SAP HANA SQL 基础教程
- 1、SQL 标准简介
- 2、HANA STUDIO 的安装
- 3、HANA STUDIO 的设置
- 4、HANA SQL 基础教程
- (1)查看表数据
- (2)查看表结构
- (3)SELECT
- (4)WHERE
- (5)WHERE CLAUSE
- (6)ORDER BY
- (7)FUNCTION
- (8)GROUP BY
- (9)HAVING
- (10)CREATE
- (11)INSERT
- (12)UPDATE
- (13)DELETE / TRUNCATE
- (14)DROP
- (15)UNION
- (16)SUB SELECT
- (17)IN & EXISTS
- (18)JOIN
- (19)NULL
1、SQL 标准简介
SQL是什么?
- SQL (Structured Query Language:结构化查询语言),是用于访问和处理数据库的标准的计算机语言,是关系数据库管理系统(RDBMS)的主要管理工具。
- SQL让您可以访问和处理数据库,包括数据插入、查询、更新和删除,以及数据访问控制。
- SQL 在1986年成为 ANSI(AmericanNational Standards Institute 美国国家标准化组织)的一项标准,在 1987年成为国际标准化组织(ISO)标准。
SQL具体能做什么?
- SQL 面向数据库执行查询
- SQL 可从数据库取回数据
- SQL 可在数据库中插入新的记录
- SQL 可更新数据库中的数据
- SQL可从数据库删除记录
- SQL 可创建新数据库
- SQL 可在数据库中创建新表
- SQL 可在数据库中创建存储过程
- SQL 可在数据库中创建视图
- SQL 可以设置表、存储过程和视图的权限
SQL只是一种标准
- 虽然 SQL 是一门 ANSI(American National Standards Institute美国国家标准化组织)标准的计算机语言,但是仍然存在着多种不同版本的 SQL 语言,以各种不同的关系型数据库为代表,如SQLServer、Mysql、Oracle、Hana等。
- 然而,为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的命令(比如
SELECT、UPDATE、DELETE、INSERT、WHERE 等等)。 - 所以,不同关系型数据库的基本SQL语法是大同小异的,掌握任意一种数据库SQL语法,便能很快上手其他数据库的SQL语法。
RDBMS 是什么?
- RDBMS 指关系型数据库管理系统,全称 Relational Database Management System。
- RDBMS 是SQL 的基础,同样也是所有现代数据库系统的基础,比如 MS SQL Server、IBM DB2、Oracle、MySQL 以及Microsoft Access。
- RDBMS 中的数据存储在被称为表的数据库对象中。
- 表是相关的数据项的集合,它由列和行组成。
SAP HANA 是什么?
- SAP HANA数据库,支持标准的关系型数据库特性。数据通常以列式存储为主,也支持行式存储。支持ABAP、JavaScript、Python等,具有基于SQL92 ANSI/ISO标准模型语言。
- SAP HANA是内存数据库,通过使用内存中的数据平台,SAP HANA可以获得比运行在磁盘上的方式更好的整体性能。
2、HANA STUDIO 的安装
(1)直接拷贝他人的Hana Studio程序包
(2)安装Eclipse,再安装Hana相关组件,请参考《SAP Eclipse ADT开发环境配置与应用》。
3、HANA STUDIO 的设置
包括如何连接 HANA DB 服务器,如何执行SQL查询等。
(1)可以参考《HANA STUDIO的使用入门》。
(2)可以参考《SAP S/4 HANA 数据库底表查询及运维管理》。
4、HANA SQL 基础教程
本SQL教程的示例,使用SAP自带的航班系统数据模型,继续学习之前,请先参考《SAP Flight 航班系统数据模型简介》熟悉该模型的数据关系。
(1)查看表数据
启动 Hana Studio,点击 Hana 服务器,展开Catalog → SAPHANADB(SAP S4对应Schema)→ Tables,右键 → Filters…
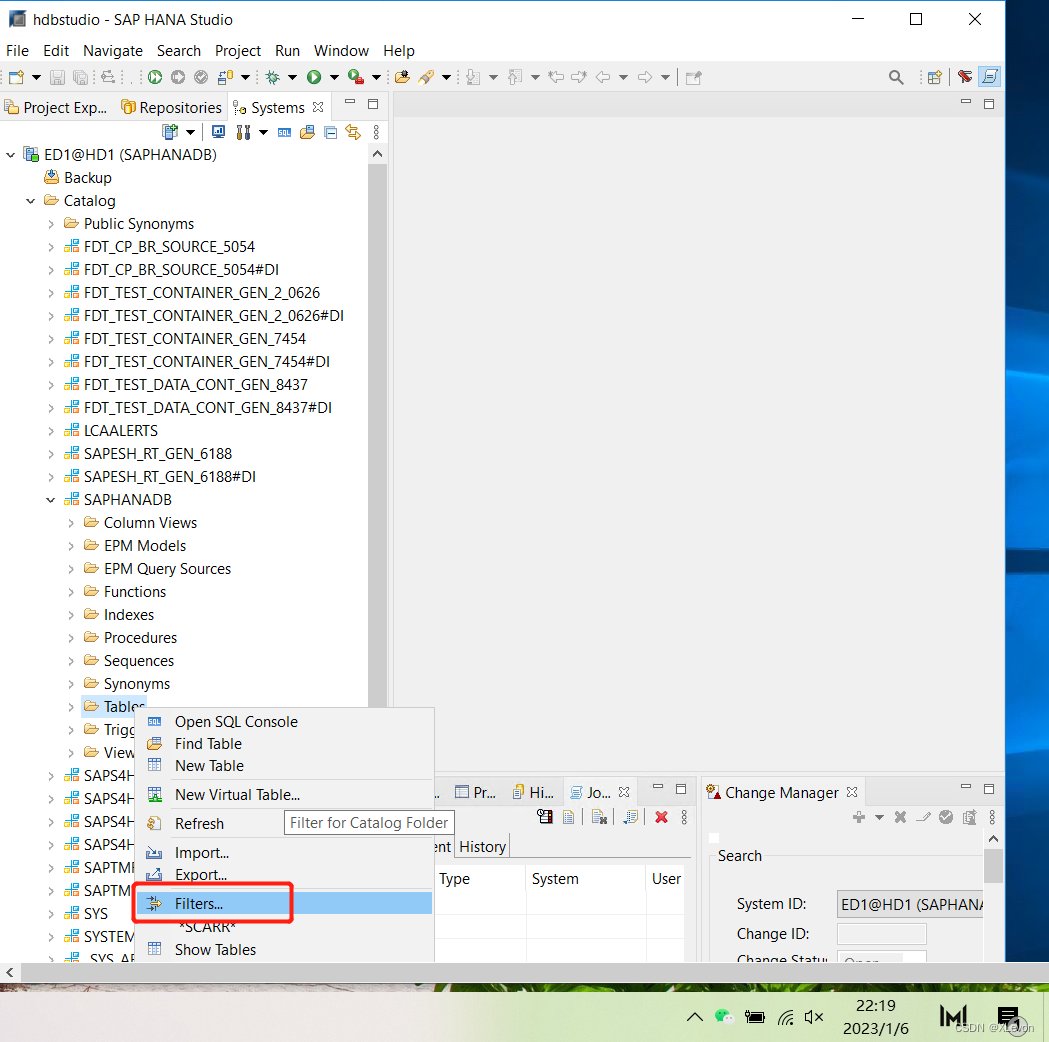
搜索过滤 SCARR 表
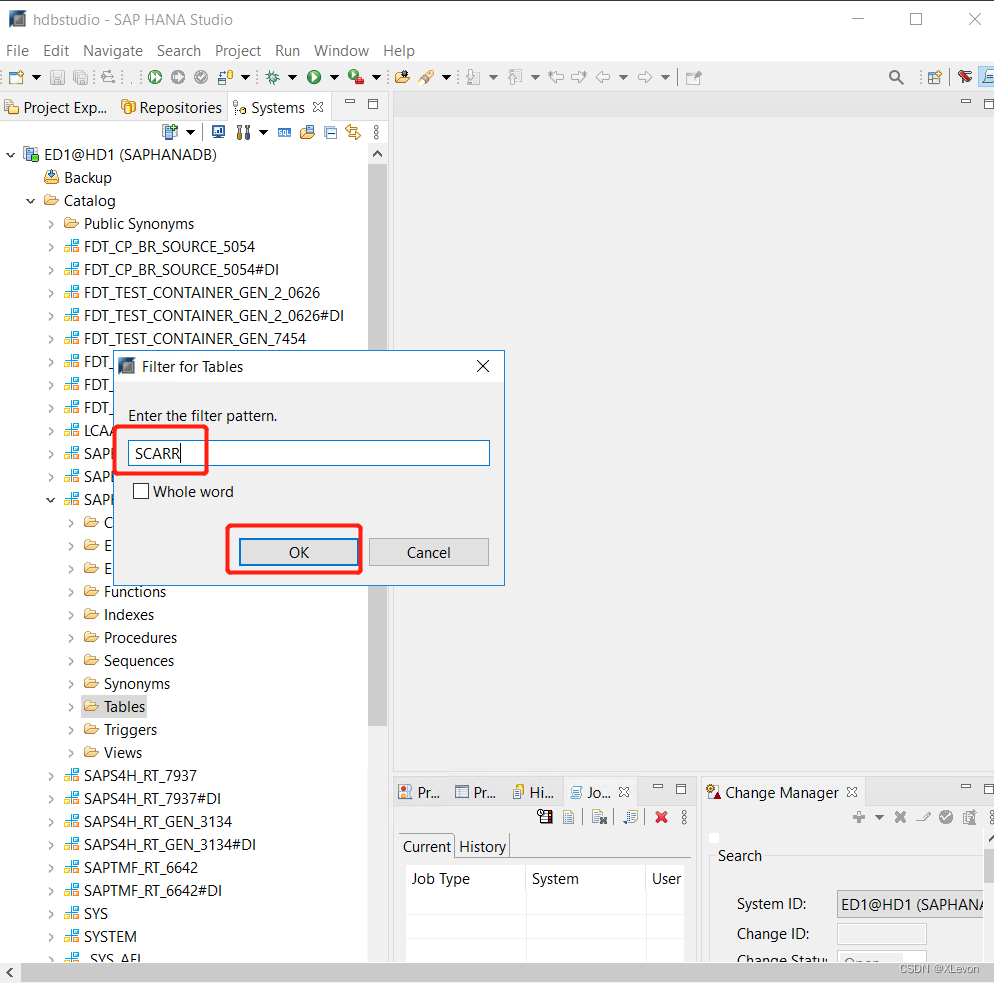
在 SCARR 表上右键 → Open Data Preview 查看表数据
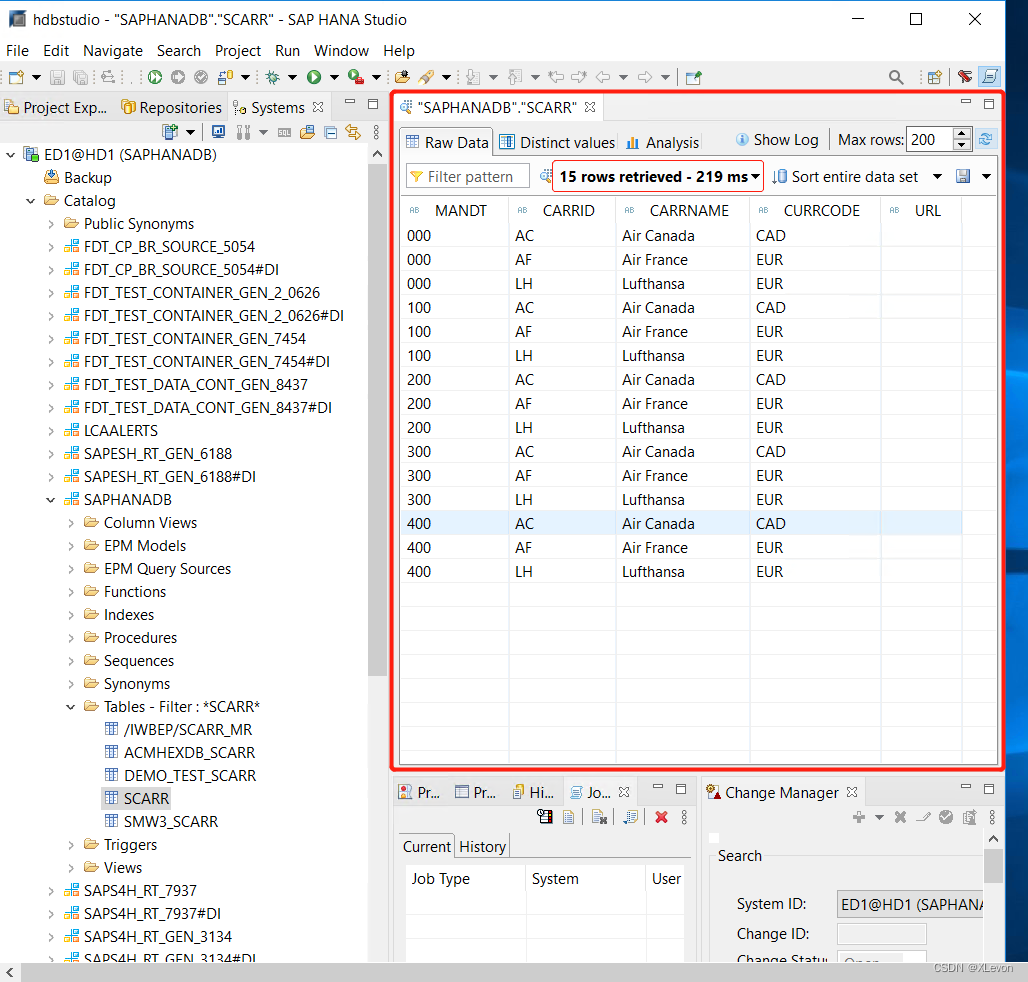
