场与人的关系
“人—货—场”是零售中重要的三要素,我们一直在追求,将零售中的人、货、场进行数字化并在云端进行整合,形成属于我们自己的云平台。
随着互联网技术为信息提供的便利,消费者的集体力量正在逐渐形成一股强大的反向推动力,在零售商的“场”中,起到十分重要的推动作用。
过往的传统模式下,绝大多数的零售商们,会通过强化自己的营销方式,用以吸引消费者的注意力,促成消费者的消费行为。伴随着“消费降级”,使用这种方式,已经很难吸引消费者。
现如今,消费者的消费行为往往会以自身真实的体验为中心,寻找满足自身定制化需求的商品更加能吸引消费者进行购买。
场与人的关系,从原本单向的“场”对人的“消费吸引”,逐渐演变成现在的双向需求升级。

互动+消费
在零售1.0时代,信息的传递渠道相对较少,零售商占据主导地位,消费者处于被动接受的角色。产品方面,零售商之间,产品没有特别大的差别,也不具备多样性。
显然,零售商在消费者需求方面并没有倾注太多的精力。
在零售2.0时代,消费者的可选性逐渐变多了起来,消费者的个性化需求开始有所显露。应对这种变化,零售商需要在选品之前把握市场需求,避免与真正的市场需求脱节。同时,消费者开始且能够将自己对产品的体验、需求、建议等反馈给零售商,反馈意见可作为零售商持续产品改革的依据,进而推出更符合消费者需求的产品。
受到互联网发展的影响,信息传递更加便捷,消费者可以在互联网平台查询各类信息,这也促使了零售3.0时代的到来。消费者开始有更加个性化需求,深度的互动参与反向的体现了消费者的创造价值。
如今,很多零售商引入“互动+消费”的模式,在吸引消费者的同时,允许消费者发挥自己的创新思维,根据自己的实际需求提出产品建议。

GaussDB:助力消费逻辑重构
消费逻辑重构
1、消费群体的重构
伴随着移动互联网的发展,原本的消费中时间与空间的限制开始逐渐失效,消费群体的消费行为开始向移动化、碎片化、场景化的方向演变。
消费群体的重构的一大重要表现为:消费群体的精众化细分。即放弃通过地理、人口特征进行群体分类,转变为通过兴趣图谱重构新的消费群体。
对于零售商而言,消费群体身上所拥有的标签相较于其拥有的存款更加重要。此外,高频出没的消费场景,也成为零售商需要把握的内容。
2、商品价值重构
信息渠道的不断丰富,消费者不再被动地接受信息,主动反馈对产品建议、需求。
零售商开始借助多种社会化的媒介平台,与消费者进行持续的、深度的、有效的沟通,围绕消费者实现商品价值的重构。
商品价值,开始由消费者与零售商共同定义,以便满足消费者的多层次、定制化需求。
3、商品生命周期重构
随着快速时尚的商品越来越受消费者的青睐,商品生命周期也在潜移默化的发生着改变。
消费者对快时尚的追求要求商品的创新必须更快,于是,商品的更新迭代速度需要紧跟消费者的脚步,才能优先被消费者选择。
商品生命周期的重构,让零售商跳出原本的商品创新逻辑思维,在速度和时尚性等多方面下功夫,在最佳的时机将商品推向市场,吸引消费者的目光。
消费逻辑数据化
我们收集到的消费者兴趣图谱、商品建议和商品反馈等信息数据,存储在我们的大数据平台上,便于我们后续的数据挖掘等操作。
这是一项十分庞大且复杂的数据,对数据库的要求很高。
相较于本地数据库,我们更倾向选择有超强能力且成本更低的云数据库。
在寻找的过程中,华为云GaussDB进入我的视野。
为何钟情GaussDB
GaussDB的应用场景
在了解GaussDB时,我首先查看GaussDB的应用场景,两个应用场景,两段描述文字,简直像是量身为我们的业务打造的一般,十分贴合我们的需求。

GaussDB的产品优势
除了对于业务场景需要,安全也是我们最看重的因素之一。GaussDB拥有超高的的商业数据库安全特性,同时服务化能力也十分全面,基本满足我们所有的日常工作需要。

