数字三角形
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 32768K,其他语言65536K
64bit IO Format: %lld
题目描述
KiKi学习了循环,BoBo老师给他出了一系列打印图案的练习,该任务是打印用数字组成的数字三角形图案。
输入描述:
多组输入,一个整数(3~20),表示数字三角形边的长度,即数字的数量,也表示输出行数。
输出描述:
针对每行输入,输出用数字组成的对应长度的数字三角形,每个数字后面有一个空格。
示例1
输入
4
输出
1
1 2
1 2 3
1 2 3 4
示例2
输入
5
输出
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
#include <iostream>
using namespace std;
int main() {
int n;
while ((scanf("%d", &n)) != EOF) {
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
cout << j << " ";
}
cout << endl;
}
}
}多组输入,多组测试用例
有关多组输入,多组测试用例,只需要在代码的最外面嵌套一层while循环,while ((scanf("%d", &n)) != EOF)即可。这个while循环会一直执行,直到没有更多的输入(也就是遇到EOF,文件结束符)。scanf("%d", &n)用于从标准输入读取一个整数到变量n中。
代码对应实际意义
我们用for循环遍历次数,可以使用for(int i=0;i<n;i++)形式的代码,也可以使用for(int i=1;i<=n;i++)形式的代码,两段代码的相同点是,都会循环遍历执行n次,不同的是后者的i具有实际意义,表示此时正在输出三角形的第i行数据。
字符金字塔
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 32768K,其他语言65536K
64bit IO Format: %lld
题目描述
请打印输出一个字符金字塔,字符金字塔的特征请参考样例
输入描述:
输入一个字母,保证是大写
输出描述:
输出一个字母金字塔。
示例1
输入
C
输出
A
ABA
ABCBA
#include <iostream>
using namespace std;
int main() {
char ch;
cin >> ch;
int n = ch - 'A' + 1;
for (int i = 1; i <= n; i++) {
int x = n - i;
while (x--) {
cout << " ";
}
char char1;
for (int j = 1; j <= i; j++) {
char1 = 'A' + j - 1;
cout << char1;
}
char1--;
while (char1 != 'A' - 1) {
cout << char1;
char1--;
}
cout << endl;
}
}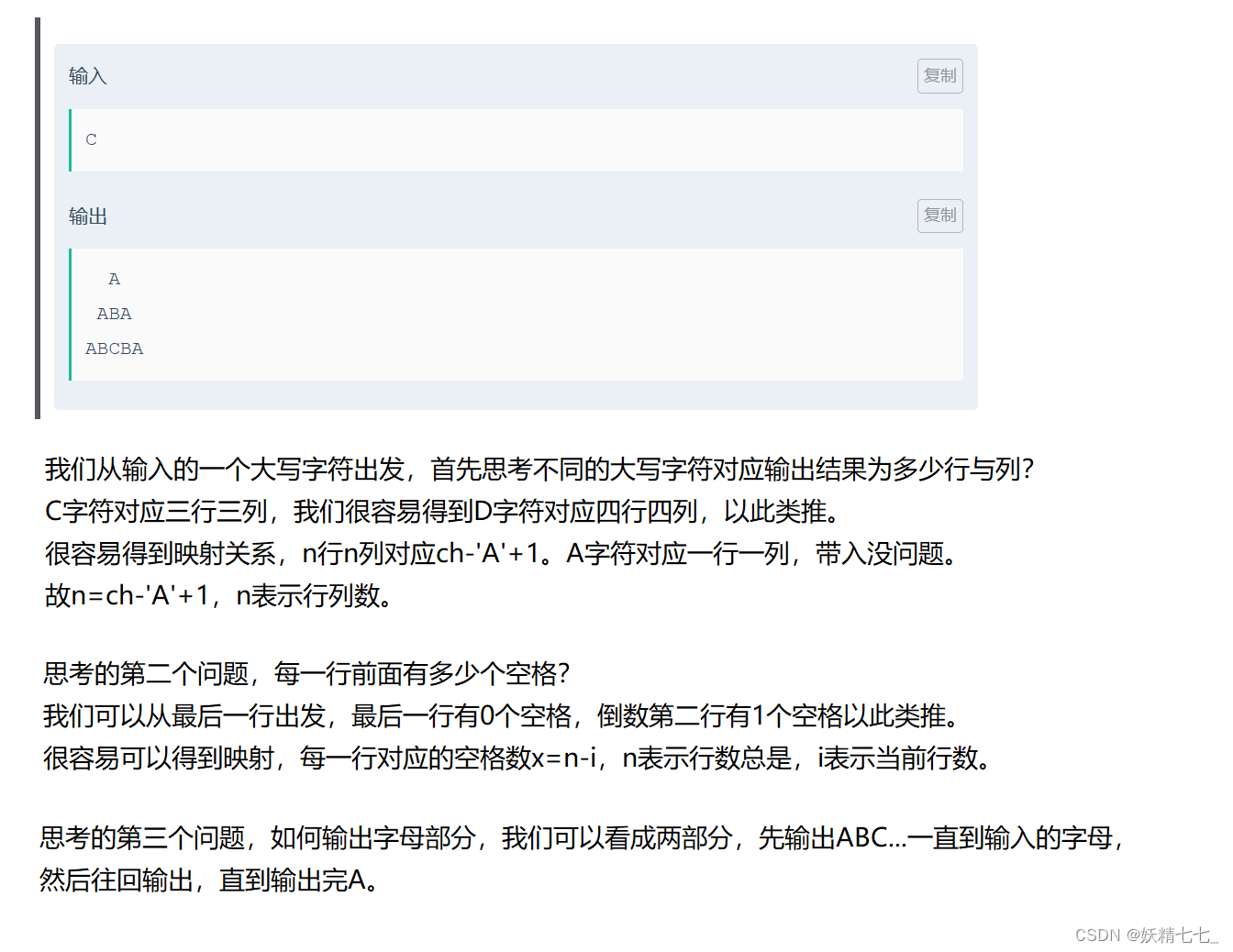
这段代码的主要功能是读取一个字符输入,然后基于这个字符(假设为大写字母),打印一个特定的字母图案。这个图案的形状是根据输入的字母来决定的,具体是一个以这个字母为顶点的金字塔形状。
char ch;声明一个char类型的变量ch,用于存储用户输入的字符。
cin >> ch;通过标准输入流cin读取用户输入的一个字符,并将其赋值给变量ch。
int n = ch - 'A' + 1;计算字符ch相对于'A'的位置,然后加1。这是因为如果输入为'A',我们想要n为1,表示金字塔的高度为1。
for (int i = 1; i <= n; i++) {这是一个循环,从1开始,直到n结束。i表示当前行。
int x = n - i;计算并存储当前行前需要打印的空格数。
int x = n - i;
while (x--) {
cout << " ";
}使用一个临时变量temp,通过一个while循环打印出每行前的空格。
char char1;
for (int j = 1; j <= i; j++) {
char1 = 'A' + j - 1;
cout << char1;
}在打印完空格后,这个循环打印从'A'开始的字符,直到当前行i指定的字符。当前是第i行,从A开始打印i个数据即可。
