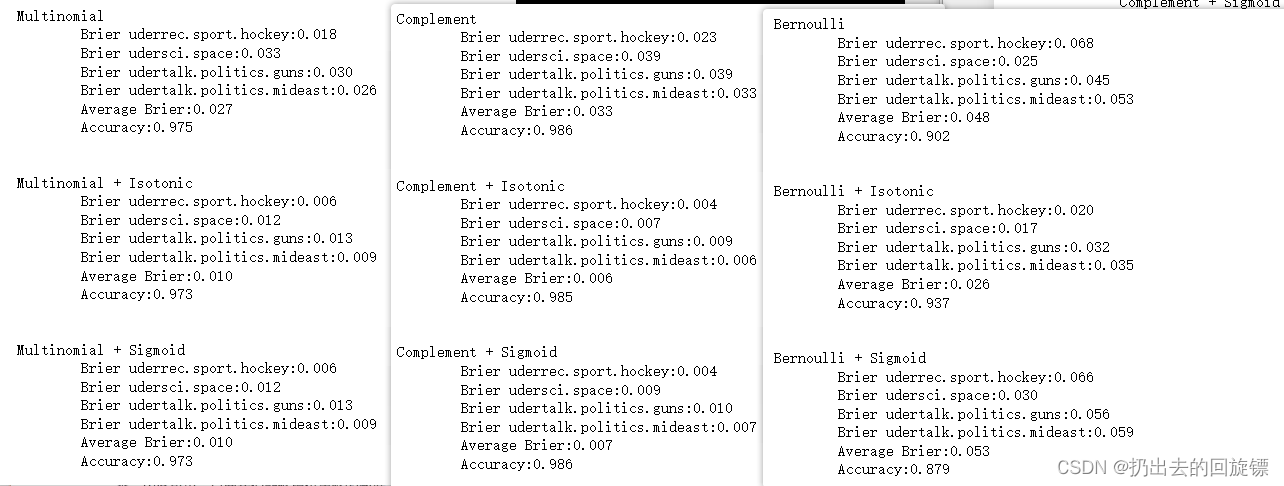
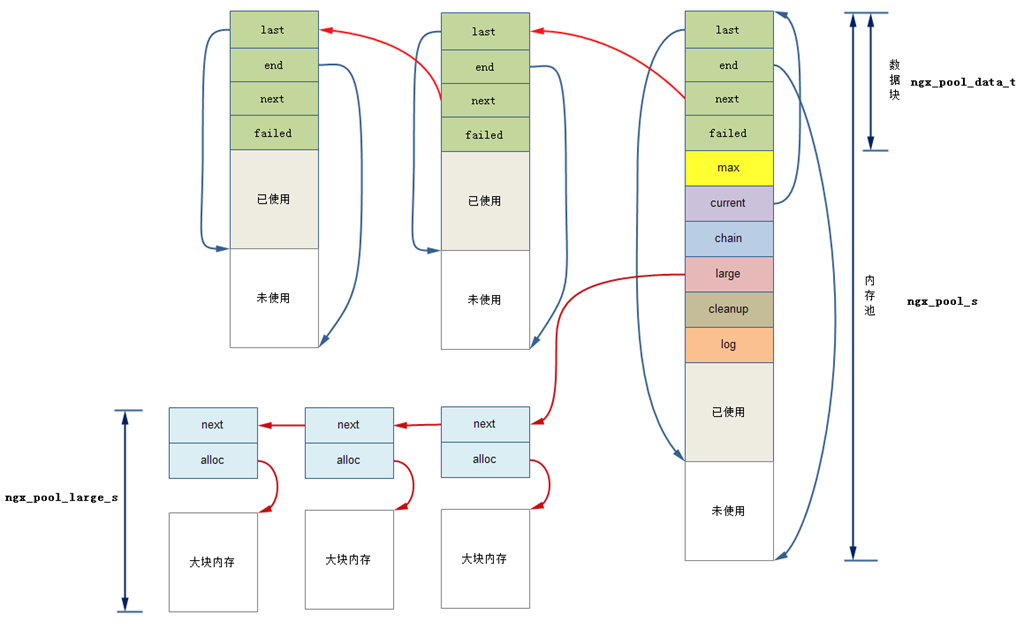
一、人脸关键点检测数据集
在计算机视觉人脸计算领域,人脸关键点检测是一个十分重要的区域,可以实现例如一些人脸矫正、表情分析、姿态分析、人脸识别、人脸美颜等方向。
人脸关键点数据集通常有 5点、15点、68点、96点、98点、106点、186点 等,例如通用 Dlib 中的 68 点检测,它将人脸关键点分为脸部关键点和轮廓关键点,脸部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。

本文基于 kaggle 的 Facial Keypoints Detection 中的数据集进行实践,该数据集包含包括7,049幅训练图像,图像是 96 x 96像素的灰度图像,其中关键点有 15个点,注意数据集有的字段缺失,如果去除字段缺失的数据,实际训练数据只有 2,140 幅训练图像,还包括1,783张测试图片,数据集的效果如下所示:

可以看出,关键点包括眉毛的两端、眼睛的中心和两端、鼻子尖、嘴巴两端和上下嘴唇的中间。
下载数据集
数据集在 kaggle 的官方网址上:
https://www.kaggle.com/c/facial-keypoints-detection
下载前需要进行登录,如果没有 kaggle 账号可以注册一个。
下载解压后,可以看到 training.zip 和 test.zip 两个文件,分别对应训练集和测试集,解压后数据是以 CSV 的格式进行存放的:
其中 training.csv 中的字段分别表示:
| 序号 | 字段 | 含义 |
|---|---|---|
| 0 | left_eye_center_x | 左眼中心 x 点 |
| 1 | left_eye_center_y | 左眼中心 y 点 |
| 2 | right_eye_center_x | 右眼中心 x 点 |
| 3 | right_eye_center_y | 右眼中心 y 点 |
| 4 | left_eye_inner_corner_x | 左眼内端 x 点 |
| 5 | left_eye_inner_corner_y | 左眼内端 y 点 |
| 6 | left_eye_outer_corner_x | 左眼外端 x 点 |
| 7 | left_eye_outer_corner_y | 左眼外端 y 点 |
| 8 | right_eye_inner_corner_x | 右眼内端 x 点 |
| 9 | right_eye_inner_corner_y | 右眼内端 y 点 |
| 10 | right_eye_outer_corner_x | 右眼外端 x 点 |
| 11 | right_eye_outer_corner_y | 右眼外端 y 点 |
| 12 | left_eyebrow_inner_end_x | 左眉毛内端 x 点 |
| 13 | left_eyebrow_inner_end_y | 左眉毛内端 y 点 |
| 14 | left_eyebrow_outer_end_x | 左眉毛外端 x 点 |
| 15 | left_eyebrow_outer_end_y | 左眉毛外端 y 点 |
| 16 | right_eyebrow_inner_end_x | 右眉毛内端 x 点 |
| 17 | right_eyebrow_inner_end_y | 右眉毛内端 y 点 |
| 18 | right_eyebrow_outer_end_x | 右眉毛外端 x 点 |
| 19 | right_eyebrow_outer_end_y | 右眉毛外端 y 点 |
| 20 | nose_tip_x | 鼻尖中心 x 点 |
| 21 | nose_tip_y | 鼻尖中心 y 点 |
