Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
2. 流的无模拟训练
3. 流轨迹
3.1. RF 模型的定制 SNR 采样器
4. 文本到图像的体系结构
5. 实验
0. 摘要
扩散模型通过反转数据的正向路径,从噪音中创建数据,已经成为处理高维、感知数据(如图像和视频)的强大生成建模技术。整流流(Rectified flow)是一种最近提出的生成模型形式,它将数据和噪音连接成一条直线。尽管它具有更好的理论性质和概念上的简单性,但它尚未被明确确立为标准实践。在这项工作中,我们改进了现有的噪音采样技术,用于训练整流流模型,使其偏向感知上相关的尺度。通过大规模研究,我们展示了这种方法相较于已建立的扩散公式在高分辨率文本到图像合成方面的卓越性能。此外,我们提出了一种基于 transformer 的文本到图像生成体系结构,该体系结构为两种模态使用独立权重,并实现了图像和文本 token 之间的双向信息流,改善了文本理解、排版和人类偏好评分。我们证明了这种体系结构遵循可预测的缩放趋势,并将较低的验证损失与通过各种指标和人类评估测得的改进的文本到图像合成相关联。我们的最大模型胜过当前最先进的模型,我们将公开我们的实验数据、代码和模型权重。

2. 流的无模拟训练
(2023,InstaFlow & 整流流 & 回流 & 蒸馏)InstaFlow:一步就足以实现基于扩散的高质量文本到图像生成
我们考虑生成模型,其定义了从噪声分布 p1 中的样本 x1 到数据分布 p0 中的样本 x0 之间的映射,采用常微分方程(ordinary differential equation,ODE)表示为:
![]()
其中速度(velocity) v 由神经网络的权重 Θ 参数化。Chen 等人(2018)的先前工作建议通过可微 ODE 求解方程(1)。然而,这个过程在计算上是昂贵的,特别是对于参数化 vΘ(yt,t) 的大型网络架构。一个更高效的替代方案是直接回归生成概率路径 p0 和 p1 之间的矢量场 u_t。为构建这样的 u_t,我们定义一个前向过程,对应于 p0 到 p1=N(0,1) 之间的概率路径 pt,如下:
![]()
对于 a0=1, b0=0, 以及 a1=0, b1=1,边缘分布
![]()
与数据和噪声分布一致。
为了表达 zt, x0 和 ϵ 之间的关系,我们引入 ψt 和 ut,如下所示:


流匹配(Flow Matching)目标
![]()
条件流匹配(Conditional Flow Matching,CFM)
![]()
噪声预测目标(推导见原论文)

![]()
请注意,上述目标的最优解在引入时间依赖权重时不会改变。因此,可以导出各种加权损失函数,提供朝着期望解决方案的信号,但可能会影响优化轨迹。为了对不同方法进行统一分析,包括经典的扩散公式,我们可以将目标写成以下形式(参考 Kingma & Gao(2023)):

