摘要:最近,看了下慕课2周刷完n道面试题,记录下...
1. JS内存泄漏如何检测?场景有哪些?
1.1 垃圾回收 GC
垃圾回收是一种自动管理内存的机制,它负责在运行时跟踪内存的分配和使用情况,并在不再需要的对象上进行自动内存释放,常用的垃圾回收算法:
标记清除 (Mark-and-Sweep):最常用的垃圾回收算法,垃圾回收器会从根对象(如全局对象、调用栈)出发,标记所有可以访问到的对象,扫描整个堆内存,清除那些未被标记的对象;
引用计数 (Reference Counting):通过记录对象的引用次数来判断对象是否可达。当对象的引用次数为零时,该对象被视为垃圾并进行回收。引用计数算法的缺点是难以解决循环引用问题。
JS闭包属于内存泄漏吗?
内存泄漏是指不再需要的对象(非预期的对象)仍然占用内存,导致系统资源浪费和性能下降。严格意义上说闭包并不算内存泄漏,使用闭包是预期相关对象会继续存在在内存中,闭包的数据不能被垃圾回收更合适,因为它依然保持对外部变量的引用。
1.2 JS内存泄漏如何检测?
主要有如下途径:
- 利用浏览器开发者工具,如Chrome DevTools包含 Memory 面板,可以监控内存使用情况、快照内存状态、查看对象分配情况等;
- 借助的第三方工具,如 Heap Profiler 工具可以捕获 JavaScript 堆栈中的快照,并分析对象的分配情况、引用关系等,从而发现潜在的内存泄漏问题;
- 当然也可以在开发过程中手动检测,避免导内存泄漏的情况出现,例如监听时间处理函数未处理、循环引用的存在等。
1.3 至于内存泄漏的场景(Vue为例)
被全局变量、函数引用,组件销毁时未清除
被全局事件、定时器引用,组件销毁时未清除
被自定义事件引用,组件销毁时未清除
扩展:WeakMap WeakSet
WeakMap和WeakSet是JavaScript的内置对象,它们提供了一种存储对象的弱引用的机制,被广泛用于解决内存泄漏和垃圾回收的问题。他们的特点类似:
WeakMap:
- 一种键值对的集合,其中键必须是对象,值可以是任意类型。键是对象的弱引用,即当对象没有其他引用时,垃圾回收机制可以自动清理该键值对(Vue 3的响应系统中也是用了WeakMap这一特性避免内存泄漏);
- 没有提供遍历方法,也不能获取其大小或键列表;
- 由于键是弱引用,所以 WeakMap 是不可迭代的,也不支持常规的对象方法,如 size、forEach 等;
- 主要用于存储额外的数据或元数据,这些数据与对象的生命周期相关,当对象被销毁时,与之关联的额外数据也会被自动清除。
WeakSet:
- 一种存储对象的集合,其中的对象是弱引用,同样在没有其他引用时,垃圾回收机制可以自动清除对象。 只能存储对象,不能存储原始值;
- 不可迭代,也没有提供查询大小、遍历等功能;
- 主要用于存储一组对象,并且需要确保这些对象不会产生内存泄漏;
- 与 Set 不同,WeakSet 中的对象是弱引用,因此它们不会阻止垃圾回收器销毁这些对象。
2. 浏览器和node.js的事件循环有什么区别?
2.1 浏览器事件循环
JS是单线程的(无论浏览器还是nodejs),浏览前中JS执行和DOM渲染共用一个线程,这就需要使用异步编程模型,实现非阻塞的操作,提高程序的性能和响应速度。这就需要使用事件循环机制来处理异步操作,这些异步任务又被分为宏任务和微任务。
宏任务是一个独立的、完整的任务单元,比如setTimeout SetInterval 网络请求
微任务通常是一些更小粒度的任务,如Promise async/await
微任务会被插入到微任务队列(microtask queue)中,在每个宏任务执行完成后,事件循环会检查微任务队列,然后依次执行微任务,直到微任务队列为空
console.log('start')
setTimeout(() => {
console.log('timeout')
})
Promise.resolve().then(() => {
console.log('promise then')
})
console.log('end')
// start
// end
// promise then
// timeout
// 微任务在页面渲染前触发,宏任务是在页面渲染之后触发
const p = document.createElement('p')
p.innerHTML = 'new paragraph'
document.body.appendChild(p)
const list = document.getElementsByTagName('p')
