🌞欢迎来到AI+医学的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2024年3月3日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
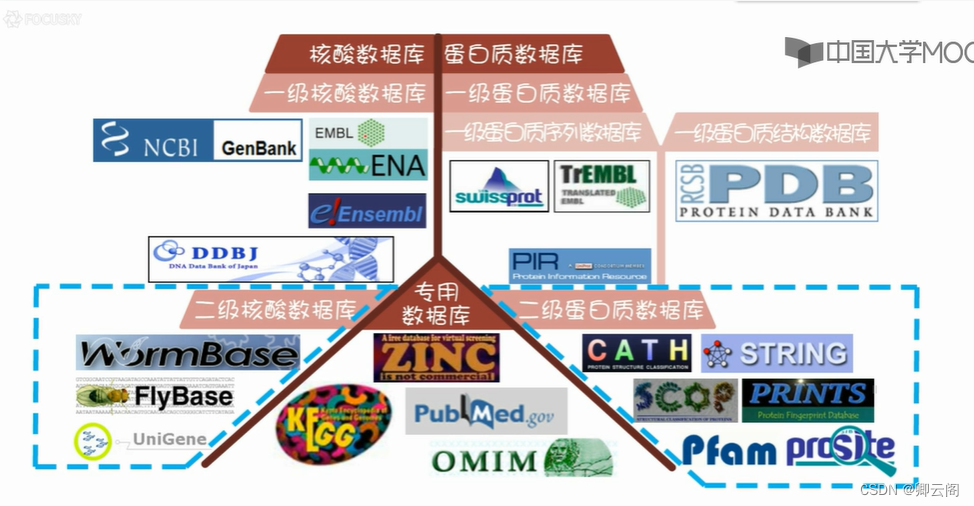
生物数据库
生物数据库的分类
这个世界上,到底有多少生物数据库?很难统计,但是用成百上千这个词儿一点儿也不夸张。著名的学术期刊 Nucleic Acids Research 有一个生物数据库专刊。有点儿规模的数据库 都争相在这里发表。包括 Genbank,PDB 等等,都在这里发表更新版本。截止 2015 年底, 这个专刊收录的生物数据库累计 1685 个。当然还有一些在其他刊物发表的小型专项数据库。 加上这些,目前世界上得有超过 2000 个生物数据库。当然,不是所有数据库都是活的。NAR 数据库专刊曾经发文指出,已发表的数据库中有相当数量的数据库在发表之后就死去了。事 实上,数据库不是一个可以放在那里保质期无限长的罐头,他需要专业人员不断的管理、维 护和更新。这些工作一旦停止,数据库便立刻失去了生命力。所以如果将来有一天,你也有 了自己开发的数据库,请善待它,不要轻易抛弃他。 可是这么多数据库,一节课讲不完,甚至一年也讲不完啊!所以这里只挑最重要的,最常用的,以及和大家的专业最密切相关的几个数据库进行讲解。正是因为数据库太多,所以大家特别喜欢给他们分类。不同的教材分类原则不同,也就是没有标准的分类方法。我们这里选取了比较好理解的原则,把生物数据库首先分成三大类。核酸数据库,蛋白质数据库和专用数据库。核酸数据库顾名思义,是与核酸相关的数据库。蛋白质数据库是与蛋白质相关的数据库。而专用数据库是专门针对某一主题的数据库,或者是综合性的数据库,以及无法归入其他两类的数据库。
可是这么多数据库,一节课讲不完,甚至一年也讲不完啊!所以这里只挑最重要的,最常用的,以及和大家的专业最密切相关的几个数据库进行讲解。正是因为数据库太多,所以大家特别喜欢给他们分类。不同的教材分类原则不同,也就是没有标准的分类方法。我们这里选取了比较好理解的原则,把生物数据库首先分成三大类。核酸数据库,蛋白质数据库和专用数据库。核酸数据库顾名思义,是与核酸相关的数据库。蛋白质数据库是与蛋白质相关的数据库。而专用数据库是专门针对某一主题的数据库,或者是综合性的数据库,以及无法归入其他两类的数据库。核酸数据库和蛋白质数据库又分为一级和二级。一级数据库存储的 是通过各种科学手段得到的最直接的基础数据。比如测序获得的核酸序列,或者 X 射线衍 射法等获得的蛋白质三维结构。蛋白质的一级数据库还可以再具体分为蛋白质序列数据库和 蛋白质结构数据库。二级数据库是通过对一级数据库的资源进行分析、整理、归纳、注释而 构建的具有特殊生物学意义和专门用途的数据库。比如从三大核酸数据库和基因组数据库中 提取并加工出的果蝇和蠕虫数据库,再比如根据蛋白质三维结构数据库中的结构信息,分析 统计出的蛋白质结构分类数据库 CATH 和 SCOP 等。
文献数据库 PubMed:基本使用
我们先从一个简单,但是非常常用的文献数据库 PUBMED 入手。 事情是这样的。我们的 3D 小人 Jim 拿到了一条老板给的基因序列。老板让他好好了解 一下这条序列,因为这是他这一阶段工作的主要研究对象。Jim 很头疼,一堆字母怎么研究 啊!这时,他听说有个师兄,上过生物信息学慕课,号称生物信息学专家。于是 Jim 把他的 序列交给了这位专家。很快专家告诉他,这条序列看上去像是一个 dUPTase。Jim 很开心, 太棒了,原来是dUTPase 啊!可是转过头想问问专家什么是 dUTPase,专家只丢给他一个话: 牛仔很忙,找 PubMed 去!Pubmed 是什么啊?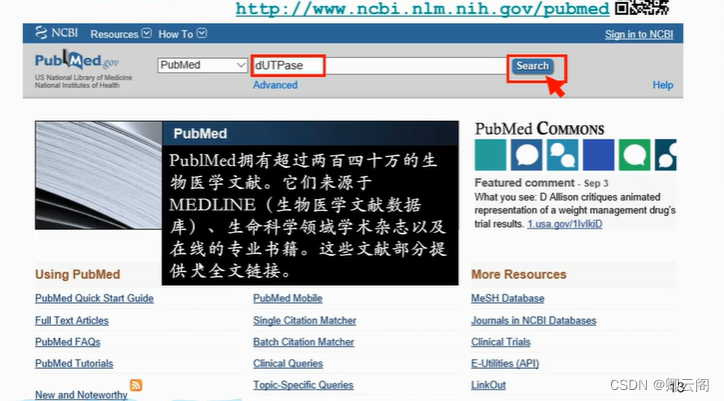 PubMed 是拥有超过两百六十万生物医学文献的数据库。这些文献来源于 MEDLINE,也就是生物医学文献数据库、生命科学领域学术杂志以及在线的专业书籍。他们大部分提供全文链接。注意,提供的是链接,你有没有权限通过这个链接打开或者下载全文另当别论。不管怎么说,看上去还不错。PubMed 主页( http://www.ncbi.nlm.nih.gov/pubmed )上有个搜 索条。不管三七二十一,先把家说的 dUTPase 敲到搜索条里,点搜索。找到了五百多条文 献。每个文献有题目,作者,刊物,出版时间等等。如果列出的这些信息还不够,或者无法 满足你的要求,你从页面上方设置每个文献是要显示内容、总结、摘要,还是其他。还可以 控制每页显示几个文献,以及按照你期望的顺序进行排序。
