处理和上传大文件是Web开发中的常见挑战。一方面,我们需要确保应用的性能和响应性不被影响;另一方面,还要保证数据的安全性和完整性。接下来,我们将逐步探讨如何使用文件分片、Web Workers和SHA-256散列计算来解决这些问题。
问题引入:直接上传大文件的弊端
想象一下,当用户尝试上传一个几GB大小的视频文件时,直接上传可能会导致应用卡顿,且在网络不稳定的情况下容易上传失败,用户体验极差。此外,未对文件内容进行验证增加了数据损坏的风险。
思考:有没有更好的方法?
是的,这引出了我们的第一个解决方案:文件分片。通过将大文件切割成小的片段,我们可以逐个上传这些片段。这不仅可以有效管理网络资源,还能在上传过程中断时只重新上传未完成的片段,大大提高了效率和用户体验。我们可以有效地提高上传效率,减少失败的风险,并通过散列计算来验证数据的完整性。
如何在后台处理文件分片?
接下来,我们遇到了第二个问题:如何处理这些文件片段,而不阻塞用户界面?在JavaScript中,所有的文件处理操作默认都在主线程执行,这意味着在文件处理(特别是大文件)时,用户界面可能会出现卡顿。
幸运的是,HTML5引入了Web Workers,允许我们在后台线程中运行脚本,解决了UI阻塞的问题。但这如何实现呢?我们可以将文件分片和计算散列值的任务交给Web Worker,这样主线程就可以专注于处理用户交互,保持应用的响应性。
保证数据完整性的又一挑战:SHA-256散列计算
在文件分片上传的过程中,确保每个片段数据的安全性和完整性至关重要。传统的MD5散列计算已不再能满足安全需求,因此,我们选择使用更加安全的SHA-256散列算法。但这带来了一个新问题:如何在不影响性能的情况下计算每个文件片段的SHA-256散列值?
答案还是使用Web Workers。我们可以在Worker线程中为每个片段计算SHA-256散列值,这样即使是计算密集型的任务也不会影响主线程的性能。
实现步骤
Step 1: 文件分片
用户选择文件后,我们可以根据预设的分片大小,使用JavaScript将文件分割成多个片段。
const CHUNK_SIZE = 5 * 1024 * 1024; // 分片大小为5MB
let chunks = [];
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
let currentChunk = 0;
let file = document.getElementById('fileInput').files[0];
while (currentChunk < file.size / CHUNK_SIZE) {
let start = currentChunk * CHUNK_SIZE;
let end = Math.min(start + CHUNK_SIZE, file.size);
chunks.push(blobSlice.call(file, start, end));
currentChunk++;
}
Step 2: 使用Web Workers进行后台处理
为了不阻塞主线程,我们可以将分片处理和SHA-256散列计算的任务交给Web Worker。
// 主线程代码
let worker = new Worker('fileProcessorWorker.js');
worker.postMessage({chunks: chunks});
// Web Worker (fileProcessorWorker.js)
self.addEventListener('message', function(e) {
let chunks = e.data.chunks;
chunks.forEach(async (chunk) => {
// 对每个分片进行SHA-256计算
});
});
Step 3: 计算分片的SHA-256散列值
在Web Worker中,我们可以利用crypto.subtle.digest方法为每个分片计算SHA-256散列值。
async function calculateSHA256(chunk) {
const hashBuffer = await crypto.subtle.digest('SHA-256', chunk);
const hashArray = Array.from(new Uint8Array(hashBuffer));
const hashHex = hashArray.map(b => b.toString(16).padStart(2, '0')).join('');
return hashHex;
}
思考:如何证明主线程未被阻塞?
