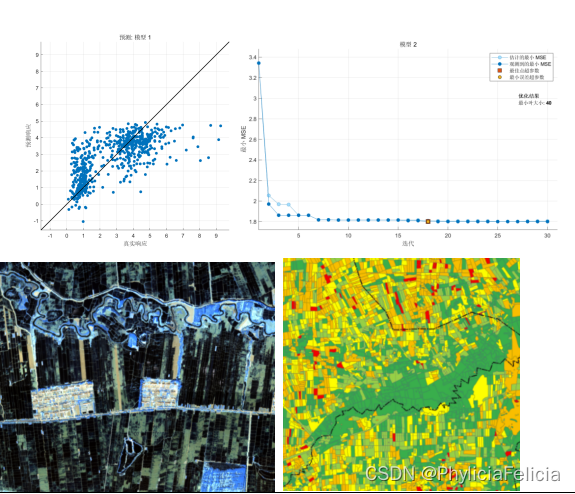
本文基于最适合入门的100个深度学习项目的学习记录,同时在Google clolab上面是实现,文末有资源连接
天气变化的时间序列的难点
天气变化的时间序列预测涉及到了一系列复杂的挑战,主要是因为天气系统的高度动态性和非线性特征。以下是几个主要难点以及为什么要使用深度学习方法来解决这些问题:
天气变化时间序列的难点
-
非线性和多尺度动态:天气系统涉及从微观到宏观的多尺度过程,这些过程相互作用,形成非常复杂的非线性动态系统。例如,局部的温度变化可能会受到遥远地区气候模式的影响。
-
高维度和多变量:天气预测通常涉及多个变量(如温度、湿度、风速、气压等),这些变量之间存在相互依赖关系,增加了预测的复杂性。
-
时空关联性:天气数据在时间和空间上都表现出强烈的相关性。时间上的连续性和空间上的地理分布都对预测模型提出了挑战。
为什么使用深度学习
深度学习方法,特别是基于循环神经网络(RNN)的变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),对于天气变化的时间序列预测非常有用,原因包括:
-
能够处理非线性和高维度数据:深度学习模型能够自动学习和提取高维数据中的复杂特征和非线性关系,无需人工设计特征。
-
记忆长期依赖关系:LSTM和GRU等RNN变体专门设计用来处理序列数据,能够记住长期的依赖关系,这对于理解天气数据中的时序动态非常关键。
-
时空数据建模能力:通过结合卷积神经网络(CNN)和RNN,深度学习模型能够同时捕捉数据的时空特征,这对于天气预测尤为重要。
-
灵活性和可扩展性:深度学习模型可以通过增加网络深度和宽度来提高其复杂性和表达能力,从而更好地处理大规模和复杂的气象数据。
-
自动特征提取:深度学习免除了传统机器学习方法中需要手动特征工程的步骤,能够自动从原始数据中提取有用的特征。
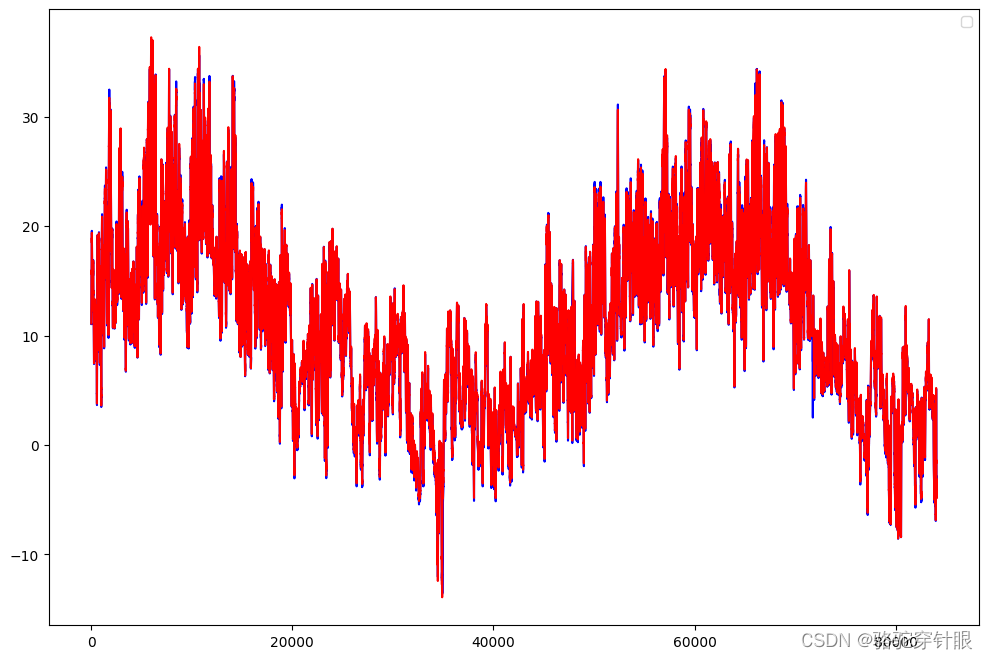
数据集介绍
背景描述
一个天气时间序列数据集,它由德国耶拿的马克思 • 普朗克生物地球化学研究所的气象站记录。在这个数据集中,每 10 分钟记录 14 个不同的量(比如气温、气压、湿度、风向等),其中包含2009-2016多年的记录。
数据说明
格式:csv
数据来源
下载1:https://www.kaggle.com/datasets/stytch16/jena-climate-2009-2016
下载2:https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip

定义网络结构
Gated Recurrent Unit (GRU) 是一种用于处理序列数据的深度学习模型,特别是在自然语言处理和时间序列分析中非常受欢迎。GRU被设计来解决标准循环神经网络(RNN)难以捕捉长期依赖关系的问题。它通过引入更新门(update gate)和重置门(reset gate)来优化长序列中信息的流动,从而有效地捕捉到长距离依赖关系,同时减少计算复杂性和缓解梯度消失问题。
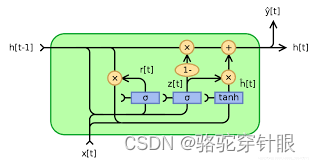
GRU网络结构的关键组件:
更新门(Update Gate):
更新门帮助模型决定之前的状态有多少信息需要保留到当前状态。它可以看作是决定何时更新隐藏状态的机制,这样可以保留长期依赖信息而忽略无关信息。
更新门的计算涉及当前输入和前一个隐藏状态,使用sigmoid函数来输出一个介于0到1之间的值,以控制保留信息的比例。
重置门(Reset Gate):
重置门决定了有多少过去的信息需要忘记,它允许模型抛弃与未来无关的信息,从而更灵活地学习数据中的依赖关系。
类似于更新门,重置门的值也是通过当前输入和前一个隐藏状态计算得到的,使用sigmoid函数确定保留多少之前状态的信息。
候选隐藏状态(Candidate Hidden State):
候选隐藏状态是一个临时状态,它包含了当前步骤可能需要添加到实际隐藏状态的信息。它的计算考虑了重置门的影响,允许模型在必要时丢弃无用的历史信息。
通过tanh函数处理,以确保其值在-1到1之间,有助于保持网络的非线性。
