文章目录
- 版权声明
- 修复问题
- 内存溢出问题分类
- 分页查询文章接口的内存溢出
- 问题背景
- 解决思路
- 问题根源
- 解决思路
- Mybatis导致的内存溢出
- 问题背景
- 问题根源
- 解决思路
- 导出大文件内存溢出
- 问题背景
- 问题根源
- 解决思路
- ThreadLocal占用大量内存
- 问题背景
- 问题根源
- 解决思路
- 文章内容审核接口的内存问题
- 问题背景
- 设计1:Async异步审核
- 存在问题
- 设计2:生产者消费者模式
- 存在问题
- 设计3:Mq消息队列模式
- 问题根源和解决思路
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。
- 本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
修复问题
内存溢出问题分类
- 修复内存溢出问题的要具体问题具体分析,问题总共可以分成三类
- 代码中的内存泄漏
- 解决方案:完善代码
- 并发引起内存溢出
- 参数不当 由于参数设置不当,比如堆内存设置过小,导致并发量增加之后超过堆内存的上限。
- 解决方案:调整参数,下一章中详细介绍
- 并发引起内存溢出 – 设计不当
- 系统的方案设计不当,比如:从数据库获取超大数据量的数据、线程池设计不当、生产者-消费者模型,消费者消费性能问题
- 解决方案:优化设计方案
分页查询文章接口的内存溢出
问题背景
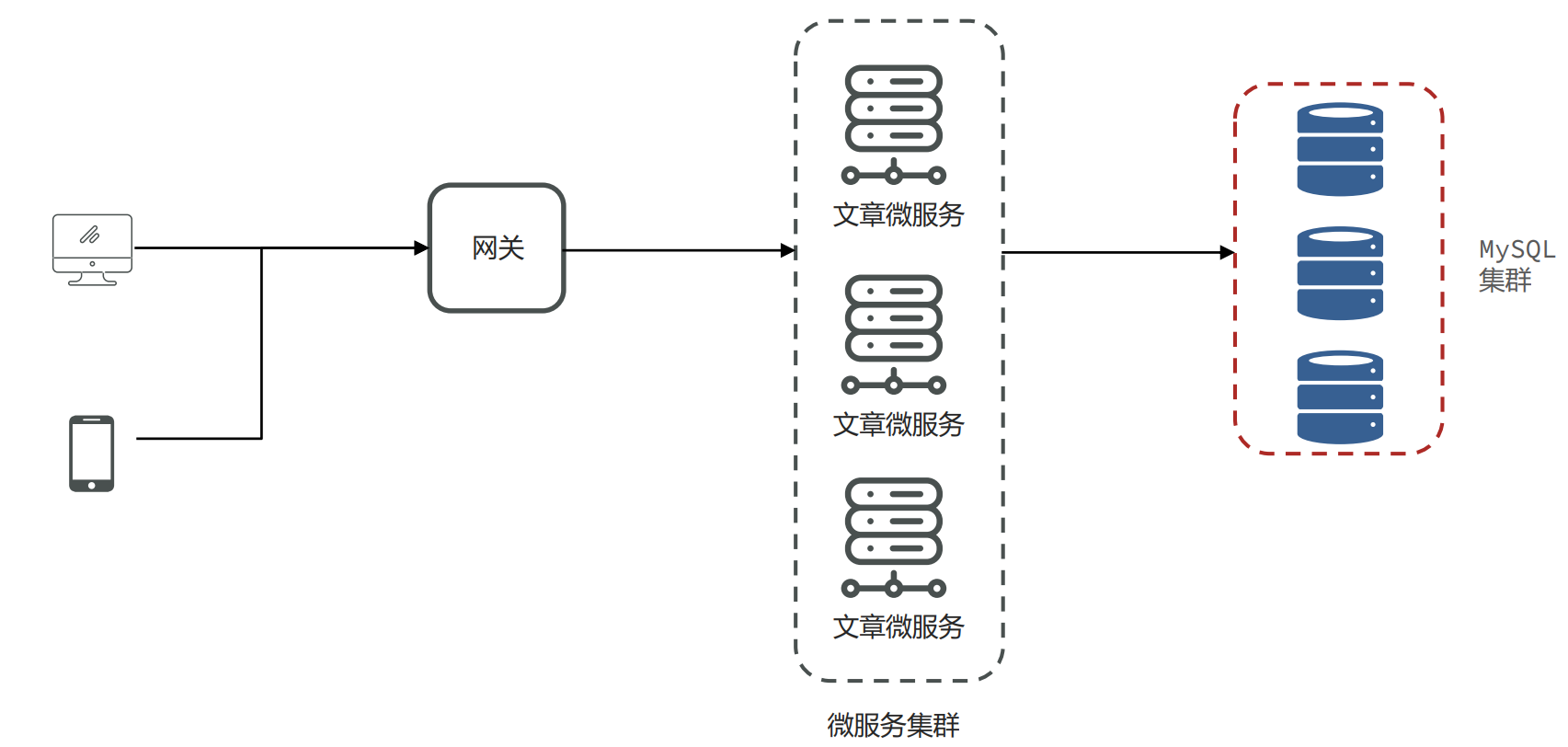
- 背景:小李负责的新闻资讯类项目采用了微服务架构,其中有一个文章微服务,这个微服务在业务高峰期出现内存溢出的现象
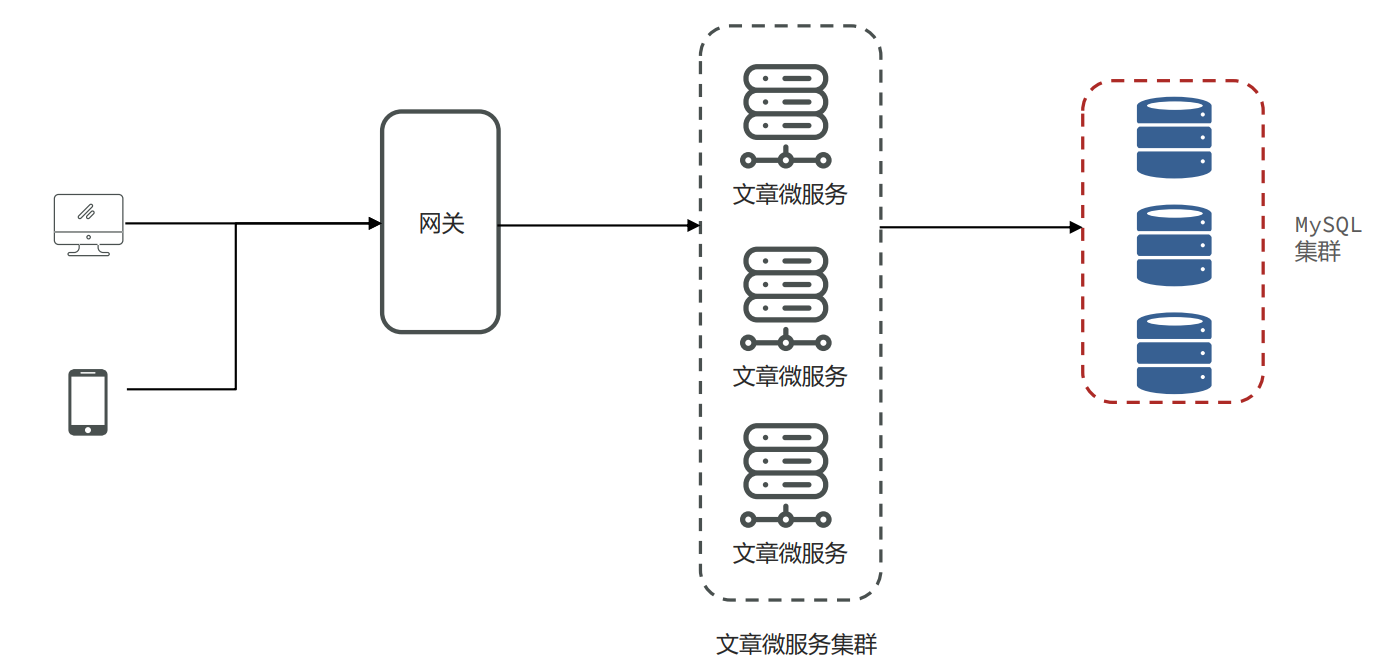
解决思路
- 服务出现OOM内存溢出时,生成内存快照
- 使用MAT分析内存快照,找到内存溢出的对象
- 尝试在开发环境中重现问题,分析代码中问题产生的原因
- 修改代码
- 测试并验证结果


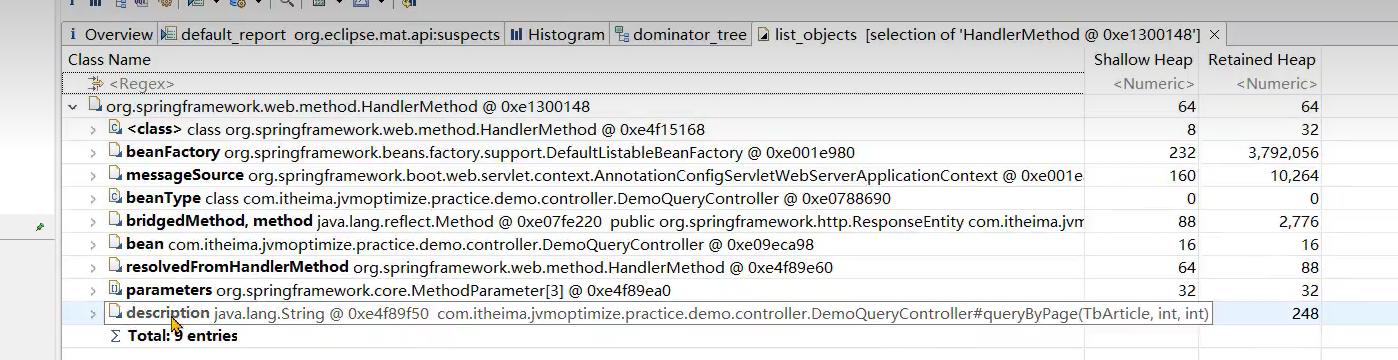
- MAT使用技巧:从线程对象入手,找到当前的处理器方法,再右键选择处理器方法的outgoing references,即可快速找到当前线程执行的方法。