多样化连接方式
GaussDB提供使用内网、公网和数据管理服务的连接方式。

连接实例
根据我们的安全需要,选择“内网连接”的方式连接实例。
接入之前,先简单介绍一下我们的大数据平台和数据处理与存储。
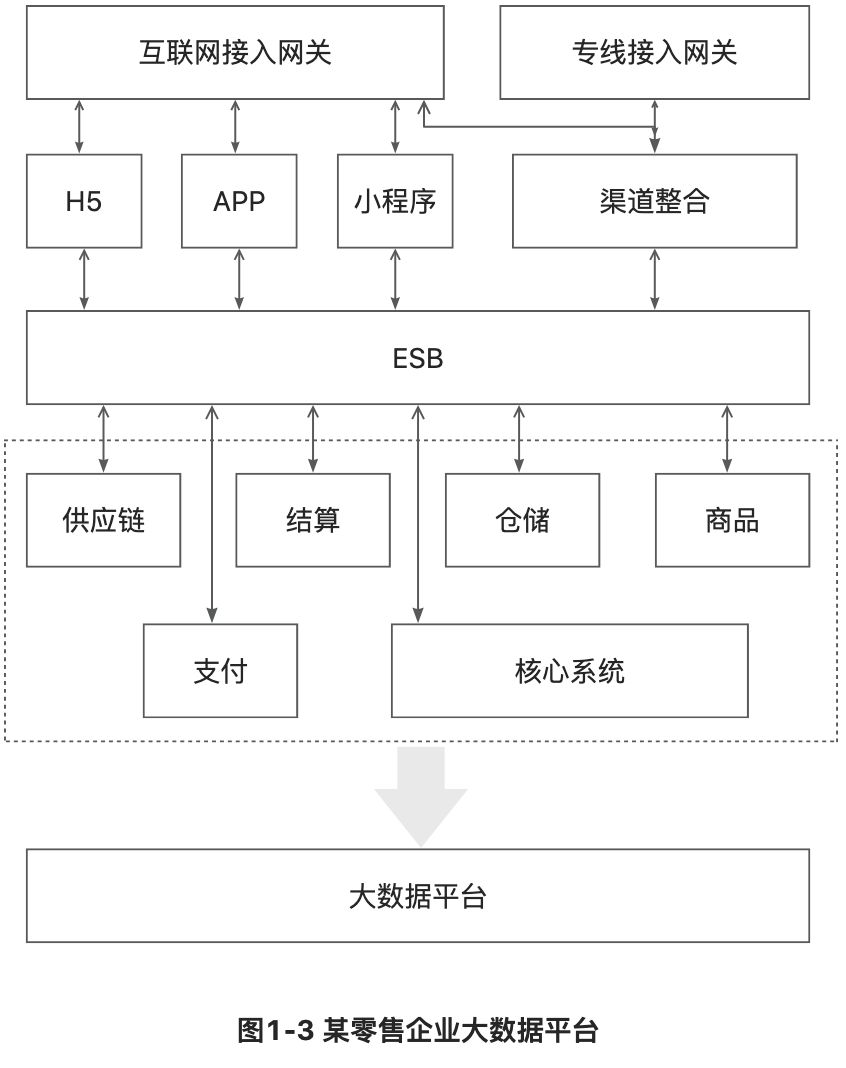
大数据平台
简单绘制了一下我们的大数据平台,从前台到中间的核心系统的数据流向如下图:
数据处理与存储
在进行数据存入数据库之前,我们会先简单处理一下数据。
已本地商品文件入库为例:
com.cz.comment.GoodManage
public class GoodManage
public static void main(String[] args) {
MySOLConfigmysqlConfig = new MySOLConfig();
Properties connectionProperties = mysqlConfig.getMySOLProp();
String url = connectionProperties.get("url") + "";
SparkConf conf = new SparkConf0).setAppName("XinLingShou").setMaster("local[8]");
JavaSparkContext sc = new avaSparkContext(conf);
SOLContextsqlContext = new SOLContext(sc);
SparkSession spark = SparkSession.builder().config(conf).getOrCreate();
// 商品本地文件
String csvInput = "data/good.csv";
// 写入的数据内容
JavaRDD<String>goodData = sc.textFile(csvInput);
JavaRDD<CommentBean>commentBeanJavaRDD = goodData.map(new Function<String,CommentBean>(){
@Override
public CommentBean call(String line) throws Exception {
CommentBeancommentBean = new CommentBean();
Stringl[] splited = line.split(" ");
if (splited.length= 3) {
commentBean.setld(splitedr[0]);
commentBean.setGood_id(splitedr[1]);
commentBean.setGood_id(splitedr[2]);
}
return commentBean;
}
});
Dataset commentGd = salContext.createDataFrame(commentBeanJavaRDD,CommentBean.class):
System.out.println("商品数量:" + commentGd.count());
sc.close();
}通过内网连接实例
通过内网连接实例,官网提供了详细的文档:《通过内网连接实例》。
其中需要额外注意几点。
1、客户端工具包相对位置为解压后位置
实际位置可能与案例提供的有出入,以实际解压位置为准。
cd /tmp/tools/GaussDB_driver/Centralized/Euler2.5_X86_64/
cp GaussDB-Kernel_VxxxRxxxCxx_EULER_64bit_Gsql.tar.gz /tmp/tools
2、需要连接的数据库名称
postgres为需要连接的数据库名称,如果是分布式实例,10.0.0.0为CN的IP地址,如果是主备版实例,10.0.0.0则为主DN的IP地址,root为登录数据库的用户名,8000为分布式版CN或主备版DN的默认端口号。
gsql -d postgres -h 10.0.0.0 -U root -p 8000
Password for user root:总结
新零售时代,场与人的关系,从原本单向的“场”对人的“消费吸引”,逐渐演变成现在的双向需求升级。
需求升级在零售3.0时代中尤为显著,消费者开始有更加个性化需求,深度的互动参与反向的体现了消费者的创造价值。
消费者创造价值的模式,即“互动+消费”的模式,引发了消费逻辑的重构。
想要满足重构之后的消费逻辑数据化需求,我们决定选择云数据库——华为云GaussDB。之所以选择GaussDB,主要是它提供的业务场景、产品优势,对我们的业务契合度非常高。
所以,我们选择华为云GaussDB,帮助重构新零售中的消费逻辑升级所带来的数据化的业务需要。
未来,我准备继续摸索华为云GaussDB的更多场景化实践。
作者:非职业「传道授业解惑」的开发者叶一一
简介:「趣学前端」、「CSS畅想」系列作者,华夏美食、国漫、古风重度爱好者,刑侦、无限流小说初级玩家。
如果看完文章有所收获,欢迎点赞👍 | 收藏⭐️ | 留言📝。