一、关于mismatch问题
在training阶段和inference阶段使用不同的阈值很容易导致mismatch,什么意思呢?
在training阶段,由于给定了GT,所以可以把与GT的IoU大于阈值的proposals作为正样本,这些正样本参与之后的bbox回归学习和分类。
在inference阶段,由于GT是未知的,所以只能把所有的proposals都当作正样本,让后面的bbox回归器回归坐标。且在inference阶段,只有生成的proposals自身的IoU值和训练器训练时设定的IoU阈值较为接近时,训练器输出的IoU值才会高即网络性能才好。
所以在training阶段和inference阶段,bbox回归的输入分布是不一样的,training阶段输入的proposals质量更高(被采样过,IoU>threshold),inference阶段的输入proposals质量相对较差(没有采样过,可能包含很多IoU<threshold的情况),这就是论文中提到的mismatch问题,这个问题是固有存在的,通常threshold取 时,mismatch问题不会很严重。
二、关于单纯增大训练时IoU阈值问题
在训练阶段,IoU一般设定为 ,在RPN选择正负anchor的时候,往往会产生close but not correct的框,而检测器必须找到正样本并且抑制这些IoU接近于正样本的负样本,“However,to produce a high quality detector,it does not suffice to simply increase IoU during training.”
单纯的增大训练时的IoU阈值会带来什么问题呢?
- 过拟合问题。提高了IoU阈值,满足这个阈值条件的proposals必然比之前少了,即正样本数量减少,容易导致过拟合。
- 带来更严重的mismatch问题。R-CNN结构本身就有这个问题,IoU阈值变得更高,在inference阶段产生的proposals分布与训练时的proposals分布之间的mismatch会更加的严重,进而使得网络预测结果变差。
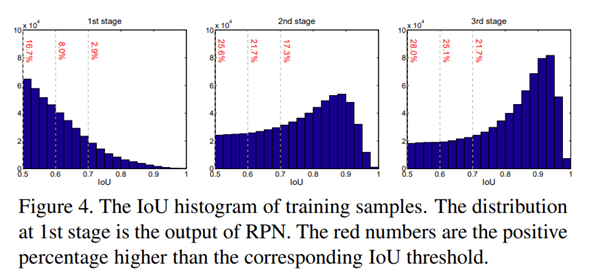
从上图可以看到,随着stage的加深,相应区域的positive依旧拥有大量的proposal,因此不会出现严重的过拟合现象。