test1
test2
test3
test4
test5
test1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
程序的结果是什么?
首先分析代码,a是数组名,是数组首元素地址,&a取到整个数组的地址,+1跳过了整个数组,a强转成int*类型,然后赋值给ptr,此时ptr指向的就是数组a后面的地址,如下图:
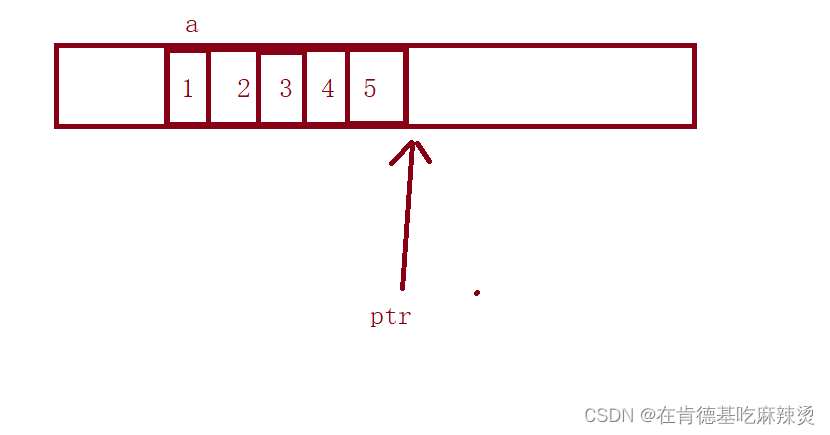
(ptr -1 ) ,指针-1, 跳过了一个int,指向了5的地址,再*,找到了5。
a是数组名,表示数组首元素地址,即1的地址,a+1,跳过一个int,表示第二个元素地址,再 *,找到了第二个元素,即2。
所以打印的结果是2 ,5
test2
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
假设p 的值为0x100000。 如下表表达式的值分别为多少?
已知,结构体Test类型的变量大小是20个字节
int main()
{
p = (struct Test*)0x100000 ;
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
关于结构体大小为什么是20字节,具体可以参考结构体内存对齐问题,这里的重点是题目的讲解。
来看:p是一个结构体之这么,p + 0x1,0x1的意思就是16进制的1,相当于指针+1(十六进制),由于p是一个结构体指针,该结构体指针的大小是20字节,所以p+1跳过了20个字节,即0x10 00 14,(16进制的结果)。
第一个打印结果,以%p形式打印,打印的是地址,由于0x10 00 14不够一个十六进制的打印方式,所以需要在前面补00,即0x00 10 00 14 。
对于第二个打印 p被强转成了unsigned long类型,是长整型,p+1,就是整型+1,整型+1就是+1,就跳过一个字节,即0x10 00 01,所以以%p形式打印出来,就是0x00 10 00 01。
对于第三个打印,p被强转成unsigned int*的指针,是一个整型指针,指针+1,跳过一个整型,即跳过4个字节,所以是0x10 00 04,以%p形式打印,就是0x00 10 00 04.
