背景需求:
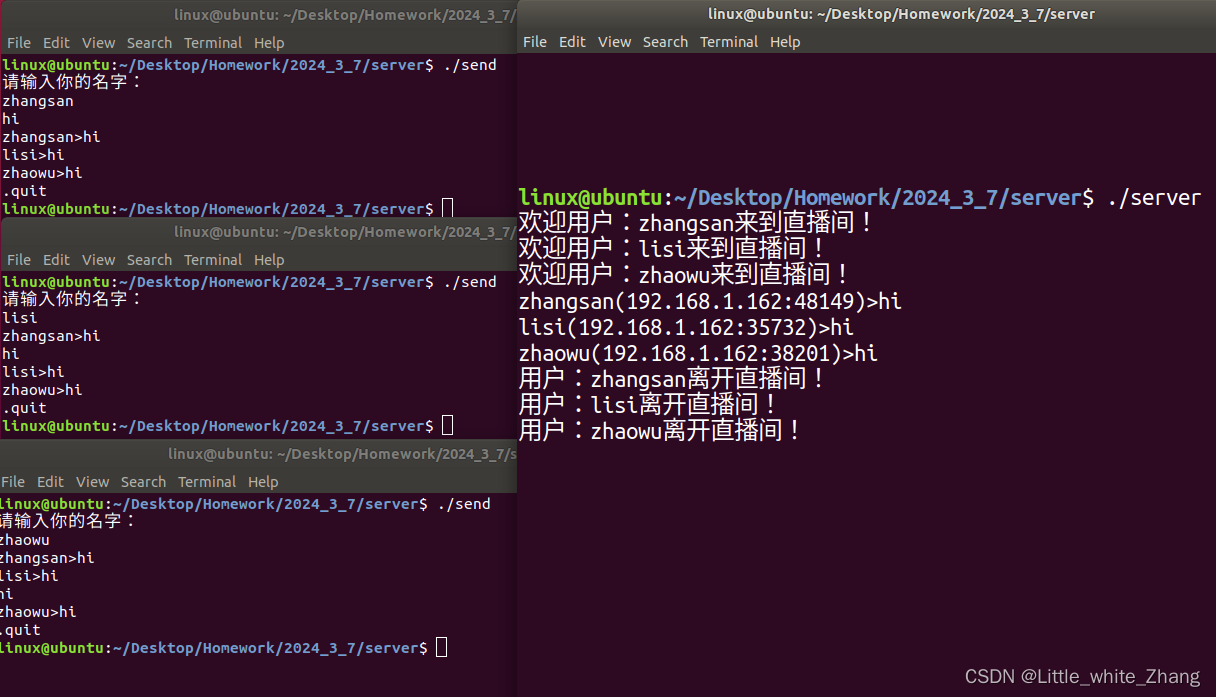
测试两种公众号图片下载,
1、UIBOT下载速度慢,也需要有UIBOT软件
【办公类-39-01】批量下载微信公众号图片(一)UIBOT图片下载-CSDN博客文章浏览阅读289次。【办公类-39-01】批量下载微信公众号图片(一)UIBOT图片下载https://blog.csdn.net/reasonsummer/article/details/1365229842、360套图无法下载所有图片。
【办公类-39-02】批量下载微信公众号图片(二)-360浏览器套图-CSDN博客文章浏览阅读84次,点赞2次,收藏2次。【办公类-39-01】批量下载微信公众号图片(二)-360浏览器套图https://blog.csdn.net/reasonsummer/article/details/136522853
因此,我只能试试Python爬虫了。
测试过程:
第一次问题:AI不能生成