点击 “Show Log” → 双击 Generated SQL 行 → Copy,复制出数据查询脚本
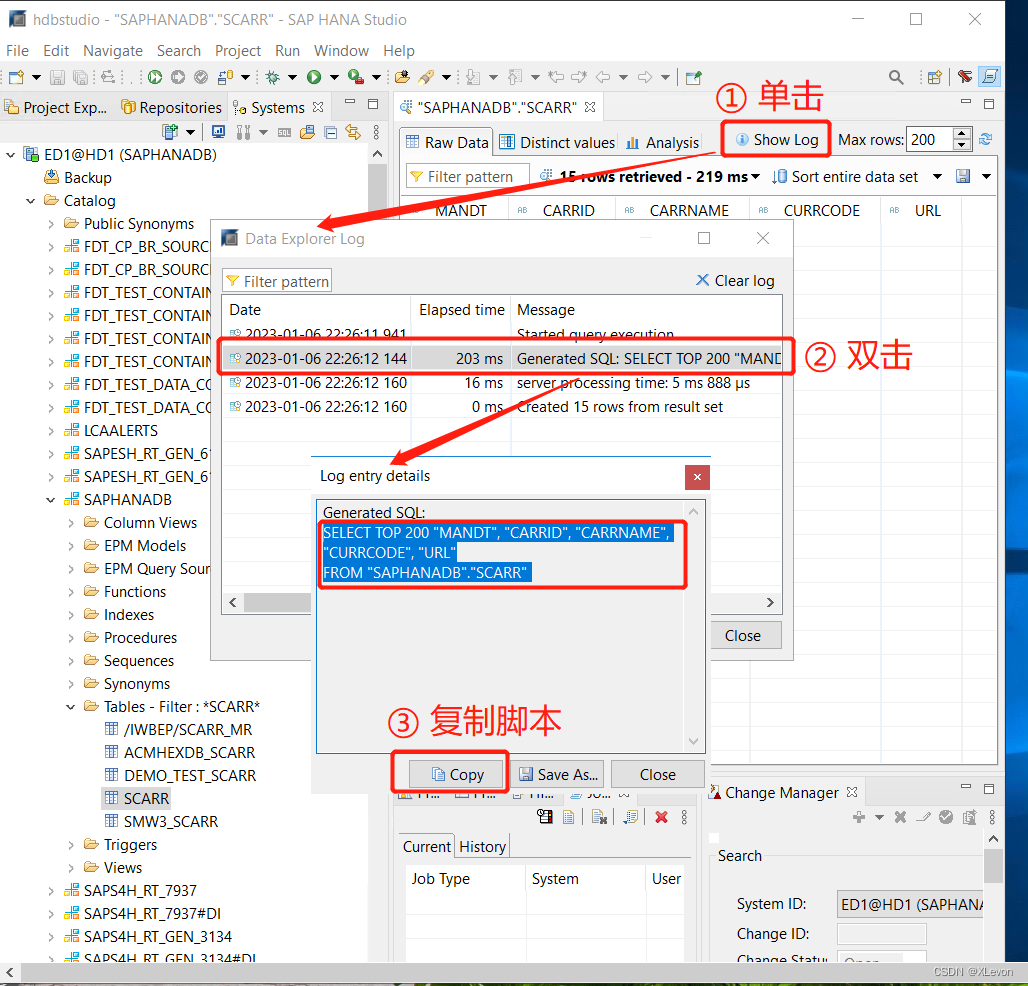
SELECT TOP 200 "MANDT", "CARRID", "CARRNAME", "CURRCODE", "URL"
FROM "SAPHANADB"."SCARR"
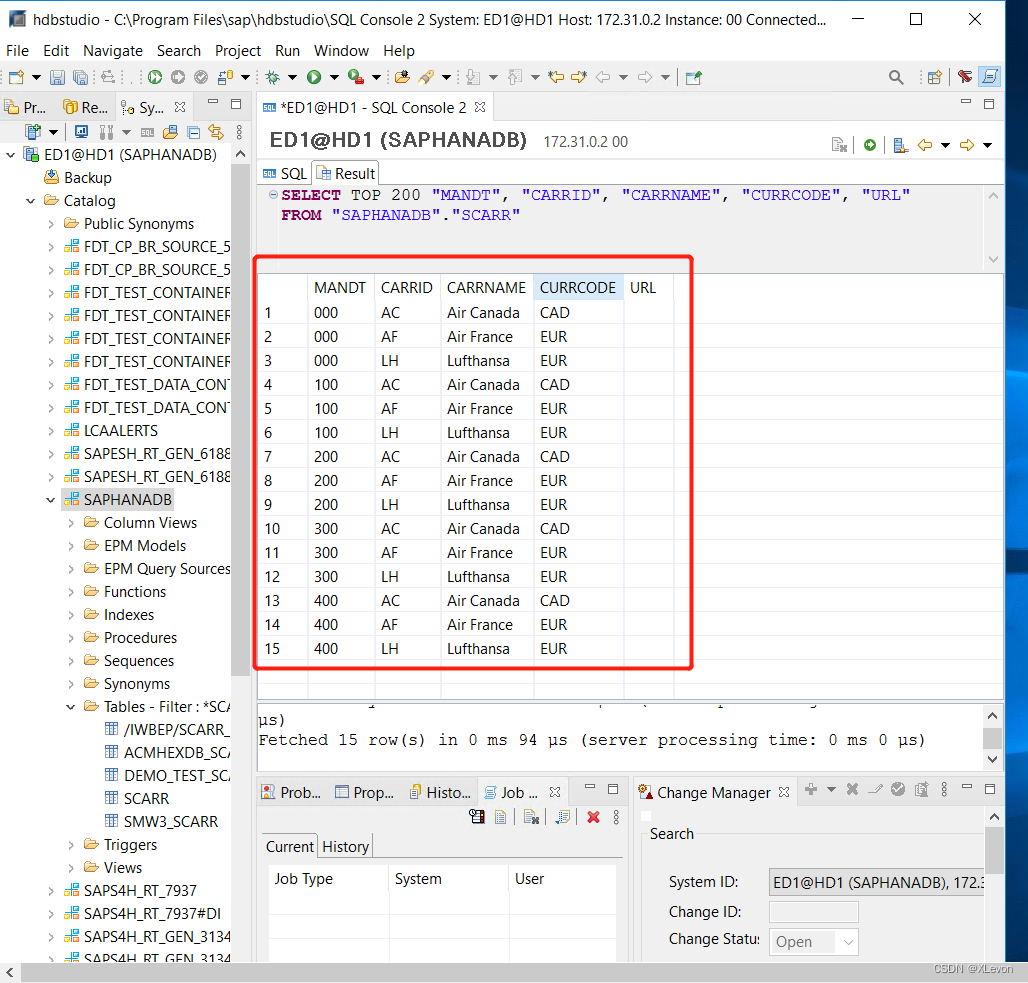
关闭右侧所有窗口,点击 SAPHANADB → 左侧右上角“SQL”按钮 → 打开右侧SQL编辑框 → 粘贴以上脚本 → 执行(F8)

第一条SQL查询语句执行成功
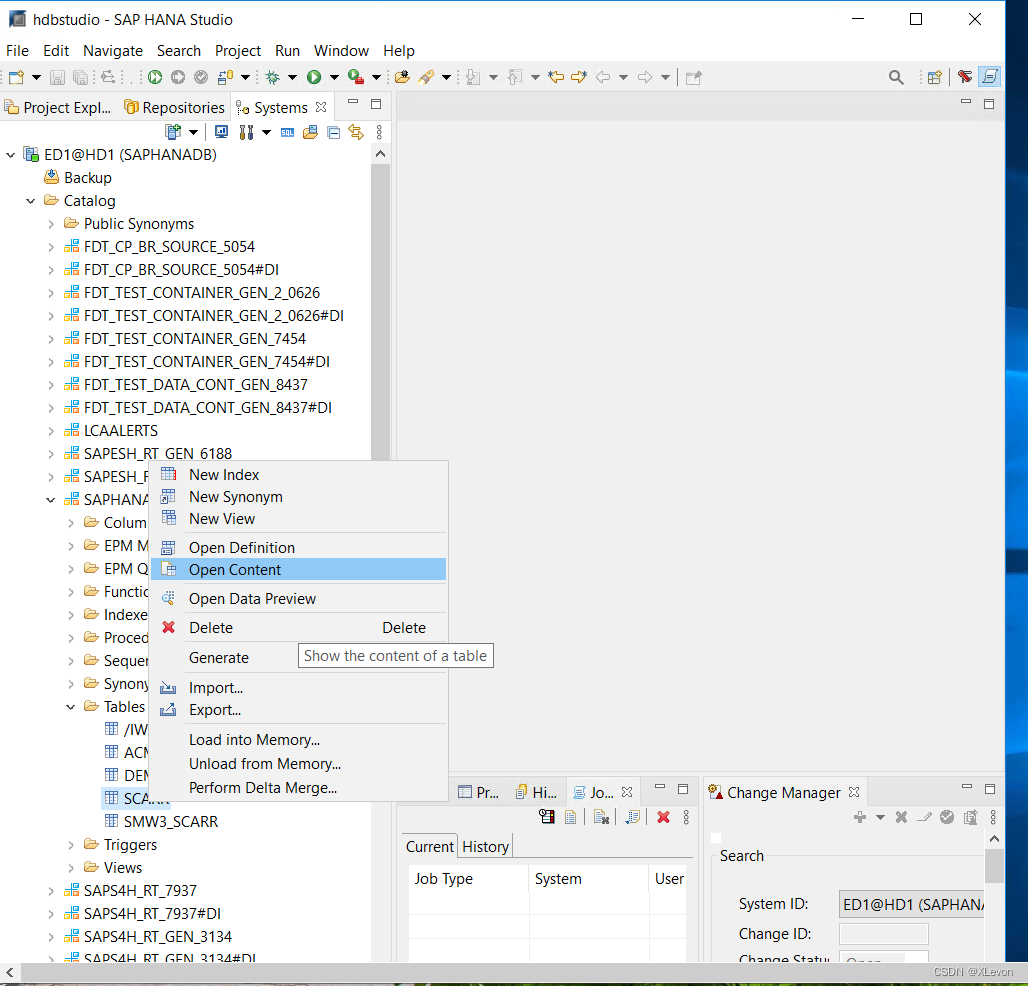
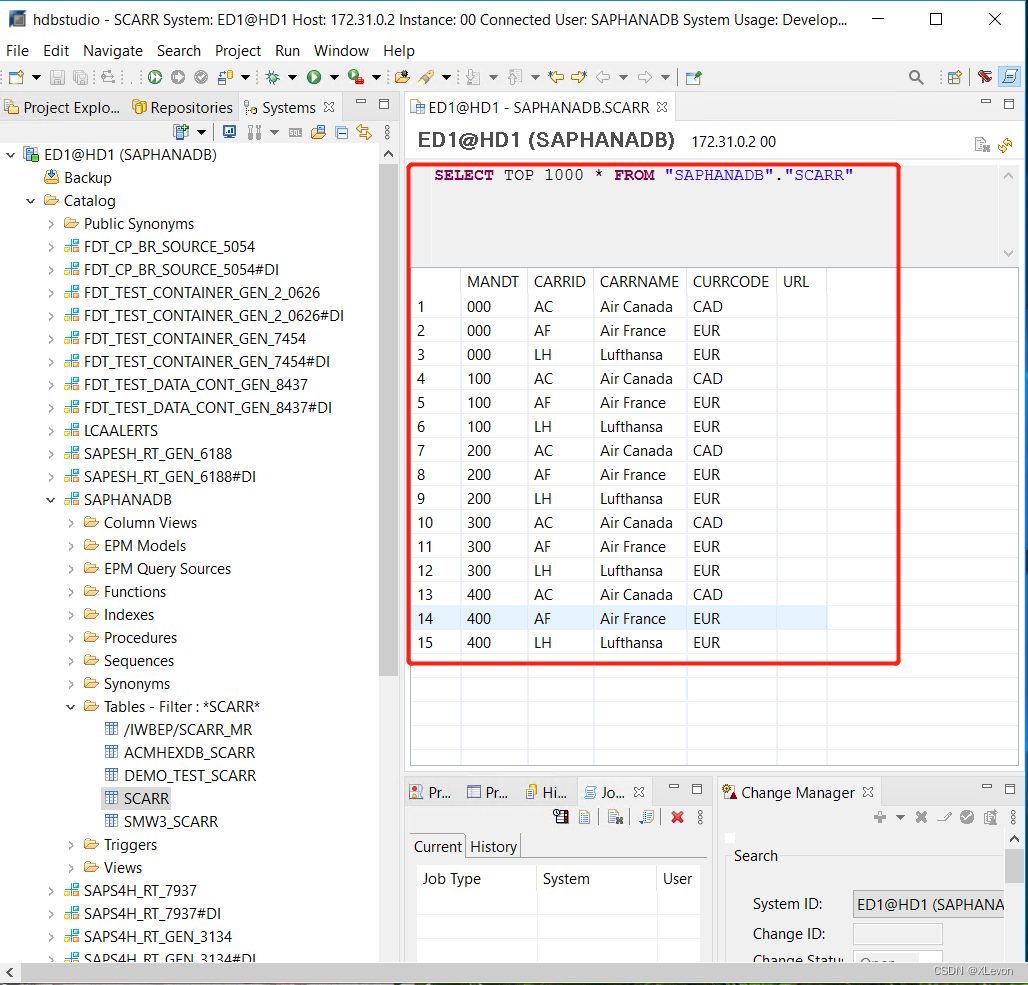
以上过程,也可以直接在 SCARR 表上右键 → Open Content 实现
(2)查看表结构
在 SCARR 表上右键 → Open Definition,或者直接双击 SCARR 表,查看表结构定义。
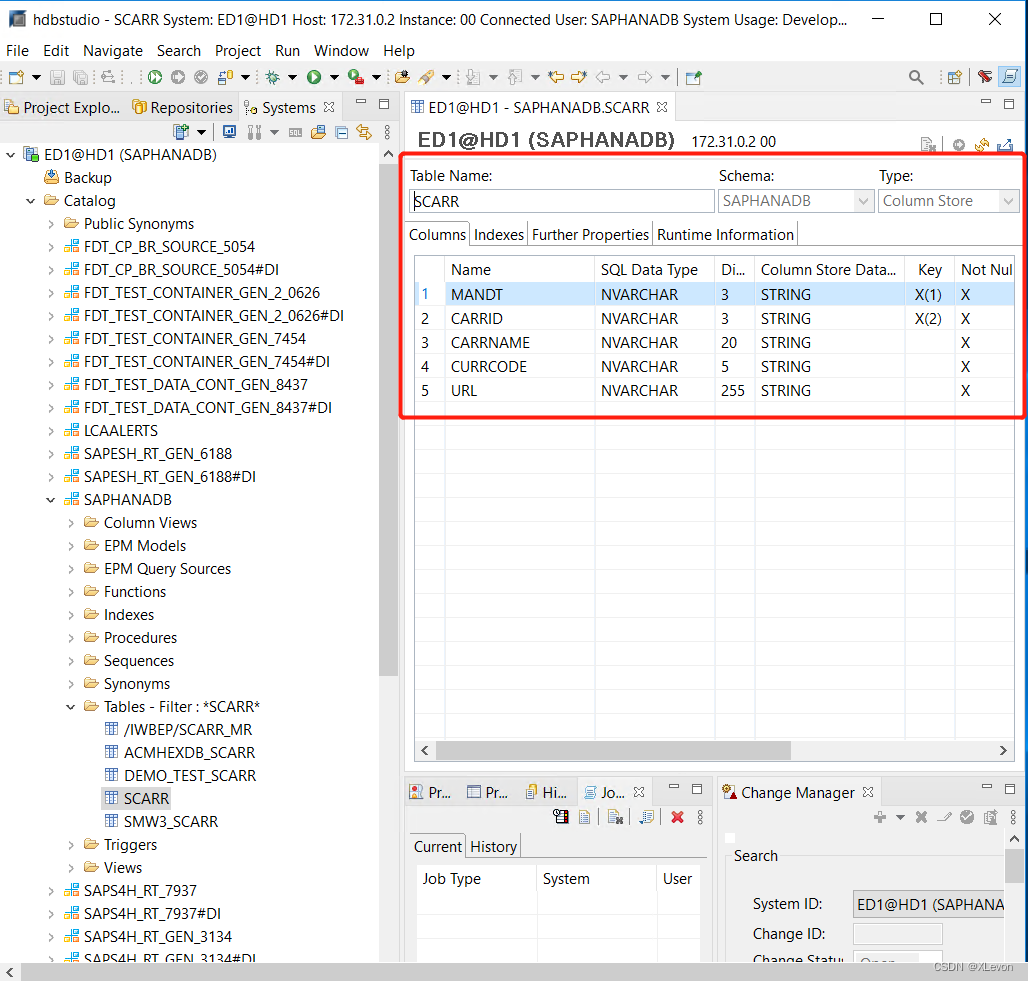
具体有:表字段名,字段类型,数据长度,列式存储数据类型,关键字,是否允许NULL,默认值,字段注释。
在右侧上方“Table Name”处 右键 → Export SQL,可以导出表格创建脚本
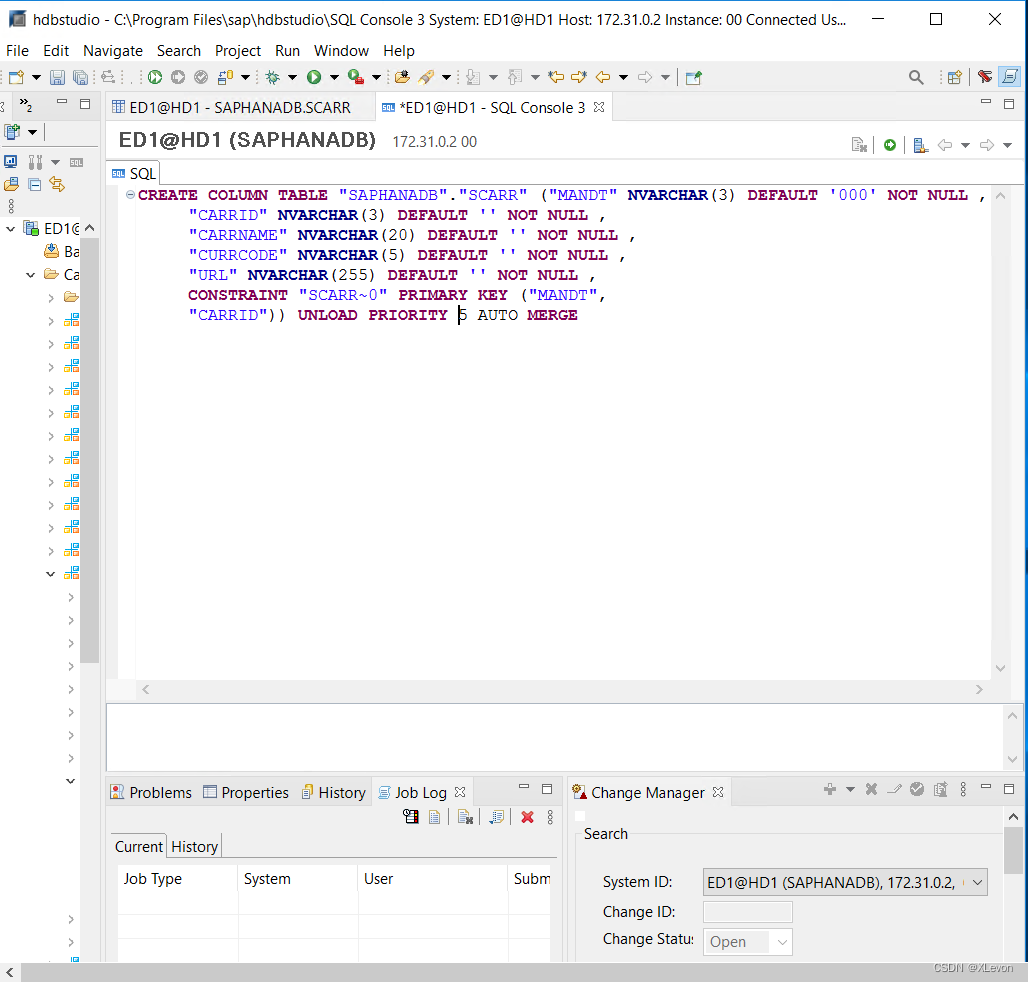
CREATE COLUMN TABLE "SAPHANADB"."SCARR"
(
"MANDT" NVARCHAR(3) DEFAULT '000' NOT NULL ,
"CARRID" NVARCHAR(3) DEFAULT '' NOT NULL ,
"CARRNAME" NVARCHAR(20) DEFAULT '' NOT NULL ,
"CURRCODE" NVARCHAR(5) DEFAULT '' NOT NULL ,
"URL" NVARCHAR(255) DEFAULT '' NOT NULL ,
CONSTRAINT "SCARR~0" PRIMARY KEY ("MANDT","CARRID")
) UNLOAD PRIORITY 5 AUTO MERGE
(3)SELECT
后续我们的操作将主要在 SQL 编辑框内,通过SQL脚本来实现,所以第一步操作,打开 SQL 编辑框。
启动 Hana Studio,点击 Hana 服务器,展开Catalog → SAPHANADB(SAP S4对应Schema)→ 左侧右上角“SQL”按钮 → 打开右侧SQL编辑框 → 输入SQL脚本 → 执行(F8)
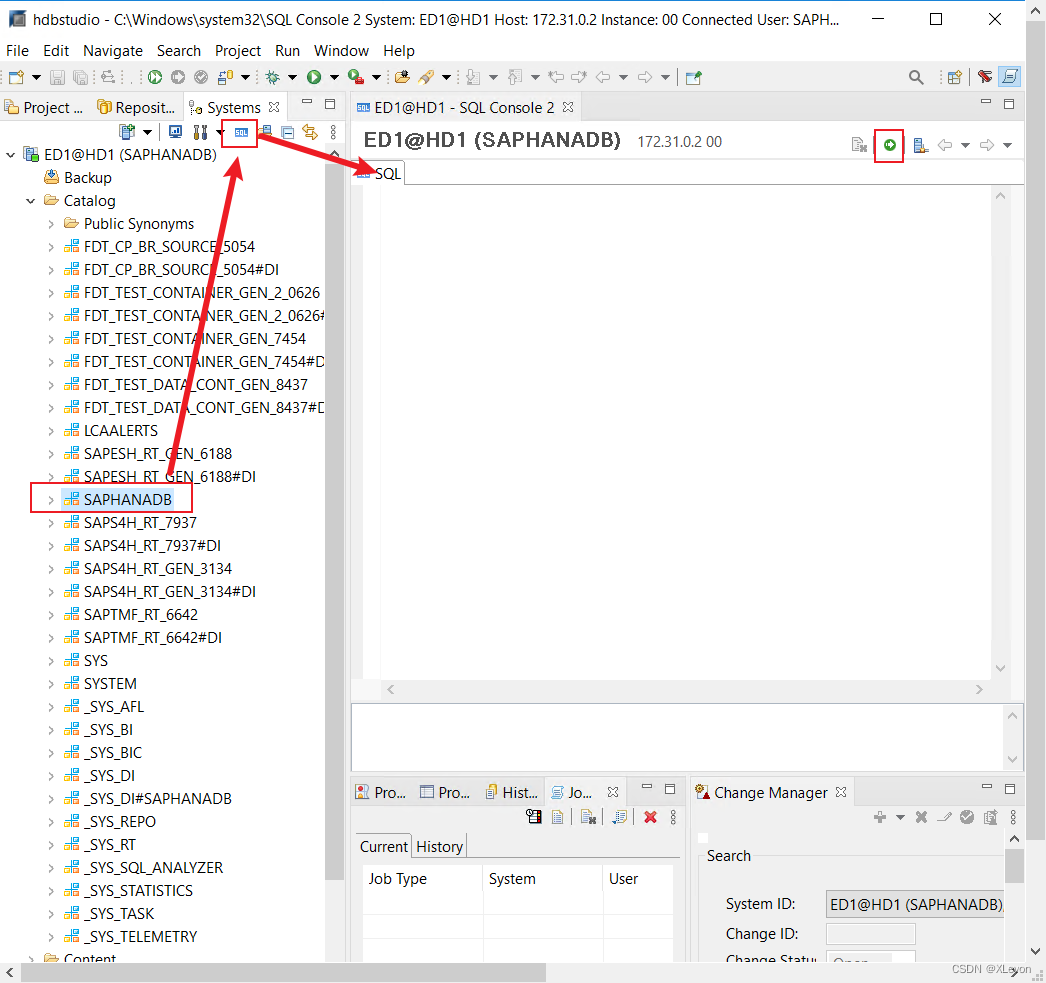
SELECT语句:主要用于查询数据库表记录。
示例1:查询航空公司的代码和名称
select carrid, carrname from scarr;
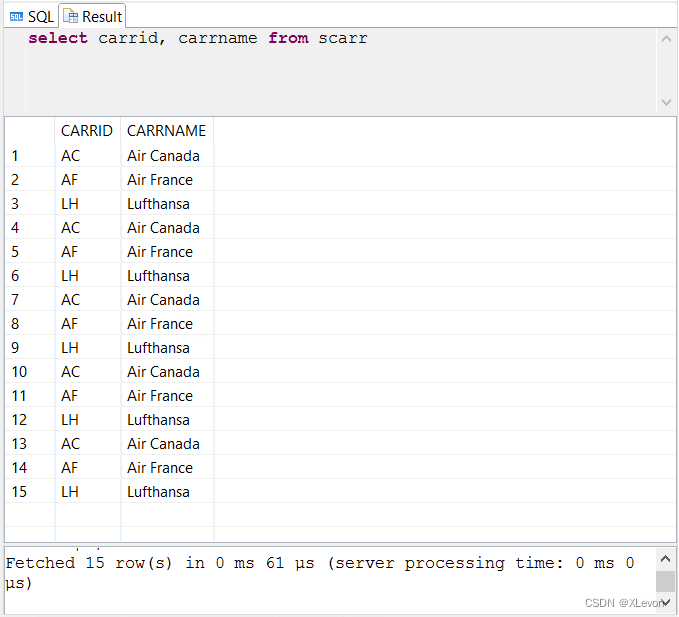
示例2:查询航空公司的所有信息
select mandt, carrid, carrname, currcode, url from scarr;
-- 或者:
select * from scarr;
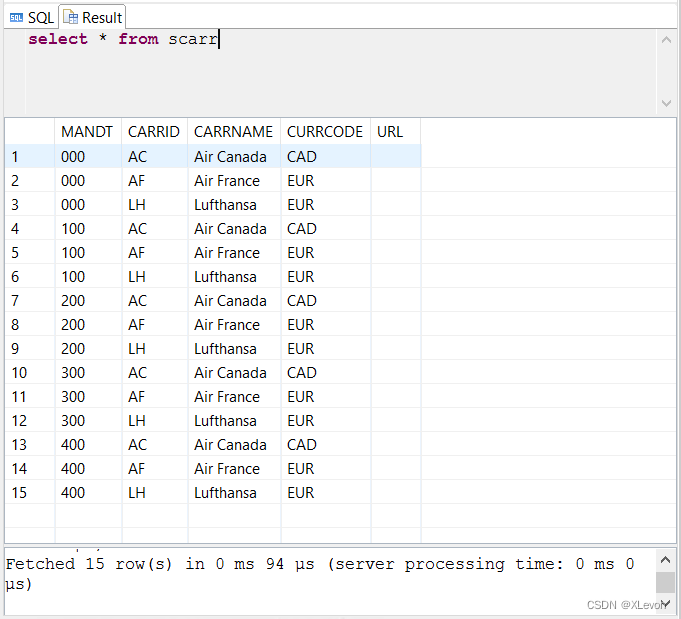
示例3:查询前2条航空公司记录
select top 2 * from scarr;
--或者:
select * from scarr limit 2;
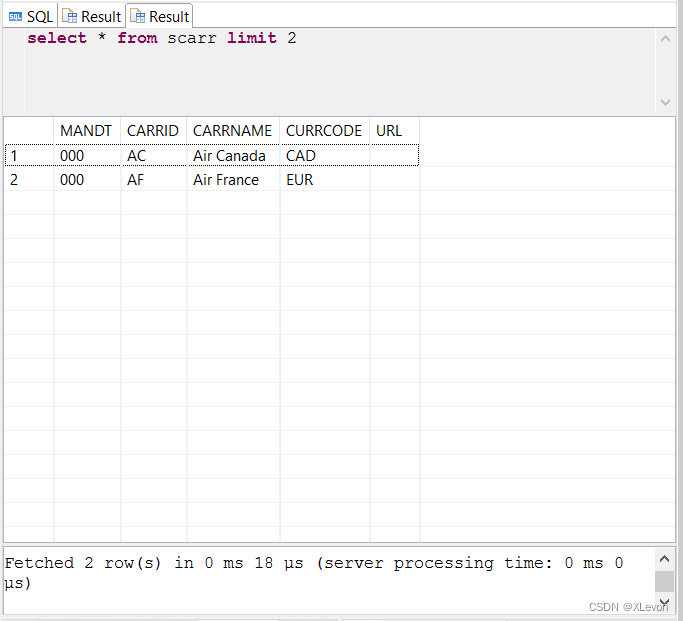
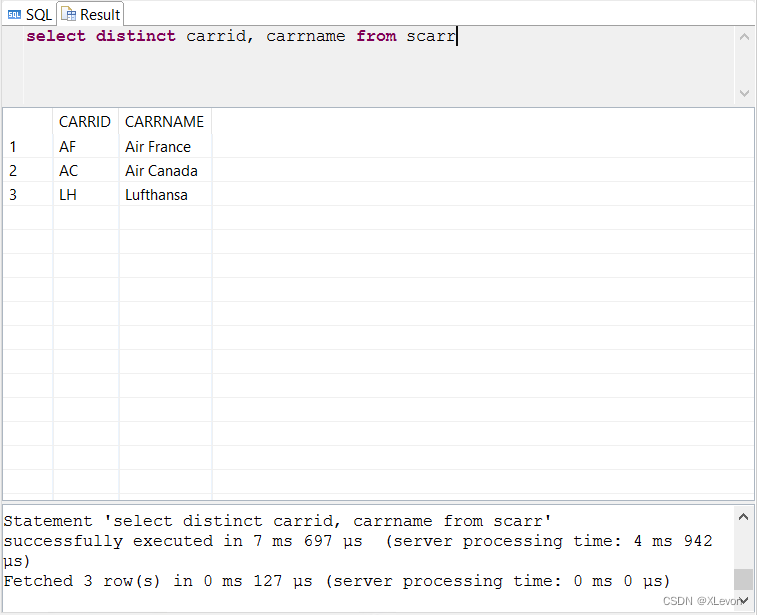
示例4:查询去重后的航空公司的代码和名称
select distinct carrid, carrname from scarr;
select case a when b then c as d from table
select a*b as c from table
注意事项:
1、hana 数据库对象本身是区分大小写的,定义时未用双引号指定小写的,系统一律会转成大写存储;
2、hana sql脚本没加双引号时,不区分大小写,系统自动会将脚本中所有小写转换成大写后执行,所以以下两句是等效的
select distinct carrid, carrname from scarr;
SELECT Distinct CARRID, CARRNAME FROM Scarr;