char1--;减少char1的值,准备反向打印字符。
while (char1 != 'A' - 1) { cout << char1; char1--; }
这个循环反向打印字符,直到'A'之前的字符,这样就完成了一行的字符打印。
cout << endl;每打印完一行后,输出一个换行符,为打印下一行做准备。
时间复杂度和空间复杂度分析
时间复杂度: 对于这个程序,最内层的循环次数依赖于i的值,且每行字符的打印次数随i线性增加。因此,总的操作次数是一个关于n的平方级数(具体为n*(n+1)/2),即时间复杂度为O(n^2)。
空间复杂度: 程序使用了固定数量的变量(ch, n, i, x, temp, char1),不依赖于输入大小。因此,空间复杂度为O(1),即常量空间。
牛牛学数列3
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 32768K,其他语言65536K
64bit IO Format: %lld
题目描述
牛牛准备继续进阶,计算更难的数列
输入一个整数n,计算 1+1/(1-3)+1/(1-3+5)+...+1/(1-3+5-...((-1)^(n-1))*(2n-1))的值
输入描述:
输入一个整数
输出描述:
输出一个浮点数,保留3位小数
示例1
输入
1
输出
1.000
#include <iostream>
#include <iomanip> // 需要包含这个头文件来使用setprecision
using namespace std;
int main() {
int n;
cin >> n;
double sum = 0;
double fm = 1;
double nextfm = 1;
int flag = 1;
for (int i = 1; i <= n; i++) {
fm = nextfm;
sum += 1 / fm;
flag = -flag;
nextfm = fm + (2 * (i + 1) - 1) * flag;
}
cout << setprecision(3) << sum;
}
//5---0.783
//6---0.617
这段代码主要用于计算和打印出一个特定序列的前n项和,其中n是用户输入的。这个序列的特点是分母交替增加一个奇数然后减去一个奇数。
int n;声明一个整型变量n,用于存储用户输入的序列长度。
cin >> n;通过标准输入流cin读取用户输入的整数,将其赋值给变量n。
double sum = 0;声明并初始化一个double类型的变量sum,用于累加序列的各项值。
double fm = 1;声明并初始化一个double类型的变量fm,表示当前项的分母。初始化为1,因为序列的第一项分母是1。
double nextfm = 1;声明并初始化一个double类型的变量nextfm,用于计算下一项的分母。
int flag = 1;声明并初始化一个整型变量flag,初始值为1。这个变量用于控制分母增加或减去的奇数值的正负,以实现交替变化。
for (int i = 1; i <= n; i++) {开始一个循环,从1迭代到n。循环的每一次迭代计算序列的一个项。n表示有n个数字,i表示当前是第i个数。
fm = nextfm;将nextfm的值赋给fm,准备计算当前项的值。
sum += 1 / fm;将当前项的值(1除以fm)加到sum上。
flag = -flag;将flag的值取反,使得下一次分母的变化方向相反。
nextfm = fm + (2 * (i + 1) - 1) * flag;计算下一项的分母,根据flag的值增加或减去一个奇数。这里的奇数是通过2 * (i + 1) - 1计算得到,确保每次都是奇数。
cout的精度设置
cout << setprecision(3) << sum;使用setprecision(3)设置下一个输出的数精度为3,使用setprecision需要包#include <iomanip>的头文件。
时间复杂度和空间复杂度分析
时间复杂度: 这个程序的执行时间主要取决于外层循环的迭代次数,即用户输入的n。因此,时间复杂度为O(n),表示随着n的增加,所需的时间成线性增加。
空间复杂度: 程序使用了固定数量的变量(n, sum, fm, nextfm, flag),这些变量的总数不随输入的n变化。因此,空间复杂度为O(1),即常量空间。
[NOIP2018]标题统计
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 262144K,其他语言524288K
