PRewrite: Prompt Rewriting with Reinforcement Learning
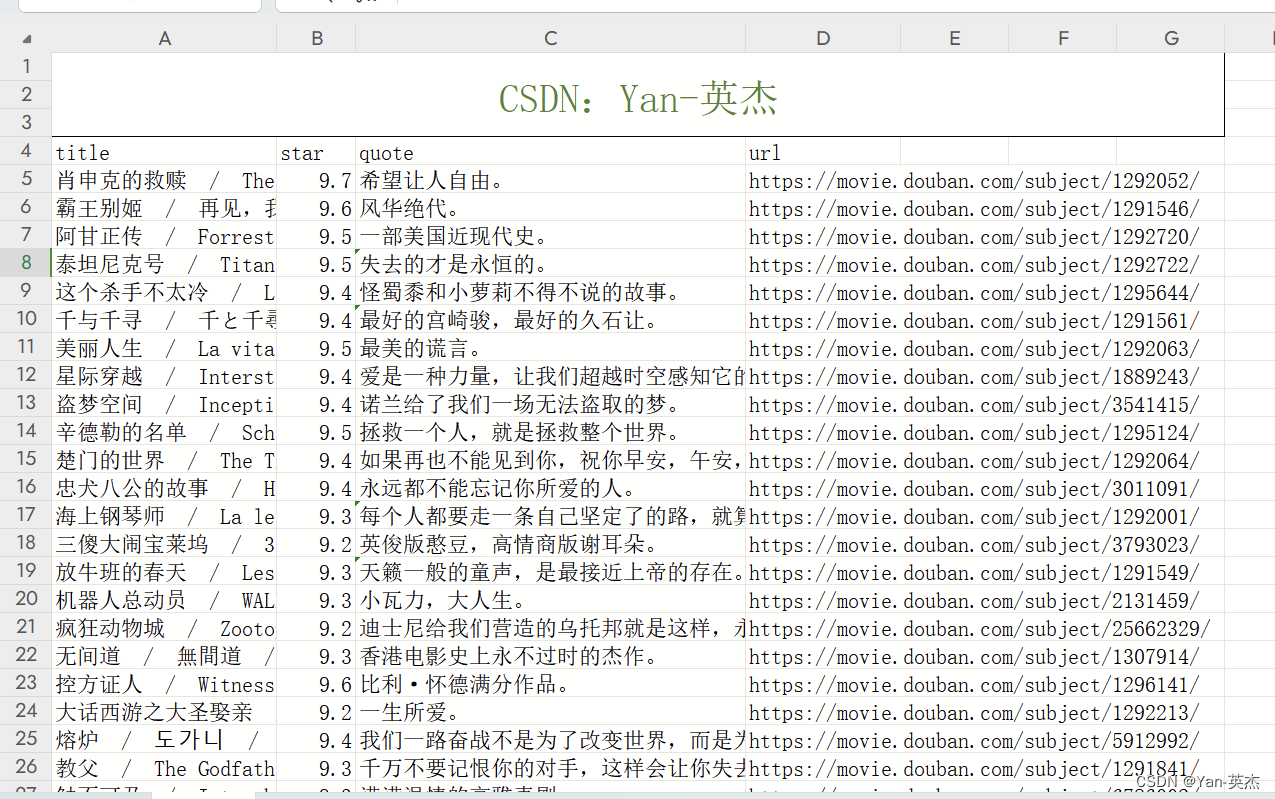
基本信息
2024-01谷歌团队提交到arXiv
博客贡献人
徐宁
作者
Weize Kong,Spurthi Amba Hombaiah,Mingyang Zhang
摘要
工程化的启发式编写对于LLM(大型语言模型)应用的发展至关重要。然而,通常这种编写是以“试错”的方式手动进行的,这可能耗时、低效且不够优化。即使对于表现良好的提示,也总会有一个悬而未决的问题:是否可以通过进一步修改使提示更好?