| 22 | mouth_left_corner_x | 嘴巴左端 x 点 |
| 23 | mouth_left_corner_y | 嘴巴左端 y 点 |
| 24 | mouth_right_corner_x | 嘴巴右端 x 点 |
| 25 | mouth_right_corner_y | 嘴巴右端 y 点 |
| 26 | mouth_center_top_lip_x | 上嘴唇中心 x 点 |
| 27 | mouth_center_top_lip_y | 上嘴唇中心 y 点 |
| 28 | mouth_center_bottom_lip_x | 下嘴唇中心 x 点 |
| 29 | mouth_center_bottom_lip_y | 下嘴唇中心 y 点 |
| 30 | Image | 图形像素 |
由于数据是存放在CSV中,可以借助 pandas 工具对数据进行解析,如果没有安装 pandas 工具,可以通过下面指令安装:
pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
下面程序通过 pandas 解析 CSV 文件,并将图片转为 numpy 数组,通过 matplotlib 可视化工具查看,其中具体的解释都写在了注释中:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def main():
csv_path = './data/training.csv'
# 读取 CSV 文件
train_df = pd.read_csv(csv_path)
# 查看数据框,并列出数据集的头部。
train_df.info()
# 丢弃有缺失数据的样本
train_df = train_df.dropna()
# 获取图片信息,并转为 numpy 结构
x_train = train_df['Image'].apply(lambda img: np.fromstring(img, sep=' '))
x_train = np.vstack(x_train)
# 重新修改形状
x_train = x_train.reshape((-1, 96, 96, 1))
# 去除最后一列的 Image
cols = train_df.columns[:-1]
y_train = train_df[cols].values
print('训练集 shape: ', x_train.shape)
print('训练集label shape: ', y_train.shape)
plt.figure(figsize=(10, 10))
for p in range(2):
data = x_train[(p * 9):(p * 9 + 9)]
label = y_train[(p * 9):(p * 9 + 9)]
plt.clf()
for i in range(9):
plt.subplot(3, 3, i + 1)
img = data[i].reshape(96, 96, 1)
plt.imshow(img, cmap='gray')
# 画关键点
l = label[i]
# 从 1 开始,每次走 2 步,j-1,j 就是当前点的坐标
for j in range(1, 31, 2):
plt.plot(l[j - 1], l[j], 'ro', markersize=4)
plt.show()
if __name__ == '__main__':
main()
运行之后,可以看到如下效果图:

下面我们基于该数据集进行建模,训练一个自己的关键点检测模型。
二、构建模型
1. 数据集预处理
1.1 灰度图像转3维度图像
