目录
- 一、论文阅读
- 1.1 论文标题
- 1.2 论文摘要
- 1.3 论文背景
- 1.4 提出的系统:MAER
- 1.4.1 基于Asyncio的预处理
- 1.4.2 多模态信号下的情感识别
- 1.4.3 针对情感不匹配情况的自适应融合
一、论文阅读
1.1 论文标题
Beyond superficial emotion recognition: Modality-adaptive emotion recognition system(模态适应的情绪识别系统)
1.2 论文摘要
该论文提出了一个实时的模态自适应情感识别(MAER)系统,解决了现有面部表情识别系统在可靠性和实时操作方面的限制。该系统通过并行处理和模态自适应融合来改善情感识别的性能和可靠性。通过实时试验,该系统的准确性比仅使用外部信号(视频和音频)的情感识别高出33%。该系统能够推断出真实的情感,即使在内部和外部状态之间存在情感不匹配的情况下,通过给予真实情感信号更大的权重。该系统利用轻量级网络和可穿戴设备进行信号采集,实现了实时计算和实际应用。
1.3 论文背景
随着深度学习的发展,面部表情的情感识别取得了进展,但在实际应用中仍存在可靠性的问题。根据提供的来源,这些限制包括面部表情和真实情感之间的不一致性,以及仅使用外部信号进行情感识别的有限可靠性。此外,由于MAER系统基于预训练的神经网络,它对于超出分布范围的输入是脆弱的。为了提高情感识别的可靠性,研究人员开始探索使用音频或生物信号作为辅助模态。该论文提出了一种模态自适应融合的方法,通过并行处理和特征提取来预测主体的综合情感状态。通过实时试验验证了该系统的性能,并取得了比仅使用外部信号的情感识别更高的准确性。
1.4 提出的系统:MAER
该系统是一种多模态情感识别系统,通过融合视频、音频和生物信号来检测内部和外部情感信号之间的差异。该系统采用异步并行处理,可以实时响应多模态信号输入。通过模态自适应融合,该系统可以更加精细地识别内部情感,相比仅使用两种模态信号的传统方法更具优势。该系统在真实环境中进行了多种场景的实时试验,验证了多模态信号的协同效应。该系统的技术贡献包括实时自适应融合三种模态信号、通过实际试验验证系统的可行性,并且能够更好地捕捉真实情感。
