文章目录
- 1.1 概述
- 1.1.1 Parser
- 1.1.2 分析仪/分析器
- 1.1.3 Rewriter
- 1.1.4 Planner和Executer
- 1.2 单表查询的成本估算
- 1.2.1 顺序扫描
- 1.2.2 索引扫描
- 1.2.3 排序
- 1.3 .创建单表查询的计划树
- 1.3.1 预处理
- 1.3.2 获取最便宜的访问路径
- 示例1
- 示例二
- 1.3.3 创建计划树
- 示例1
- 例二
- 1.4 EXECUTOR的执行方式
- 1.5 JOIN操作
- 1.5.1 嵌套循环连接NestLoop join
- 图3.18.索引嵌套循环连接。 下面显示了索引嵌套循环连接的一个具体示例。 1 2 3 4 5 6 7 8 testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id; QUERY PLAN
- 图3.19.嵌套循环的三种变体通过外部索引扫描连接。 这些连接的结果如下所示。 (a)带外索引扫描的嵌套循环连接 testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_mergejoin TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id = 500; QUERY PLAN
- Nested Loop (cost=0.29..93.81 rows=1 width=16) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..8.30 rows=1 width=8) Index Cond: (id = 500) -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1 width=8) Filter: (id = 500) (5 rows) (二)带外索引扫描的物化嵌套循环连接 testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_mergejoin TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id < 40 AND b.id < 10; QUERY PLAN
- Nested Loop (cost=0.29..99.76 rows=1 width=16) Join Filter: (c.id = b.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..8.97 rows=39 width=8) Index Cond: (id < 40) -> Materialize (cost=0.00..85.55 rows=9 width=8) -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=9 width=8) Filter: (id < 10) (7 rows) (三)带外索引扫描的索引嵌套循环连接 testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_mergejoin TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_d AS d WHERE a.id = d.id AND a.id < 40; QUERY PLAN
- 图3.20.合并连接。 如果所有元组都可以存储在内存中,那么排序操作将能够在内存中进行,否则将使用临时文件。 下面显示了合并连接的一个具体示例。 1 2 3 4 5 6 7 8 9 10 11 12 13 testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND b.id < 1000; QUERY PLAN
- 图3.21.物化合并连接。 显示了物化合并连接结果的示例,很容易看出与上面的合并连接结果的区别是第9行:'物化'。 1 2 3 4 5 6 7 8 9 10 11 12 13 testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id; QUERY PLAN
- 图3.22.使用外部索引扫描的merge join的三种变体。 这些连接的结果如下所示。 (一)合并连接与外部索引扫描 testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_nestloop TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 1000; QUERY PLAN
- Merge Join (cost=135.61..322.11 rows=1000 width=16) Merge Cond: (c.id = b.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8) -> Sort (cost=135.33..137.83 rows=1000 width=8) Sort Key: b.id -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8) Filter: (id < 1000) (7 rows) (b)带外索引扫描的物化合并连接 testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_nestloop TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 4500; QUERY PLAN
- Merge Join (cost=421.84..672.09 rows=4500 width=16) Merge Cond: (c.id = b.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8) -> Materialize (cost=421.55..444.05 rows=4500 width=8) -> Sort (cost=421.55..432.80 rows=4500 width=8) Sort Key: b.id -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=4500 width=8) Filter: (id < 4500) (8 rows) (c)带外索引扫描的索引合并连接 testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_nestloop TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_d AS d WHERE c.id = d.id AND d.id < 1000; QUERY PLAN
- testdb-# WHERE a.bid = b.bid AND a.aid BETWEEN 100 AND 1000; QUERY PLAN
- 例如,在嵌套循环连接中,估计有7条连接路径,第一条表示外层路径为tbl_a,内层路径为tbl_b的顺序扫描路径;第二条表示外层路径为tbl_a的顺序扫描路径,内层路径为tbl_b的物化顺序扫描路径。以此类推。 规划器最终从估计的join路径中选择最便宜的访问路径,并将最便宜的路径添加到RelOptInfo {tbl_a,tbl_b}的路径列表中。如图3.33所示。 在这个例子中,如下面的结果所示,规划器选择了内表和外层表分别为tbl_b和tbl_c的哈希连接。 testdb=# EXPLAIN SELECT * FROM tbl_b AS b, tbl_c AS c WHERE c.id = b.id AND b.data < 400; QUERY PLAN
1.1 概述
在PostgreSQL中,尽管9.6版本中实现的并行查询使用了多个后台工作进程,但一个后端进程基本上处理连接的客户端发出的所有查询。
解析器 Parser
解析器从明文的SQL语句生成解析树。
分析仪/分析仪 Analyzer
分析器/分析器对解析树进行语义分析,生成查询树。
重写器 Rewriter
重写器使用存储在规则体系rules
计划员 Planner
计划员从查询树中生成最有效执行的计划树。
执行者 Executor
执行器通过按照计划树创建的顺序访问表和索引来执行查询。
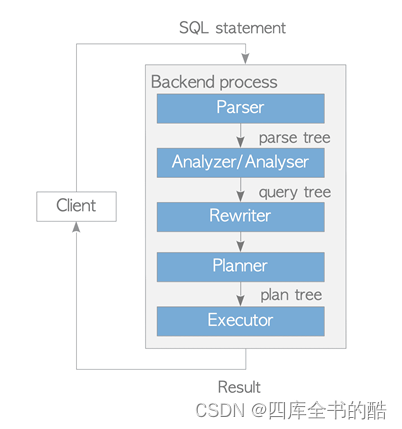
图3.1 查询过程
1.1.1 Parser
解析器从明文的SQL语句中生成一个可供后续子系统读取的解析树,这里是一个具体的例子,不做详细说明。
让我们考虑下面显示的查询。
testdb=# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;
解析树是指根节点为parsenode.h中定义的SelectStmt结构的树。.图3.2(b)说明了图3.2(a)所示查询的解析树。
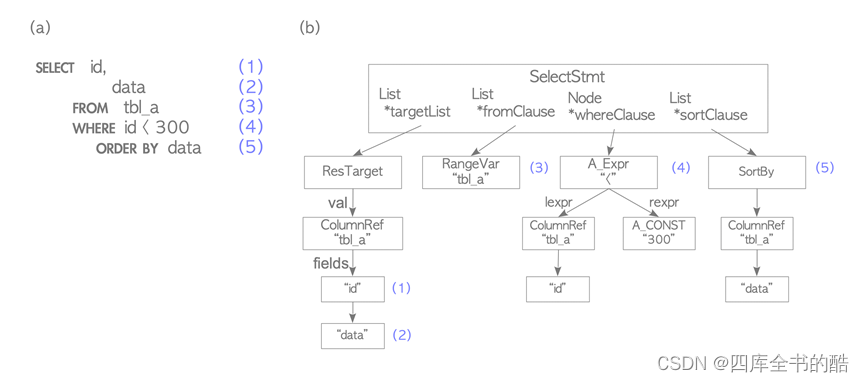
图3.2.解析树的一个示例
SELECT查询的元素和解析树的相应元素编号相同。例如,(1)是第一个目标列表的项,它是表的列’id’;(4)是WHERE子句;等等。
解析器在生成解析树时只检查输入的语法,因此,只有当查询中存在语法错误时,解析器才返回错误。
解析器不检查输入查询的语义。例如,即使查询包含不存在的表名,解析器也不会返回错误。语义检查由分析器/分析器完成。
1.1.2 分析仪/分析器
分析器/分析器对解析器生成的解析树进行语义分析,生成查询树。
查询树的根是parsenode.h中定义的查询结构。此结构体包含其相应查询的元数据,例如命令的类型(SELECT、INSERT或其他)和几个叶子。每个叶子构成一个列表或树,并保存单个特定子句的数据。
查询
图3.3展示了上一小节中图3.2(a)所示查询的查询树。
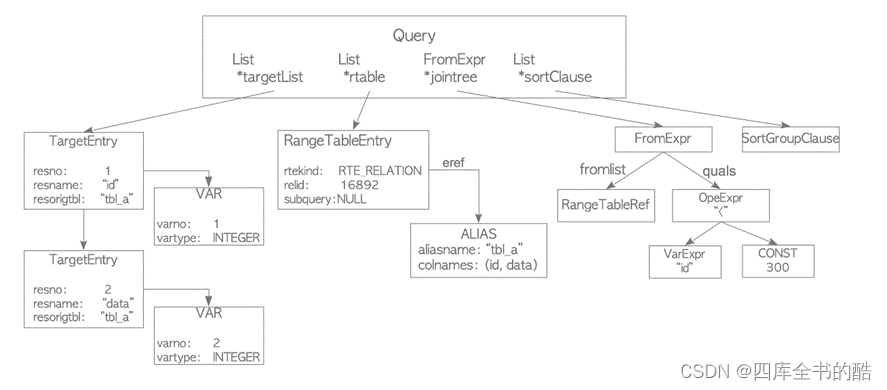
图3.3.查询树的一个示例。
上面的查询树简要描述如下:
• targetlist是作为此查询结果的列的列表。在此示例中,列表由两列组成:‘id’和’data’。如果输入查询树使用’∗∗’(星号),分析器/分析器将显式替换为所有列。
• 范围表是此查询中使用的关系列表。在此示例中,该列表保存表“tbl_a”的信息,例如OID和表的名称
• 连接树存储FROM子句和WHERE子句。
• sort子句是SortGroupClause的列表。
查询树的详细信息在The Query Tree.
1.1.3 Rewriter
重写器是实现规则体系rules.它根据存储在pg_ruler系统目录(如有必要)。规则系统本身就是一个有趣的系统,但为了防止本章太长,省略了对规则系统和重写器的描述。
视图及其规则系统在PostgreSQL中,使用规则系统来实现,当视图由创建视图命令,则相应的规则会自动生成并存储在目录中。
假设已经定义了以下视图,并且相应的规则存储在pg_rules系统目录:
sampledb=# CREATE VIEW employees_list
sampledb-# AS SELECT e.id, e.name, d.name AS department
sampledb-# FROM employees AS e, departments AS d WHERE e.department_id = d.id;
当发出包含如下所示视图的查询时,解析器会创建如图3.4(a)所示的解析树。
sampledb=# SELECT * FROM employees_list;
在这个阶段,重写器将范围表节点处理为子查询的解析树,即对应的视图,存储在pg_ruler.
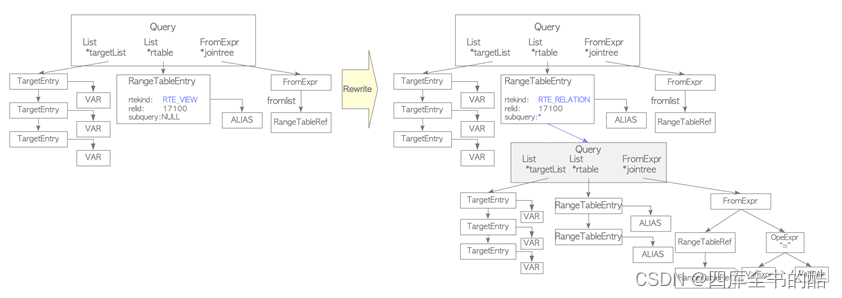
图3.4.重写阶段的一个例子。
由于PostgreSQL使用这样的机制来实现视图,所以视图直到9.2版本才可以更新。然而,从9.3版本开始,视图可以更新;尽管如此,更新视图还是有很多限制。
1.1.4 Planner和Executer
规划器接收来自重写器的查询树,并生成一个(查询)计划树,该计划树可以被执行器最有效地处理。
PostgreSQL中的规划器基于纯粹的基于成本的优化。它不支持基于规则的优化或提示。此规划器是PostgreSQL中最复杂的子系统。因此,本章后续章节将提供对规划器的概述。
pg_hint_plan
PostgreSQL不支持SQL中的计划器提示,而且它将永远不会被支持。如果你想在查询中使用提示,扩展引用pg_hint_plan将值得考虑。请参阅官方网站详细介绍
与其他RDBMS中一样,EXPLAIN PostgreSQL中的命令会显示计划树本身。具体示例如下所示:
testdb=# EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)
结果如图3.5所示的计划树。
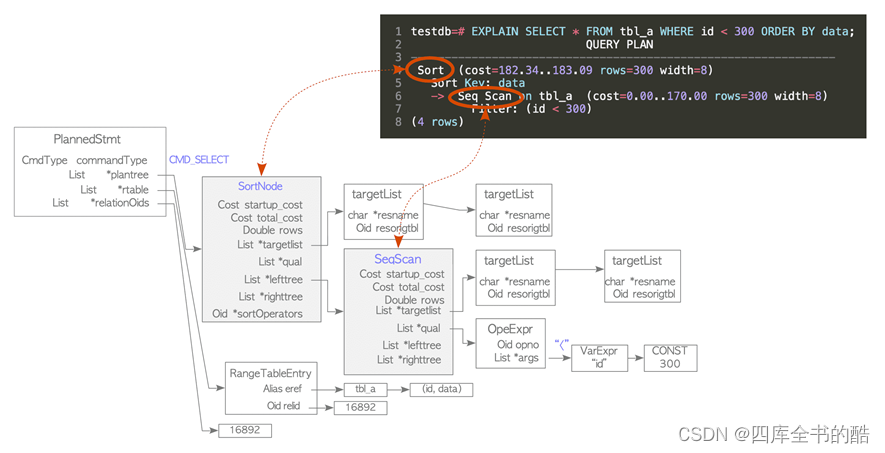
图3.5.一个简单的计划树,以及计划树和命令的结果之间的关系。
计划树由称为的元素组成计划节点,并且它连接到计划时间结构。这些元素定义在plannode.h.详情将在第3.3.3节(和)第3.5.4.2节).
每个计划节点都有执行器需要处理的信息,在单表查询的情况下,执行器从计划树的末尾到根进行处理。
例如,图3.5所示的计划树是一个排序节点和一个顺序扫描节点的列表,因此执行器扫描该表tbl_a通过顺序扫描,然后对得到的结果进行排序。
执行器通过中的缓冲区管理器对数据库集群中的表和索引进行读写。第8章.执行器在处理查询时,会使用一些提前分配的内存区域,如temp_buffers和work_mem,必要时创建临时文件。
此外,在访问元组时,PostgreSQL使用并发控制机制来保持运行事务的一致性和隔离性。第5章.
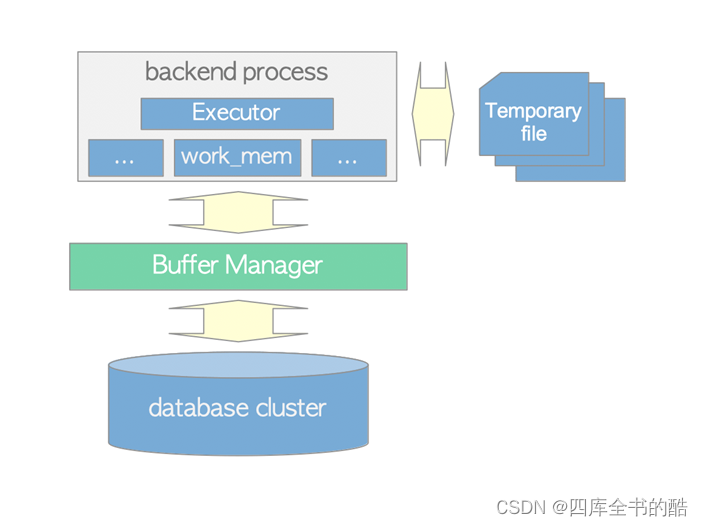
图3.6.执行器、缓冲区管理器和临时文件之间的关系。
1.2 单表查询的成本估算
PostgreSQL的查询优化是基于成本的。成本是无量纲值,它不是绝对的绩效指标,而是比较业务相对绩效的指标。
成本根据中定义的函数进行估算costsize.c.执行器执行的所有操作都有相应的代价函数,例如顺序扫描和索引扫描的代价分别通过cost_seqscan()和cost_index()来估算。
在PostgreSQL中,有三种成本:启动成本、运行成本和总成本,总成本是启动成本和运行成本的总和,所以只有启动成本和运行成本是独立估算的。
• 在启动cost是在获取第一个元组之前花费的开销。例如,索引扫描节点的启动开销是读取索引页以访问目标表中的第一个元组的开销。
• 在运行cost是获取所有元组的成本。
• 在总计成本是启动成本和运行成本的总和。
在EXPLAIN命令显示每个操作的启动成本和总成本。最简单的示例如下所示:
testdb=# EXPLAIN SELECT * FROM tbl;
QUERY PLAN
---------------------------------------------------------
Seq Scan on tbl (cost=0.00..145.00 rows=10000 width=8)
(1 row)
在第4行,命令显示有关顺序扫描的信息。在成本部分,有两个值;0.00和145.00。在本例中,启动成本和总成本分别为0.00和145.00。
在本节中,我们将详细探讨如何评估顺序扫描、索引扫描和排序操作。
在下面的说明中,我们将使用如下所示的特定表和索引:
testdb=# CREATE TABLE tbl (id int PRIMARY KEY, data int);
testdb=# CREATE INDEX tbl_data_idx ON tbl (data);
testdb=# INSERT INTO tbl SELECT generate_series(1,10000),generate_series(1,10000);
testdb=# ANALYZE;
testdb=# \d tbl
Table "public.tbl"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
data | integer |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
"tbl_data_idx" btree (data)
1.2.1 顺序扫描
顺序扫描的成本由cost_seqscan()函数估计。在本小节中,我们将探讨如何估计以下查询的顺序扫描成本:
testdb=# SELECT * FROM tbl WHERE id < 8000;
在顺序扫描中,启动成本等于0,运行成本由下式定义:
‘run cost’=‘cpu run cost’+‘disk run cost’=(cpu_tuple_cost+cpu_operator_cost)×Ntuple+seq_page_cost×Npage
其中seq_page_cost,cpu_tuple_cost和cpu_operator_cost在postgresql.conf文件中设置,默认值分别为1.0、0.01和0.0025。Ntuple和Npage分别是此表的所有元组的编号和所有页的编号。可以使用以下查询显示这些编号:
testdb=# SELECT relpages, reltuples FROM pg_class WHERE relname = 'tbl';
relpages | reltuples
----------+-----------
45 | 10000
(1 row)
Ntuple=10000 (1)
Npage =45 (2)
因此,
‘运行成本’=(0.01+0.0025)×10000+1.0×45=170.0
最后,
“总成本”=0.0+170.0=170“总成本”=0.0+170.0=170
为便于确认,上述查询的解命令的结果如下所示:
testdb=# EXPLAIN SELECT * FROM tbl WHERE id < 8000;
QUERY PLAN
--------------------------------------------------------
Seq Scan on tbl (cost=0.00..170.00 rows=8000 width=8)
Filter: (id < 8000)
(2 rows)
在第4行,我们可以看到启动和总成本分别为0.00和170.00,通过扫描所有行,估计将选择8000行(元组)。
在第5行,一个Filter:(id<8000)的顺序扫描。更准确地说,它被称为表级筛选器谓词.
需要注意的是,这种类型的过滤器是在读取表中的所有元组时使用的,它不会缩小表页的扫描范围。
提示信息
从运行成本估算可以理解,PostgreSQL假定所有页都将从存储中读取,换句话说,PostgreSQL不考虑扫描的页是否在共享缓冲区中。
1.2.2 索引扫描
虽然PostgreSQL支持一些索引方法,例如BTree,GIST,GIN和BRIN,索引扫描的开销是使用公共的开销函数cost_index()来估算的。
在本小节中,我们将探讨如何估计以下查询的索引扫描成本:
testdb=# SELECT id, data FROM tbl WHERE data < 240;
在估算成本之前,首先要确定索引页和索引元组的数量。
NIndex,page 和 Nindex,tuple,如下所示:
testdb=# SELECT relpages, reltuples FROM pg_class WHERE relname = 'tbl_data_idx';
relpages | reltuples
----------+-----------
30 | 10000
(1 row)
Nindex,page = 10000 (3)
Nindex,tuple = 3 (4)
启动成本
索引扫描的启动开销是读取索引页以访问目标表中的第一个元组的开销。它由以下等式定义:
'start-up cost'={ceil(log2(10000))+(1+1)×50}×0.0025=0.285 (5)
运行成本

其中:
• CPU-INDEX-TUPLE-COST和RANDOM-PAGE-COST在postgresql.conf文件中设置。默认值分别为0.005和4.0。
• qual_op_cost粗略地说,是评估索引谓词的成本。默认值为0.0025。
• Selectivity是满足WHERE子句的索引的搜索范围的百分比,它是一个从0到1的浮点数。
((Selectivity×Ntuple) 表示要读取的表元组数;
(Selectivity×Nindex,page)表示要读取的索引页数。
Selectivity详见以下
查询谓词的选择性是使用histogram_bounds或MCV(最常用值)来估计的,这两者都存储在pg_stats.
在此,通过具体的例子简要说明选择性的计算。
更多详细信息请参见公文.
表的每一列的MCV存储在pg_stats将视图视为名为“most_common_vals”和“most_common_freqs”的一对列:
• 'most_common_vals'是列中的MCV的列表。
• 'most_common_freqs'是MCV的频点列表。
下面是一个简单的示例:
表“国家/地区”有两列:
• a列“国家”:该列存储国家名称。
• a列“大陆”:该列存储国家所属的大洲名称。
国家
testdb=# \d countries
Table "public.countries"
Column | Type | Modifiers
-----------+------+-----------
country | text |
continent | text |
Indexes:
"continent_idx" btree (continent)
testdb=# SELECT continent, count(*) AS "number of countries",
testdb-# (count(*)/(SELECT count(*) FROM countries)::real) AS "number of countries / all countries"
testdb-# FROM countries GROUP BY continent ORDER BY "number of countries" DESC;
continent | number of countries | number of countries / all countries
---------------+---------------------+-------------------------------------
Africa | 53 | 0.274611398963731
Europe | 47 | 0.243523316062176
Asia | 44 | 0.227979274611399
North America | 23 | 0.119170984455959
Oceania | 14 | 0.0725388601036269
South America | 12 | 0.0621761658031088
(6 rows)
请考虑以下具有WHERE子句的查询,'大陆='亚洲'':
testdb=# SELECT * FROM countries WHERE continent = 'Asia';
在这种情况下,规划器使用“大陆”列的MCV估计索引扫描开销。此列的“most_common_vals”和“most_common_freqs”如下所示:
testdb=# \x
Expanded display is on.
testdb=# SELECT most_common_vals, most_common_freqs FROM pg_stats
testdb-# WHERE tablename = 'countries' AND attname='continent';
-[ RECORD 1 ]-----+-------------------------------------------------------------
most_common_vals | {Africa,Europe,Asia,"North America",Oceania,"South America"}
most_common_freqs | {0.274611,0.243523,0.227979,0.119171,0.0725389,0.0621762}
most_common_vals的'Asia'对应的most_common_freqs的值为0.227979。因此,在此估计中使用0.227979作为选择性。
如果不能使用MCV,例如,目标列类型是整数或双精度,则直方图_边界的目标列用于估计成本。
• 直方图_边界是一个值列表,它将列的值分成大致相等的组。
下面显示了一个具体的示例。这是表“tbl”中列“data”的histogram_bounds的值:
testdb=# SELECT histogram_bounds FROM pg_stats WHERE tablename = 'tbl' AND attname = 'data';
histogram_bounds
---------------------------------------------------------------------------------------------------
{1,100,200,300,400,500,600,700,800,900,1000,1100,1200,1300,1400,1500,1600,1700,1800,1900,2000,2100,
2200,2300,2400,2500,2600,2700,2800,2900,3000,3100,3200,3300,3400,3500,3600,3700,3800,3900,4000,4100,
4200,4300,4400,4500,4600,4700,4800,4900,5000,5100,5200,5300,5400,5500,5600,5700,5800,5900,6000,6100,
6200,6300,6400,6500,6600,6700,6800,6900,7000,7100,7200,7300,7400,7500,7600,7700,7800,7900,8000,8100,
8200,8300,8400,8500,8600,8700,8800,8900,9000,9100,9200,9300,9400,9500,9600,9700,9800,9900,10000}
(1 row)
默认情况下,直方图_bounds被划分为100个桶。图3.7显示了本例中的桶和对应的直方图_bounds。桶从0开始编号。并且每个桶存储(近似)相同数量的元组。histogram_bounds的值是对应桶的边界。例如,直方图边界的第0个值为1。表示它是存储在桶0中的元组的最小值,第一个值是100,这是存储在桶1中的元组的最小值,以此类推。

图3.7.桶和直方图_边界
接下来,将使用本小节中的示例显示选择性的计算。查询有WHERE子句’数据<240,值240在第二个桶中。在这种情况下,可以通过应用线性插值来推导选择性。因此,使用以下公式计算此查询中列“data”的选择性:

因此,根据(1)、(3)、(4)和(6),
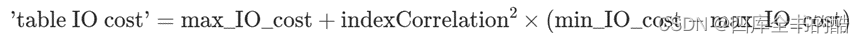
'table IO cost’由下式定义:
max_IO_cost是IO成本的最坏情况,即随机扫描所有表页的成本;该成本由下式定义:
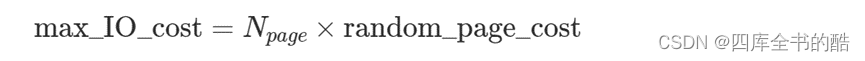
在这种情况下,根据(2),NP型一个克电子=45�P型一个克电子=45,因此
max_IO_cost=45×4.0=180.0 (10)
min_IO_cost是IO成本的最佳情况,即顺序扫描选定表页的成本;此成本由以下等式定义:
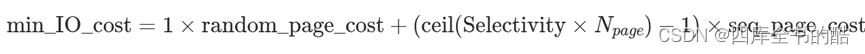
在这种情况下,
min_IO_cost=1×4.0+(脑电图(0.024×45))-1)×1.0=5.0(11)
indexCorrelation在中详细介绍了下面,在这个例子中,
indexCorrelation=1.0 (12)
因此,根据(10)、(11)和(12),
'table io cost '=180.0+1.02×(5.0-180.0)=5.0 (13)
最后,根据(7)、(8)、(9)和(13),
'运行成本'=(1.8+2.4)+(4.0+5.0)=13.2 (14)
索引相关性是物理行排序和列值逻辑排序之间的统计相关性(引用自官方文档)。范围从-1到+1。为了理解索引扫描和索引相关性之间的关系,下面给出一个具体的示例。
表“tbl_corr”有5列,其中2列是文本类型,3列是整数类型。这3个整数列存储从1到12的数字。每个页有四个元组,每个整数类型的列都有一个索引,其名称为index_col_asc等等。
testdb=# \d tbl_corr
Table "public.tbl_corr"
Column | Type | Modifiers
----------+---------+-----------
col | text |
col_asc | integer |
col_desc | integer |
col_rand | integer |
data | text |
Indexes:
"tbl_corr_asc_idx" btree (col_asc)
"tbl_corr_desc_idx" btree (col_desc)
"tbl_corr_rand_idx" btree (col_rand)
testdb=# SELECT col,col_asc,col_desc,col_rand
testdb-# FROM tbl_corr;
col | col_asc | col_desc | col_rand
----------+---------+----------+----------
Tuple_1 | 1 | 12 | 3
Tuple_2 | 2 | 11 | 8
Tuple_3 | 3 | 10 | 5
Tuple_4 | 4 | 9 | 9
Tuple_5 | 5 | 8 | 7
Tuple_6 | 6 | 7 | 2
Tuple_7 | 7 | 6 | 10
Tuple_8 | 8 | 5 | 11
Tuple_9 | 9 | 4 | 4
Tuple_10 | 10 | 3 | 1
Tuple_11 | 11 | 2 | 12
Tuple_12 | 12 | 1 | 6
(12 rows)
这些列的索引相关性如下所示:
testdb=# SELECT tablename,attname, correlation FROM pg_stats WHERE tablename = 'tbl_corr';
tablename | attname | correlation
-----------+----------+-------------
tbl_corr | col_asc | 1
tbl_corr | col_desc | -1
tbl_corr | col_rand | 0.125874
(3 rows)
当执行以下查询时,PostgreSQL只读取第一页,因为所有的目标元组都存储在第一页中,如图3.8(a)所示。
testdb=# SELECT * FROM tbl_corr WHERE col_asc BETWEEN 2 AND 4;
另一方面,当执行下面的查询时,PostgreSQL必须读取所有页,参见图3.8(b)。
testdb=# SELECT * FROM tbl_corr WHERE col_rand BETWEEN 2 AND 4;
这样,索引相关性是一种统计相关性,它反映了在估计索引扫描成本时,由于索引排序和表中物理元组排序不一致而导致的随机访问的影响。
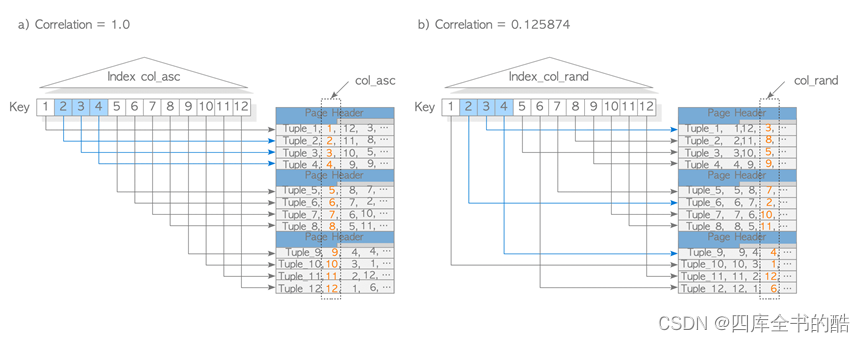
图3.8.指数相关性。
总成本
根据(3)和(14),
“总成本”=0.285+13.2=13.485 (15)
为便于确认,上述SELECT查询的parse命令的结果如下所示:
testdb=# EXPLAIN SELECT id, data FROM tbl WHERE data < 240;
QUERY PLAN
---------------------------------------------------------------------------
Index Scan using tbl_data_idx on tbl (cost=0.29..13.49 rows=240 width=8)
Index Cond: (data < 240)
(2 rows)
在第4行,我们可以发现,启动和总成本分别是0.29和13.49,估计要扫描240行(元组)。
在第5行,(data<240)的索引扫描。更准确地说,这种情况称为访问谓词它表示索引扫描的开始和停止条件。
索引条件
根据这个帖,PostgreSQL中的parse命令并不区分访问谓词和索引过滤谓词,因此,如果您分析该命令的输出,不仅要关注索引条件,还要关注行的估计值。
seq_page_cost和random_page_cost
的默认值seq_page_cost和random_page_cost分别为1.0和4.0。
这意味着PostgreSQL假定随机扫描比顺序扫描慢4倍,换句话说,PostgreSQL的默认值是基于使用HDD。
另一方面,最近一段时间,由于大部分使用SSD盘,所以random_page_cost的默认值过大,如果不使用SSD盘,仍然使用默认的random_page_cost会导致计划员选择无效的计划,所以在使用SSD盘的时候,最好将random_page_cost的值修改为1.0。
博客当使用random_page_cost的默认值时,报告了这个问题。
1.2.3 排序
排序路径用于排序操作,例如ORDER BY、合并连接操作的预处理和其他函数。使用cost_sort()函数估计排序的开销。
在排序操作中,如果所有待排序的元组都可以存放在work_mem中,则使用快速排序算法,否则创建一个临时文件,使用文件合并排序算法。
排序路径的启动开销是对目标元组进行排序的开销,因此,开销是O(Nsort×log2(Nsort)),其中Nsort是要排序的元组数。排序路径的运行开销是读取已排序的元组的开销。因此,开销为O(Nsort).
在本小节中,我们将探索如何估计以下查询的排序成本。假设此查询将在work_mem中排序,而不使用临时文件。
testdb=# SELECT id, data FROM tbl WHERE data < 240 ORDER BY id;
在这种情况下,启动成本定义为以下公式:
'start-up cost'=C+comparison_cost×Nsort×log2(Nsort)
其中:
• C是上次扫描的总成本,也就是索引扫描的总成本,根据(15),它是13.485。
• Nsort是要排序的元组数。在这种情况下,它是240。
• Comparison_cost在中定义2×cpu_operator_cost
因此,在启动成本启动成本计算如下:
“启动成本”=13.485+(2×0.0025)×240.0×log2(240.0)=22.973
在运行成本是读取内存中已排序元组的开销。
'运行成本'=cpu_operator_cost×Nsort=0.0025×240=0.6
最后,
“总成本”=22.973+0.6=23.573
为便于确认,上述SELECT查询的parse命令的结果如下所示:
testdb=# EXPLAIN SELECT id, data FROM tbl WHERE data < 240 ORDER BY id;
QUERY PLAN
---------------------------------------------------------------------------------
Sort (cost=22.97..23.57 rows=240 width=8)
Sort Key: id
-> Index Scan using tbl_data_idx on tbl (cost=0.29..13.49 rows=240 width=8)
Index Cond: (data < 240)
(4 rows)
在第4行,我们可以发现启动成本和总成本分别为22.97和23.57。
1.3 .创建单表查询的计划树
由于planner的处理比较复杂,本节介绍最简单的过程,即单表查询的计划树的创建过程,更复杂的过程,即多表查询的计划树的创建过程,请参见下文描述。
PostgreSQL中的planner执行三个步骤,如下所示:
- 进行预处理
- 通过估计所有可能的path的成本,得到最便宜的访问路径。
- 从最便宜的路径创建计划树。
path是估算成本的处理单位,例如顺序扫描、索引扫描、排序和各种连接操作都有其对应的路径,path仅在planner内部用于创建计划树。
访问路径最基本的数据结构是Path中定义的结构pathnode.h,它对应于顺序扫描,其他所有访问路径都是基于它的,后面会详细说明。
path
为了处理上述步骤,计划员在内部创建一个PlannerInfo结构,并保存查询树、有关查询中包含的关系的信息、访问路径等。
plannerInfo
在本节中,将通过具体的示例介绍如何从查询树创建计划树。
1.3.1 预处理
在创建计划树之前,planner会对存储在计划信息结构中的查询树进行一些预处理。
虽然预处理涉及到很多步骤,但在本小节中我们只讨论单表查询的主要预处理,其他预处理操作在下文
预处理步骤包括:
- 简化目标清单、限制条款等。
例如,eval_const_expressions()函数clauses.c将“2+2”重写为“4”。 - 规范化布尔表达式
例如,'NOT(NOT a)‘被重写为’a’。 - 扁平化AND/OR表达式。
SQL标准中的AND和OR是二元运算符,但在PostgreSQL内部,它们是n元运算符,并且planner始终假定所有嵌套的AND和OR表达式都要扁平化。
给出了一个具体的例子。考虑布尔表达式’(id=1)OR(id=2)OR(id=3)'。图3.9(a)显示了使用二元运算符时查询树的一部分。规划者通过使用三元运算符进行展平来简化这棵树。参见图3.9(b)。
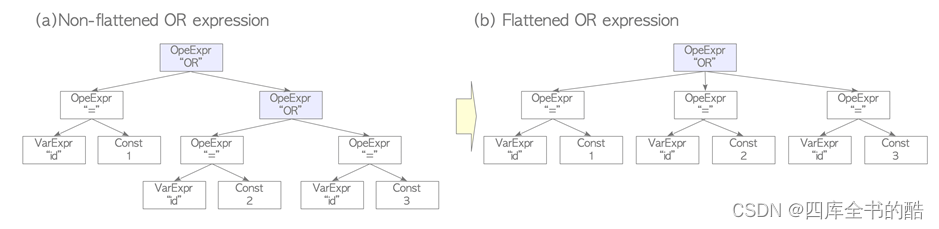
图3.9.一个扁平化AND/OR表达式的例子。
1.3.2 获取最便宜的访问路径
为了得到最便宜的访问路径,planner估计所有可能的访问路径的开销,并选择最便宜的访问路径。具体来说,planner执行以下操作:
- 创建一个RelOptInfo结构体来存储访问路径和相应的开销。
RelOptInfo结构由make_one_rel()函数创建,并存储在simple_rel_array参见图3.10。在其初始状态下,RelOptInfo持有基本限制信息和索引表if有相关索引.baserestrictinfo保存查询的WHERE子句,indexlist保存目标表的相关索引。
RelOptInfo - 估计所有可能的访问路径的开销,并将访问路径添加到RelOptInfo结构体中。
此处理的细节如下: - 创建一个路径,估计顺序扫描的开销,并将估计的开销写入该路径,然后将该路径添加到RelOptInfo结构的pathlist中。
- 如果目标表相关的索引存在,则创建索引访问路径,估计所有的索引扫描开销,并将估计开销写入路径中,然后将索引路径添加到路径列表中。
- 如果可以进行位图扫描,创建位图扫描路径,估计所有的位图扫描开销,并将估计开销写入路径,然后将位图扫描路径添加到路径列表中。
- 获取RelOptInfo结构的pathlist中最便宜的访问路径。
- 必要时估计Limit、ORDER BY和ARREGISFDD成本。
为了清楚地了解规划器的执行情况,下面给出两个具体的示例。
示例1
首先,我们探索一个没有索引的简单单表查询,该查询同时包含WHERE和ORDER BY子句。
testdb=# \d tbl_1
Table "public.tbl_1"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
data | integer |
testdb=# SELECT * FROM tbl_1 WHERE id < 300 ORDER BY data;
图3.10和3.11描述了规划器在此示例中的执行情况。
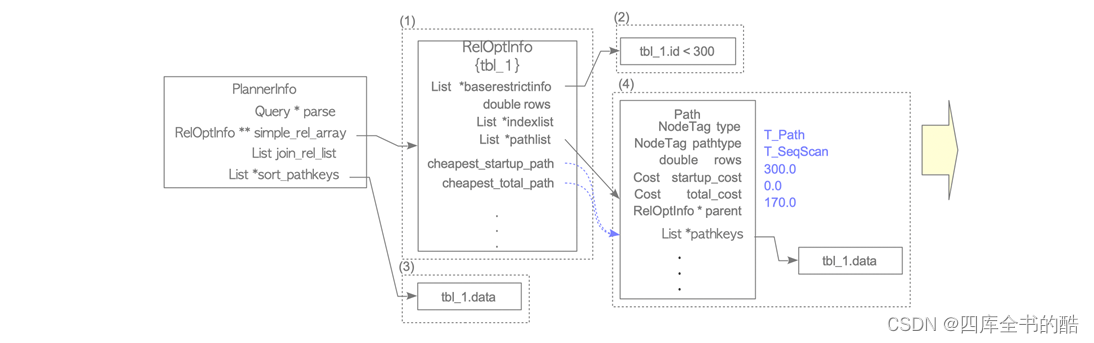
图3.10.如何得到示例1的最便宜路径
•(1)创建一个RelOptInfo结构体,并将其存储在PlannedInfo的simple_rel_array中。
• (2)在RelOptInfo的baserestrictinfo中添加WHERE子句。
WHERE子句’id<300’是由initsplan.c中定义的distribute_restrictinfo_to_rels()函数添加到baserestrictinfo中。另外,RelOptInfo的indexlist是NULL,因为目标表没有相关的索引。
• (3)通过planner.c.中定义的standard_qp_callback()函数,将用于排序的pathkey添加到PlannerInfo的sort_pathkeys中
Pathkey是表示路径的排序顺序的数据结构。在此示例中,列“data”作为路径键添加到sort_pathkeys中,因为查询包含ORDER BY子句且其列为“data”。
• (4)创建路径结构,使用cost_seqscan函数估算顺序扫描的开销,并将估算的开销写入路径中,然后通过pathnode.c.定义的add_path()函数将路径添加到RelOptInfo中
前面提到过,在Path结构体包含由cost_seqscan函数估计的启动成本和总成本,依此类推。
在这个例子中,由于没有目标表的索引,planner只估算了顺序扫描的开销,因此自动确定最便宜的访问路径。
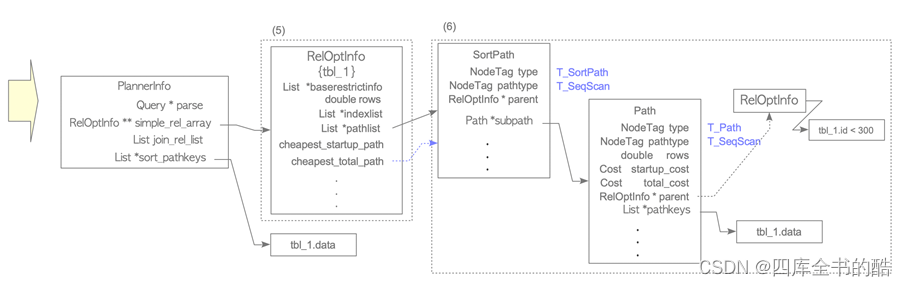
图3.11.如何获得示例1的最便宜路径。(接上图3.10)
• (5)创建一个新的RelOptInfo结构体来处理ORDER BY过程。
注意新的RelOptInfo没有baserestrictinfo,也就是WHERE子句的信息。
• (6)创建一个排序路径,并将其添加到新的RelOptInfo中,然后将顺序扫描路径链接到排序路径的子路径。
在SortPath结构由两个路径结构组成:path和subpath。path存储排序操作本身的信息,subpath存储排序操作的路径。
请注意,顺序扫描路径的项“父项”持有到旧的RelOptInfo的链接,该RelOptInfo将WHERE子句存储在其baserestrictinfo中。因此,在下一个阶段,即创建plan tree,planner可以创建包含WHERE子句的顺序扫描节点作为“过滤器”。即使新的RelOptInfo没有baserestrictinfo。
SortPath
根据这里得到的最便宜的访问路径,生成一个计划树。
示例二
接下来,我们将探索另一个具有两个索引的单表查询,该查询包含WHERE子句。
testdb=# \d tbl_2
Table "public.tbl_2"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
data | integer |
Indexes:
"tbl_2_pkey" PRIMARY KEY, btree (id)
"tbl_2_data_idx" btree (data)
testdb=# SELECT * FROM tbl_2 WHERE id < 240;
图3.12至3.14描述planner在此示例中的执行情况。
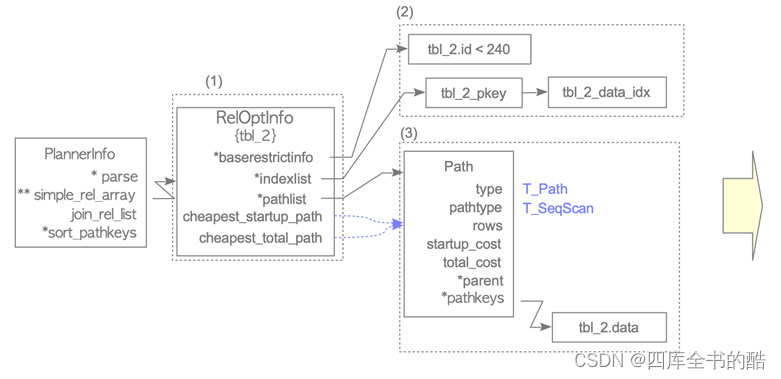
图3.12.如何获得示例2的最便宜路径。
• (1)创建一个RelOptInfo结构体。
• (2)在baserestrictinfo中添加WHERE子句,将目标表的索引添加到indexlist中。
在此示例中,WHERE子句’id<240’增加在baserestrictinfo中’,并增加了两个索引。tbl_2_pkey和tbl_2_数据IDx,被添加到RelOptInfo的indexlist中。
• (3)创建路径,估算顺序扫描的开销,并将路径添加到RelOptInfo的pathlist中。
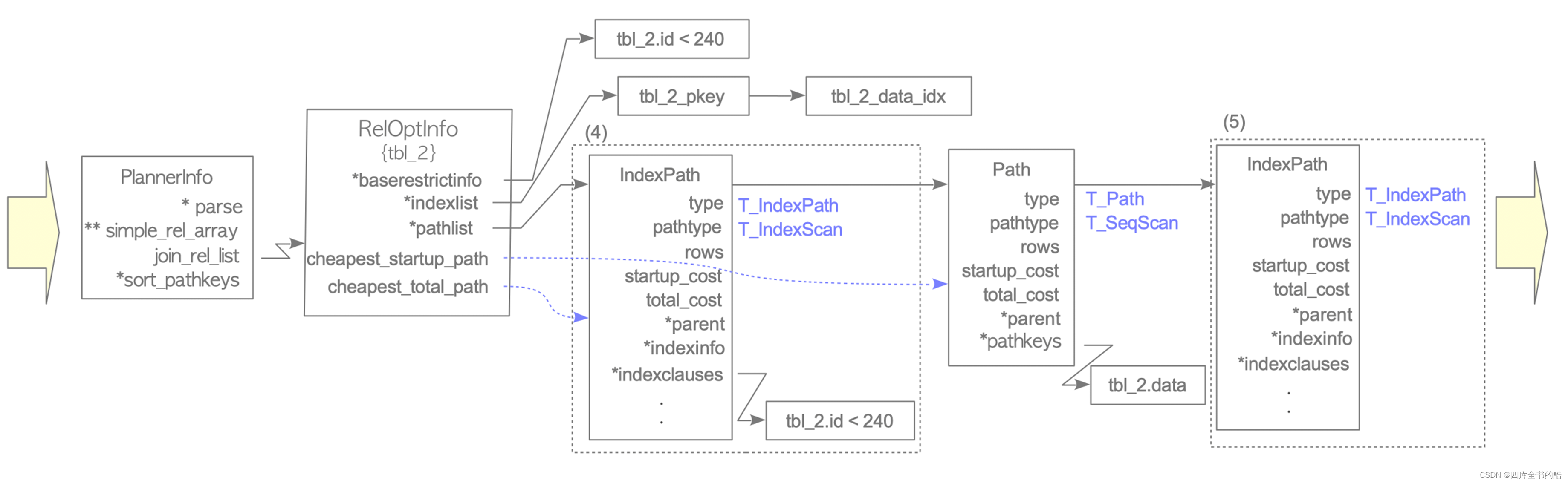
图3.13.如何获得示例2的最便宜路径。(接上图3.12)
• (四)创建一个IndexPath,估计索引扫描的开销,并使用add_path()函数将IndexPath添加到RelOptInfo的pathlist中。
在本例中,由于有两个索引,tbl_2_pkey和tbl_2_data_idx,这些索引将按顺序进行处理。tbl_2_pkey首先处理
为创建了一个IndexPath。tbl_2_pkey,并估算启动成本和总成本。在此示例中,tbl_2_pkey是与列“id”相关的索引,而WHERE子句包含列“id”;因此,WHERE子句存储在索引子句的IndexPath。
请注意,在向路径列表中添加访问路径时,add_path()函数按总成本的排序顺序添加路径。在此示例中,此索引扫描的总成本小于顺序总成本;因此,此索引路径被插入到顺序扫描路径之前。
indexPath
• (五)创建另一个IndexPath,估算其他索引扫描的开销,并将索引路径添加到RelOptInfo的pathlist中。
接下来,为创建一个IndexPath。tbl_2_数据IDx,估计开销,并将此IndexPath添加到路径列表中。在此示例中,没有与tbl_2_数据IDx索引;因此,索引子句为NULL。
注解
add_path()函数并不总是添加路径,由于该操作比较复杂,所以省略了细节,具体可以参考add_path()函数的注释。
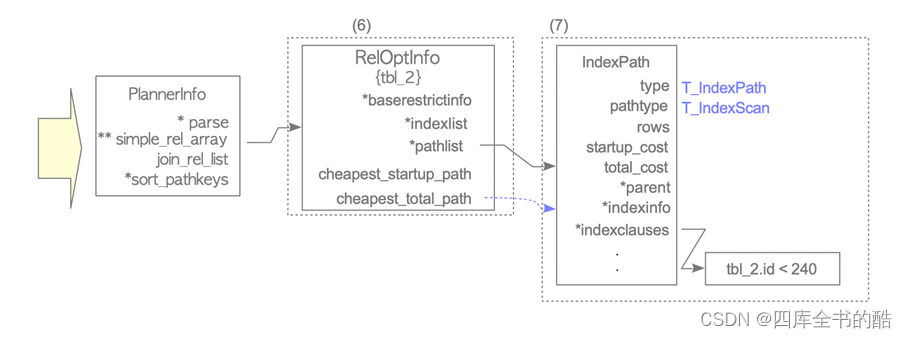
图3.14.如何获得示例2的最便宜路径。(接上图3.13)
• (六)创建一个新的RelOptInfo结构体。
• (7)将最便宜的路径添加到新的RelOptInfo的pathlist中。
在此示例中,最便宜的路径是使用索引的索引路径tbl_2_pkey;因此,它的路径被添加到新的RelOptInfo的路径列表中。
1.3.3 创建计划树
在最后一个阶段,planner根据最便宜的路径生成计划树。
计划树的根是一个PlannedStmt中定义的结构plannodes.h.它包含19个字段,但这里有4个代表性的字段:
• commandType存储一种操作类型,如SELECT、UPDATE或INSERT。
• rtable存储rangeTable表项。
• relationOids存储此查询的相关表的oid。
• plantree存储由计划节点组成的计划树,每个节点对应一个特定的操作,如顺序扫描、排序、索引扫描等。
如上文所述,计划树是由各种计划节点组成的。PlanNode结构是基本节点,其他节点总是包含它。例如,SeqScanNode用于顺序扫描,由一个PlanNode和一个整型变量“scanrelid”组成,一个PlanNode包含14个字段,下面是7个代表性的字段。
• 启动成本和总成本是该节点对应的操作的估计成本。
• rows是要扫描的行数,由规划器估计。
• targetlist存储查询树中包含的目标列表项。
• qual的是一个存储限定条件的列表。
• lefttree 和 righttree 是用于添加子节点的节点。
在下文中,将描述两个计划树,它们将从上一小节中的示例中显示的最便宜的路径生成。
示例1
第一个示例是中示例的planner。图3.11所示的路径是由排序路径和顺序扫描路径组成的树,根路径是排序路径,子路径是顺序扫描路径。
虽然省略了详细的解释,但是很容易理解,计划树几乎可以从最便宜的路径生成。
在这个例子中,一个SortNode在PlannedStmt结构的plantree中添加了一个SeqScanNode,在SortNode的左树中添加了一个SeqScanNode,如图3.15(a)所示。
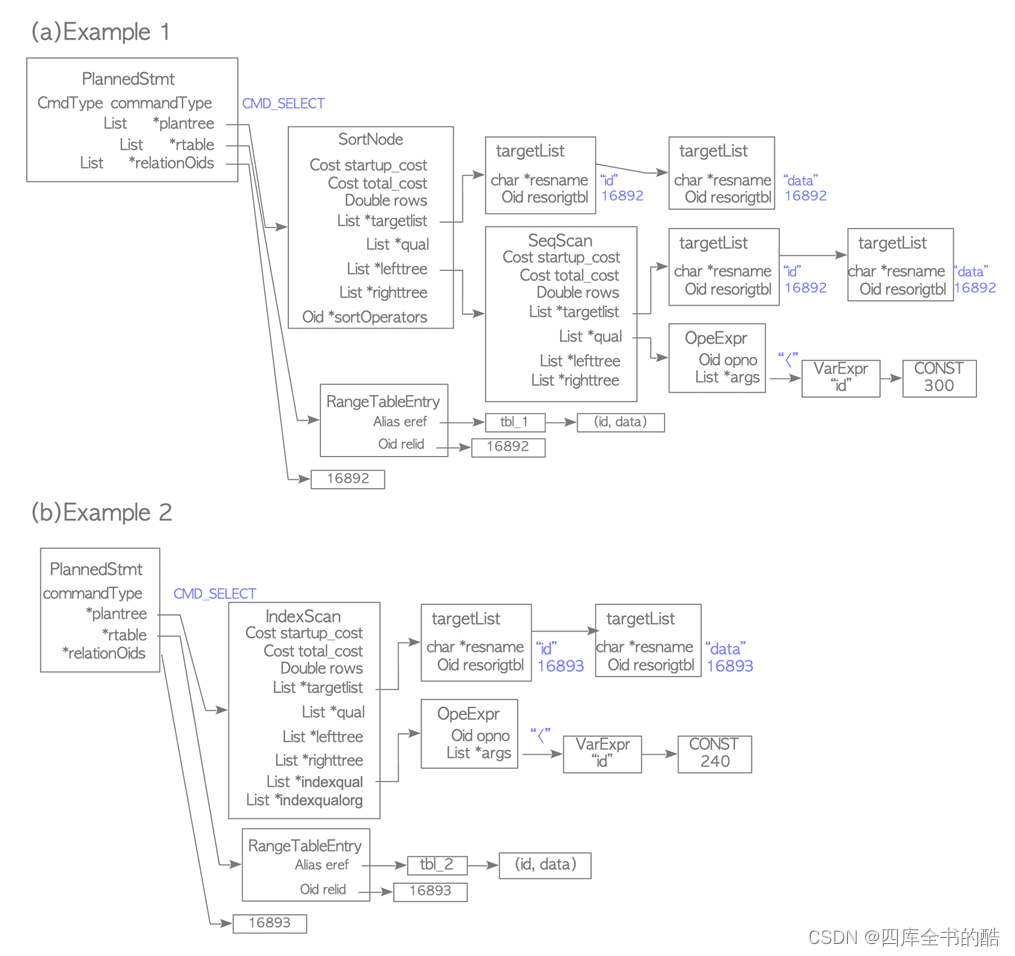
图3.15.计划树的例子。
在SortNode中,左树指向SeqScanNode。
在SeqScanNode中,qual保存WHERE子句’id<300’
例二
第二个示例是中示例的计划树图3.14所示的路径是索引扫描路径,因此计划树由IndexScanNode参见图3.15(b)。
索引扫描节点
在本例中,WHERE子句’id<240’是一个访问谓词,所以它存储在IndexScanNode的indexqual中。
1.4 EXECUTOR的执行方式
在单表查询中,执行器按照从计划树的末尾到根的顺序取出计划节点,然后调用执行相应节点处理的函数。
每个计划节点都有用于执行相应操作的函数。这些函数位于src/backend/executor/目录
例如,执行顺序扫描(ScanScan)的函数定义在nodeSeqscan.c;执行索引扫描(IndexScanNode)的函数定义在nodeIndexscan.c;对SortNode进行排序的函数定义在nodeSort.c等
当然,了解执行器执行情况的最好方法是读取命令的输出。PostgreSQL的CHARGE几乎是原样地显示计划树。它将使用中的示例1进行解释。
testdb=# EXPLAIN SELECT * FROM tbl_1 WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_1 (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)
让我们来探讨一下执行器是如何执行的。从最下面一行到最上面一行读取命令的执行结果。
• Line 6:首先,执行器使用中定义的函数执行顺序扫描操作nodeSeqscan.c.
• Line 4:接下来,执行器使用中定义的函数对顺序扫描的结果进行排序nodeSort.c
虽然executor使用work_men和temp_buffers(分配在内存中)进行查询处理,但是如果不能单独在内存中进行处理,它就会使用临时文件。
如果使用ANALYZE选项,则解命令实际执行查询,并显示实际的行计数、实际的运行时间和实际的内存使用情况。具体示例如下所示:
testdb=# EXPLAIN ANALYZE SELECT id, data FROM tbl_25m ORDER BY id;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Sort (cost=3944070.01..3945895.01 rows=730000 width=4104) (actual time=885.648..1033.746 rows=730000 loops=1)
Sort Key: id
Sort Method: external sort Disk: 10000kB
-> Seq Scan on tbl_25m (cost=0.00..10531.00 rows=730000 width=4104) (actual time=0.024..102.548 rows=730000 loops=1)
Planning time: 1.548 ms
Execution time: 1109.571 ms
(6 rows)
在第6行,可以看到执行器使用了一个临时文件,大小为10000kB。
临时文件临时建立在base/pg_tmp子目录下,命名方法如下:
{"pgsql_tmp"} + {PID of the postgres process which creates the file} . {sequencial number from 0}
例如,临时文件’pgsql_tmp8903.5’是postgres进程创建的第6个临时文件,pid为8903。
$ ls -la /usr/local/pgsql/data/base/pgsql_tmp*
-rw------- 1 postgres postgres 10240000 12 4 14:18 pgsql_tmp8903.5
1.5 JOIN操作
PostgreSQL支持三种连接操作:嵌套循环连接、合并连接和哈希连接,PostgreSQL中的嵌套循环连接和合并连接有几种变体。
在下文中,我们假设读者已经熟悉这三种连接的基本行为。
如果您不熟悉这些术语,请参阅参考资料:
参考文献
- 亚伯拉罕·西尔伯沙兹、亨利·F·科思和S·苏达山数据库系统概念",麦格劳-希尔教育,ISBN-13: 978-0073523323
- 托马斯·M·康诺利和卡罗琳·E·贝格数据库系统", Pearson, ISBN-13: 978-0321523068
但是,由于关于PostgreSQL支持的带倾斜的混合哈希连接并没有太多的解释,这里将进行更详细的解释。
章节内容
• 嵌套循环连接
• 合并联接
• 哈希连接
• 连接访问路径和连接节点
请注意,PostgreSQL支持的三种连接方法可以执行所有的连接操作,不仅可以执行内连接,还可以执行左/右外连接、全外连接等等。不过,为了简单起见,我们在本章中重点介绍内连接。
1.5.1 嵌套循环连接NestLoop join
嵌套循环连接是最基本的连接操作,它可以用于所有的连接条件,PostgreSQL支持嵌套循环连接及其五种变体。
嵌套循环连接
嵌套循环连接不需要任何启动操作,因此启动开销为0:
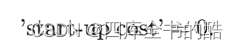
嵌套循环连接的运行成本与外部表和内部表的大小的乘积成正比。'e ‘run cost’=O(Nouter×Ninner),,其中Nouter 和 Ninner分别是外层表和内层表的元组数。更准确地说,运行成本由下式定义:
其中 Couter和Cinner分别是外层表和内层表的扫描开销。

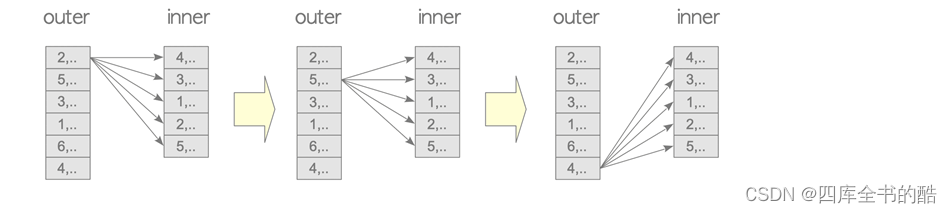
图3.16.嵌套循环连接。
嵌套循环连接的开销总是被估计出来的,但是这种连接操作很少被使用,因为通常会使用更高效的变体,下面将介绍这些变体。
物化嵌套循环连接
上面描述的嵌套循环连接必须在读取外部表的每个元组时扫描内部表的所有元组。由于为每个外部表元组扫描整个内部表是一个代价高昂的过程,PostgreSQL支持物化嵌套循环连接以减少内表的总扫描开销。
在运行嵌套循环连接之前,执行器将内部表元组写入work_mem或临时文件,方法是使用临时元组存储中描述的模块以下
这可能比使用缓冲区管理器更有效地处理内部表元组,特别是当至少所有元组都写入work_mem时。
图3.17说明了物化嵌套循环连接是如何执行的。扫描物化元组在内部调用重新扫描.
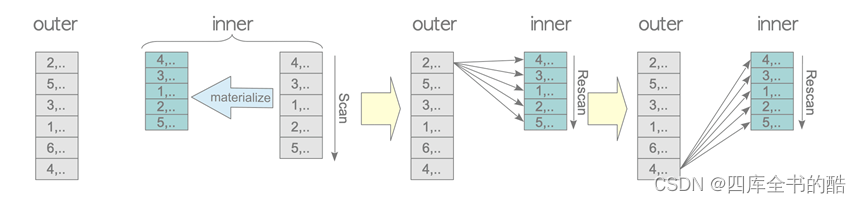
图3.17.物化嵌套循环连接。
PostgreSQL内部提供了一个临时元组存储模块,用于物化表,创建混合哈希连接中的批处理等。被定义在tuplestore.c。它们存储和从work_mem或临时文件读取一系列元组,决定是否使用work_mem或临时文件取决于要存储的元组的总大小。
我们将使用下面显示的具体示例来探索执行器如何处理物化嵌套循环连接的计划树,以及如何估算成本。
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id;
QUERY PLAN
-----------------------------------------------------------------------
Nested Loop (cost=0.00..750230.50 rows=5000 width=16)
Join Filter: (a.id = b.id)
-> Seq Scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..98.00 rows=5000 width=8)
-> Seq Scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
(5 rows)
首先显示执行器的操作,执行器对显示的计划节点进行如下处理:
• Line 7:执行器通过顺序扫描(第8行)将内表tbl_b物化。
• Line 4:执行器进行嵌套循环连接操作,外层表为tbl_a,内层表为物化tbl_b。
在下面的内容中,估计了“物化”(第7行)和“嵌套循环”(第4行)操作的开销。假设物化的内部元组存储在work_mem中。
物化:
启动没有成本,所以启动成本为0。
运行成本由以下公式定义:
因此,
‘运行成本’=2×0.0025×5000=25.0
此外,总成本是启动成本、顺序扫描总成本和运行成本之和:
因此,
“总成本”=(0.0+73.0)+25.0=98.0
(物化)嵌套循环:
启动没有成本,所以启动成本为0。
在估算运行成本之前,我们考虑重新扫描成本该成本由以下公式定义:
在这种情况下,
‘重新扫描成本’=(0.0025)×5000=12.5.