由于自己构建模型,初始值比较随机,loss 收敛起来没那么快,又因为该数据集的训练数据比较少,因此模型这里,我们基于 MobileNetV2 作为基础模型,并使用 ImageNet 上的权重作为初始值,可以让 loss 快速收敛,但 MobileNetV2 是基于 RGB 彩色三通道进行构建的,因此在训练时,需要将灰度图像转为 3 维形式,这里可以借助 PIL 工具的 Image.convert('RGB') 进行实现,转换程序如下所示,这里我分出了 80% 的训练数据,20% 的验证数据
import numpy as np
import pandas as pd
from PIL import Image
def toRgbImg(img):
img = np.fromstring(img, sep=' ').astype(np.uint8).reshape(96, 96)
img = Image.fromarray(img).convert('RGB')
return img
def main():
csv_path = './data/training.csv'
# 读取 CSV 文件
train_df = pd.read_csv(csv_path)
# 查看数据框,并列出数据集的头部。
train_df.info()
# 丢弃有缺失数据的样本
train_df = train_df.dropna()
# 获取图片信息,并转为 numpy 结构
# x_train = train_df['Image'].apply(lambda img: np.fromstring(img, sep=' '))
x_train = train_df['Image'].apply(toRgbImg)
x_train = np.vstack(x_train)
# 重新修改形状
x_train = x_train.reshape((-1, 96, 96, 3))
# 去除最后一列的 Image
cols = train_df.columns[:-1]
y_train = train_df[cols].values
# 使用 80% 的数据训练,20% 的数据进行验证
size = int(x_train.shape[0] * 0.8)
print(size)
x_val = x_train[size:]
y_val = y_train[size:]
x_train = x_train[:size]
y_train = y_train[:size]
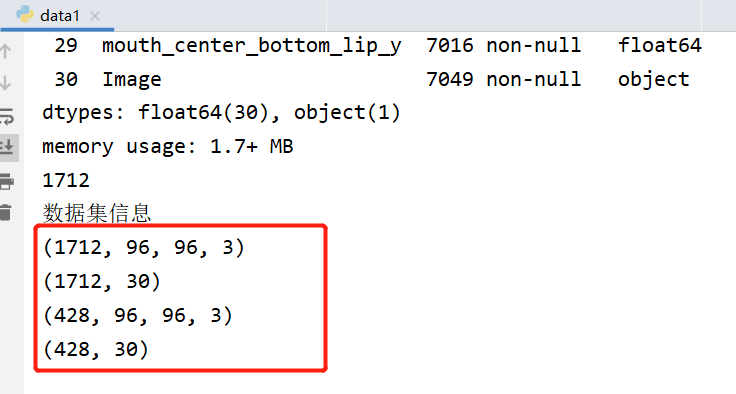
print("数据集信息")
print(x_train.shape)
print(y_train.shape)
print(x_val.shape)
print(y_val.shape)
if __name__ == '__main__':
main()
运行后可以看到如下日志:
1.2 y_train 标签转为比例点
针对于 y_train 标签 ,是表示着图像上真实关键点的坐标,直接让模型回归真实点的话,会出现浮动大的情况,因此这里将真实点转为相对于图像的比例点,也就是直接除于图像的大小,得到一个相对点的位置,相对点的位置都在 0 - 1 区间:
# 去除最后一列的 Image, 将y值缩放到[0,1]区间
cols = train_df.columns[:-1]
y_train = train_df[cols].values / 96.0
1.3 数据集打乱
在喂入数据前还需要对数据进行打乱,使每次都随机数据喂入模型,在 Tensorflow 中 tf.data 都已经帮我们完成了这些逻辑:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
随机打乱,并根据 batch 分批:
SHUFFLE_BUFFER_SIZE = 100
train_dataset = train_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(batch_size=batch_size)