PubMed 是拥有超过两百六十万生物医学文献的数据库。这些文献来源于 MEDLINE,也就是生物医学文献数据库、生命科学领域学术杂志以及在线的专业书籍。他们大部分提供全文链接。注意,提供的是链接,你有没有权限通过这个链接打开或者下载全文另当别论。不管怎么说,看上去还不错。PubMed 主页( http://www.ncbi.nlm.nih.gov/pubmed )上有个搜 索条。不管三七二十一,先把家说的 dUTPase 敲到搜索条里,点搜索。找到了五百多条文 献。每个文献有题目,作者,刊物,出版时间等等。如果列出的这些信息还不够,或者无法 满足你的要求,你从页面上方设置每个文献是要显示内容、总结、摘要,还是其他。还可以 控制每页显示几个文献,以及按照你期望的顺序进行排序。 如果找到的文献太多,一时看不完,可以把他们保存到本地。只要选中你要保存的文献,然后通过发送按钮,选择文件,再选择保存的内容以及顺序,最后点创建文件。这样你选中文章的信息就以纯文本文件的形式保存到本地电脑上了。
如果找到的文献太多,一时看不完,可以把他们保存到本地。只要选中你要保存的文献,然后通过发送按钮,选择文件,再选择保存的内容以及顺序,最后点创建文件。这样你选中文章的信息就以纯文本文件的形式保存到本地电脑上了。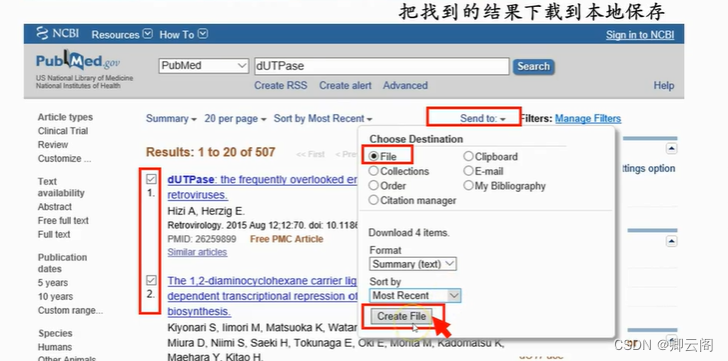 初次尝试 PubMed 搜做之后,Jim 突然想起来,老板是和一个美国人一起研究这个dUTPase 的。那个美国人他见过,好像是叫 Abergel。那不如,下一步就查查看这个 Abergel 发表的文章。这次他在搜索条中输入 Abergel,搜索!这次一共找到四百多条文献,比刚刚 搜 dUTPase 少了一些,但还是挺多的,而且世界上叫 Abergel 的人看来不少,找到的文章也 大多和 dUTPase 没有关系。看来这些都不是 Jim 见过的那个 Abergel 写的。经过这次尝试之后,Jim 想到,如果把 dUTPase 和 Abergel 都写到搜索条里,是不是就能找到 Abergel 写的关于 dUTPase 的文章了呢?试一下!果然,就剩 2 条了。第二篇文章,题目里有 dutpase,作者里有 abergel,有点儿意思,点一下题目,看看详细。Pubmed提供文献的摘要和全文链接。这里有两个全文链接。其中一个链接的图标上有 free 字样。Jim 很幸运,这篇文章是 open access 的,也就是免费阅读的。两个链接,第一个是期刊提供的全文链接,第二个是 PubMed 中心提供的全文链接。点其中一个链接,就可以在线浏览文献全文了,或者下载全文的 PDF 文件到本地。至此,JIM 总算找到了些许有用的信息。
初次尝试 PubMed 搜做之后,Jim 突然想起来,老板是和一个美国人一起研究这个dUTPase 的。那个美国人他见过,好像是叫 Abergel。那不如,下一步就查查看这个 Abergel 发表的文章。这次他在搜索条中输入 Abergel,搜索!这次一共找到四百多条文献,比刚刚 搜 dUTPase 少了一些,但还是挺多的,而且世界上叫 Abergel 的人看来不少,找到的文章也 大多和 dUTPase 没有关系。看来这些都不是 Jim 见过的那个 Abergel 写的。经过这次尝试之后,Jim 想到,如果把 dUTPase 和 Abergel 都写到搜索条里,是不是就能找到 Abergel 写的关于 dUTPase 的文章了呢?试一下!果然,就剩 2 条了。第二篇文章,题目里有 dutpase,作者里有 abergel,有点儿意思,点一下题目,看看详细。Pubmed提供文献的摘要和全文链接。这里有两个全文链接。其中一个链接的图标上有 free 字样。Jim 很幸运,这篇文章是 open access 的,也就是免费阅读的。两个链接,第一个是期刊提供的全文链接,第二个是 PubMed 中心提供的全文链接。点其中一个链接,就可以在线浏览文献全文了,或者下载全文的 PDF 文件到本地。至此,JIM 总算找到了些许有用的信息。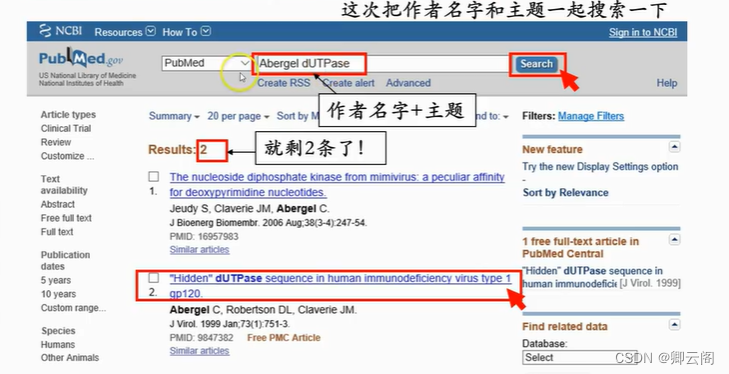
文献数据库 PubMed:高级搜索
回到 PUBMED 搜索结果页面,在显示内容格式这个下拉菜单里,除了总结,摘要,还有个叫 MEDLINE 的项目。你可以把它简单的理解为数据库中文献记录的内部结构。每条文献都是以这样的内部结构存储在数据库中的。一篇文献的所以信息被分割成小节,每个小节都有自己的索引名,比如 TI 代表题目,AB 代表摘要,AU 代表作者等等。这些由几个字母组成的索引名是规定好的。