第二次问题:生成爬虫程序,但没有成功获取图片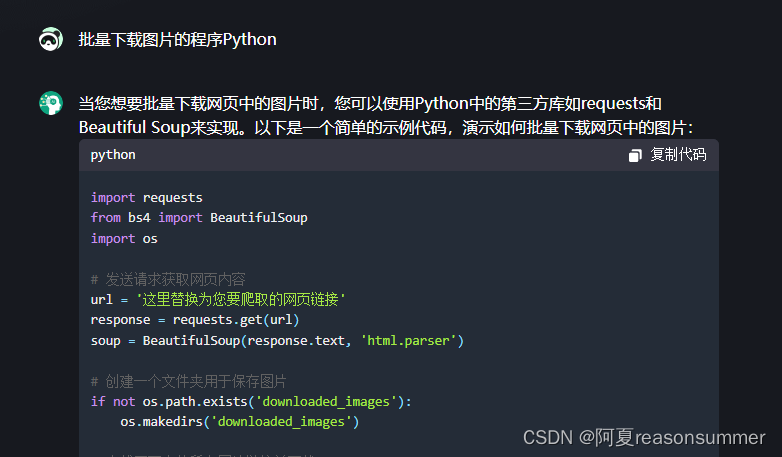 第三次:搜索CSDN
第三次:搜索CSDN
Python爬虫——批量下载微信公众号图片_批量提取微信公众号上的图片-CSDN博客文章浏览阅读1k次,点赞4次,收藏4次。编写Python爬虫程序来实现微信公众号文章图片的下载。_批量提取微信公众号上的图片https://blog.csdn.net/qq_41301570/article/details/131592967
感谢这篇的作者,让我1秒快速下载了图片
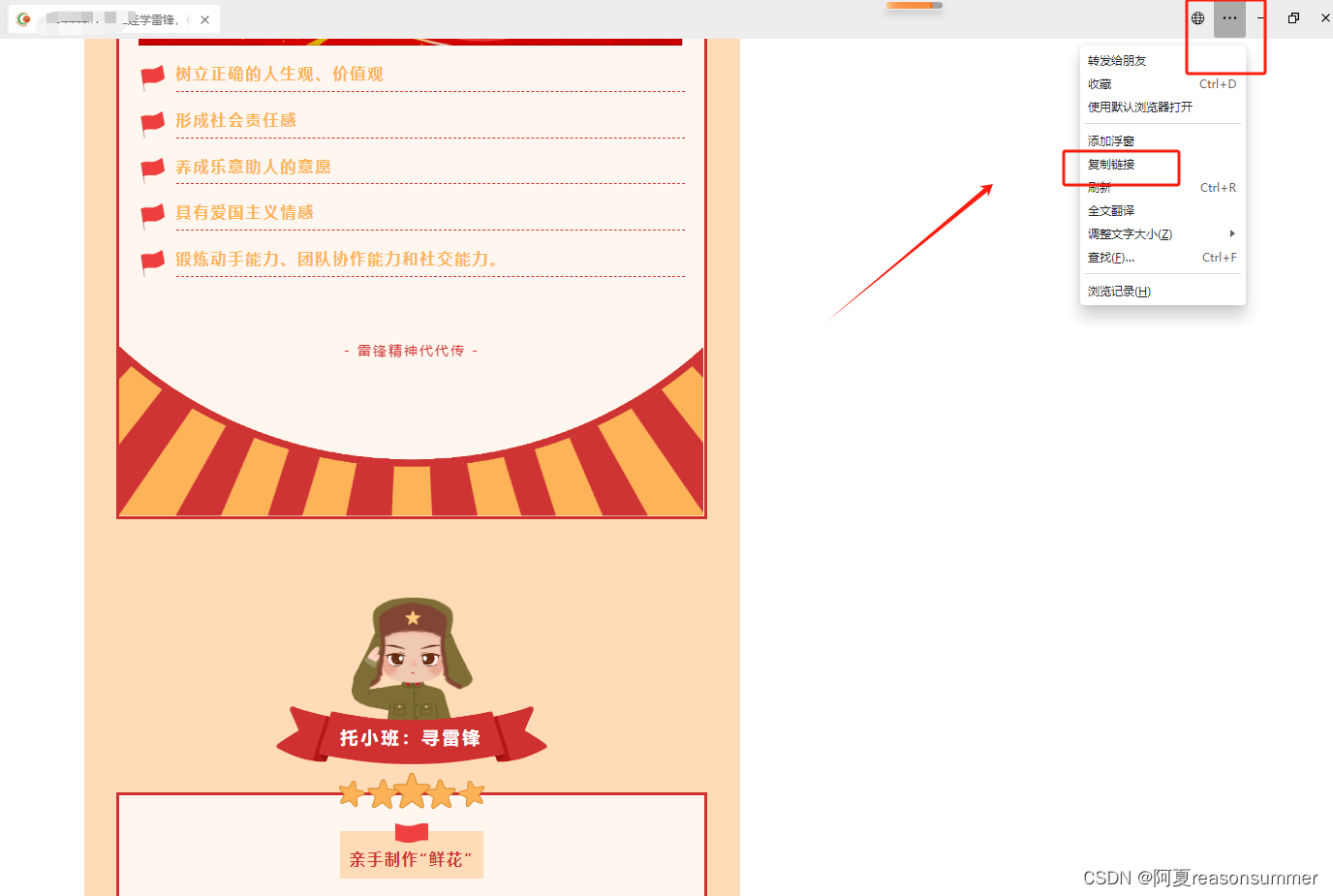
1、打开微信,打开微信里的公众号,打开文章,复制右上角的链接
2、代码展示
# 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
# 原文链接:https://blog.csdn.net/qq_41301570/article/details/131592967
import requests
