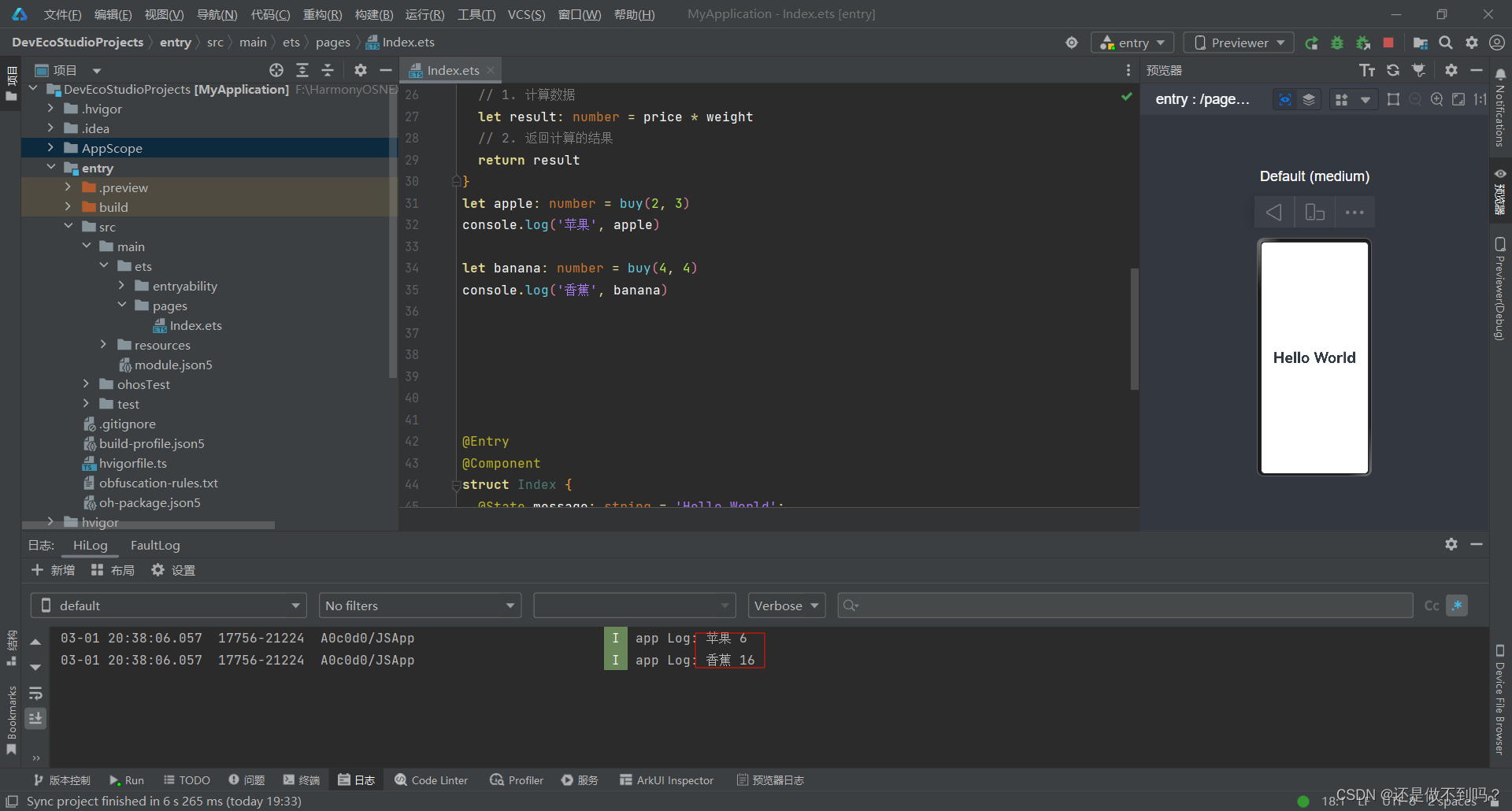
作者:来自 Elastic David Pilato

我们在上一篇文章中看到,我们可以使用摄取管道中的 Elasticsearch Enrich Processor 在 Elasticsearch® 中进行数据丰富。 但有时,你需要执行更复杂的任务,或者你的数据源不是 Elasticsearch,而是另一个源。 或者,你可能希望存储在 Elasticsearch 和第三方系统中,在这种情况下,将管道的执行转移到 Logstash® 很有意义。
使用 Elasticsearch 丰富 Elasticsearch 数据
使用 Logstash,使用类似于以下的管道,这非常容易:
input {
# Read all documents from Elasticsearch
elasticsearch {
hosts => ["${ELASTICSEARCH_URL}"]
user => "elastic"
password => "${ELASTIC_PASSWORD}"
index => "kibana_sample_data_logs"
docinfo => true
ecs_compatibility => "disabled"
}
}
filter {
# Enrich every document with Elasticsearch
elasticsearch {
hosts => ["${ELASTICSEARCH_URL}"]
user => "elastic"
password => "${ELASTIC_PASSWORD}"
index => "vip"
query => "ip:%{[clientip]}"
sort => "ip:desc"
fields => {
"[name]" => "[name]"
"[vip]" => "[vip]"
}
}
mutate {
remove_field => ["@version", "@timestamp"]
}
}
output {
if [name] {
# Write all modified documents to Elasticsearch
elasticsearch {
manage_template => false
hosts => ["${ELASTICSEARCH_URL}"]
user => "elastic"
password => "${ELASTIC_PASSWORD}"
index => "%{[@metadata][_index]}"
document_id => "%{[@metadata][_id]}"
}
}
}总共,我们有 14074 个事件需要解析。 虽然不是很多,但对于这个演示来说已经足够了。 这是一个示例事件:
{
"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes": 1831,
"clientip": "30.156.16.164",
"extension": "",
"geo": {
"srcdest": "US:IN",
"src": "US",
"dest": "IN",
"coordinates": {
"lat": 55.53741389,
"lon": -132.3975144
}
},
"host": "elastic-elastic-elastic.org",
"index": "kibana_sample_data_logs",
"ip": "30.156.16.163",
"machine": {
"ram": 9663676416,
"os": "win xp"
},
"memory": 73240,
"message": "30.156.16.163 - - [2018-09-01T12:43:49.756Z] \"GET /wp-login.php HTTP/1.1\" 404 1831 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"",
"phpmemory": 73240,
"referer": "http://www.elastic-elastic-elastic.com/success/timothy-l-kopra",
"request": "/wp-login.php",
"response": 404,
"tags": [
"success",
"info"
],
"timestamp": "2023-03-18T12:43:49.756Z",