了解了 MEDLINE 结构,我们就可以在搜索条中通过引入索引名,来按照不同的规则搜索。比如搜索 Down 这个词。我们在 Down 的后面加上空格,中括号 AU(Down [AU]), 就会返回所有作者名里有 Down 这个词的文献。如果加上[TI],则返回题目中有 Down 的 文献。中括号 AD 是搜索发表单位。如果什么限制都没有,只写 Down 的话是在任意地方搜 索。我们看到,引入不同索引名后,搜索到的文献数量是不相同的。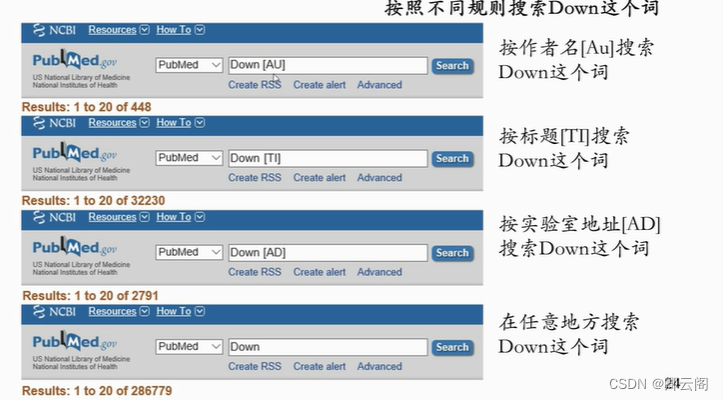 现在,我们的 Jim 已经学会了 PubMed 的基本使用。他打算趁暑假回北京期间找个相关的专家拜访一下。于是他在 PubMed 上搜索,题目和摘要里有 dUTPase 的文献,而且文献的 发表单位是北京的(dUTPase [TIAB] Beijing [AD])。搜索后,找到了这四篇文章。其中第二篇文章是研究 dUTPase 晶体结构的,Jim 很感兴趣。点进去看一下,找到最后一位的作者。我们说,通常课题的主要负责人会以通讯作者的身份出现在作者列队的最后。那么, 这个研究团队的主要负责人就是这位 Su XD,Su 教授。他的单位是北京大学。之后的任务 就可以交给度娘来完成了。度娘很快就找到了苏教授的地址和电话,而且连照片都有。Jim 通过这些信息,成功的拜访了北京大学生命科学学院的苏晓东教授。
现在,我们的 Jim 已经学会了 PubMed 的基本使用。他打算趁暑假回北京期间找个相关的专家拜访一下。于是他在 PubMed 上搜索,题目和摘要里有 dUTPase 的文献,而且文献的 发表单位是北京的(dUTPase [TIAB] Beijing [AD])。搜索后,找到了这四篇文章。其中第二篇文章是研究 dUTPase 晶体结构的,Jim 很感兴趣。点进去看一下,找到最后一位的作者。我们说,通常课题的主要负责人会以通讯作者的身份出现在作者列队的最后。那么, 这个研究团队的主要负责人就是这位 Su XD,Su 教授。他的单位是北京大学。之后的任务 就可以交给度娘来完成了。度娘很快就找到了苏教授的地址和电话,而且连照片都有。Jim 通过这些信息,成功的拜访了北京大学生命科学学院的苏晓东教授。 除了搜索条,我们还可以利用高级搜索工具更精确的查找。高级搜索可以无限的添加条件。比如发表日期从哪天到哪天,文章类型是 research article 还是 review,语言是英语发表的还是其他语言发表的等等。我们可以查找比如 2000 年至今发表的,题目有 dUTPase 关键词的,英语的,review 文章。一共找到五篇,相信 Jim 同学看完这 5 篇文章之后,一定会对dUPTase 有一个很好的了解。
除了搜索条,我们还可以利用高级搜索工具更精确的查找。高级搜索可以无限的添加条件。比如发表日期从哪天到哪天,文章类型是 research article 还是 review,语言是英语发表的还是其他语言发表的等等。我们可以查找比如 2000 年至今发表的,题目有 dUTPase 关键词的,英语的,review 文章。一共找到五篇,相信 Jim 同学看完这 5 篇文章之后,一定会对dUPTase 有一个很好的了解。 关于 PubMed 还有几点要说明的。在搜索时,可以使用引号。引号里的词会被当作一个整体来看待,而不会被拆开。这个小技巧同样适用于度娘等网络搜索引擎。也可以使用逻辑词 AND OR NOT。比如你可以规定,题目里有 dUPTase,并且题目里有 bacteria,但是作者 里不要有 Smith(dUTPase [TI] AND bacteria [TI] NOT Smith [AU])。此外,如果知名知姓,可以利用正确的名字缩写来提高搜索的准确度。还有非常关键的一点,每篇文章都有自己唯一的 PubMed ID(PMID)。通过这个号,可以直接找到某一篇文章。最后,不 得不说的是,有的时候 PubMed 也帮不了你。比如,搜索 1995 年以前的文献中排名十位以 后的作者是白费力气。搜索 1976 年以前的文献是没有摘要的。搜索 1965 年以前的文献,就 别想了。关于 PubMed 就给大家介绍到这里。
关于 PubMed 还有几点要说明的。在搜索时,可以使用引号。引号里的词会被当作一个整体来看待,而不会被拆开。这个小技巧同样适用于度娘等网络搜索引擎。也可以使用逻辑词 AND OR NOT。比如你可以规定,题目里有 dUPTase,并且题目里有 bacteria,但是作者 里不要有 Smith(dUTPase [TI] AND bacteria [TI] NOT Smith [AU])。此外,如果知名知姓,可以利用正确的名字缩写来提高搜索的准确度。还有非常关键的一点,每篇文章都有自己唯一的 PubMed ID(PMID)。通过这个号,可以直接找到某一篇文章。最后,不 得不说的是,有的时候 PubMed 也帮不了你。比如,搜索 1995 年以前的文献中排名十位以 后的作者是白费力气。搜索 1976 年以前的文献是没有摘要的。搜索 1965 年以前的文献,就 别想了。关于 PubMed 就给大家介绍到这里。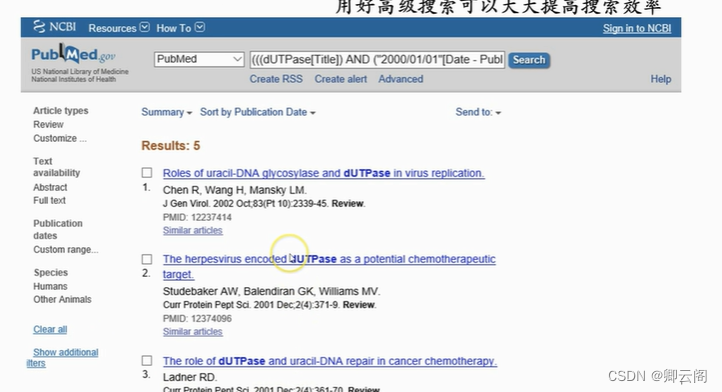
