目录
- 1. 算法总览
- 2. 算法详解
- 2.1. 基础相关滤波跟踪
- 2.2. 各模块详解
- 2.2.1. 相关跟踪
- 2.2.2. 在线检测器
- 3. 算法实现
- 3.1. 算法步骤
- 3.2. 实现细节
- 4. 相关讨论&总结
1. 算法总览
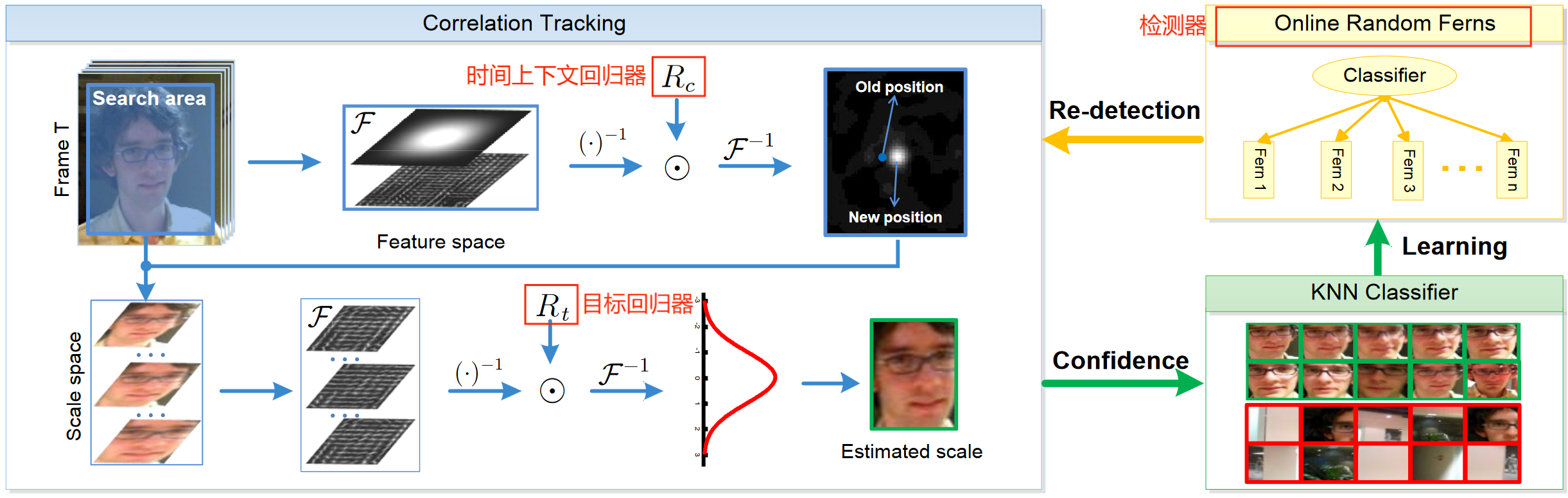
LCT的总体流程如上图所示,其思想为:将长时跟踪(long-term tracking)分解为对运动目标的平移(translation)估计和尺度(scale)变化估计,再配置一个检测器(detector),以实现re-detection。
其主要包含三个模块,即图中标红的部分,分别为:
- 时间上下文回归器 R c R_c Rc:旨在积极适应平移估计来解决重大变形和重度遮挡问题。
- 目标回归器 R t R_t Rt:保守地适应并应用于外观金字塔以进行尺度估计。
- 检测器 D r f D_{rf} Drf:在跟踪失败的情况下激活目标重新检测,并通过使用目标回归器来决定是否采用重新检测结果。
2. 算法详解
2.1. 基础相关滤波跟踪
LCT中无论是对运动目标的位置平移估计还是尺度变化估计,都是在相关滤波跟踪方法的基础上改良得到的。
相关跟踪可以总结为公式(1),如下所示:
w
=
arg
min
w
∑
m
,
n
∣
ϕ
(
x
m
,
n
)
⋅
w
−
y
(
m
,
n
)
∣
2
+
λ
∣
w
∣
2
(1)
w=\mathop{\arg\min}\limits_w \sum_{m,n} |\phi(x_{m,n})\cdot w-y(m,n)|^2+\lambda|w|^2 \tag{1}
w=wargminm,n∑∣ϕ(xm,n)⋅w−y(m,n)∣2+λ∣w∣2(1)
其中:
-
w w w表示训练出的滤波器参数
-
x m , n x_{m,n} xm,n代表图像块的大小为 M × N M×N M×N
-
y ( m , n ) y(m,n) y(m,n)代表应用二维高斯函数生成得到的高斯标签
-
ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)代表映射到核空间的操作,即核函数
-
λ \lambda λ是正则化参数。
这个公式有些类似于KCF中的公式,具体可以参考这篇Kernelized Correlation Filters KCF算法原理详解(阅读笔记)中的公式(2),其实就是应用了kernel-trick的岭回归加上一个高斯标签来训练得到一个滤波器。关于岭回归,可以学习这篇岭回归详解 从零开始 从理论到实践。
文中提到,由于应用的高斯标签
y
(
m
,
n
)
y(m,n)
y(m,n)并不是单纯的二分类标签(即0代表背景,1代表目标),而是加上了高斯权重,因此其学习到的滤波器
w
w
w包含高斯岭回归系数,而不是一个二进制分类器,
w
w
w可以被表示为:
w
=
∑
m
,
n
a
(
m
,
n
)
ϕ
(
x
m
,
n
)
(2)
w=\sum_{m,n}a(m,n)\phi(x_{m,n}) \tag{2}
