Scrapy核心组件与运行机制
引言
这一章开始讲解Scrapy核心组件的功能与作用,通过流程图了解整体的运行机制,然后了解它的安装与项目创建,为后续实战做好准备。
Scrapy定义
Scrapy是一个为了爬取网站数据、提取结构性数据而编写的应用框架。它使用Python语言编写,并基于异步网络框架Twisted来实现高性能的爬虫。Scrapy最初是为了页面抓取(更确切地说是网络抓取)而设计的,但它也可以用于获取API返回的数据或通用的网络爬虫。
体系结构图
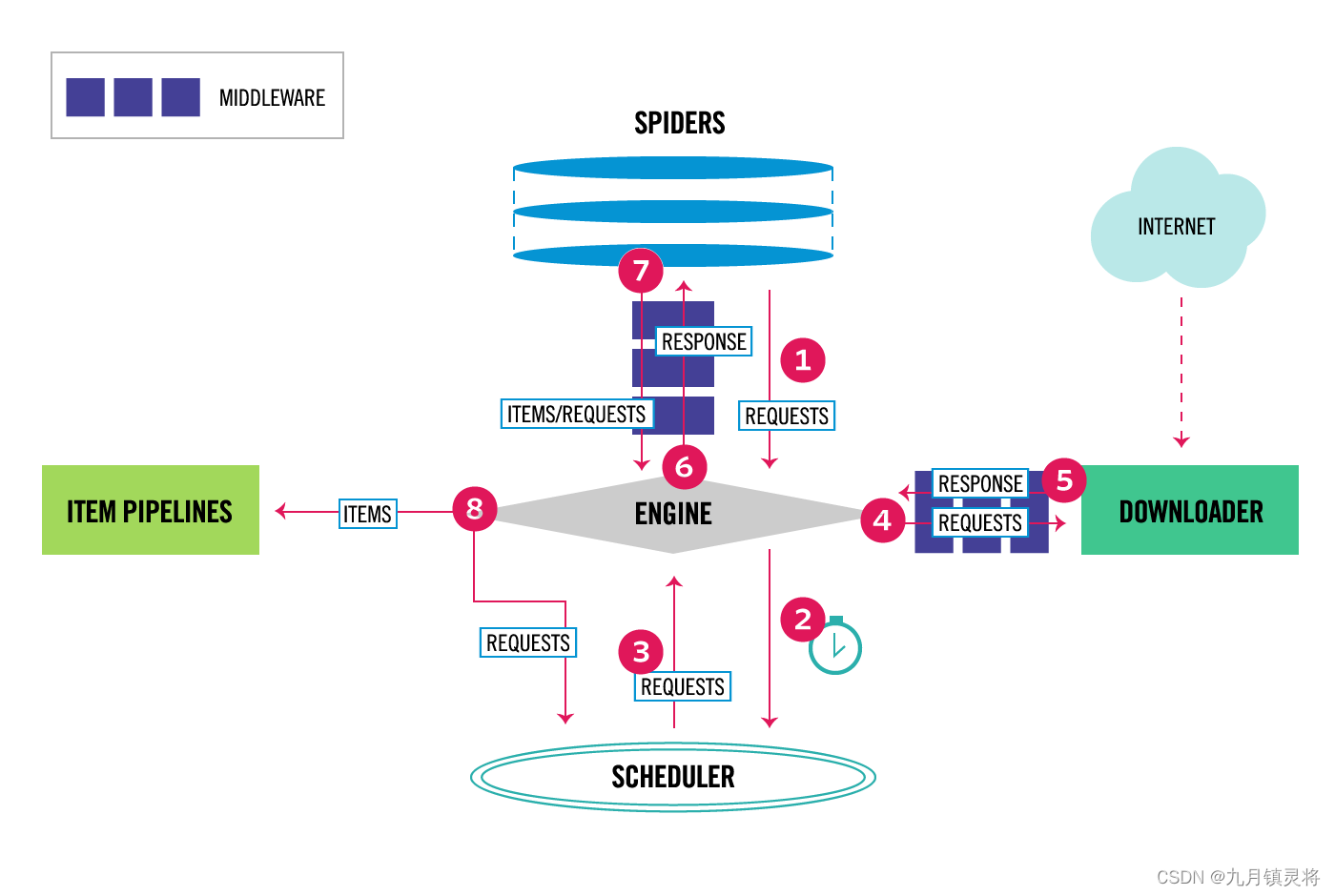
Scrapy核心组件
Scrapy框架主要由以下几个核心组件构成:
- 引擎(Engine):Scrapy的引擎负责控制数据流在系统中所有组件之间的流动。它接收请求并将其分派给调度器,同时也接收来自下载器的响应并将其分派给相应的Spider进行处理。
- 调度器(Scheduler):调度器负责接收请求并将其加入队列中,以便在引擎空闲时按一定的顺序分派给下载器。Scrapy默认使用优先级队列来实现调度器。
- 下载器(Downloader):下载器负责获取网页内容。当引擎将请求分派给下载器时,下载器会向目标网站发起请求,并将获取到的响应返回给引擎。
- Spider:Spider是Scrapy框架中的核心组件之一,负责处理网页内容并提取结构化数据。每个Spider都需要定义一个或多个解析方法,用于从响应中提取数据。
- 项目管道(Item Pipeline):项目管道负责处理Spider提取的数据。你可以在管道中定义一系列的数据处理步骤,如数据清洗、数据验证和数据持久化等。
- 中间件(Middlewares):中间件是Scrapy框架中的一个重要概念,它允许你在请求和响应的处理过程中插入自定义的逻辑。Scrapy提供了下载器中间件和Spider中间件,分别用于处理下载过程中的请求和响应,以及Spider处理过程中的请求和响应。
Scrapy组件之间的交互过程深度解析
Scrapy的各个组件之间的交互过程就像是一个协同工作的流水线,每个组件都有自己特定的任务,并且它们通过消息传递进行交互,确保数据的流畅传递和处理。
