督方法:Leveraging FrameNet to Improve Automatic Event Detection. (ACL 2016)。
其中:
- FrameNet是语言学家定义及标注的语义框架资源,采用层级的结构。
- FrameNet和事件抽取有着很高的相似性;
- ACE 语料训练的分类器去判定FrameNet中句子的事件类别,再利用全局推断将FrameNet的语义框架和ACE中的事件类别进行映射。
知识抽取的前沿技术
基于深度学习的知识抽取方法大多都依赖海量的标注数据。在真是的数据中,数据通常是长尾的,数据的标注成本也制约着模型的效果。知识抽取在少样本和零样本的场景下面临着严峻的挑战。例如:给定极少的包含某种关系的样本模型很难在测试集中识别出这一关系,且无法抽取不在训练集中的关系。
知识是不断更新的,我们也需要模型不断学习后抽取新的知识。然而模型在持续学习新知识抽取范式的时候,存在灾难性遗忘问题,这也衍生了一些需求:少样本知识抽取、零样本知识抽取、终生知识收取。
少样本知识抽取
人类可以根据很少的样本就能学习到知识。然而机器仍然需要大量的数据才能获得预测能力。那么如何让机器具备少样本学习能力就成了学者研究的重点。少样本学习的经典模型:
- N-way-K-shot
- 原型网络
原型网络:Prototypical networks for few-shot learning. (NeurIPS2017)
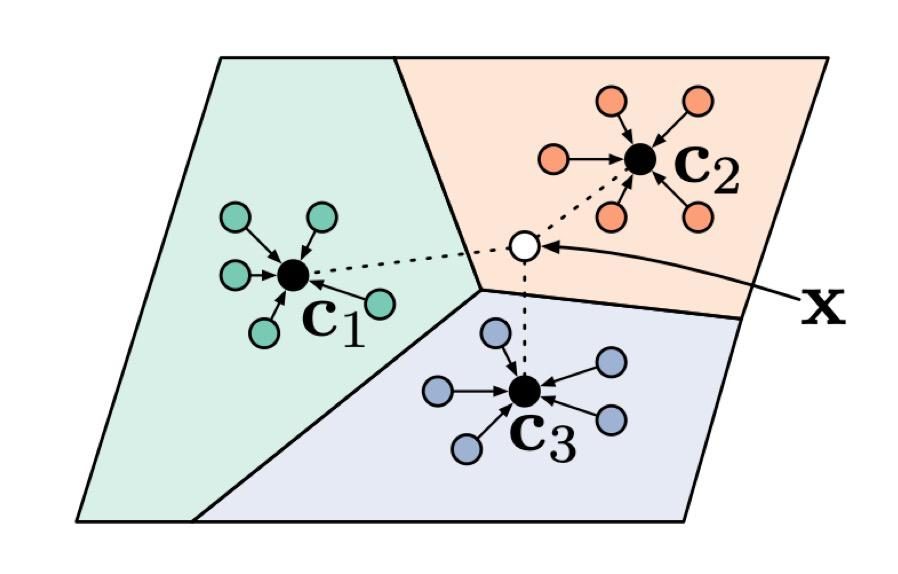
对于每个类别的若干样本,可以通过特征平均的方式取得每个类别的原型,对于未知的X,通过计算X与原型中心的距离,可以判断出它所属的类别。
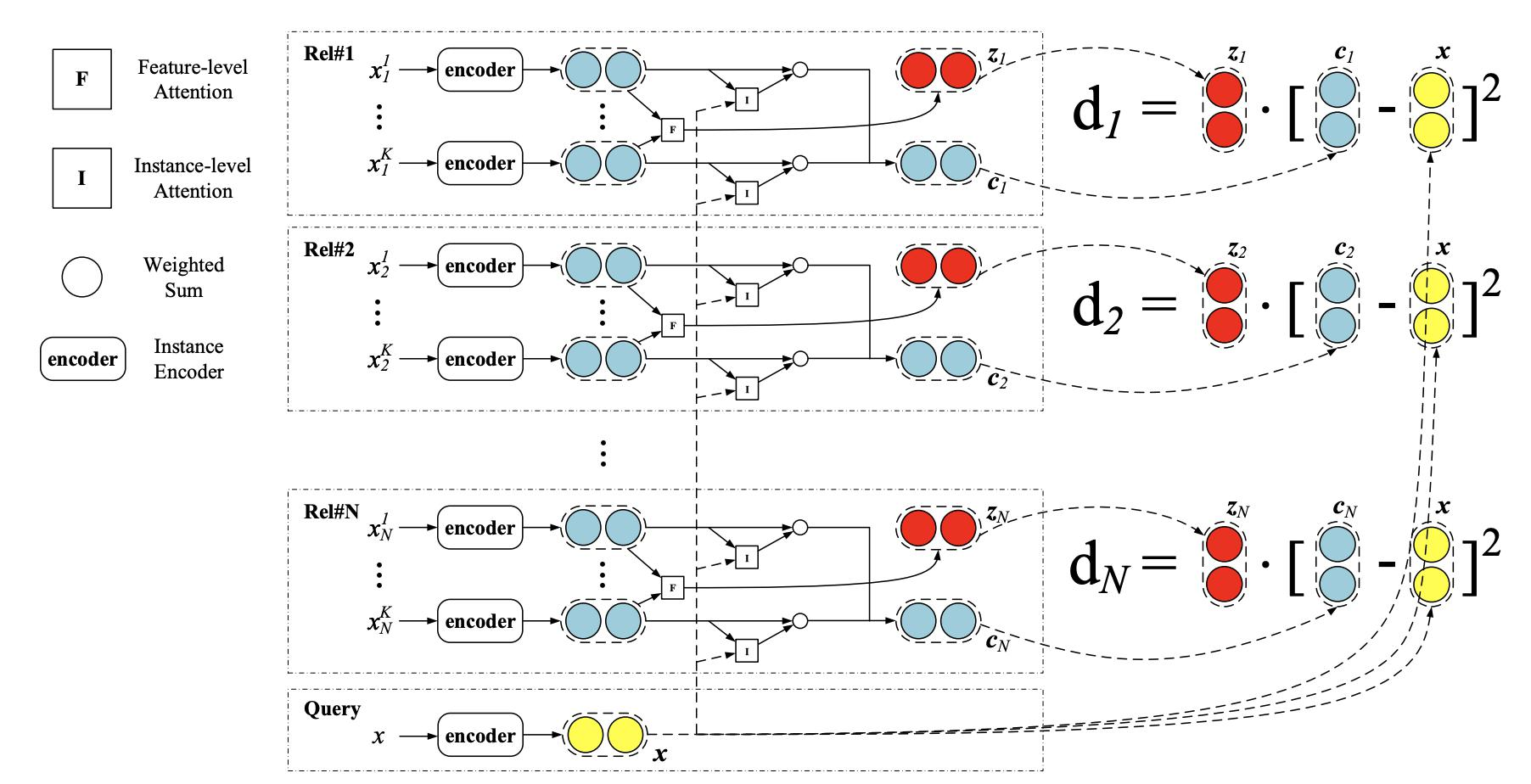
少样本问题的特性是容易受到噪声的干扰,因此有学者提出基于混合注意力的原型网络的少样本关系抽取模型。通过引入Instance-Level Attention和Feature-Level Attention减少原型计算的影响。