🌈 博客个人主页:Chris在Coding
🎥 本文所属专栏:[高并发内存池]
❤️ 前置学习专栏:[Linux学习]
⏰ 我们仍在旅途

目录
2.高并发内存池整体架构
3.ThreadCache实现
3.1 ThreadCache整体架构
3.2 哈希桶映射规则的实现
内存对齐
下标计算
封装成SizeTable类
3.3 ThreadCache类
ThreadCache.h
FreeList类
allocate()
deallocate()
3.4 TLS无锁访问
3.5 对外提供申请内存
3.6 ThreadCache单元测试
2.高并发内存池整体架构
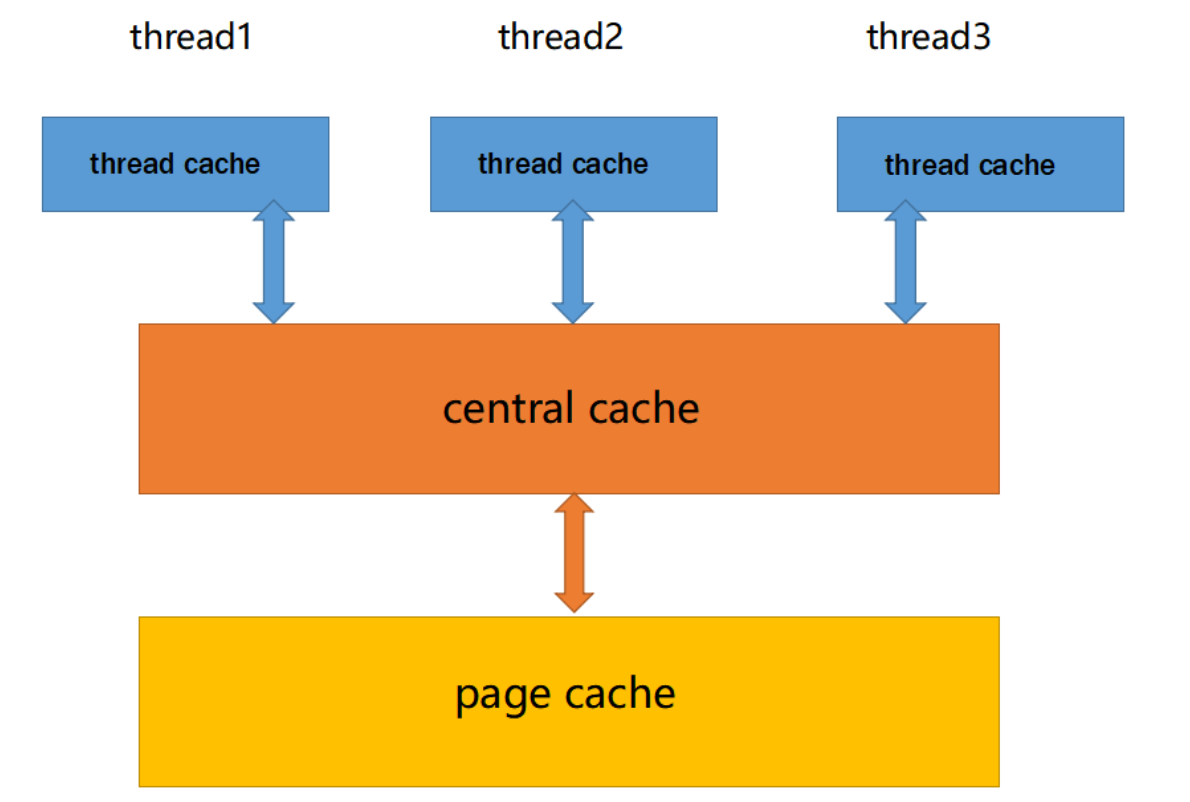
这个高并发内存池的设计是为了在多线程环境下有效地管理内存分配和回收,避免了频繁的锁竞争,提高了性能。以下是这个内存池的整体框架设计:
Thread Cache(线程缓存):
- 每个线程都有一个私有的线程缓存,用于小内存分配(小于等于256KB)。
- 线程在需要内存时,首先检查自己的线程缓存,无需加锁即可进行内存分配。
- 内存释放时也无需加锁,直接返回给线程缓存。
Central Cache(中心缓存):
- 所有线程共享的中心缓存,用于处理大内存分配需求。
- 当线程缓存无法满足内存需求时,线程会向中心缓存申请内存。
- 由于中心缓存是共享资源,访问时需要加锁,但采用哈希桶结构,只有在多个线程同时访问同一个桶时才需要加锁,降低了锁竞争的激烈程度。
Page Cache(页缓存):
- 以页为单位进行内存存储和分配,用于向中心缓存提供内存。
- 当中心缓存需要内存时,页缓存会分配一定数量的页给中心缓存。
- 当中心缓存中的内存满足一定条件时,页缓存会回收内存并尽可能地合并成更大的连续内存块,以减少内存碎片问题的发生。
整体框架设计保证了高并发环境下的内存管理效率和线程安全性。每个线程的私有线程缓存减少了锁竞争,而中心缓存的哈希桶结构和页缓存的内存合并机制则进一步减少了锁的争用,提高了整个内存池的并发处理能力。
3.ThreadCache实现
3.1 ThreadCache整体架构

哈希桶结构:
- Thread Cache 是一个哈希桶结构,每个哈希桶中存放一个空闲链表,用于管理不同大小的内存块。
- 哈希桶的数量可以根据需要进行调整,以适应内存块的大小范围。
对齐规则:
- thread cache支持小于等于256KB内存的申请,如果我们将每种字节数的内存块都用一个空闲链表进行管理的话,那么此时我们就需要20多万个空闲链表,光是存储这些空闲链表的头指针就需要消耗大量内存,这显然是得不偿失的,为了减少哈希桶的数量和节约内存空间,内存块的申请会按照一定的对齐规则进行处理。
- 例如,我们让这些字节数都按照8字节进行向上对齐,那么此时当线程申请1~8字节的内存时会直接给出8字节,而当线程申请9~16字节的内存时会直接给出16字节,以此类推。
内存块申请:
- 当线程要申请内存块时,根据所需大小经过对齐规则计算得到实际需要的字节数。
- 然后根据计算得到的字节数找到对应的哈希桶。
- 如果哈希桶中有可用内存块,则从空闲链表中头部获取一个内存块并返回。
- 如果哈希桶中的空闲链表为空,则需要向下一层的 Central Cache 请求内存块。
内存块释放:
- 当线程释放内存块时,根据内存块的大小找到对应的哈希桶。
- 将释放的内存块加入到哈希桶对应的空闲链表的头部,以便下次分配使用。
内存碎片:
- 由于对齐规则的存在,可能会导致部分内存块产生内部碎片,即多分配了一些不被利用的内存空间。
- 这些内部碎片会导致一定程度的空间浪费,但是通过对齐规则可以减少哈希桶数量,提高了内存管理的效率。
3.2 哈希桶映射规则的实现
这里我们创建一个Common.h来存放项目里面通用的类
内存对齐
对齐规则的目的是将不同大小的内存块按照一定的规则映射到哈希桶中,以降低哈希桶数量,节省内存空间,并减少对齐导致的内存浪费
但如果所有的字节数都按照8字节进行对齐的话,那么我们就需要建立32768(256 × 1024 ÷ 8)个桶,这个数量还是比较多的,实际上我们可以让不同范围的字节数按照不同的对齐数进行对齐,具体对齐方式如下:
| 字节数 | 对齐数 | 哈希桶下标 |
|---|---|---|
| [1,128] | 8 bytes | [0,16) |
