写在前面
基础环境可以参考ElasticSearch之分布式模型介绍,选主,脑裂 。
本文看下es的数据分片和故障转移相关内容。
1:数据分片
分片,英文是shard,存储在data node ,分为主分片和副本分片,英文分别是primary shards和replica shards,比如当前我们的完整数据是1,2,3,4,5,6,进行如下设置:

则可能的数据存储情况如下:
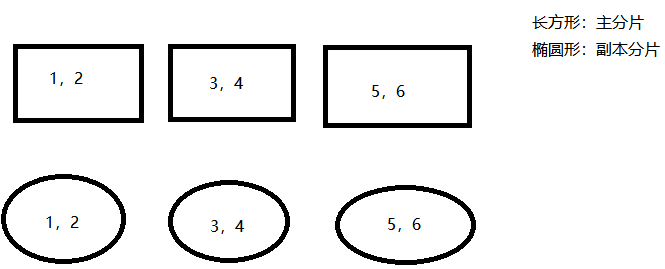
这里的number_of_shard:3指的就是上图的3个长方形,即将数据分成了3份来存储,number_of_replica:1指的是每个长方形的主分片都将复制一份存储,也就是存储到对应的椭圆形副本分片, 这个关系参考下图:

在生产环境中我们需要设置合理的主分片和副本分片数,主分片数如果是设置过小,将无法无法实现通过增加节点的方式来实现数据存储的横向扩展,比如主分片设置为1,则最多只有一个data node可以分配主分片,再增加data node也于事无补,但是也不能设置过多的数据分片,数据分片过多会导致数据读取性能的下降(多份来自不同主分片的数据需要聚合),一个节点上过多的分片也会导致性能下降。副本分片数设置为0可能会有数据丢失风险,设置过大,会影响数据的写入性能。
所以不管是主分片数还是副本分片数都需要设置一个合理的数值才行。主分片数需要结合具体的业务数据量来测试得出,副本分片数一般设置为1即可,这样即不会过度影响数据写入的性能,也避免了因为主分片所在data node损坏而出现的数据丢失。
2:故障转移和实例
准备es和cerebro的基础环境参考这篇文章 。
2.1:什么是故障转移
自动将宕机节点的分片信息(主分片primary shard,副本分片 replica shard)转移到正常节点,以正常的对外提供服务。
2.2:实例
首先我们来启动第一个es:
bin/elasticsearch -E node.name=xiaohengnode1 -E cluster.name=xiaoheng -E path.data=xiaoheng0_data -E http.port=9200
cerebro查看:

然后我们创建一个主分片=3,副本分片=1即索引test:



可以看到此时集群的状态是yellow的,这是因为副本分片没有可分配的data node,接着我们再来启动一个es实例:
bin/elasticsearch -E node.name=xiaohengnode2 -E cluster.name=xiaoheng -E path.data=xiaoheng1_data -E http.port=9201
再看cerebro,就正常了:
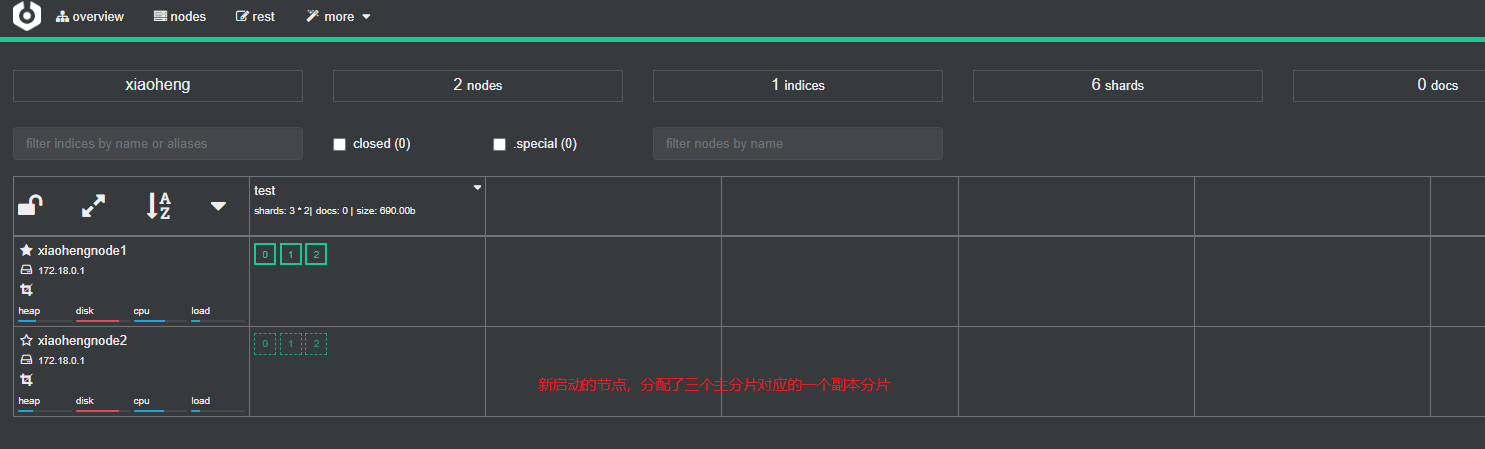
为了测试故障转移的效果,我们再来启动一个es实例:

此时分片就重新分配到三个节点了:
接着我们来停止一个节点:
# 停止
[elk@localhost elasticsearch-7.6.2]$ ps -ef | grep elasti
elk 2957 1 40 01:56 pts/0 00:00:20 /opt/program/elasticsearch-7.6.2/jdk/bin/java -Des.networkaddress.cache.ttl=60 -Des.networkaddress.... -cp /opt/program/elasticsearch-7.6.2/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
[elk@localhost elasticsearch-7.6.2]$ kill -9 2957
看下故障转移的效果:
集群状态变为yellow:
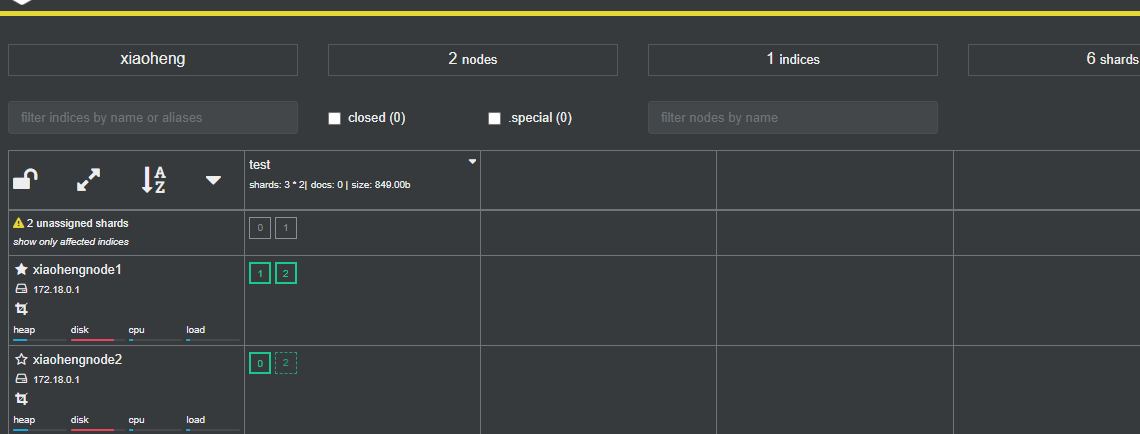
在等几秒种,多刷几次,看下故障转移的效果:
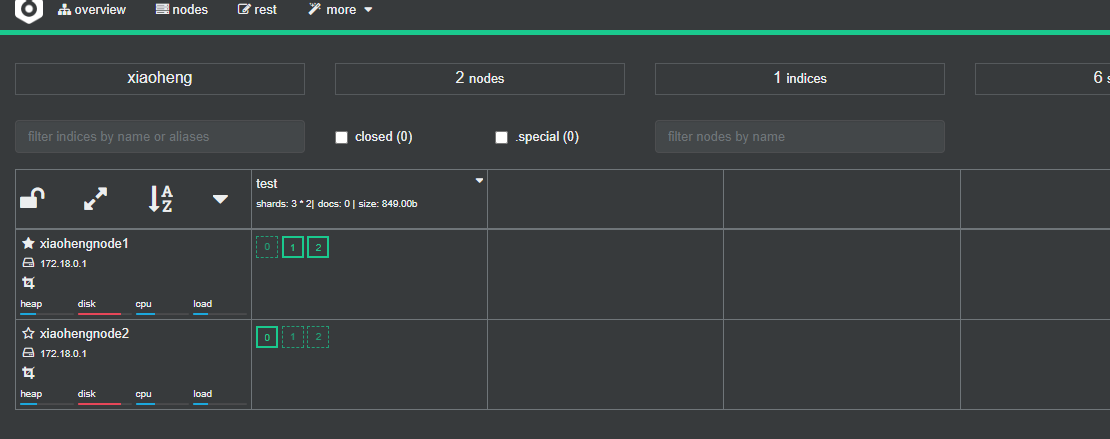
可以看到恢复到了2节点集群时的状态。
写在后面
参考文章列表
ElasticSearch之分布式模型介绍,选主,脑裂 。
ElasticSearch之安装和简单配置 。










![BUUCTF---[BJDCTF2020]藏藏藏1](https://img-blog.csdnimg.cn/direct/65af539ad7ab427f885b2aa3e1f3936a.png)