为了解决这些问题,我们在本文中研究了自动化的启发式编写。具体而言,我们提出了PRewrite,一种自动化方法,用于将未优化的提示重写为更有效的提示。我们使用LLM实例化提示重写器。重写器LLM经过强化学习训练,以优化给定下游任务的性能。我们在多样化的基准数据集上进行实验,证明了PRewrite的有效性
目前研究存在问题:
- 手工编辑prompt
- 该方法是基于试错的,且要编写较好的prompt还受限于对应的指导原则。
- 自动化设置prompt
- 有基于梯度的搜索方法来迭代编辑prompt,但对语言模型进行梯度访问代价过大。
- 使用强化学习的方法来优化prompt,该方法可能会产生难以解释的胡言乱语的解释;同时这种方法虽然可以允许根据任务输入编辑prompt,但导致其较小的行动空间也会阻碍探索最优prompt的产生。
- 之前的方法采用的语言模型都较小,例如BERT,并不清楚在只通过API访问模型的情况下,上述方法能否有效推广到更大规模的模型上。
本文研究思路:
- 将prompt的自动化生成视作一个优化问题,通过强化学习的方式训练一个prompt重写器来寻找更有效的提示。
- 人工给定初始的instruction生成prompt
- 通过prompt重写器LLM来重写生成一个prompt
- 重写的prompt通过另一个任务LLM生成最终的输出
- 通过最终输出和真实输出进行比较计算奖励,以此对重写器LLM进行强化学习微调
- 值得注意的是,重写的提示是与特定输入(input)无关的(agnostic)。即所重写的提示是通用的,不是为了响应或适应特定的输入而定制的(泛化性)。
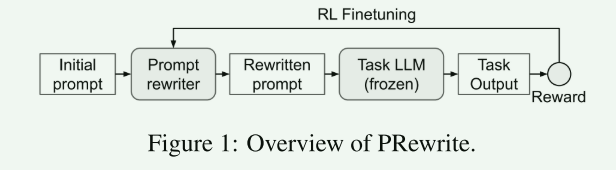
研究方法:
prompts:


-
Meta Prompt
- 元提示是用于指导重写器LLM重写初始prompt的重写指令
- 整个训练过程中,元提示不会改变
- 但在训练模型时以及针对不同的数据集会尝试不同的元提示
-
Instruction
- 上图中的Prompt即由Instruction和Input构成,其中Instruction是由重写器LLM从初始提示生成的最终重写提示。
强化学习
-
强化学习算法:近端策略优化算法(PPO)
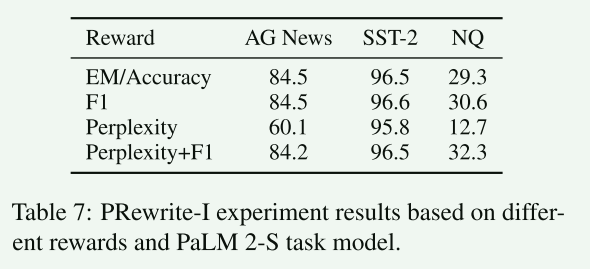
使用不同的奖励函数在数据集上的效果 -
奖励函数
- EM(精确匹配)
- F1:实际输出与预测输出之间的令牌 F1 分数
- 困惑度(Perplexity)
- 困惑度 + F1:困惑度和 F1 分数的线性组合
重写策略
- 在重写器LLM训练好之后,对instruction重新进行优化组合时,可采取两种策略
- 设置了一个行动空间,作为提示重写模型词汇表中所有token的集合,这些token可以用来通过添加、删除或修改来编辑/重写提示。