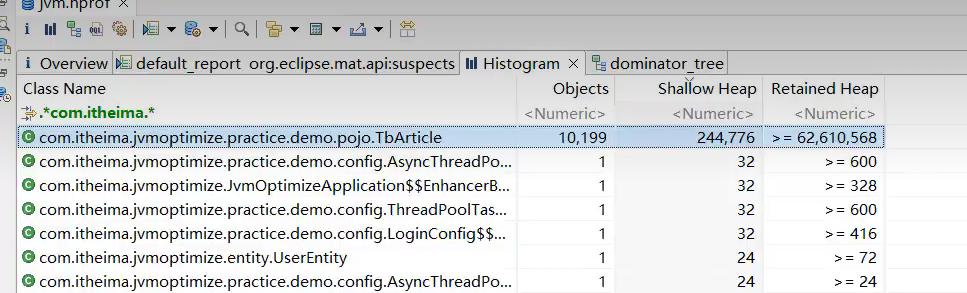
问题根源
- 文章微服务中的分页接口没有限制最大单次访问条数,并且单个文章对象占用的内存量较大,在业务高峰期并发量较大时这部分从数据库获取到内存之后会占用大量的内存空间。
解决思路
- 与产品设计人员沟通,限制最大的单次访问条数
- 分页接口如果只是为展示文章列表,不需要获取文章内容,可以大大减少对象的大小
- 在高峰期对微服务进行限流保护
Mybatis导致的内存溢出
问题背景
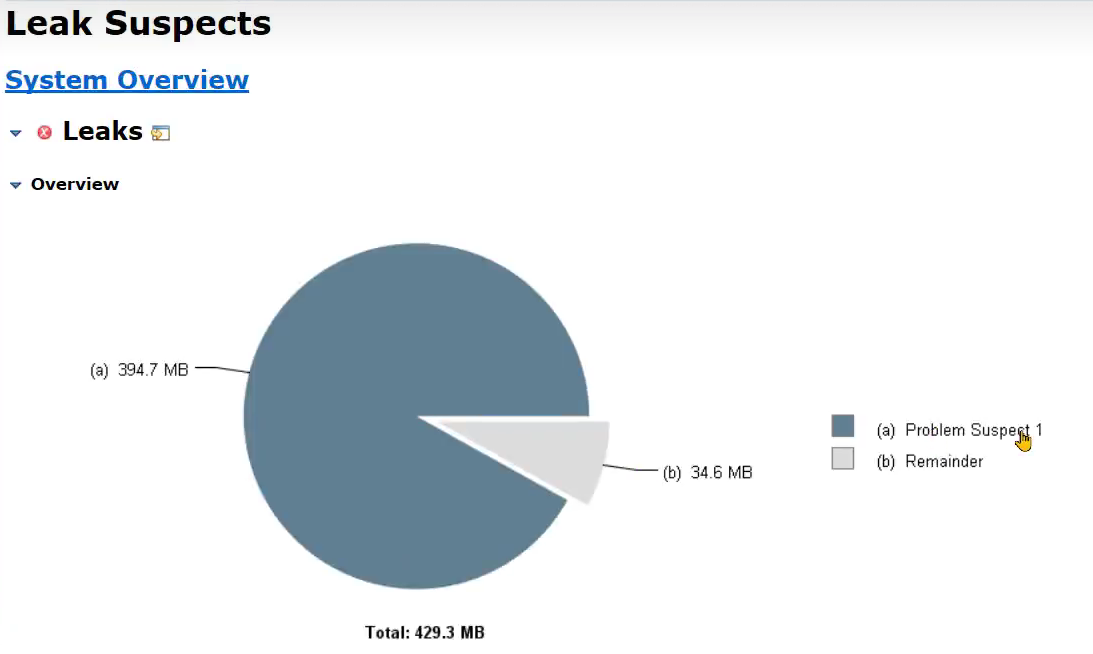
- 小李负责的文章微服务进行了升级,新增加了一个判断id是否存在的接口,第二天业务高峰期再次出现了内存溢出,小李觉得应该和新增加的接口有关系
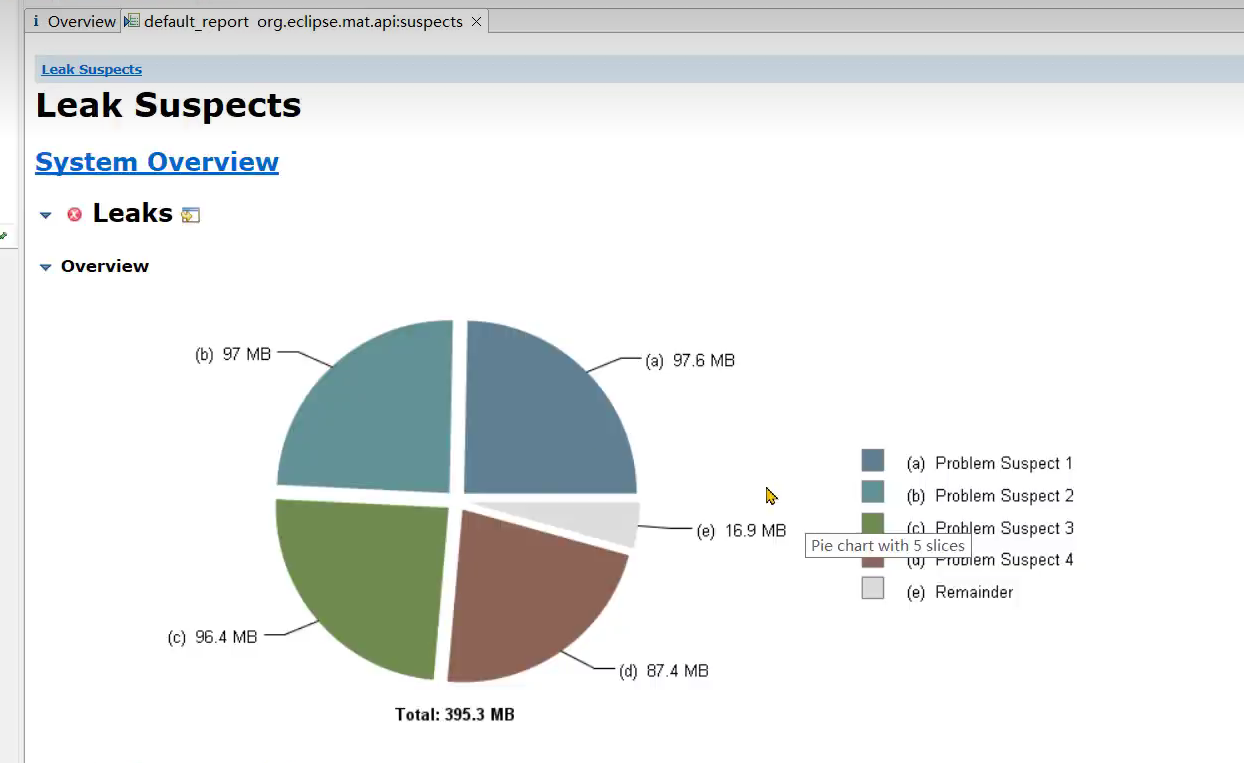
- 堆内存快照情况如下
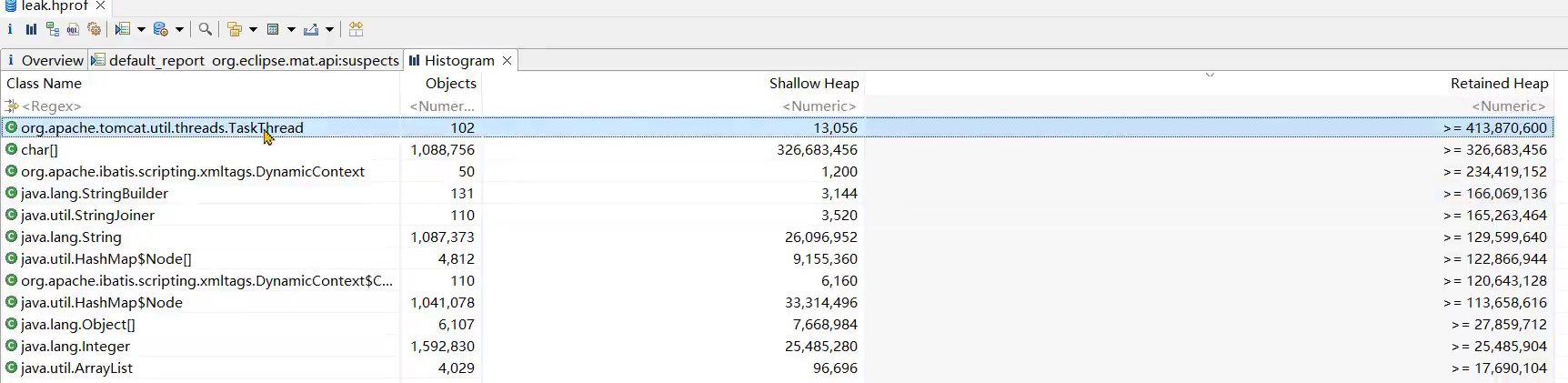
问题根源
- Mybatis在使用foreach进行sql拼接时,会在内存中创建对象,如果foreach处理的数组或者集合元素个数过多,会占用大量的内存空间
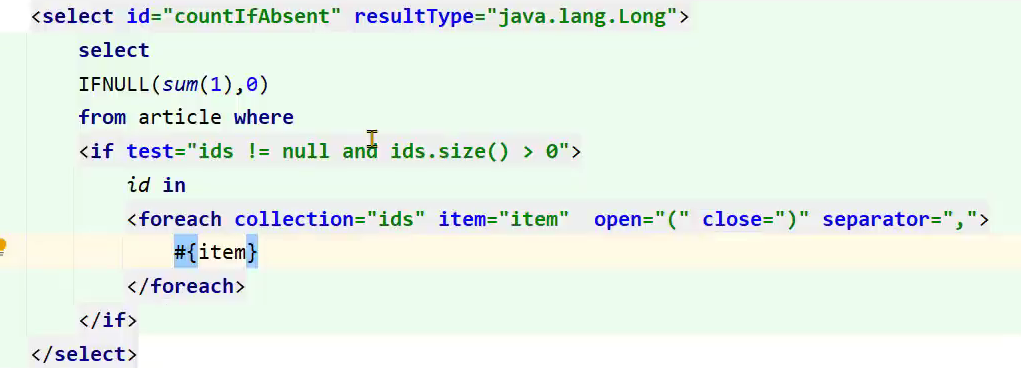
解决思路
- 限制参数中最大的id个数
- 将id缓存到redis或者内存缓存中,通过缓存进行校验
导出大文件内存溢出
问题背景
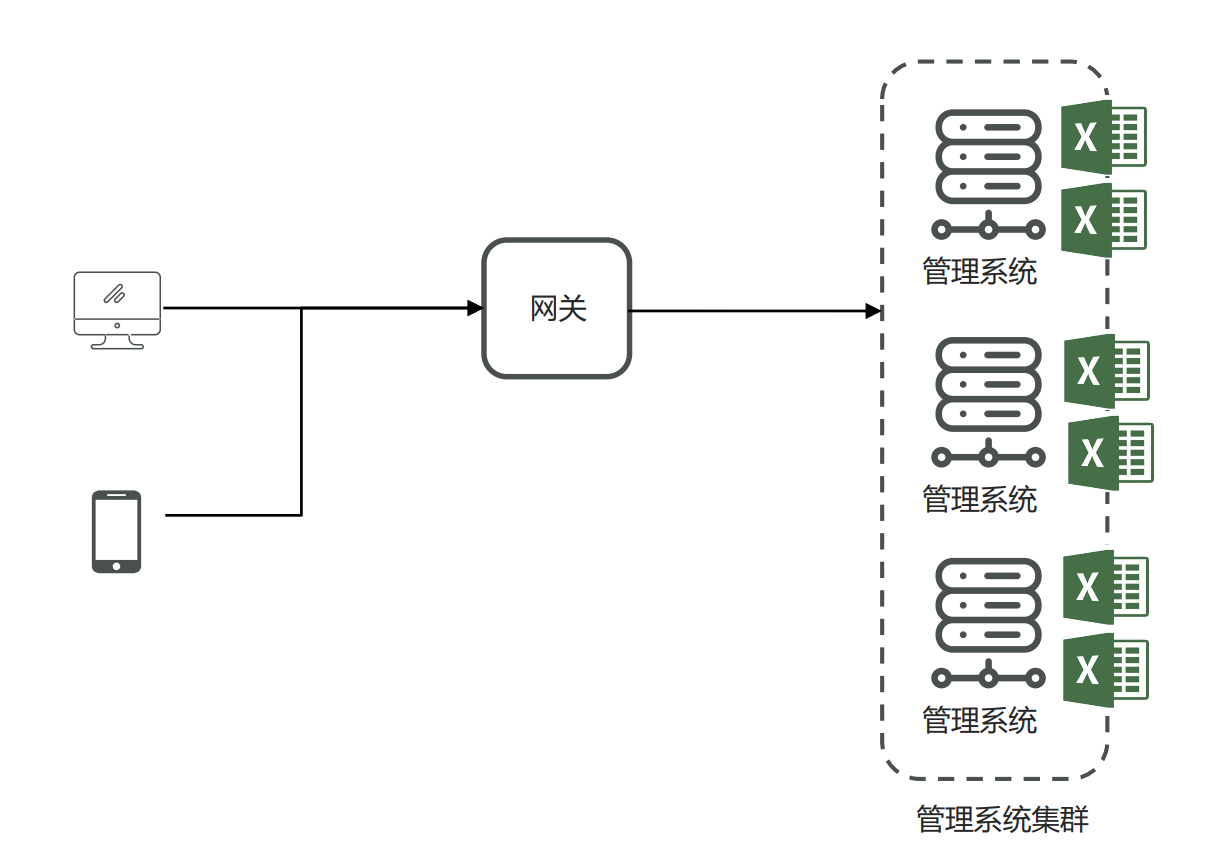
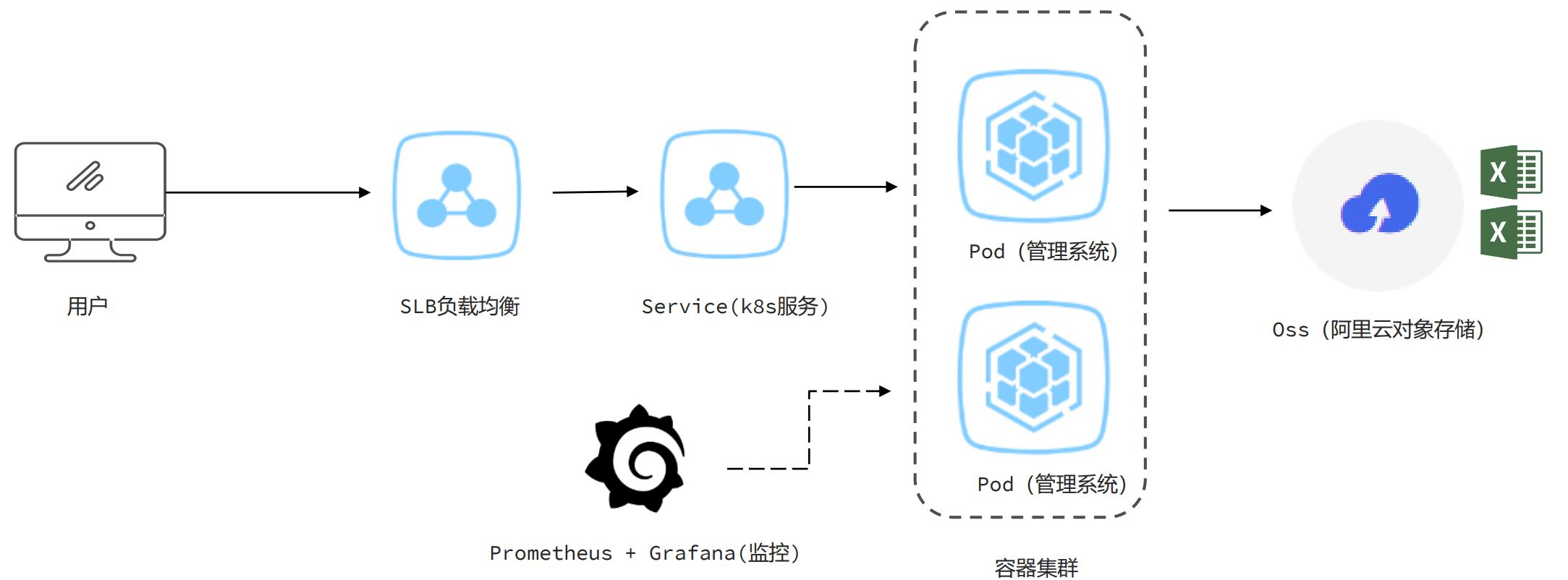
- 小李负责的一个管理系统,使用的是k8s将管理系统部署到容器中,这个管理系统支持几十万条数据的excel文件导出。他发现系统在运行时如果有几十个人同时进行大数据量的导出,会出现内存溢出。
问题根源
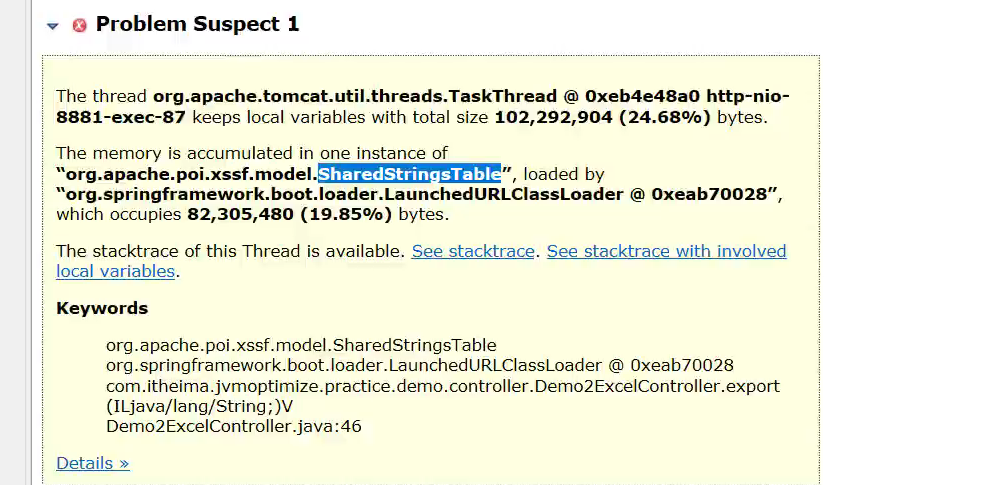
- Excel文件导出如果使用POI的XSSFWorkbook,在大数据量(几十万)的情况下会占用大量的内存。
解决思路
-
使用poi的SXSSFWorkbook(不推荐)
