一、分类任务常见评估:
准确度(Accuracy) 评估预测正确的比例,精确率(Precision) 评估预测正例的查准率,召回率(Recall) 评估真实正例的查全率。如果是多分类,则每个类别各自求P、R最终求平均值。
TP(True Positives):真正例,预测为正例而且实际上也是正例;
FP(False Positives):假正例,预测为正例然而实际上却是负例;
FN(false Negatives):假负例,预测为负例然而实际上却是正例;
TN(True Negatives):真负例,预测为负例而且实际上也是负例。
1、精确率(Precision):以预测结果为判断依据,预测为正例的样本中预测正确的比例。
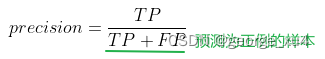
用此标准来评估预测正例的准确度。
2、召回率(Recall):以实际样本为判断依据,实际为正例的样本中,被预测正确的正例占总实际正例样本的比例。也叫“查全率”。
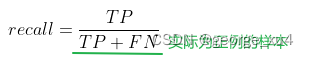
3、准确率(Accuracy):最直观的就是准确率: 模型判断正确的数据(TP+TN)占总数据的比例
(TP+TN)/(TP+TN+FP+FN)
什么情况下精确率很高但是召回率很低?
一个极端的例子,比如我们黑球实际上有3个,分别是1号、2号、3号球,如果我们只预测1号球是黑色,此时预测为正例的样本都是正确的,精确率p=1,但是召回率r=1/3。
什么情况下召回率很高但是精确率很低?
如果我们10个球都预测为黑球,此时所有实际为黑球都被预测正确了,召回率r=1,精确率p=3/10。
4、F1值:中和了精确率和召回率的指标
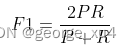
当P和R同时为1时,F1=1。当有一个很大,另一个很小的时候,比如P=1,R~0 , 此时F1~0。分子2PR的2完全了为了使最终取值在0-1之间,进行区间放大,无实际意义。
语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率。
5、PPL
困惑度(Perplexity,PPL) 基本思想是:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好 ,公式如下:
困惑度越小,句子概率越大,语言模型越好。

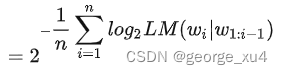
这里补充开N次根号(N为句子长度,如果是中文,那就是分词后词的个数)意味着几何平均数:
1、需要平均 的原因是,因为每个字符的概率必然小于1,所以越长的句子的概率在连乘的情况下必然越小,所以为了对长短句公平,需要平均一下,使得不同长度的句子困惑度可以在一个量级下比较。2、如果有其中的一个概率是很小的,就会影响最终结果小,所以要用几何平均。机器翻译常用指标BLEU 也使用了几何平均,还有机器学习常用的F-score 使用的调和平均数 ,也有类似的效果。
N-gram(uni-gram, bi-gram, tri-gram) 不同词袋模型
uni-gram:单个词语概率独立

重点:如uni-gram就是单个词语的出现频率(词频/语料库中所有的词语数量),而例如tri-gram则是:

困惑度是交叉熵的指数形式。log perplexity和交叉熵cross entropy是等价的
6 BLEU
双语评估替补(Bilingual Evaluation Understudy)。衡量机器翻译的好坏,取值范围是[0, 1],越接近1,表明翻译质量越好,主要是基于精确率。
BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。
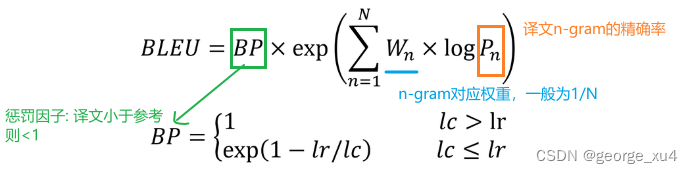
1、Pn及n-gram精确率计算:
假设机器翻译的pred译文C和一个targets参考翻译S1如下:
C: a cat is on the table或there there there there there
S1: there is a cat on the table (参考翻译有m个)