val_dataset = val_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(batch_size=batch_size)
最后,完整的数据处理方法如下:
def toRgbImg(img):
img = np.fromstring(img, sep=' ').astype(np.uint8).reshape(96, 96)
img = Image.fromarray(img).convert('RGB')
return img
# 处理数据集
def getData(csv_path, img_width, img_height, dim, batch_size):
train_df = pd.read_csv(csv_path)
# 丢弃有缺失数据的样本
train_df = train_df.dropna()
# 获取图片信息,并转为 numpy 结构
x_train = train_df['Image'].apply(toRgbImg)
x_train = np.vstack(x_train)
# 重新修改形状
x_train = x_train.reshape((-1, img_width, img_height, dim))
# 去除最后一列的 Image, 将y值缩放到[0,1]区间
cols = train_df.columns[:-1]
y_train = train_df[cols].values / 96.0
# 使用 80% 的数据训练,20% 的数据进行验证
size = int(x_train.shape[0] * 0.8)
x_val = x_train[size:]
y_val = y_train[size:]
x_train = x_train[:size]
y_train = y_train[:size]
# 加载为数据集
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
SHUFFLE_BUFFER_SIZE = 100
train_dataset = train_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(batch_size=batch_size)
val_dataset = val_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(batch_size=batch_size)
return train_dataset, val_dataset
1.4 数据增强
上面提到实际训练的数据集并不多,因此有必要通过数据增强扩充数据,数据增强这里就做一个随机对比度的改变,这样不会影响关键点的位置,增强部分放在模型的Sequential中,这样在训练时有增强的效果,在预测或评估时增强又会被禁用:
# 数据增强
data_augmentation = tf.keras.Sequential([
# 随机对比度改变
keras.layers.RandomContrast(0.3)
])
2. 构建模型
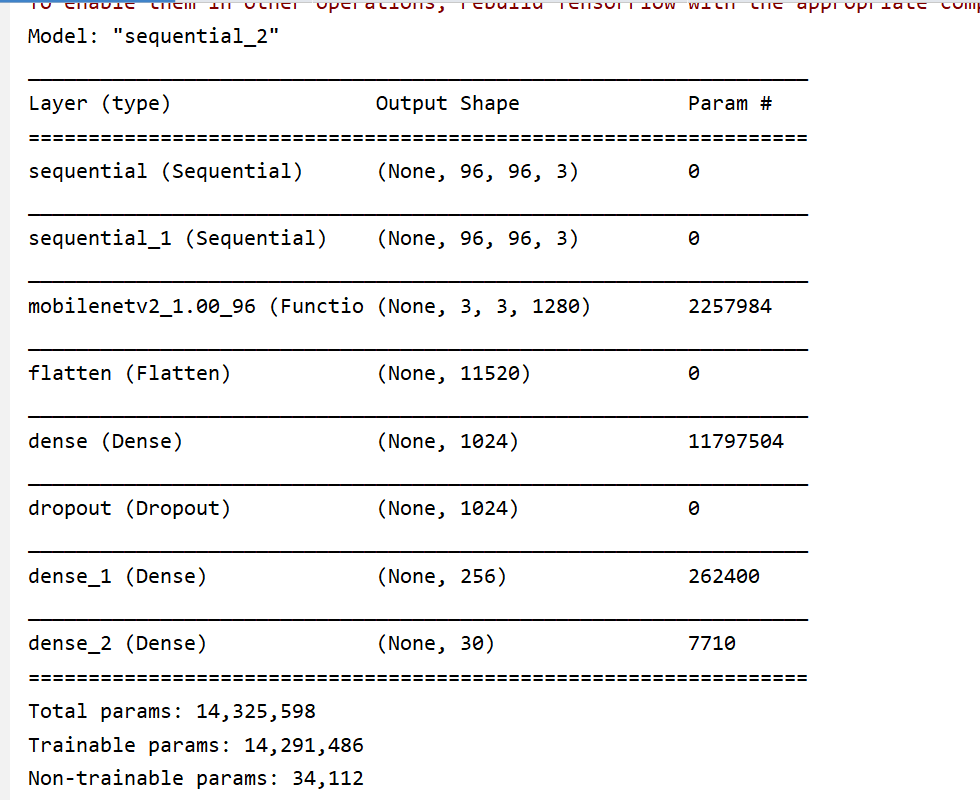
上面提到我们基于 MobileNetV2 作为基础模型,并进行迁移学习,这里需要去除 MobileNetV2 的分类器层,最后添加我们自己的全链接层,最后给到一个 30 的输出,其输出的顺序就表示训练数据集中去除Image列后剩下的一一对应,就是这 15 个关键点的 x,y 比例数据, loss 函数,使用均方差来计算,整体模型结构如下:

下面使用 keras 构建模型结构:
import tensorflow as tf
import tensorflow.keras as keras
# 定义模型类
class Model():