w=m,n∑a(m,n)ϕ(xm,n)(2)
这里为什么又可以这样表示呢?我个人理解为这里是因为应用了核方法。
什么是核方法?基于相关滤波的跟踪首先就是要训练一个滤波器,然后基于滤波器来区分目标和背景对吧。也就是说,这可以被简化为一个二分类模型的训练问题。
假如我们的目标和背景是线性可分的,即我们可以训练一个线性分类器:
f
(
x
)
=
w
T
(3)
f(x)=w^T \tag{3}
f(x)=wT(3)
来在当前的特征空间中将目标和线性分类的很好,这自然是皆大欢喜。式中的
x
x
x是一个矩阵,每一行代表一个样本,每一列代表各个样本的某一个属性(注意,这里只考虑了一维的情况)。
w
w
w同样是采用岭回归进行训练得到的滤波器参数(也可以理解为滤波器本身)。
而当数据在当前的特征空间中不能线性可分时,我们可以考虑把数据特征从当前特征空间映射到更高维的空间,从而使得在低维空间不可分的情况到高维空间之后就能变的线性可分了。核函数主要的目的就是把一个线性问题映射到一个非线性核空间,这样把在低维空间不可分的到核空间之后就能够可分了。
因此,需要找到一个非线性映射函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅),使得映射后的样本在高维空间中线性可分。那么在这个高维空间中,就可以使用岭回归来寻找一个分类器 f ( x i ) = w T ϕ ( x i ) f(x_i)=w^T\phi(x_i) f(xi)=wTϕ(xi),其中, ϕ ( x i ) \phi(x_i) ϕ(xi)表示对样本 x i x_i xi通过非线性映射函数 ϕ \phi ϕ变换到高维空间后的样本向量。
对于分类模型
f
(
x
i
)
=
w
T
ϕ
(
x
i
)
f(x_i)=w^T\phi(x_i)
f(xi)=wTϕ(xi),
f
(
x
i
)
f(x_i)
f(xi)和
x
i
x_i
xi都已知,
ϕ
(
⋅
)
\phi(\cdot)
ϕ(⋅)取决于我们选取的映射函数,因此主要是想求得对
w
w
w的解,而在使用Kernel-trick之后,
w
w
w可以用训练样本的线性组合来表示:
w
=
∑
i
a
i
ϕ
(
x
i
)
(4)
w=\sum_i{a_i \phi(x_i)} \tag 4
w=i∑aiϕ(xi)(4)
则最优化问题不再是求解
w
w
w,而是
a
a
a。至于为什么可以将
w
w
w表示为样本的线性组合,可以参考这篇高维映射 与 核方法(Kernel Methods),里面有详细的解释,建议精读。
公式(4)拓展到二维情况,即可以得到公式(2)。
对于
a
a
a,其可以由以下公式得到:
A
=
F
(
a
)
=
F
(
y
)
F
(
ϕ
(
x
)
⋅
ϕ
(
x
)
)
+
λ
(5)
A=\mathcal{F}(a)=\frac{\mathcal{F}(y)}{F(\phi(x)\cdot\phi(x))+\lambda} \tag{5}
A=F(a)=F(ϕ(x)⋅ϕ(x))+λF(y)(5)
其中,
F
\mathcal{F}
F代表离散傅里叶变换。