一级核酸数据库:GenBank 原核生物核酸序列(1)
这一节我们来看一级核酸数据库,他主要包括三大核酸数据库和基因组数据库。三大核酸数据库包括 NCBI 的 Genbank,EMBL 的 ENA 和 DDBJ,它们共同构成国际核酸序列数据 库。三大核酸数据库,美国一个,欧洲一个,亚洲一个。美国的 Genbank 由美国国家生物 技术信息中心 NCBI 开发并负责维护。NCBI 隶属于美国国立卫生研究院 NIH。欧洲核苷酸 序列数据集 ENA 由欧洲分子生物学研究室 EMBL 开发并负责维护。亚洲的核酸数据库 DDBJ 由位于日本静冈的日本国立遗传学研究所 NIG 开发并负责维护。Genbank,EMBL 与 DDBJ 共同构成国际核酸序列数据库合作联盟 INSDC。通过 INSDC,三大核酸数据库的信息每日 相互交换,更新汇总。这使得他们几乎在任何时候都享有相同的数据。
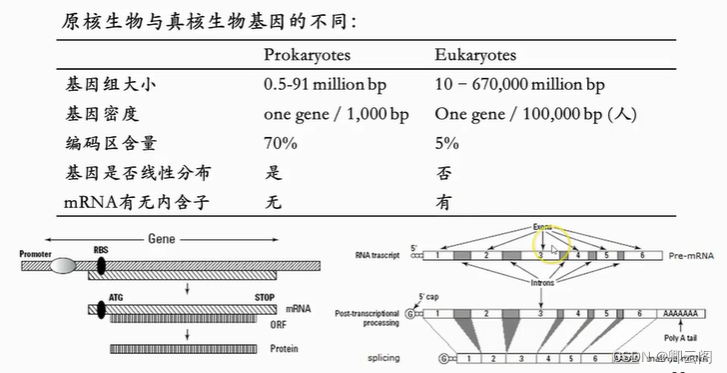
我们以 NCBI 的 Genbank 为例,教你如何解读一级核酸数据库。我们将分别浏览一个原核生物的基因和一个真核生物的基因。为此,请先跟我复习一下原核生物与真核生物基因的不同之处。原核生物基因组小,真核生物基因组大。原核生物基因密度高,1000 个碱基里就有 1 个基因,而真核生物基因密度低,比如人,要 10 万个碱基才有 1 个基因。与此对应, 原核生物编码区含量高,而真核生物低。此外,原核生物的基因是呈线性分布的,而真核生物的基因是非线性的,因为翻译蛋白质的外显子被内含子分隔开来。也就是真核生物的mRNA 要经历剪切的过程,剪切后的成熟 mRNA 才能进行翻译。这是原核生物和真核生物基因的最大区别,即,原核生物没有内含子,真核生物有内含子。这个巨大的区别,将导致两种基因在数据库中不同的存储及注释方式。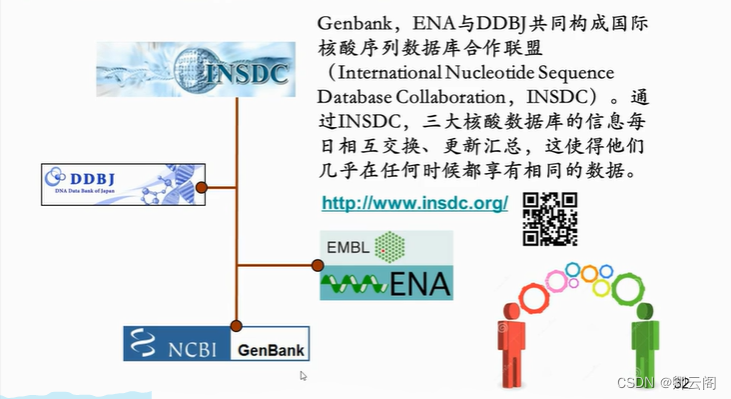
 我们首先来看一条原核生物的 DNA 序列,它是编码大肠杆菌 dUTPase 的基因,在Genbank 里的数据库编号是 X01714。从 NCBI 的主页( http://www.ncbi.nlm.nih.gov/ )选择 Genbank 数据库。Nucleotide 数据库就是 Genbank 数据库,然后在搜索条中直接写入这条序 列对应的数据库编号 X01714,点击“搜索”。结果返回编号为 X01714 的序列在 Genbank 中 详细记录。从这条记录的标题我们得知,dUTPase 是脱氧尿苷焦磷酸酶,编码他的基因叫 dut 基因,所属物种是大肠杆菌。下面是关于这个基因的详细注释,我们逐条浏览一下:
我们首先来看一条原核生物的 DNA 序列,它是编码大肠杆菌 dUTPase 的基因,在Genbank 里的数据库编号是 X01714。从 NCBI 的主页( http://www.ncbi.nlm.nih.gov/ )选择 Genbank 数据库。Nucleotide 数据库就是 Genbank 数据库,然后在搜索条中直接写入这条序 列对应的数据库编号 X01714,点击“搜索”。结果返回编号为 X01714 的序列在 Genbank 中 详细记录。从这条记录的标题我们得知,dUTPase 是脱氧尿苷焦磷酸酶,编码他的基因叫 dut 基因,所属物种是大肠杆菌。下面是关于这个基因的详细注释,我们逐条浏览一下: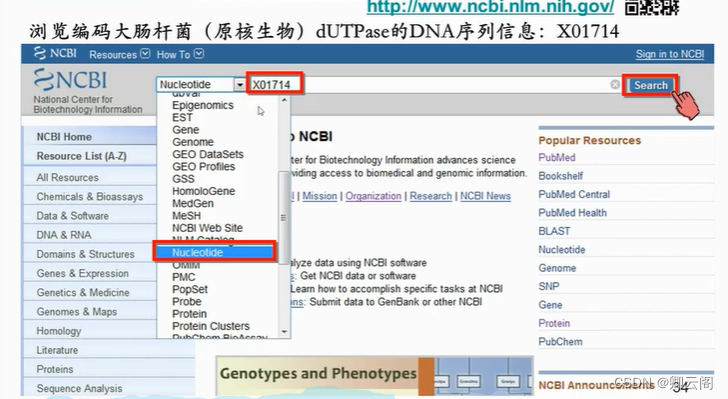 LOCUS 这一行里包括基因座的名字,核酸序列长度,分子的类别,拓扑类型,原核生物的基因拓扑类型都是线性的,最后是更新日期。DEFINITION 是这条序列的简短定义,也就是前面看到的标题。ACCESSION 就是在搜索条中输入的那个数据库编号,也叫做检索号,每条记录的检索号在数据库中是唯一且不变的。即使数据提交者改变了数据内容,Accession 也不会变。你会发现,这条记录里,Accession 和 Locus 是一样的。这是因为这个基因在录入数据库之前并没有起名字,因此录入数据的时候便将检索号作为了基因的名字。但是有些基因,在录入数据库之前已经有了自己的名字,那么这些基因所对应的 Accession 和 Locus 就不一样了。你可以这样理解,Locus 是一个同学的真实姓名,而 Accession 是这个同学的学号。同一个人在不同的学校里会有不同的学号,而名字只有一个。基因也是一样,同一个基因在不同的数据库中会有不同的检索号,而基因的名字只有一个。Version 版本号和 Locus,Accession 长得差不多。版本号的格式是“检索号点上一个数字”。版本号于 1999 年 2 月由三大数据库采纳使用。主要用于识别数据库中一条单一的特定核苷酸序列。在数据库中,如果某条序列发生了改变,即使是单碱基的改变,它的版本号都将增加,而它的 Accession 也就是检索号保持不变。比如,版本号由 U12345.1 变为 U12345.2,而检索号依然是 U12345。版本号后面还有个 GI 号。GI 号与前面的版本号系统是平行运行的。当一条序列改变后,它将被赋予一个新的 GI 号,同时它的版本号将增加。