我们通过在界面上加入动画来直观地展示主线程的响应性。即使后台线程正在进行计算密集型的SHA-256散列计算,主线程的UI动画依然能够流畅运行,证明了我们的实现方法有效。
绝对可以。以下是在文章中讨论的技术方案的完整代码实现,供读者参考。
完整代码实现
HTML 文件 (index.html)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>大文件分片处理</title>
<script src="./spark-md5.min.js"></script> <!-- 假设使用SHA-256, 这里仅作示例 -->
<style>
.cube {
width: 50px;
height: 50px;
background-color: #3498db;
position: relative;
transform-style: preserve-3d;
animation: moveCube 1s linear infinite alternate;
}
@keyframes moveCube {
0% {
transform: translateX(0);
}
100% {
transform: translateX(100%);
}
}
</style>
</head>
<body>
分块大小:<span id="chunkSize"></span>
<input type="file" id="fileInput" multiple />
<button onclick="handleFiles()">处理文件</button>
<div class="cube"></div>
<script src="main.js"></script>
</body>
</html>
主线程 JavaScript 文件 (main.js)
const CHUNK_SIZE = 5 * 1024 * 1024; // 定义分片大小为5MB
let chunkSize = document.getElementById('chunkSize');
chunkSize.innerHTML = formatSizeUnits(CHUNK_SIZE);
// 格式化显示文件大小
function formatSizeUnits(bytes) {
if (bytes < 1024) return bytes + ' B';
else if (bytes < 1024 * 1024) return (bytes / 1024).toFixed(2) + ' KB';
else if (bytes < 1024 * 1024 * 1024) return (bytes / (1024 * 1024)).toFixed(2) + ' MB';
else return (bytes / (1024 * 1024 * 1024)).toFixed(2) + ' GB';
}
let fileInput = document.getElementById('fileInput');
function handleFiles() {
let files = fileInput.files;
if (files.length === 0) {
alert('请先选择文件');
return;
}
for (let i = 0; i < files.length; i++) {
processAllChunks(files[i], CHUNK_SIZE);
}
}
async function processAllChunks(file, chunkSize) {
// 分片逻辑省略,详见上文
}
Web Worker 文件 (worker.js)
// 导入spark-md5.min.js库以进行SHA-256计算,这里用于示例,实际应用中应该使用crypto API
importScripts('spark-md5.min.js'); // 假定更改为适合SHA-256的库
onmessage = function (event) {
const { file, totalChunks, chunkSize } = event.data;
// 分片处理和SHA-256散列值计算的逻辑,详见上文
};
请注意,这里的代码仅作为示例提供,并未包含所有细节。例如,processAllChunks函数和worker.js中的具体实现需要根据前文的描述进行完善。此外,原始代码示例中使用了spark-md5库进行MD5计算,但在实际实现中,你应使用Web Crypto API进行SHA-256计算,以确保数据的安全性和完整性。
偷懒想一键复制?
worker.js
// 导入 spark-md5.min.js 库以进行MD5计算
importScripts('spark-md5.min.js');
onmessage = function (event) {
const { file, totalChunks, chunkSize } = event.data;
let completedChunks = 0;
var startTime = new Date().getTime();
const processChunk = (currentChunk) => {
const start = currentChunk * chunkSize;
const end = Math.min(start + chunkSize, file.size);
const chunk = file.slice(start, end);
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = async function (e) { // 将事件处理器标记为async
try {
const data = e.target.result;
const hashHex = await calculateSHA256(data); // 等待异步SHA-256计算完成
resolve({
chunkIndex: currentChunk,
start,
end,
hashHex, // 使用计算得到的散列值
message: `Chunk ${currentChunk + 1}/${totalChunks} processed.`,
});
} catch (error) {
reject(error);
}
};
reader.onerror = () => reject(reader.error);
reader.readAsArrayBuffer(chunk);
});
};
async function calculateSHA256(data) {