Hybrid Attention-based Prototypical Networks for Noisy Few-Shot Relation Classification. (AAAI2019)
除此之外还有:基于实体关系原型网络的少样本知识抽取Bridging Text and Knowledge with Multi-Prototype Embedding for Few-Shot Relational Triple Extraction. (COLING2020),以进行三元组的抽取。
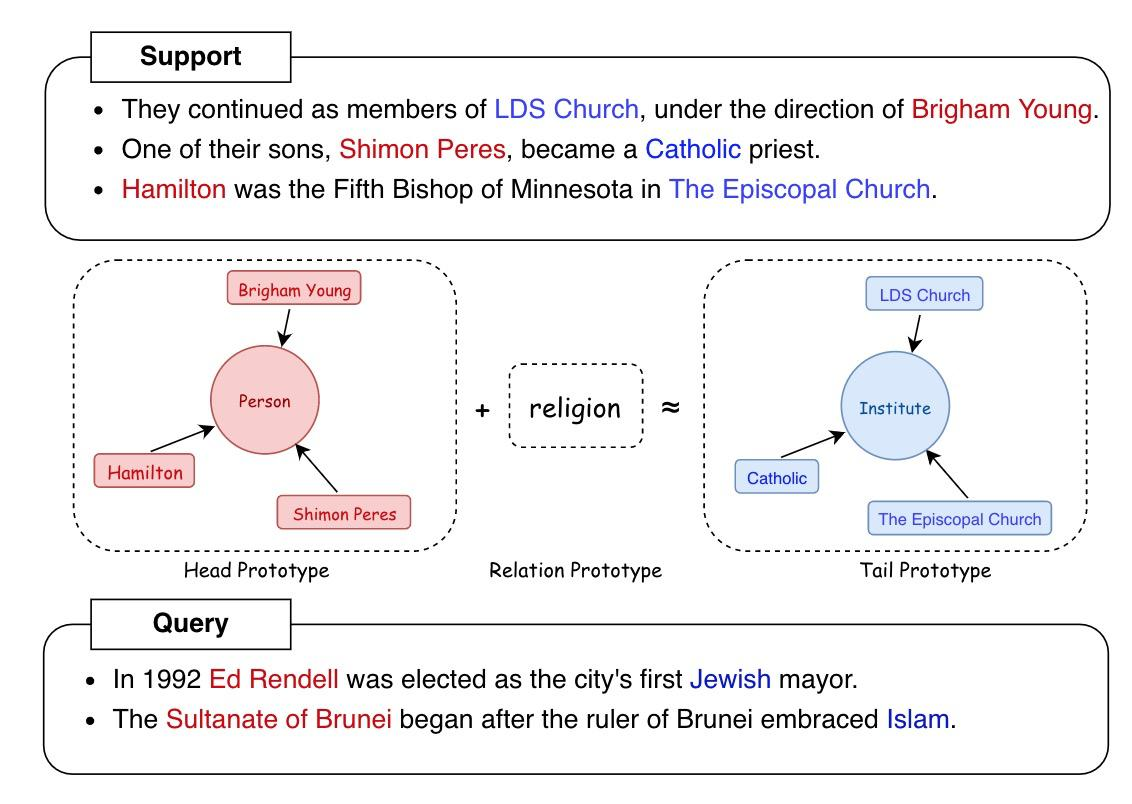
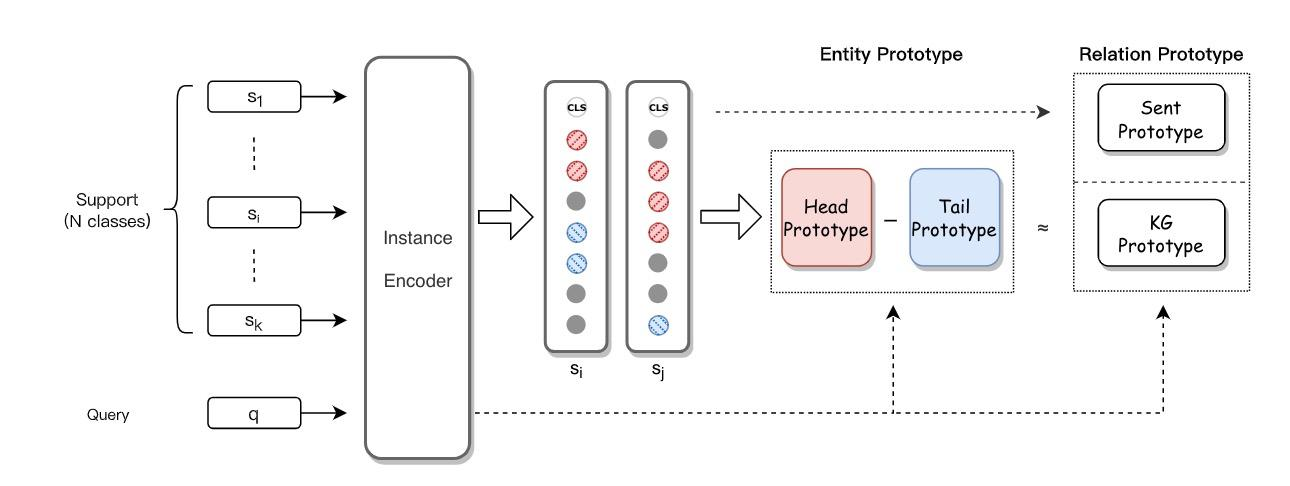
我们知道三元组的抽取包含实体以及实体之间的关系。显然就可以学习实体原型以及关系原型的方式,基于原型网络实现少样本知识获取。
零样本学习
零样本学习(zero short learning, zsl),基于可见标注数据集及可见标签集合,学习并预测不可见数据集结果.
