淘汰策略
- 只有 redis 内存空间已满并且往里面写新数据,才会触发淘汰策略。
- 通过 expire / / /pexpire 让 key-value 过期,从而让 redis 清除这个 key-value。
- value 的数据结构
typedef struct redisObject { unsigned tpye:4; unsigned encoding:4; // 判断哪些 key 要被删除 unsigned lru:LRU_BITS; // 占用 24位,8位用来记录访问的次数(0-255次),16位用来记录上一次访问的时间 int refcount; // 引用计数 void *ptr; // 指向 value 的存储空间 } robj;object idletime key # 展示 value 的 lru 字段 - 配置淘汰策略
- 如果 redis 内存空间已满,并且没有设置淘汰策略,再 set key value 会直接返回错误,提示内存空间已满;如果设置了淘汰策略,redis 会按照淘汰策略选择数据进行删除,再 set key value 就会成功。
# redis.conf maxmemory <bytes> # redis 最多可以使用多少空间 maxmemory-policy # 淘汰策略,默认为 noeviction, 不进行淘汰 maxmemory-samples # 默认为 5,选择多少个 key 进行淘汰 - 过期 key 中
- volatile-lru:最长时间没有使用。
- volatile-lfu:最少次数使用,随机采样。
- volatile-ttl:最近要过期。
- volatile-random:随机。
- 所有 key
- allkeys-lru。
- allkeys-lfu 。
- allkeys-random 。
- 禁止淘汰:no-eviction。
- 如果 redis 内存空间已满,并且没有设置淘汰策略,再 set key value 会直接返回错误,提示内存空间已满;如果设置了淘汰策略,redis 会按照淘汰策略选择数据进行删除,再 set key value 就会成功。
持久化
- redis 为什么需要持久化 ?
- 因为 redis 是内存数据库,一旦关闭,内存中的数据就丢失了,所以需要把内存中的数据写到磁盘中,这样 redis 重启后就可以从磁盘中加载原来的数据到内存中。
- 只有写操作(增删改操作,会引起数据库变更的操作)才会进行持久化。
- redis 持久化方式
- aof
- 持久化的是写操作协议内容(通过重放恢复内存中的数据),会有很多冗余数据;在 redis 进程中完成,every_sec 会另启线程做持久化。
*3 $3 set $4 mark $1 2 - 策略
- no:关闭 aof。
- always:先将数据持久化到磁盘,再响应客户端。(效率很低,一般不采用)
- every_sec:只要内存修改成功,立刻响应客户端。
- 先将数据写到 aof buffer 中,一秒后将 aof buffer 中的数据持久化到磁盘,这个过程是异步的,使用 bio_fsync_aof。
- always 和 every_sec 会调用
fsync(fd)将 page cache 中的数据立刻持久化到磁盘。
- aof-rewrite
- 因为 aof 文件过大,数据恢复速度太慢,所以要减少 aof 文件大小。
- 工作原理
- fork 进程,根据内存数据生成 aof 文件,避免同一个 key 的历史冗余数据。
- 在重写 aof 期间,对 redis 的写操作会被记录到重写缓冲区,在重写 aof 结束后,再将这些写操作附加到 aof 文件末尾(可能有冗余数据)。
- 持久化的是写操作协议内容(通过重放恢复内存中的数据),会有很多冗余数据;在 redis 进程中完成,every_sec 会另启线程做持久化。
- rdb
- 持久化的是二进制数据(根据磁盘中的二进制数据恢复内存中的数据);另启进程做持久化。
- 工作原理:通过 fork 子进程进行持久化,基于内存中对象编码直接持久化。
- fork 相当于给父进程的内存做了一个快照。
- fork 写时复制

- 页表存储了虚拟内存和物理内存之间的映射关系。
- linux 为了加快 fork 的流程,fork 仅仅会复制页表,然后将两个页表中的所有保护位修改为只读,此时父进程和子进程共用一块物理内存;父进程依然对外提供服务。
- 当父进程处理写操作时,首先会找到虚拟内存的内存页,然后通过页表写物理内存页的时候,发现保护位是只读的,此时会触发写保护中断:在物理内存中完成一次物理页复制(把原来的物理页复制一份),然后把数据写入到复制后物理页中,最后在写保护中断的处理函数中将页表中的保护位修改为可读可写,并且重新构建页表中的映射关系(页表中该虚拟内存的指向变为新的物理页)。
- rdb-aof 混用
- 通过 fork 子进程,根据内存数据生成 rdb 文件。
- 在 rdb 持久化期间,对 redis 的写操作会被记录到重写缓冲区,在 rdb 持久化结束后,采用 aof 的方式附加到文件末尾。
- aof
- redis 持久化方式优缺点
- aof
- 优点:数据可靠,丢失较少;持久化过程代价较低(是顺序磁盘 IO,持久化速度快)。
- 缺点:aof 文件过大,数据恢复慢(通过重放恢复内存中的数据)。
- rdb
- 优点:rdb 文件小,数据恢复快。
- 缺点:数据丢失较多;持久化过程代价较高。
- aof
- 大 key 问题:kv 中,value 如果占用大量空间就是大 key,比如 value 是 hash、zset,里面存储大量元素。
- fsync 压力大。
- 因为页表大,所以 fork 时间长,写时复制造成持久化时间长。
高可用
- 为什么实际业务中有高可用的需求 ?
