scrapy框架的基本使用,请参考我的另一篇文章:scrapy框架的基本使用
起始爬取的网页如下:
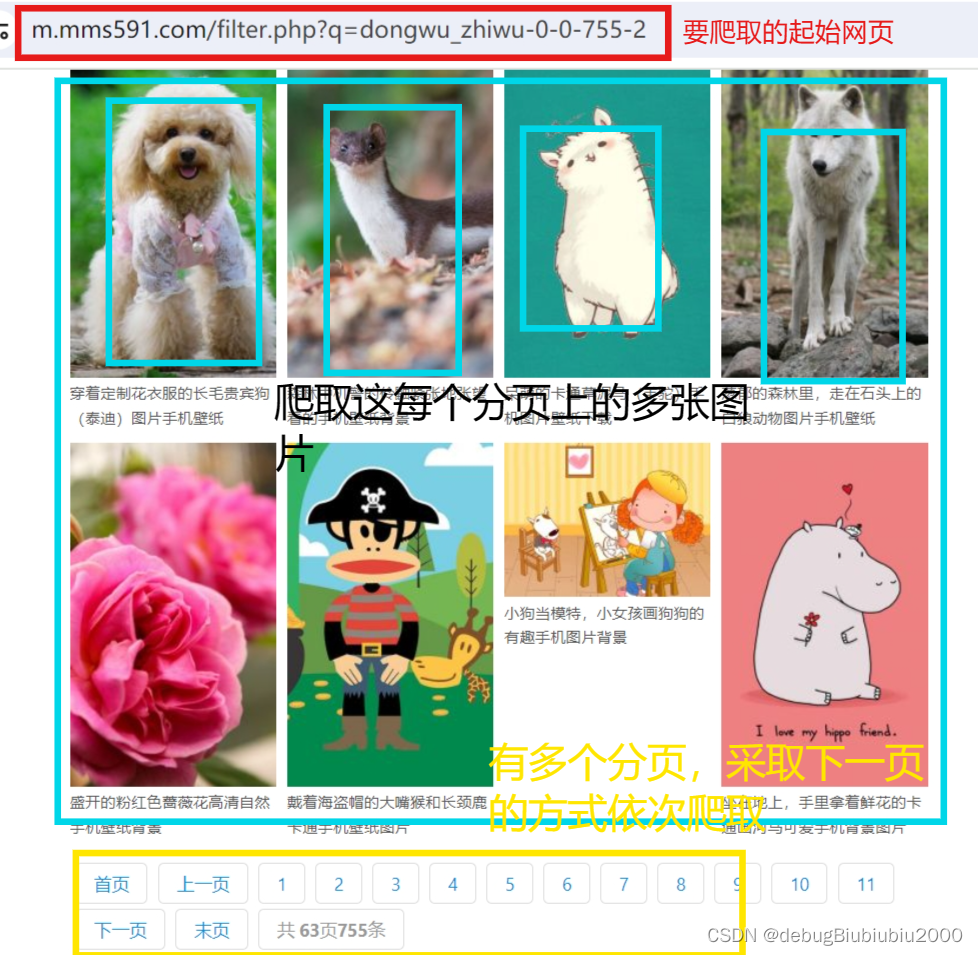
点击每张图片,可以进入图片的详情页,如下:
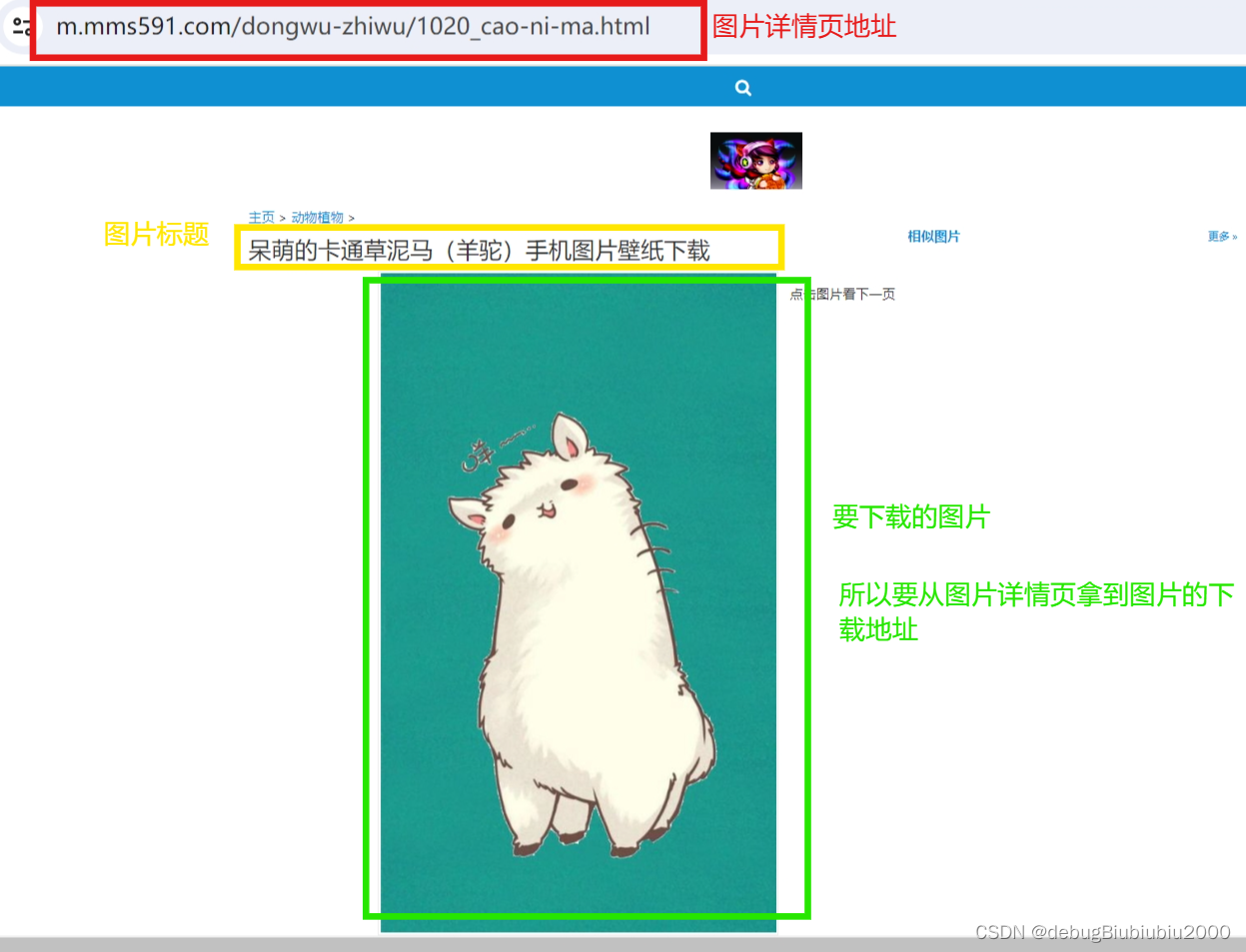
代码实现:
项目文件结构如下
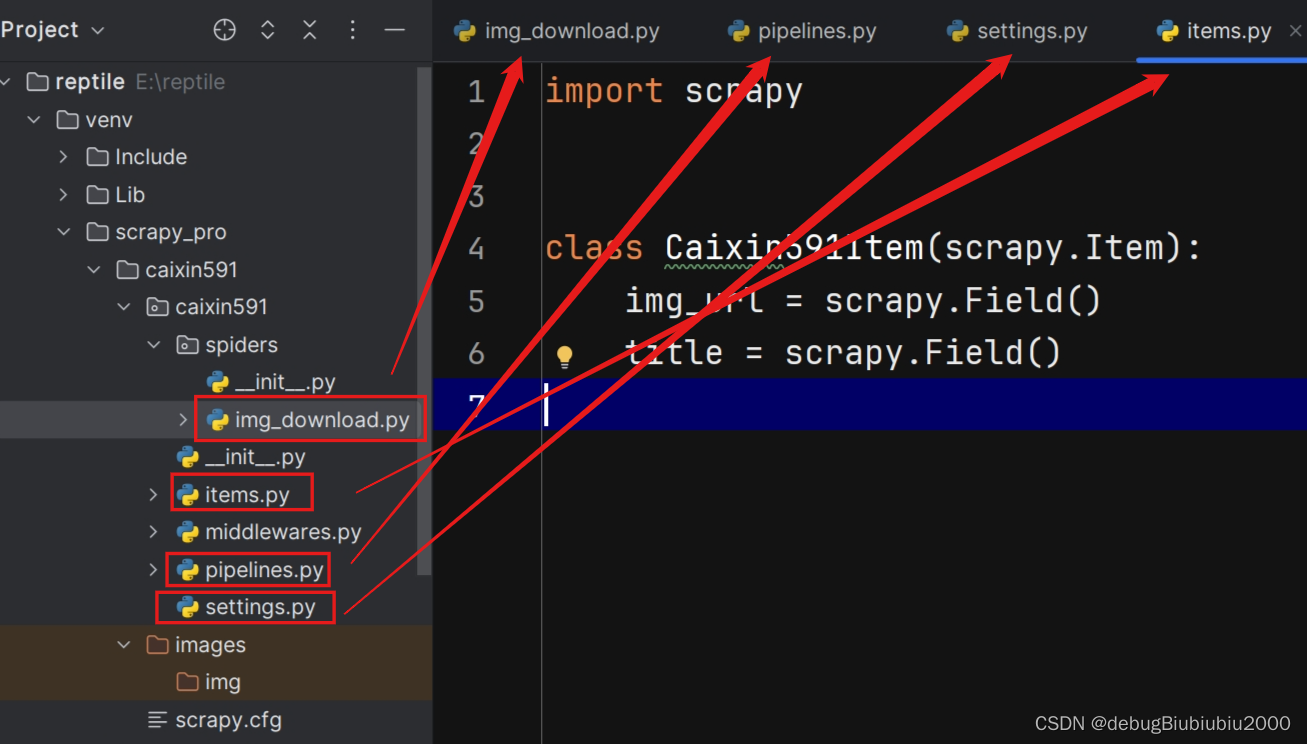
img_download.py文件代码
import scrapy
# 这里导包的时候会显示报错,但其实不影响运行,如果想去掉,可以百度一下方法
from caixin591.items import Caixin591Item
class ImgDownloadSpider(scrapy.Spider):
name = "img_download"
allowed_domains = ["m.mms591.com"]
# 修改默认的爬虫入口
# start_urls = ["https://m.mms591.com"]
start_urls = ["https://m.mms591.com/filter.php?q=dongwu_zhiwu-0-0-755-2"]
def parse(self, response, **kwargs):
# print(response.text) # 打印页面源代码
# 从页面源代码中拿到图片详情网址
# 这里有多种方法进行解析,大家可以按照自己的思路来
# 我这里先拿到每个图片所在li
lis = response.xpath('//div[@class="am-list-news-bd"]/ul/li')
for li in lis:
href = li.xpath('./div/a/@href').extract_first()
# 这里拿到的地址是不完整的,需要拼接完整的URL
# print(href) # '/dongwu-zhiwu/1015_he-ma.html'
# 之前我们是用from urllib.parse import urljoin进行拼接
# 但是scrapy中的response对象有相应的URL拼接方法
detail_img = response.urljoin(href)