3、hana sql脚本添加双引号后,则不会转换大小写,系统会直接按输入的大小去执行,从而可能导致访问失败,如以下脚本,会报错:SAP DBTech JDBC: [259]: invalid table name: Could not find table/view Scarr in schema SAPHANADB: line 1 col 54 (at pos 53)
select distinct carrid, carrname from "Scarr";
4、如果查询的表不在当前登录用户schema下,则需要通过添加schema前缀来访问表,如下所示
select distinct carrid, carrname from saphanadb.scarr;
(4)WHERE
WHERE语句:配合SELECT使用,主要用于查询数据库表记录时的条件查询,或者叫数据过滤。
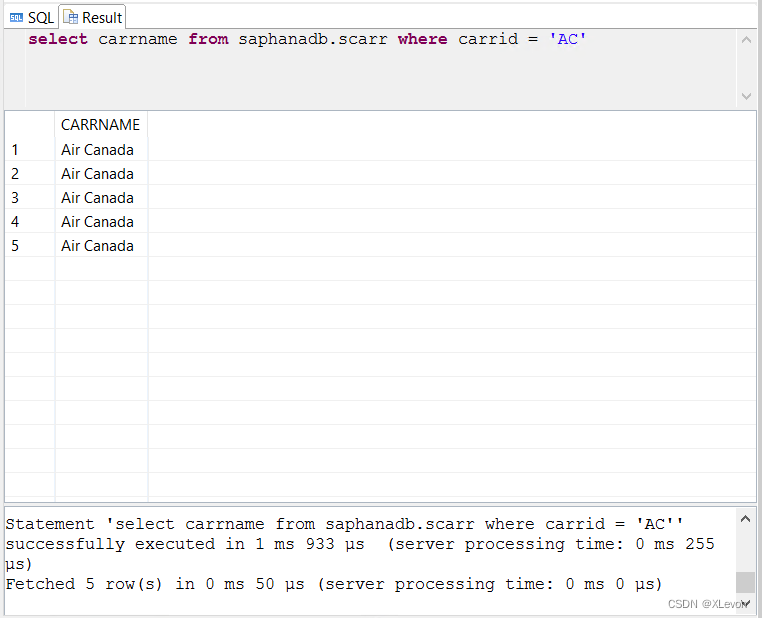
示例1:查找代码是AC的航空公司名称
select carrname from saphanadb.scarr where carrid = 'AC'; -- 注意:区分大小写
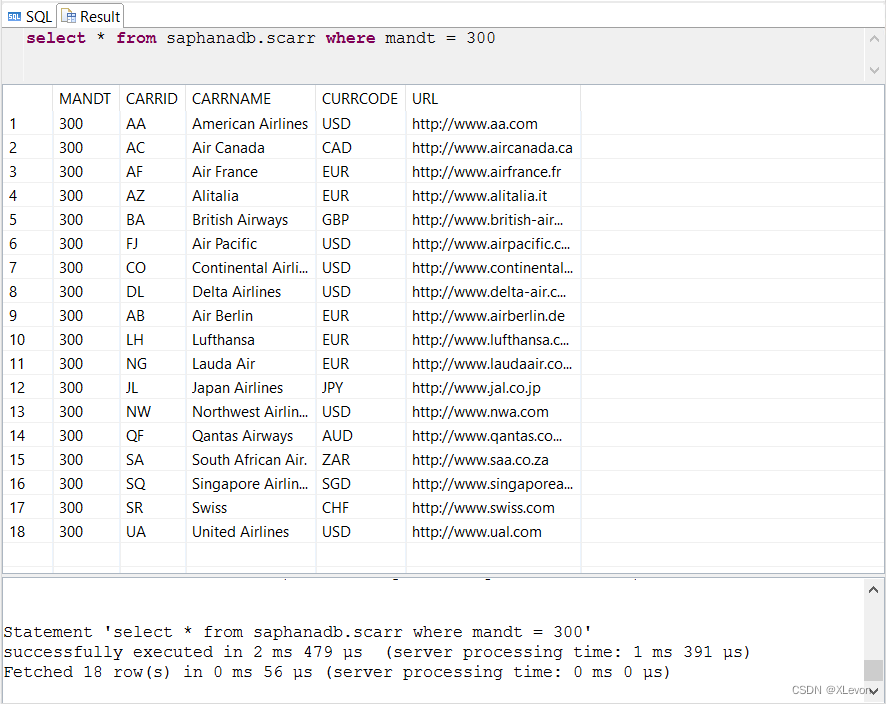
示例2:查找300客户端中的航空公司清单
select * from saphanadb.scarr where mandt = 300;
示例3:查找客户端号大于300的航空公司清单
select * from saphanadb.scarr where mandt > 300;
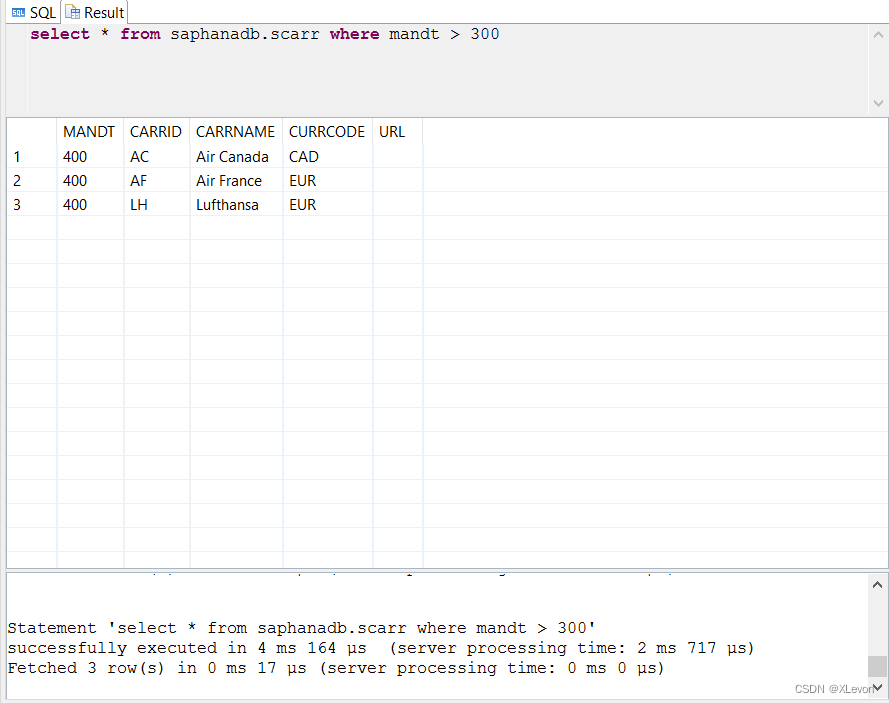
注意事项:
1、对于SAP系统中存在客户端号字段的表查询,都必须明确指定客户端号过滤条件,否则数据会出现冗余。所以后续的查询中未明确说明的,默认都查找300客户端中的数据。
2、mandt 本质是数值类型,可以直接用 300 来过滤,其他字符型,必须要加上单引号,否则会报错。
(5)WHERE CLAUSE
** LIKE:一般与通配符结合使用,用于模糊匹配查询。**
** AND & OR:用于逻辑表达式中,如WHERE中,组合多个条件查询。**
** BETWEEN AND:用于限定一个有序值范围(从小到大)。**
** IN:用于指定一个无序值范围。**
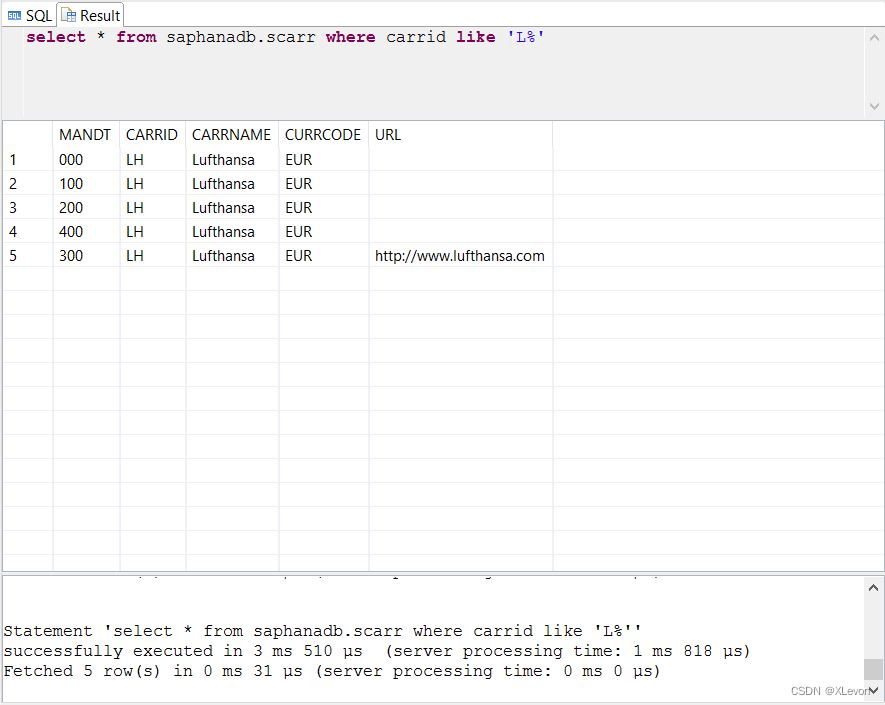
示例1:查找代码是L开头的航空公司清单
select * from saphanadb.scarr where carrid like 'L%';
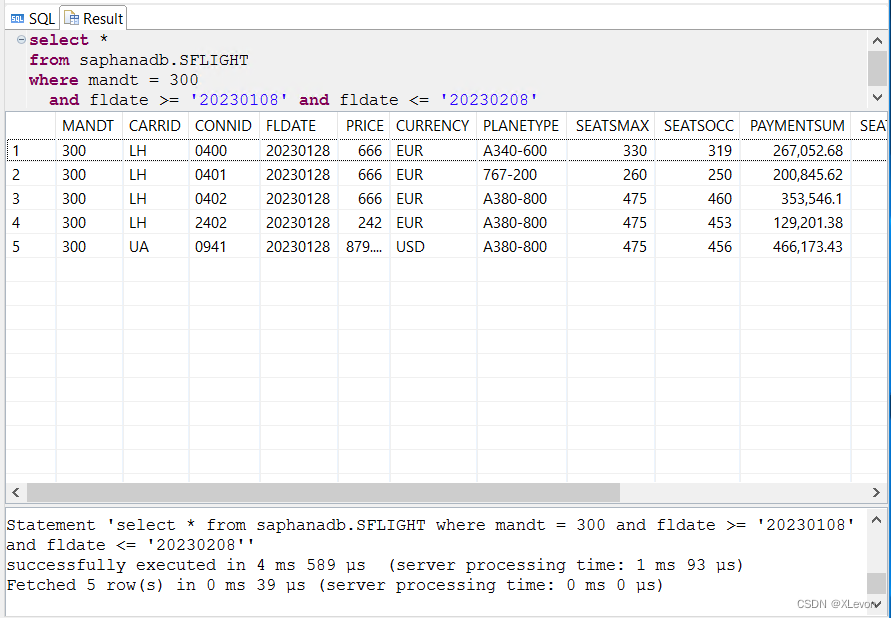
示例2:查找未来一个月的航班信息。
select *
from saphanadb.SFLIGHT
where mandt = 300
and fldate >= '20230108' and fldate <= '20230208';
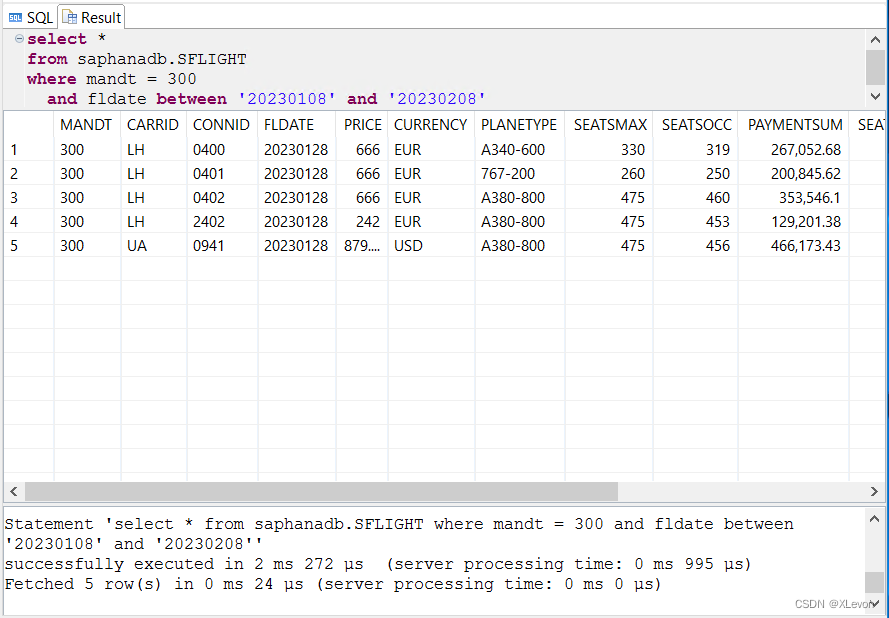
-- 或者:
select *
from saphanadb.SFLIGHT
where mandt = 300
and fldate between '20230108' and '20230208';
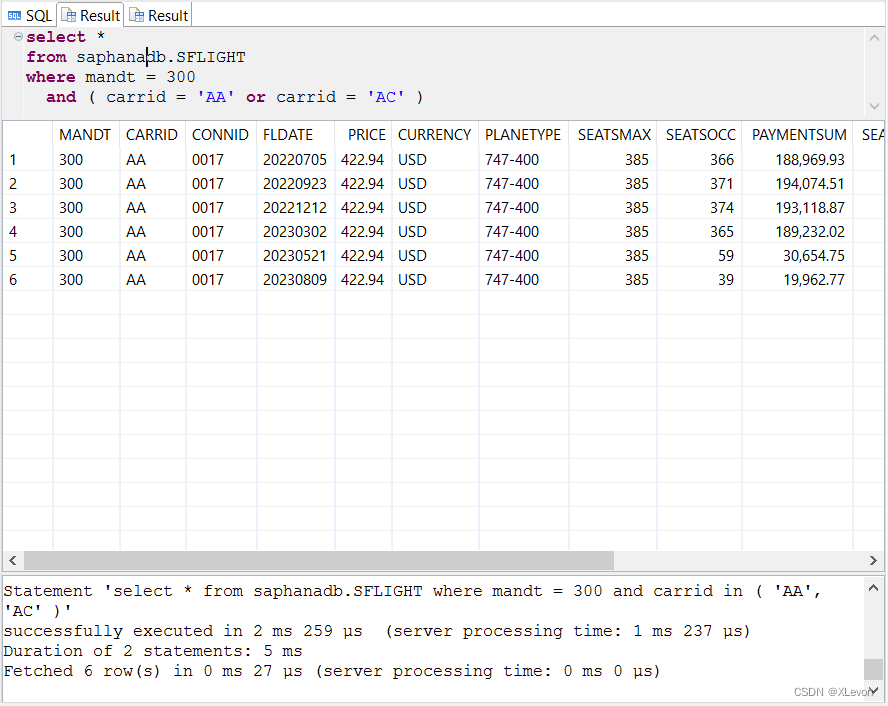
示例3:查找美国(AA)、加拿大(AC)航空公司的航班信息。
select *
from saphanadb.SFLIGHT
where mandt = 300
and ( carrid = 'AA' or carrid = 'AC' ); -- 注意:此处需要有 ()
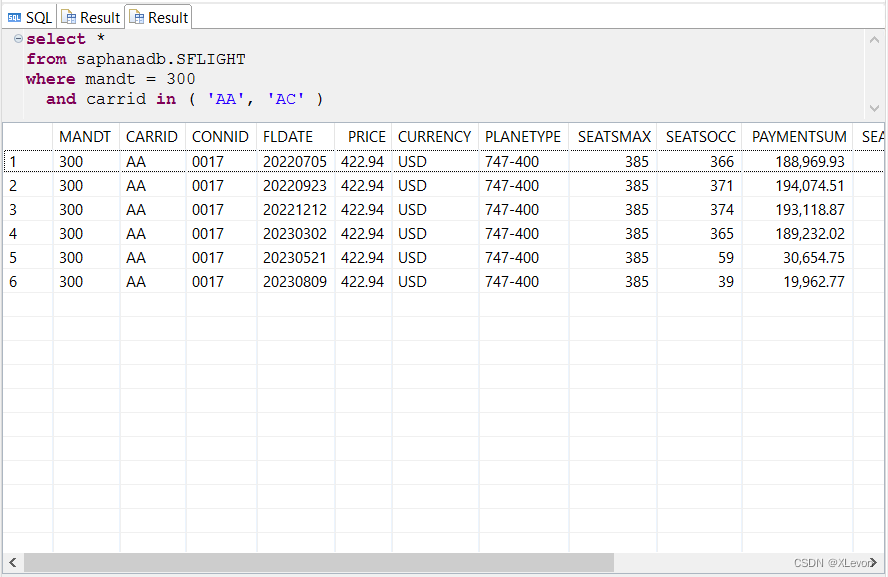
-- 或者:
select *
from saphanadb.SFLIGHT
where mandt = 300
and carrid in ( 'AA', 'AC' );
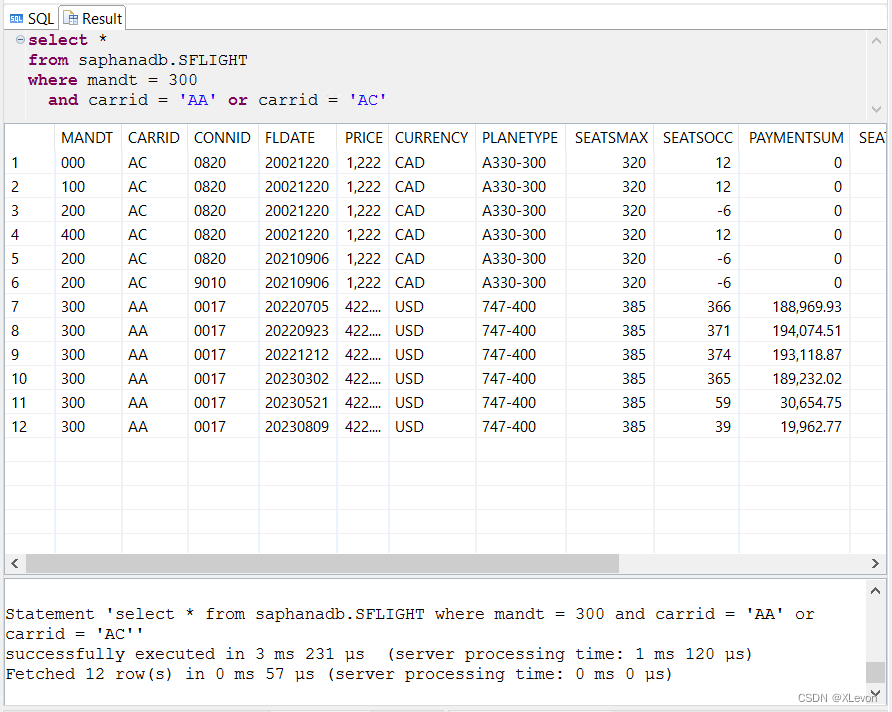
对比:错误逻辑
select *
from saphanadb.SFLIGHT
where mandt = 300
and carrid = 'AA' or carrid = 'AC'; -- 注意:此处没有 ()
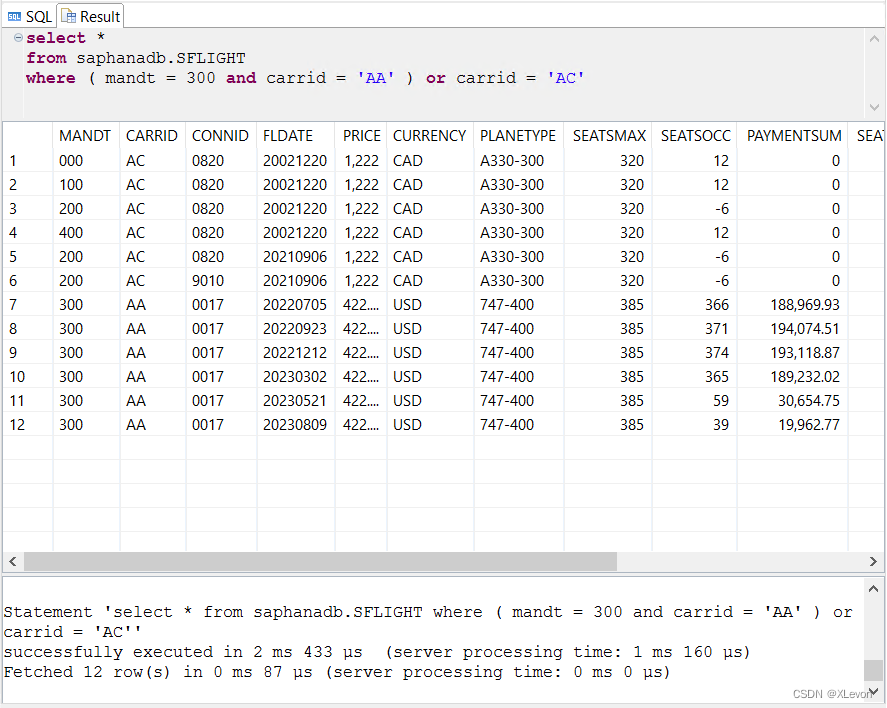
-- 等同以下逻辑:
select *
from saphanadb.SFLIGHT
where ( mandt = 300 and carrid = 'AA' ) or carrid = 'AC';
注意事项:
1、Between A and B 中,A≤B,否则数据结果为空。
2、多个 And 和 Or 条件组合时,必要的时候需要增加“( )”来控制逻辑的准确性。
