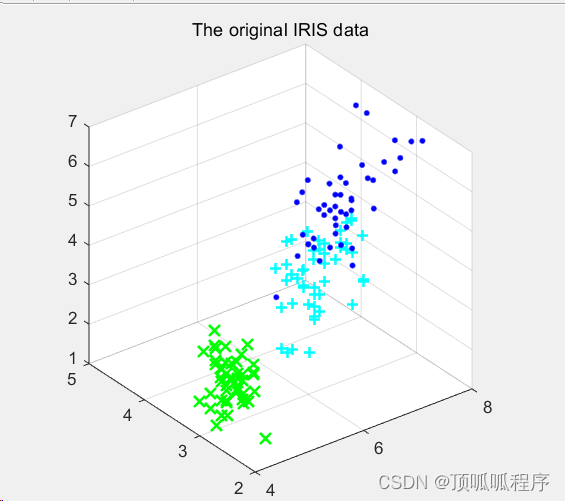
三范式
概念:
三范式(3NF)是关系型数据库设计理论的基础,它确保数据的结构化和减少数据的冗余性。三范式由数学家E.F. Codd在1970年提出,作为关系理论的一部分。三范式包括:
第一范式(1NF):
每一个列都不可再分,即列中存储的都是原子值,不可再分的数据项。
同一个关系中,每个属性都有唯一的属性名。
每个记录(或行)都有一个唯一的标识,通常是主键。
每个列都不可再分,即列中存储的都是原子值,不可再分的数据项。
第二范式(2NF):
满足第一范式。
每个非主属性都完全函数依赖于整个主键。这意味着如果表有一个复合主键,则该表的每一个非主属性都应该依赖于这个复合主键的整个部分,而不仅仅是部分。
第三范式(3NF):
满足第二范式。
非主属性之间没有传递依赖。简单来说,非主属性不应该依赖于其他非主属性。
进一步地,还有其他的范式,如BCNF、3.5NF等,但它们在日常的关系数据库设计中并不常用。满足三范式通常被认为是创建无冗余和结构良好的数据库的最小要求。
设计满足三范式的数据库可以确保数据的结构清晰、易于维护,并减少数据的冗余性和插入、更新、删除操作时的异常。然而,有时在某些应用场景中,为了查询性能或其他优化,可能会故意违反三范式。在这种情况下,需要仔细权衡规范化的好处和其可能带来的问题。
第一范式,例:

分析:不符合第一范式
表包含“学生ID”、“班级”、“班主”、“课程”和“分数”这五个属性,不符合第一范式(1NF),是因为某些属性包含了可以进一步拆分的复合数据或数组。在第一范式中,每个列都应该只包含原子值,即不可再分的数据项。
例如,如果“班级”这一列包含了多个班级的信息,如“1A, 2B, 3C”,或者“课程”这一列包含了多门课程的信息,如“数学, 物理, 化学”,那么这个表就不符合第一范式。因为这些列包含了可以进一步拆分的复合数据。
为了使其符合第一范式,我们可以进行如下拆分:
学生表 (Students):
学生ID (StudentID, 主键)
其他与学生相关的属性(例如:姓名、性别等)
班级表 (Classes):
班级ID (ClassID, 主键)
班级名称 (ClassName)
班主 (TeacherID, 外键,关联到教师表)
课程表 (Courses):
课程ID (CourseID, 主键)
课程名称 (CourseName)
分数表 (Scores):
学生ID (StudentID, 外键,关联到学生表)
课程ID (CourseID, 外键,关联到课程表)
分数 (Score)
班级ID (ClassID, 外键,关联到班级表,可选,如果需要考虑班级对分数的影响)
这样,每个表都只包含原子值,每个列都不可再分,并且每个表都有一个明确的主键。同时,通过外键关联,可以确保数据的引用完整性。这样拆分后的数据库结构就满足了第一范式的要求。
第二范式,例:

一个表中只能保存一种类型数据
第三范式,例:

同一个表中互相都不能被推导出来,例如上面的例子,班主任可以由班级推导出来,所以拆成两个表
ER模型
概念:
E-R模型(Entity-relationship model)实体关系模型,E- R模型的构成成分是实体集、属性和联系集。
表示方法:
(1)实体集用矩形框表示, 矩形框内写上实体名。
(2)实体的属性用椭圆框表示, 框内写上属性名,并用无向边与其实体集相连。
(3)实体间的联系用菱形框表示, 联系以适当的含义命名,名字写在萎形框中,用无向连线将参加联系的实体矩形框分别与菱形框相连,并在连线上标明联系的类型,即1——1、1——N或M——N.
数据库设计的过程,就是将现实世界抽象到信息系统的过程,使用的工具就是ER图,我们把所有参与到业务流程中的对象,抽象为“实体”,每个实体有自己的“属性”,实体与实体之间产生的动作叫"关系”,用线连接起来。