@GetMapping("/export") public void export(int size, String path) throws IOException { // 1 、创建工作薄 Workbook workbook = new XSSFWorkbook(); // 2、在工作薄中创建sheet Sheet sheet = workbook.createSheet("测试"); for (int i = 0; i < size; i++) { // 3、在sheet中创建行 Row row0 = sheet.createRow(i); // 4、创建单元格并存入数据 row0.createCell(0).setCellValue(RandomStringUtils.randomAlphabetic(1000)); } // 将文件输出到指定文件 FileOutputStream fileOutputStream = null; try { fileOutputStream = new FileOutputStream(path + RandomStringUtils.randomAlphabetic(10) + ".xlsx"); workbook.write(fileOutputStream); } catch (Exception e) { e.printStackTrace(); } finally { if (fileOutputStream != null) { fileOutputStream.close(); } if (workbook != null) { workbook.close(); } } } -
hutool提供的BigExcelWriter减少内存开销(推荐)
//http://www.hutool.cn/docs/#/poi/Excel%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%94%9F%E6%88%90-BigExcelWriter @GetMapping("/export_hutool") public void export_hutool(int size, String path) throws IOException { List<List<?>> rows = new ArrayList<>(); for (int i = 0; i < size; i++) { rows.add( CollUtil.newArrayList(RandomStringUtils.randomAlphabetic(1000))); } BigExcelWriter writer= ExcelUtil.getBigWriter(path + RandomStringUtils.randomAlphabetic(10) + ".xlsx"); // 一次性写出内容,使用默认样式 writer.write(rows); // 关闭writer,释放内存 writer.close(); } -
使用阿里巴巴easy excel,对内存进行大量的优化(推荐)
//https://easyexcel.opensource.alibaba.com/docs/current/quickstart/write#%E9%87%8D%E5%A4%8D%E5%A4%9A%E6%AC%A1%E5%86%99%E5%85%A5%E5%86%99%E5%88%B0%E5%8D%95%E4%B8%AA%E6%88%96%E8%80%85%E5%A4%9A%E4%B8%AAsheet @GetMapping("/export_easyexcel") public void export_easyexcel(int size, String path,int batch) throws IOException { // 方法1: 如果写到同一个sheet String fileName = path + RandomStringUtils.randomAlphabetic(10) + ".xlsx"; // 这里注意 如果同一个sheet只要创建一次 WriteSheet writeSheet = EasyExcel.writerSheet("测试").build(); // 这里 需要指定写用哪个class去写 try (ExcelWriter excelWriter = EasyExcel.write(fileName, DemoData.class).build()) { // 分100次写入 for (int i = 0; i < batch; i++) { // 分页去数据库查询数据 这里可以去数据库查询每一页的数据 List<DemoData> datas = new ArrayList<>(); for (int j = 0; j < size / batch; j++) { DemoData demoData = new DemoData(); demoData.setString(RandomStringUtils.randomAlphabetic(1000)); datas.add(demoData); } excelWriter.write(datas, writeSheet); //写入之后datas数据就可以释放了 } } }
ThreadLocal占用大量内存
问题背景
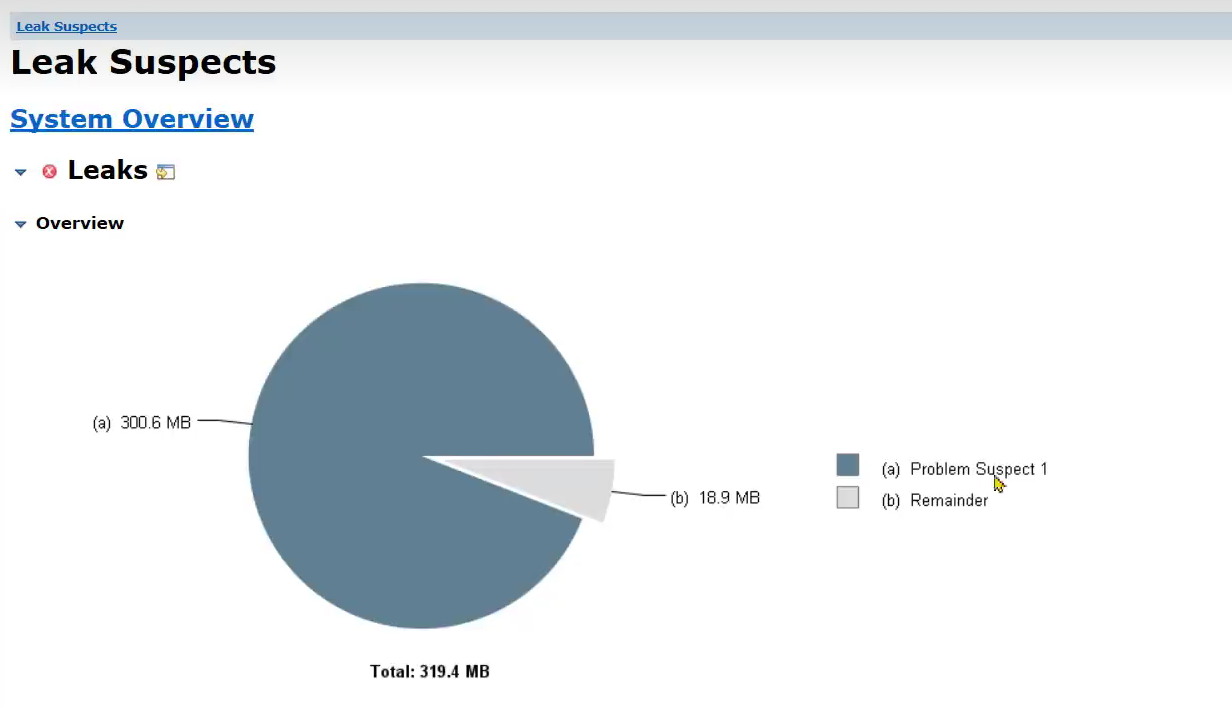
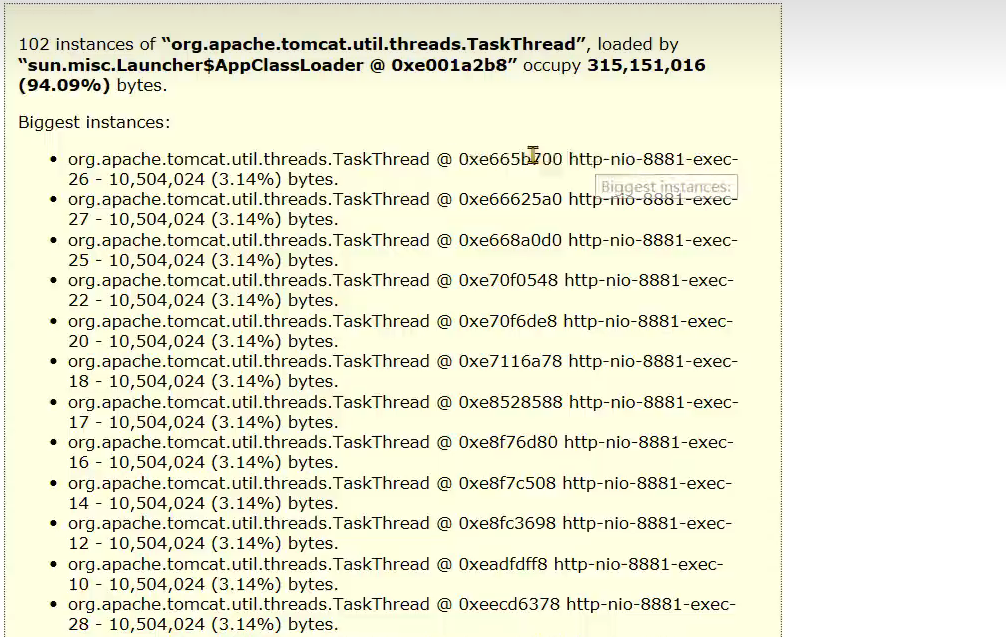
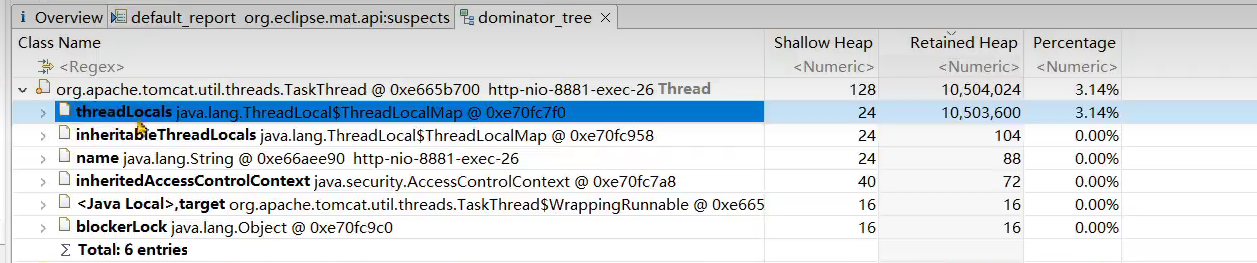
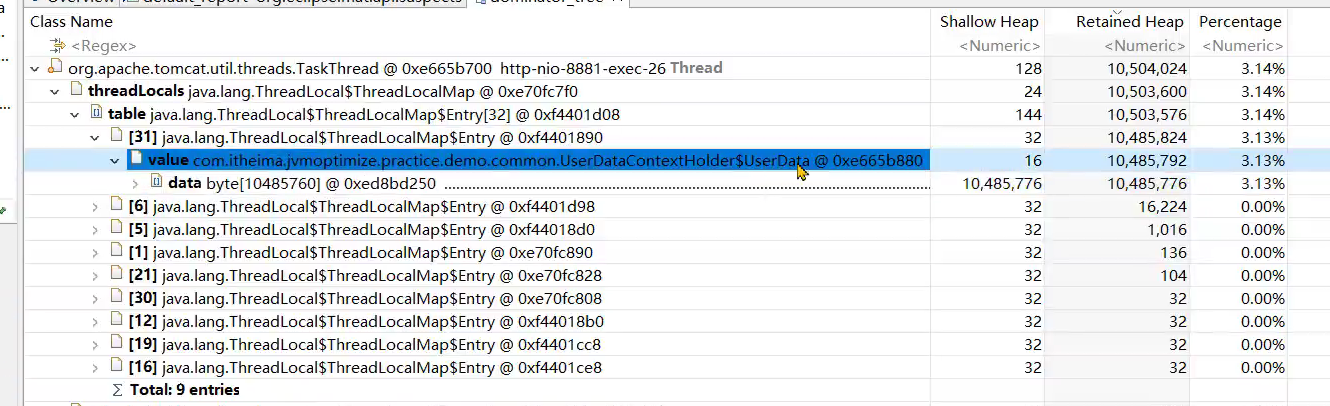
- 小李负责了一个微服务,但是他发现系统在没有任何用户使用时,也占用了大量的内存。导致可以使用的内存大大减少
问题根源
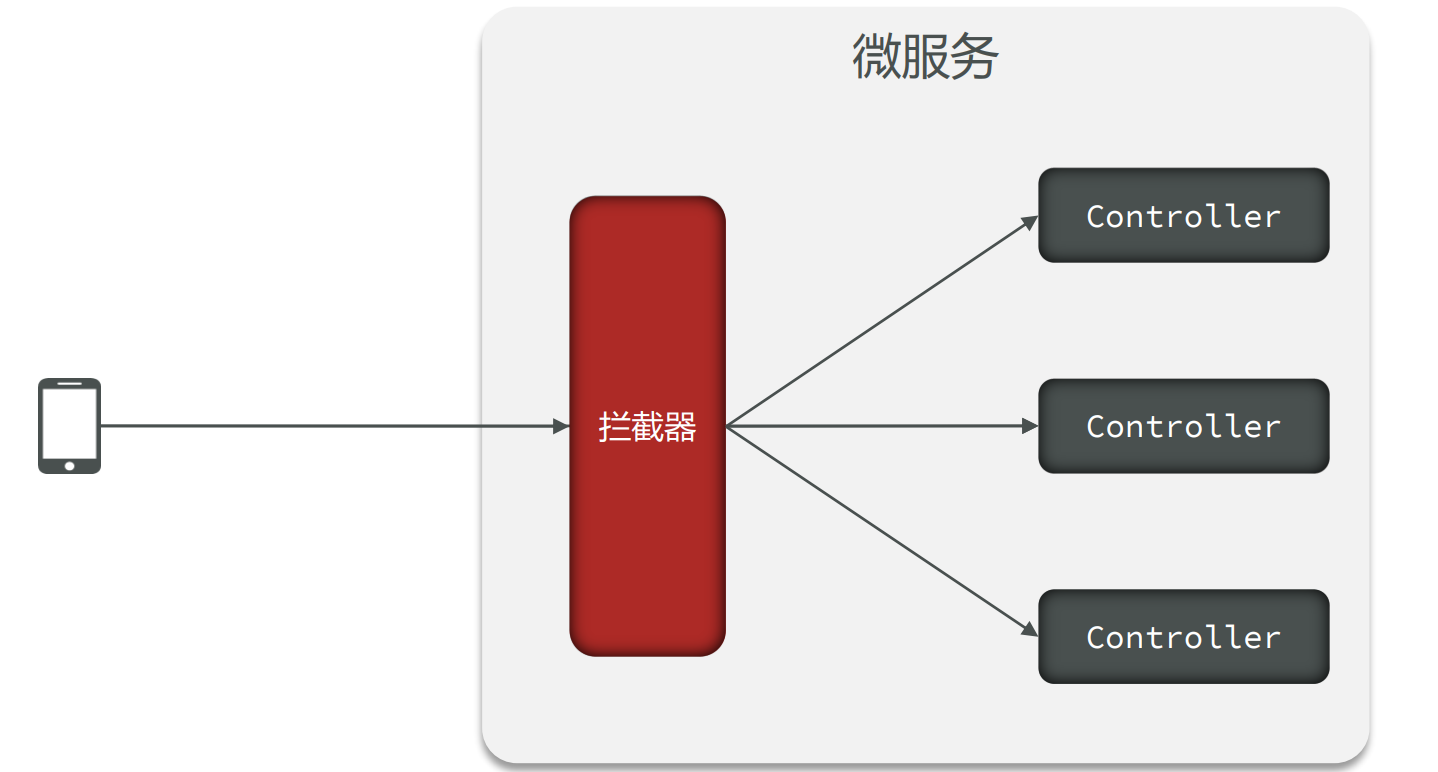
- 很多微服务会选择在拦截器preHandle方法中去解析请求头中的数据,并放入一些数据到ThreadLocal中方便后续使用。
解决思路
- 在拦截器的afterCompletion方法中,必须要将ThreadLocal中的数据清理掉。
import com.itheima.jvmoptimize.practice.demo.common.UserDataContextHolder; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; /** * 拦截器的实现,模拟放入数据到threadlocal中 */ public class UserInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { UserDataContextHolder.userData.set(new UserDataContextHolder.UserData()); return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { UserDataContextHolder.userData.remove(); } }