64bit IO Format: %lld
题目描述
凯刚写了一篇美妙的作文,请问这篇作文的标题中有多少个字符?
注意:标题中可能包含大、小写英文字母、数字字符、空格和换行符。统计标题字 符数时,空格和换行符不计算在内。
输入描述:
输入文件只有一行, 一个字符串s。
输出描述:
输出文件只有一行,包含一个整数,即作文标题的字符数(不含空格和换行符)。
示例1
输入
234
输出
3
说明
标题中共有 3 个字符,这 3 个字符都是数字字符。
示例2
输入
Ca 45
输出
4
说明
标题中共有 5 个字符,包括 1 个大写英文字母,1 个小写英文字母和 2 个数字字符,
还有 1 个空格。由于空格不计入结果中,故标题的有效字符数为 4 个。
备注:
规定|s|表示字符串s的长度(即字符串中的字符串中的字符和空格数)。
对于40%的数据,1≤|s|≤5,保证输入为数字符及行末换符。
对于80%的数据,1≤|s|≤5,输入只可能包含大、小写英文字母大、小写英文字母、数字符及行末换符。
对于100%的数据,1≤|s|≤5,输入可能包含大,输入可能包含大、小写英文字母写英文字母、数字符、空格和行末换符。
#include <iostream>
using namespace std;
int main() {
string str;
getline(cin, str);
int count = 0;
for (auto x : str) {
if (isalpha(x) || isdigit(x)) {
count++;
}
}
cout << count;
}cin和getline
在C++中,常见的读取数据的方式是使用cin和getline函数。这两种方式可以用于从控制台或文件中读取数据。
getline:
istream& getline ( istream &is , string &str , char delim );
istream& getline ( istream&is, string&str);
is 进行读入操作的输入流
str 存储读入的内容
delim 终结符
返回值
与参数is是一样的
功能
将输入流is中读到的字符存入str中,直到遇到终结符delim才结束。对于第一个函数delim是可以由用户自己定义的终结符;对于第二个函数delim默认为 '\n'(换行符)。
函数在输入流is中遇到文件结束符(EOF)或者在读入字符的过程中遇到错误都会结束。
在遇到终结符delim后,delim会被丢弃,不存入str中。在下次读入操作时,将在delim的下个字符开始读入。
示例一
#include <string>//getline包含在string头文件里
#include <iostream>
using namespace std;
int main()
{
string str;
getline(cin , str , '#');
char c = getchar();
cout << str << ' ' << c << endl;
return 0;
}控制台:
输入:aa#b
输出:aa b示例二
#include <string>//getline包含在string头文件里
#include <iostream>
using namespace std;
int main()
{
string line;
cout<<"Please enter a string:";
getline(cin,line,'#');
cout<<"The line you enter is:"<<line<<endl;
system("pause");
return 0;
}控制台
输入:Please enter a string:Nice to meet you!#Hello!
输出:The line you enter is:Nice to meet you!这里输入流实际上只读入了Nice to meet you!,#后面的Hello!并没有存放到line中(仍停留在输入缓冲区里)。而且这里把终止符设为#,你输入的时候就算输入几个回车换行也没关系,输入流照样会读入。
控制台
输入:Please enter a string:Nice to meet you!
Hello!
#
输出:The line you enter is:Nice to meet you!
Hello!
isalpha() 和 isdigit()
isalpha()