from bs4 import BeautifulSoup
import re
import os
#获取网页信息
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
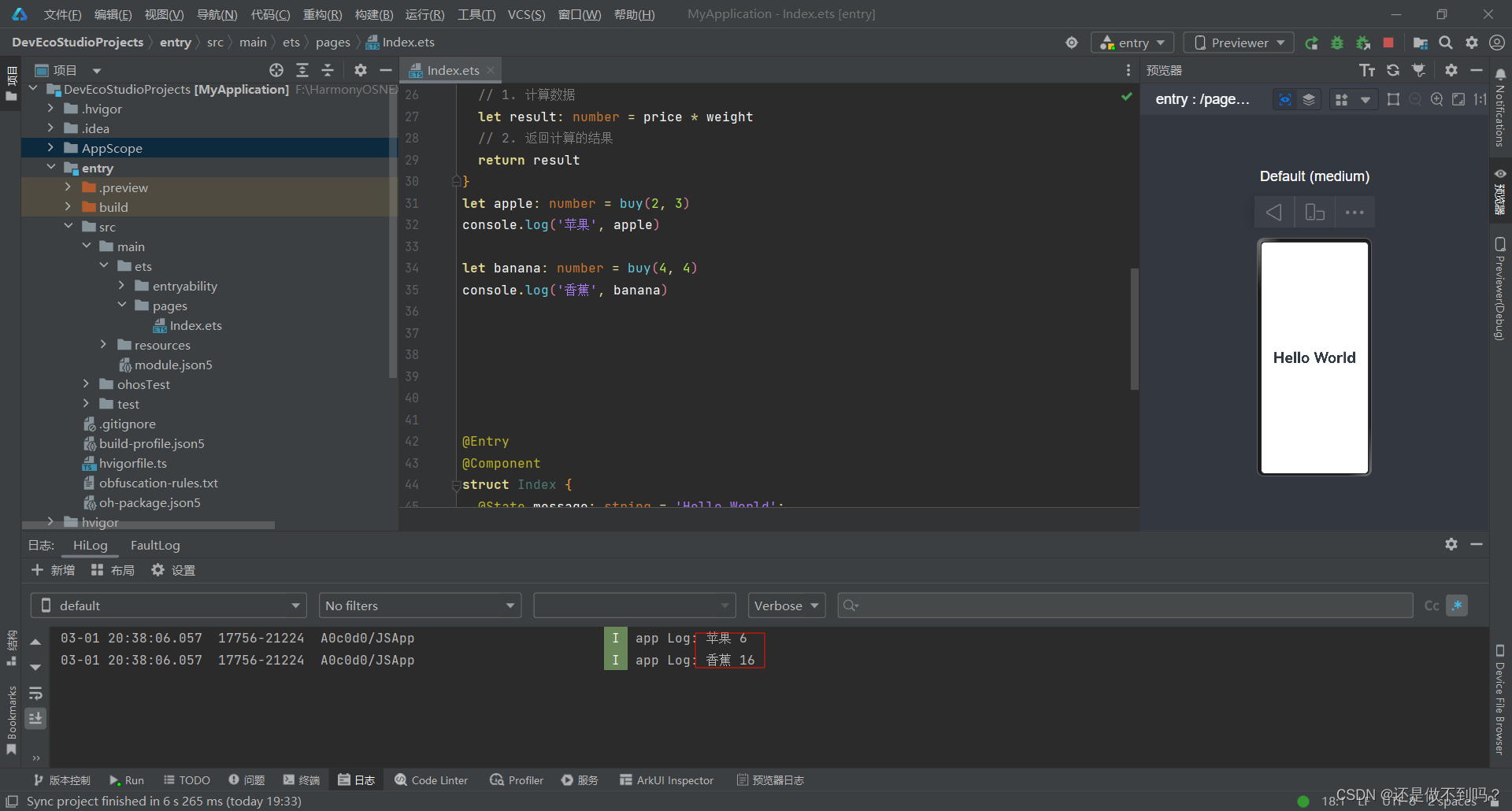
return r.text
except:
return ""
#解析网页,获取所有图片url
def getimgURL(html):
soup = BeautifulSoup(html , "html.parser")
adlist=[]
for i in soup.find_all("img"):
try:
ad= re.findall(r'.*src="(.*?)?" .*',str(i))
if ad :
adlist.append(ad)
except:
continue
return adlist
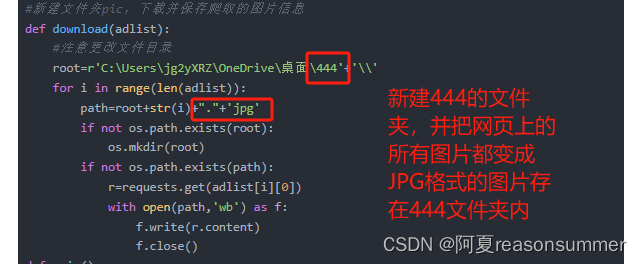