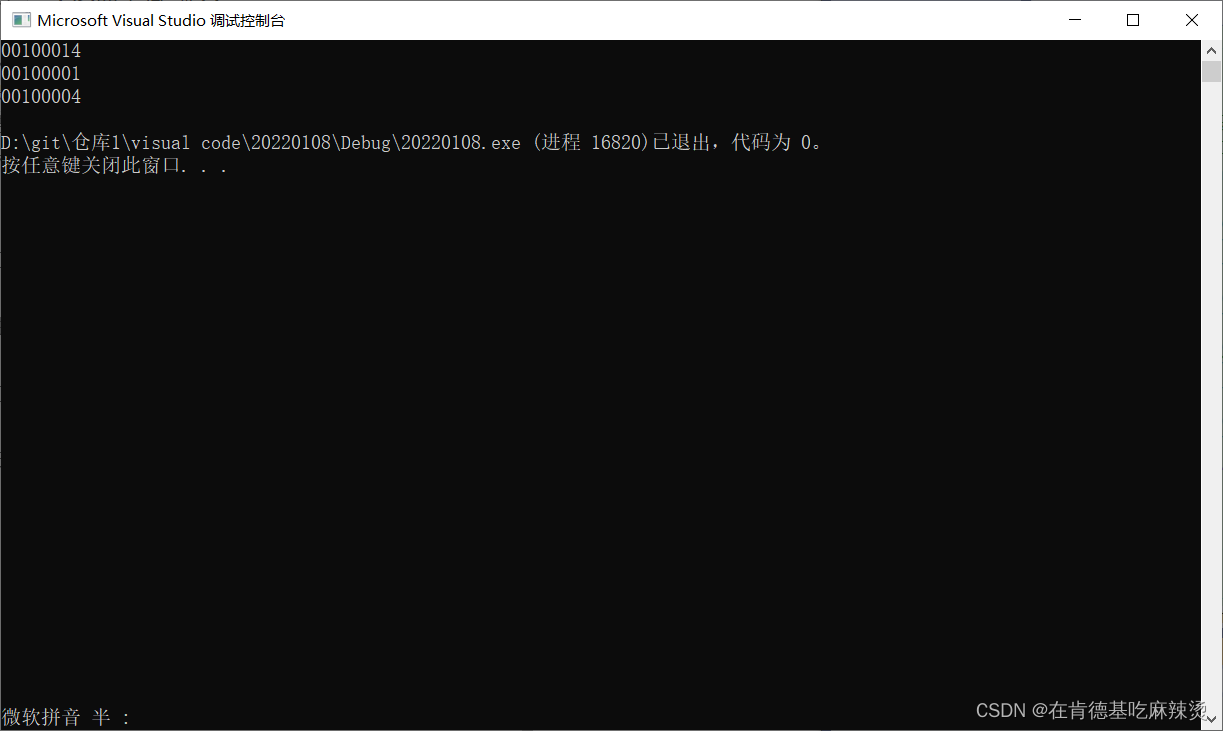
结果如上:0x会在打印的时候自动省略。
test3
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}
分析:
a是数组名,&a,取到的是整个数组的地址,+1就跳过了整个数组,此时ptr1指向如下图:
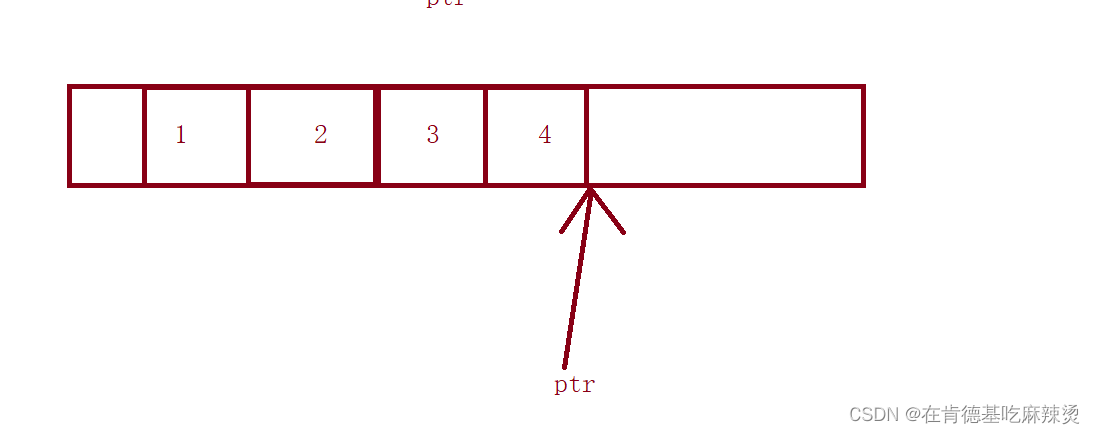
ptr[-1] == *(ptr-1) ,此时找到了4,以%x的形式打印出来,

4的十六进制形式仍然是4,故打印的是4.