针对上面的例子:n去1代表1-gram词袋精确率统计;
p1=min(5,1)/5
所以 p1 = 1/5 (因为there在C和S1中都出现了 我们按最少的次数来)
2、BP惩罚因子:对翻译结果的长度进行惩罚。这样做的目的是为了防止翻译结果过长而得分过高,因为较长的翻译结果往往可以包含更多的词汇,从而有更高的概率在参考翻译结果中找到匹配的词汇。
bp = exp(1 - (ref_len / cand_len))
其中:ref_len 表示参考翻译结果的长度(一般是词汇数量),cand_len 表示生成的翻译结果的长度(同样是词汇数量),exp 表示指数函数。
当生成翻译长度小于参考翻译长度,惩罚因子会降低BLEU得分,使得较长的翻译结果在评估中得到较低的权重。当机器翻译的长度比较短时,BLEU 得分也会比较高(这里为1),但是这个翻译是会损失很多信息的。所以在实际应用中,可以根据具体的需求和任务情况,调整长度惩罚因子的数值,以满足评估的要求。
7 ROUGE
Recall-Oriented Understudy for Gisting Evaluation主要是基于召回率(recall) 的。可用来衡量生成结果和标准结果的匹配程度
ROUGE-N: 在 N-gram 上计算召回率
ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列
ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列
ROUGE-S: 其实是Rouge-N的一种扩展,N-gram是连续的,Skip-bigram是允许跳过中间的某些词,同时结合了Rouge-L的计算方式。
1、ROUGE-N 主要统计 N-gram 上的召回率,对于 N-gram,可以计算得到 ROUGE-N 分数:
公式的分母是统计在参考译文targets中 N-gram 的个数,
而分子是统计参考译文与机器译文pred共有的 N-gram 个数。
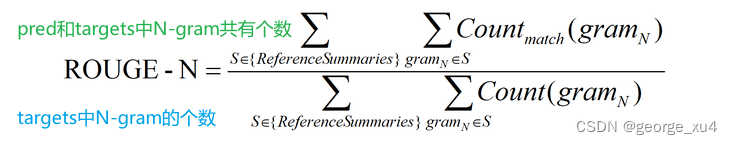
值为(0~1)
如果给定多个参考译文 Si, ROUGE-N 会分别计算机器译文和这些参考译文的ROUGE-N 分数,并取其最大值
2、ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文C和参考译文S的最长公共子序列:
如果len(C )=6,S=7;则LCS=6
3、作者提出了一种加权最长公共子序列方法 (WLCS),给连续翻译正确的更高的分数。

