Flink学习笔记
前言:今天是学习 flink 的第 11 天啦!学习了 flink 四大基石之 Checkpoint (检查点),主要是解决大数据领域持久化中间结果数据,以及取消任务,下次启动人可以恢复累加数据问题,结合自己实验猜想和代码实践,总结了很多自己的理解和想法,希望和大家多多交流!
Tips:检查点,检查的是历史记录!过去的时间值得怀念,未来的道路运气会继续累加,能力会继续提升,明天也要继续努力!
文章目录
- Flink学习笔记
- 三、Flink 高级 API 开发
- 4. Checkpoint
- 4.1 Checkpoint 介绍
- 4.1.1 流程简介:
- 4.1.2 单流的 barrier
- 4.1.3 双流的 checkpoint 实现
- 4.2 持久化存储
- 4.2.1 MemStateBackend
- 4.2.2 FsStateBackend
- 4.2.3 RocksDBStateBackend
- 4.2.4 配置参数用法
- 4.2.5 修改 State Backend 的两种方式(简略,新版本前)
- (1) 单任务调整(灵活)
- (2) 全局调整
- 4.2.6 从传统后端迁移的三种情况(详细,新版本后)
- (1) MemoryStateBackend
- (2) FsStateBackend
- (3) RocksDBStateBackend
- 4.6.7 Checkpoint 案例演示
- 4.3 Flink 的重启策略
- 4.3.1 概述
- 4.3.2 固定延迟重启策略
- (1) 全局配置 flink-conf.yaml
- (2) 代码设置
- 4.3.3 失败率重启策略
- (1) 全局配置 flink-conf.yaml
- (2) 代码设置
- 4.3.4 无重启策略
- (1) 全局配置 flink-conf.yaml
- (2) 代码设置
- 4.3.5 重启策略的案例演示
- 4.4 Savepoint
- 4.4.1 应用场景
- 4.4.2 面试问题
- 4.4.3 案例演示
三、Flink 高级 API 开发
4. Checkpoint
4.1 Checkpoint 介绍
4.1.1 流程简介:
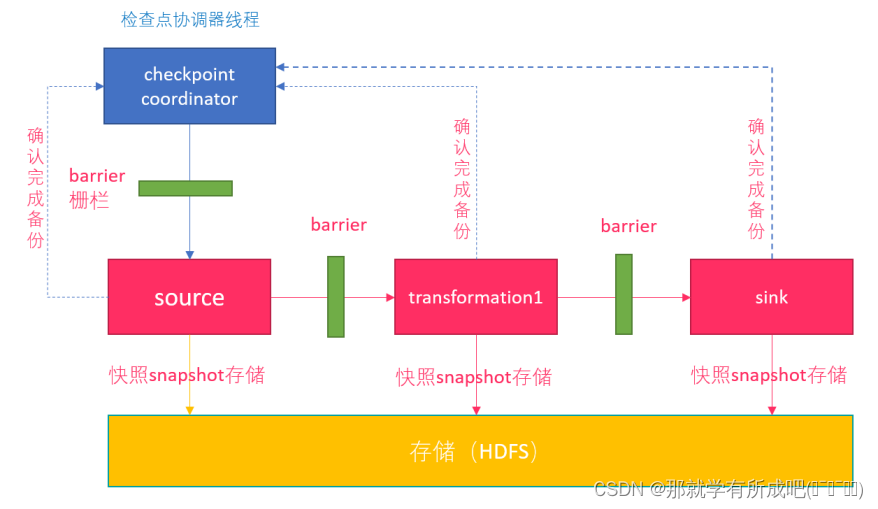
- 1- Flink 检查点机制,CheckpointCoordinator (协调者)定期在数据流上生成 checkpoint barrier;
- 2- 当某个算子接收到 barrier(数据栅栏) 时,会基于当前状态生成一份快照;
- 3- 后将 barrier 传递给下游算子,依次快照并传递下去,直到 sink;
- 4- 出现异常时,根据最近的快照数据,将所有算子恢复到之前状态;
- 5- CheckpointCoordinator 收到所有算子的报告后,才认为该周期快照成功。
4.1.2 单流的 barrier
- 每个 barier 都带有快照 id,并且 barrier之前的数据都进入了该快照;
- 一个数据源可以有多个 barrier,工作独立,互不干扰;

4.1.3 双流的 checkpoint 实现
- 一个算子有两个数据源,阻塞先收到 barrier 的快数据源,等慢数据源接到相同编号的 barrier,再制作自身快照。
- (1)快慢不一,阻塞快源

- (2)双源到齐,制作快照
4.2 持久化存储
4.2.1 MemStateBackend
- 1- 将状态维护在 Java 堆上的一个内部状态后端
- 2- 大小限制
- 默认状态限制 5Mb,可以通过其构造函数增加大小
- 状态大小 <= akka 帧大小(akka 是并发框架)
- 状态大小 <= job manager 内存大小
- 3- 适用场景
- debug 模式下使用,不适合生产环境使用
4.2.2 FsStateBackend
-
1- 将状态存储在 [本地文件/ HDFS]
- 使用本地文件:new FsStateBackend(“file:///Data”)),不推荐,集群间读文件难