LOCUS 这一行里包括基因座的名字,核酸序列长度,分子的类别,拓扑类型,原核生物的基因拓扑类型都是线性的,最后是更新日期。DEFINITION 是这条序列的简短定义,也就是前面看到的标题。ACCESSION 就是在搜索条中输入的那个数据库编号,也叫做检索号,每条记录的检索号在数据库中是唯一且不变的。即使数据提交者改变了数据内容,Accession 也不会变。你会发现,这条记录里,Accession 和 Locus 是一样的。这是因为这个基因在录入数据库之前并没有起名字,因此录入数据的时候便将检索号作为了基因的名字。但是有些基因,在录入数据库之前已经有了自己的名字,那么这些基因所对应的 Accession 和 Locus 就不一样了。你可以这样理解,Locus 是一个同学的真实姓名,而 Accession 是这个同学的学号。同一个人在不同的学校里会有不同的学号,而名字只有一个。基因也是一样,同一个基因在不同的数据库中会有不同的检索号,而基因的名字只有一个。Version 版本号和 Locus,Accession 长得差不多。版本号的格式是“检索号点上一个数字”。版本号于 1999 年 2 月由三大数据库采纳使用。主要用于识别数据库中一条单一的特定核苷酸序列。在数据库中,如果某条序列发生了改变,即使是单碱基的改变,它的版本号都将增加,而它的 Accession 也就是检索号保持不变。比如,版本号由 U12345.1 变为 U12345.2,而检索号依然是 U12345。版本号后面还有个 GI 号。GI 号与前面的版本号系统是平行运行的。当一条序列改变后,它将被赋予一个新的 GI 号,同时它的版本号将增加。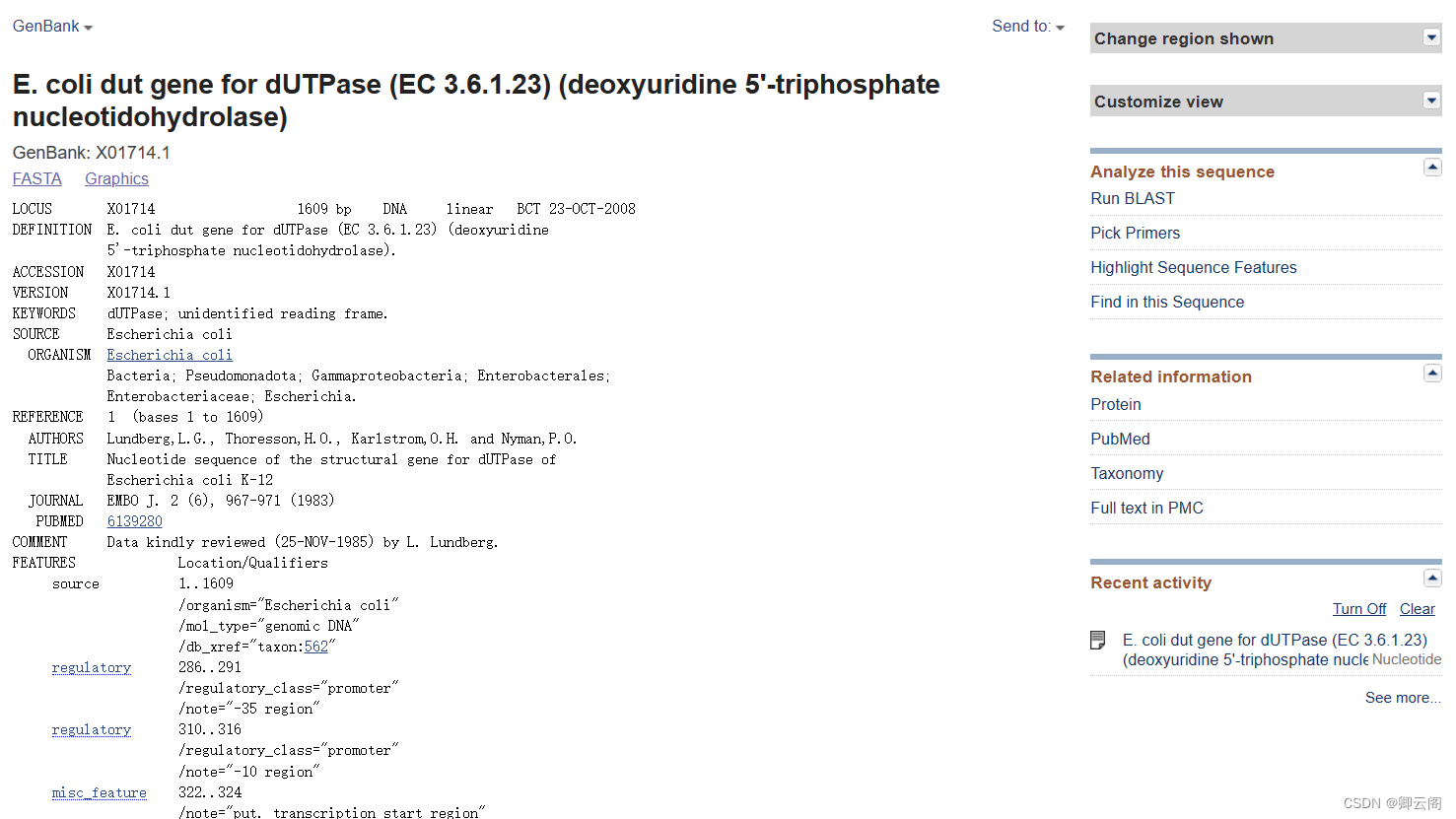 容易混淆的就是 LOCUS,ACCESSION,VERSION 和 GI。后面的都很好理解。KEYWORDS 提供能够大致描述该条目的几个关键词,可用于数据库搜索。SOURCE, 基因序列所属物种的俗名。他下面还有一个子条目, ORGANISM ,是对所属物种更详细的定义,包括他的科学分类。REFERENCE 是基因序列来源的科学文献。有时一条基因序列的不同片段可能来源于不同的文献,那样的话,就会有很多个 REFERENCE 条目出现。REFERENCE 的子条目包括文献的作者、题目和刊物。刊物下面还包括 PubMed ID 作为其子条目。COMMENT 是自由撰写的内容,比如致谢,或者是无法归入前面几项的内容。FEATURES 是非常重要的注释内容,它描述了核酸序列中各个已确定的片段区域,包含很多子条目,比如来源,启动子,核糖体结合位点等等。source 说明了核酸序列的来源,据此可以容易的分辨出这条序列是来源于克隆载体还是基因组。可以看到,当前序列来源于大肠杆菌的基因组 DNA。promoter 列出了启动子的位置。细菌有两个启动子区,-35 区和-10 区。-35 区位于第286 个碱基到第 291 个碱基 ,-10 区位于第 310 个碱基到第 316 个碱基。misc_feature 列出了一些杂项,比如,这条说明了从第 322 个碱基到第 324 个碱基是一个推测的,但无实验证实的转录起始位置。RBS 是核糖体结合位点的位置。CDS ,Coding Segment,编码区。对于原核生物来讲,CDS 记录了一个开放阅读框,从第 343 个碱基开始的起始密码子 ATG 到第 798 个碱基结束的结束密码子 TAA。除了位置信息,还包括翻译产物的诸多信息。翻译产物蛋白的名字是 dUTPase,这个编码区编码该蛋白的第 1 到第 151 个氨基酸。翻译的起始位置和翻译所使用的密码本,以及计算机使用翻译密码本根据核酸序列翻译出的蛋白质序列。需要强调的是,这不是生物自然翻译的,而是计算机翻译的。事实上,蛋白质数据库中的大多数蛋白质序列都是根据核酸序列由计算机根据翻译密码本自动翻译出来的。中间部分是翻译出的蛋白在各种蛋白质数据库中对应的检索号。通过这些检索号可以轻松的链接到其他数据库。此外,X01714 这条核酸序列还包含第二个“潜在的”基因,也就是计算机预测出来的基因。它编码的蛋白目前的数据库里没有详细记录,是个未知的蛋白。像这样,一条核酸序列包含多个基因的情况在 Genbank 里是很常见的。