运行成本由以下公式定义:
其中
Ctotalouter,seqsca是外部表的总扫描成本,
Ctotalmaterialize是物化的总成本。因此,
‘运行成本’=(0.0025+0.01)×5000×10000+12.5×(10000-1)+145.0+98.0=750230.5.
索引嵌套循环连接
如果内表上有一个索引可以用来查找满足连接条件的外表每个元组的元组,那么规划器将考虑使用这个索引来直接查找内表元组,而不是顺序扫描。这种变化称为索引嵌套循环连接参见图3.18。尽管名称如此,该算法可以在一次循环中处理外层表的所有元组,因此它可以高效地执行连接操作。
图3.18.索引嵌套循环连接。
下面显示了索引嵌套循环连接的一个具体示例。
1
2
3
4
5
6
7
8
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id;
QUERY PLAN
Nested Loop (cost=0.29…1935.50 rows=5000 width=16)
-> Seq Scan on tbl_b b (cost=0.00…73.00 rows=5000 width=8)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29…0.36 rows=1 width=8)
Index Cond: (id = b.id)
(4 rows)
在第6行,显示了访问内部表的元组的开销,这是在该元组满足索引条件时,查找内部表的开销’(id=b.id) ',如第7行所示
在索引条件中’Id=b.id)'在第7行,'b.id’是连接条件中使用的外部表的属性的值。每当通过顺序扫描检索外部表的元组时,第6行中的索引扫描路径将查找要连接的内部元组。换句话说,每当外部表作为参数传递时。这个索引扫描路径查找满足连接条件的内部元组。这样的路径叫做parameterized (index) path…详情见自述文件.
此嵌套循环连接的启动开销等于第6行中索引扫描的开销;因此,
“启动成本”=0.285.
索引嵌套循环连接的总成本由以下等式定义:
其中
Ctotalinner,parameterized是参数化内部索引扫描的总成本。
在这种情况下,
“总成本”=(0.01+0.3625)×5000+73.0=1935.5
运行成本如下:
‘运行成本’=1935.5-0.285=1935.215.
如上所示,索引嵌套循环的总成本为O(Nouter).
其他变更
如果存在外层表的索引,且其属性参与连接条件,则可以使用该索引进行索引扫描,而不是外层表的顺序扫描。特别是,如果存在索引,其属性可以在WHERE子句中用作访问谓词。就缩小了外层表的搜索范围,这可以大大减少嵌套循环连接的开销。
PostgreSQL支持使用外部索引扫描的嵌套循环连接的三种变体,参见图3.19。
图3.19.嵌套循环的三种变体通过外部索引扫描连接。
这些连接的结果如下所示。
(a)带外索引扫描的嵌套循环连接
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_mergejoin TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id = 500;
QUERY PLAN
Nested Loop (cost=0.29…93.81 rows=1 width=16)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29…8.30 rows=1 width=8)
Index Cond: (id = 500)
-> Seq Scan on tbl_b b (cost=0.00…85.50 rows=1 width=8)
Filter: (id = 500)
(5 rows)
(二)带外索引扫描的物化嵌套循环连接
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_mergejoin TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id < 40 AND b.id < 10;
QUERY PLAN
Nested Loop (cost=0.29…99.76 rows=1 width=16)
Join Filter: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29…8.97 rows=39 width=8)
Index Cond: (id < 40)
-> Materialize (cost=0.00…85.55 rows=9 width=8)
-> Seq Scan on tbl_b b (cost=0.00…85.50 rows=9 width=8)
Filter: (id < 10)
(7 rows)
(三)带外索引扫描的索引嵌套循环连接
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_mergejoin TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_d AS d WHERE a.id = d.id AND a.id < 40;
QUERY PLAN
Nested Loop (cost=0.57…173.06 rows=20 width=16)
-> Index Scan using tbl_a_pkey on tbl_a a (cost=0.29…8.97 rows=39 width=8)
Index Cond: (id < 40)
-> Index Scan using tbl_d_pkey on tbl_d d (cost=0.28…4.20 rows=1 width=8)
Index Cond: (id = a.id)
(5 rows)
1.5.2 合并连接 merge join
与嵌套循环连接不同,合并连接只能用于natural joins和 equi-joins.
merge join的开销是通过initial_cost_mergejoin()和final_cost_mergejoin()函数来估算的。
具体的成本估计比较复杂,所以这里就省略了,我们只介绍合并连接算法的运行时顺序,合并连接的启动成本是内表和外表的排序成本之和,这意味着启动成本是O(Nouterlog2(Nouter)+Ninnerlog2(Ninner)),其中
Nouter和Ninner分别为外层表和内层表的元组数,运行开销为 O(Nouter+Ninner)
与嵌套循环连接类似,PostgreSQL中的合并连接有四种变体。
合并连接
图3.20显示了合并连接的概念图。
图3.20.合并连接。
如果所有元组都可以存储在内存中,那么排序操作将能够在内存中进行,否则将使用临时文件。
下面显示了合并连接的一个具体示例。
1
2
3
4
5
6
7
8
9
10
11
12
13
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND b.id < 1000;
QUERY PLAN
Merge Join (cost=944.71…984.71 rows=1000 width=16)
Merge Cond: (a.id = b.id)
-> Sort (cost=809.39…834.39 rows=10000 width=8)
Sort Key: a.id
-> Seq Scan on tbl_a a (cost=0.00…145.00 rows=10000 width=8)
-> Sort (cost=135.33…137.83 rows=1000 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00…85.50 rows=1000 width=8)
Filter: (id < 1000)
(9 rows)
• Line 9:执行器使用顺序扫描(第11行)对内表tbl_b进行排序。
• Line 6:执行器使用顺序扫描(第8行)对外层表tbl_a进行排序。
• Line 4:执行器进行merge join操作,外层表是排序后的tbl_a,内层表是排序后的tbl_b。
物化合并连接
和嵌套循环连接一样,合并连接也支持物化合并连接,将内表物化,使内表扫描更高效。
图3.21.物化合并连接。
显示了物化合并连接结果的示例,很容易看出与上面的合并连接结果的区别是第9行:‘物化’。
1
2
3
4
5
6
7
8
9
10
11
12
13
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id;
QUERY PLAN
Merge Join (cost=10466.08…10578.58 rows=5000 width=2064)
Merge Cond: (a.id = b.id)
-> Sort (cost=6708.39…6733.39 rows=10000 width=1032)
Sort Key: a.id
-> Seq Scan on tbl_a a (cost=0.00…1529.00 rows=10000 width=1032)
-> Materialize (cost=3757.69…3782.69 rows=5000 width=1032)
-> Sort (cost=3757.69…3770.19 rows=5000 width=1032)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00…1193.00 rows=5000 width=1032)
(9 rows)
• 第10行:执行器使用顺序扫描(第12行)对内表tbl_b进行排序。
• Line 9:执行器将排序后的tbl_b的结果物化。
• Line 6:执行器使用顺序扫描(第8行)对外层表tbl_a进行排序。
• Line 4:执行器进行合并连接操作,外层表是排序后的tbl_a,内层表是物化排序后的tbl_b。
其他变更
与嵌套循环连接类似,PostgreSQL中的合并连接也有基于的变体,可以进行外层表的索引扫描。
图3.22.使用外部索引扫描的merge join的三种变体。
这些连接的结果如下所示。
(一)合并连接与外部索引扫描
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_nestloop TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 1000;
QUERY PLAN
Merge Join (cost=135.61…322.11 rows=1000 width=16)
Merge Cond: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29…318.29 rows=10000 width=8)
-> Sort (cost=135.33…137.83 rows=1000 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00…85.50 rows=1000 width=8)
Filter: (id < 1000)
(7 rows)
(b)带外索引扫描的物化合并连接
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_nestloop TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 4500;
QUERY PLAN
Merge Join (cost=421.84…672.09 rows=4500 width=16)
Merge Cond: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29…318.29 rows=10000 width=8)
-> Materialize (cost=421.55…444.05 rows=4500 width=8)
-> Sort (cost=421.55…432.80 rows=4500 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00…85.50 rows=4500 width=8)
Filter: (id < 4500)
(8 rows)
(c)带外索引扫描的索引合并连接
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_nestloop TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_d AS d WHERE c.id = d.id AND d.id < 1000;
QUERY PLAN
Merge Join (cost=0.57…226.07 rows=1000 width=16)
Merge Cond: (c.id = d.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29…318.29 rows=10000 width=8)
-> Index Scan using tbl_d_pkey on tbl_d d (cost=0.28…41.78 rows=1000 width=8)
Index Cond: (id < 1000)
(5 rows)
1.5.3 哈希连接 Hash join
与合并连接类似,哈希连接只能用于自然连接和等价连接。
PostgreSQL中的哈希连接根据表的大小有不同的行为。如果目标表足够小(更准确地说,内部表的大小是work_mem的25%或更少),它将是一个简单的两阶段内存内哈希连接。否则,混合哈希连接与倾斜方法一起使用。
在本小节中,将介绍PostgreSQL中两种哈希连接的执行。
由于成本估算比较复杂,所以省略了讨论。粗略地说,如果假设搜索和插入哈希表时没有冲突,启动和运行成本是O(Nouter+Ninner)。
内存中哈希连接
在本小节中,将介绍内存中的哈希连接。
这种内存中的哈希连接在work_mem中处理,哈希表区域称为batch在PostgreSQL中,批处理具有哈希slots,内部称为buckets,桶的个数由nodeHash.c中定义的ExecChooseHashTableSize()函数决定。桶的数量始终为2n,其中n是一个整数
内存内哈希连接有两个阶段:build和probe.在build阶段,将内表的所有元组插入到batch中;在probe阶段,将外层表的每个元组与批处理中的内部元组进行比较,如果满足连接条件,则进行连接。
下面给出一个具体的例子来清楚地理解这个操作,假设下面显示的查询是使用哈希连接执行的。
testdb=# SELECT * FROM tbl_outer AS outer, tbl_inner AS inner WHERE inner.attr1 = outer.attr2;
下面展示了哈希连接的操作,请参阅图。3.23和3.24。
图3.23.内存中哈希连接的构建阶段。
• (一)在work_mem上创建批处理。
在本例中,该批次有8个桶,这意味着桶的数量为23.
• (二)将内表的第一个元组插入到批次的对应桶中。
具体如下:
- 计算连接条件中涉及的第一个元组的属性的hash-key。
在这个例子中,第一个元组的属性’attr1’的哈希键是使用内置的哈希函数计算的,因为WHERE子句是’inner.attr1=external.attr2’。 - 将第一个元组插入到对应的桶中。
假设第一个元组的hash-key为’0x000…001’用二进制表示法表示,即后三位为’001’,此时这个元组被插入到key为’001’的桶中。
在本文档中,用于构建批处理的插入操作由以下运算符表示:⊕
• (三)插入内表的剩余元组。
图3.24.内存中哈希连接中的探测阶段。
• (四)探测外层表的第一个元组。
具体如下:
- 计算外层表的连接条件中涉及的第一个元组的属性的哈希键。
在本例中,假设第一个元组的属性“attr2”的hash-key为“0x000”。100’,即后3位为‘100’。 - 将外部表的第一个元组与批处理中的内部元组进行比较,如果满足连接条件,则连接元组。
由于第一个元组的hash-key的后三位是“100”,因此执行器将检索属于键为“100”的桶的元组,并比较由连接条件(由WHERE子句定义)指定的表的各自属性的两个值。
如果满足连接条件,则将外部表的第一个元组和内部表的相应元组进行连接。否则,执行器什么也不做。
在本例中,key为’100’的桶中有Tuple_C。如果Tuple_C的attr1等于第一个元组(Tuple_W)的attr2,则Tuple_C和Tuple_W将被连接并保存到内存或临时文件中。
在本文档中,用于探测批处理的此类操作由操作员表示:⊗⊗
• (五)探测外层表的剩余元组。
带偏斜的混合哈希连接Hybrid Hash Join with Skew
当内部表的元组无法一次性存储在work_mem中时,PostgreSQL会使用带有倾斜算法的混合哈希连接,这是基于混合哈希连接的变体。
首先介绍混合哈希连接的基本概念,在第一个build和probe阶段,PostgreSQL会准备多个batch,batch的数量与桶的数量相同,由ExecChooseHashTableSize()函数决定,始终是2m,其中m是一个整数,在这个阶段,在work_mem中只分配了一个batch,其他batch被创建为临时文件,属于这些batch的元组被写入到相应的文件中,并使用临时元组存储特性保存。
图3.25说明了元组是如何在四个(=22)中存储的。在这种情况下,哪个batch存储每个元组是由元组的hash-key的后5位的前两位决定的,因为桶和批次的大小是23和33分别为.Batch_0存储hash-key的后5位在’00000’和’00111’之间的元组,Batch_1存储hash-key的后5位在’01000’和’01111’之间的元组,以此类推.
图3.25.混合哈希连接中的多个批次。
在混合哈希连接中,build和probe阶段的执行次数与批次数相同,因为内表和外表存储在相同的批次数中。在build和probe阶段的第一轮中,不仅每个batch都创建,而且内表和外表的第一批都会被处理。第二轮和后续轮次的处理需要写入和重新加载to/from临时文件,因此这些都是昂贵的过程。因此,PostgreSQL还准备了一个特殊的批处理,称为skew以在第一轮中更高效地处理许多元组。
skew批处理存储的是将与连接条件所涉及的属性的MCV值相对较大的外部表元组进行连接的内表元组,但是这个解释可能不太容易理解,下面将通过一个具体的例子来解释。
假设有两个表,一个是customer,一个是purchase_history。
• customer表有两个属性:‘name’和’address’。
• 购买历史表有两个属性:‘customer_name’和’purchased_item’。
• customer的表有10,000行,purchased_item表有1,000,000行。
• 排名前10%的客户购买了所有商品的70%。
在这些假设下,让我们考虑在执行下面所示的查询时,带有倾斜的混合哈希连接在第一轮中是如何执行的。
testdb=# SELECT * FROM customers AS c, purchase_history AS h WHERE c.name = h.customer_name;
如果客户表是内部表,而购买历史表是外部表,则使用购买历史表的MCV值将前10%的客户存储在倾斜批次中。请注意,参考外部表的MCV值将内部表元组插入到倾斜批次中。在第一轮的探测阶段,外层表的元组的70%(sort_history)将与倾斜批次中存储的元组连接,这样外层表的分布越不均匀,外层表的元组在第一轮可以处理的越多。
在下文中,显示了带倾斜的混合哈希连接的工作原理。请参阅图。3.26至3.29。
图3.26.第一轮混合哈希连接的构建阶段。
• (一)在work_mem上创建批处理和倾斜批处理。
• (二)创建存放内表元组的临时批处理文件。
在本例中,创建了三个批处理文件,因为内表将被划分为四个批处理。
• (三)对内表的第一个元组执行build操作。
具体描述如下:
- 如果应该将第一个元组插入到倾斜批处理中,请执行此操作。否则,执行2。
在上面解释的示例中,如果第一个元组是前10%的客户之一,则将其插入到倾斜批次中。 - 计算第一个元组的hash key,然后插入到对应的batch中。
• (四)对内表的剩余元组执行build操作。
图3.27.第一轮混合哈希连接的探测阶段。
• (五)创建存放外层表元组的临时批处理文件。
• (六)如果第一个元组的MCV值很大,则使用skew batch进行探测操作。否则,执行(七)。
在上面解释的示例中,如果第一个元组是前10%客户的购买数据,则将其与倾斜批次中的元组进行比较。
• (七)对第一个元组进行探测操作。
根据第一个元组的hash-key值,执行以下过程:
• 如果第一个元组属于Batch_0,则执行探测操作。
• 否则,插入到对应的批次中。
• (八)从外层表的剩余元组中执行探测操作。
请注意,在此示例中,外层表的元组的70%已经在第一轮中被倾斜处理,而没有对临时文件进行读写操作。
图3.28.第二轮的构建和探测阶段。
• (9)去掉歪斜的batch,清零Batch_0,准备第二轮。
• (10)从’'中的批处理文件’batch_1_'执行构建操作。
• (11)对存储在批处理文件’batch_1_out’中的元组执行探测操作。
图3.29.第三轮和最后一轮的构建和探测阶段。
• (12)使用批处理文件“batch_2_in”和“batch_2_out”执行构建和探测操作。
• (13)使用批处理文件“batch_3_in”和“batch_3_out”执行构建和探测操作。
哈希连接中的索引扫描
PostgreSQL中的Hash join尽可能使用索引扫描,具体示例如下所示。
testdb=# EXPLAIN SELECT * FROM pgbench_accounts AS a, pgbench_branches AS b
testdb-# WHERE a.bid = b.bid AND a.aid BETWEEN 100 AND 1000;
QUERY PLAN
Hash Join (cost=1.88…51.93 rows=865 width=461)
Hash Cond: (a.bid = b.bid)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.43…47.73 rows=865 width=97)
Index Cond: ((aid >= 100) AND (aid <= 1000))
-> Hash (cost=1.20…1.20 rows=20 width=364)
-> Seq Scan on pgbench_branches b (cost=0.00…1.20 rows=20 width=364)
(6 rows)
• Line 7在探测阶段,PostgreSQL在扫描pgbench_accounts表时使用了索引扫描,因为在WHERE子句中有一个索引的列’help’的条件。
1.5.4 Join Access Paths
The JoinPath structure is an access path for the nested loop join. Other join access paths, such as MergePath and HashPath, are based on it.
All join access paths are illustrated below, without explanation.
JoinPath
typedef JoinPath NestPath;
/*
-
JoinType -
-
enums for types of relation joins
-
JoinType determines the exact semantics of joining two relations using
-
a matching qualification. For example, it tells what to do with a tuple
-
that has no match in the other relation.
-
This is needed in both parsenodes.h and plannodes.h, so put it here…
/
typedef enum JoinType
{
/- The canonical kinds of joins according to the SQL JOIN syntax. Only
- these codes can appear in parser output (e.g., JoinExpr nodes).
/
JOIN_INNER, / matching tuple pairs only /
JOIN_LEFT, / pairs + unmatched LHS tuples /
JOIN_FULL, / pairs + unmatched LHS + unmatched RHS /
JOIN_RIGHT, / pairs + unmatched RHS tuples */
/*
- Semijoins and anti-semijoins (as defined in relational theory) do not
- appear in the SQL JOIN syntax, but there are standard idioms for
- representing them (e.g., using EXISTS). The planner recognizes these
- cases and converts them to joins. So the planner and executor must
- support these codes. NOTE: in JOIN_SEMI output, it is unspecified
- which matching RHS row is joined to. In JOIN_ANTI output, the row is
- guaranteed to be null-extended.
/
JOIN_SEMI, / 1 copy of each LHS row that has match(es) /
JOIN_ANTI, / 1 copy of each LHS row that has no match /
JOIN_RIGHT_ANTI, / 1 copy of each RHS row that has no match */
/*
- These codes are used internally in the planner, but are not supported
- by the executor (nor, indeed, by most of the planner).
/
JOIN_UNIQUE_OUTER, / LHS path must be made unique /
JOIN_UNIQUE_INNER / RHS path must be made unique */
/*
- We might need additional join types someday.
*/
} JoinType;
/*
- All join-type paths share these fields.
*/
typedef struct JoinPath
{
pg_node_attr(abstract)
Path path;
JoinType jointype;
bool inner_unique; /* each outer tuple provably matches no more
* than one inner tuple */
Path *outerjoinpath; /* path for the outer side of the join */
Path *innerjoinpath; /* path for the inner side of the join */
List *joinrestrictinfo; /* RestrictInfos to apply to join */
/*
* See the notes for RelOptInfo and ParamPathInfo to understand why
* joinrestrictinfo is needed in JoinPath, and can't be merged into the
* parent RelOptInfo.
*/
} JoinPath;
MergePath
/*
- A mergejoin path has these fields.
- Unlike other path types, a MergePath node doesn’t represent just a single
- run-time plan node: it can represent up to four. Aside from the MergeJoin
- node itself, there can be a Sort node for the outer input, a Sort node
- for the inner input, and/or a Material node for the inner input. We could
- represent these nodes by separate path nodes, but considering how many
- different merge paths are investigated during a complex join problem,
- it seems better to avoid unnecessary palloc overhead.
- path_mergeclauses lists the clauses (in the form of RestrictInfos)
- that will be used in the merge.
- Note that the mergeclauses are a subset of the parent relation’s
- restriction-clause list. Any join clauses that are not mergejoinable
- appear only in the parent’s restrict list, and must be checked by a
- qpqual at execution time.
- outersortkeys (resp. innersortkeys) is NIL if the outer path
- (resp. inner path) is already ordered appropriately for the
- mergejoin. If it is not NIL then it is a PathKeys list describing
- the ordering that must be created by an explicit Sort node.
- skip_mark_restore is true if the executor need not do mark/restore calls.
- Mark/restore overhead is usually required, but can be skipped if we know
- that the executor need find only one match per outer tuple, and that the
- mergeclauses are sufficient to identify a match. In such cases the
- executor can immediately advance the outer relation after processing a
- match, and therefore it need never back up the inner relation.
- materialize_inner is true if a Material node should be placed atop the
- inner input. This may appear with or without an inner Sort step.
*/
typedef struct MergePath
{
JoinPath jpath;
List path_mergeclauses; / join clauses to be used for merge */
List outersortkeys; / keys for explicit sort, if any */
List innersortkeys; / keys for explicit sort, if any /
bool skip_mark_restore; / can executor skip mark/restore? /
bool materialize_inner; / add Materialize to inner? /
} MergePath;
HashPath
/
- A hashjoin path has these fields.
- The remarks above for mergeclauses apply for hashclauses as well.
- Hashjoin does not care what order its inputs appear in, so we have
- no need for sortkeys.
*/
typedef struct HashPath
{
JoinPath jpath;
List path_hashclauses; / join clauses used for hashing /
int num_batches; / number of batches expected /
Cardinality inner_rows_total; / total inner rows expected */
} HashPath;
Fig. 3.30. Join access paths.
1.5.5 Join Nodes
This subsection shows the three join nodes: NestedLoopNode, MergeJoinNode and HashJoinNode, without explanation. They are all based on the JoinNode.
JoinNode
/* ----------------
-
Join node - jointype: rule for joining tuples from left and right subtrees
- inner_unique each outer tuple can match to no more than one inner tuple
- joinqual: qual conditions that came from JOIN/ON or JOIN/USING
-
(plan.qual contains conditions that came from WHERE) - When jointype is INNER, joinqual and plan.qual are semantically
- interchangeable. For OUTER jointypes, the two are not interchangeable;
- only joinqual is used to determine whether a match has been found for
- the purpose of deciding whether to generate null-extended tuples.
- (But plan.qual is still applied before actually returning a tuple.)
- For an outer join, only joinquals are allowed to be used as the merge
- or hash condition of a merge or hash join.
- inner_unique is set if the joinquals are such that no more than one inner
- tuple could match any given outer tuple. This allows the executor to
- skip searching for additional matches. (This must be provable from just
- the joinquals, ignoring plan.qual, due to where the executor tests it.)
-
*/
typedef struct Join
{
pg_node_attr(abstract)
Plan plan;
JoinType jointype;
bool inner_unique;
List *joinqual; /* JOIN quals (in addition to plan.qual) */
} Join;
NestedLoopNode
/* ----------------
-
nest loop join node - The nestParams list identifies any executor Params that must be passed
- into execution of the inner subplan carrying values from the current row
- of the outer subplan. Currently we restrict these values to be simple
- Vars, but perhaps someday that’d be worth relaxing. (Note: during plan
- creation, the paramval can actually be a PlaceHolderVar expression; but it
- must be a Var with varno OUTER_VAR by the time it gets to the executor.)
-
*/
typedef struct NestLoop
{
Join join;
List nestParams; / list of NestLoopParam nodes */
} NestLoop;
typedef struct NestLoopParam
{
pg_node_attr(no_equal, no_query_jumble)
NodeTag type;
int paramno; /* number of the PARAM_EXEC Param to set */
Var *paramval; /* outer-relation Var to assign to Param */
} NestLoopParam;
MergeJoinNode
/* ----------------
-
merge join node - The expected ordering of each mergeable column is described by a btree
- opfamily OID, a collation OID, a direction (BTLessStrategyNumber or
- BTGreaterStrategyNumber) and a nulls-first flag. Note that the two sides
- of each mergeclause may be of different datatypes, but they are ordered the
- same way according to the common opfamily and collation. The operator in
- each mergeclause must be an equality operator of the indicated opfamily.
-
*/
typedef struct MergeJoin
{
Join join;
/* Can we skip mark/restore calls? */
bool skip_mark_restore;
/* mergeclauses as expression trees */
List *mergeclauses;
/* these are arrays, but have the same length as the mergeclauses list: */
/* per-clause OIDs of btree opfamilies */
Oid *mergeFamilies pg_node_attr(array_size(mergeclauses));
/* per-clause OIDs of collations */
Oid *mergeCollations pg_node_attr(array_size(mergeclauses));
/* per-clause ordering (ASC or DESC) */
int *mergeStrategies pg_node_attr(array_size(mergeclauses));
/* per-clause nulls ordering */
bool *mergeNullsFirst pg_node_attr(array_size(mergeclauses));
} MergeJoin;
HashJoinNode
/* ----------------
-
hash join node -
*/
typedef struct HashJoin
{
Join join;
List *hashclauses;
List *hashoperators;
List *hashcollations;
/*
* List of expressions to be hashed for tuples from the outer plan, to
* perform lookups in the hashtable over the inner plan.
*/
List *hashkeys;
} HashJoin;
1.6 创建多表查询计划树
在本节中,我们将介绍多表查询的planner tree创建过程。
1.6.1 预处理
Planner.c中定义的subquery_planner()函数调用预处理.本小节将介绍多表查询的预处理,但由于有很多,所以只介绍部分部分。
- 规划和转换CTE
如果有WITH列表,计划器将通过SS_process_ctes()函数处理每个WITH查询。 - 上拉子查询
如果FROM子句具有子查询,并且它不具有GROUP BY、HASH、ORDER BY、LIMIT或INTERSECT子句,并且它也不使用INTERSECT或SELECTION子句,则planner将通过pull_up_subqueries()函数转换为连接形式。
例如,下面显示的在FROM子句中包含子查询的查询可以转换为自然连接查询。不用说,这种转换是在查询树中完成的。
testdb=# SELECT * FROM tbl_a AS a, (SELECT * FROM tbl_b) as b WHERE a.id = b.id;
⇓⇓
testdb=# SELECT * FROM tbl_a AS a, tbl_b as b WHERE a.id = b.id; - 将外部连接转换为内部连接
如果可能,规划器会将外连接查询转换为内连接查询。
1.6.2 获取最便宜的路径
为了得到最优的计划树,规划者必须考虑索引和连接方法的所有组合。这是一个非常昂贵的过程,如果由于组合爆炸而导致表的数量超过一定水平,这将是不可行的。幸运的是,如果表的数量小于12,规划者可以通过动态规划得到最优的规划方案,否则,规划者使用遗传算法.参考以下
遗传查询优化器
当执行连接多个表的查询时,将需要大量的时间来优化查询计划。为了处理这种情况,PostgreSQL实现了一个有趣的特性:遗传查询优化器.
这是一种在合理的时间内确定合理计划的近似算法,因此,在查询优化阶段,如果连接表的数量高于参数指定的阈值geqo_threshold(默认值为12),PostgreSQL使用遗传算法生成查询计划。
通过动态规划确定最优计划树可以通过以下步骤来解释:
• level=1
获取每个表的最便宜路径。最便宜的路径存储在相应的RelOptInfo中。
• level=2
获取两个表的每个组合的最便宜路径。
例如,如果有两个表,A和B,则得到表A和表B的连接路径,这是最终的答案。
下面用{A,B}表示两张表的RelOptInfo。
如果有三个表,则获取{A,B},{A,C},{B,C}中每个表的最便宜路径。
• level=3及以上
继续相同的过程,直到达到等于表数的级别。
通过这种方法,在每个层次上得到局部问题的最便宜路径,并用于上层的计算,从而使得高效地计算最便宜的计划树成为可能。
图3.31.如何使用动态规划获得最便宜的访问路径。
下面将介绍规划器如何获取以下查询的最便宜计划的过程。
testdb=# \d tbl_a
Table “public.tbl_a”
Column | Type | Modifiers
--------±--------±----------
id | integer | not null
data | integer |
Indexes:
“tbl_a_pkey” PRIMARY KEY, btree (id)
testdb=# \d tbl_b
Table “public.tbl_b”
Column | Type | Modifiers
--------±--------±----------
id | integer |
data | integer |
testdb=# SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND b.data < 400;
一级处理
在level 1中,规划器创建一个RelOptInfo结构,并为查询中的每个关系估计最便宜的成本。RelOptInfo结构被添加到该查询的规划器信息的simple_rel_array中。
图3.32.Level 1处理后的PlannedInfo和RelOptInfo。
tbl_a的RelOptInfo有三个访问路径,添加到RelOptInfo的pathlist中,每个访问路径都链接到一个开销最便宜的路径:最便宜的启动(成本)路径、的最便宜的总(开销)路径、以及最便宜的参数化(开销)路径.最便宜的启动路径和总成本路径是显而易见的,因此将描述最便宜的参数化索引扫描路径的开销。
规划器考虑使用参数化路径进行索引嵌套循环连接(很少使用带有外部索引扫描的索引合并连接)。最便宜的参数化开销是估计的参数化路径的最便宜的开销。
tbl_b的RelOptInfo只有顺序扫描访问路径,因为tbl_b没有相关的索引。
3.6.2.2.二级处理
在第2级中,创建一个RelOptInfo结构体,并将其添加到规划器信息的join_rel_list中,然后估计所有可能的join路径的开销,并确定最佳的访问路径,其总开销是最便宜的。RelOptInfo将最佳的访问路径存储为最便宜的总成本路径,如图3.33所示。
图3.33.Level 2处理后的PlannedInfo和RelOptInfo。
表3.1显示了此示例中连接访问路径的所有组合。此示例的查询是等连接类型,因此估计了所有三种连接方法。为了方便起见,引入了访问路径的一些表示法:
• SeqScanPath(表)表示表的顺序扫描路径。
• 物化->SeqScanPath(表)表示表的物化顺序扫描路径。
• IndexScanPath(表,属性)是指通过a表的属性进行索引扫描的路径。
• ParameterizedIndexScanPath(表,属性1,属性2)是通过表的属性1参数化的索引路径,通过外层表的属性2参数化的索引路径。
表3.1:本例中所有join访问路径的组合
Outer Path Inner Path
Nested Loop Join
1 SeqScanPath(tbl_a) SeqScanPath(tbl_b)
2 SeqScanPath(tbl_a) Materialized->SeqScanPath(tbl_b) Materialized nested loop join
3 IndexScanPath(tbl_a,id) SeqScanPath(tbl_b) Nested loop join with outer index scan
4 IndexScanPath(tbl_a,id) Materialized->SeqScanPath(tbl_b) Materialized nested loop join with outer index scan
5 SeqScanPath(tbl_b) SeqScanPath(tbl_a)
6 SeqScanPath(tbl_b) Materialized->SeqScanPath(tbl_a) Materialized nested loop join
7 SeqScanPath(tbl_b) ParametalizedIndexScanPath(tbl_a, id, tbl_b.id) Indexed nested loop join
Merge Join
1 SeqScanPath(tbl_a) SeqScanPath(tbl_b)
2 IndexScanPath(tbl_a,id) SeqScanPath(tbl_b) Merge join with outer index scan
3 SeqScanPath(tbl_b) SeqScanPath(tbl_a)
Hash Join
1 SeqScanPath(tbl_a) SeqScanPath(tbl_b)
2 SeqScanPath(tbl_b) SeqScanPath(tbl_a)
例如,在嵌套循环连接中,估计有7条连接路径,第一条表示外层路径为tbl_a,内层路径为tbl_b的顺序扫描路径;第二条表示外层路径为tbl_a的顺序扫描路径,内层路径为tbl_b的物化顺序扫描路径。以此类推。
规划器最终从估计的join路径中选择最便宜的访问路径,并将最便宜的路径添加到RelOptInfo {tbl_a,tbl_b}的路径列表中。如图3.33所示。
在这个例子中,如下面的结果所示,规划器选择了内表和外层表分别为tbl_b和tbl_c的哈希连接。
testdb=# EXPLAIN SELECT * FROM tbl_b AS b, tbl_c AS c WHERE c.id = b.id AND b.data < 400;
QUERY PLAN
Hash Join (cost=90.50…277.00 rows=400 width=16)
Hash Cond: (c.id = b.id)
-> Seq Scan on tbl_c c (cost=0.00…145.00 rows=10000 width=8)
-> Hash (cost=85.50…85.50 rows=400 width=8)
-> Seq Scan on tbl_b b (cost=0.00…85.50 rows=400 width=8)
Filter: (data < 400)
(6 rows)
1.6.3 获取三表查询的最便宜路径
获取三张表的查询最便宜的路径
testdb=# \d tbl_a
Table “public.tbl_a”
Column | Type | Modifiers
--------±--------±----------
id | integer |
data | integer |
testdb=# \d tbl_b
Table “public.tbl_b”
Column | Type | Modifiers
--------±--------±----------
id | integer |
data | integer |
testdb=# \d tbl_c
Table “public.tbl_c”
Column | Type | Modifiers
--------±--------±----------
id | integer | not null
data | integer |
Indexes:
“tbl_c_pkey” PRIMARY KEY, btree (id)
testdb=# SELECT * FROM tbl_a AS a, tbl_b AS b, tbl_c AS c
testdb-# WHERE a.id = b.id AND b.id = c.id AND a.data < 40;
• 1级:
规划器估计所有表的最便宜路径,并将此信息存储在相应的RelOptInfo对象中:{tbl_a}、{tbl_b}和{tbl_c}。
• 2级:
规划器选取三个表对的所有组合,并估计每个组合的最便宜路径。然后将信息存储在相应的RelOptInfo对象中:{tbl_a, tbl_b}, {tbl_b, tbl_c}和{tbl_a, tbl_c}。
• 第3级:
规划器最终使用已经获取的RelOptInfo对象得到最便宜的路径。
更准确地说,规划器考虑了三个RelOptInfo对象的组合:{tbl_a, {tbl_b, tbl_c}}, {tbl_b, {tbl_a, tbl_c}和{tbl_a, {tbl_a, tbl_b},因为
{tbl_a,tbl_b,tbl_c}=min({tbl_a,{tbl_b,tbl_c}},{tbl_b,{tbl_a,tbl_c}},{tbl_c,{tbl_a,tbl_b}}).{tbl_a,tbl_b,tbl_c}=敏({tbl_a,{tbl_b,tbl_c}},{tbl_b,{tbl_a,tbl_c}},{tbl_c,{tbl_a,tbl_b}}).
然后,规划器估计其中所有可能的连接路径的成本。
在RelOptInfo onject {tbl_c, {tbl_a, tbl_b}}中,规划器估计tbl_c的所有组合和{tbl_a, tbl_b}的最便宜路径。在本例中,内表和外层表分别为tbl_a和tbl_b的哈希连接。
估计的连接路径将包含三种类型的连接路径及其变体,例如上一小节中显示的那些,即嵌套循环连接及其变体、合并连接及其变体和散列连接。
规划器对RelOptInfo对象{tbl_a, {tbl_b, tbl_c}和{tbl_a, {tbl_a, tbl_c}}进行相同的处理,最终在所有估计的路径中选择最便宜的访问路径。
下面显示了此查询的解命令的结果:
最外层连接是索引嵌套循环连接(第5行)。内层参数化索引扫描如第13行所示,外层关系是哈希连接的结果,其内外层表分别为tbl_b和tbl_a(第7-12行)。因此,执行器首先执行tbl_a和tbl_b的哈希连接,然后执行索引嵌套循环连接。