对于ptr2, a被强转成int类型,a就是整型地址,假设a的地址是0x0012FF40,那么a+1就是0x0012FF41,增加的是一个字节的大小,即跳过了一个字节的地址,如下图:
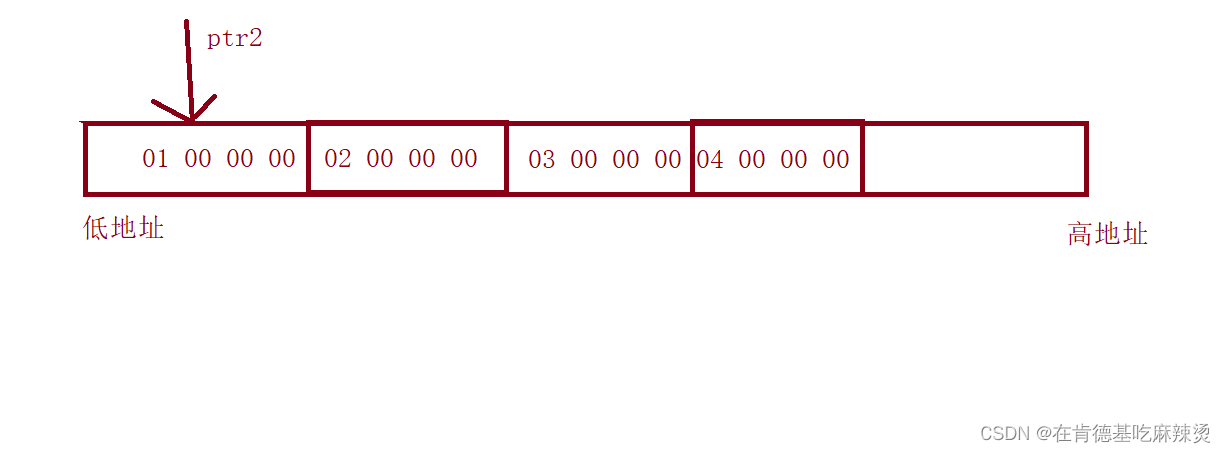
*ptr2,就顺着ptr所在地址,往后访问4个字节。
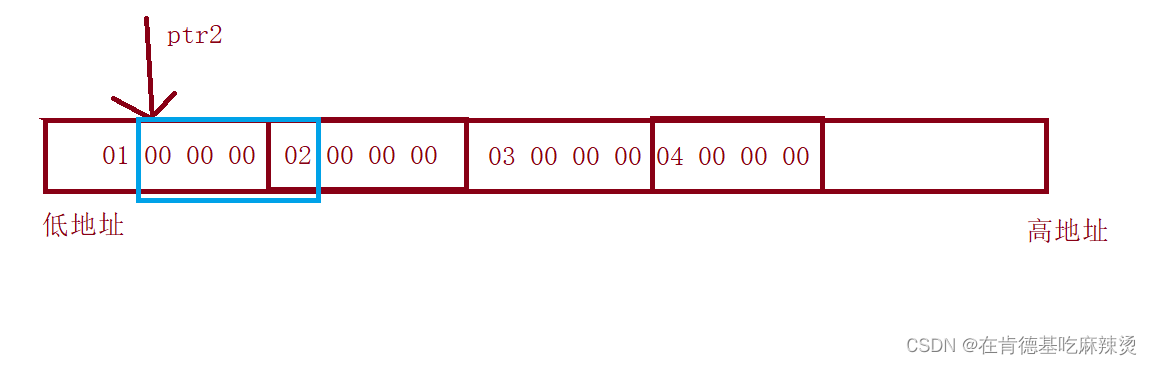
由于计算机是小端存储,低位放在低地址,高位放在高地址,故读取时是 0x02 00 00 00,以%x的形式打印出来,结果就是2000000,2前面的0对于%x来说是没有意义的,所以不会打印出来。所以两个打印的结果是4,2000000
test4
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
解析:
对于a来说,a的类型是 int(*)[5] ,对于p来说,
p的类型是 int (*)[4],所以我们可以知道,p和a的类型并不相同,有所差异,这将会导致在下面的地址访问有差异,
