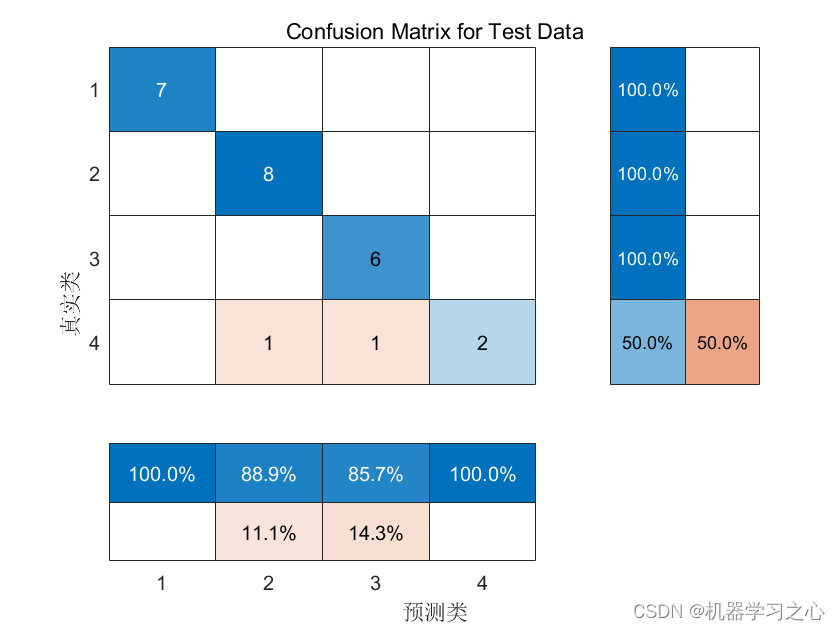
排序算法经典中的经典
参考
推荐系统之GBDT+LR
极客时间 手把手带你搭建推荐系统 课程
逻辑回归(LR)模型
逻辑回归(LR,Logistic Regression)是一种传统机器学习分类模型,也是一种比较重要的非线性回归模型,其本质上是在线性回归模型的基础上,加了一个 Sigmoid 函数(也就是非线性映射),由于其简单、高效、易于并行计算的特点,在工业界受到了广泛的应用。
作为广义线性模型的一种,LR 假设因变量 y 服从伯努利分布。在推荐系统中我们用它来预估点击率,实际上就是来预测“点击”这个事件是否发生。这个“是否发生”实际上就是因变量 y。因为点击事件只有两种可能性,点击或者不点击(二分类问题)。这个问题,实际上就是服从伯努利分布的。总结一下,逻辑回归实际上就是在数据服从伯努利分布的假设下,通过极大似然的方法,运用梯度下降算法对参数进行求解,从而达到二分类。
在线性回归的基础上,把它的输出通过另一个函数映射到[0, 1]这个区间范围内就能解决这个问题。这个映射函数我们一般用 Sigmoid 函数,而映射之后的函数就是一个逻辑回归模型,它对应的逻辑回归图像如下。

其函数原型为
y
=
1
1
+
e
−
z
y = \frac{1}{1+ e^{-z}}
y=1+e−z1.

GBDT 模型
GBDT(Gradient Boosting Decision Tree)算法是一种基于决策树的集成学习算法,它通过不断训练决策树来提高模型的准确性。GBDT 在每一次训练中都利用当前的模型进行预测,并将预测误差作为新的样本权重,然后训练下一棵决策树模型来拟合加权后的新数据。
GBDT 中的 B 代表 Boosting。Boosting 算法的基本思想是通过将多个弱分类器线性组合形成一个强分类器,达到优化训练误差和测试误差的目的。具体应用时,每一轮将上一轮分类错误的样本重新赋予更高的权重,这样一来,下一轮学习就容易重点关注错分样本,提高被错分样本的分类准确率。
GBDT 由多棵 CART 树组成,本质是多颗回归树组成的森林。每一个节点按贪心分裂,最终生成的树包含多层,这就相当于一个特征组合的过程。
在推荐系统中,我们使用 GBDT 算法来优化和提高个性化推荐的准确性。通过 GBDT 算法对用户历史行为数据进行建模和学习,可以很容易地学习到学习用户的隐式特征(例如品味、购买能力、口味偏好等)。另外,GBDT 算法可以自动选择重要的特征,对离散型和连续型特征进行处理(如缺失值填充、离散化等),为特征工程提供更好的支持。
FM模型通过隐变量的方式,发现两两特征之间的组合关系,但这种特征组合仅限于两两特征之间,后来发展出来了使用深度神经网络去挖掘更高层次的特征组合关系。但其实在使用神经网络之前,GBDT也是一种经常用来发现特征组合的有效思路。
GBDT+LR
在推荐系统中,GBDT+LR 使用最广泛的场景就是点击率预估,然后根据点击率预估的结果进行排序,因此 GBDT+LR 一般被应用于排序层中。

可以看到,整个模型实际上被分成两个部分,下面是 LR 上面是 GBDT。从上往下看,整个模型的训练可以分成下面五个步骤。
- GBDT 训练:使用 GBDT 对原始数据进行训练并生成特征。在训练过程中,每棵树都是基于前一棵树的残差进行构建。这样,GBDT 可以逐步减少残差,生成最终的目标值。
- 特征转换:使用 GBDT 生成的特征进行转换。这些特征是树节点的输出,每个特征都对应于一个叶子节点。在转换过程中,每个叶子节点都会被转换为一个新的特征向量,代表这个叶子节点与其他节点的相对位置,并将这些特征向量连接起来形成新的训练集。
- 特征归一化:对生成的特征进行归一化处理,确保不同维度的特征在训练过程中具有相等的权重。
- LR 训练:使用 LR 对转换后的特征进行二分类或回归。特征向量被送入逻辑回归模型中进行训练,以获得最终的分类模型。在训练过程中,使用梯度下降法来更新模型参数,以最小化损失函数,损失函数的选择取决于分类问题的具体情况。
- 模型预测:训练完成后,使用 LR 模型对新的数据进行预测。GBDT+LR 模型将根据特征生成函数和逻辑回归模型预测新数据的类别或值。
优缺点
使用 GBDT+LR 结合的形式进行点击率预测好处:
- 可以利用 GBDT 对复杂数据进行非线性特征提取和降维,又可以运用 LR 对特征进行加权和融合,提高模型的预测精度。
- BDT+LR 不需要手动选择特征(通过 GBDT 自动选择),使得模型更具有鲁棒性和可扩展性。
- GBDT+LR 具有良好的可解释性,可以通过分析 GBDT 中的特征重要度和 LR 中的权重,得到每个特征在模型中的贡献程度,从而更好地理解模型的预测结果。
虽然 GBDT+LR 来进行点击率预测有很多的好处,但是同时也有很多的问题,比如下面三点。
- GBDT+LR 建模复杂度较高,需要调节多个超参数,如 GBDT 中的树深度、叶子节点数量、学习率等,LR 中的正则化参数等,增加了模型调优的难度。
- GBDT+LR 需要大量的数据和计算资源进行训练,尤其是对于大规模的数据集,训练时间和计算成本都较高。
- GBDT+LR 对异常值和噪声数据敏感,需要进行数据预处理和异常值处理,以提高模型的稳定性和鲁棒性。
现在的GBDT和LR的融合方案真的适合现在的大多数业务数据么?现在的业务数据是什么?是大量离散特征导致的高维度离散数据。而树模型对这样的离散特征,是不能很好处理的,要说为什么,因为这容易导致过拟合。GBDT只是对历史的一个记忆罢了,没有推广性,或者说泛化能力。