〇、两个预测任务
(1)任务一:银行预测偿还能力
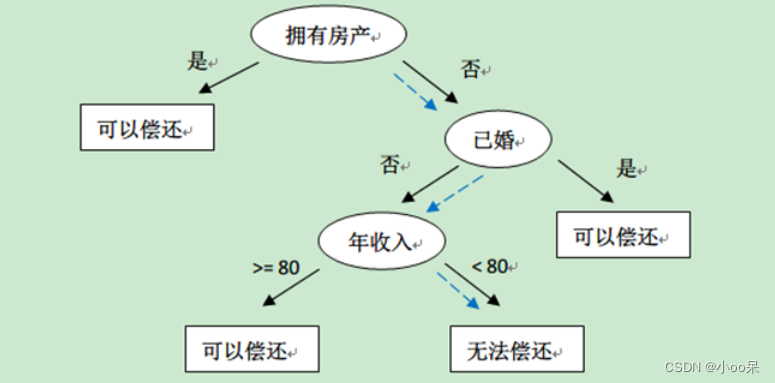
当前,某银行正致力于发掘潜在的放贷用户。他们掌握了每位用户的三个关键特征:房产状况、婚姻状况以及年收入。此外,银行还拥有过往这些用户的债务偿还能力的数据。面对这一情境,银行现需制定一套有效的策略,用以评估新用户的偿债能力,从而做出是否向其提供贷款的决策。
(2)任务二:相亲优质男性
一位母亲想要为她的女儿介绍合适的男朋友,女孩对此提出了四个明确的要求:年龄、相貌、收入、公务员。她明确表示,只有满足条件的男性,她才愿意与之相亲。面对如此具体的条件,母亲该如何在浩渺的婚恋市场中挑选出一位优质男性,让女儿愿意与之相见呢?
一、什么是决策树
相信你看到上面两个例子的时候,心中已经有了一个判断。你是怎么做的判断呢?我先来说说我是怎么做出决策的。将我所做的决策画成树,这就被称为决策树。
(1)直观理解
对与任务一来说,如果我是银行,我肯定选择对有房子、结了婚、年收入高的人进行放贷。这里思考几个问题,有房子难道就一定能还贷嘛?万一他的房子很偏僻很小不值几个钱呢?不结婚的人也许存款更多,还款能力还强些呢?到底怎么定义高收入呢?
对于任务二来说,如果我是这个女孩儿,我也许会选择年轻点的、长得还行就好、收入中等就行、最好是公务员。同样思考一下,从我的决策中就能够看出有许多的模糊字眼。
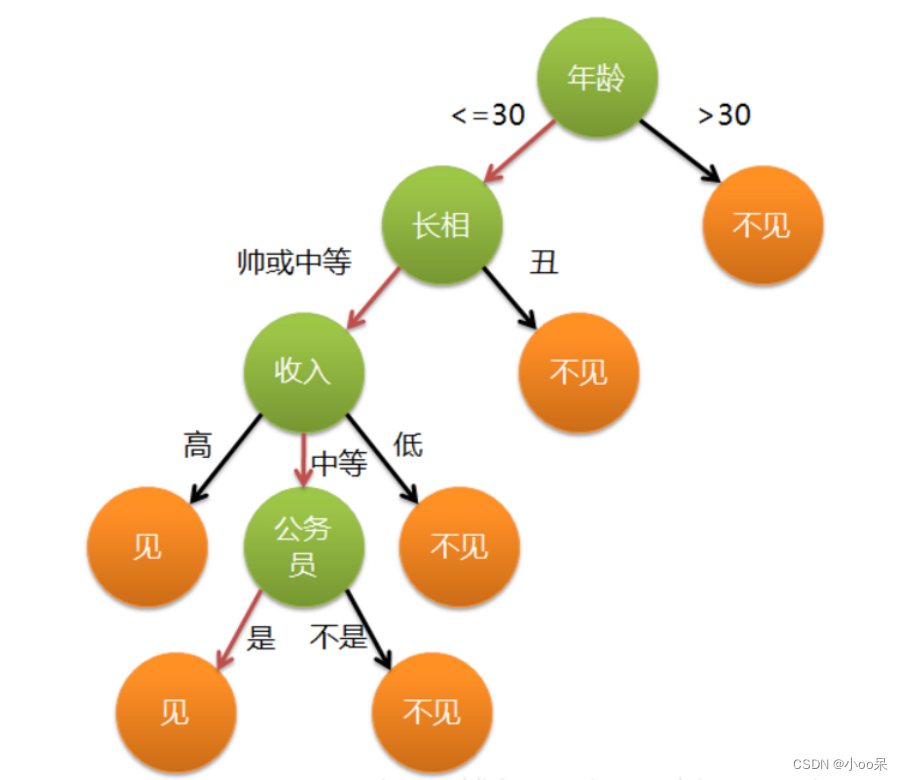
(2)定义
决策树是一种有监督学习算法,通过特征选择和递归分割数据集构建树状模型,用于分类或回归分析。其中每个内部节点代表一个特征测试,分支表示不同的测试结果,而叶节点则对应最终的类别或数值预测。分支节点又叫决策节点,叶子节点又叫预测结果节点。
- 每个内部节点代表一个特征或属性测试。
- 每个分支表示该特征可能的输出或取值。
- 每个叶节点(终端节点)则代表一个决策结果或者分类标签,在分类任务中对应某个类别的预测;而在回归任务中,叶节点会对应一个连续数值的预测。
二、不就是if-else语句吗怎么被称为机器学习模型
如果你也有这种疑问,不妨回顾一下先前我们做的两个小预测任务,上面提出了的思考问题可以总结为两个:我们为什么会这样的特征来辅助决策?以及我们要用怎样的阈值做为判断依据?