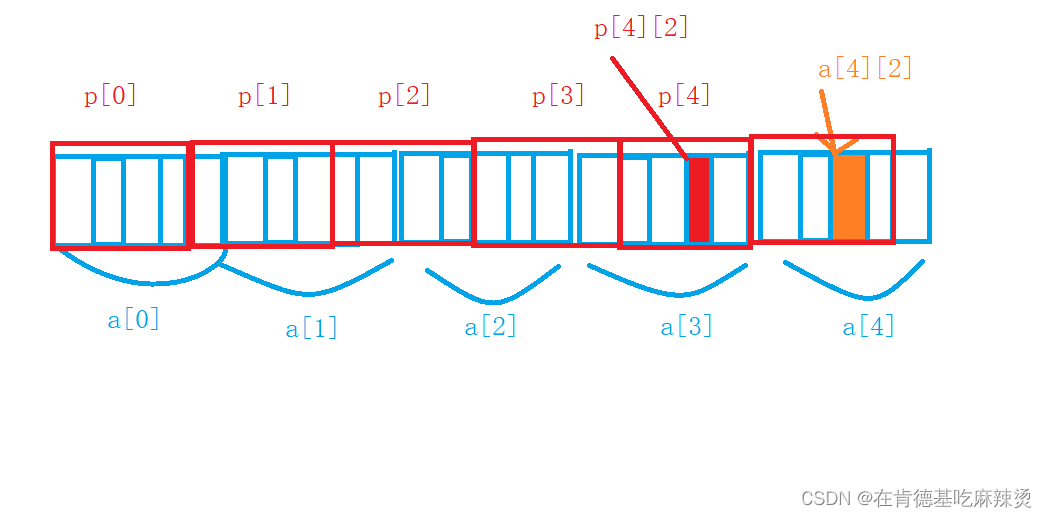
a和p在内存中的地址如下图,a[4][2]和p[4][2]的地址也如下图:
在内存中,数组下标是从低地址向着高地址增长的,所以上图左边是低地址,右边是高地址,所以p[4][2]的地址小于a[4][2]的地址。
p[4][2] 和a[4][2]之间相差4个元素,故以%d打印出来是 -4 ,(小-大),以%p的形式打印的话,由于%p打印的是地址,所以先将-4的原码反码补码先写出来,(-4在内存中是以补码来存储的).
1000 0000 0000 0000 0000 0000 0000 0100 - 原码
11111111111111111111111111110111 - 反码
1111 1111 1111 1111 1111 1111 1111 1000 - 补码
对于%p而言,%p认为-4 的补码就是地址,地址没有原码反码的说法,所以直接打印-4的补码(以16进制的形式),对于-4的补码,翻译成16进制就是 FF FF FF FC ,故打印结果就是