#新建文件夹pic,下载并保存爬取的图片信息
def download(adlist):
#注意更改文件目录
root=r'C:\Users\jg2yXRZ\OneDrive\桌面\444'+'\\'
for i in range(len(adlist)):
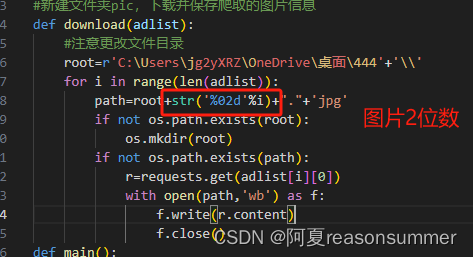
path=root+str('%02d'%i)+"."+'jpg'
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(adlist[i][0])
with open(path,'wb') as f:
f.write(r.content)
f.close()
def main():
url = 'https://mp.weixin.qq.com/s/u60kJ1Rxs_qnbLkF-Xv6fw'
html=getHTMLText(url)
list=getimgURL(html)
download(list)
main()重点说明
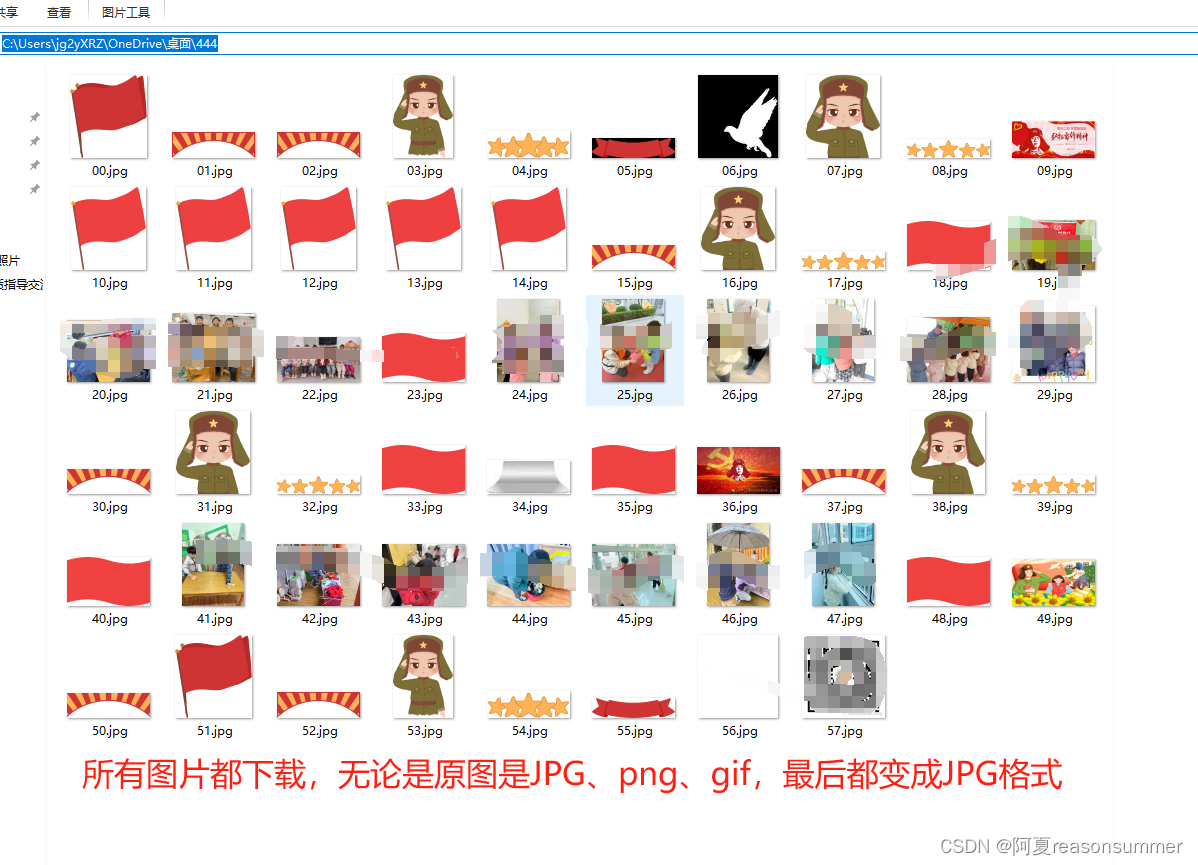
“444”文件夹里的图片
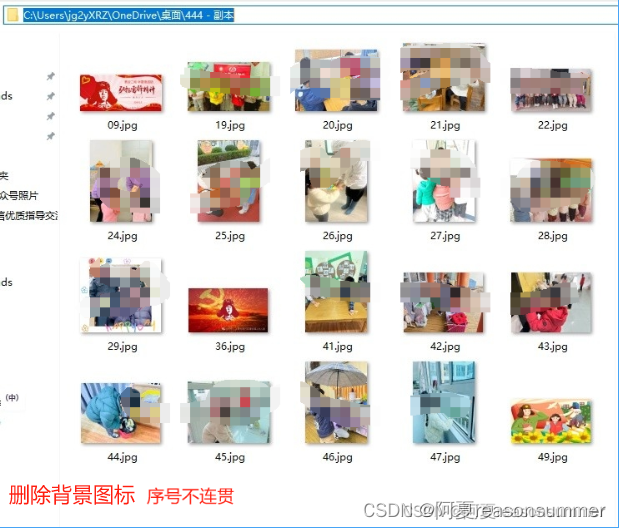
删除图片后,文件编号就不是连贯的
3、替换文件名,更改序号。
''''
下载公众号图片,所有图片按照文件名改成01 02、03
作者:AI对话大师
时间:2024月3月7日
'''
import os
import shutil
folder_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\444'
file_list = os.listdir(folder_path)
image_list = [file for file in file_list if file.lower().endswith(('.jpg'))]
for i, image_file in enumerate(image_list):
