前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!
欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!
本文目录:
- 一、爬虫的基本概念
- 1.为什么要学习爬虫
- 1.1 数据的来源
- 1.2 爬取到的数据用途
- 2.什么是爬虫
- 3. 爬虫的更多用途
- 二、爬虫的分类和爬虫的流程
- 1.爬虫的分类
- 2.爬虫的流程
- 3.robots协议
- 小结
一、爬虫的基本概念
1.为什么要学习爬虫
如今,人工智能,大数据离我们越来越近,很多公司在开展相关的业务,但是人工智能和大数据中有一个东西非常重要,那就是数据,但是数据从哪里来呢?
首先我们来看下面这个例子:
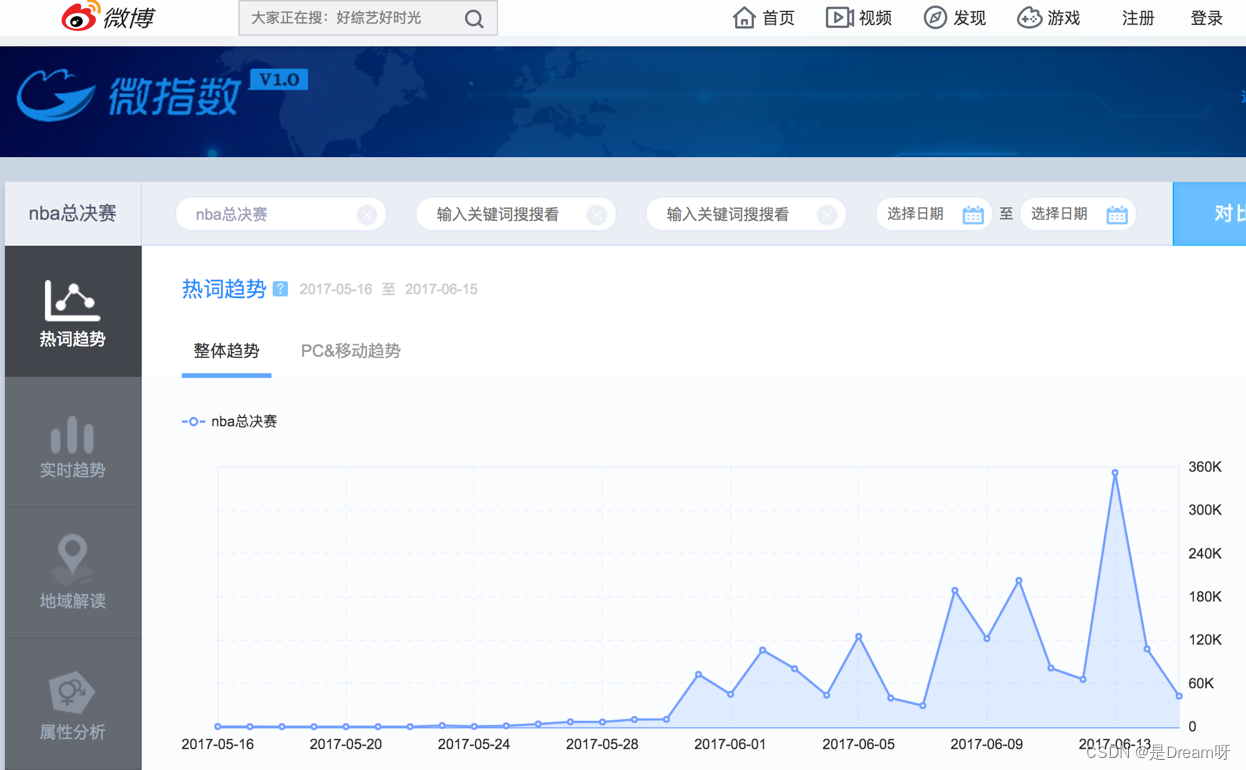
这是微博的微指数的一个截图,他把在微博上的用户的微博和评论中的关键词语做了提取,然后进行了统计,然后根据统计结果得出某个词语的流行趋势,之后进行了简单的展示
类似微指数的网站还有很多,比如百度指数,阿里指数,360指数等等,这些网站有非常大的用户量,他们能够获取自己用户的数据进行统计和分析
那么对于一些中小型的公司,没有如此大的用户量的时候,他们该怎么办呢?
1.1 数据的来源
- 去第三方的公司购买数据(比如企查查)
- 去免费的数据网站下载数据(比如国家统计局)
- 通过爬虫爬取数据
- 人工收集数据(比如问卷调查)
在上面的来源中:人工的方式费时费力,免费的数据网站上的数据质量不佳,很多第三方的数据公司他们的数据来源往往也是爬虫获取的,所以获取数据最有效的途径就是通过爬虫爬取
1.2 爬取到的数据用途
百度新闻,一家并不是做新闻的公司,这个网站上的新闻数据从哪里来的呢?

通过点击,我们可以发现,他的新闻数据都是其他网站上的,在百度新闻上仅仅做了展示
那么同样的,我们后续想要做一个和网易云音乐类似的音乐网站,是不是也可以这样来做呢?
*
通过前面的列子,能够总结出,爬虫获取的数据的用途:
- 进行在网页或者是app上进行展示
- 进行数据分析或者是机器学习相关的项目
2.什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做
3. 爬虫的更多用途
-
12306抢票
-
网站上的投票
-
短信轰炸
二、爬虫的分类和爬虫的流程
- 了解 爬虫分类
- 记忆 爬虫流程
- 了解 robots协议
1.爬虫的分类
在上一小结中,我们介绍
爬虫爬取到的数据用途的时候,给大家举了两个例子,其实就是两种不同类型的爬虫
根据被爬网站的数量的不同,我们把爬虫分为:
-
通用爬虫 :通常指搜索引擎的爬虫(https://www.baidu.com)
-
聚焦爬虫 :针对特定网站的爬虫
2.爬虫的流程
请思考:如果自己要实现一个和百度新闻一样的网站需要怎么做?
爬虫的工作流程:

- 向起始url发送请求,并获取响应
- 对响应进行提取
- 如果提取url,则继续发送请求获取响应
- 如果提取数据,则将数据进行保存
3.robots协议
在百度搜索中,不能搜索到淘宝网中某一个具体的商品的详情页面,这就是robots协议在起作用
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的一般约定
小结
- 爬虫分类:通用爬虫、聚焦爬虫
- 爬虫的流程:
- 向起始url发送请求,并获取响应
- 对响应进行提取
- 如果提取url,则继续发送请求获取响应
- 如果提取数据,则将数据进行保存
- robots协议:无需遵守该协议
❤️好啦,这就是今天要分享给大家的全部内容啦,如果你喜欢的话,就不要吝惜你的一键三连了~