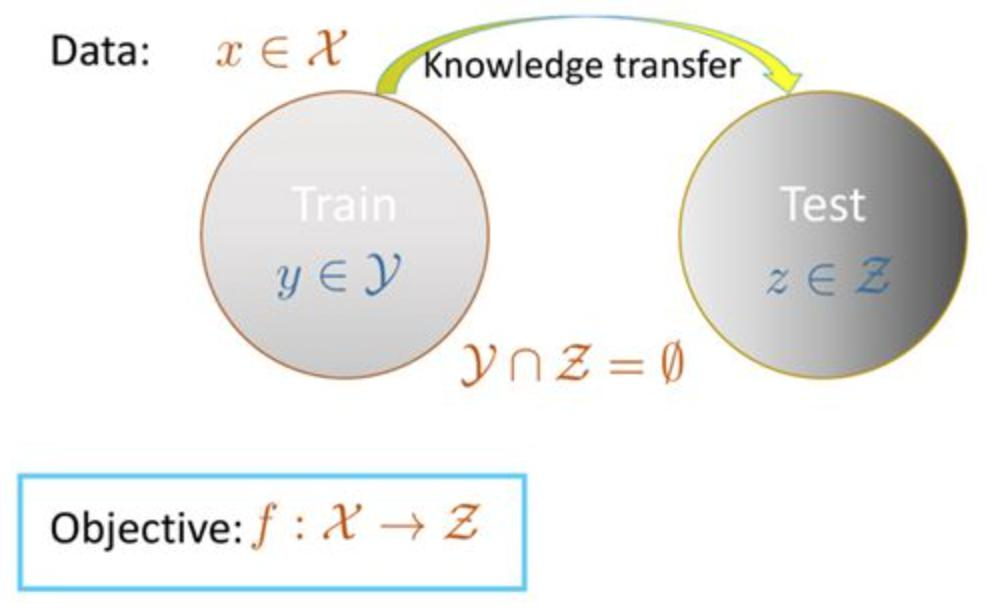
当前使用的主要方法有:转换问题设定,学习输入特征空间到类别描述的语义空间的映射。
基于阅读理解的零样本关系抽取:将零样本关系抽取问题转换成阅读理解,已知实体对中的一个实体以及它们之间的关系,去抽取另一个实体。Zero-Shot Relation Extraction via Reading Comprehension. (CONLL2017)

![[Linux理论基础1]----手写和使用json完成[序列化和反序列化]](https://img-blog.csdnimg.cn/7c48388057d349b3b443568051f6f8e7.png)







![[ 数据结构 ] 查找算法--------线性、二分、插值、斐波那契查找](https://img-blog.csdnimg.cn/img_convert/10bb5ebed35220bdf74e2cbb24f7205e.png)