# print(detail_img) # https://m.mms591.com/dongwu-zhiwu/1023_qi-e.html
# 向图片的详情地址发送请求
# 之前我们说爬虫程序要么解析出具体的数据,传递给引擎,然后通过引擎传递给通道
# 要么解析出新的URL,然后传递给引擎,引擎封装成request对象,再给调度器
# 所以这里我们解析出了一个新的URL,那么就封装成request对象,
# 至于引擎是怎么给调度器、怎么发送这个请求得到数据的不用我们关心
req = scrapy.Request(
url=detail_img, # 要请求的地址
method='get', # 请求的方式
# 这里是自定义一个解析函数
# 请求返回的内容交给谁进行数据解析
callback=self.parse_detail_page
)
# 把请求返回给引擎
yield req
break
# 上面的过程只下载了一页图片,如果我们想下载多页图片,可以在这里进行
# 可以一次性拿到所有分页的URL,然后协程或者for循环进行下载
# 这里采取拿到“下一页”这个按钮的URL,然后一页一页的下载
# 相当于不断地手动点击下一页这个按钮
# 从页面中获取下一页按钮的URL
# 这里的URL也是不完整的,需要拼接
next_page_url = response.xpath(
# a[contains(text(), "下一页")] 表示获取文本内容包含“下一页”的a标签
'//ul[@data-am-widget="pagination"]/li/a[contains(text(), "下一页")]/@href'
).extract_first()
print(next_page_url)
if next_page_url: # 如果有下一页
yield scrapy.Request(
url=response.urljoin(next_page_url),
method='get',
# 请求返回的又是一页新的有多个图片的页面,解析逻辑桶上面,所以调用parse方法
callback=self.parse
)
def parse_detail_page(self, response):
"""
在这个函数里对图片的详情页进行解析,这个方法是自定义的
:param response: 请求详情页网址时返回的内容