# 初始化结构
def __init__(self, checkpoint_path, log_path, model_path, img_width, img_height, dim):
# checkpoint 权重保存地址
self.checkpoint_path = checkpoint_path
# 训练日志保存地址
self.log_path = log_path
# 训练模型保存地址:
self.model_path = model_path
# 图片大小信息
self.img_width = img_width
self.img_height = img_height
self.dim = dim
# 数据统一大小并归一处理
resize_and_rescale = tf.keras.Sequential([
keras.layers.Resizing(img_width, img_height),
keras.layers.Rescaling(1. / 255)
])
# 数据增强
data_augmentation = tf.keras.Sequential([
# 对比度
keras.layers.RandomContrast(0.3)
])
# MobileNetV2 模型结构
mobienet = keras.applications.MobileNetV2(weights='imagenet', include_top=False, input_shape=(img_width, img_height, dim))
# 初始化模型结构
self.model = keras.Sequential([
resize_and_rescale,
data_augmentation,
mobienet,
keras.layers.Flatten(),
keras.layers.Dense(1024,
kernel_initializer=keras.initializers.truncated_normal(stddev=0.05),
kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
keras.layers.Dropout(0.1),
keras.layers.Dense(256,
kernel_initializer=keras.initializers.truncated_normal(stddev=0.05),
kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
keras.layers.Dense(30)
])
# 编译模型
def compile(self):
# 输出模型摘要
self.model.build(input_shape=(None, self.img_width, self.img_height, self.dim))
self.model.summary()
# 定义训练模式, loss 使用均方差
self.model.compile(optimizer='adam',
loss='mean_squared_error',
metrics=['mae'])
# 训练模型
def train(self, train_ds, val_ds, epochs):
# tensorboard 训练日志收集
tensorboard = keras.callbacks.TensorBoard(log_dir=self.log_path)
# 训练过程保存 Checkpoint 权重
model_checkpoint = keras.callbacks.ModelCheckpoint(self.checkpoint_path, monitor='val_loss', verbose=0,
save_best_only=True, save_weights_only=True, mode='auto',