- 比如服务器依赖 redis,如果 redis 宕机了,那么服务器就不能给客户端响应了,此时整个服务器处于不可用状态。
- redis 高可用:如果 redis 中的一个节点宕机了,会有备用节点顶替它,服务器不会因为 redis 中的一个节点宕机了,造成服务不可用。
- 什么是高可用 ?
- 在合理的时间内给出合理的回复。
- 合理的时间:秒级的。
- 合理的回复:给一个请求,如果发生错误,需要回复是到底是什么错误,不能模棱两可。
- 在合理的时间内给出合理的回复。
- 如何实现高可用 ?
- 数据备份。
- 节点切换策略。
主从复制
- 主从复制不能保证高可用,只起到了数据备份的作用。
- 含义
- 主从复制是异步复制,服务器写数据到主数据库(master),主数据库立刻返回;从数据库(replica)不断地从主数据库中拉取数据并保存,以达到从数据库和主数据库数据一致。
- replica 主动向 master 建立连接(否则无法线上新增 replica)
- replica 主动向 master 拉取数据(若网络出现问题,replica 持有同步位置:复制偏移量)
- 缺点:可能带来数据不一致:某一时刻如果从 replica 中获取数据,数据可能不是最新的。
- 实现

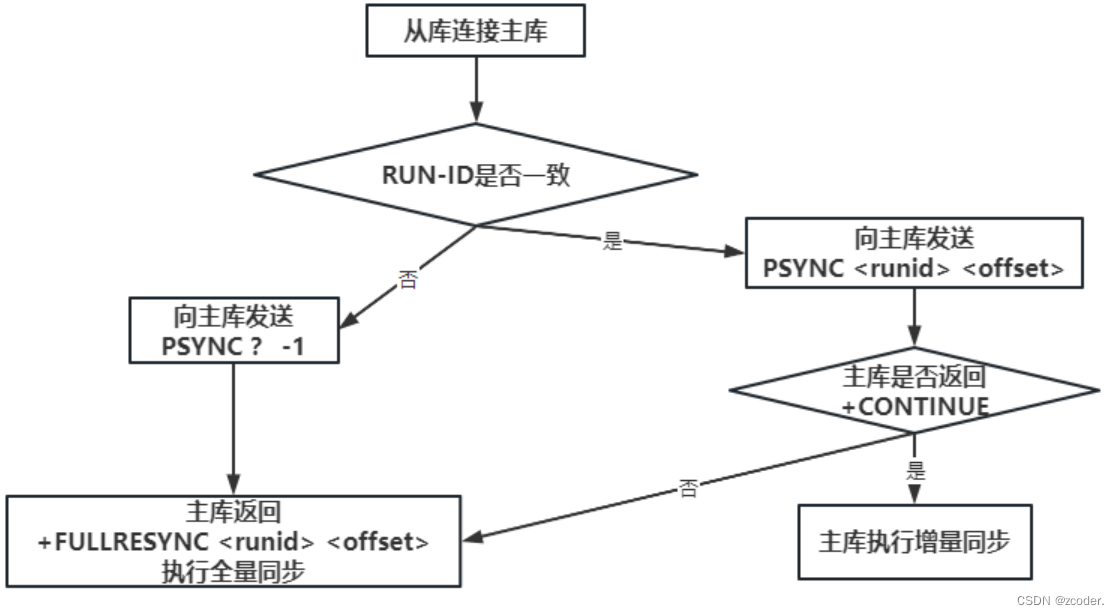
- master 记录了一个环形缓冲区和一个复制偏移量,replica 记录了一个复制偏移量。
- RUN ID:
- 无论 master 还是 replica 都有自己的 RUN ID,RUN ID 在其启动时自动产生,由 40 个随机的十六进制字符组成。
- 当 replica 对 master 初次复制时,master 将自身的 RUN ID 发送给 replica,replica 会将 RUN ID 保存;当 replica 断线重连 master 时,replica 将向 master 发送之前保存的 RUN ID。
- 如果 replica RUN ID 和 master RUN ID 一致,说明 replica 断线前复制的就是当前的 master,master 尝试执行增量更新。若不一致,说明 replica 断线前复制的 master 并不是当前的 master,则 master 将对 replica 执行全量更新。
- 复制偏移量 offset(64 位的整数且一直累加):
- master 和 offset 都会维护一个复制偏移量;master 向 replica 发送 N 个字节的数据时,将自己的复制偏移量加上 N,replica 接收到 master 发送的 N 个字节的数据时,将自己的复制偏移量加上 N。
- 如果 replica 记录的复制偏移量在环形缓冲区中,就将 master 中的数据偏移和 replica 的数据偏移之间的数据发给 replica(增量更新)。
- 如果 replica 记录的复制偏移量不在环形缓冲区中,就把 master 中的 rdb 数据发给 replica(全量更新)。
- 通过比较主从偏移量得知主从之间数据是否一致;偏移量相同则数据一致,偏移量不同则数据不一致。
复制偏移量越大,数据越新。
哨兵模式

- 哨兵模式是 redis 高可用的解决方案:
- 由一个或多个 sentinel 实例构成 sentinel 集群,该集群可以监视任意多个主库以及这些主库所属的从库;当主库处于下线状态,会自动将该主库所属的某个数据最新的从库升级为新的主库。
- 客户端连接集群时,首先会连接 sentinel(任意一个 sentinel),通过 sentinel 来查询主库的地址(ip 地址 + 端口),并且通过 subscribe 监听主库切换,然后再连接主库进行数据交互。
- 当主库发生故障时,sentinel 会主动推送新的主库地址。这样客户端无须重启即可自动完成节点切换。
- 检测异常
- 主观下线:sentinel 会以每秒一次的频率向所有节点(其他 sentinel、主节点、从节点)发送 ping 消息,然后通过接收返回判断该节点是否下线;如果配置指定了 down-after-milliseconds,则在该时间内没有返回就被判断为主观下线。
- 客观下线:当一个 sentinel 节点将一个主节点判断为主观下线之后,为了确
认这个主节点是否真的下线,它会向其他 sentinel 节点进行询问,如果收到一定数量(半数以上)的已下线回复,sentinel 会将主节点判定为客观下线,并通过领头 sentinel 节点对主节点执行故障转移。 - 故障转移:
- 在从节点中选举一个节点作为新的主节点(选复制偏移量最大的从节点)。
- 通知其他从节点复制连接新的主节点。
- 若故障主节点重新连接,将作为新的主节点的从节点。
- 缺点:
- 延迟较大:redis 采用异步复制的方式,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息将会丢失。如果主从延迟特别大,那么丢失可能会特别多。
- 不能进行数据扩容。
- 部署麻烦。
- 配置
# sentinel.cnf # sentinel 只需指定检测主节点就行了,通过主节点自动发现从节点 sentinel monitor mymaster 127.0.0.1 6379 2 # 判断主观下线时长 sentinel down-after-milliseconds mymaster 30000 # 指定可以有多少个 redis 服务同步新的主机,一般而言,这个数字越小同步时间越长; 越大,则对网络资源要求越高 sentinel parallel-syncs mymaster 1 # 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为 3分钟 sentinel failover-timeout mymaster 180000
cluster 集群

- 实现高可用
- 数据备份:每个主节点都会有多个从节点。
- 主节点转移:集群节点间会互相发送消息,交换节点的状态信息;若某主节点下线,将会被其它节点标记下线,接着在该下线主节点的从节点中选择一个数据最新的从节点作为主节点;从节点继承下线主节点的槽位信息,并广播改消息给集群中的其它节点。
- 特征:
- 去中心化:没有中心节点。
- 主节点对等。
- 能够进行数据扩容。
- 读写数据只会通过主节点进入集群。
- 流程:
- 连接集群中任意一个节点。
- 若数据不在该节点,将收到连接切换的命令,继而连接到目标节点。
- 缺点:因为主从采用异步复制,在主节点转移时仍存在数据丢失的情况。
- 配置集群

# 创建 6 个文件夹
mkdir -p 7001 7002 7003 7004 7005 7006
cd 7001
vi 7001.conf
# 7001.conf 中的内容如下
pidfile "/home/zcoder/redis-cluster/7001/7001.pid"
logfile "/home/zcoder/redis-cluster/7001/7001.log"
dir /home/zcoder/redis-cluster/7001/
port 7001
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
# 复制配置
cp 7001/7001.conf 7002/7002.conf
cp 7001/7001.conf 7003/7003.conf
cp 7001/7001.conf 7004/7004.conf
cp 7001/7001.conf 7005/7005.conf
cp 7001/7001.conf 7006/7006.conf
# 查看目录结构
tree .
# 修改配置
sed -i 's/7001/7002/g' 7002/7002.conf
sed -i 's/7001/7003/g' 7003/7003.conf
sed -i 's/7001/7004/g' 7004/7004.conf
sed -i 's/7001/7005/g' 7005/7005.conf
sed -i 's/7001/7006/g' 7006/7006.conf
#!/bin/bash
# 创建启动配置 start.sh
redis-server 7001/7001.conf
redis-server 7002/7002.conf
redis-server 7003/7003.conf
redis-server 7004/7004.conf
redis-server 7005/7005.conf
redis-server 7006/7006.conf
# 增加可执行权限
chmod +x start.sh
# 启动全部 redis 节点
./start.sh
# 查看 redis 节点是否全部启动
ps aux | grep redis-server
# 智能创建 redis 集群
# --cluster-replicas: 一个主节点对应几个从节点
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
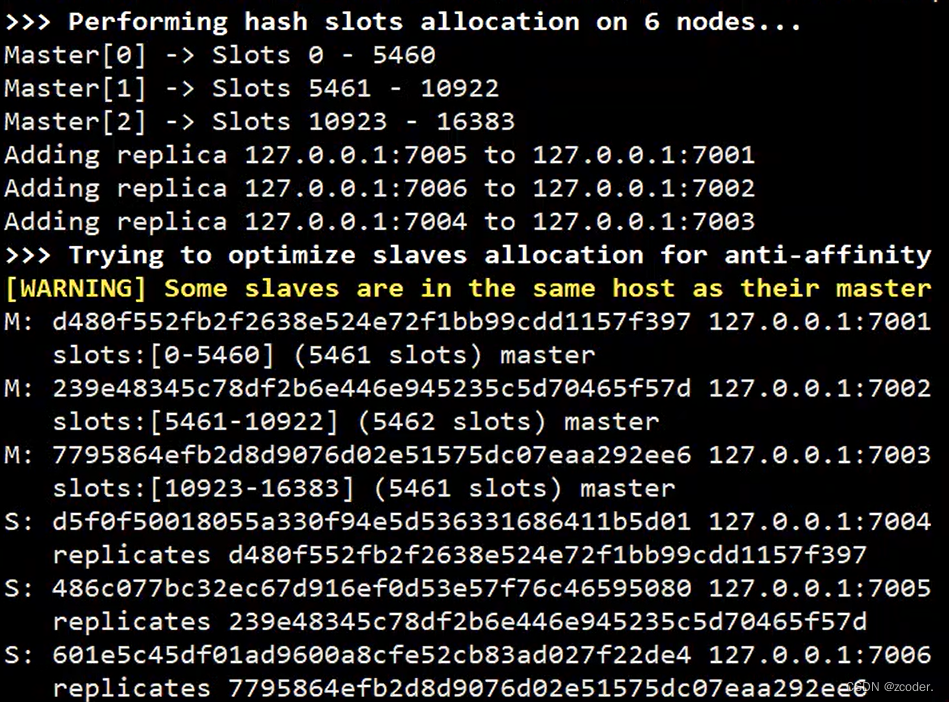
# 读写数据只会通过主节点进入集群
# 进入指定的 redis 节点
redis-cli -c -p 7006 # 127.0.0.1:7006
set zcoder 1 # 会重定向到存储该数据的主节点
# 主节点宕机
redis-cli -p 7001 shutdown
# 主节点重启
redis-server 7001/7001.conf
- 使用 crc16(zcoder) % 16384,通过增大样本数,让各个主节点存储的数据量较为均衡。

- 扩容:先增加节点,再分配槽位。
cp -R 7001 7007 cd 7007 mv 7001.conf 7007.conf rm 7001.log dump.rdb nodes-7001.conf sed -i "s/7001/7007/g" 7007.conf cp -R 7007 7008 cd 7008 mv 7007.conf 7008.conf sed -i "s/7007/7008/g" 7008.conf cd .. redis-server 7007/7007.conf redis-server 7008/7008.conf # 7007 是主节点,7008 是从节点 redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id 主节点的id # 将槽位重新分配到整个集群的所有节点中 redis-cli --cluster reshard 127.0.0.1:7001 How many slots do you want to move (from 1 to 16384)? #1000 What is the receiving node ID? # 主节点的id Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node # all # 将节点 A 的槽位迁移到节点 B redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 节点A的id --cluster-to 节点B的id --cluster-slots 1000 - 缩容:先移动槽位,再删除节点
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 节点B的id --cluster-to 节点A的id --cluster-slots 1000 # 删除节点 7007 redis-cli --cluster del-node 127.0.0.1:7001 节点7007的id # 此时 7008 成为其他节点的从节点 redis-cli --cluster del-node 127.0.0.1:7001 节点7008的id