new_file_name = f"{str(i+1).zfill(2)}{os.path.splitext(image_file)[1]}"
old_file_path = os.path.join(folder_path, image_file)
new_file_path = os.path.join(folder_path, new_file_name)
shutil.move(old_file_path, new_file_path)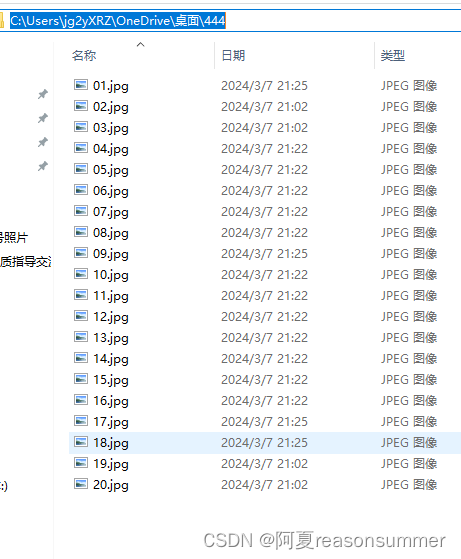
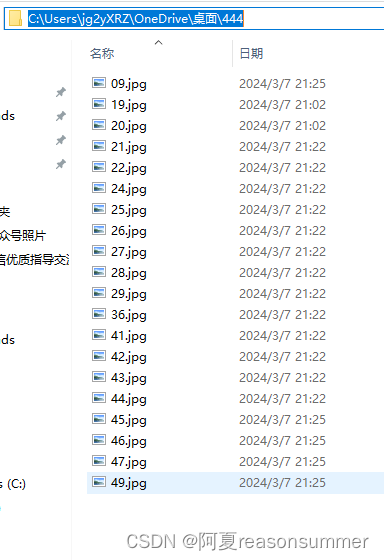
最终效果图 01 、02、03……
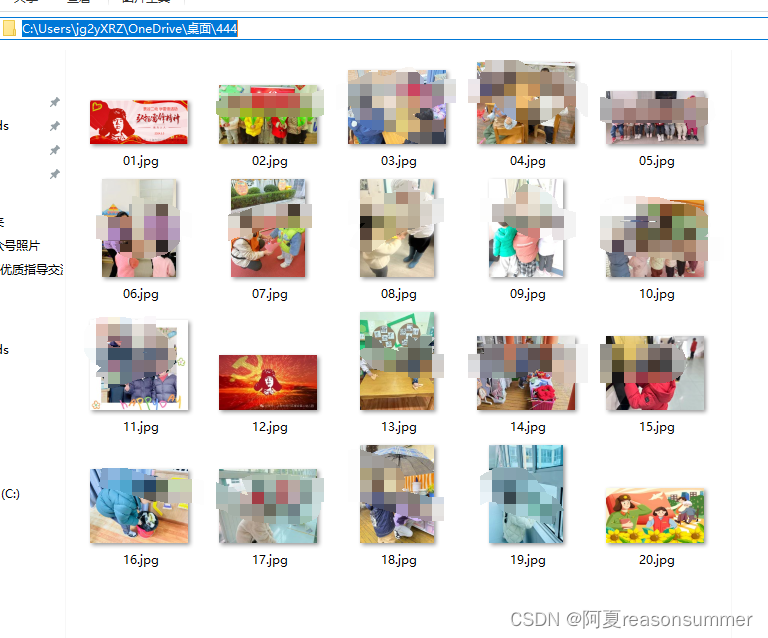
原来的图片编码 09 19 20……




![[HackMyVM]Quick 2](https://img-blog.csdnimg.cn/direct/c64b2edd06bb4045b64f0a577999b0ae.png)