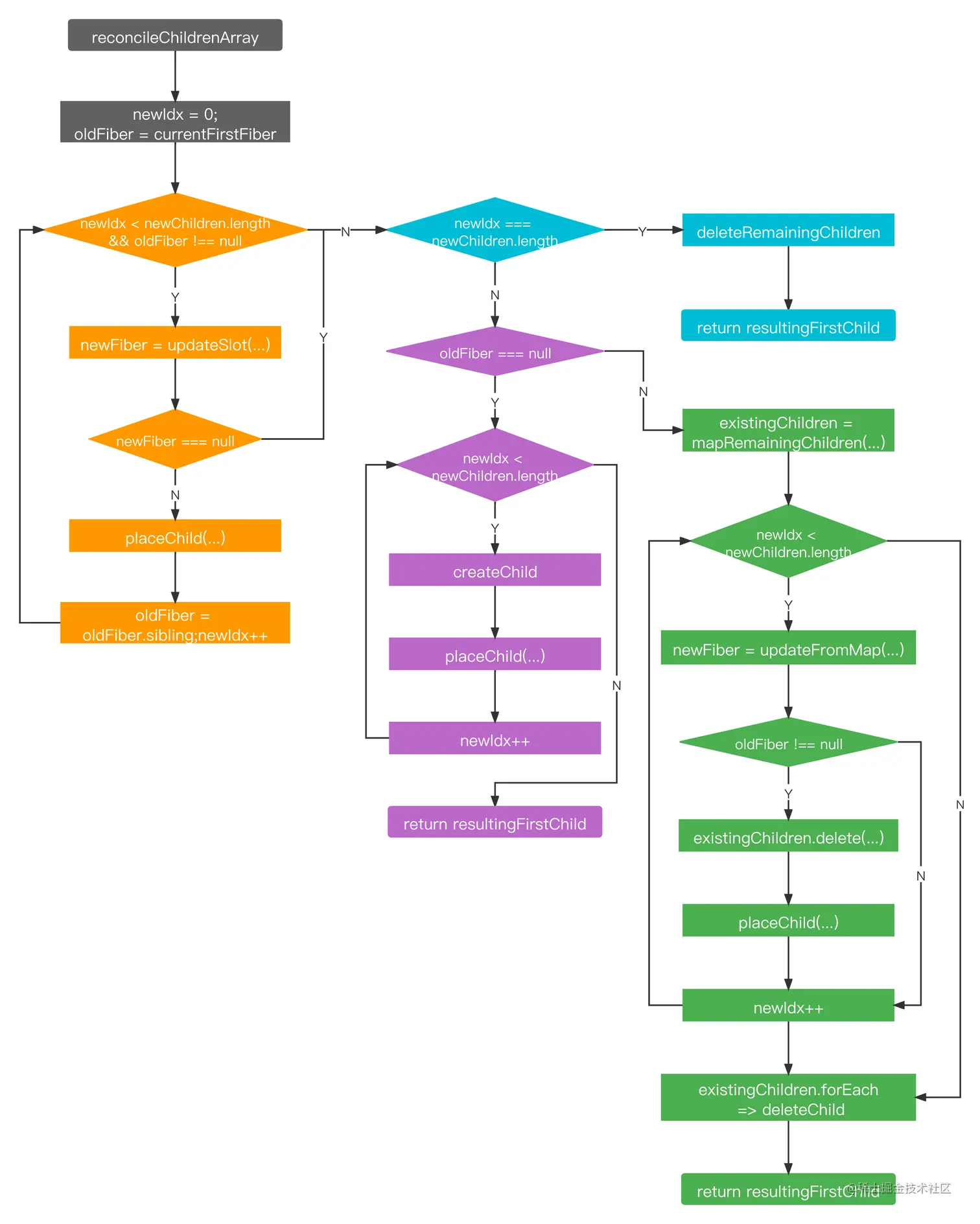
参考代码如下(从GitHub - luchangli03/export_llama_to_onnx: export llama to onnx修改而来,后面会合入进去)
模型权重链接参考:
https://huggingface.co/google/gemma-2b-it
可以对modeling_gemma.py进行一些修改(transformers升级为最新版本内置该模型代码),从而提升导出的onnx性能:
1,GemmaForCausalLM中原始的logits计算为:
hidden_states = outputs[0]
logits = self.lm_head(hidden_states)修改为:
hidden_states = outputs[0]
hidden_states = hidden_states[:,-1:,:]
logits = self.lm_head(hidden_states)这样使得降低prefill阶段lm_head的计算量。
2,模型使用了GemmaSdpaAttention,导出的onnx模型从一个很大的张量中索引向量仅仅用作attention mask:
causal_mask = attention_mask
if attention_mask is not None and cache_position is not None:
causal_mask = causal_mask[:, :, cache_position, : key_states.shape[-2]]
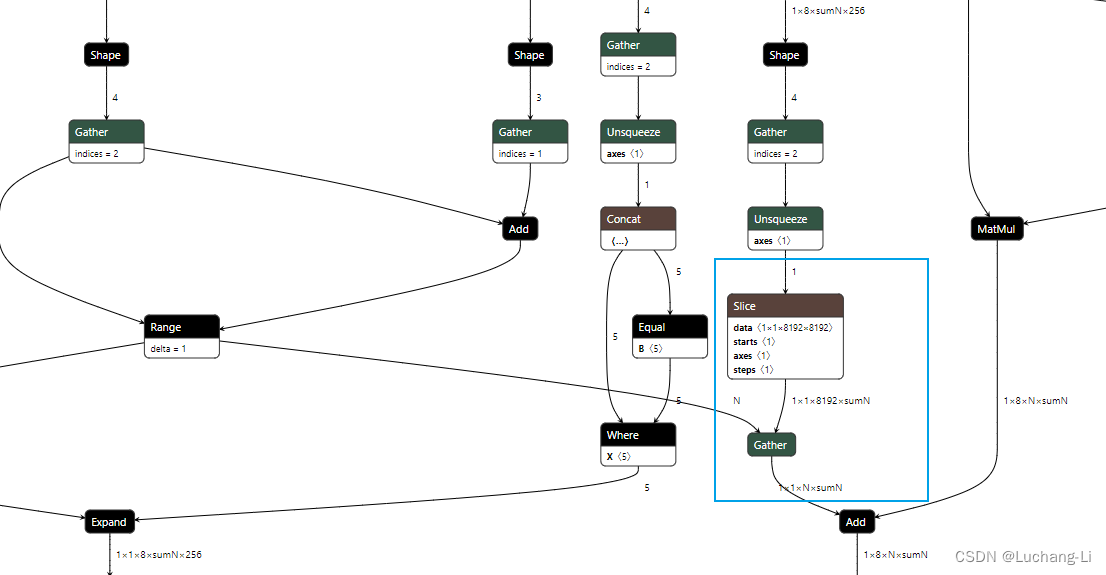
这里即增加了存储又增加了计算。实际上可以直接把扩展后的attention mask作为onnx输入传入进来,从而完全消除这个存储和计算。
不知为何很多模型(例如千问等)都输入一个[1, seq_len]的向量,然后内部扩展为一个[1,1, seq_len, sumN]的mask,这些操作都可以直接替换为模型直接采用[1,1, seq_len, sumN]的mask输入。
这里对modeling_gemma.py修改方法为:
class GemmaModel(GemmaPreTrainedModel):
def forward(
# causal_mask = self._update_causal_mask(attention_mask, inputs_embeds)
causal_mask = attention_mask
class GemmaSdpaAttention(GemmaAttention):
def forward(
# if attention_mask is not None and cache_position is not None:
# causal_mask = causal_mask[:, :, cache_position, : key_states.shape[-2]]
模型导出代码(进行了上述修改,如果不想修改的话,修改下这里面的atten mask的shape,dtype即可):
import os
import argparse
import torch
from torch import nn
from transformers import AutoModelForCausalLM, AutoTokenizer
class LLMForCausalLMWrapper(nn.Module):
def __init__(self, model, config, args):
super().__init__()
self.model = model
self.config = config
self.args = args
def forward(
self,
input_ids,
attention_mask,
position_ids,
past_key_values,
output_attentions=False,
output_hidden_states=False,
use_cache=True,
):
"""
Note: you can modify modeling_gemma.py to make the converted model more efficient:
hidden_states = outputs[0]
hidden_states = hidden_states[:,-1:,:]
logits = self.lm_head(hidden_states)
"""
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=None,
use_cache=True,
)
logits = outputs.logits
kv_caches_out = []
for past_kv in outputs.past_key_values:
kv_caches_out.extend(past_kv)
topk_outputs = []
if self.args.add_topk_warper > 0:
logging.warning("add topk to glm model")
if self.args.topk < 0:
raise ValueError("topk {} is invalid")