period=3)
# 填充数据,迭代训练
self.model.fit(
train_ds, # 训练集
validation_data=val_ds, # 验证集
epochs=epochs, # 迭代周期
verbose=2, # 训练过程的日志信息显示,一个epoch输出一行记录
callbacks=[tensorboard, model_checkpoint]
)
# 保存训练模型
self.model.save(self.model_path)
def evaluate(self, val_ds):
# 评估模型
test_loss, test_acc = self.model.evaluate(val_ds)
return test_loss, test_acc
处理数据集,使用 80% 的图像进行训练,20% 的图像进行验证,并将将数据喂入模型训练:
import numpy as np
import pandas as pd
from PIL import Image
import tensorflow as tf
def toRgbImg(img):
img = np.fromstring(img, sep=' ').astype(np.uint8).reshape(96, 96)
img = Image.fromarray(img).convert('RGB')
return img
# 处理数据集
def getData(csv_path, img_width, img_height, dim, batch_size):
train_df = pd.read_csv(csv_path)
# 丢弃有缺失数据的样本
train_df = train_df.dropna()
# 获取图片信息,并转为 numpy 结构
x_train = train_df['Image'].apply(toRgbImg)
x_train = np.vstack(x_train)
# 重新修改形状
x_train = x_train.reshape((-1, img_width, img_height, dim))
# 去除最后一列的 Image, 将y值缩放到[0,1]区间
cols = train_df.columns[:-1]
y_train = train_df[cols].values / 96.0
# 使用 80% 的数据训练,20% 的数据进行验证
size = int(x_train.shape[0] * 0.8)
x_val = x_train[size:]
y_val = y_train[size:]
x_train = x_train[:size]
y_train = y_train[:size]
# 加载为数据集
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
SHUFFLE_BUFFER_SIZE = 100
train_dataset = train_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(batch_size=batch_size)
val_dataset = val_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(batch_size=batch_size)
return train_dataset, val_dataset
def main():
train_csv_path = './data/training.csv'
img_width = 96
img_height = 96
dim = 3
batch_size = 20
epochs = 100
checkpoint_path = './checkout/'
log_path = './log'