"url": "https://elastic-elastic-elastic.org/wp-login.php",
"utc_time": "2023-03-18T12:43:49.756Z",
"event": {
"dataset": "sample_web_logs"
}
}正如我们在上一篇文章中看到的,vip 索引包含有关我们客户的信息:
{
"ip" : "30.156.16.164",
"vip": true,
"name": "David P"
}我们可以通过以下方式运行管道:
docker run \
--name=logstash \
--rm -it \
-v $(pwd)/logstash-config/pipeline/:/usr/share/logstash/pipeline/ \
-e XPACK_MONITORING_ENABLED=false \
-e ELASTICSEARCH_URL="$ELASTICSEARCH_URL" \
-e ELASTIC_PASSWORD="$ELASTIC_PASSWORD" \
docker.elastic.co/logstash/logstash:8.12.0丰富的文档现在看起来像这样:
{
"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes": 1831,
"clientip": "30.156.16.164",
"extension": "",
"geo": {
"srcdest": "US:IN",
"src": "US",
"dest": "IN",
"coordinates": {
"lat": 55.53741389,
"lon": -132.3975144
}
},
"host": "elastic-elastic-elastic.org",
"index": "kibana_sample_data_logs",
"ip": "30.156.16.163",
"machine": {
"ram": 9663676416,
"os": "win xp"
},
"memory": 73240,
"message": "30.156.16.163 - - [2018-09-01T12:43:49.756Z] \"GET /wp-login.php HTTP/1.1\" 404 1831 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"",
"phpmemory": 73240,
"referer": "http://www.elastic-elastic-elastic.com/success/timothy-l-kopra",
"request": "/wp-login.php",
"response": 404,
"tags": [
"success",
"info"
],
"timestamp": "2023-03-18T12:43:49.756Z",
"url": "https://elastic-elastic-elastic.org/wp-login.php",
"utc_time": "2023-03-18T12:43:49.756Z",
"event": {
"dataset": "sample_web_logs"
},
"vip": true,
"name": "David P"
}实际上很简单,但有一个问题:速度很慢。 通过网络进行查找,尽管 Elasticsearch 速度极快,但仍然会减慢整个管道的速度。
使用静态 JDBC 过滤器
我最近在 ParisJUG 遇到了 Laurent,他来自令人惊叹的 Elastic Consulting 团队,我们讨论了这个问题。 他告诉我,他的一位客户必须面对这个问题。 他建议改用 Logstash 中的 Elasticsearch 缓存。
问题是:Logstash 中没有这样的过滤器缓存插件。 他找到了一种非常聪明的方法来解决该问题,即利用静态 JDBC 过滤器插件和 Elasticsearch JDBC 驱动程序。
请注意,这需要拥有白金许可证(或试用版)。
添加 Elasticsearch JDBC 驱动程序
我们首先需要将 JDBC 驱动程序添加到 Logstash 实例中。
mdir -p logstash-config/lib
wget https://artifacts.elastic.co/maven/org/elasticsearch/plugin/x-pack-sql-jdbc/8.12.0/x-pack-sql-jdbc-8.12.0.jar