- 推断策略:在生成重写提示时,贪婪的选择每一个最高概率的标记,最终生成一个单一的重写提示,存在局部最优的问题。
- 搜索策略:在生成重写提示时会考虑多种可能性,生成多个重写提示,最终根据重写提示在测试数据集上的表现来选定最终的重写提示。
实验结果:
数据集
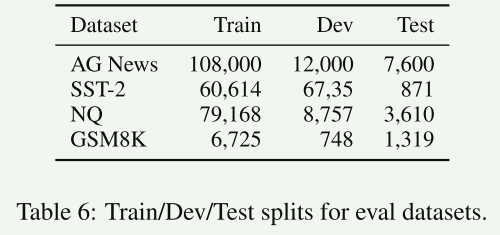
- 本文一共使用了4个数据集涵盖了分类,问答,算术推理任务。
- 分类:AG News、SST-2
- 问答:NQ(自然问题数据集)
- 算数推理:GSM8K
实验结果
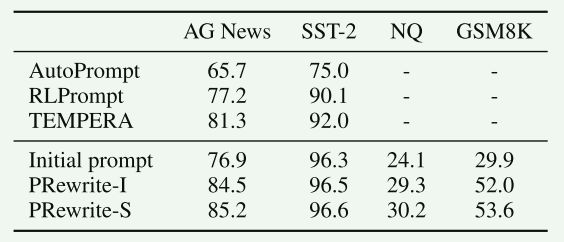
- 本文方法所使用的模型为:PaLM 2-S。
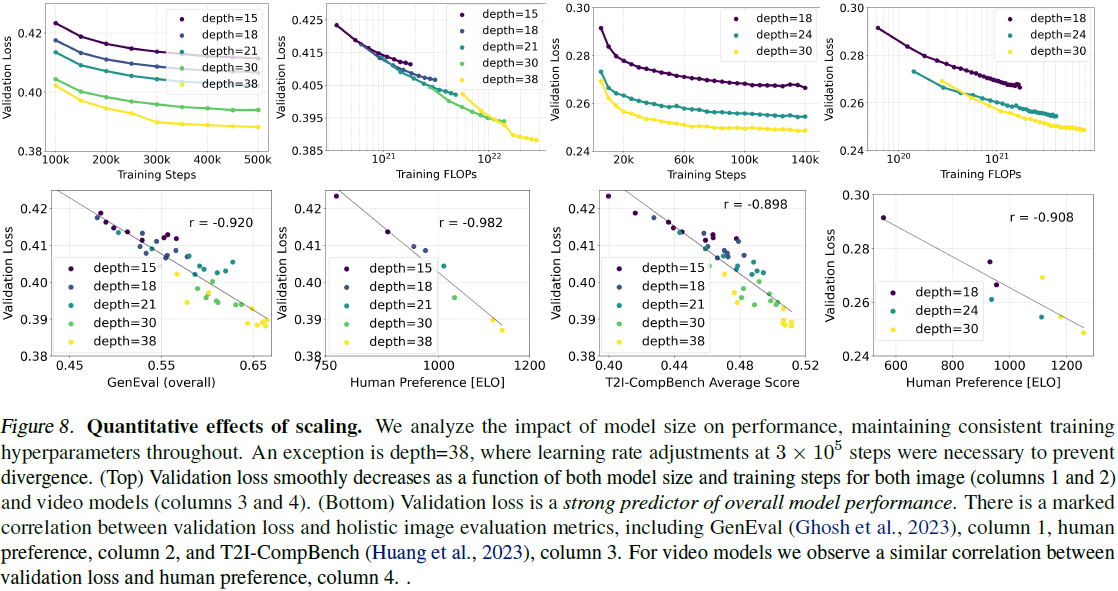
- 由上表可看出,但强化学习有更大的行动空间之后,强化学习方法的改进效果更加显著。
- 本文提出的方法在三个任务四个数据集上的效果普遍优于基线模型,但基线模型效果不佳也存在是使用了较小的任务模型RoBERTa-Large导致的。
- PRewrite-S持续显示出优于PRewrite-I的改进,表明搜索策略可能更有帮助。

- 此次实验基于模型PaLM 2-L。
- PRewrite-S不仅显著改进了初始提示,而且超过了诸如APE和OPRO之类的强基线,并且与Promptbreeder不相上下。
- 这几个强基线任务对GSM8K数据有特殊处理,但本文方法只是用了一个通用的元提示用于GSM8K。也可以体现出本方法有效性。
相关知识链接
下载
论文下载
总结
局限
- 大模型使用的局限性: 本文只是用了PaLM系列的大模型,并未在其他大模型上验证其效果。
- 元提示: 还可以探究不同的元提示和初始提示的组合对整体任务性能的影响。
- **数据集:**目前测试使用的数据集较少,需要在更多不同种类和数量的数据集上持续验证其性能。
优点
- 本文所使用的方法不再需要开源大模型,仅通过大模型API的方式进行使用,降低了对资源的要求
- 利用大模型和传统机器学习结合的方式优化prompt是可以尝试的方向。
BibTex
@article{kong2024prewrite,
title={PRewrite: Prompt Rewriting with Reinforcement Learning},
author={Kong, Weize and Hombaiah, Spurthi Amba and Zhang, Mingyang and Mei, Qiaozhu and Bendersky, Michael},
journal={arXiv preprint arXiv:2401.08189},
year={2024}
}