topk_outputs = torch.topk(logits, k=self.args.topk, dim=-1)
return logits, *kv_caches_out, *topk_outputs
def export_llm_to_single_onnx(model, config, dtype, args, model_name):
llama_model_wrapper = LLMForCausalLMWrapper(model, config, args)
onnx_file_name = os.path.join(args.out_dir, f"{model_name}.onnx")
layer_num = len(model.model.layers)
hidden_size = config.hidden_size
head_num = config.num_attention_heads
head_dim = config.head_dim
batch = 1
N = 1
sumN = 32
lastSum = sumN - N
input_ids_shape = [batch, N]
input_ids = torch.ones(input_ids_shape, dtype=torch.int64).to(args.device)
# Note: orig atten_mask shape is [1, sumN]
attention_mask = torch.randn([batch, 1, N, sumN], dtype=dtype).to(args.device)
position_ids = torch.ones([batch, N], dtype=torch.int64).to(args.device)
in_names = ["input_ids", "attention_mask", "position_ids"]
dynamic_axes = {
'input_ids': {1: 'N', },
'attention_mask': {2: 'N', 3: 'sumN'},
"position_ids": {1: 'N', },
}
if args.dyn_batch:
dynamic_axes['input_ids'][0] = "batch"
dynamic_axes['attention_mask'][0] = "batch"
dynamic_axes['position_ids'][0] = "batch"
kv_caches_in = []
out_names = ["lm_logits"]
kv_cache_in_shape = [1, 1, lastSum, head_dim]
kv_cache_dyn_axes = {2: "sumN-N"}
if args.dyn_batch:
kv_cache_dyn_axes[0] = "batch"
past_key_values = []
for i in range(layer_num):
past_key_in = torch.randn(kv_cache_in_shape, dtype=dtype).to(args.device)
past_value_in = torch.randn(kv_cache_in_shape, dtype=dtype).to(args.device)
kv_caches_in.extend([past_key_in, past_value_in])
in_names.extend([f"past_key_in{i}", f"past_value_in{i}"])
out_names.extend([f"past_key{i}", f"past_value{i}"])
dynamic_axes[f"past_key_in{i}"] = kv_cache_dyn_axes
dynamic_axes[f"past_value_in{i}"] = kv_cache_dyn_axes
past_key_values.append((past_key_in, past_value_in))
input_datas = (input_ids, attention_mask, position_ids, past_key_values)
torch.onnx.export(
llama_model_wrapper,
input_datas,
onnx_file_name,
opset_version=args.opset,
do_constant_folding=True,
input_names=in_names,
output_names=out_names,
dynamic_axes=dynamic_axes,
)
def export_llama(args):
device = args.device
dtype_map = {
"float32": torch.float32,
"float16": torch.float16,
"bfloat16": torch.bfloat16,
}
dtype = dtype_map[args.dtype]
print(f"begin load model from {args.model_path}")
model = AutoModelForCausalLM.from_pretrained(