| [128+1,1024] | 16 bytes | [16,72) |
| [1024+1,8*1024] | 128 bytes | [72,128) |
| [8*1024+1,64*1024] | 1024 bytes | [128,184) |
| [64*1024,256*1024] | 8*1024 bytes | [184,208) |
空间浪费率=对齐后的字节数 / 浪费的字节数
根据给定的对齐规则,我们可以计算每个区间的最大空间浪费率,然后对整体的空间利用率进行分析。
首先,我们列出每个区间的对齐规则以及计算最大空间浪费率的公式:
区间:1字节到128字节
- 对齐数:8字节
- 最大浪费率:7 ÷ 8 = 87.5%
区间:129字节到1024字节
- 对齐数:16字节
- 最大浪费率:15 ÷ 144 ≈ 10.42%
区间:1025字节到8 * 1024字节
- 对齐数:128字节
- 最大浪费率:127 ÷ 1152 ≈ 11.02%
区间:8 * 1024 + 1字节到64 * 1024字节
- 对齐数:1024字节
- 最大浪费率:1023 ÷ 9216 ≈ 11.10%
区间:64 * 1024 + 1字节到256 * 1024字节
- 对齐数:8 * 1024字节
- 最大浪费率:8191 ÷ 73728 ≈ 11.10%
根据计算,我们可以看出:
- 在1字节到128字节的区间中,最大浪费率为87.5%,浪费较为严重。
- 在其他区间中,最大浪费率均在10%左右,空间利用率较高。
综合来看,整体的空间利用率是比较高的,尤其是针对较大的内存块。但在小内存块的情况下,由于对齐规则会导致较大的内部碎片,空间利用率不够理想。
在处理对齐时,我们先判断该字节数属于哪一个区间,然后再通过调用同一个子函数进行进一步处理。
static size_t RoundUp(size_t bytes)
{
if (bytes <= 128)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 1024)
{
return _RoundUp(bytes, 16);
}
else if (bytes <= 8 * 1024)
{
return _RoundUp(bytes, 128);
}
else if (bytes <= 64 * 1024)
{
return _RoundUp(bytes, 1024);
}
else if (bytes <= 256 * 1024)
{
return _RoundUp(bytes, 8 * 1024);
}
else
{
assert(false);
return -1;
}
}此时我们就需要编写一个子函数,该子函数需要通过对齐数计算出某一字节数对齐后的字节数,最容易想到的就是下面这种写法。
static inline size_t _RoundUp(size_t bytes, size_t alignnum)
{
size_t alignSize = 0;
if (bytes % alignnum != 0)
{
alignSize = (bytes / alignnum + 1) * alignnum;
}
else
{
alignSize = bytes;
}
return alignSize;
}除了上述写法,我们还可以通过位运算的方式来进行计算,虽然位运算可能并没有上面的写法容易理解,但计算机执行位运算的速度是比执行乘法和除法更快的。
static inline size_t _roundup(size_t bytes, size_t alignnum)
{
return ((bytes + alignnum - 1) & ~(alignnum - 1));
}请注意,对于第两种方式,需要确保 alignnum 是 2 的幂次方,才能正确进行位运算。第一种方法是对齐的通用解法。
这里我们先看后半部分的式子,由于alignum也就是对齐数都是2的幂次方,此时在二进制下表示alignum一定是最高位为1,其余位置为0。这里以对齐数16为例,它在二进制下的表示为:
0000000000000000000000010000
那么当alignum-1后,它的二进制结果一定是原本的最高位变为0,后面的位置再变成1
0000000000000000000000001111
此时再对其取反~