- 使用 HDFS:new FsStateBackend(“hdfs:///lql/checkpoint”))
-
2- 适用场景:
- 具有大状态,长窗口,大键 / 值状态的作业
- 所有高可用性设置
-
3- 弊端:
- 分布式文件持久化,每次读写都会产生网络 IO,整体性能不佳
4.2.3 RocksDBStateBackend
-
1- RockDB 是一种嵌入式的本地数据库,默认是配置成异步快照(不需要等待所有信号结束才开始状态拷贝)
-
2- 适用场景:
- 最适合用于处理大状态,长窗口,或大键值状态的有状态处理任务
- 非常适合用于高可用方案
-
3- 也需要配置一个文件系统:本地 / HDFS
-
4- RocksDBStateBackend(flink1.13) 唯一支持增量 checkpoint 的后端
4.2.4 配置参数用法
- 1- 设置checkpoint周期执行时间,即两个 checkpoint 之间的间距
- env.enableCheckpointing(5000);
- 2- 设置checkpoint的执行模式,最多执行一次(默认值)或者至少执行一次
- env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
- env.getCheckpointConifg().setCheckpointingMode(ChexkpointingMode.AT_LEAST_ONCE)
- 3- 设置checkpoint的超时时间(即一个checkpoint操作的最大允许时间)
- env.getCheckpointConfig().setCheckpointTimeout(60000);
- 4- 如果在只做快照过程中出现错误,是否让整体任务失败:true是 false不是
- env.getCheckpointConfig().setFailOnCheckpointingErrors(false);
- 5- 设置同一时间有多少 个checkpoint可以同时执行
- env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
- 6- 任务被 cancel,检查点被自动删除了,保留以前做的 checkpoint 可以启动外部检查点持久化
- env**.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.**RETAIN_ON_CANCELLATION):在作业取消时保留检查点,注意,您必须在取消后手动清理检查点状态
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业被cancel时,删除检查点,检查点仅在作业失败时可用
4.2.5 修改 State Backend 的两种方式(简略,新版本前)
(1) 单任务调整(灵活)
- 修改方案1:env.setStateBackend(new FsStateBackend(“hdfs://node01:8020/flink/checkpoints”));
- 修改方案2:new MemoryStateBackend()
- 修改方案3:new RocksDBStateBackend(filebackend, true) 需要添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.7.0</version>
</dependency>
(2) 全局调整
- 修改
flink-conf.yaml- state.backend: filesystem
- state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
- state.backend的值可以是下面几种
- jobmanager (MemoryStateBackend)
- filesystem (FsStateBackend)
- rocksdb (RocksDBStateBackend)
4.2.6 从传统后端迁移的三种情况(详细,新版本后)