ORIGIN 作为最后一个条目记录的是核酸序列,并以双斜线作为整条记录的结束符。至此整条记录就浏览完了。有时你可能会想要保存这条序列,但是直接从这里拷贝,序列里既有空格,又有数字,不是纯序列,手动删除这些又很麻烦。这时,你可以在这条记录的标题下面找到一个叫做FASTA 的链接。点击他,你会获得 FASTA 格式的核酸序列。FASTA 格式是最常用的序列书写格式,他由两部分组成,第一部分就是第一行,以大于号开始。大于号后面接序列的名称或注释。第二部分就是第二行以后的纯序列部分,这部分只能写序列,不能有其他内容,比如空格,注释,行号之类的都不能在序列部分出现。早期的 FASTA 格式要求序列部分每行60 个字母。但这个规定早已被打破,每行 80,或每行 100,都可以。标题下方,除了 FASTA 链接,还有一个图形化链接,点击可以看到 Features 里的注释信息以图形的形式更直观的展示出来。可以看到这条序列包含的两个基因,他们的启动子的位置,核糖体结合位点的位置等。其中一条基因是编码 dUTPase 的 dut 基因,另一个是编码未知蛋白的潜在的通过计算预测出的基因。如果想要保存这条记录,最好的方法是像保存 PubMed 文献列表那样,点击发送链接,然后选择以纯文本文件的形式保存整条记录到本地电脑上。
容易混淆的就是 LOCUS,ACCESSION,VERSION 和 GI。后面的都很好理解。KEYWORDS 提供能够大致描述该条目的几个关键词,可用于数据库搜索。SOURCE, 基因序列所属物种的俗名。他下面还有一个子条目, ORGANISM ,是对所属物种更详细的定义,包括他的科学分类。REFERENCE 是基因序列来源的科学文献。有时一条基因序列的不同片段可能来源于不同的文献,那样的话,就会有很多个 REFERENCE 条目出现。REFERENCE 的子条目包括文献的作者、题目和刊物。刊物下面还包括 PubMed ID 作为其子条目。COMMENT 是自由撰写的内容,比如致谢,或者是无法归入前面几项的内容。FEATURES 是非常重要的注释内容,它描述了核酸序列中各个已确定的片段区域,包含很多子条目,比如来源,启动子,核糖体结合位点等等。source 说明了核酸序列的来源,据此可以容易的分辨出这条序列是来源于克隆载体还是基因组。可以看到,当前序列来源于大肠杆菌的基因组 DNA。promoter 列出了启动子的位置。细菌有两个启动子区,-35 区和-10 区。-35 区位于第286 个碱基到第 291 个碱基 ,-10 区位于第 310 个碱基到第 316 个碱基。misc_feature 列出了一些杂项,比如,这条说明了从第 322 个碱基到第 324 个碱基是一个推测的,但无实验证实的转录起始位置。RBS 是核糖体结合位点的位置。CDS ,Coding Segment,编码区。对于原核生物来讲,CDS 记录了一个开放阅读框,从第 343 个碱基开始的起始密码子 ATG 到第 798 个碱基结束的结束密码子 TAA。除了位置信息,还包括翻译产物的诸多信息。翻译产物蛋白的名字是 dUTPase,这个编码区编码该蛋白的第 1 到第 151 个氨基酸。翻译的起始位置和翻译所使用的密码本,以及计算机使用翻译密码本根据核酸序列翻译出的蛋白质序列。需要强调的是,这不是生物自然翻译的,而是计算机翻译的。事实上,蛋白质数据库中的大多数蛋白质序列都是根据核酸序列由计算机根据翻译密码本自动翻译出来的。中间部分是翻译出的蛋白在各种蛋白质数据库中对应的检索号。通过这些检索号可以轻松的链接到其他数据库。此外,X01714 这条核酸序列还包含第二个“潜在的”基因,也就是计算机预测出来的基因。它编码的蛋白目前的数据库里没有详细记录,是个未知的蛋白。像这样,一条核酸序列包含多个基因的情况在 Genbank 里是很常见的。ORIGIN 作为最后一个条目记录的是核酸序列,并以双斜线作为整条记录的结束符。至此整条记录就浏览完了。有时你可能会想要保存这条序列,但是直接从这里拷贝,序列里既有空格,又有数字,不是纯序列,手动删除这些又很麻烦。这时,你可以在这条记录的标题下面找到一个叫做FASTA 的链接。点击他,你会获得 FASTA 格式的核酸序列。FASTA 格式是最常用的序列书写格式,他由两部分组成,第一部分就是第一行,以大于号开始。大于号后面接序列的名称或注释。第二部分就是第二行以后的纯序列部分,这部分只能写序列,不能有其他内容,比如空格,注释,行号之类的都不能在序列部分出现。早期的 FASTA 格式要求序列部分每行60 个字母。但这个规定早已被打破,每行 80,或每行 100,都可以。标题下方,除了 FASTA 链接,还有一个图形化链接,点击可以看到 Features 里的注释信息以图形的形式更直观的展示出来。可以看到这条序列包含的两个基因,他们的启动子的位置,核糖体结合位点的位置等。其中一条基因是编码 dUTPase 的 dut 基因,另一个是编码未知蛋白的潜在的通过计算预测出的基因。如果想要保存这条记录,最好的方法是像保存 PubMed 文献列表那样,点击发送链接,然后选择以纯文本文件的形式保存整条记录到本地电脑上。