-
起始阶段:Spider与引擎的交互
- Spider:首先,Spider会将自己感兴趣的URL或URL模式告知引擎。这是整个流程的起点。
- 引擎:引擎接收到Spider提供的URL后,将其封装成一个请求(Request)对象。
-
调度阶段:引擎与调度器的交互
- 引擎:引擎将封装好的请求对象传递给调度器。
- 调度器:调度器会检查这个请求是否已经被处理过(去重),如果没有,则将其放入待处理队列中。
-
下载阶段:引擎与下载器的交互
- 引擎:引擎从调度器队列中取出一个请求,并交给下载器。
- 下载器:下载器根据请求中的URL,发送HTTP请求到目标网站,并下载网页内容。
-
解析阶段:引擎与爬虫的交互
- 下载器:下载完成后,下载器将下载的网页内容(即响应对象,Response)返回给引擎。
- 引擎:引擎将响应对象交给爬虫进行解析。
- 爬虫:爬虫根据预设的规则,解析响应对象,提取出需要的数据,并可能生成新的请求(比如点击链接、进行分页等)。
-
数据处理阶段:引擎与项目管道的交互
- 爬虫:爬虫将解析得到的数据和新的请求返回给引擎。
- 引擎:引擎将解析得到的数据交给项目管道进行进一步的处理,如清洗、验证和存储。
- 项目管道:项目管道处理完数据后,可以选择将其存储到数据库、文件或其他存储介质中。
-
循环与结束
- 引擎:对于爬虫生成的新请求,引擎会重复上述流程(从调度阶段开始),直到调度器中没有更多的请求,或者达到了某种终止条件(如达到设定的爬取数量、时间等)。
- 结束:当所有请求都处理完毕,且没有新的请求生成时,整个Scrapy流程结束。
在这个过程中,每个组件都扮演着特定的角色,并通过消息传递进行交互。这种协同工作的模式使得Scrapy能够高效地爬取和处理网页数据。同时,Scrapy还提供了丰富的中间件机制,允许用户自定义和扩展各个组件之间的交互过程,以满足更复杂的爬取需求。
Scrapy安装与项目创建
Scrapy的安装
首先,确保你的Python版本是3.6或以上,因为Scrapy需要Python 3.6+。你可以使用以下命令来安装Scrapy:
pip install scrapy
如果你想卸载Scrapy,可以使用以下命令:
pip uninstall scrapy
如果你需要安装特定版本的Scrapy(例如2.6.1版本),可以使用以下命令:
pip install scrapy==2.6.1
安装完成后,你可以通过以下命令来检查Scrapy是否成功安装:
pip list
在列表中,你应该能看到Scrapy及其版本号。
创建Scrapy项目
安装完Scrapy后,你可以开始创建一个新的Scrapy项目。打开终端或命令行,然后导航到你想要创建项目的目录,并使用以下命令来创建一个新的Scrapy项目:
scrapy startproject myproject
这里的myproject是你的项目名称,你可以根据自己的需要来命名。执行上述命令后,Scrapy会在当前目录下创建一个名为myproject的新文件夹,其中包含了一些基本的文件和目录结构。
接下来,你可以在myproject目录下创建一个新的爬虫。使用以下命令来生成一个新的爬虫文件:
cd myproject
scrapy genspider myspider example.com
这里的myspider是你的爬虫名称,example.com是你要爬取的网站域名。执行上述命令后,Scrapy会在myproject/spiders目录下创建一个名为myspider.py的新文件,其中包含了一个基本的爬虫框架。
演示流程图
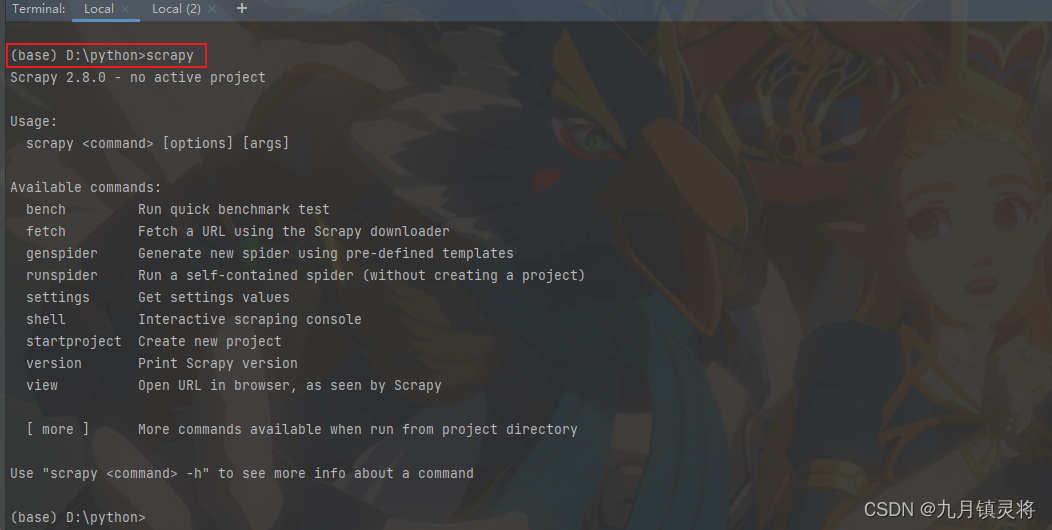
注意,安装scrapy需要进入python环境,如果大家是使用Anaconda安装的python环境,需要进去指定的环境才能进行下面操作,实际上我们直接在pycharm中进行即可
进入指定环境和目录,输入scrapy验证已安装scrapy
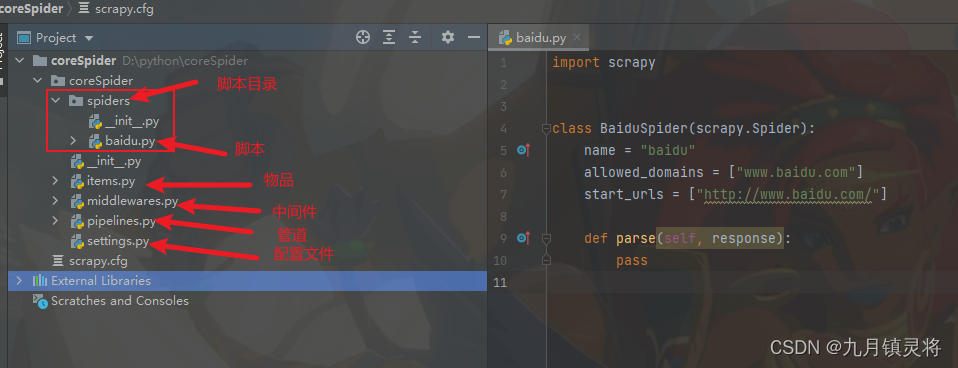
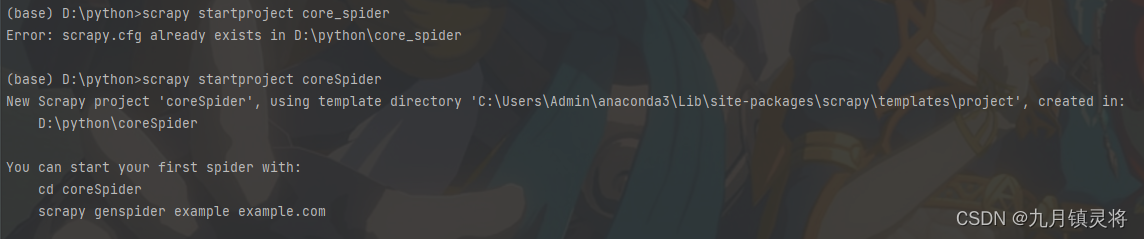
创建项目coreSpider,命令是scrapy startproject coreSpider
进入新创建好的coreSpider目录,先拿百度为例创建爬虫脚本
再使用pycharm打开新创建好的项目即可
项目构成