(6)ORDER BY
ORDER BY:用于对查询结果排序,可以指定一个或多个字段,按升序或降序排序。
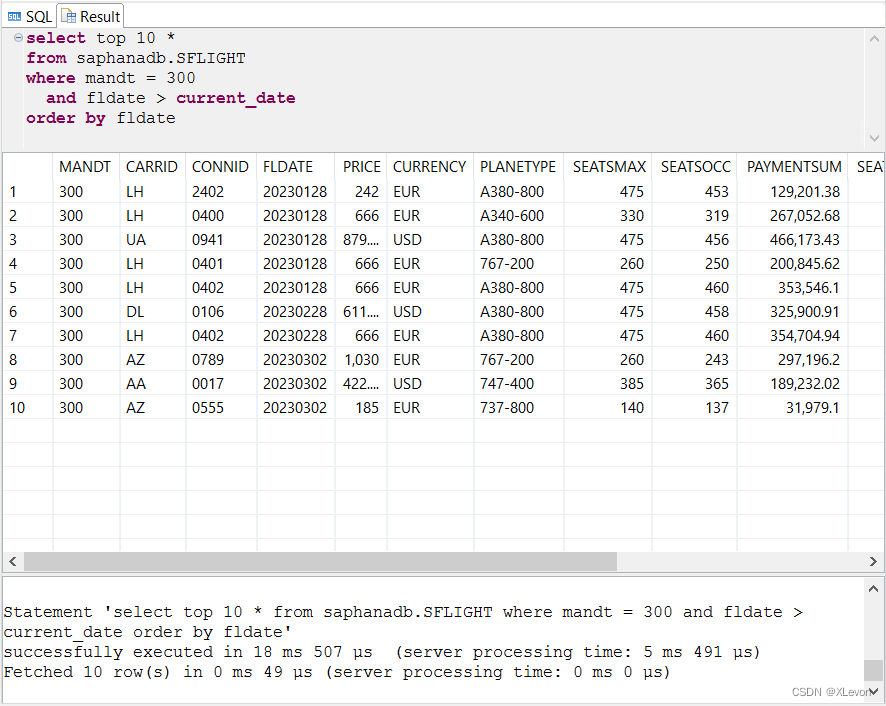
示例1:查找未来最近日期的10条航班信息。
select top 10 *
from saphanadb.SFLIGHT
where mandt = 300
and fldate > current_date -- current_date 系统当前日期
order by fldate;
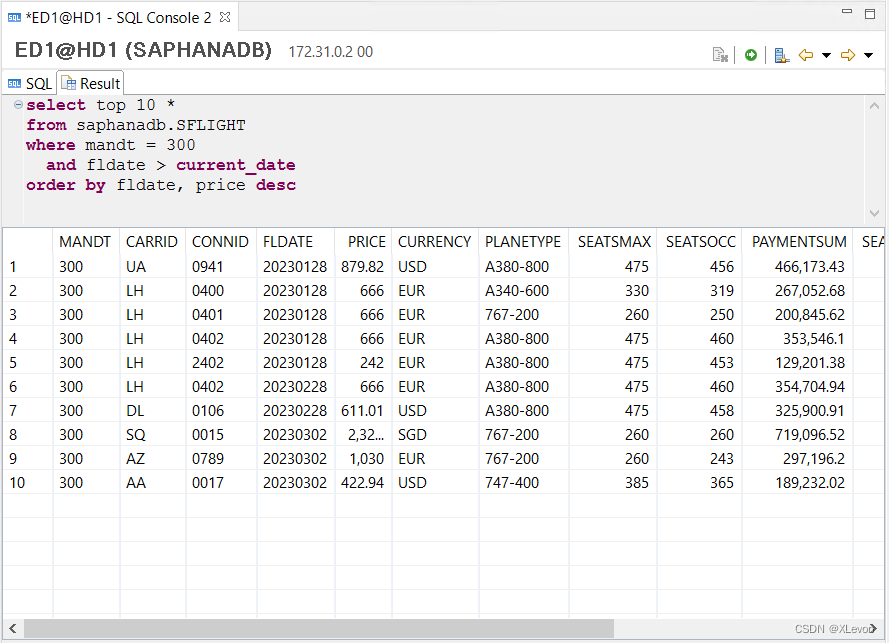
示例2:查找未来最近日期的10条航班信息,如果是同一天的则按价格有高到底排序。
select top 10 *
from saphanadb.SFLIGHT
where mandt = 300
and fldate > current_date -- current_date 系统当前日期
order by fldate, price desc;
注意事项:
1、默认按升序(asc)排序,可选按降序(desc)排序;
2、可以按多个字段排序,左边的排序优先级高于右边的;
3、可以针对列或聚合函数的别名来排序。
(7)FUNCTION
SQL预置的一些标准值函数,用于返回值,如count()、sum()、max()、min()、round()等。
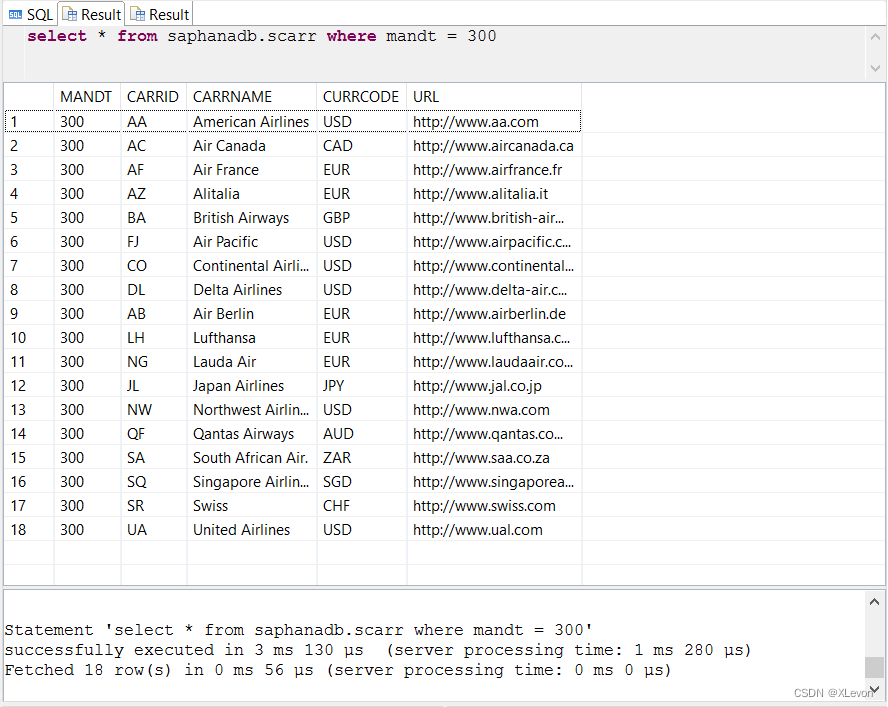
示例1:查看系统中航空公司清单,并统计系统中航空公司数量
select * from saphanadb.scarr where mandt = 300;
select count(*) as carr_count
from saphanadb.scarr
where mandt = 300;

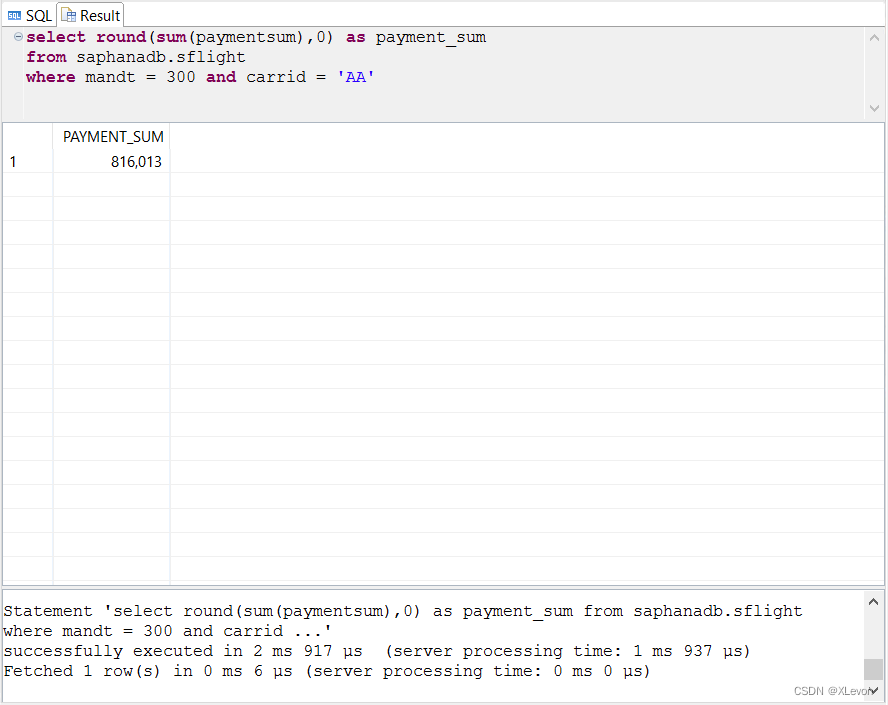
示例2:统计美国航空公司(AC)航班已预定金额总额,并且保留0位小数
select round( sum(paymentsum), 0 ) as payment_sum
from saphanadb.sflight
where mandt = 300 and carrid = 'AA';
注意事项:
1、值函数表示的列一般都需要起列别名(Alias)。
(8)GROUP BY
GROUP BY:一般和聚合函数结合使用,用于分组统计。
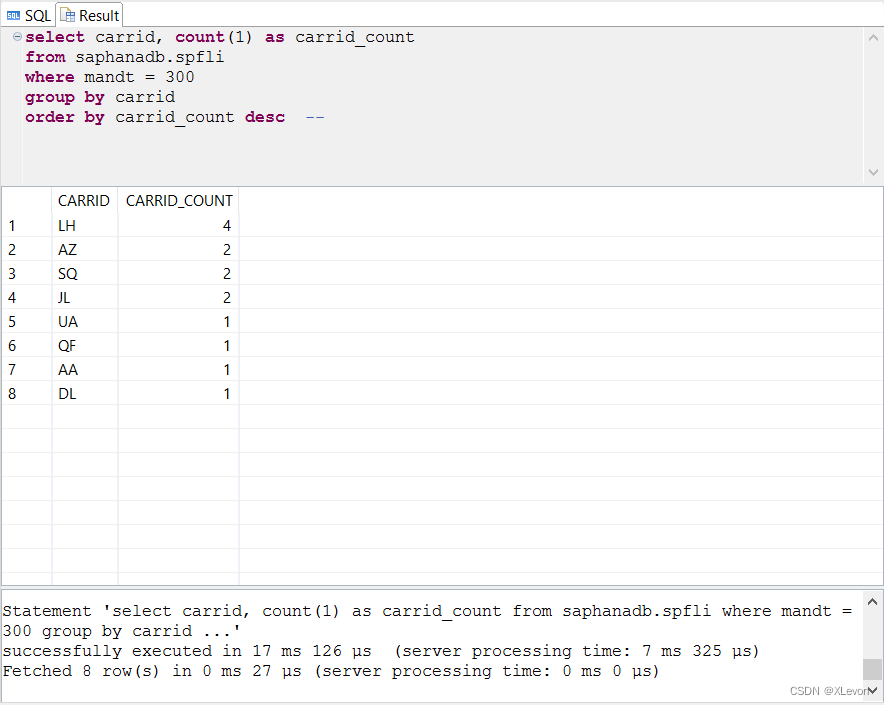
示例1:统计每家航空公司的航线数量,并且由高到低排序。
select carrid, count(1) as carrid_count
from saphanadb.spfli
where mandt = 300
group by carrid
order by carrid_count desc;
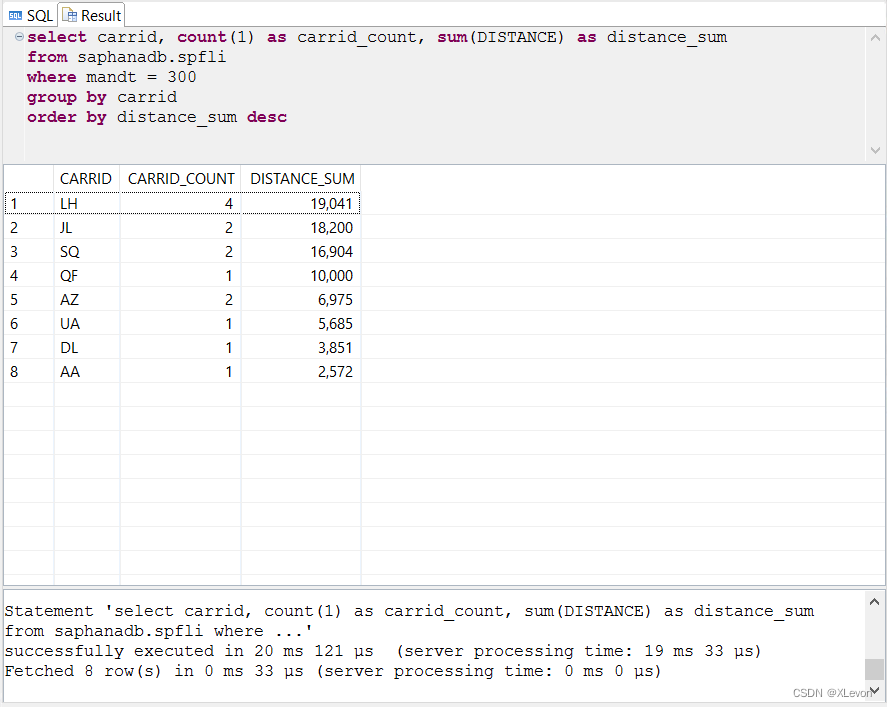
示例2:统计每家航空公司的航线数量和总里程数,并且按总里程数由高到低排序。
select carrid, count(1) as carrid_count, sum(DISTANCE) as distance_sum
from saphanadb.spfli
where mandt = 300
group by carrid
order by distance_sum desc;
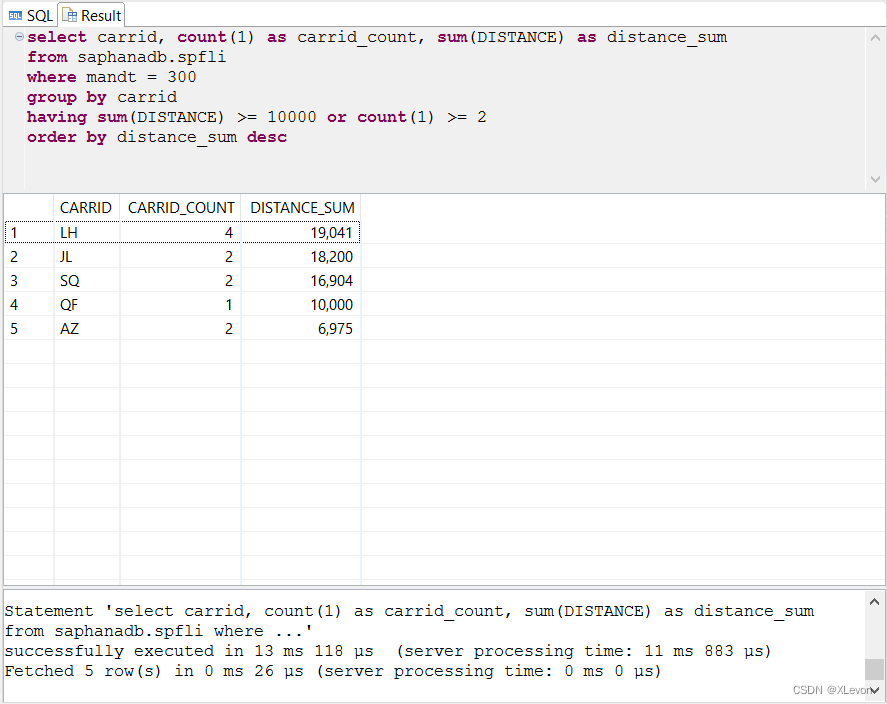
(9)HAVING
HAVING:用于对聚合函数做条件查询。
示例1:查找总里程数大于等于10000或者航线数量大于等于2的航空公司名单,并且按总里程数由高到低排序。
select carrid, count(1) as carrid_count, sum(DISTANCE) as distance_sum
from saphanadb.spfli
where mandt = 300
group by carrid
having sum(DISTANCE) >= 10000 or count(1) >= 2
order by distance_sum desc;
对比:错误写法
select carrid, count(1) as carrid_count, sum(DISTANCE) as distance_sum
from saphanadb.spfli
where mandt = 300
and ( sum(DISTANCE) >= 10000 or count(1) >= 2 )
group by carrid
order by distance_sum desc;
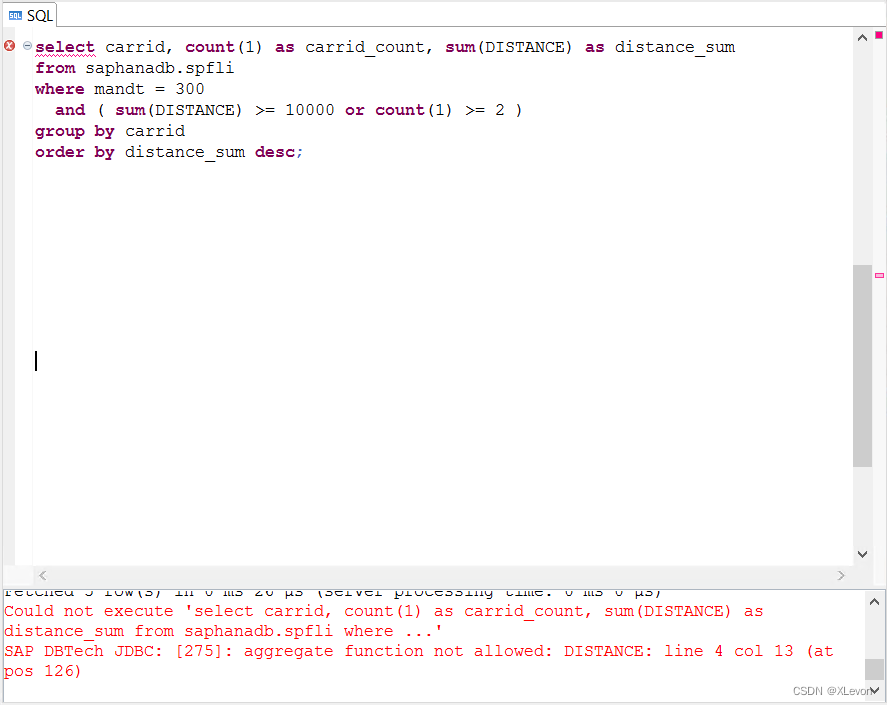
注意事项:
1、聚合函数过滤条件,不能放在where从句中,必须放在having从句中;
2、having从句中,不能使用聚合函数别名,必须书写完整的聚合函数;
3、order by从句中,可以使用列别名、聚合函数别名。
(10)CREATE
CREATE:用于创建数据库对象,如数据库表TABLE、视图VIEW、函数FUNCTION、存储过程PROCEDURE、索引INDEX、约束CONSTAINT等。
Hana Studio 查找 数据库表 Scarr,右键 Open Defintion 或者 双击表名,查看表定义,表名上右键 → Export SQL
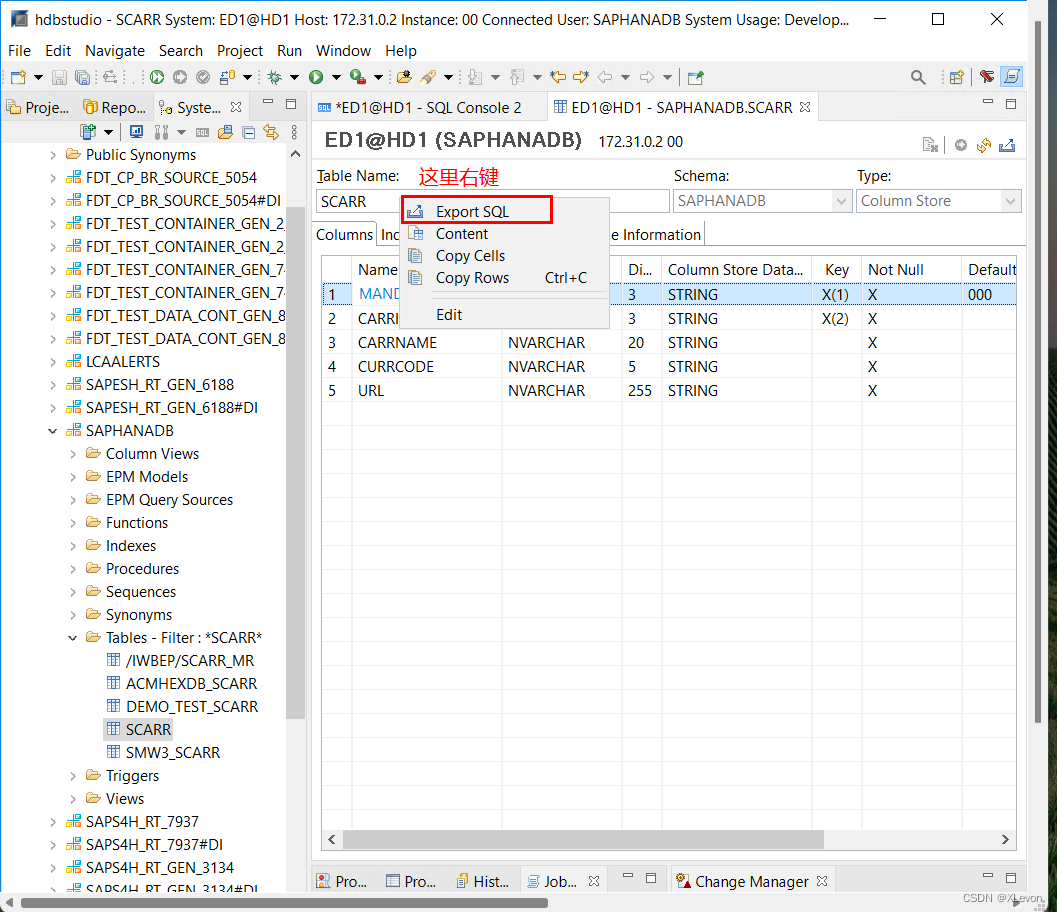
获得该表的创建脚本,如下:
CREATE COLUMN TABLE "SAPHANADB"."SCARR"
(
"MANDT" NVARCHAR(3) DEFAULT '000' NOT NULL ,
"CARRID" NVARCHAR(3) DEFAULT '' NOT NULL ,
"CARRNAME" NVARCHAR(20) DEFAULT '' NOT NULL ,
"CURRCODE" NVARCHAR(5) DEFAULT '' NOT NULL ,
"URL" NVARCHAR(255) DEFAULT '' NOT NULL ,
CONSTRAINT "SCARR~0" PRIMARY KEY ("MANDT", "CARRID")
) UNLOAD PRIORITY 5 AUTO MERGE
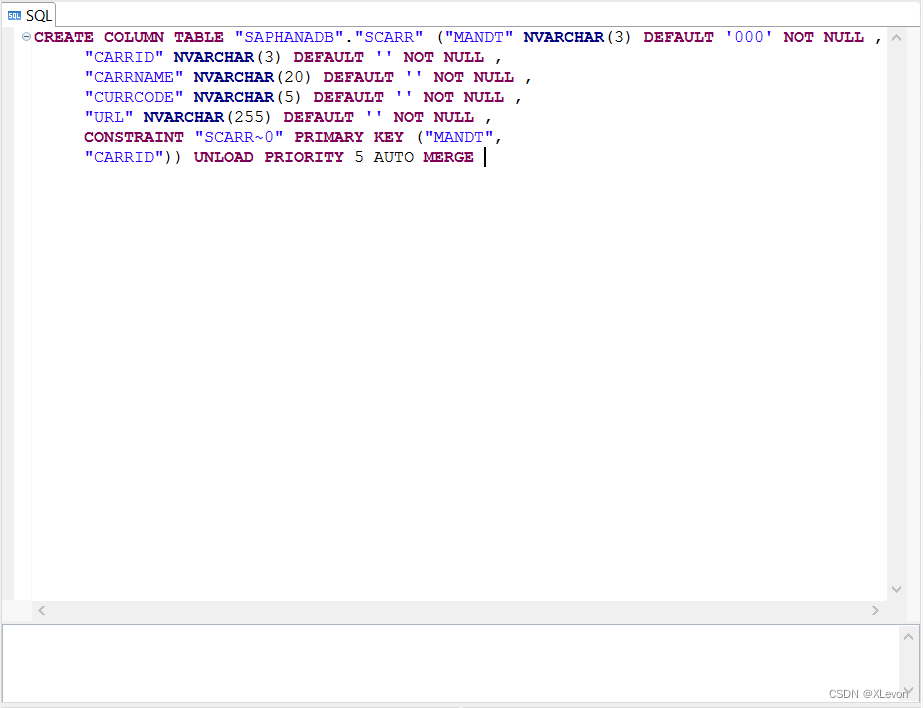
调整以上脚本,更改表名、字段名,执行,即可创建新的数据库表。
CREATE COLUMN TABLE "SAPHANADB"."ZSCARR"
(
"ZMANDT" NVARCHAR(3) DEFAULT '000' NOT NULL ,
"ZCARRID" NVARCHAR(3) DEFAULT '' NOT NULL ,
"ZCARRNAME" NVARCHAR(20) DEFAULT '' NOT NULL ,
"ZCURRCODE" NVARCHAR(5) DEFAULT '' NOT NULL ,
"ZURL" NVARCHAR(255) DEFAULT '' NOT NULL ,
CONSTRAINT "ZSCARR~0" PRIMARY KEY ("ZMANDT", "ZCARRID") --创建关键字约束
)
查询验证一下:
select * from saphanadb.zscarr
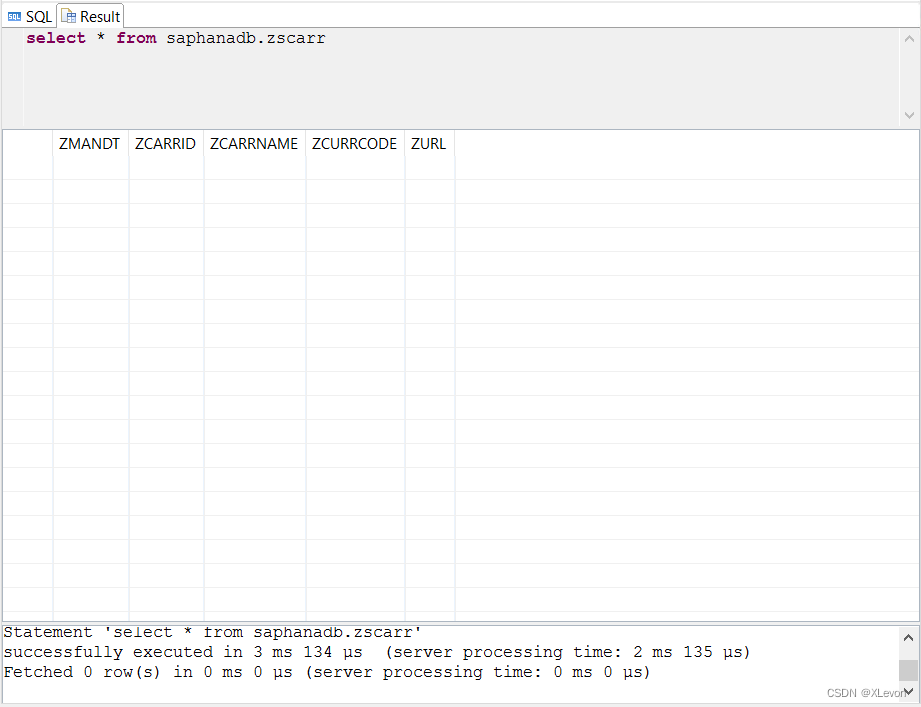
数据库表ZSCARR,已经创建成功,目前数据记录为空。
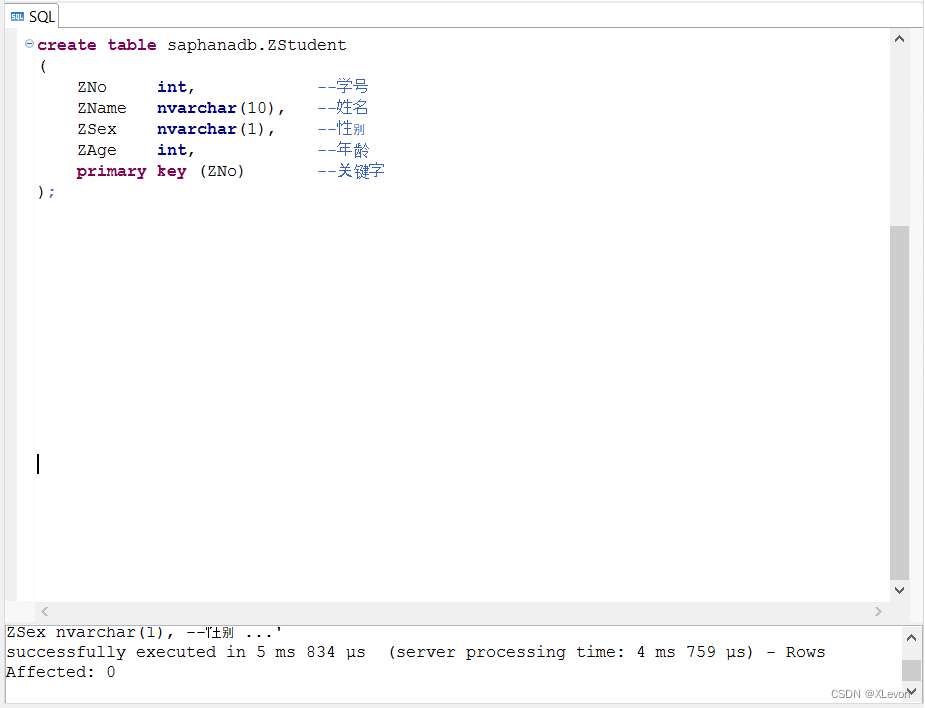
示例1:创建一张学生表ZStudent,包括学号ZNo,姓名ZName,性别ZSex,年龄ZAge。
create table saphanadb.ZStudent
(
ZNo int, --学号
ZName nvarchar(10), --姓名
ZSex nvarchar(1), --性别
ZAge int, --年龄
primary key (ZNo) --关键字
);
注意事项:
1、一般情况,对于SAPHANADB库,业务顾问只会被授予访问权限,即只能进行数据库查询操作(SELECT),而不会授予CREATE、INSERT、UPDATE、DROP等操作权限,故只做了解即可。
2、在用户登录账号同名的SCHEMA中,用户具备所有的操作权限。
3、SAP HANA 支持列式存储(列表,column table)和行式存储(行表,table),其他数据库一般只支持行表,故建表语句为:Create table。
(11)INSERT
INSERT:用于往表里插入数据。
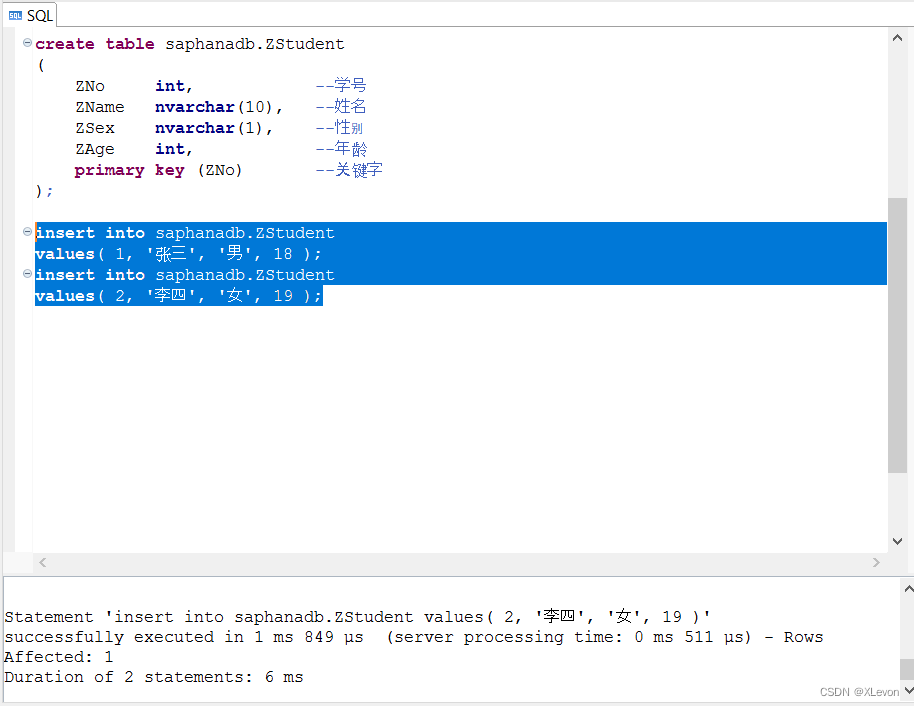
示例1:往自建的学生表ZStudent,插入几个学生记录。
insert into saphanadb.ZStudent
values( 1, '张三', '男', 18 );
insert into saphanadb.ZStudent
values( 2, '李四', '女', 19 );
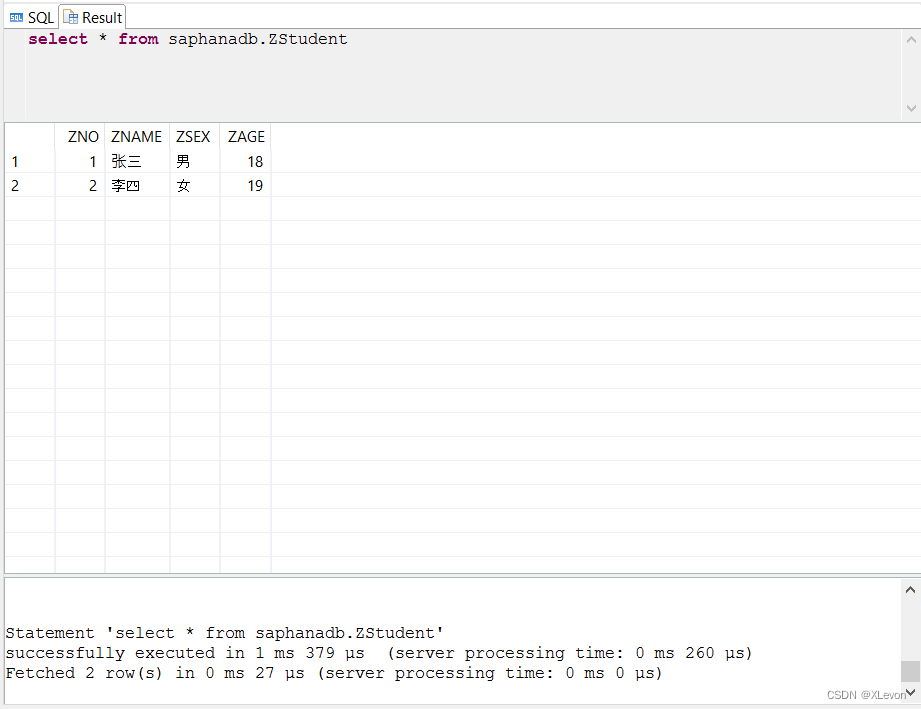
查询验证一下:
select * from saphanadb.ZStudent;
技巧:
1、Hana sql 编辑器,支持对选中的部分sql进行执行操作。
(12)UPDATE
UPDATE:用于更新表数据。
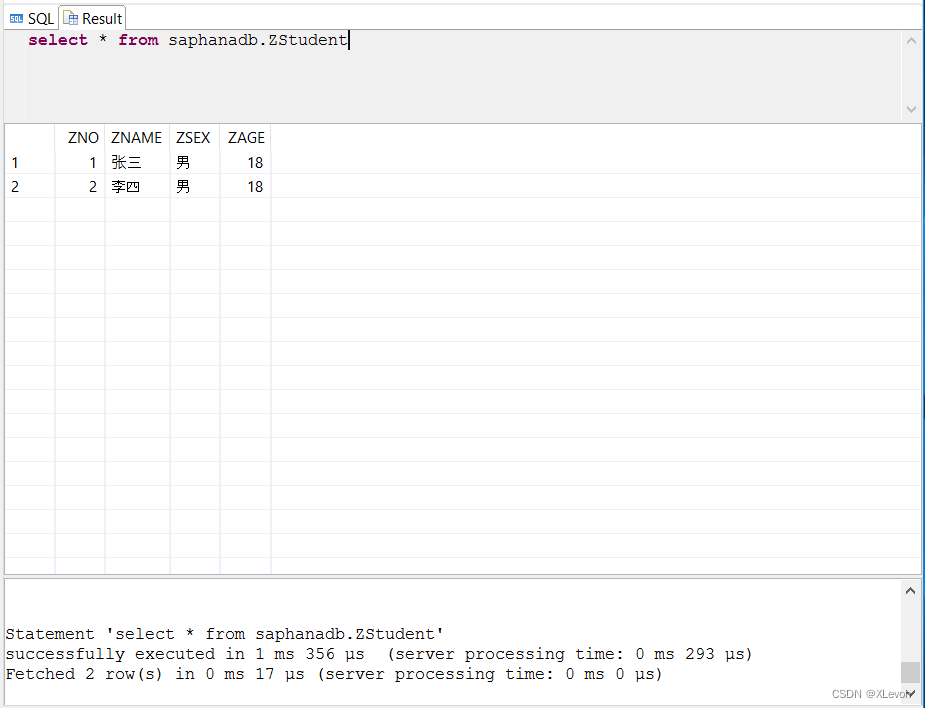