【bioinformation 2】生物数据库
news2026/2/14 13:56:49






本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1485527.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【新书推荐】11.1 子程序设计
第十一章 子程序及参数传递 本章先讲述子程序设计的方法,然后介绍在子程序调用中参数的四种传递方法。
11.1 子程序设计
在前面的示例和练习中,会发现程序中会有一些反复使用到的代码片段。我们将程序中反复出现的程序片段设计成子程序,这样…
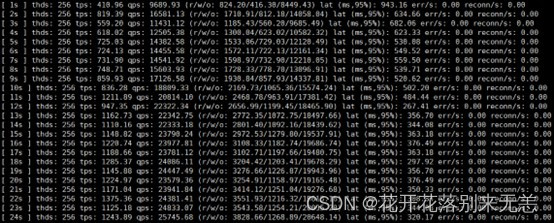
DM数据库学习之路(十九)DM8数据库sysbench部署及压力测试
sysbench部署 安装依赖
yum -y install make automake libtool pkgconfig libaio-devel vim-common 上传sysbench源代码
sysbench_tool.tar 测试是否安装成功
$ /opt/sysbench/sysbench-master-dpi/src/lua
$ ./sysbench --version
sysbench 1.1.0 sysbench测试DM 测试…
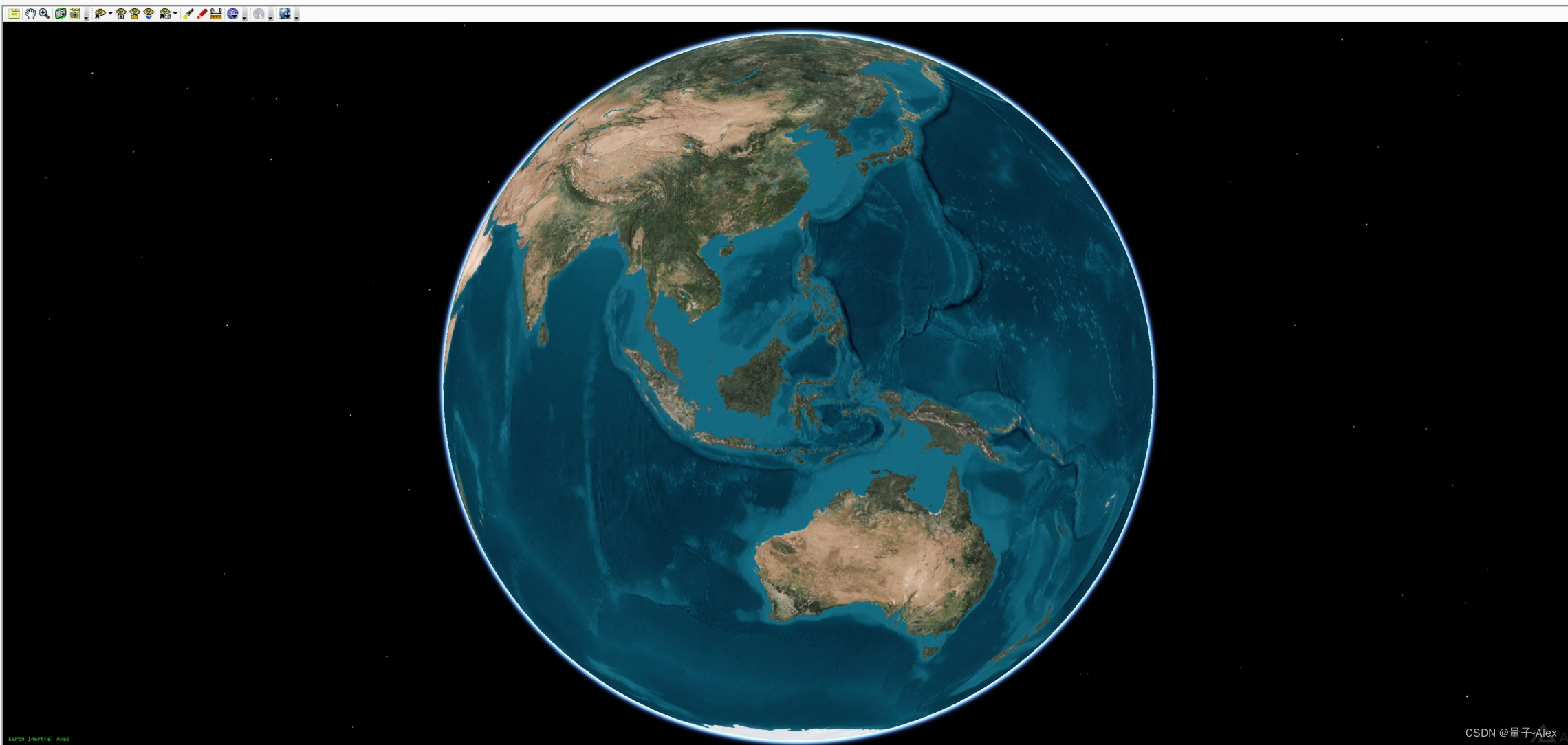
【STK】手把手教你利用STK进行仿真-STK软件基础02 STK系统的软件界面01 STK的界面窗口组成
STK系统是Windows窗口类型的桌面应用软件,功能非常强大。在一个桌面应用软件中集成了仿真对象管理、仿真对象属性参数、设置、空间场景二三维可视化、场景显示控制欲操作、仿真结果报表定制与分析、对象数据管理、仿真过程控制、外部接口连接和系统集成编程等复杂的功能。 STK…
MyBatis源码分析之基础支持层解析器
(/≧▽≦)/~┴┴ 嗨~我叫小奥 ✨✨✨ 👀👀👀 个人博客:小奥的博客 👍👍👍:个人CSDN ⭐️⭐️⭐️:传送门 🍹 本人24应届生一枚,技术和水平有限&am…

录制用户操作实现自动化任务
先上视频!! 流程自动化工具-录制操作绘制流程 这个想法之前就有了,趁着周末时间给它撸出来。
实现思路
从之前的文章自动化桌面未来展望中已经验证了录制绘制流程图的可行性。基于DOM录制页面操作轨迹的思路监听页面点击、输入事件即可&…

蓝桥杯练习题——二分
1.借教室 思路
1.随着订单的增加,每天可用的教室越来越少,二分查找最后一个教室没有出现负数的订单编号 2.每个订单的操作是 [s, t] 全部减去 d
#include<iostream>
#include<cstring>
using namespace std;
const int N 1e6 10;
int d[…

Linux之相对路径、绝对路径、特殊路径符
相对路径和绝对路径 cd /root/temp 绝对路径写法 cd temp 相对路径写法 1、绝对路径:以根目录为起点,描述路径的一种写法,路径描述以 / 开头。
2、相对路径:以当前目录为起点,路径描述无需以 / 开头。 特殊路径符 如…

cRIO9040中NI9871模块的测试
硬件准备
CompactRIO9040NI9871直流电源(可调)网线RJ50转DB9线鸣志STF03-R驱动器和步进电机
软件安装
参考:cRIO9040中NI9381模块的测试
此外,需安装NI-Serial 9870和9871扫描引擎支持
打开NI Measurement&Automa…

C++之set、multiset
1、set简介 set是一种关联式容器,包含的key值唯一,所有元素都会在插入时自动被排序,其存储结构为红黑树。set只能通过迭代器(iterator)访问。
set和multiset的区别:
(1)set不允许容器中有重复的元素&…

C++_程序流程结构_选择结构_if
程序流程结构
C/C支持最基本的三种程序运行结构:顺序、选择、循环结构
顺序结构:程序按顺序执行,不发生跳转选择结构:依据条件是否满足,有选择地执行相应功能循环结构:依据条件是否满足,循环多…

跟 AI 学 StarRocks:简介
因为要支持公司的 BI 建设,团队引入了 StarRocks 数据库,此前我没有了解过此项技术,不过因为有架构师引入了此项技术栈,就顺便学习一下。
一、什么是 MPP 数据库?