公式(5)也是相关滤波算法中的常见公式,我个人是在推过一遍KCF的算法公式之后,看到公式(5)直接秒了。不理解的去看KCF原文中的公式(16)以及其推导过程,同样可以参考这篇Kernelized Correlation Filters KCF算法原理详解(阅读笔记)。
在训练得到
a
a
a之后,对于一张大小为
M
×
N
M×N
M×N的测试图像patch
z
z
z,计算其响应图如下:
y
^
=
F
−
1
(
A
⊙
F
(
ϕ
(
z
)
⋅
ϕ
(
x
^
)
)
)
(6)
\hat{y}=\mathcal{F}^{-1}(A\odot \mathcal{F}(\phi(z)\cdot\phi(\hat{x}))) \tag{6}
y^=F−1(A⊙F(ϕ(z)⋅ϕ(x^)))(6)
其中,
F
−
1
\mathcal{F}^{-1}
F−1表示逆傅里叶变换,也就是将结果从频率域转换到咱们常见的时间域,
⊙
\odot
⊙代表哈达姆积,也就是element-wise product,逐元素相乘。
x
^
\hat{x}
x^是学习到的目标外观模型,也就是训练滤波器时作为输入的训练图像patch
x
x
x的特征。
这个公式也很好理解吧,我们从最简单的一维情况考虑,基于公式(3)和公式(4),在非线性情况下,对于一个新的输入
z
z
z,有
f
(
z
i
)
=
w
T
ϕ
(
z
i
)
=
∑
i
a
i
ϕ
(
x
i
)
ϕ
(
z
i
)
\begin{align*} f(z_i)&=w^T\phi(z_i) \\ &=\sum_i{a_i \phi(x_i)}\phi(z_i) \tag{7} \end{align*}
f(zi)=wTϕ(zi)=i∑aiϕ(xi)ϕ(zi)(7)
公式(7)拓展到2维情况,符号一改,再加个傅里叶逆变换,不就是公式(6)了吗,秒了!
2.2. 各模块详解
原文中曾提到过对以前工作的两点观察,分别为:
-
对于一个视频流,当其连续帧之间的时间间隔很短时(比如<0.04秒),其帧间变化也会很小。即使目标此时遭遇严重遮挡,其周围的上下文环境仍然可能保持不变。因此,对由跟踪目标及其上下文组成的外观时间关系进行建模非常重要。
it is important to model the temporal relationship of appearance consisting of a target object and its context.
-
增强长期跟踪器的检测模块对(i)估计比例变化和(ii)在长时间遮挡或者在视野外发生跟踪失败的情况下重新检测跟踪目标是至关重要的。
Second, it is critical to enhance the detection module of a long-term tracker to (i) estimate the scale change and (ii) redetect the object in case of tracking failure when long-term occlusion or out-of-view occurs.