model_path = './model/model_mobie.h5'
# 加载数据集
train_ds, val_ds = getData(train_csv_path, img_width, img_height, dim, batch_size)
# 构建模型
model = Model(checkpoint_path, log_path, model_path, img_width, img_height, dim)
# 编译模型
model.compile()
# 训练模型
model.train(train_ds, val_ds, epochs)
# 评估模型
test_loss, test_acc = model.evaluate(val_ds)
print(test_loss, test_acc)
if __name__ == '__main__':
main()
运行后可以看到打印的网络结构:
从训练日志中,可以看到 loss 一直在减小:

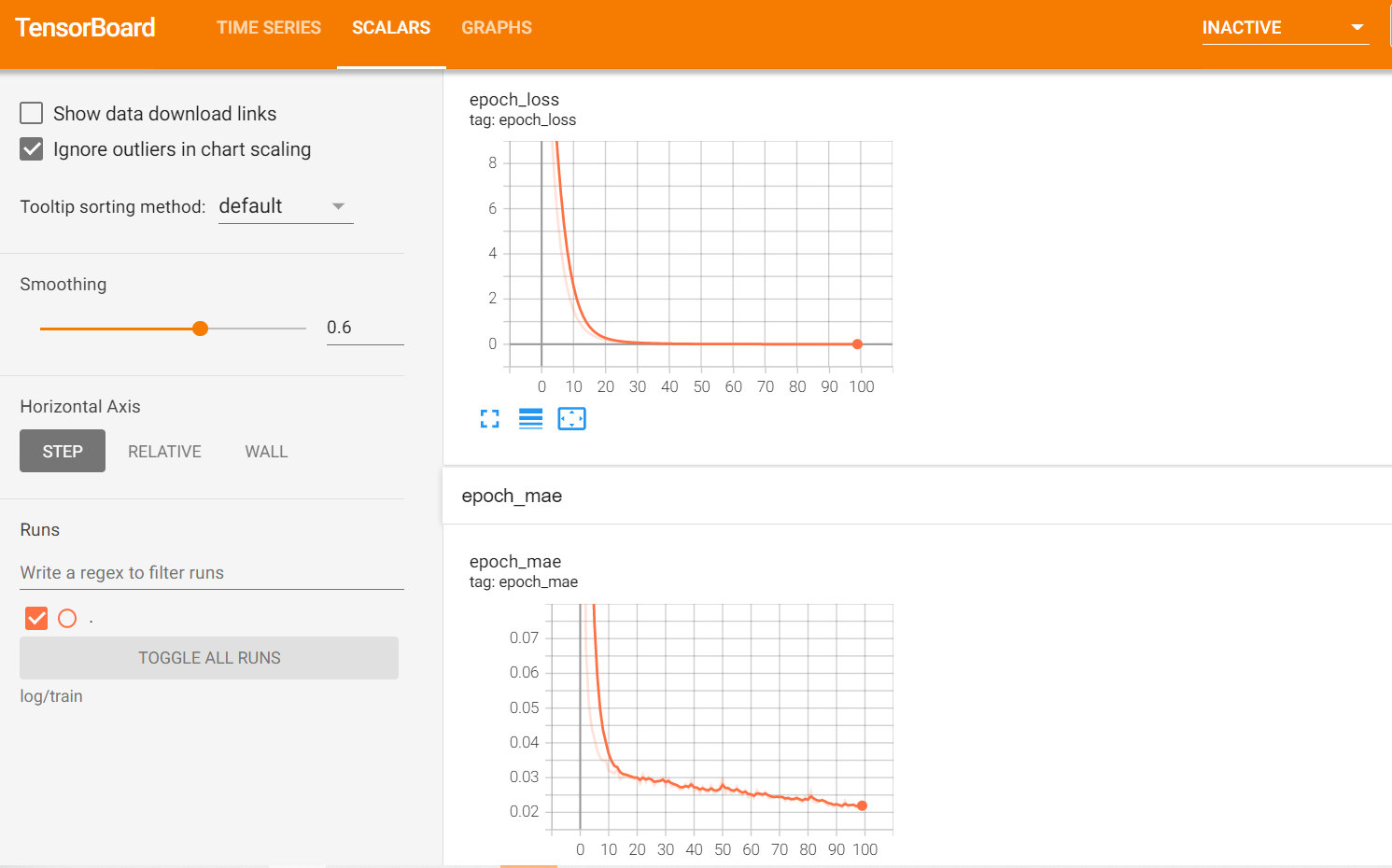
训练结束后可以看到在评估集上的评估结果,最终 loss 降到了 0.00175

结合 tensorboard 中可视化的损失看下迭代的曲线:
tensorboard --logdir=log/train
三、模型预测
训练后会在 model 下生成 model.h5 模型,下面可以直接加载该模型进行预测,这里换成对数据集的 test.csv 进行解析,同样将灰度图转为 3 维后输入到模型:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from PIL import Image
def toRgbImg(img):
img = np.fromstring(img, sep=' ').astype(np.uint8).reshape(96, 96)
img = Image.fromarray(img).convert('RGB')
return img
def main():
csv_path = './data/test.csv'
# 读取 CSV 文件
test_df = pd.read_csv(csv_path)
# 查看数据框,并列出数据集的头部。
test_df.info()
# 获取图片信息,并转为 numpy 结构
test_df = test_df['Image'].apply(toRgbImg)
test_df = np.vstack(test_df)
# 重新修改形状
test_df = test_df.reshape((-1, 96, 96, 3))
# 加载模型
model = keras.models.load_model('./model/model.h5')
plt.figure(figsize=(10, 10))
for p in range(5):
data = test_df[(p * 9):(p * 9 + 9)]
plt.clf()
for i in range(9):
plt.subplot(3, 3, i + 1)
img = data[i].reshape(96, 96, 3)
plt.imshow(img, cmap='gray')
res = model.predict(tf.expand_dims(img, 0))
# 画关键点,从 1 开始,每次走 2 步,j-1,j 就是当前点的坐标
for j in range(1, 31, 2):
plt.plot(res[0][j - 1] * 96, res[0][j] * 96, 'ro', markersize=4)
plt.show()
if __name__ == '__main__':
main()


可以看到对于嘴部位置的关键点有些会出现偏差。
四、结合 MTCNN 测试