isalpha是一种函数:判断字符ch是否为英文字母,若为英文字母,返回非0(小写字母为2,大写字母为1)。若不是字母,返回0。在标准c中相当于使用“ isupper( ch ) || islower( ch ) ”做测试。
extern intisalpha(int c);判断字符c是否为英文字母,参数c为英文字母,返回非零值。
isdigit()
isdigit是计算机C(C++)语言中的一个函数,主要用于检查其参数是否为十进制数字字符。
int isdigit(int c);若参数c为阿拉伯数字0~9,则返回非0值,否则返回0。
时间复杂度和空间复杂度
时间复杂度: 时间复杂度为O(n),其中n是输入字符串的长度。这是因为我们需要遍历字符串一次来统计字母和数字的数量。
空间复杂度: 空间复杂度为O(1),因为我们只使用了固定的额外空间(count变量),不论输入字符串的长度如何,额外空间的使用量都保持不变。
[NOIP2003]乒乓球
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 131072K,其他语言262144K
64bit IO Format: %lld
题目描述
国际乒联现在主席沙拉拉自从上任以来就立志于推行一系列改革,以推动乒乓球运动在全球的普及。其中11分制改革引起了很大的争议,有一部分球员因为无法适应新规则只能选择退役。华华就是其中一位,他退役之后走上了乒乓球研究工作,意图弄明白11分制和21分制对选手的不同影响。在开展他的研究之前,他首先需要对他多年比赛的统计数据进行一些分析,所以需要你的帮忙。
华华通过以下方式进行分析,首先将比赛每个球的胜负列成一张表,然后分别计算在11分制和21分制下,双方的比赛结果(截至记录末尾)。
比如现在有这么一份记录,(其中W表示华华获得一分,L表示华华对手获得一分):
WWWWWWWWWWWWWWWWWWWWWWLW
在11分制下,此时比赛的结果是华华第一局11比0获胜,第二局11比0获胜,正在进行第三局,当前比分1比1。而在21分制下,此时比赛结果是华华第一局21比0获胜,正在进行第二局,比分2比1。如果一局比赛刚开始,则此时比分为0比0。
你的程序就是要对于一系列比赛信息的输入(WL形式),输出正确的结果。
输入描述:
每次输入包含若干行字符串(每行至多20个字母),字符串有大写的W、L和E组成。其中E表示比赛信息结束,程序应该忽略E之后的所有内容。
输出描述:
输出由两部分组成,每部分有若干行,每一行对应一局比赛的比分(按比赛信息输入顺序)。
第一部分是11分制下的结果;
第二部分是21分制下的结果,两部分之间由一个空行分隔。
示例1
输入
WWWWWWWWWWWWWWWWWWWW
WWLWE
输出
11:0
11:0
1:1
21:0
2:1
#include <iostream>
#include <string>
using namespace std;
void printScores(const string& records, int winScore) {
int scoreW = 0, scoreL = 0;
for (char record : records) {
if (record == 'W') scoreW++;
if (record == 'L') scoreL++;
if ((scoreW >= winScore || scoreL >= winScore) && abs(scoreW - scoreL) >= 2) {
cout << scoreW << ":" << scoreL << endl;
scoreW = 0;
scoreL = 0;
}
if (record == 'E') break;
}
cout << scoreW << ":" << scoreL << endl;
}
int main() {
string input, records;
while (getline(cin, input)) {
records += input;
if (input.find('E') != string::npos) break;
}
// 11分制的比分计算和输出
printScores(records, 11);
cout << endl; // 两部分之间的空行
// 21分制的比分计算和输出
printScores(records, 21);
return 0;
}定义printScores函数