最终隐藏状态(Final Hidden State):
最终隐藏状态是当前时间步的输出,它结合了之前的隐藏状态和当前的候选隐藏状态,受更新门的控制。
通过更新门和候选隐藏状态的加权平均,模型可以选择保留多少旧状态信息以及添加多少新信息。
class GRU(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, output_dim):
super(GRU, self).__init__()
self.hidden_dim = hidden_dim # 隐层大小
self.num_layers = num_layers # LSTM层数
# input_dim为特征维度,就是每个时间点对应的特征数量,这里为14
self.gru = nn.GRU(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
output, h_n = self.gru(x) # output为所有时间片的输出,形状为:16,1,4
# print(output.shape) torch.Size([16, 1, 64]) batch_size,timestep,hidden_dim
# print(h_n.shape) torch.Size([3, 16, 64]) num_layers,batch_size,hidden_dim
# print(c_n.shape) torch.Size([3, 16, 64]) num_layers,batch_size,hidden_dim
batch_size, timestep, hidden_dim = output.shape
# 将output变成 batch_size * timestep, hidden_dim
output = output.reshape(-1, hidden_dim)
output = self.fc(output) # 形状为batch_size * timestep, 1
output = output.reshape(timestep, batch_size, -1)
return output[-1] # 返回最后一个时间片的输出
优化器和损失函数
model = GRU(input_dim, hidden_dim, num_layers, output_dim) # 定义LSTM网络
loss_function = nn.MSELoss() # 定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 定义优化器
模型训练
# 8.模型训练
for epoch in range(epochs):
model.train()
running_loss = 0
train_bar = tqdm(train_loader) # 形成进度条
for data in train_bar:
x_train, y_train = data # 解包迭代器中的X和Y
optimizer.zero_grad()
y_train_pred = model(x_train)
loss = loss_function(y_train_pred, y_train.reshape(-1, 1))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# 模型验证
model.eval()
test_loss = 0
with torch.no_grad():
test_bar = tqdm(test_loader)
for data in test_bar:
x_test, y_test = data
y_test_pred = model(x_test)
test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1))
if test_loss < best_loss:
best_loss = test_loss
torch.save(model.state_dict(), save_path)
print('Finished Training')
数据集和代码