mv x-pack-sql-jdbc-8.12.0.jar logstash-config/lib我们只需要与 Logstash docker 实例共享此目录:
time docker run \
--name=logstash \
--rm -it \
-v $(pwd)/logstash-config/pipeline/:/usr/share/logstash/pipeline/ \
-v $(pwd)/logstash-config/lib/:/tmp/lib/ \
-e XPACK_MONITORING_ENABLED=false \
-e ELASTICSEARCH_URL="$ELASTICSEARCH_URL" \
-e ELASTIC_PASSWORD="$ELASTIC_PASSWORD" \
docker.elastic.co/logstash/logstash:8.12.0更新管道
input 部分不变。 但现在,我们要在内存中创建一个名为 vip 的临时表(为了保持一致性)。 该表结构是使用 local_db_objects 参数定义的:
jdbc_static {
local_db_objects => [ {
name => "vip"
index_columns => ["ip"]
columns => [
["name", "VARCHAR(255)"],
["vip", "BOOLEAN"],
["ip", "VARCHAR(64)"]
]
} ]
}当 jdbc_static 启动时,我们要首先从 Elasticsearch vip索引中读取所有数据集。 这是在 loaders 选项中完成的:
jdbc_static {
loaders => [ {
query => "select name, vip, ip from vip"
local_table => "vip"
} ]
jdbc_user => "elastic"
jdbc_password => "${ELASTIC_PASSWORD}"
jdbc_driver_class => "org.elasticsearch.xpack.sql.jdbc.EsDriver"
jdbc_driver_library => "/tmp/lib/x-pack-sql-jdbc-8.12.0.jar"
jdbc_connection_string => "jdbc:es://${ELASTICSEARCH_URL}"
}每次我们需要进行查找时,我们都希望使用以下语句来执行它:
SELECT name, vip FROM vip WHERE ip = "THE_IP"这可以使用 local_lookups 参数定义:
jdbc_static {
local_lookups => [ {
query => "SELECT name, vip FROM vip WHERE ip = :ip"
parameters => { "ip" => "clientip" }
target => "vip"
} ]
}如果没有找到数据,我们可以使用 default_hash 选项提供默认值:
jdbc_static {
local_lookups => [ {
query => "SELECT name, vip FROM vip WHERE ip = :ip"
parameters => { "ip" => "clientip" }
target => "vip"
default_hash => {
name => nil
vip => false
}
} ]
}最后,这将在事件中生成 vip.name 和 vip.vip 字段。
我们现在可以定义我们想要对这些临时字段执行的操作:
jdbc_static {
add_field => { name => "%{[vip][0][name]}" }
add_field => { vip => "%{[vip][0][vip]}" }
remove_field => ["vip"]
}这给出了以下过滤器:
filter {
# Enrich every document with Elasticsearch via static JDBC
jdbc_static {
loaders => [ {
query => "select name, vip, ip from vip"
local_table => "vip"
} ]
local_db_objects => [ {
name => "vip"
index_columns => ["ip"]