11111111111111111111111111110000
此时再与别的数字&运算,结果就是该数字除以alignum的余数被清0,也就是向下对齐成alignum的整数倍 , 但是,由于我们需要的是将bytes向上对齐成alignum的整数倍,但当我们先(bytes + alignnum - 1)再向下对齐时,只要bytes不是alignnum的整数倍,都会被调整到下一个alignnum的倍数
下标计算
此时我们编写一个子函数来处理字节数在某个区间内的对齐后坐标,容易想到的就是下面的方法
static inline size_t _Index(size_t bytes, size_t alignnum)
{
size_t index = 0;
if (bytes % alignnum != 0)
{
index = bytes / alignnum;
}
else
{
index = bytes / alignnum - 1;
}
return index;
}当然,为了提高效率下面也提供了一个用位运算来解决的方法。 需要注意的是,此时我们并不是传入该字节数的对齐数,而是将对齐数写成2的n次方的形式后,将这个n值进行传入。所以对于第两种方式,仍需要确保 alignnum 是 2 的幂次方
static size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}当 align_shift 是指定的对齐数的对数形式时(例如,如果对齐数是 8,那么 align_shift 应该是 3,因为 8 是 2 的 3 次幂),此时满足:
alignnum = 1 << align_shift
此时式子就可以变成:
((bytes + alignnum - 1) >> align_shift) - 1;
这是我们可以参考原先向上对齐的式子来思考,原先的向上对齐的式子是在(bytes + alignnum - 1)的基础上把二进制下alignnum的最高位除外的后面位都置为0。而这里我们选择向右位移align_shift,其实本质上就是把alignnum的最高位除外的后面位都位移掉。这里我们就可以理解成先把后面位都置为0(也就是先向上对齐),然后>>align_shift就相当于除以alignnum。
这时我们会得到得结果就是bytes / alignnum向上取整得结果,当然这里由于坐标是从0开始计算的,我们还要减一。
在获取某一字节数对应的哈希桶下标时,也是先判断该字节数属于哪一个区间,然后再通过调用一个子函数进行进一步处理。这里要注意在计算当前区间坐标时,我们要减去上一个区间的最大值,在计算出当前区间的坐标后,还要加上前面的坐标总和。同时我们此时采用第二种子函数设计,所以传入的都是对齐数的幂次方数。
static size_t Index(size_t bytes)
{
assert(bytes <= MAXSIZE);
if (bytes <= 128)
{
return _Index(bytes, 3);
}
else if (bytes <= 1024)
{
return _Index(bytes-128, 4)+16;
}
else if (bytes <= 8 * 1024)
{
return _Index(bytes-1024, 7)+72;
}
else if (bytes <= 64 * 1024)
{
return _Index(bytes-8*1024, 10)+128;
}
else
{
return _Index(bytes-64*1024, 13)+184;
}
}封装成SizeTable类
这里我们在Common.h中封装一个SizeTable类,用来专门处理哈希桶映射规则
class SizeTable
{
public:
static inline size_t _RoundUp(size_t bytes, size_t alignnum)
{
return ((bytes + alignnum - 1) & ~(alignnum - 1));
}
static size_t RoundUp(size_t bytes)
{
if (bytes <= 128)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 1024)
{
return _RoundUp(bytes, 16);
}