示例1:更新学生表里李四同学的性别为男,年龄为18。
update saphanadb.ZStudent
set zsex = '男', zage = 18
where zname = '李四';

查询验证一下:
select * from saphanadb.ZStudent;
(13)DELETE / TRUNCATE
DELETE:用于删除表记录,支持WHERE条件删除。
TRUNCATE:用于清空表,即删除表所有记录,不支持WHERE条件。
示例1:删除学生表里学号为1的记录。
delete from saphanadb.ZStudent where zno = 1;
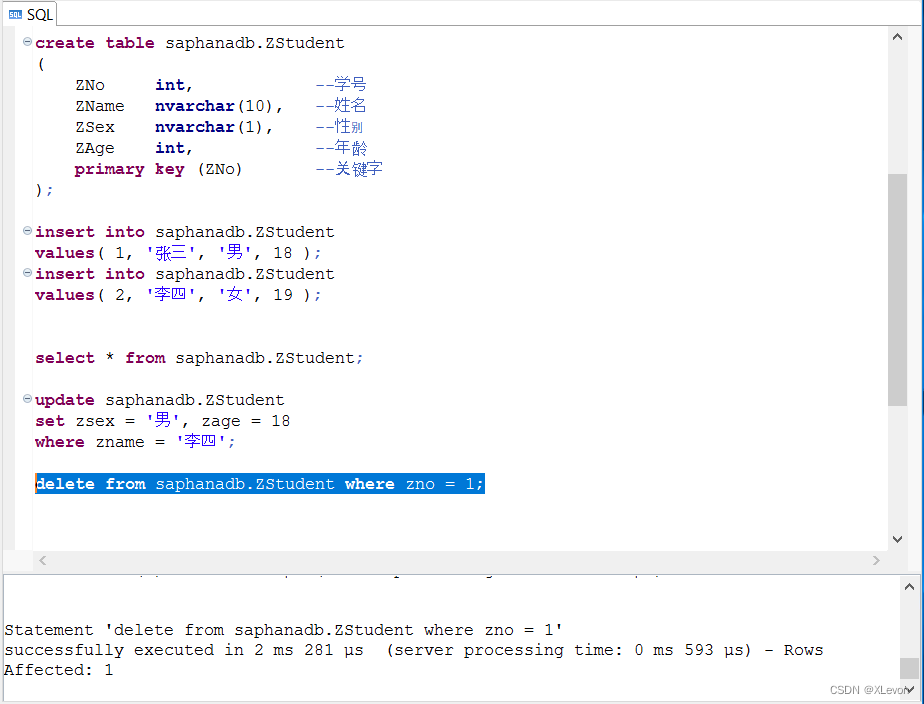
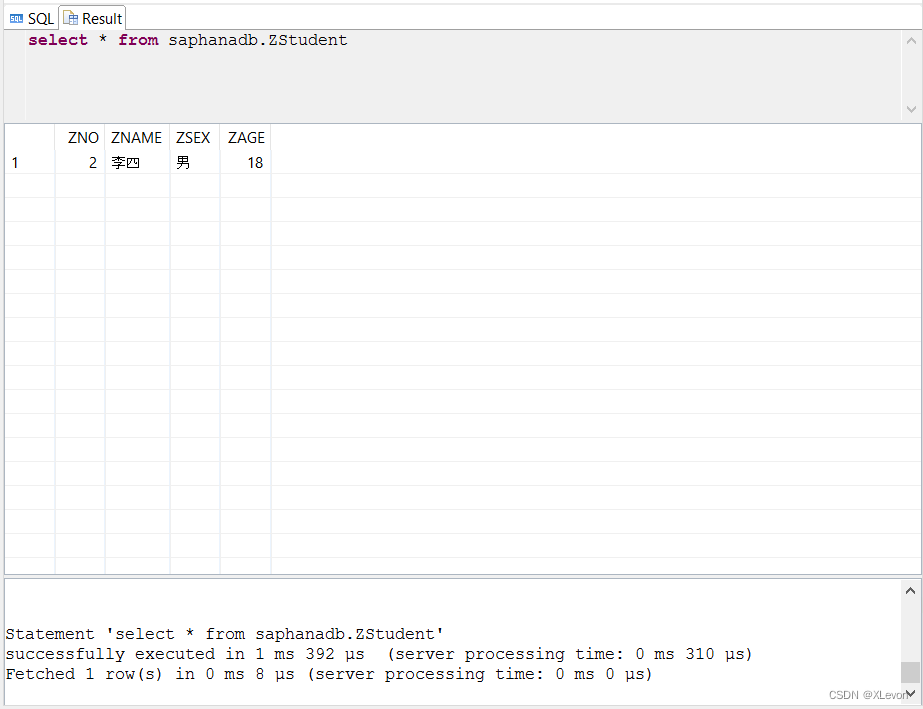
查询验证一下:
select * from saphanadb.ZStudent;
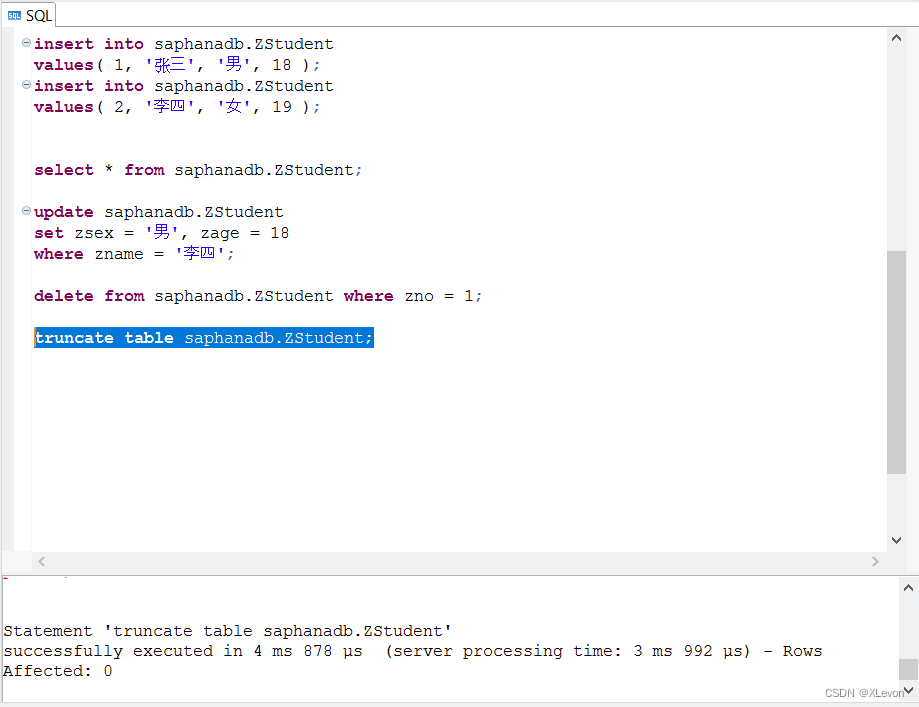
示例2:清空学生表。
delete * from saphanadb.ZStudent;
--或者:
truncate table saphanadb.ZStudent;
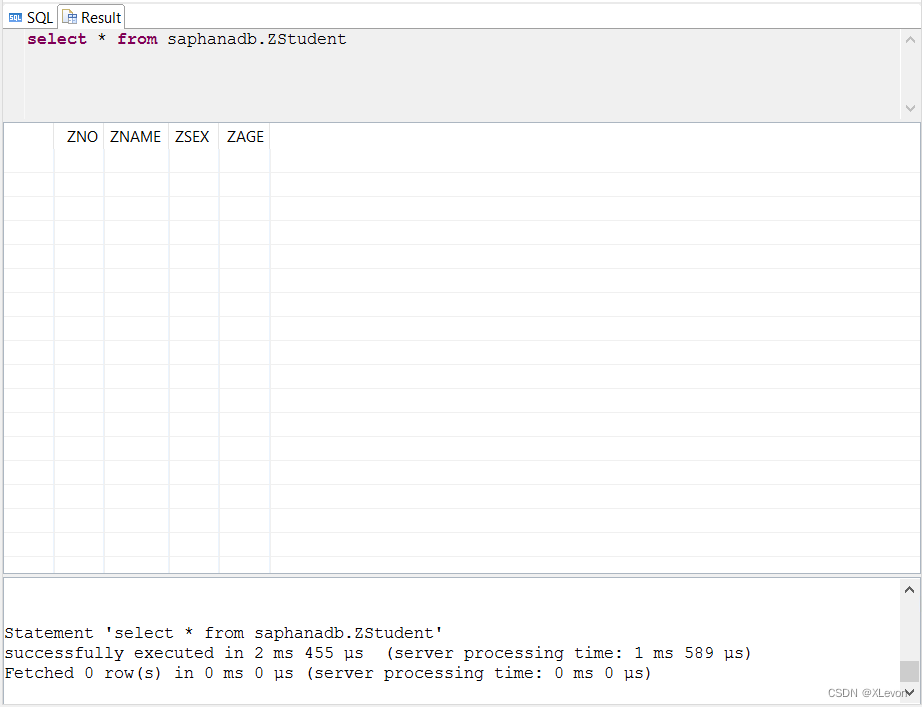
查询验证一下:
select * from saphanadb.ZStudent;
注意事项:delete和truncate的区别
- 条件删除
这个比较好理解,因为delete是可以带WHERE的,所以支持条件删除;而truncate只能删除整个表。 - 事务回滚
由于delete是数据操作语言(DML - Data Manipulation Language),操作时原数据会被放到 rollback segment中,可以被回滚;而truncate是数据定义语言(DDL - Data Definition Language),操作时不会进行存储,不能进行回滚。 - 清理速度
在数据量比较小的情况下,delete和truncate的清理速度差别不是很大。但是数据量很大的时候就能看出区别。由于第二项中说的,truncate不需要支持回滚,所以使用的系统和事务日志资源少。delete 语句每次删除一行,并在事务日志中为所删除的每行记录一项,固然会慢,但是相对来说也较安全。 - 高水位重置
随着不断地进行表记录的DML操作,会不断提高表的高水位线(HWM),delete操作之后虽然表的数据删除了,但是并没有降低表的高水位,随着DML操作数据库容量也只会上升,不会下降。所以如果使用delete,就算将表中的数据减少了很多,在查询时还是很和delete操作前速度一样。
而truncate操作会重置高水位线,数据库容量也会被重置,之后再进行DML操作速度也会有提升。
(14)DROP
DROP:用于删除数据库对象,与CREATE相对。
示例1:删除学生表。
drop table saphanadb.ZStudent;
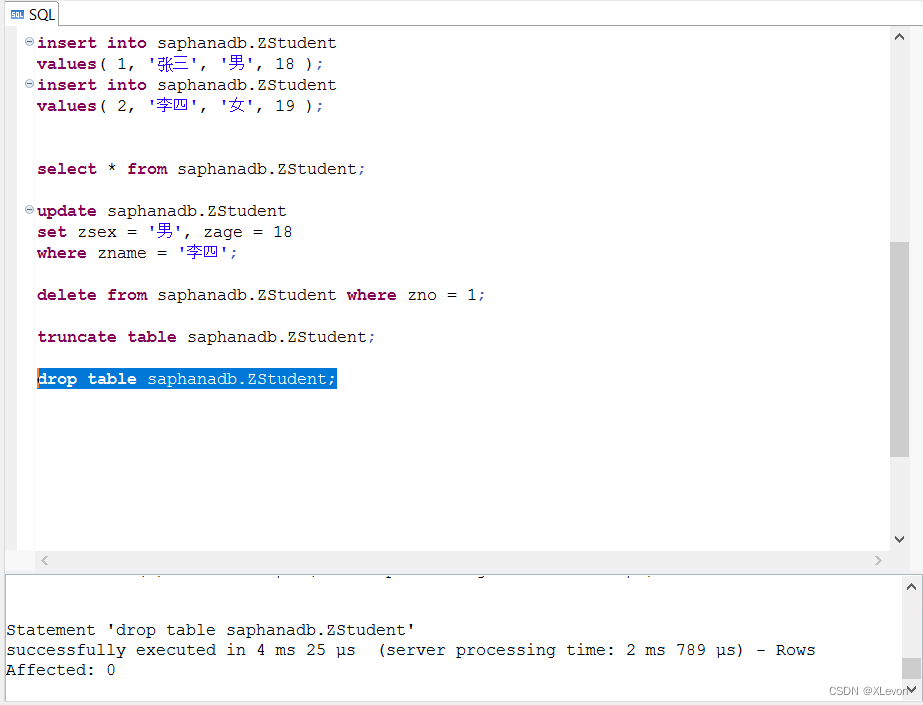
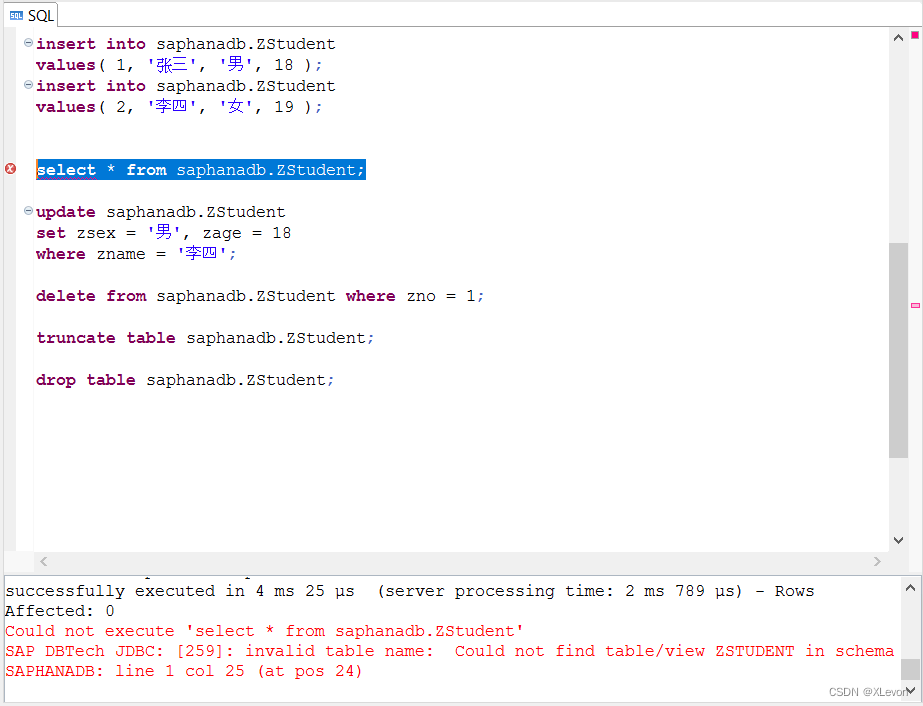
查询验证一下:
select * from saphanadb.ZStudent;
(15)UNION
UNION:操作符用于合并两个或多个 SELECT 语句的结果集,重复的结果只保留一行。
UNION ALL:操作符用于合并两个或多个 SELECT 语句的结果集,保留重复的结果行。
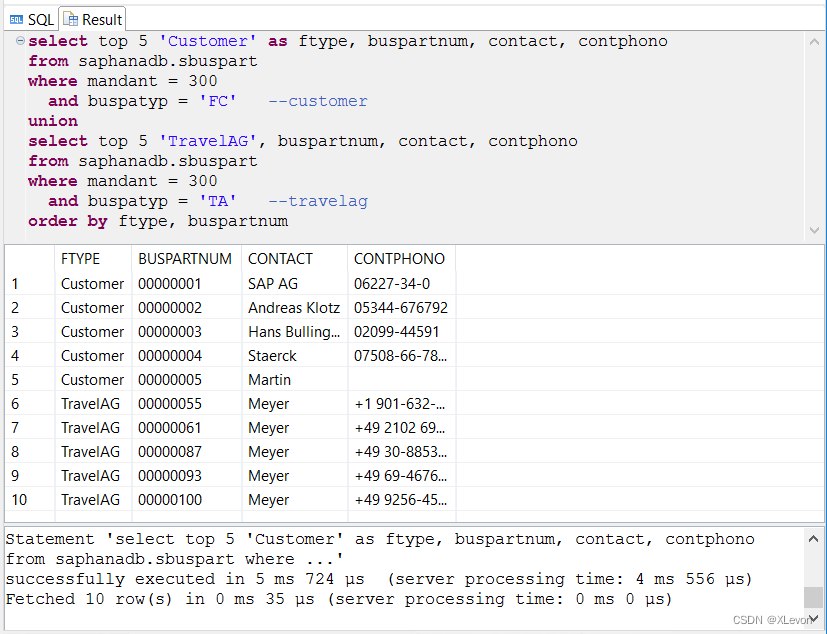
示例1:查询航空公司业务伙伴中的乘客与旅行社各前5名的编码和联系信息,乘客在前,旅行社在后显示。
select top 5 'Customer' as ftype, buspartnum, contact, contphono
from saphanadb.sbuspart
where mandant = 300
and buspatyp = 'FC' --customer
union all
select top 5 'TravelAG', buspartnum, contact, contphono
from saphanadb.sbuspart
where mandant = 300
and buspatyp = 'TA' --travelag
order by ftype, buspartnum; --注:ftype的值在排序时需要符合乘客在前,旅行社在后
注意事项:
1、UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。UNION 结果集中的列名总是以 UNION 中第一个 SELECT 语句中的列名为准。