:return:
"""
# print(response.text)
# 拿到图片真正的下载地址
img_url = response.xpath('//img[@class="mainimg"]/@src').extract_first()
# print(img_url)
title = response.xpath('//h3/text()').extract_first()
# print(title)
item = Caixin591Item()
item['img_url'] = img_url
item['title'] = title
yield item # 把具体的数据传递给管道settings.py文件代码(删掉了没有用到的注释代码)
BOT_NAME = "caixin591"
SPIDER_MODULES = ["caixin591.spiders"]
NEWSPIDER_MODULE = "caixin591.spiders"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
"caixin591.pipelines.Caixin591Pipeline": 300,
"caixin591.pipelines.DownloadImgPipeline": 299
}
# 配置日志界别
LOG_LEVEL = 'WARNING'
# 配置保存图片的文件夹
IMAGES_STORE = './images'
# 要配置这个,否则图片管道下载图片的时候会报错:
# File (code: 301): Error downloading file from <GET http:...> referred in <None>
MEDIA_ALLOW_REDIRECTS = True
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"pipelines.py文件代码
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class Caixin591Pipeline:
def process_item(self, item, spider):
return item
# 下载图片
# 这里利用图片管道完成图片下载操作
# 注意要在settings文件中配置保存文件的文件夹
class DownloadImgPipeline(ImagesPipeline):
# 下面三个方法都是重写ImagesPipeline类中的
def get_media_requests(self, item, info):
# 本方法负责发送请求进行下载
# item 就是爬虫程序传递过来的数据
# img_url是图片真正的下载地址,发送请求后会返回图片的字节信息
# 而把图片的字节存储起来这一操作我们不需要关心
# 只需要实现这三个方法就可以完成下载图片到本地这一需求
req = scrapy.Request(url=item['img_url'], method='get')
return req # 把请求返回给引擎
# 上面是封装一个请求然后下载一次,应该也可以先封装好所有请求然后一起下载
# 但是我没尝试过,感兴趣的可以试一试
def file_path(self, request, response=None, info=None, *, item=None):
# 本方法负责提供图片文件的存储路径
# request这里对应着上面方法get_media_requests中的req
# 一个图片对应一个req
# 和以前一样,我们以URL的最后一部分命名图片
# 请求的URL可以通过request.url获取
file_name = request.url.split('/')[-1]
return f'img/{file_name}' # 返回图片文件的存储路径
def item_completed(self, results, item, info):
# 本方法可以拿到文件的详细信息
# 可以自己打印出来看看具体有什么东西
# print(results)
# print(item)
# print(info)
passitems.py文件代码
import scrapy
class Caixin591Item(scrapy.Item):
img_url = scrapy.Field()
title = scrapy.Field()


![[两个栈实现队列]](https://img-blog.csdnimg.cn/direct/1569b7459eaa4c6f9dbc92afffc6b887.png)