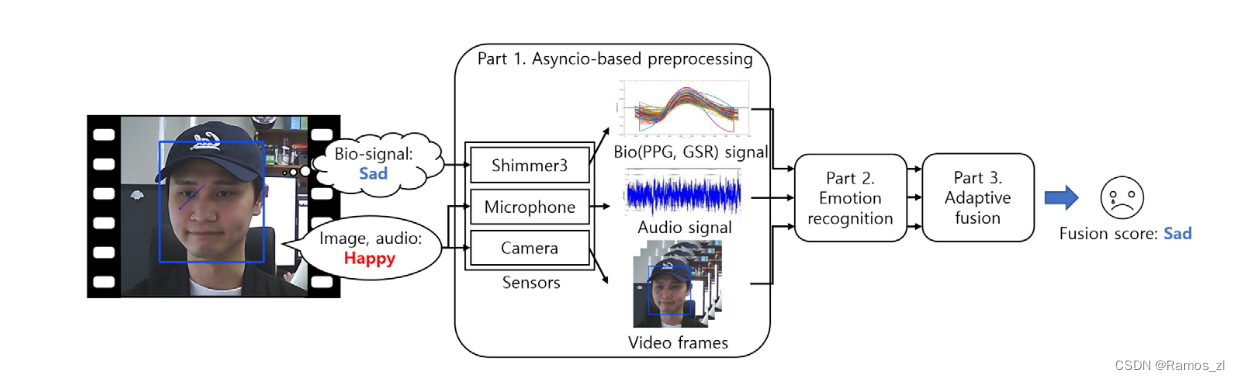
1.4.1 基于Asyncio的预处理
MAER的第1部分是建立一个对多个信号进行实时处理的环境。MAER系统基于三种模态的信号:来自网络摄像头的视频信号,来自麦克风的音频信号,以及来自Shimmer3传感器信号。与大多数基于深度学习的框架一样,MAER系统是用Python实现的。然而,Python基本上都是通过一个全局解释器锁( GIL )来限制任务之间的并行性,从而防止多个任务同时被执行。因此,作为一种替代方案,提供了Asyncio库来保证任务之间的并发性。Asyncio通过基于协程反复测量每个任务的进度,支持任务之间的快速切换,并且具有微型性。通过在读取另一个信号的同时等待一个信号来最小化延迟。
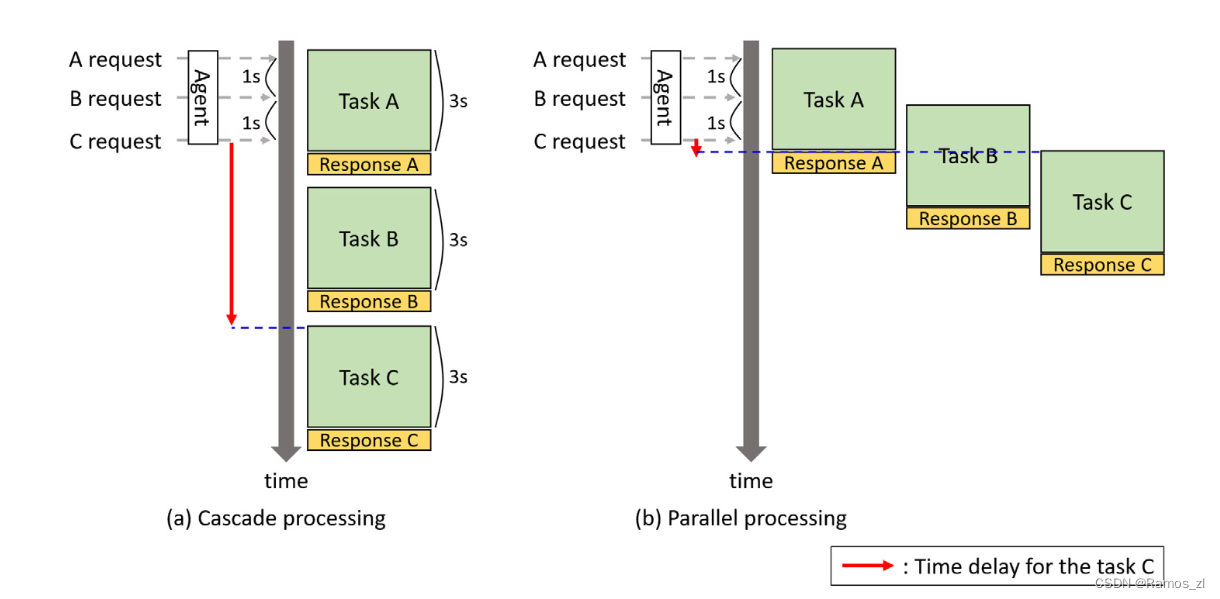
来自三个传感器的多模态数据的帧率,即每秒帧数( fps )各不相同。例如,生物信号的采集速率为1 fps,而视频信号的输入速率为30 fps。音频信号是零星激活的(只有当主体说话时),输入数据的长度是可变的。为了解决这个实际问题,我们的代理不仅独立地处理每个信号,而且并行地从每个信号中识别情绪。因此,MAER系统必须能够异步地处理各模态信号,同时对连续信号做出响应。
为了平滑的系统维护,代理包括以下两个功能:( 1 )当多个任务同时请求时,提供适当的时间延迟以防止开销。( 2 )在情感识别分布式处理的同时,实现了各任务的数据采集。如果在模型运行过程中收到数据请求,则代理配备允许同时获取数据的功能。
1.4.2 多模态信号下的情感识别
- 面孔情绪识别
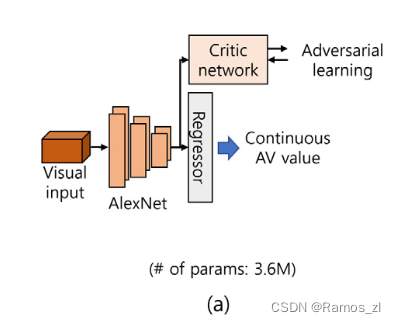
人脸检测器对人脸图像的预处理和基于深度学习网络的情感分析。采用平幅皂洗机单次曝光检测器( SSD )框架进行人脸检测。该检测器输出的人脸区域裁剪后大小为300 × 300,并输入到后续的网络中。为了从人脸数据中识别情绪,我们使用了FER模型。首先,FER模型可以在潜在特征空间中通过基于批评网络的对抗学习区分强、弱情感组,从而学习到多样性的表情。其次,它基于简单的AlexNet,保证了操作的实时性。特别地,FER模型适用于许多看不见的对象频繁出现的野外环境。该FER模型在ImpactNet数据集上进行预训练,并返回范围为[ -1⋅1 ]的连续AV值。