const hashBuffer = await crypto.subtle.digest('SHA-256', data);
const hashArray = Array.from(new Uint8Array(hashBuffer)); // 转换为字节数组
const hashHex = hashArray.map(b => b.toString(16).padStart(2, '0')).join(''); // 转换为十六进制字符串
return hashHex;
}
const updateProgress = () => {
completedChunks++;
if (completedChunks === totalChunks) {
postMessage({ message: (new Date().getTime() - startTime)+'ms,All chunks processed.', allChunksProcessed: true });
}
};
const promises = Array.from({ length: totalChunks }, (_, i) => processChunk(i));
Promise.all(promises).then((results) => {
results.forEach((result) => {
// Ideally, instead of posting message for each chunk, aggregate results or update UI at key intervals
postMessage(result);
updateProgress();
});
}).catch((error) => {
postMessage({ error: error.message });
});
};
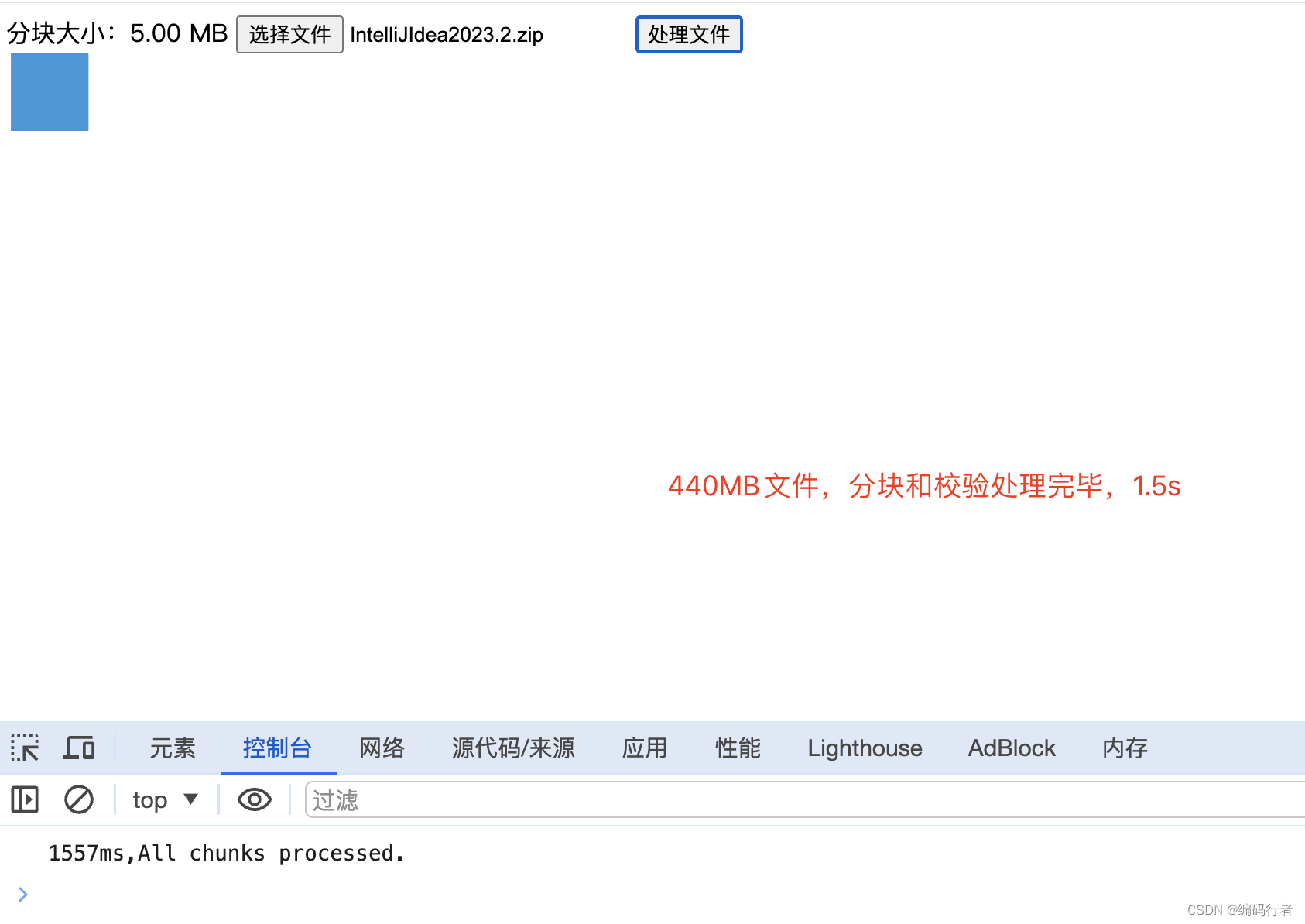
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>大文件分片处理</title>
<script src="./spark-md5.min.js"></script>
<style>
.cube {
width: 50px;
height: 50px;
background-color: #3498db;
position: relative;
transform-style: preserve-3d;
animation: moveCube 1s linear infinite alternate;
}
@keyframes moveCube {
0% {
transform: translateX(0);
}
100% {
transform: translateX(100%);
}
}
</style>
</head>
<body>
分块大小:<span id="chunkSize"></span>
<input type="file" id="fileInput" multiple />
<button onclick="handleFiles()">处理文件</button>
<div class="cube"></div>
<script>
const CHUNK_SIZE = 5 * 1024 * 1024;
let chunkSize = document.getElementById('chunkSize');
chunkSize.innerHTML = formatSizeUnits(CHUNK_SIZE);
// 格式化显示文件大小
function formatSizeUnits(bytes) {
if (bytes < 1024) {
return bytes + ' B';
} else if (bytes < 1024 * 1024) {
return (bytes / 1024).toFixed(2) + ' KB';
} else if (bytes < 1024 * 1024 * 1024) {
return (bytes / (1024 * 1024)).toFixed(2) + ' MB';
} else {
return (bytes / (1024 * 1024 * 1024)).toFixed(2) + ' GB';
}
}
let fileInput = document.getElementById('fileInput');
async function processAllChunks(file,chunkSize) {
const totalChunks = Math.ceil(file.size / CHUNK_SIZE);
const worker = new Worker('worker.js');
worker.postMessage({ file, totalChunks , chunkSize});
worker.onmessage = function (event) {
const chunkResult = event.data;
if(chunkResult['allChunksProcessed'] && chunkResult['message']){
console.log(chunkResult['message']);
}
// 在这里可以处理已经完成的分片数据,例如上传到服务器
// chunkResult 包含了分片的信息和处理后的数据
// chunkResult.data 就是分片的处理后的数据
};
worker.onerror = function (error) {
console.error('处理分片时发生错误:', error);
};
}
function handleFiles() {
let files = fileInput.files;
if (files.length === 0) {
alert('请先选择文件');
return;
}
for (let i = 0; i < files.length; i++) {
processAllChunks(files[i], CHUNK_SIZE);
}
}
</script>
</body>
</html>
总结
通过文件分片、后台计算和SHA-256散列值验证,我们不仅优化了大文件的处理和上传过程,还确保了数据的安全性和完整性。以上实现方式展示了现代Web技术如何解决传统问题,提升用户体验,同时保障数据处理的效率和安全。
希望这篇博客能够帮助你理解和实现在Web应用中处理大文件的最佳实践。







](https://img-blog.csdnimg.cn/direct/ed23e46ddb6140919ce24c611926718c.png)