FFFFFFFC,-4
test5
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
这道题目较为复杂,先画图理解:
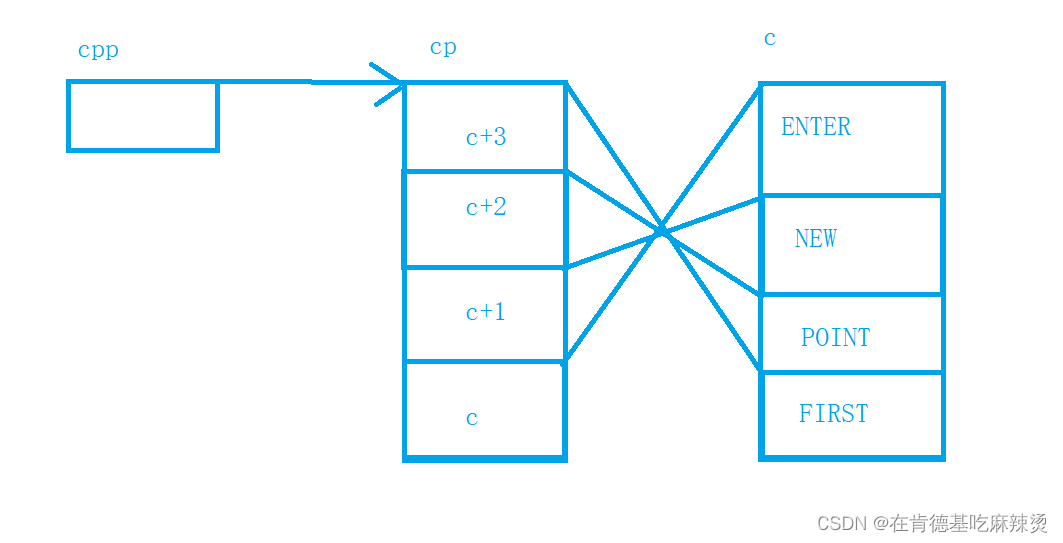
c是一级指针数组,cp是二级指针数组,存储的是一级指针数组的地址,cpp是三级指针,指向二级指针数组的地址。
先看第一个printf,先++cpp,cpp最初指向的是cp首元素地址,++后,cpp指向第二个元素地址。
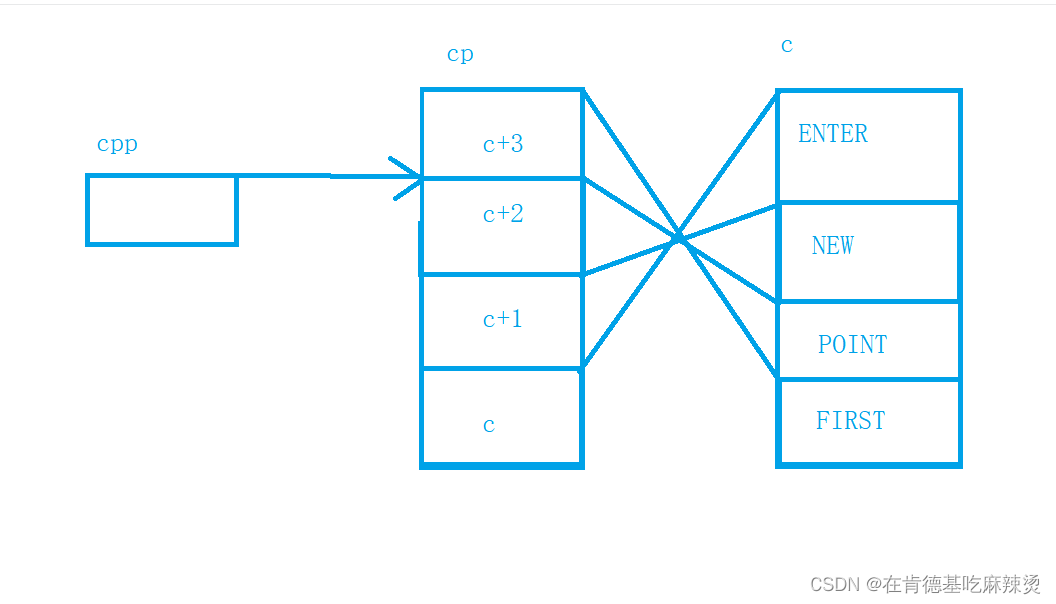
然后*cpp,此时找到了cp第二个元素,而这个元素是c+2,也就是c的第三个元素的地址,
再进行*,即对c+2进行 *,也就找到了c+2这个元素,即POINT,此时打印出来,也就是打印出POINT。
1. printf("%s\n", **++cpp);