MTCNN 是2016年中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,该模型采用了三个级联的网络,还采用候选框加分类器的思想,进行快速高效的人脸检测。可以借助 MTCNN 检测出的人脸,经过裁剪后再交于我们训练的模型进行识别关键点。
首先下载 MTCNN 的依赖:
pip3 install mtcnn -i https://pypi.tuna.tsinghua.edu.cn/simple
使用 MTCNN 检测人脸:
from matplotlib import pyplot as plt
from mtcnn.mtcnn import MTCNN
def main():
# MTCNN 人脸检测器
detector = MTCNN()
# 读取图片
img = plt.imread('./img/1.jpg')
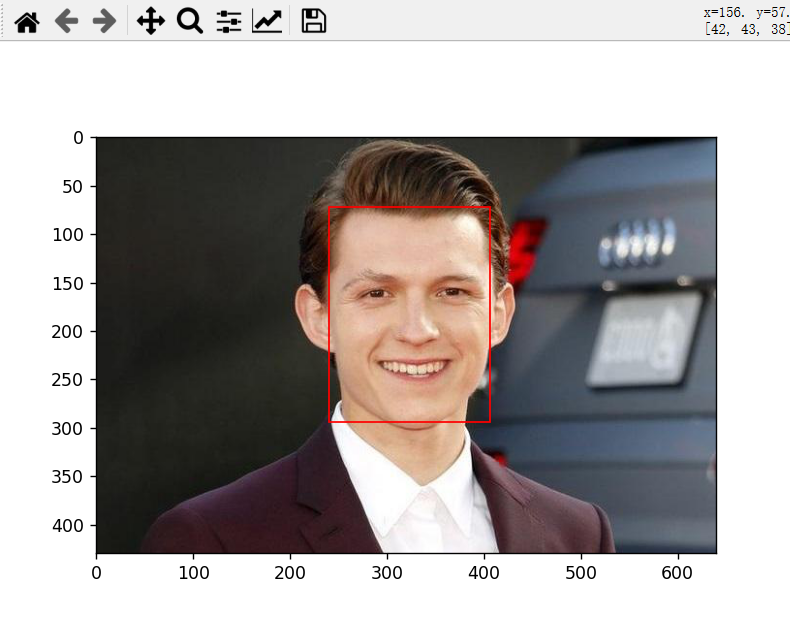
# 检测人脸
faces = detector.detect_faces(img)
if len(faces) > 0:
ax = plt.gca()
for face in faces:
x1, y1, width, height = face['box']
x2, y2 = x1 + width, y1 + height
# 画出人脸矩形框
ax.add_patch(plt.Rectangle((x1, y1), width, height, fill=False, color='red'))
plt.imshow(img)
plt.show()
if __name__ == '__main__':
main()
下面对检测到的人脸裁剪出人脸,交给上面训练的模型预测:
from matplotlib import pyplot as plt
from mtcnn.mtcnn import MTCNN
import tensorflow.keras as keras
import tensorflow as tf
import numpy as np
def main():
# 加载关键点模型
model = keras.models.load_model('./model/model.h5')
# MTCNN 人脸检测器
detector = MTCNN()
# 读取图片
img = plt.imread('./img/1.jpg')
# 检测人脸
faces = detector.detect_faces(img)
if len(faces) > 0:
ax = plt.gca()
for face in faces:
x1, y1, width, height = face['box']
x2, y2 = x1 + width, y1 + height
# 画出人脸矩形框
ax.add_patch(plt.Rectangle((x1, y1), width, height, fill=False, color='red'))
# 裁剪人脸图像
crop = img[y1:y2, x1:x2]
# 预测关键点的偏移量
res = model.predict(tf.expand_dims(crop, 0))
# 画出关键点
# 关键点在原图的真实位置 = 偏移量*人脸图像的大小 + 人脸图像在原图的位置
shape = crop.shape
for j in range(1, 31, 2):
plt.plot(res[0][j - 1] * shape[1] + x1, res[0][j] * shape[0] + y1, 'ro', markersize=3)
plt.imshow(img)
plt.show()
if __name__ == '__main__':
main()

可以看到对于真实图片模型还是有些偏差,一方面模型方面没有做过多的策略,另一方面数据集不多,且都是灰度图,对于真实的 RGB 彩色图,势必会有一定的偏差。