console.log('length----', list.length)
console.log('start')
setTimeout(() => { // 渲染之后触发
const list = document.getElementsByTagName('p')
console.log('length on timeout----', list.length)
alert('阻塞 Timeout')
})
// DOM 渲染
Promise.resolve().then(() => { // 渲染前触发
const list = document.getElementsByTagName('p')
console.log('length on promise.then----', list.length)
alert('阻塞 promise')
})
console.log('end')
// length---- 67
// start
// end
// length on promise.then---- 67
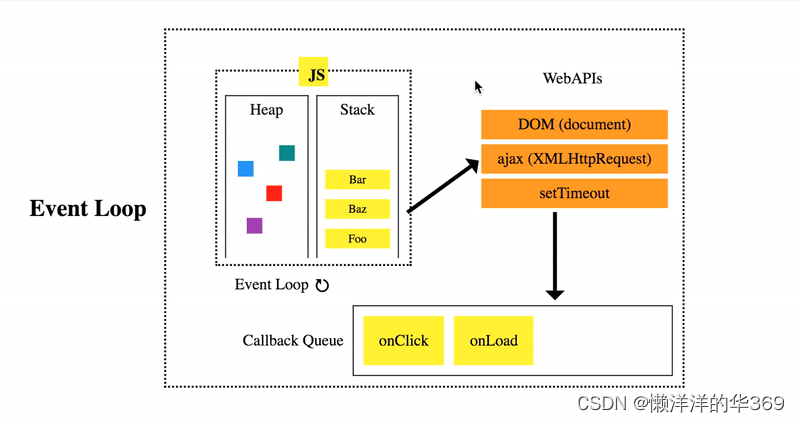
// length on timeout---- 67参考下图,浏览器事件循环机制首先执行左上角的同步代码,遇到异步任务会放入Callback Queue(现在已经分为Macro Queue 和Micro Queue)中,等同步代码执行完成之后,通过Event Loop机制执行队列中的任务
2.2 Node.js事件循环
Nodejs同样使用ES语法,也是单线程,也需要异步;异步任务也分为:宏任务 + 微任务
Node.js中事件循环实现是依靠libuv 引擎事件循环中表现得状态与浏览器大致相同。Node.js事件循环的大致执行流程也是先执行同步代码,再执行微任务(process.nextTick),按顺序执行6个类型的宏任务(每当开始之前都执行当前的微任务)
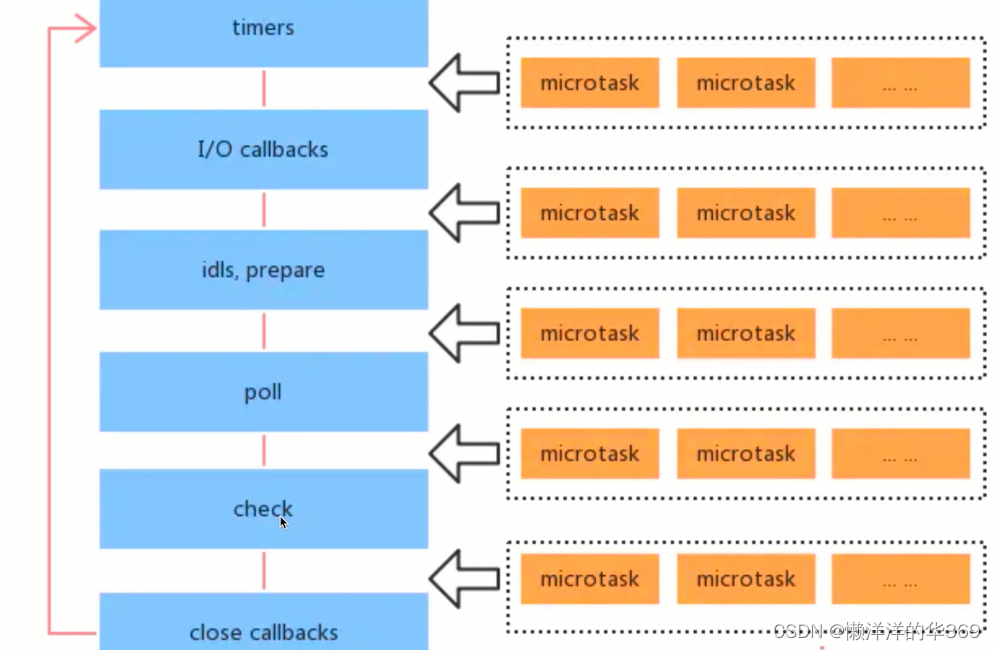
但是,Node.js的宏任务和微任务,分不同类型,有不同的优先级
Node.js中宏任务的类型和优先级(由高到低):
- Timers - setTimout setInterval
- I/O callbacks - 处理网络、流、TCP的错误回调(执行延迟到下一个循环迭代的I/O回调)
- Idle,prepare - 闲置状态(Node.js内部使用)
- Poll轮询 - 执行poll中的I/O队列
- Check检查 - 存储setImmediate回调
- Close callbacks - 关闭回调,如socket.on('clos')
Node.js 微任务类型和优先级:
包括: Promise,async/await,process.nextTick,其中process.nextTick优先级最高
总之,在一次事件循环中,先执行当前执行栈中的代码,然后检查是否有微任务需要执行,如果有,则依次执行微任务,直到微任务队列为空;接着从宏任务队列中提取下一个宏任务进行执行。这样的设计保证了微任务能够在宏任务执行结束之后立即得到执行,从而更及时地处理异步操作的结果。
注:
MDN上最新描述已经不再使用宏任务,沿用它是为了更容易理解
在 JavaScript 中通过 queueMicrotask() 使用微任务 - Web API 接口参考 | MDN一个微任务(microtask)就是一个简短的函数,当创建该微任务的函数执行之后,并且只有当 Javascript 调用栈为空,而控制权尚未返还给被用户代理用来驱动脚本执行环境的事件循环之前,该微任务才会被执行。事件循环既可能是浏览器的主事件循环也可能是被一个 web worker 所驱动的事件循环。这使得给定的函数在没有其他脚本执行干扰的情况下运行,也保证了微任务能在用户代理有机会对该微任务带来的行为做出反应之前运行。![]() https://developer.mozilla.org/zh-CN/docs/Web/API/HTML_DOM_API/Microtask_guide
https://developer.mozilla.org/zh-CN/docs/Web/API/HTML_DOM_API/Microtask_guide
Node.js新版本,推荐使用setImmediate代替process.nextTick。
3. 遍历数组,for和forEach那个更快?