决策树确实可以被视为一系列嵌套的if-else语句,但其作为机器学习模型的意义在于,这些if-else规则不是由人类程序员手动编写,而是通过从训练数据中自动学习得出。在构建决策树的过程中,特征的选择和阈值的确立都是根据优化准则自动生成的。
(1)该选哪些特征?
在构建决策树时,算法会遍历所有可能的特征,并计算每个特征用于划分数据集时带来的信息增益、基尼不纯度或者其他类似的评价指标(取决于所使用的具体算法)。信息增益是衡量一个特征对分类纯度提升程度的一种量度,而基尼不纯度则用来表示样本集合不确定性或随机性的大小。在每一轮迭代中,算法会选择当前能够带来最大信息增益或最小基尼不纯度的特征作为节点来划分数据集。这样做的目的是逐步形成一个能最好地描述输入数据与输出类别之间关系的树状结构。
(2)该选哪个阈值?
对于数值型特征来说,在确定了使用该特征进行分割之后,算法需要找到一个最优的阈值来划分数据。这个阈值通常是在当前特征的所有可能取值中搜索出来的,使得基于此阈值划分数据后,子集的信息增益或基尼不纯度达到最优。例如,在CART(Classification and Regression Trees)算法中,对于连续特征,会在特征的所有不同取值上尝试,以找到最佳分割点。
三、决策树的优缺点
(1)优点
-
易于理解和解释:决策树的结构直观且易于理解,可以生成易于解释的规则,对于非专业人士来说也很友好,可以可视化展示整个决策过程。
-
可处理多种类型的数据:无论是离散型、连续型还是混合型数据,决策树都可以直接处理,无需进行复杂的预处理。
-
能够处理缺失值:在一定程度上,决策树算法可以自动处理特征值缺失的情况,通过特定策略(如基于均值、中位数或众数填充)来决定缺失值所在分支。
-
特征选择能力:决策树能够对输入变量的重要性进行排序,帮助识别哪些特征对预测结果影响最大。
-
并行性:决策树训练过程中,不同节点的划分可以相对独立地计算,理论上支持并行化构建。
(2)缺点
-
过拟合问题:决策树容易生成过于复杂的树结构,导致过拟合训练数据,不适用于未见过的新数据,即泛化能力可能较差。
-
不擅长处理连续数值特征:虽然决策树可以处理连续特征,但在处理连续变量时可能不如其他模型(如线性回归)那样准确有效。
-
偏向于选择类别较多的特征:决策树倾向于选择拥有更多类别的特征进行分割,这可能导致忽略那些对决策真正重要的但类别较少的特征。
-
无法捕捉非线性关系和光滑边界:对于数据分布较为复杂或者分类边界平滑的问题,决策树的表现可能不尽如人意。
-
不稳定:对于数据的小幅变动敏感,尤其是当多个特征具有相近重要性时,决策树的结果可能会因为样本顺序的变化而产生较大差异。
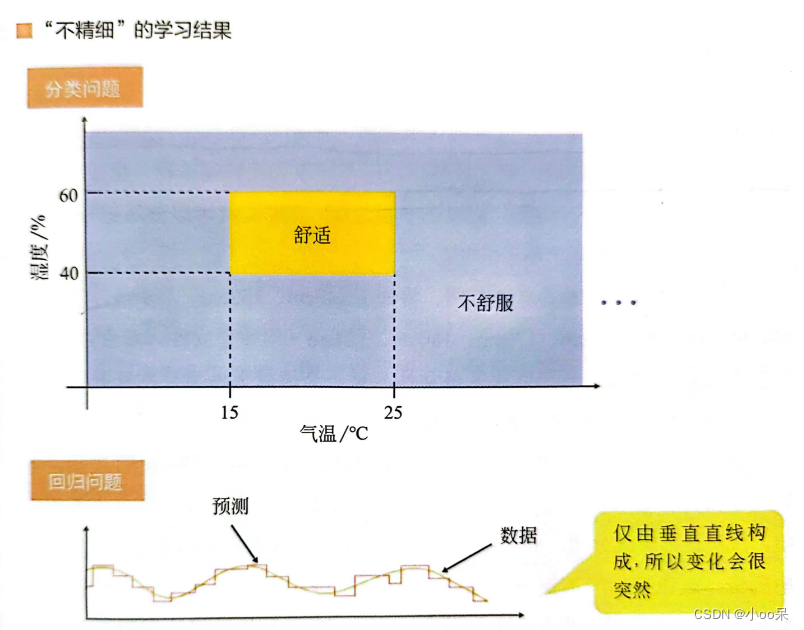
四、如何避免决策树的过拟合?
避免决策树过拟合的主要策略包括:
-
设置树的最大深度:限制决策树的最大深度可以防止模型过于复杂,减少节点划分的次数,从而降低过拟合的风险。
-
最小样本数(或叶子节点最少样本数):要求每个内部节点(或者叶子节点)至少包含一定数量的样本,这样可以防止在训练集上构建过度复杂的分支结构。
-
剪枝:通过后剪枝或预剪枝的方法来简化决策树。后剪枝是先生成一颗完整的决策树,然后从底部开始自下而上地删除对验证集性能改善不大的子树;预剪枝则是在构建过程中,每当扩展一个节点时,都基于验证集的表现决定是否继续划分。




![[HackMyVM]Quick 2](https://img-blog.csdnimg.cn/direct/c64b2edd06bb4045b64f0a577999b0ae.png)