2、UNION 操作符选取不同的记录。如果允许重复的记录,请使用 UNION ALL。
3、需要合并的结果集记录量比较大时,UNION ALL 较 UNION 效率更高,因为省去了判重校验。
(16)SUB SELECT
SUB SELECT:子查询(又叫 Sub Query),是一种嵌套在其他 SQL 查询中的查询语句。一般结合IN、EXISTS使用。
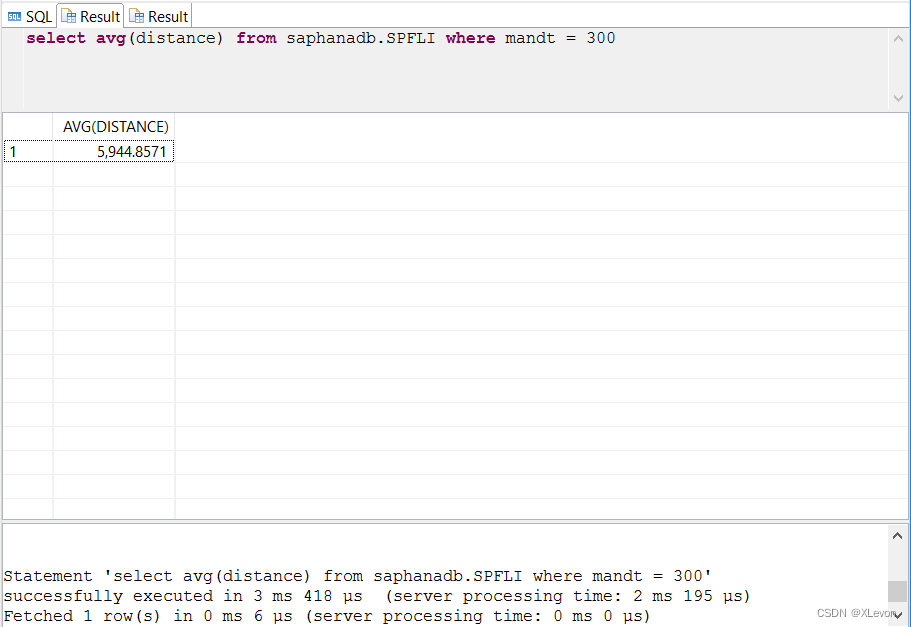
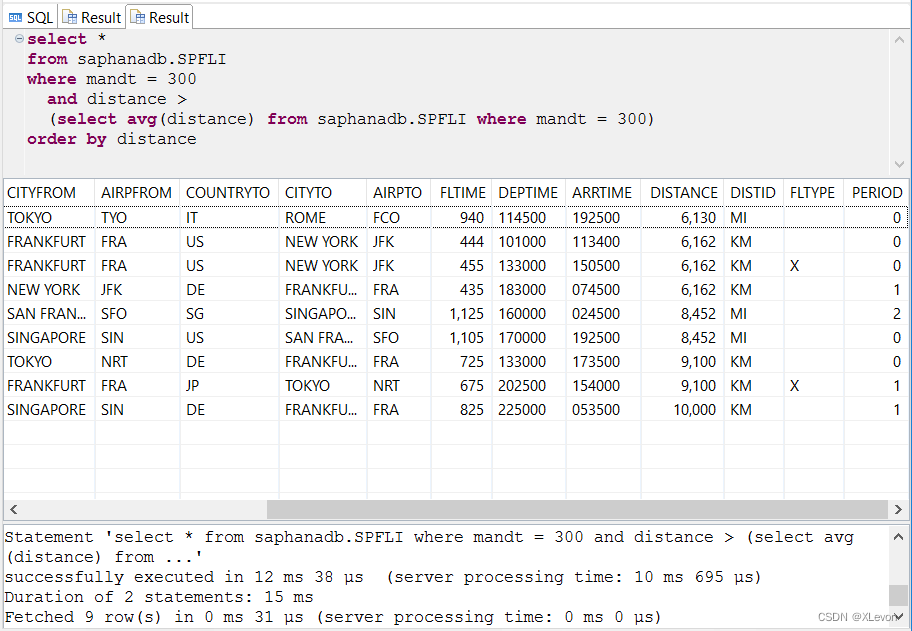
示例1:(用在 WHERE子 句中,作为过滤条件值)计划航线的平均里程数,并列出大于平均里程数的航线清单。
select avg(distance) from saphanadb.SPFLI where mandt = 300;
select *
from saphanadb.SPFLI
where mandt = 300
and distance >
(select avg(distance) from saphanadb.SPFLI where mandt = 300)
order by distance;
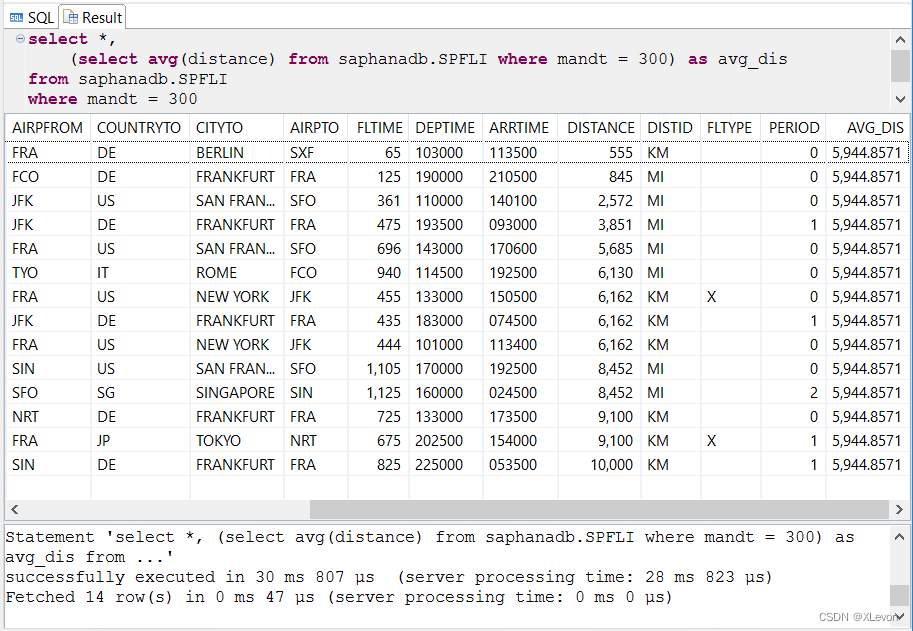
示例2:(用在 SELECT 子句中,作为自定义列)显示所有航程信息,并按里程数从小到大排列,同时增加一个所有航线的平均里程数。
select *,
(select avg(distance) from saphanadb.SPFLI where mandt = 300) as avg_dis
from saphanadb.SPFLI
where mandt = 300
order by distance;
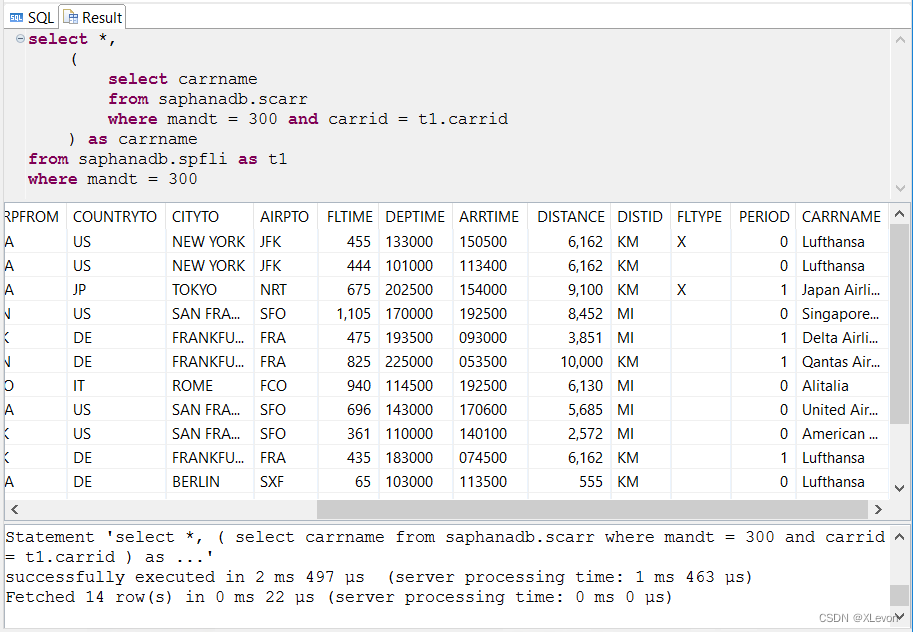
示例3:(用在 SELECT 子句中,作为自定义列)显示航线信息,并且关联显示航空公司名称。
select *,
(
select carrname
from saphanadb.scarr
where mandt = 300 and carrid = t1.carrid
) as carrname
from saphanadb.spfli as t1
where mandt = 300;
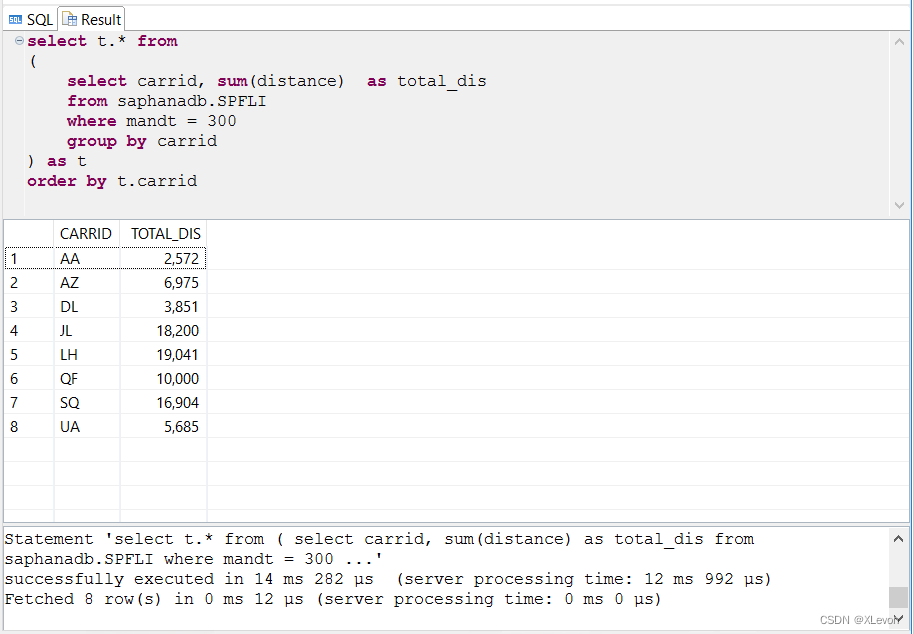
示例4:(用在 FROM 子句中,作为自定义数据源)显示航空公司的里程总数。
select t.* from
(
select carrid, sum(distance) as total_dis
from saphanadb.SPFLI
where mandt = 300
group by carrid
) as t
order by t.carrid;
注意事项:
1、子查询用于WHERE子句时,如果是比较表达式,只能返回单行单列结果;如果是IN可以返回多行单列结果,EXISTS则不关注返回的结果。
2、子查询用于SELECT列表时,只能返回单行单列结果。
3、子查询用于FROM子句时,作为一个数据源表用,可以返回多行多列结果。
(17)IN & EXISTS
IN:返回子查询的单列结果集,判断是否存在结果集中。
EXISTS:可以匹配多列,只判断存在与否,不关注子查询的列表。
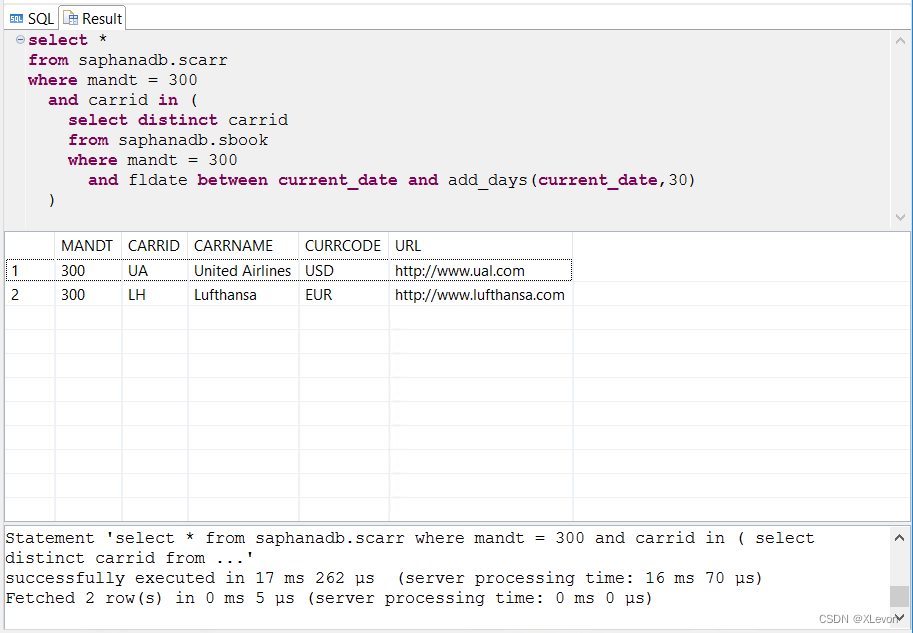
示例1:查找最近一个月有航班计划的航空公司清单。
select *
from saphanadb.scarr
where mandt = 300
and carrid in (
select distinct carrid
from saphanadb.sbook
where mandt = 300
and fldate between current_date and add_days(current_date,30)
);
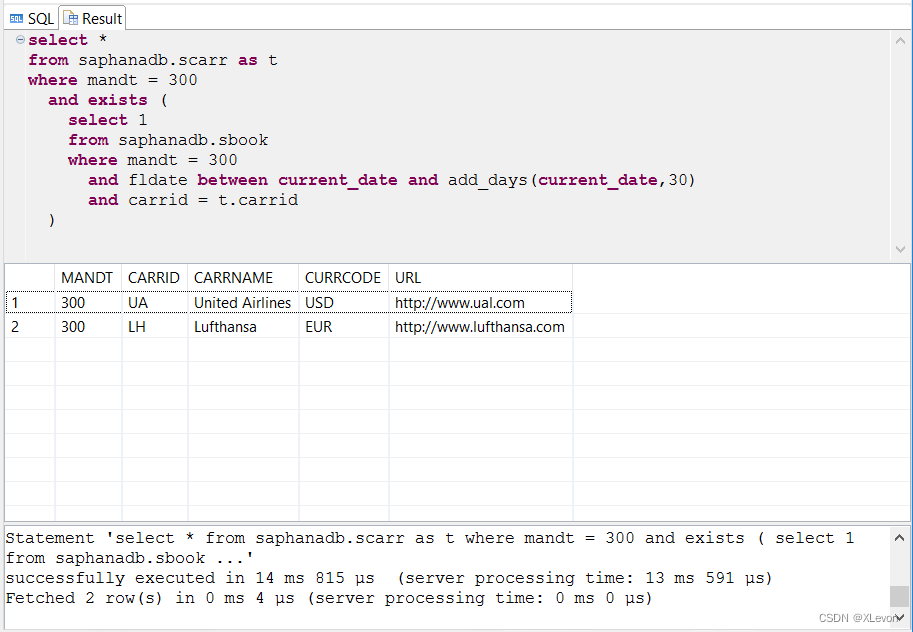
-- 或者:
select *
from saphanadb.scarr as t
where mandt = 300
and exists (
select 1
from saphanadb.sbook
where mandt = 300
and fldate between current_date and add_days(current_date,30)
and carrid = t.carrid
);
(18)JOIN
JOIN:用于多表关联查询,主要是通过键、外键等与其他表来进行关联,包括以下类型:
INNER JOIN:内连接,根据关联条件,左右表都存在的记录,才会显示,左右表记录的字段都会显示。
