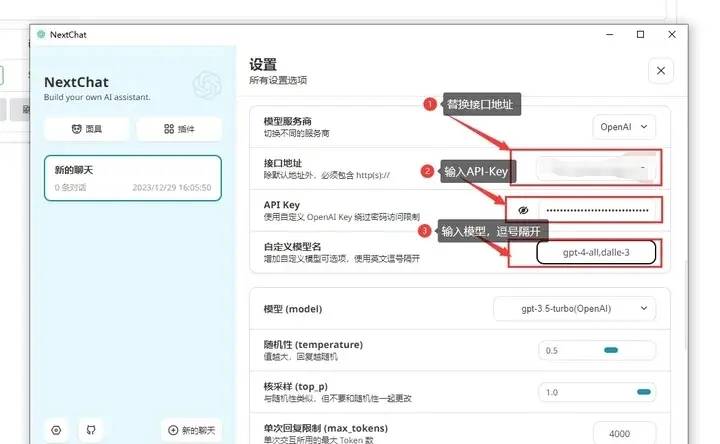
Algorithm 1 维护了一个所有玩家策略的策略池。然后循环地选定玩家,然后从他的策略集中选择出一个策略,固定其它所有玩家此时的策略,然后不断地训练这个策略使得该策略成为一个在别的玩家策略不变的情况下、近似的best respond。然后将其加入策略集合中。

参考:
https://blog.csdn.net/Xixo0628/article/details/126405395
Algorithm 1 维护了一个所有玩家策略的策略池。然后循环地选定玩家,然后从他的策略集中选择出一个策略,固定其它所有玩家此时的策略,然后不断地训练这个策略使得该策略成为一个在别的玩家策略不变的情况下、近似的best respond。然后将其加入策略集合中。
参考:
https://blog.csdn.net/Xixo0628/article/details/126405395
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1490676.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!