读完全文,可以发现这两点观察基本上就昭示了后文的所有工作。即:
- 对于一个long-term跟踪任务,LCT会基于观察1,对跟踪目标及其周围的上下文环境进行建模,这里对应了时间上下文模块 R c R_c Rc。
- 作者认为,长时跟踪算法需要对跟踪目标进行尺度估计,这对应了目标回归器 R t R_t Rt。
- 当由于长时间的遮挡和消失出视野等原因而导致跟踪失败时,需要一个检测器来实现re-detection。
再回过来这张图,可以发现LCT的流程其实也很简单,位移估计+尺度估计统一构成了对运动目标的跟踪,当跟踪失败时,应用检测器来进行re-detection即可,至于图中的KNN classfier,我们后面再看。
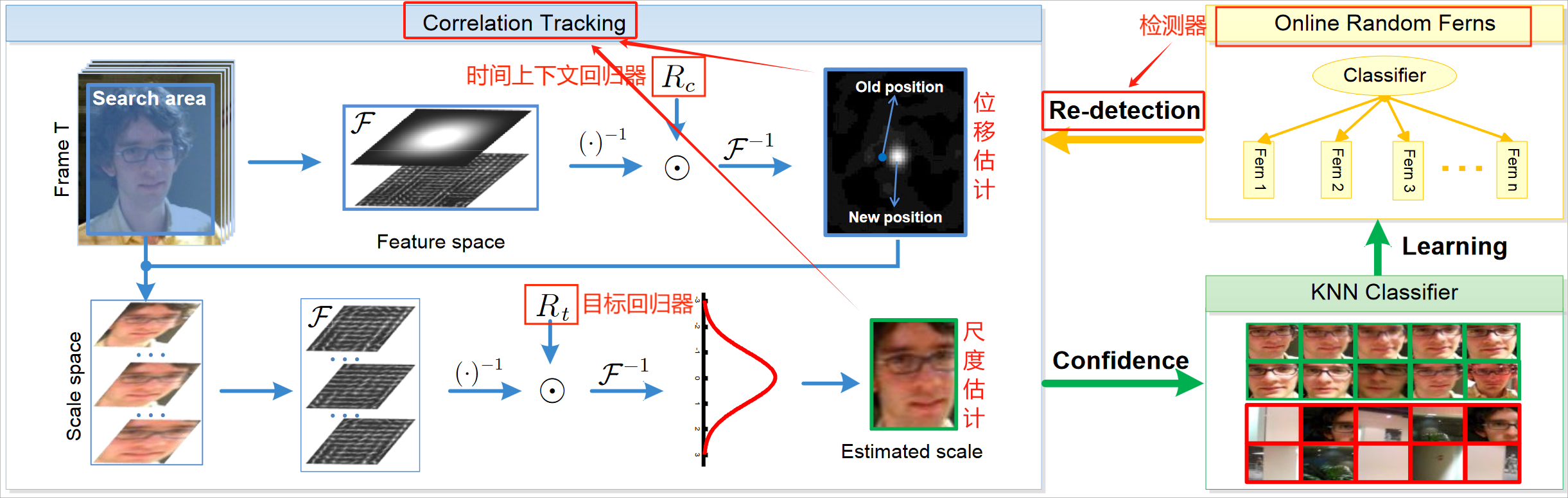
2.2.1. 相关跟踪

如图所示,相关跟踪部分由时间上下文回归器实现的平移估计+目标回归器实现的尺度估计构成。
对于时间上下文回归器 R c R_c Rc:
-
其接收目标和周遭上下文信息作为输入,将这些信息(像素值)转化为某种特征(后面会说是什么特征)。
-
如图中所示,同样原文中也提到:为了消除响应图的空间不连续性,对输入的特征施加了空间权重(Spatial weights)。这里是通过余弦窗实现的,其实就是越靠近中心的像素生成的特征会被赋予更大的权重(目标附近的特征对最终的位置估计有更大的贡献,而远离目标的特征则贡献较小。)。
-
考虑到回归器的自适应更新能够更好地应对目标被遮挡、变形和突然消失的情况,因此 R c R_c Rc以学习率 α \alpha α进行更新,如公式(8)所示:
x ^ t = ( 1 − α ) x ^ t − 1 + α x t , A ^ t = ( 1 − α ) A ^ t − 1 + α A t , \begin{align} \hat{x}^t&=(1-\alpha)\hat{x}^{t-1}+\alpha x^t, \tag{8a}\\ \hat{A}^t&=(1-\alpha)\hat{A}^{t-1}+\alpha A^t, \tag{8b}\\ \end{align} x^tA^t=(1−α)x^t−1+αxt,=(1−α)A^t−1+αAt,(8a)(8b)
其中, t t t代表时间帧编号, x ^ \hat{x} x^是学习到的目标外观模型,也就是训练滤波器时作为输入的训练图像patch x x x的特征。 x t x^t xt代表第 t t t帧的输入特征。 A ^ \hat{A} A^代表之前学习到的参数,也就是滤波器, A t A^t At则代表基于当前帧特征学习得到的参数。
对于目标回归器 R t R_t Rt:
-
对于一个响应图,选取其 y ^ \hat{y} y^的最大值作为跟踪结果的置信度。
-
为了保持模型的稳定性,使用了预定义的阈值 T a \mathcal{T}_a Ta,如果 m a x ( y ^ ) ≥ T a max(\hat{y}) \ge \mathcal{T_a} max(y^)≥Ta,则使用公式(8)来更新 R t R_t Rt,这样就保证了 R t R_t Rt只在比较可靠的帧(与之前的模板匹配程度更高的帧)上进行训练学习。即原文中提到的:
we learn another discriminative regression model Rt from the most reliable tracked targets.