从 Flink 1.13 版本开始,社区重新设计了其公共状态后端类,用户可以迁移现有应用程序以使用新 API,而不会丢失任何状态或一致性。
(1) MemoryStateBackend
以前的 MemoryStateBackend 相当于使用 HashMapStateBackend 和 JobManagerCheckpointStorage
- 全局配置 flink-conf.yaml
state.backend: hashmap
# Optional, Flink will automatically default to JobManagerCheckpointStorage
# when no checkpoint directory is specified.
state.checkpoint-storage: jobmanager
- 代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 因为使用新的类:HashMapStateBackend
env.setStateBackend(new HashMapStateBackend());
// 因为 JobManagerCheckpointStorage 即:checkpoint 与 jobmanager 有关
env.getCheckpointConfig().setCheckpointStorage(new JobManagerStateBackend());
(2) FsStateBackend
以前的 FsStateBackend 相当于使用 HashMapStateBackend 和 FileSystemCheckpointStorage
- 全局配置 flink-conf.yaml
state.backend: hashmap
state.checkpoints.dir: file:///checkpoint-dir/
# Optional, Flink will automatically default to FileSystemCheckpointStorage
# when a checkpoint directory is specified.
state.checkpoint-storage: filesystem
- 代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 因为使用新的类:HashMapStateBackend
env.setStateBackend(new HashMapStateBackend());
// 因为 JobManagerCheckpointStorage 即:checkpoint 与 jobmanager 有关
env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");
// 下面的设置更高级一点,可以传入参数,建议!
// Advanced FsStateBackend configurations, such as write buffer size
// can be set by manually instantiating a FileSystemCheckpointStorage object.
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("file:///checkpoint-dir"));
(3) RocksDBStateBackend
以前的 RocksDBStateBackend相当于使用 EmbeddedRocksDBStateBackend 和 FileSystemCheckpointStorage
- 全局配置 flink-conf.yaml
state.backend: rocksdb
state.checkpoints.dir: file:///checkpoint-dir/
# Optional, Flink will automatically default to FileSystemCheckpointStorage
# when a checkpoint directory is specified.
state.checkpoint-storage: filesystem
- 代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 因为使用新的类:EmbeddedRocksDBStateBackend
env.setStateBackend(new EmbeddedRocksDBStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");
// If you manually passed FsStateBackend into the RocksDBStateBackend constructor
// to specify advanced checkpointing configurations such as write buffer size,
// you can achieve the same results by using manually instantiating a FileSystemCheckpointStorage object.
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("file:///checkpoint-dir"));
4.6.7 Checkpoint 案例演示
例子:socket 数据源,词频统计,开启 checkpoint,每隔 5s 写入 HDFS
package cn.itcast.day10.checkpoint;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.CheckpointStorage;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackendFactory;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.runtime.state.storage.JobManagerCheckpointStorage;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 读取服务器node01中端口9999的内容,并切分单词,统计数量
* 要求: 开启checkpoint支持,每隔5s钟写入HDFS一次
*/
public class StreamCheckpointDemo {
public static void main(String[] args) throws Exception {
//todo 1)获取flink流处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo 2)开启checkpoint
//每隔5s周期性的生成barrier(栅栏),默认情况下没有开启checkpoint
env.enableCheckpointing(5000L);
//设置checkpoint的超时时间
env.getCheckpointConfig().setCheckpointTimeout(2000L);
//同一个时间只能有一个栅栏在运行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//设置checkpoint的执行模式。仅执行一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000L);
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);
//指定checkpoint的存储位置
if(args.length< 1){
//env.setStateBackend(new FsStateBackend("file:///D:\\checkpoint"));
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///D:\\checkpoint");
}else{
//env.setStateBackend(new FsStateBackend(args[0]));
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage(args[0]);
}
// 设置任务失败时候,能够外部持久化检查点
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//todo 2)接入数据源,读取文件获取数据
DataStreamSource<String> lines = env.socketTextStream("node01", 7777);
//todo 3)数据处理
// 3.1:使用flatMap对单词进行拆分
SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] words = line.split(" ");
//返回数据
for (String word : words) {
out.collect(word);
}
}
});
// 3.2:对拆分后的单词进行记一次数
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
// 3.4:对分组后的key进行聚合操作
SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = grouped.sum(1);
//todo 4)构建sink,输出结果
sumed.print();
//todo 5)启动运行
env.execute();
}
}
结果:
将程序打包成jar包放在flink的提交页面
# 启动 jobmanager 和 taskmanager
bin/start-cluster.sh
输入地址参数,最终发现:
1. 手动取消作业,检查点文件没有消失
2. 输入hdfs地址参数,检查点文件生成在hdfs目录上
总结:
- 理解配置参数,修改后端的方法
4.3 Flink 的重启策略
4.3.1 概述
flink-conf.yaml 配置文件的 restart-strategy 配置参数决定重启策略。
| 重启策略 | 重启策略值 | 说明 |
|---|---|---|
| Fixed delay | fixed-delay | 固定延迟重启策略 |
| Failure rate | failure-rate | 失败率重启策略 |
| No restart | None | 无重启策略 |
4.3.2 固定延迟重启策略
| 配置参数 | 描述 | 默认值 |
|---|---|---|
| restart-strategy.fixed-delay.attempts | 在 Job 最终失败前,Flink 尝试执行的次数 | 如果启用 checkpoint 的话是Integer.MAX_VALUE |
| restart-strategy.fixed-delay.delay | 延迟重启指一个执行失败后,不立即重启,等待一段时间。 | akka.ask.timeout,如果启用checkpoint的话是1s |
(1) 全局配置 flink-conf.yaml
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
(2) 代码设置
// 1. 初始化流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
))
4.3.3 失败率重启策略
| 配置参数 | 描述 | 默认值 |
|---|---|---|
| restart-strategy.failure-rate.max-failures-per-interval | 在一个Job认定为失败之前,最大的重启次数 | 1 |
| restart-strategy.fixed-delay.delay | 计算失败率的时间间隔 | 1分钟 |
| restart-strategy.failure-rate.delay | 两次连续重启尝试之间的时间间隔 | akka.ask.timeout |
(1) 全局配置 flink-conf.yaml
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
意思就表明为:
失败重启之间的间隔是10秒
如果5分钟内,失败3次,就不会在重启了,直接结束任务
(2) 代码设置
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启尝试的时间间隔
))
4.3.4 无重启策略
(1) 全局配置 flink-conf.yaml
restart-strategy: none
(2) 代码设置
// 直接失败,不会重启
env.setRestartStrategy(RestartStrategies.noRestart());
4.3.5 重启策略的案例演示
例子:基于之前的单词统计案例改造,当遇到"laowang"字符串的时候,程序抛出异常,出现3次异常后,程序退出.
/**
* 演示flink的重启策略
* flink的重启策略是,在配置了checkpoint的前提下,不停的重启的重启,如果不配置checkpoint不能使用重启策略,作业直接停止
* flink有三种重启策略的方式:
* 固定延迟重启策略:
* 设置失败重启的次数,以及两次重启的时间间隔,如:设置重启失败次数是3次,每次间隔5秒钟,那么输入三次异常以后,尝试重启三次,第四次依然失败,则作业停止
* 失败率重启策略:
* 给定一定时间,如果这个时间内设置了n次失败重启,一旦超过了N次,则作业停止,如:3分钟失败五次,每次时间间隔10秒,则任务结束
* 无重启策略:
* 表示运行失败以后,立刻停止作业运行
*/
public class FixedDelayRestartStrategyDemo {
public static void main(String[] args) throws Exception {
/**
* 实现步骤:
* 1)初始化flink的流处理的运行环境
* 2)开启checkpint
* 3)配置重启策略
* 4)接入数据源
* 5)对字符串进行空格拆分,每个单词记一次数
* 6)分组聚合
* 7)打印测试
* 8)运行作业
*/
//TODO 1)初始化flink流处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//TODO 2)开启checkpoint
//周期性的生成barrier(栅栏),默认情况下checkpoint是没有开启的
env.enableCheckpointing(5000L);
//设置checkpoint的超时时间
env.getCheckpointConfig().setCheckpointTimeout(6000L);
//设置同一个时间只能有一个栅栏在运行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 设置checkpoint的执行模式,最多执行一次或者至少执行一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//Checkpointing最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//指定checkpoint的存储位置
if(args.length < 1) {
env.setStateBackend(new FsStateBackend("file:///E:\\checkpoint"));
}else{
env.setStateBackend(new FsStateBackend(args[0]));
}
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//TODO 3)配置重启策略
//固定延迟重启策略,程序出现异常的时候,重启三次,每次延迟五秒钟重启,超过三次,则程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(5)));
//TODO 4)接入数据源
DataStreamSource<String> socketTextStream = env.socketTextStream("node1", 9999);
//TODO 5)对字符串进行空格拆分,每个单词记一次数
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> collector) throws Exception {
if(line.startsWith("laowang")){
System.out.println(line);
int i = 1/0;
System.out.println(i);
throw new RuntimeException("老王驾到,程序挂了!");
}
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}
});
//TODO 6)分组聚合
SingleOutputStreamOperator<Tuple2<String, Long>> sumed = wordAndOne.keyBy(0).sum(1);
//TODO 7)打印测试
sumed.print();
//TODO 8)运行作业
env.execute();
}
}
总结:
- 抛出异常:throw new RuntimeException();
4.4 Savepoint
4.4.1 应用场景
savepoint的目的是为了从上一次保存的中间结果中恢复过来,比如:在生产环境中运行着一个作业,因为今晚要升级作业,因此需要将生产环境的作业停止掉,将升级后的jar进行部署和发布,希望重新发布以后可以将上一个作业的运行结果恢复后继续运行
4.4.2 面试问题
checkpoint和savepoint的区别?