![]()
其中 w_t 对应于 L_CFM。
3. 流轨迹
在这项工作中,我们考虑上述形式主义的不同变体,我们将在以下简要描述。
整流流(Rectified Flow,RF)。整流流(Liu等人,2022;Albergo & Vanden-Eijnden,2022;Lipman等人,2023)将前向过程定义为数据分布和标准正态分布之间的直线路径,即
![]()
并使用 L_CFM,其中
![]()
网络输出直接参数化速度 vΘ。
EDM。
Cosine。
(LDM-)Linear。
3.1. RF 模型的定制 SNR 采样器
RF 损失在 [0, 1] 的所有时间步上均匀训练速度 vΘ。然而,直观地说,由于对于 [0, 1] 中间的 t 来说,速度预测目标 ϵ−x0 更为困难,因为对于 t = 0,最优预测是 p1 的均值,而对于 t = 1,最优预测是 p0 的均值。一般来说,将 t 上的分布从通常使用的均匀分布 U(t) 更改为密度 π(t) 的分布等效于加权损失
![]()
![]()
因此,我们的目标是通过更频繁地对中间时间步进行采样,给予它们更多的权重。接下来,我们描述用于训练模型的时间步密度 π(t)。
Logit-Normal Sampling。
Mode Sampling with Heavy Tails。
CosMap。
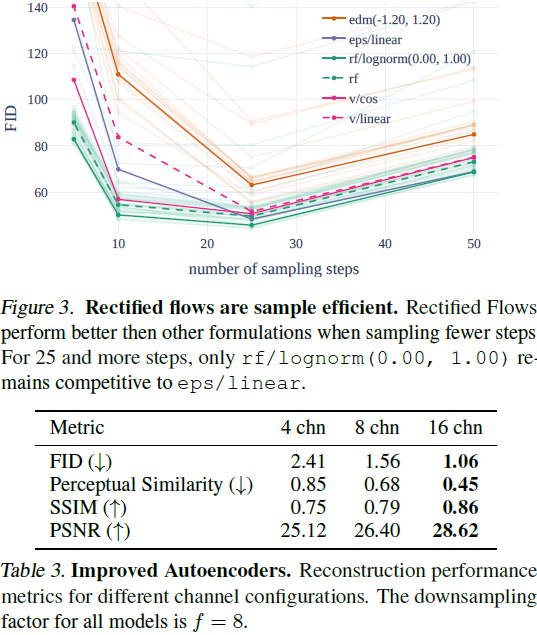
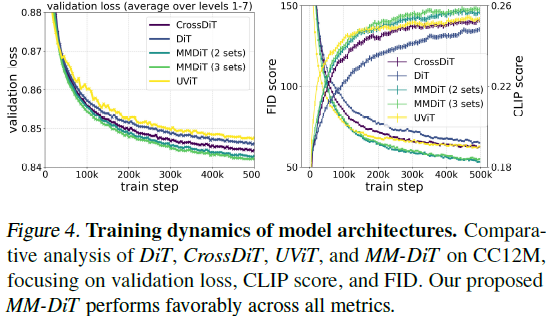
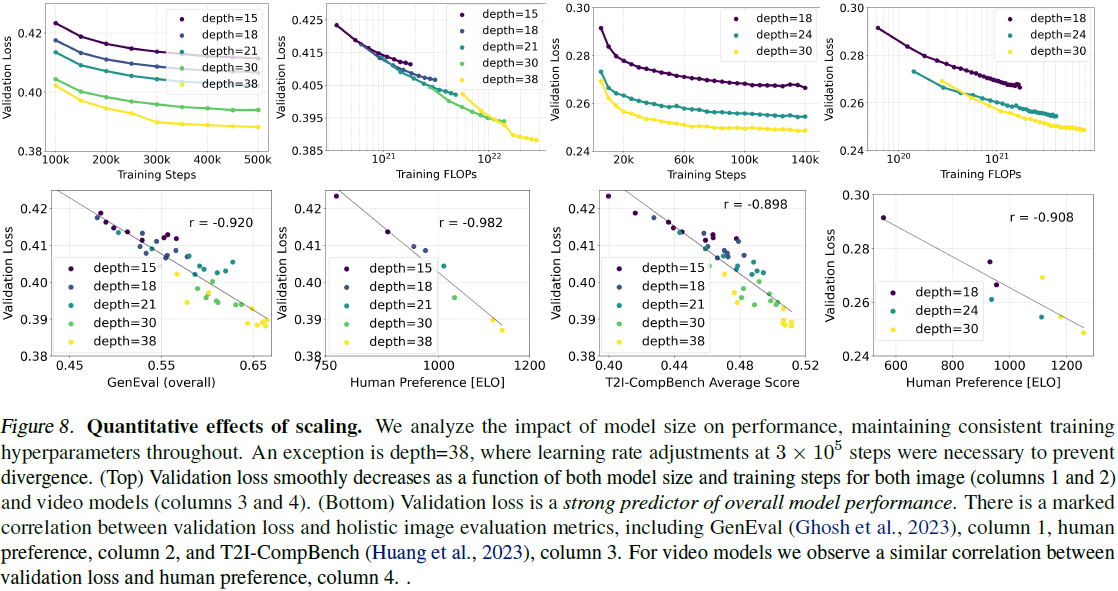
(略,详见原论文)

4. 文本到图像的体系结构
对于图像的文本条件采样,我们的模型必须考虑文本和图像两种模态。我们使用预训练模型来获取适当的表示,然后描述我们扩散骨干的体系结构。此概述见图 2。
我们的一般设置遵循 LDM(Rombach等人,2022),用于在预训练自编码器的潜在空间中训练文本到图像模型。与将图像编码为潜在表示类似,我们还遵循以前的方法(Saharia等人,2022b;Balaji等人,2022),使用预训练、冻结的文本模型对文本条件 c 进行编码。详细信息可见附录 B.2。
多模态扩散骨干。我们的体系结构基于 DiT(Peebles & Xie,2023)架构。DiT 只考虑类别条件的图像生成,并使用调制机制以扩散过程的时间步和类别标签作为条件。类似地,我们使用时间步 t 和 c_vec 的嵌入作为输入传递给调制机制。然而,由于汇总的文本表示仅保留关于文本输入的粗粒度信息(Podell等人,2023),网络还需要来自序列表示 c_ctxt 的信息。
我们构建一个包含文本和图像输入嵌入的序列。具体来说,我们添加位置编码,并将潜在像素表示 x ∈ R^(h×w×c) 的 2 × 2 补丁平铺为长度为 1/2 · h · 1/2 · w 的补丁编码序列。在嵌入此补丁编码和文本编码 c_ctxt 到一个共同的维度后,我们连接这两个序列。然后,我们遵循 DiT,并应用一系列调制注意力和 MLP。
由于文本和图像嵌入在概念上相当不同,我们使用两个独立的权重集用于两种模态。如图 2b 所示,这相当于每种模态都有两个独立的 transformer ,但在注意力操作中连接两种模态的序列,以便两种表示可以在各自的空间中工作,但也考虑到对方。
对于我们的扩展实验,我们通过将 hidden 大小设置为 64 · d(在 MLP 块中扩展为 4 · 64 · d 通道)以及注意力头的数量等于 d,通过将模型的大小参数化为模型深度 d,即注意力块的数量。
5. 实验