-
对于 R t R_t Rt接收的输入特征,没有像 R c R_c Rc一样采用余弦窗来附加空间权重。
-
在跟踪过程中,以 R c R_c Rc预测的位置为中心,构建目标金字塔以进行尺度估计:
-
设跟踪目标的大小为 P × Q P×Q P×Q,总共有 N N N个不同尺度;
-
尺度集合 S = { a n ∣ n = ⌊ − N − 1 2 ⌋ , ⌊ − N − 3 2 ⌋ , … , ⌊ − N − 1 2 ⌋ } S=\{ a^n|n=\left \lfloor -\frac{N-1}{2} \right \rfloor, \left \lfloor -\frac{N-3}{2} \right \rfloor , \dots, \left \lfloor -\frac{N-1}{2} \right \rfloor \} S={an∣n=⌊−2N−1⌋,⌊−2N−3⌋,…,⌊−2N−1⌋},对于 s ∈ S s\in S s∈S,以预测位置为中心,提取一个大小为 s P × s Q sP\times sQ sP×sQ的图像patch J s J_s Js;
-
将提取出的所有patch归一化到 P × Q P\times Q P×Q的统一大小,并提取其HOG特征;
-
对于 s ∈ S s\in S s∈S,将各个尺度对应 J s J_s Js的HOG特征与 R t R_t Rt进行相关操作,从而得到 N N N个响应图,每个响应图都对应一种尺度,计算其最大响应度值;
-
则最优尺度 s ^ \hat{s} s^可以由下式计算得到:
s ^ = arg max s ( m a x ( y ^ 1 ) , m a x ( y ^ 2 ) , … , m a x ( y ^ S ) ) (9) \hat{s}=\mathop{\arg\max}\limits_s(max(\hat{y}_1), max(\hat{y}_2),\dots,max(\hat{y}_S)) \tag{9} s^=sargmax(max(y^1),max(y^2),…,max(y^S))(9)
-
-
如前面所述,当 m a x ( y ^ s ^ ) ≥ T a max(\hat{y}_{\hat{s}}) \ge \mathcal{T}_a max(y^s^)≥Ta时,更新目标回归器 R t R_t Rt,从而保证 R t R_t Rt只在可靠帧上进行训练和学习。
2.2.2. 在线检测器
当跟踪失败时,long-term跟踪器需要一个检测模块来实现对跟踪目标的re-detection。在以往的工作中,检测器对每一帧都进行重新检测,而本文则采用了一个阈值 T r \mathcal{T}_r Tr,只有当 m a x ( y ^ s ^ ) < T r max(\hat{y}_{\hat{s}})< \mathcal{T}_r max(y^s^)<Tr时,才激活检测器。
文中提到,为了提高计算效率,并没有使用目标回归器 R t R_t Rt作为检测器(因为检测器需要对全局图像进行搜索),而是使用随机蕨(Random Ferns)分类器来进行检测:
-
令 c i , i ∈ { 0 , 1 } c_i,i\in\{0,1\} ci,i∈{0,1}表示类别标签, f j , j ∈ { 1 , 2 , … , N } f_j,j\in\{1,2,\dots ,N\} fj,j∈{1,2,…,N}为二元特征的集合,即,对于每一个图像块,提取 N N N个特征。常见的蕨分类器(其实就是TLD算法中的蕨分类器)使用的特征是2bit BP特征,即2bit Binary Pattern特征,参见这篇随机蕨(Random Fern)。
-
以2bit BP特征为例,所有二元特征 f j f_j fj取不同的值(0或1),一直一直向下延伸,像一个二叉树一样,最终在不同的叶节点组成了不同的“Fern”,如下图所示:
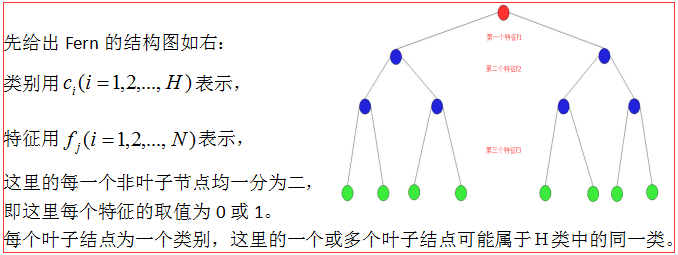