对于第二个printf,注意:此时cpp已经指向了cp第二个元素的地址:
2. printf("%s\n", *--*++cpp+3);
先++cpp,此时cpp指向了cp第三个元素的地址,
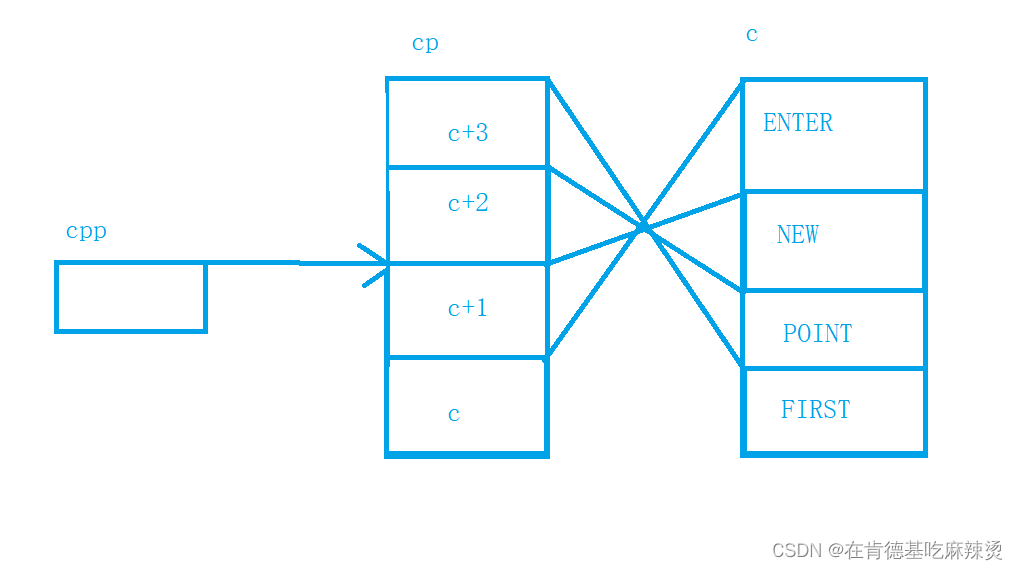
再进行*,找到了c+1这个元素,然后对c+1进行–操作,即从c+1变成了c,此时找到了c这个元素,而c就是数组首元素的地址,即ENTER的地址,再进行* 操作,找到了ENTER,然后+3,跳过了三个字符,找到了ER,打印出来的结果就算ER。
对于第三个printf,
3. printf("%s\n", *cpp[-2]+3);
[]的优先级比*的优先级高,所以cpp先和[-2]结合,即cpp[-2],等价于 *(cpp-2),此时cpp指向的是cp第三个元素的地址,-2就指向了第一个元素的地址,即c+3的地址,*操作后,找到了c+3这个元素,而c+3就是c这个数组第三个元素的地址,再 * 操作后,找到了c数组第三个元素,即FIRST,再+3,找到了ST,所以打印出来ST。