void printScores(const string& records, int winScore) 定义了一个名为printScores的函数,该函数接收两个参数:records是一个对字符串的常量引用,存储比赛的胜负记录;winScore是一个整数,表示胜利所需的分数。
int scoreW = 0, scoreL = 0;在函数内部定义了两个整型变量scoreW和scoreL,初始值都为0,分别用来跟踪胜方和负方的得分。
for (char record : records) 使用基于范围的for循环遍历records字符串。每个字符(record)代表一次比赛的结果:'W'表示胜方胜利,'L'表示负方胜利。
if (record == 'W') scoreW++; if (record == 'L') scoreL++;如果字符是'W',胜方分数scoreW加一;如果字符是'L',负方分数scoreL加一。
if ((scoreW >= winScore || scoreL >= winScore) && abs(scoreW - scoreL) >= 2) 这里判断是否有一方已经赢得这一局:即一方的得分达到了winScore,并且两者得分之差至少为2。
cout << scoreW << ":" << scoreL << endl; scoreW = 0; scoreL = 0;如果满足胜利条件,则输出当前比分,并将两方得分重置为0,以便开始新一局的计分。
if (record == 'E') break;如果遇到字符'E',表示比赛结束,退出循环。 cout << scoreW << ":" << scoreL << endl;循环结束后,输出最后一局的比分(可能因为比赛提前结束而未达到胜利条件)。
main函数
string input, records;定义了两个字符串变量input和records。input用于读取一行输入,records用于累积存储所有比赛的胜负记录。
while (getline(cin, input)) 使用getline函数从标准输入读取一行数据,存储到input变量中。这个循环会一直执行,直到读取到包含字符'E'的输入,表示输入结束。
records += input; if (input.find('E') != string::npos) break;将输入的字符串追加到records字符串中。如果input中包含字符'E',则退出循环。 printScores(records, 11); cout << endl; printScores(records, 21);分别调用printScores函数两次,一次使用11分制计算并输出比分,另一次使用21分制计算并输出比分。两次输出之间插入一个空行作为分隔。
[NOIP2017]图书管理员
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 262144K,其他语言524288K
64bit IO Format: %lld
题目描述
图书馆中每本书都有一个图书编码,可以用于快速检索图书,这个图书编码是一个正整数。
每位借书的读者手中有一个需求码,这个需求码也是一个正整数。如果一本书的图书编码恰好以读者的需求码结尾,那么这本书就是这位读者所需要的。
小 D 刚刚当上图书馆的管理员,她知道图书馆里所有书的图书编码,她请你帮她写一个程序,对于每一位读者,求出他所需要的书中图书编码最小的那本书,如果没有他需要的书,请输出-1。
输入描述:
输入的第一行,包含两个正整数 n 和 q,以一个空格分开,分别代表图书馆里书的数量和读者的数量。
接下来的 n 行,每行包含一个正整数,代表图书馆里某本书的图书编码。
接下来的 q 行,每行包含两个正整数,以一个空格分开,第一个正整数代表图书馆里读者的需求码的长度,第二个正整数代表读者的需求码。
输出描述:
输出有 q 行,每行包含一个整数,如果存在第 i 个读者所需要的书,则在第 i 行输出第 i 个读者所需要的书中图书编码最小的那本书的图书编码,否则输出-1。
示例1
输入
5 5
2123
1123
23
24
24
2 23
3 123
3 124
2 12
2 12
输出
23
1123
-1
-1
-1
说明
第一位读者需要的书有 2123、1123、23,其中 23 是最小的图书编码。
第二位读者需要的书有 2123、1123,其中 1123 是最小的图书编码。
对于第三位,第四位和第五位读者,没有书的图书编码以他们的需求码结尾,即没有他们需要的书,输出-1。
备注:
对于 20%的数据,1 ≤ n ≤ 2。 另有 20%的数据,q= 1。
另有 20%的数据,所有读者的需求码的长度均为1。
另有 20%的数据,所有的图书编码按从小到大的顺序给出。
对于 100%的数据,1≤n ≤1,000,1 ≤ q ≤ 1,000,所有的图书编码和需求码均不超过 10,000,000。
#include <iostream>
#include <vector>
using namespace std;
// 检查num1是否以num2结尾
bool endsWith(int num1, int num2) {
while (num1 && num2) {
if (num1 % 10 != num2 % 10) return false;
num1 /= 10;
num2 /= 10;
}
return num2 == 0; // 如果num2已经减少到0,说明num1以num2结尾
}
int main() {
int n, m;
cin >> n >> m;
vector<int> bookCodes(n);
for (int& bookCode : bookCodes) {
cin >> bookCode;
}
while (m--) {
int length, requirement;
cin >> length >> requirement;
int minCode = -1; // 初始化为-1,表示没有找到
for (int bookCode : bookCodes) {
if (endsWith(bookCode, requirement) && (minCode == -1 || bookCode < minCode)) {
minCode = bookCode;
}
}
cout << minCode << endl;
}
return 0;
}endsWith函数
bool endsWith(int num1, int num2) 定义了一个名为endsWith的函数,用于检查num1是否以num2结尾。这个函数返回一个布尔值。
while (num1 && num2) { if (num1 % 10 != num2 % 10) return false; num1 /= 10; num2 /= 10; }在这个循环中,同时对num1和num2进行逐位比较。如果在任何时刻它们的个位数不相同,则说明num1不以num2结尾,函数返回false。随后,通过除以10操作移除它们的个位数,以便比较下一位。
return num2 == 0;如果num2减少到0,而num1还有剩余(或同时为0),则说明所有比较的位都相同,num1以num2结尾,函数返回true。
main函数
int n, m; cin >> n >> m;定义了两个整型变量n和m。n用于存储书籍编码的数量,m用于存储查询的数量。通过标准输入读取它们的值。
vector<int> bookCodes(n);定义了一个名为bookCodes的整型向量,大小为n,用于存储所有书籍的编码。
for (int& bookCode : bookCodes) { cin >> bookCode; }使用范围for循环读取n个书籍编码,存储到bookCodes向量中。
while (m--) 使用while循环处理每一个查询。每次循环开始时,m的值减1,当m减到0时停止循环。
int length, requirement; cin >> length >> requirement;在每次查询中,定义了两个变量length和requirement。length表示查询的书籍编码长度(这个版本的代码中未使用),requirement表示书籍编码必须以此数字结尾。
int minCode = -1;初始化minCode为-1,用于存储满足条件的最小书籍编码。-1表示尚未找到满足条件的编码。
for (int bookCode : bookCodes) { if (endsWith(bookCode, requirement) && (minCode == -1 || bookCode < minCode)) { minCode = bookCode; } }遍历所有书籍编码,使用endsWith函数检查每个编码是否以requirement结尾。如果是,并且是当前找到的最小编码,则更新minCode。
cout << minCode << endl;输出找到的最小编码。如果没有找到满足条件的编码,将输出-1。
结尾
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!