- 语音情感识别。
SER过程包括三个步骤:用于信号采集的语音识别、特征提取和情感分析。注意到语音信号只有在主体说话时才会被激活,因此是在话语单元中进行处理的。因此,我们需要确定以下两点来实时采集语音信号:语音的存在和语音的结束。我们使用了能够区分语音和其他声音的WebRTC语音活动检测器,以便只收集语音信号。如果语音开始被工具检测到,则将其记录下来,直到超过一秒钟没有检测到语音信号。采集了长达10 s的语音数据,并对录制的语音信号进行批量填充。
SER的一些特征是从语音信号中提取的。据报道,速度和加速度特征显示出噪声不敏感的语音识别。因此,利用Speech Py库提取MFCC能量、速度和加速度。在这里,每个特征有13个维度。然后,将这三个特征串联成一个39维的向量,并输入到后续的网络中,即VGGNet。最后,使用IEMOCAP数据集对基于2D CNN的小尺寸VGGNet进行预训练,并将其用于SER。SER模型返回离散的唤醒度和效价值范围为[ - 2,2 ]。因此,我们的小型VGGNet表现出噪声鲁棒性的SER性能。
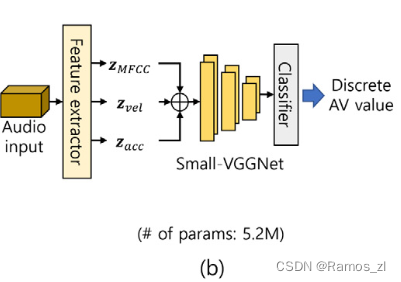
- 生物信号情绪识别
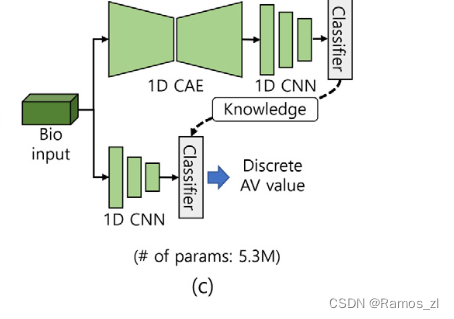
类似地,利用生物信号进行情绪识别包括3个步骤:通过可穿戴设备进行信号采集、预处理和情绪分析。如前所述,大多数基于生物信号的情绪识别系统所采用的EEG信号难以实时获取。因此,我们选择了PPG和GSR信号,即使通过简单的可穿戴设备也可以采集。PPG和GSR信号不需要额外的数据处理,可以在一秒内同时采集。在我们的系统中,巴特沃斯滤波器和滑动平均滤波器分别用于去除采集到的原始数据中的高频和低频噪声。为了保证在通用计算机上进行实时计算,必须使用小规模的输入数据或轻量级网络。然而,由于Shimmer3的硬件限制,输入数据大小不能任意减小。