对于第四个printf,
4. printf("%s\n", cpp[-1][-1]+1);
注意,第三个printf并没有改变cpp指向的位置,因为在第三个printf中,没有对cpp进行++或者–的操作,
对第四个printf , cpp[-1] == *(cpp-1),cpp[-1][-1] ==
*( *(cpp -1) -1) ,即cpp先-1操作,cpp此时是指向cp第三个元素地址:
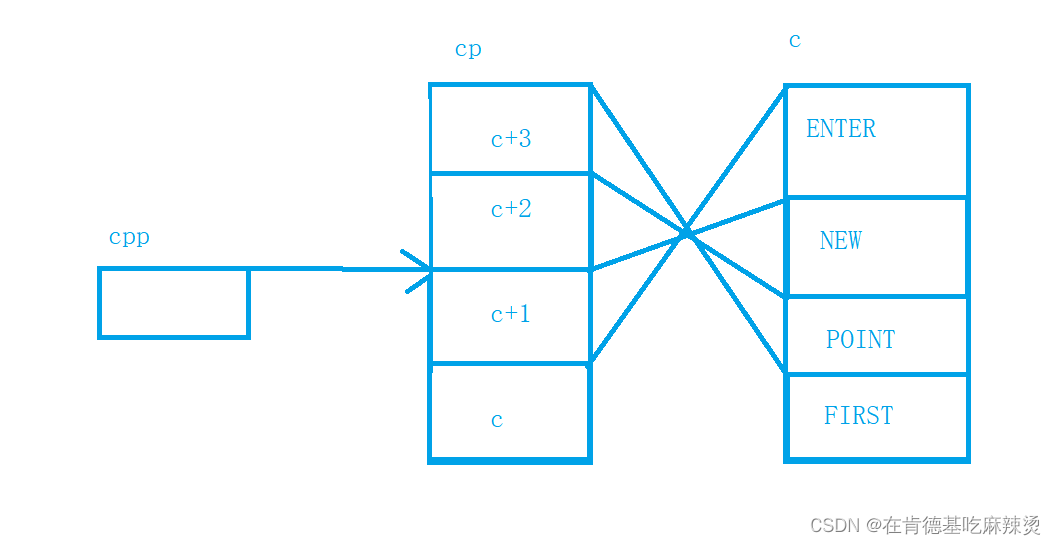
即c+1的地址,cpp-1操作后,指向了c+2的地址,*后,找到了c+2这个元素,再进行-1操作,即对c+2进行-1操作,即c+2-1 = c+1,c+1就是数组c的第二个元素的地址,也就是NEW的地址,然后进行 *操作后,找到了NEW,再+1,即找到了EW,打印出来的结果就是EW。
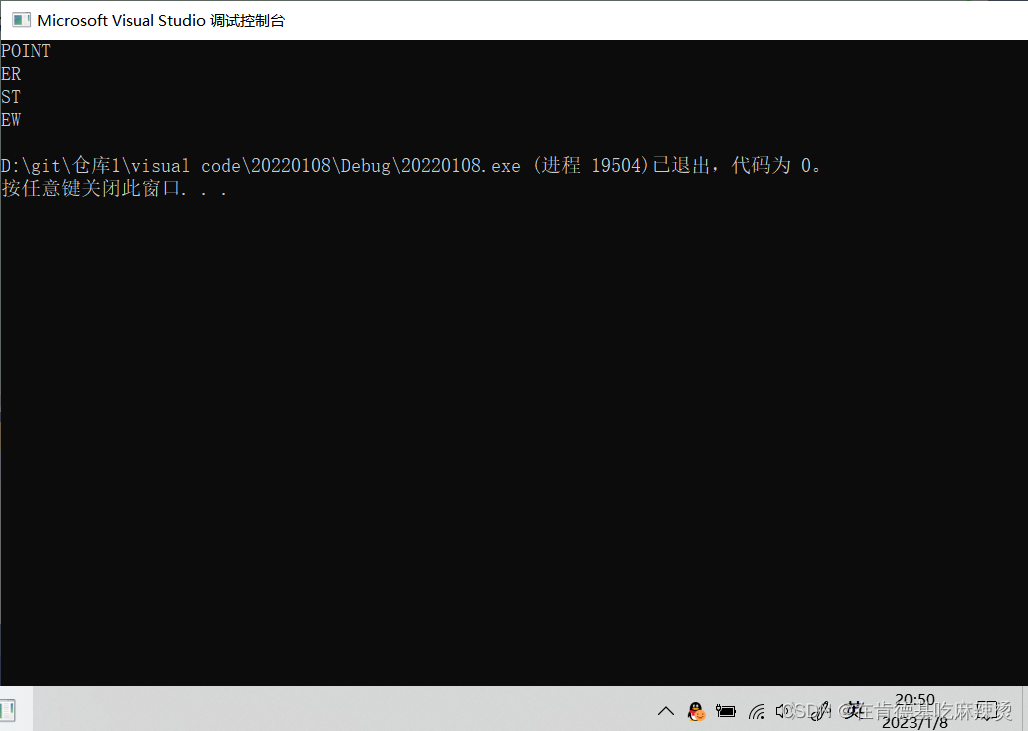
结果如上: