基于机器学习与协同过滤的图书推荐系统
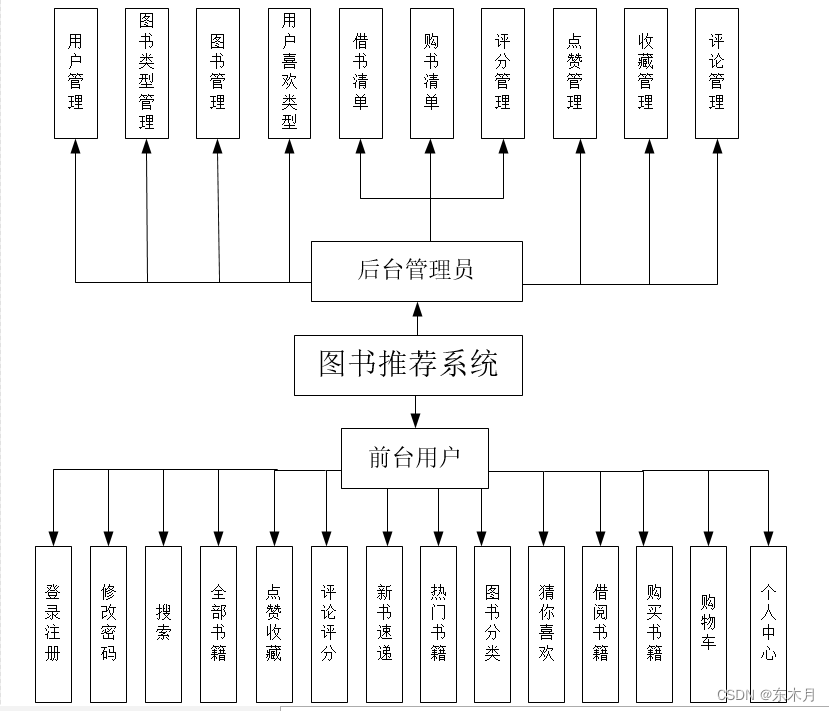
一、系统结构图
二、Demo示例
完整源码可联系博主微信【1257309054】
点我跳转

三、K-means聚类机器学习推荐算法
1、原理
从数据库中
1、首先获取书籍类别
2、获取用户注册时勾选喜欢的类别,勾选的为1,否则为0,得到一个样本数据
例:[1,0,1,0,0,...],[1,1,1,0,1,...],[0,0,1,0,0,...],
3、使用k-mean算法把用户分成6类【用户模型】
4、获取6类的【用户模型】的质心,比如[1,0,1,0,0,...]
把为1的类别找出来,然后获取该类别排行前3的书籍,组成一个推荐列表推荐给用户
5、类别书籍排行按收藏量来排序
6、用户购买书籍行为会动态更新样本数据
2、代码示例
# !/usr/bin/python
# -*- coding: utf-8 -*-
"""
@contact: 微信 1257309054
@file: test.py
@time: 2023/1/8 13:04
@author: LDC
"""
import collections
import joblib
import django
import os
import threading
from sklearn.cluster import KMeans
from book.models import User, Tags, UserSelectTypes
os.environ["DJANGO_SETTINGS_MODULE"] = "book.settings"
django.setup()
def get_data():
# 获取样本数据
users = User.objects.all() # 获取所有用户
data = []
for user in users:
tag_dict = collections.OrderedDict() # 书籍类型字典(有序字典)
# 获取所有类型,并设置值为0
for tag in Tags.objects.filter(is_show=True):
tag_dict[tag.name] = 0
# 获取用户喜欢的书籍类型
us = UserSelectTypes.objects.get(user=user)
for category in us.category.filter(is_show=True):
# 在类型字典中设置用户喜欢的类型为1
tag_dict[category.name] = 1
data.append(list(tag_dict.values()))
return data
def fit(data):
# k-mean模型训练
# 实例化K-Means算法模型,使用6个簇聚类
cluster = KMeans(n_clusters=6, random_state=0)
# 使用数据集X进行训练
cluster = cluster.fit(data)
print('重新预测数据', '各类型质心为')
for i, centers in enumerate(cluster.cluster_centers_):
print('第{}类'.format(i), centers)
return cluster
def save_model(model):
# 保存模型
joblib.dump(model, 'book-k-mean.dat')
def predict(data):
# 预测数据
loaded_model2 = joblib.load('book-k-mean.dat')
# 使用模型预测数据并获取质心
result = loaded_model2.cluster_centers_[loaded_model2.predict(data)[0]]
return list(map(lambda x: 1 if x > 0 else 0, result)) # 把质心列表设置成只有0,1值
def k_mean_main(is_run):
# 使用机器学习k-means聚类算法训练样本数据并保存
data = get_data()
if len(data) and len(data) % 2 == 0 or is_run:
# 当样本数据是6的倍数时才进行重新训练
model = fit(data)
save_model(model)
def k_mean_run(is_run=False):
# 开线程来训练样本数据
threading.Thread(target=k_mean_main, args=(is_run, )).start()
四、基于用户协同过滤算法(UserCF)
1、简介
就是把和你相似的用户喜欢的东西推荐给你。
协同过滤:利用用户的群体行为来计算用户的相关性。
计算用户相关性的时候就是通过对比他们对相同物品喜欢的相关度来计算的。
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 1 | 1 | 1 | 0 |
--------+--------+--------+--------+--------+
b | 1 | 0 | 1 | 0 |
--------+--------+--------+--------+--------+
c | 1 | 1 | 0 | 1 |
--------+--------+--------+--------+--------+
a用户选修了:X、Y、Z
b用户选修了:X、Z
c用户选修了:X、Y、R
那么很容易看到a用户和b、c用户非常相似,给a用户推荐课程R,
给b用户推荐课程Y
给c用户推荐课程Z
这就是基于用户的协同过滤。
a用户向量为(1,1,1,0)
b用户向量为(1,0,1,0)
c用户向量为(1,1,0,1)
2、多维向量夹角公式
很直观的,如果两个用户选择一样,那他们的向量夹角为0,如果两个用户选择都不一样,那向量夹角为180,就是相反的方向。
欧氏空间中定义了标准内积,就是对应分量相乘之和。
2,3,n维空间中内积定义都一样。
向量a,b夹角的余弦为:cos=(ab的内积)/(|a||b|)
即:a,b的内积除以它们的模的乘积等于二者夹角余弦。
代码:
import numpy as np
def calc_vector_cos(a, b):
'''
cos=(ab的内积)/(|a||b|)
:param a: 向量a
:param b: 向量b
:return: 夹角值
'''
a_n = np.array(a)
b_n = np.array(b)
if any(b_n) == 0:
return 0
cos_ab = a_n.dot(b_n) / (np.linalg.norm(a_n) * np.linalg.norm(b_n))
return round(cos_ab, 2)
if __name__ == "__main__":
# 二维
a = (1, -1)
b = (1, 2)
print('二维', calc_vector_cos(a, b))
# 三维
a = (1, 1, 1)
b = (1, 1, 0)
print('三维', calc_vector_cos(a, b))
# 多维
a = (1, 1, 1, 1)
b = (1, 1, 0, 0)
print('多维', calc_vector_cos(a, b))
输出:
二维 -0.32
三维 0.82
多维 0.71
4、python代码示例
点我查看
五、基于物品协同过滤算法(ItemCF)
1、算法核心
通过分析用户行为记录(评分、购买、点击、浏览等行为)来计算两个物品的相似度,同时喜欢物品A和物品B的用户数越多,就认为物品A和物品B越相似。
2、流程
1.构建⽤户–>物品的对应表
2.构建物品与物品的关系矩阵(同现矩阵)
3.通过求余弦向量夹角计算物品之间的相似度,即计算相似矩阵
4.根据⽤户的历史记录,给⽤户推荐物品
3、构建用户与物品的对应关系表
如下表,⾏表⽰⽤户,列表⽰物品(电影),数字表⽰⽤户喜欢该物品的程度(评分)
| 用户\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
|---|---|---|---|---|---|---|
| A | 5 | 1 | 2 | |||
| B | 4 | 2 | 3.5 | |||
| C | 2 | 4 | ||||
| D | 4 | 3 | ||||
| E | 4 | 3 |
4、构建物品与物品的关系矩阵(共现矩阵)
共现矩阵C表⽰同时喜欢两个物品的⽤户数,是根据⽤户物品对应关系表计算出来的。
如根据上⾯的⽤户物品关系表可以计算出如下的共现矩阵C:
| 电影\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
|---|---|---|---|---|---|---|
| 唐伯虎点秋香 | 1 | 1 | 1 | 1 | ||
| 逃学威龙1 | 1 | 1 | 2 | |||
| 追龙 | 1 | 1 | ||||
| 他人笑我太疯癫 | 2 | |||||
| 喜欢你 | 1 | 2 | ||||
| 暗战 | 1 | 2 |
5、计算相似矩阵
两个物品之间的相似度如何计算?
设|N(i)|表⽰喜欢物品i的⽤户数,|N(i)⋂N(j)|表⽰同时喜欢物品i,j的⽤户数,则物品i与物品j的相似度为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h6us6Efc-1673174354368)(D:\我的\学习\我的博客\imgs\相似矩阵.png)]
利用公式计算物品之间的余弦相似矩阵如下:
| 电影\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
|---|---|---|---|---|---|---|
| 唐伯虎点秋香 | 0.41 | 0.7 | 0.5 | 0.5 | ||
| 逃学威龙1 | 0.41 | 0.58 | 0.82 | |||
| 追龙 | 0.71 | 0.58 | ||||
| 他人笑我太疯癫 | 0.82 | |||||
| 喜欢你 | 0.5 | 1.0 | ||||
| 暗战 | 0.5 | 1.0 |
6、给用户推荐物品
根据⽤户的历史记录,给⽤户推荐物品。
最终推荐的是什么物品,是由预测兴趣度决定的。
物品j预测兴趣度=⽤户喜欢的物品i的兴趣度×物品i和物品j的相似度
例如:A⽤户喜欢唐伯虎点秋香,逃学威龙1,追龙 ,兴趣度分别为5,1,2
在用户A的评分电影列表中只有唐伯虎点秋香与喜欢你有相似度,推荐喜欢你的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有唐伯虎点秋香与暗战有相似度,推荐暗战的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有逃学威龙1与他人笑我太疯癫有相似度,推荐他人笑我太疯癫的预测兴趣度=1 x 0.82 =0.82
7、python代码示例
点我查看
六、混合推荐算法
先获取用户协同过滤推荐列表、物品协同过滤推荐列表,然后根据权重因子w,获取最终推荐列表:
推荐列表 = w*P_cu + (1-w)* p_cf