LEFT [OUTER] JOIN:左[外]连接,左表记录必定显示,根据关联条件,右表存在的记录,字段会追加显示在左边记录上。
RIGHT [OUTER] JOIN:右[外]连接,右表记录必定显示,根据关联条件,左表存在的记录,字段会追加显示在右表记录上。
FULL [OUTER] JOIN:全连接,存在匹配,匹配显示;同时,将各个表中不匹配的数据与空数据行匹配进行显示。可以看成是左外连接与右外连接的并集。
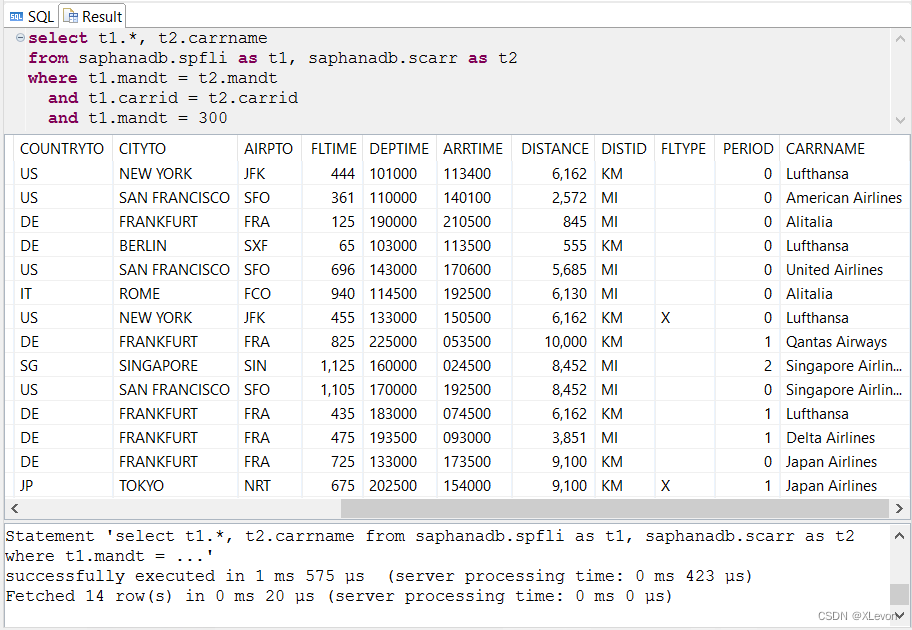
示例1:显示航线信息,同时关联显示航空公司名称。
select t1.*, t2.carrname
from saphanadb.spfli as t1, saphanadb.scarr as t2
where t1.mandt = t2.mandt
and t1.carrid = t2.carrid
and t1.mandt = 300;
-- 或者:
select t1.*, t2.carrname
from saphanadb.spfli as t1
inner join saphanadb.scarr as t2
on t1.mandt = t2.mandt and t1.carrid = t2.carrid
where t1.mandt = 300;

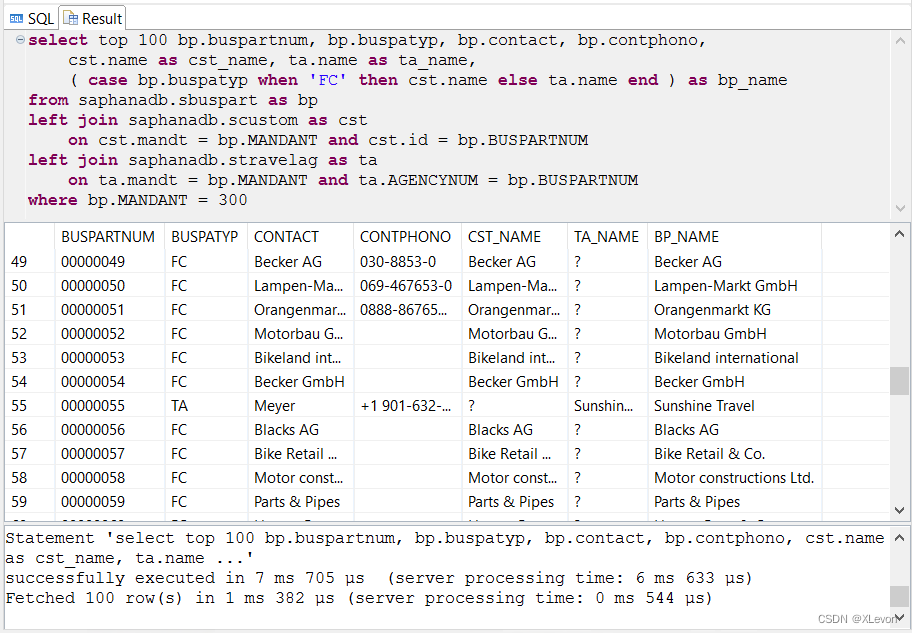
示例2:显示航空公司业务伙伴的名称( CASE 判断 )。
select top 100 bp.buspartnum, bp.buspatyp, bp.contact, bp.contphono,
cst.name as cst_name, ta.name as ta_name,
( case bp.buspatyp when 'FC' then cst.name else ta.name end ) as bp_name
from saphanadb.sbuspart as bp
left join saphanadb.scustom as cst
on cst.mandt = bp.MANDANT and cst.id = bp.BUSPARTNUM
left join saphanadb.stravelag as ta
on ta.mandt = bp.MANDANT and ta.AGENCYNUM = bp.BUSPARTNUM
where bp.MANDANT = 300;
注意事项:
1、进行JOIN时,左右表关联条件必须完整,否则会出现笛卡尔积,导致数据冗余错误。
2、比较常用的是内连接、左外连接,其他可以按需自行百度。
(19)NULL
NULL:当数据库字段值为空时,存储的是NULL值,NULL不能直接比较、参与运算。
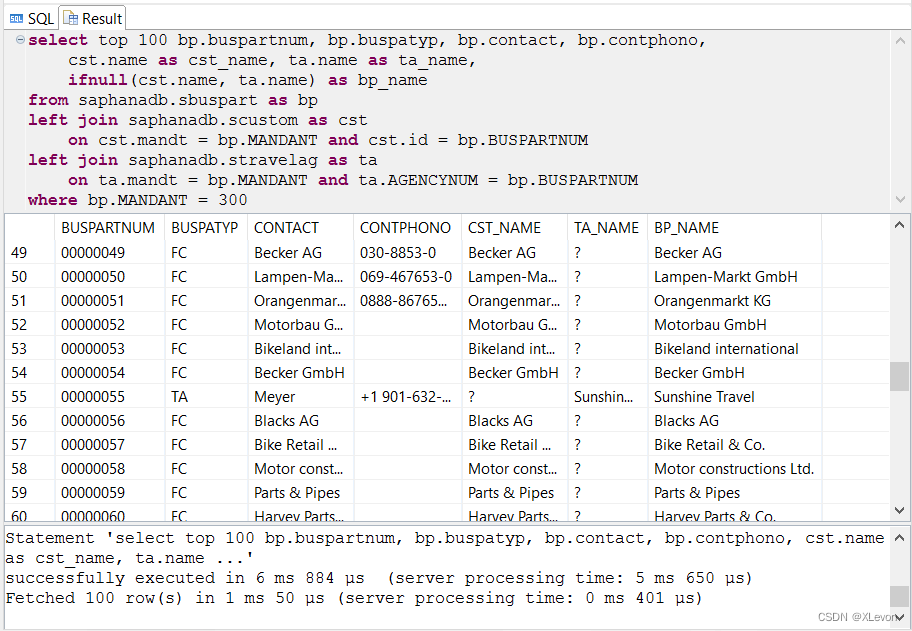
示例1:显示航空公司业务伙伴的名称(IFNULL 判断 )。
select top 100 bp.buspartnum, bp.buspatyp, bp.contact, bp.contphono,
cst.name as cst_name, ta.name as ta_name,
ifnull(cst.name, ta.name) as bp_name
-- 或者:COALESCE(cst.name, ta.name) as bp_name -- ABAP OPEN SQL仅支持该函数
from saphanadb.sbuspart as bp
left join saphanadb.scustom as cst
on cst.mandt = bp.MANDANT and cst.id = bp.BUSPARTNUM
left join saphanadb.stravelag as ta
on ta.mandt = bp.MANDANT and ta.AGENCYNUM = bp.BUSPARTNUM
where bp.MANDANT = 300;
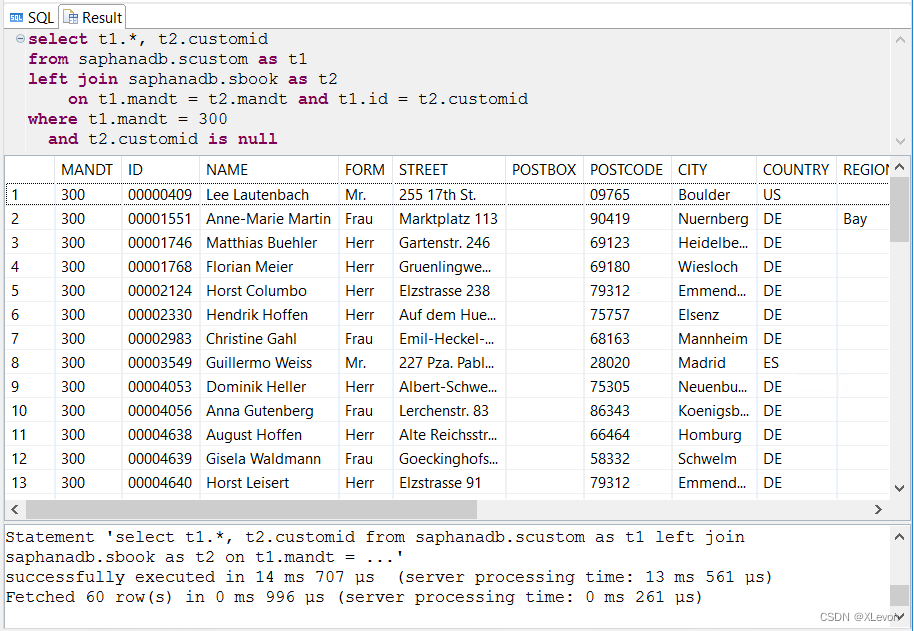
示例2:查找没有订过票的乘客信息。
select t1.*, t2.customid
from saphanadb.scustom as t1
left join saphanadb.sbook as t2
on t1.mandt = t2.mandt and t1.id = t2.customid
where t1.mandt = 300
and t2.customid is null
注意事项:
1、NULL 值不能直接参与比较,只能使用 IS NULL 或者 IS NOT NULL 来判断;
2、NULL 值不能直接参与运算,任何与 NULL 做运算的结果仍然是 NULL 值。
关注本人,敬请期待下一篇《HANA SQL 进阶教程》。