虽然Y1,Y2与 X 的最长公共子序列一样,但明显Y1更多连续匹配,应该权重加大。
4、ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许"跳词 (Skip)",即单词不需要连续出现。例如句子 “I have a cat” 的 Skip 2-gram 包括 (I, have),(I, a),(I, cat),(have, a),(have, cat),(a, cat)。
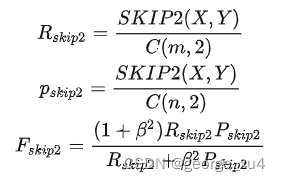
8 METEOR
meteor(Metric for Evaluation of Translation with Explicit ORdering)综合考虑了精确度和召回率,并使用外部知识源来解决同义词和形态变化问题。❤️🧡💛
METEOR引入了显式排序的方式来考虑生成翻译与参考翻译之间的语序一致性,从而可以一定程度上解决语序不一致的问题。
1、 计算unigram下的精确率P和召回率R(计算方法与BLEU、ROUGE类似),得到调和均值F值。
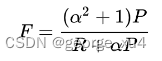
2、 使用chunk概念计算惩罚因子:候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk。chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致。
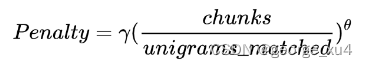
如果参考译文是“我爱你”,而模型给出译文是“你爱我”,虽然每个uni-gram都能对应上,但这种应该受到很重的惩罚,告诉模型翻译不当
3、 METEOR值计算为对应最佳候选译文和参考译文之间的精确率和召回率的调和平均。
![]()
不足:对近义词和词汇选择的灵活性较低:METEOR主要基于精确匹配、部分匹配和词义相似性来评估单词和短语的匹配程度,而对于生成翻译与参考翻译之间的近义词和词汇选择的灵活性较低。这可能导致在某些情况下,即使生成翻译在语义上与参考翻译相近,但由于词汇选择不同,METEOR得分较低。
9 CIDEr
Consensus-based Image Description Evaluation)是 BLEU 和向量空间模型的结合。
它把每个句子看成文档,然后计算 TF-IDF 向量(只不过 term 是 n-gram 而不是单词)的余弦夹角,据此得到候选句子和参考句子的相似度,同样是不同长度的 n-gram 相似度取平均得到最终结果。CIDEr指标的得分范围通常在0到几十之间,越高表示生成模型生成的图像描述与人工参考描述越一致,质量越好。
CIDEr指标在计算一致性时,会对候选描述和参考描述中的词汇进行词频权重计算,并将候选描述和参考描述的词频权重与一致性权重相乘得到一致性贡献。在计算一致性权重时,CIDEr指标可以通过引入惩罚因子来对非关键词进行降权,从而减少它们对一致性计算的贡献。(常用惩罚因子参考下面的TF-IDF)
举例:考虑一个图像描述任务,其中参考描述为:“A black cat is sitting on a red sofa.”(一只黑猫坐在一张红色沙发上。)而生成的候选描述为:“A cat is sitting on a sofa.”(一只猫坐在一张沙发上。)如果直接使用词频权重计算一致性,那么由于候选描述中缺少了"black"和"red"这两个关键词(就是非关键词),会导致一致性得分较低。然而,这两个关键词实际上并不是任务中最关键的词汇,因为它们只是描述图像中的一些颜色信息。
TF-IDF:
Term Frequency(词频)和Inverse Document Frequency(逆文档频率)。
1.TF:特定的word在文档中出现的次数/文档长度
2.IDF:log(语料库中总共的文档数/包含有特定的word的文档数)
TF-IDF值越大,表示词在当前文档中的重要性越高,且在其他文档中出现的频率越低。
在CIDEr中:如果一些n元组频繁地出现在描述图像的参考标注中,TF对于这些n元组将给出更高的权重,而IDF则降低那些在所有描述语句中都常常出现的n元组的权重。
10 Edit Distance
编辑距离(Edit Distance),也称为Levenshtein距离,是一种用于衡量两个字符串之间的相似度的指标。它定义为将一个字符串转换为另一个字符串所需的最小编辑操作数,其中编辑操作包括插入(Insertion)、删除(Deletion)和替换(Substitution)字符。
用处:
1、拼写纠错:可以使用编辑距离来计算输入的单词与词典中的单词之间的相似度,从而进行拼写错误的自动修正。
2、文本匹配:可以使用编辑距离来计算两段文本之间的相似度,从而进行文本匹配、相似性搜索等任务。
编辑距离的计算方法通常使用动态规划算法。算法通过创建一个二维矩阵,其中矩阵的每个元素表示从一个字符串的前缀转换到另一个字符串的前缀所需的最小编辑操作数。通过填充矩阵并计算最右下角的元素,我们可以得到两个字符串之间的编辑距离。后面采用回溯,从最后一个单元格开始(即最大行和最大列的单元格),跟随回溯指针的方向回溯该矩阵,从最后单元格开始到第一个单元格的每一条完整路径都代表一个最小比对距离。
举例:假设我们有两个字符串:“kitten” 和 “sitting”,我们想计算它们之间的编辑距离。
首先,我们创建一个二维矩阵,其中行表示 “kitten” 的每个字符,列表示 “sitting” 的每个字符。矩阵的大小为 (6+1) x (7+1),因为字符串的长度分别为 6 和 7,我们在每个字符串前面添加了一个空字符作为起始字符。

然后,我们从矩阵的左上角开始,按行和列遍历矩阵,并计算从一个字符转换到另一个字符的编辑操作数。我们可以使用以下三种操作:插入(I)、删除(D)和替换(R)。
- 如果两个字符相同,那么当前位置的编辑操作数等于左上角位置的编辑操作数,表示无需操作。
- 如果两个字符不同,那么当前位置的编辑操作数等于左上角、左边和上边位置的编辑操作数的最小值加1,表示需要执行一次编辑操作。
dp[i][j]=min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])+1
最终填充整个矩阵

最右下角的值 3 即为 “kitten” 和 “sitting” 之间的编辑距离,表示从字符串 “kitten” 转换到 “sitting” 需要执行的最少编辑操作数,即替换 “k” 为 “s”,删除 “e”,和插入 “i”,共计 3 次编辑操作。
不足:计算复杂度较高,特别是对于较长的字符串,会占用较多的计算资源。另外,编辑距离只考虑了单个字符的编辑操作,不考虑上下文和语义信息,因此在某些应用场景下可能不够精确。
总结
1,2,3,4这四种评估指标是基础评估指标;5,6两种评估指标主要用来辨别一句话是否是人话的概率;7,8两种指标经常用于机器翻译、文章摘要评价任务指标;9,10两种指标经常应用于机器翻译任务指标。如果还有其他比较重要或者常用的指标也欢迎大家分享,相互学习!!!
以上均为笔者在学习和研究过程中参考过的资料,并非原创,在此表明。笔者目前也正在学习和研究大模型对此领域还不太熟练,欢迎与我讨论,提出宝贵的意见和建议。如果文章对您有所帮助,还请点赞支持,谢谢!