先上代码验证下,结论是用for通常会比forEach更快
const arr = []
for(let i = 0; i < 100*10000 ; i++) {
arr.push(i)
}
const length = arr.length
console.time('for')
let n1 = 0
for (let i = 0; i < length; i++) {
n1++
}
console.timeEnd('for') // 3.838134765625 ms
console.time('forEach')
let n2 = 0
arr.forEach(() => n2++)
console.timeEnd('forEach') // 14.0830078125 msforEach每次都要创建一个函数来调用(函数需要对立的作用域,会有额外的性能开销),而for不会创建函数。
除此之外,使用for的优点还有:
- 更多控制:使用for循环可以更灵活地控制循环过程,可以通过控制索引来实现跳过、中断、反向等操作。
- 可中断性:for循环可以通过break语句或return语句随时中断循环,而forEach方法不支持中断循环,只能通过抛出异常来模拟中断。 虽然for循环在性能上可能更快,但在某些情况下,使用forEach方法可能更具可读性和简洁性
3. 虚拟DOM(vdom)真的很快吗?
虚拟DOM(virtual dom) 一种用于简化 UI 更新和渲染逻辑的技术, 主要优点在于简化了对真实 DOM 的频繁操作。我们知道Vue React等框架的核心价值在于实现了数据视图分离,数据驱动视图。这样前端程序员coding实只关注业务数据,而不用再关心DOM变化,它们实现数据驱动视图的技术方案就是vdom。
实际上,vdom并不快,JS直接操作DOM才是最快的;但是"数据驱动视图"需要合适的技术方案,不能全部DOM重建;vdom就是目前最合适的技术方案(并不是因为它快,而是合适)。
扩展:svelte框架就不用vdom
5. Node.js如何开启多进程?进程如何通讯?
进程(Process) VS 线程 (Thread)
进程,OS进行资源分配和调度的最小单位,有独立的内存空间
线程,OS进行运算调度的最小单位,共享进程内存空间
JS是单线程的,但是可以开启多个进程执行,如WebWorker
为何需要多进程?
多核CPU,更适合处理多进程
内存较大,多个进程才能更好的利用(单进程有内存上限,一般2G左右)
总之,"压榨"机器资源,更快,更节省
通过child_process.fork开启子进程
/**
* 主进程
*/
const http = require('http')
const fork = require('child_process').fork
const server = http.createServer(() => {
if(req.url === '/get-sum') {
console.info('主进程 id', process.pid)
// 开启子进程
const computeProcess = fork('./computer.js')
computeProcess.send('开始计算')
computeProcess.on('message', data => {
console.info('主进程接收到信息:', data)
res.end('sum is ' + data)
})
computeProcess.on('close', data => {
console.info('主进程因报错而退出')
computeProcess.kill()
res.end('error')
})
}
})
server.listen(3000, () => {
console.info('localhost: 3000')
})
/**
* computed.js 子进程,计算
*/
function getSum() {
let sum = 0
for (let i = 0; i <10000; i++) {
sum += i
}
return sum
}
//子进程可以通过这种自定义事件的方式来监听
process.on('message', data => {
console.log('子进程 id', process.pid)
console.log('子进程接收到的信息‘, data)
const sum = getSum()
// 发送消息给主进程
process.send(sum)
})
//localhost: 30000
// 主进程 id: 80780
// 子进程 id: 80781
// 子进程接收到的信息: 开始计算
// 主进程接收到的信息: 49995000未完待续……