因此,我们应该采用轻量级的网络。我们应用了一种针对轻量级网络的知识蒸馏技术。配置了不同结构的教师模型和学生模型。具体来说,一维( 1D )卷积自编码器( CAE )和1D CNN模型分别用作教师和学生模型。最后,我们使用MERTI - Apps数据集对基于生物信号的情绪识别网络进行预训练,返回离散的唤醒度和效价值范围[ -1⋅1 ]。
1.4.3 针对情感不匹配情况的自适应融合
所提出的模态自适应融合旨在实现对生物信号表达的内部状态和视听信号表达的外部状态之间的情感不匹配的鲁棒性。在多模态融合之前,进行基于模态的情感识别。设预处理后的视频、音频和生物信号分别为Xv∈Rvt × vw × vh、Xa∈Rat × ad和Xb∈Rbt × bd。
视频:vt、vw、vh分别表示视频帧的帧长、帧宽、帧高;
音频:at、ad分别表示音频信号的序列长度和特征维数;
生物:bt、bd分别表示生物信号的序列长度和特征维数。
用于情感识别的预训练编码器分别记为fv、fa、fb。它们的输出定义如下。

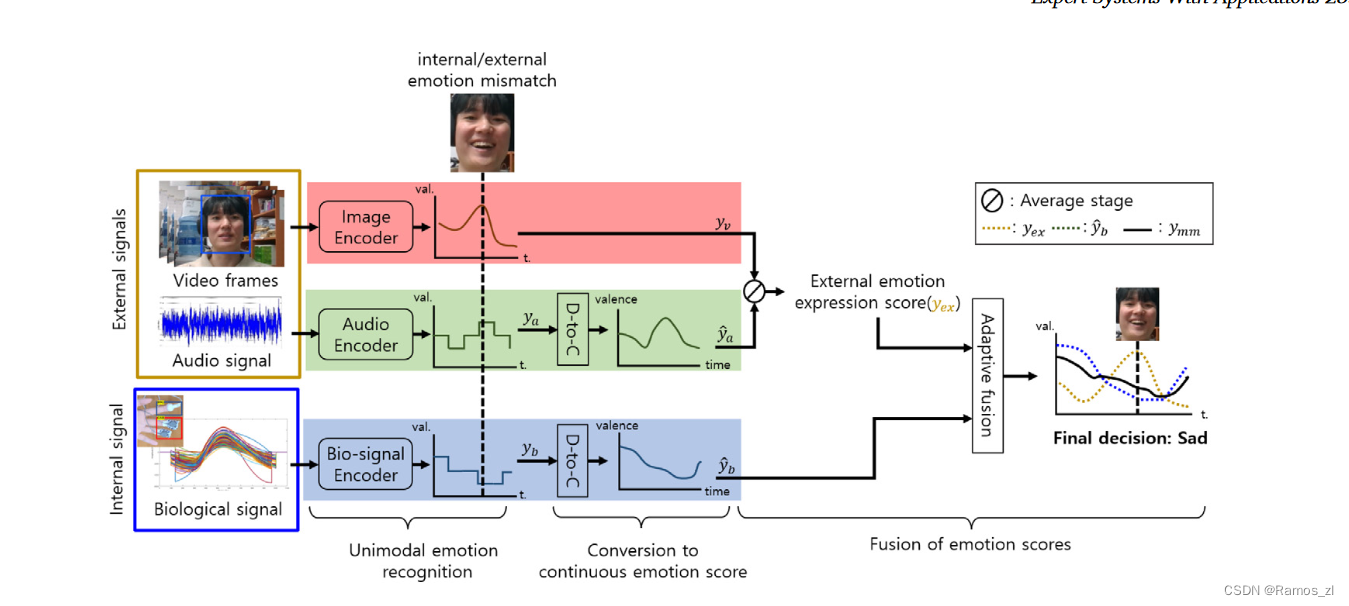
由于编码器的数据集覆盖了足够广泛的唤醒度和效价范围,因此我们假设对输出的融合没有负面影响。另一方面,每个模态的输出y具有连续或离散的形式,甚至是不同的范围。因此,我们通过使用ya和yb的置信度分数来调整ya和yb,使其具有与视频信号相同的标准(即,连续)。设ya和yb是离散的AV值.同样,令pa和pb分别表示ya和yb的置信度分数.然后将其转化为连续的AV值: ya = yapa / 2, yb = ybpb。因此,我们可以获得与视频信号相同范围[ - 1至1 ]的连续值。
为了从面部表情和音频信号中提取外部情感状态,我们使用条件平均值,该操作取决于是否启用音频输入,因为音频信号不像常规视频信号那样不规则地出现。
另一方面,一个人可以控制外在的情绪状态,却无法控制生物信号,即内在的情绪状态。因此,如果外部状态与内部状态之间的差距较大,那么主体隐藏内部(或真实)情绪的可能性就很高。基于这个假设,我们提出了一种融合方法,当外部状态和内部状态之间的差距较大时,对代表内部状态的yb赋予较大的权重。