else if (bytes <= 8 * 1024)
{
return _RoundUp(bytes, 128);
}
else if (bytes <= 64 * 1024)
{
return _RoundUp(bytes, 1024);
}
else if (bytes <= 256 * 1024)
{
return _RoundUp(bytes, 8 * 1024);
}
else
{
assert(false);
return -1;
}
}
static size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
static size_t Index(size_t bytes)
{
assert(bytes <= MAXSIZE);
if (bytes <= 128)
{
return _Index(bytes, 3);
}
else if (bytes <= 1024)
{
return _Index(bytes - 128, 4) + 16;
}
else if (bytes <= 8 * 1024)
{
return _Index(bytes - 1024, 7) + 72;
}
else if (bytes <= 64 * 1024)
{
return _Index(bytes - 8 * 1024, 10) + 128;
}
else
{
return _Index(bytes - 64 * 1024, 13) + 184;
}
}
};3.3 ThreadCache类
ThreadCache.h
按照上述的对齐规则,ThreadCache中桶的个数,也就是空闲链表的个数是208,以及Thread Cache允许申请的最大内存大小256KB,我们可以将这些数据按照如下方式进行定义。
static const int NFREELISTS = 208 ;
static const int MAXSIZE = 256 * 1024;现在就可以对ThreadCache类进行定义了,这里我们可以参考上一章实现的定长内存池,我们类中的_Freelists就是一个存储208个空闲链表的数组,这里的allocate和deallocate就对应着内存块的申请与释放,而FetchFromCentralCache接口我们留到编写CentralCache时实现
#pragma once
#include"common.h"
class ThreadCache
{
public:
void* allocate(size_t size);
void deallocate(void* ptr, size_t size);
// void* FetchFromCentralCache(size_t index, size_t size);
private:
FreeList _freelists[NFREELISTS];
};
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;FreeList类
鉴于当前项目比较复杂,我们在Common.h对空闲链表这个结构进行封装,目前我们就提供Push和Pop两个接口,后面在需要时还会添加对应的成员函数。
class FreeList
{
public:
void push(void* obj) //头插
{
assert(obj);
*(void**)obj = _FreeList;
_FreeList = obj;
}
void* pop() //头删
{
assert(_FreeList);
void* obj = _FreeList;
_FreeList = *(void**)_FreeList;;
return obj;
}
bool empty()
{
return _FreeList == nullptr;
}
private:
void* _FreeList = nullptr;
};allocate()
我们创建ThreadCache.cpp来编写ThreadCache接口的具体实现
在ThreadCache申请对象时,通过所给字节数计算出对应的哈希桶下标,如果桶中空闲链表不为空,则从该空闲链表中取出一个对象进行返回即可;但如果此时空闲链表为空,那么我们就需要从CentralCache进行获取了,如果空闲链表中对象不够,我们就会通过FetchFromCentralCache到CentralCache中进一步申请内存,这个在后面CentralCache再具体实现。