文章内容审核接口的内存问题
问题背景
- 文章微服务中提供了文章审核接口,会调用阿里云的内容安全接口进行文章中文字和图片的审核,在自测过程中出现内存占用较大的问题

设计1:Async异步审核
- 使用SpringBoot中的@Async注解进行异步的审核
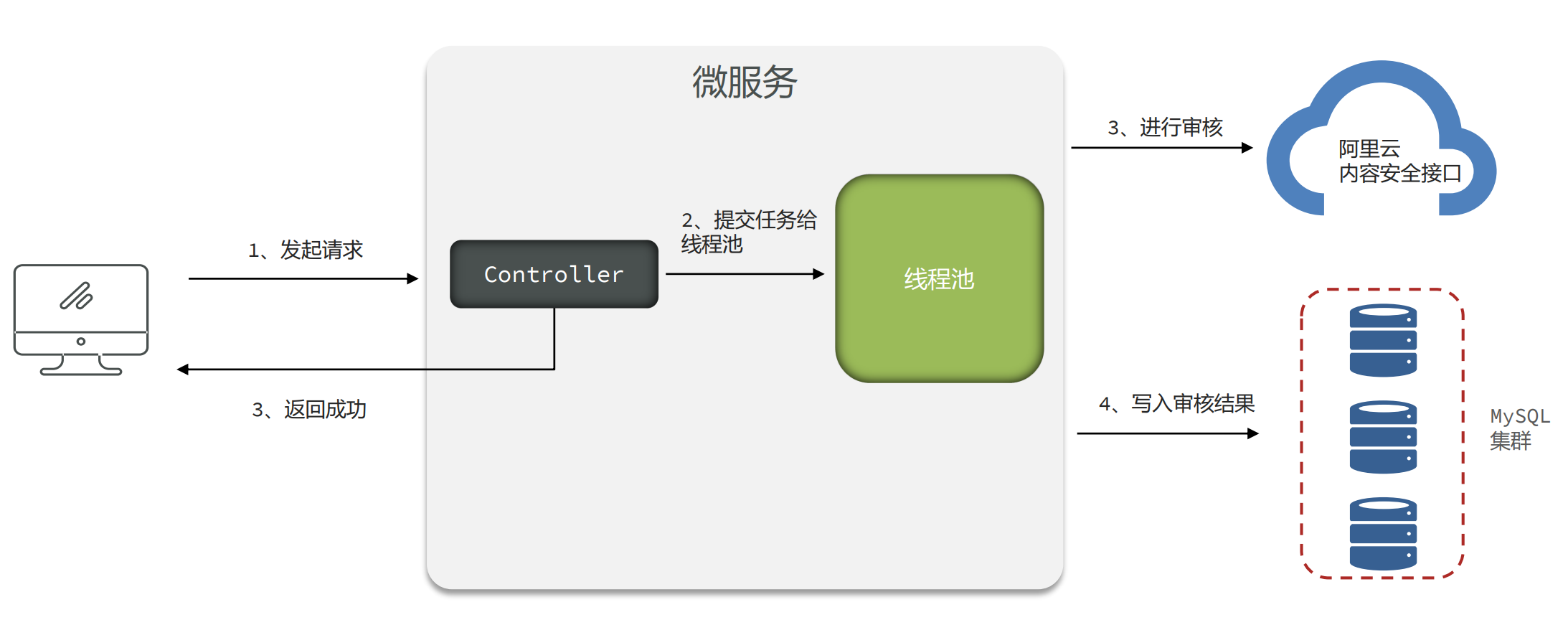
存在问题
- 线程池参数设置不当,会导致大量线程的创建或者队列中保存大量的数据。
- 任务没有持久化,一旦走线程池的拒绝策略或者服务宕机、服务器掉电等情况很有可能会丢失任务
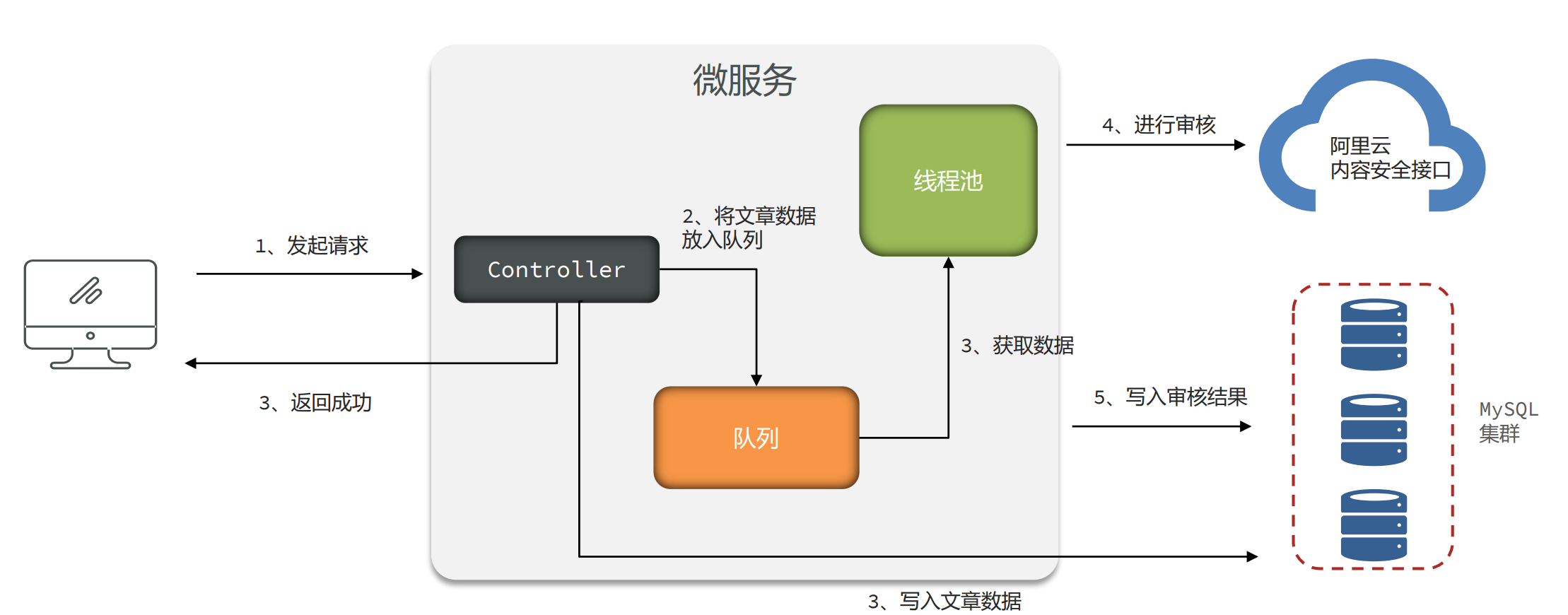
设计2:生产者消费者模式
- 使用生产者和消费者模式进行处理,队列数据可以实现持久化到数据库。
- 保存文章服务层实现代码
@Override public void saveArticle(ArticleDto article) { BUFFER_QUEUE.add(article); int size = BUFFER_QUEUE.size(); if( size > 0 && size % 10000 == 0){ System.out.println(size); } } - 线程池配置代码
@Configuration @EnableAsync public class ThreadPoolTaskConfig { public static final BlockingQueue<ArticleDto> BUFFER_QUEUE = new LinkedBlockingQueue<>(2000); private static final int corePoolSize = 50; // 核心线程数(默认线程数) private static final int maxPoolSize = 100; // 最大线程数 private static final int keepAliveTime = 10; // 允许线程空闲时间(单位:默认为秒) private static final int queueCapacity = 200; // 缓冲队列数 private static final String threadNamePrefix = "Async-Service-"; // 线程池名前缀 @Bean("taskExecutor") public ThreadPoolTaskExecutor getAsyncExecutor(){ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(corePoolSize); executor.setMaxPoolSize(Integer.MAX_VALUE); //executor.setMaxPoolSize(maxPoolSize); executor.setQueueCapacity(queueCapacity); executor.setKeepAliveSeconds(keepAliveTime); executor.setThreadNamePrefix(threadNamePrefix); // 线程池对拒绝任务的处理策略 executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy()); // 初始化 executor.initialize(); return executor; } } - 审核文章代码
@Component public class ArticleSaveTask { @Autowired @Qualifier("taskExecutor") private ThreadPoolTaskExecutor threadPoolTaskExecutor; @PostConstruct public void pullArticleTask(){ for (int i = 0; i < 50; i++) { threadPoolTaskExecutor.submit((Runnable) () -> { while (true){ try { ArticleDto data = BUFFER_QUEUE.take(); /** * 获取到队列中的数据之后,调用第三方接口审核数据,但是此时网络出现问题, * 第三方接口长时间没有响应,此处使用休眠来模式30秒 */ Thread.sleep(30 * 1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); } } }
存在问题
- 队列参数设置不正确,会保存大量的数据。
- 实现复杂,需要自行实现持久化的机制,否则数据会丢失
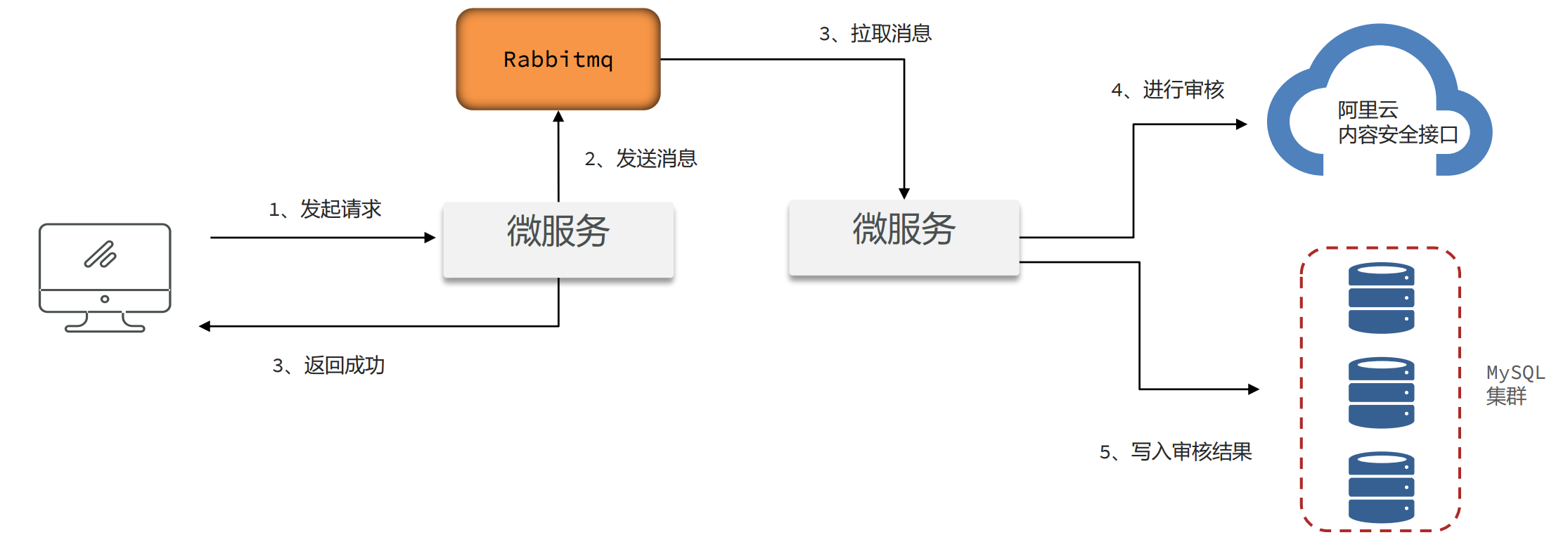
设计3:Mq消息队列模式
- 使用mq消息队列进行处理,由mq来保存文章的数据。发送消息的服务和拉取消息的服务可以是同一个,也可以不是同一个
- 生产者代码
@Autowired private RabbitTemplate rabbitTemplate; @Autowired private ObjectMapper objectMapper; @PostMapping("/demo3/{id}") public void article3(@PathVariable("id") long id, @RequestBody ArticleDto article) throws JsonProcessingException { article.setId(id); rabbitTemplate.convertAndSend("jvm-test",null, objectMapper.writeValueAsString(article)); } - 消费者代码
@Component public class SpringRabbitListener { @RabbitListener(queues = "queue1",concurrency = "10") public void listenSimpleQueue(String msg) throws InterruptedException { System.out.println(msg); Thread.sleep(30 * 1000); } }
问题根源和解决思路
- 在项目中如果要使用异步进行业务处理,或者实现生产者 – 消费者的模型,如果在Java代码中实现,会占用大量的内存去保存中间数据。
- 尽量使用Mq消息队列,可以很好地将中间数据单独进行保存,不会占用Java的内存。同时也可以将生产者和消费者拆分成不同的微服务






![【动态规划.3】[IOI1994]数字三角形 Number Triangles](https://img-blog.csdnimg.cn/direct/7931675d8d7f4db5a0d78e51aae6ff94.png)