- checkpoint:周期性定期运行,生成barrier(栅栏)发送到job作业的每个算子,当算子收到 barrier以后会将state的中间计算结果快照存储到分布式文件系统中
- savepoint:将指定的checkpoint的结果恢复过来,恢复到当前的作业中,继续运行
4.4.3 案例演示
例子:代码和之前一样
/**
* savepoint的目的是为了从上一次保存的中间结果中恢复过来
* 举例:
* 在生产环境中运行着一个作业,因为今晚要升级作业,因此需要将生产环境的作业停止掉,将升级后的jar进行部署和发布
* 希望重新发布以后可以将上一个作业的运行结果恢复后继续运行
*
* 所以这时候可以使用savepoint进行解决这个问题问题
*
* 面试问题:
* checkpoint和savepoint的区别?
* checkpoint:周期性定期运行,生成barrier(栅栏)发送到job作业的每个算子,当算子收到barrier以后会将state的中间计算结果快照存储到分布式文件系统中
* savepoint:将指定的checkpoint的结果恢复过来,恢复到当前的作业中,继续运行
*
* TODO 当作业重新递交的时候,并行度发生了概念,在flink1.10版本中,可以正常的递交作业,且能够恢复历史的累加结果
* 但是之前版本中一旦发生并行度的变化,作业无法递交
*/
public class SavepointDemo {
public static void main(String[] args) throws Exception {
/**
* 实现步骤:
* 1)初始化flink流处理的运行环境
* 2)开启checkpoint
* 3)指定数据源
* 4)对字符串进行空格拆分,然后每个单词记一次数
* 5)对每个单词进行分组聚合操作
* 6) 打印测试
* 7)执行任务,递交作业
*/
//TODO 1)初始化flink流处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//TODO 2)开启checkpoint
//周期性的生成barrier(栅栏),默认情况下checkpoint是没有开启的
env.enableCheckpointing(5000L);
//设置checkpoint的超时时间
env.getCheckpointConfig().setCheckpointTimeout(6000L);
//设置同一个时间只能有一个栅栏在运行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 设置checkpoint的执行模式,最多执行一次或者至少执行一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//Checkpointing最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//指定checkpoint的存储位置
if(args.length < 1) {
env.setStateBackend(new FsStateBackend("file:///E:\\checkpoint"));
}else{
env.setStateBackend(new FsStateBackend(args[0]));
}
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//TODO 3)指定数据源
DataStreamSource<String> socketTextStream = env.socketTextStream("node1", 9999);
//TODO 4)对字符串进行空格拆分,然后每个单词记一次数
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}
});
//TODO 5)对每个单词进行分组聚合操作
SingleOutputStreamOperator<Tuple2<String, Long>> sumed = wordAndOne.keyBy(0).sum(1);
//TODO 6) 打印测试
sumed.print();
//TODO 7)执行任务,递交作业
env.execute();
}
}
结果:
(hadoop,4)
取消程序后,再次运行,
结果累加上一次取消任务的结果:
(hadoop,5)
总结:
- 打包 jar 包到 flink 平台时,不可以修改并行度,并行度保持一致,不然会报错
- 指定 flink 平台提交任务的 savepoint 地址,即指定为上一次取消程序的 checkpoint 地址,即可恢复上一次的累加数据
- 上一次取消程序的 checkpoint 地址:flink 8081 web页面上 checkpoint 页面有历史记录地址哦!








![LeetCode 刷题 [C++] 第98题.验证二叉搜索树](https://img-blog.csdnimg.cn/direct/0969958fe1194ce59312733623e4c43f.png)