图中的绿色节点就是叶子节点,代表最终的特征,也就是“Fern”。
有点抽象我知道,所以还是建议先精读这篇随机蕨(Random Fern)和初探随机蕨(Random Ferns),先理解什么是
2bit BP,以及为什么 f j f_j fj明明是不同的特征,却都只能取值为0或1。其实,2bit BP就是对图片中的某两个像素点进行灰度值大小比较,如下图所示,当蓝色点所在的像素值大于红色点所在的像素值则二元测试结果为1,反之为0 (注意,每一个特征 f j f_j fj所选取的比较位置在被确定之后后都保持不变):

总而言之,由于 f j f_j fj只能取值 { 0 , 1 } \{0,1\} {0,1},因此最终形成的特征,也就是叶节点,为一个二值串。
-
假设有13种特征,每个特征 f j f_j fj都能取值为0或1,则最终能生成 2 13 2^{13} 213个叶节点,也就是 2 13 2^{13} 213种二值串。这些字符串代表了不同的特征。那么怎么用这个特征来判断到底是背景(标签为0)还是目标(标签为1)呢?其实只是基于简单的条件概率即可。
用 F k F_k Fk表示由所有不同特征 f j f_j fj组成的最终特征,则有:
P ( F k ∣ C = c i ) = N k , c i N k (10) P(F_k|C=c_i)=\frac{N_{k,c_i}}{N_k} \tag{10} P(Fk∣C=ci)=NkNk,ci(10)
其中, N k , c i N_{k,c_i} Nk,ci表示最终特征为 F k F_k Fk且标签为 c i c_i ci的样本数量, N k N_k Nk表示最终特征为 F k F_k Fk的所有样本数量。 -
那么,基于这个先验概率,对一个待检测的图像patch,当其得到的特征为 F k F_k Fk时,则可以基于公式(11)得到其标签:
c i = arg max c i ∏ k = 1 M P ( F k ∣ C = c i ) (11) c_i=\mathop{\arg\max}\limits_{c_i} {\textstyle \prod_{k=1}^{M}}P(F_k|C=c_i)\tag{11} ci=ciargmax∏k=1MP(Fk∣C=ci)(11)
3. 算法实现
3.1. 算法步骤
文中给出了LCT的为代码实现,简单易懂,如下所示:

3.2. 实现细节
- 输入特征:
- 时间上下文回归器 R c R_c Rc:HOG,31bins,灰度直方图,8bins,以及一个额外的8bins特征。总共47通道的特征。
- 目标回归器 R t R_t Rt:HOG,31通道。
- 随机蕨检测器 D r f D_{rf} Drf:采用2bit BP特征,将每个具有高置信度的跟踪结果对应的图像patch resize到15×15,从而获取对应的像素对特征。
- 核函数选择:高斯核,即 k ( x , x ′ ) = e x p ( − ∣ x − x ′ ∣ 2 σ 2 ) k(x,x')=\rm{exp}(-\frac{|x-x'|^2}{\sigma^2}) k(x,x′)=exp(−σ2∣x−x′∣2)。
- 检测器:检测器基于窗口扫描法来对全局图像进行搜索,同时结合KNN算法,对于某一个未知标签的图像patch,如果训练集中 k k k个最近的特征向量都具有正向标签( k = 5 k=5 k=5),则将该patch预测为目标。
4. 相关讨论&总结
long-term跟踪领域的经典之作,原理简单,结构清晰明了,感谢马超大神和他的团队成员。
这篇跟踪置信度与Long-term讨论了LCT的性能。除此之外,我在其他人的总结里面也看到了不少对LCT实际性能的评价,好像没有论文中说的那么好,还待测试实际效果。








![[Redis]——数据一致性,先操作数据库,还是先更新缓存?](https://img-blog.csdnimg.cn/direct/3e043ea768e0470db53c0bfd3d15162e.png)