columns => [
["name", "VARCHAR(255)"],
["vip", "BOOLEAN"],
["ip", "VARCHAR(64)"]
]
} ]
local_lookups => [ {
query => "SELECT name, vip FROM vip WHERE ip = :ip"
parameters => { "ip" => "clientip" }
target => "vip"
default_hash => {
name => nil
vip => false
}
} ]
add_field => { name => "%{[vip][0][name]}" }
add_field => { vip => "%{[vip][0][vip]}" }
remove_field => ["vip"]
jdbc_user => "elastic"
jdbc_password => "${ELASTIC_PASSWORD}"
jdbc_driver_class => "org.elasticsearch.xpack.sql.jdbc.EsDriver"
jdbc_driver_library => "/tmp/lib/x-pack-sql-jdbc-8.12.0.jar"
jdbc_connection_string => "jdbc:es://${ELASTICSEARCH_URL}"
}
mutate {
remove_field => ["@version", "@timestamp"]
}
}将修改后的文档写入Elasticsearch
在第一个管道中,我们测试事件中是否确实存在名称字段:
if [name] {
# Index to Elasticsearch
}我们仍然可以使用类似的东西,但因为我们提供了默认值,以防在 Elasticsearch vip 索引中找不到 ip,所以现在它会在标签表中生成一个新的 _jdbcstaticdefaultsused 标签。
我们可以用它来知道我们是否发现了某些东西,如果是前者,则将我们的数据发送到 Elasticsearch:
output {
if "_jdbcstaticdefaultsused" not in [tags] {
# Write all the modified documents to Elasticsearch
elasticsearch {
manage_template => false
hosts => ["${ELASTICSEARCH_URL}"]
user => "elastic"
password => "${ELASTIC_PASSWORD}"
index => "%{[@metadata][_index]}"
document_id => "%{[@metadata][_id]}"
}
}
}更快吗?
因此,当我们在这个小数据集上运行测试时,我们可以看到,使用 Elasticsearch 过滤器方法,需要两分钟多一点的时间来丰富我们的数据集:
real 2m3.146s
user 0m0.077s
sys 0m0.042s当使用 JDBC 静态过滤器方法运行管道时,现在只需不到一分钟:
real 0m48.575s
user 0m0.064s
sys 0m0.039s正如我们所看到的,我们显着减少了该丰富管道的执行时间(增益约为 60%)。
如果你有一个可以轻松放入 Logstash JVM 内存的小型 Elasticsearch 索引,你可以尝试此策略(或类似的策略)。 如果你有数亿个文档,你仍然应该使用 Elasticsearch Filter Plugin。
结论
在这篇文章中,我们了解了当我们需要在 Elasticsearch 中执行一些查找时,如何使用 JDBC 静态过滤器插件来加速数据丰富管道。 在下一篇文章中,我们将了解如何使用 Elastic Agent 在边缘进行类似的丰富。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付
更多阅读:
-
Logstash:Jdbc static filter plugin 介绍
-
Logstash:运用 jdbc_streaming 来丰富我们的数据
原文:Enrich your Elasticsearch documents with Logstash | Elastic Blog


![[HackMyVM]Quick 2](https://img-blog.csdnimg.cn/direct/c64b2edd06bb4045b64f0a577999b0ae.png)