args.model_path, device_map=device, torch_dtype=dtype, trust_remote_code=True).eval()
# model.model.layers = model.model.layers[:1] # only export one layer for debug
print(f"finish load model from {args.model_path}")
config = model.config
print("config:", config)
print(f"begin export llm")
export_llm_to_single_onnx(model, config, dtype, args, "llm_onnx")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description='export llm',
)
parser.add_argument('-m', '--model_path', required=True, type=str)
parser.add_argument('-o', '--out_dir', required=False, type=str, default="")
parser.add_argument('--opset', required=False, type=int, default=15)
parser.add_argument('-d', '--device', required=False, type=str, choices=["cpu", "cuda"], default="cuda")
parser.add_argument('-p', '--dtype', required=False, type=str,
choices=["float32", "float16", "bfloat16"], default="float16")
parser.add_argument('--add_topk_warper', required=False, type=int, default=0)
parser.add_argument('--topk', required=False, type=int, default=4)
parser.add_argument('--dyn_batch', action='store_true')
args = parser.parse_args()
export_llama(args)
导出的onnx文件onnxsim:
GitHub - luchangli03/onnxsim_large_model: simplify >2GB large onnx model
导出的onnx模型推理示例(依赖文件在GitHub - luchangli03/export_llama_to_onnx: export llama to onnx)
import numpy as np
from onnx_rt_utils import OnnxRuntimeModel, get_random_data
from sample_utils import sample_topk
from transformers import AutoTokenizer
def prepare_kv_cache_round0(glm_model_inputs, layer_num, lastSum):
"""
only used at the first time
in round 0, actually the lastSum is 0, thus past_key_in, past_value_in are empty tensor
"""
for i in range(layer_num):
past_key_in = get_random_data([1, 1, lastSum, 256], "float16")
past_value_in = get_random_data([1, 1, lastSum, 256], "float16")
past_key_in_name = f"past_key_in{i}"
past_value_in_name = f"past_value_in{i}"
glm_model_inputs[past_key_in_name] = past_key_in
glm_model_inputs[past_value_in_name] = past_value_in
return glm_model_inputs
def prepare_kv_cache_from_outputs(glm_model_inputs, decoder_outputs, layer_num):
offset = 1
for i in range(layer_num):
past_key_in_name = f"past_key_in{i}"
past_value_in_name = f"past_value_in{i}"
glm_model_inputs[past_key_in_name] = decoder_outputs[offset + i * 2]
glm_model_inputs[past_value_in_name] = decoder_outputs[offset + i * 2 + 1]
return glm_model_inputs
def get_atten_mask(N, sumN, padded_len):
attention_mask = np.zeros(shape=[N * padded_len], dtype="float16")
pad_num = padded_len - sumN
if (N == sumN):
for i in range(N):
mask_num = N - 1 - i + pad_num
start = padded_len - mask_num
for j in range(start, padded_len):
attention_mask[i * padded_len + j] = -65504
else:
if (N != 1):
raise ValueError("N is not 1")
lastSum = sumN - N
for i in range(pad_num):
attention_mask[lastSum + i] = -65504
attention_mask = attention_mask.reshape([N, padded_len])
return attention_mask
# all decoder layer num
layer_num = 18
eos_token_id = 2
pt_model_path = r"E:\test_models\llama\gemma-2b-it"
onnx_model_path = "llm_onnx.onnx"
prompt = "Write me a poem about Machine Learning."
tokenizer = AutoTokenizer.from_pretrained(pt_model_path, trust_remote_code=True)
input_ids = tokenizer(prompt)['input_ids']
print(input_ids)
input_ids = np.array(input_ids).reshape([1, -1]).astype("int64")
N = input_ids.shape[1]
sumN = N
lastSum = sumN - N
print("N:", N, sumN, lastSum)
position_ids = np.arange(sumN).reshape([1, -1]).astype("int64")
input_ids = input_ids.astype("int64")
position_ids = position_ids.astype("int64")
glm_model = OnnxRuntimeModel(onnx_model_path)
max_seq = 32
glm_model_inputs = {}
gen_tokens = []
for i in range(max_seq):
print("input_ids:", input_ids)
print("position_ids:", position_ids)
attention_mask = get_atten_mask(N, sumN, padded_len=sumN).astype("float16")
print("attention_mask:", attention_mask)
attention_mask = attention_mask.reshape([1, 1, N, sumN])
glm_model_inputs["input_ids"] = input_ids
glm_model_inputs["attention_mask"] = attention_mask
glm_model_inputs["position_ids"] = position_ids
if i == 0:
glm_model_inputs = prepare_kv_cache_round0(glm_model_inputs, layer_num, lastSum)
glm_model_outputs = glm_model(**glm_model_inputs)
lm_logits = glm_model_outputs[0]
print("lm_logits:", lm_logits)
next_token = sample_topk(lm_logits, topk=1)
gen_tokens.append(next_token)
print("next_token:", next_token)
if next_token == eos_token_id:
break
input_ids = np.array([next_token]).astype("int64").reshape([-1, 1])
position_ids = np.array([sumN]).astype("int64").reshape([-1, 1])
N = 1
sumN += 1
prepare_kv_cache_from_outputs(glm_model_inputs, glm_model_outputs, layer_num)
gen_text = tokenizer.decode(gen_tokens)
print("Q:", prompt)
print("A:", gen_text)