void* ThreadCache::allocate(size_t size)
{
assert(size <= MAXSIZE);
size_t align_size = SizeTable::RoundUp(size);
size_t index = SizeTable::Index(size);
if (!_freelists[index].empty())
{
return _freelists[index].pop();
}
else
{
// return FetchFromCentralCache(index, align_size);
}
}deallocate()
void ThreadCache::deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAXSIZE);
// 找对映射的空闲链表桶,对象插入进入
size_t index = SizeTable::Index(size);
_freelists[index].push(ptr);
}3.4 TLS无锁访问
线程局部存储(TLS),也称为线程本地存储,是一种变量存储的方法,使得每个线程都可以拥有自己独立的变量实例,而这些变量在不同线程之间是相互隔离的。TLS 允许每个线程在其执行期间拥有自己的全局变量的副本,而不需要担心与其他线程共享相同变量的问题。
在 Windows 平台上,可以使用_declspec(thread)语法实现线程局部存储。
由于每个线程都有一个自己独享的单例的ThreadCache,那应该如何创建这个ThreadCache呢?我们不能将这个ThreadCache创建为全局的,因为全局变量是所有线程共享的,这样就不可避免的需要锁来控制,增加了控制成本和代码复杂度。所以我们这里将ThreadCache设计为线程局部数据
//TLS - Thread Local Storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
但不是每个线程被创建时就立马有了属于自己的ThreadCache,而是当该线程调用相关申请内存的接口时才会创建自己的ThreadCache,因此在申请内存时我们会有下面的逻辑。
//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
3.5 对外提供申请内存
创建ConcurrentAlloc,h,编写一个向外提供内存申请释放的ConcurrentAlloc和ConcurrentFree函数
#pragma once
#include "Common.h"
#include "ThreadCache.h"
static void* ConcurrentAlloc(size_t size)
{
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl; //单元测试使用
return pTLSThreadCache->allocate(size);
}
static void ConcurrentFree(void* ptr, size_t size)
{
assert(pTLSThreadCache);
pTLSThreadCache->deallocate(ptr, size);
}3.6 ThreadCache单元测试
这里我们编写简单的程序来对我们现在实现的ThreadCache做简单的测试
#include "ConcurrentAlloc.h"
void Alloc1()
{
for (size_t i = 0; i < 5; ++i)
{
void* ptr = ConcurrentAlloc(6);
}
}
void Alloc2()
{
for (size_t i = 0; i < 5; ++i)
{
void* ptr = ConcurrentAlloc(7);
}
}
void TLSTest()
{
std::thread t1(Alloc1);
t1.join();
std::thread t2(Alloc2);
t2.join();
}
int main()
{
TLSTest();
return 0;
}
![]()