MPP 数据库指的是大规模并行处理(Massiv…
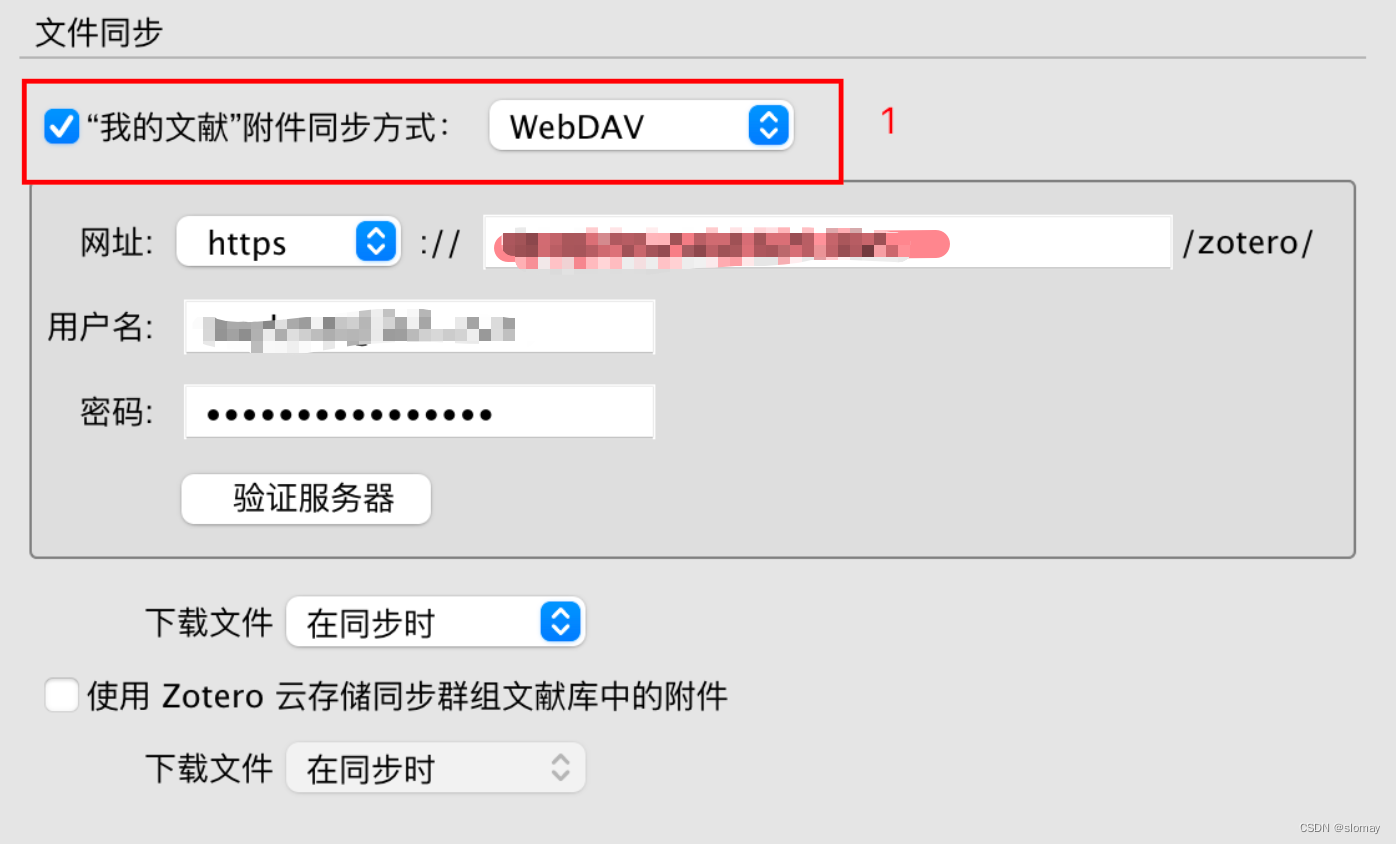
zotero | 多平台同步 | 坚果云
zotero注册登陆 打开zotero软件,mac电脑打开首选项,如下图所示: 然后点击同步选项,如下图所示,如果已经有账号,请登陆账号,无则注册账号之后再登陆;
注册坚果云账号
注册完坚果…

QT6 libModbus 用于ModbusTcp客户端读写服务端
虽然在以前的文章中多次描述过,那么本文使用开源库libModbus,可得到更好的性能,也可移植到各种平台。
性能:读1次和写1次约各用时2ms。
分别创建了读和写各1个连接指针,用于读100个寄存器和写100个寄存器,读写分离。
客户端&am…
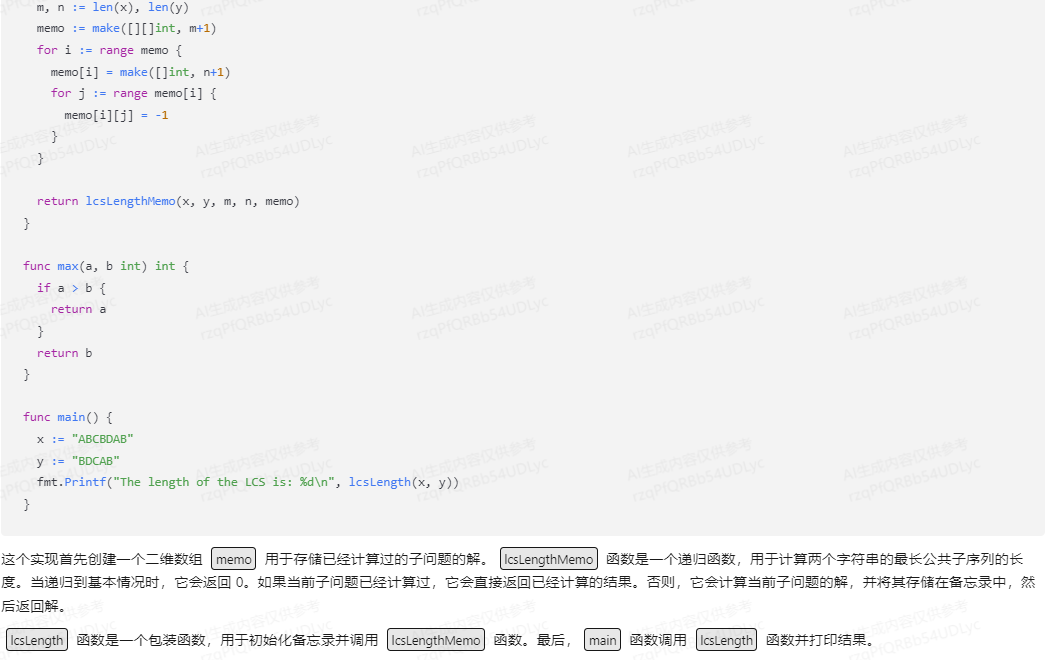
文心一言 VS 讯飞星火 VS chatgpt (206)-- 算法导论15.4 3题
三、设计 LCS-LENGTH的带备忘的版本,运行时间为O(mn)。需要写代码的时候,请用go语言。
文心一言,代码正常运行:
LCS-LENGTH(Longest Common Subsequence Length)问题的带备忘的版本通常指的是使用动态规划…

备考2024年小学生古诗文大会:历年真题15题练习和独家解析
如何提高小学生古诗词的知识?如何激发小学生古诗词的学习兴趣?如何提高小学古诗词的学习成绩?如何备考2024年小学生古诗文大会?...
如果你也在关注这些问题,我的建议是参加每年一度的小学生古诗词大会(免费…

金融行业专题|期货超融合架构转型与场景探索合集(2023版)
更新内容:
更新 SmartX 超融合在期货行业的覆盖范围、部署规模与应用场景。新增 CTP 主席系统实践与评测、容器云资源池等场景实践。更多超融合金融核心生产业务场景实践,欢迎下载阅读电子书《SmartX 金融核心生产业务场景探索文章合集》。
面对不断变…
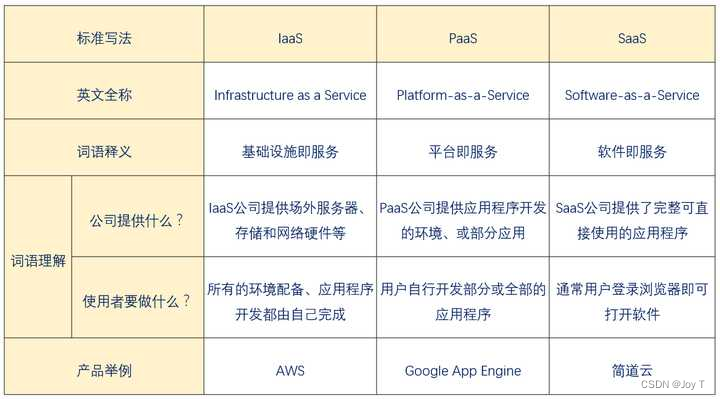
云计算与大数据课程笔记(一)云计算背景与介绍
如何实现一个简易搜索引擎?
实现一个简易的搜索引擎可以分为几个基本步骤:数据收集(爬虫)、数据处理(索引)、查询处理和结果呈现。下面是一个概括的实现流程:
1. 数据收集(爬虫&am…
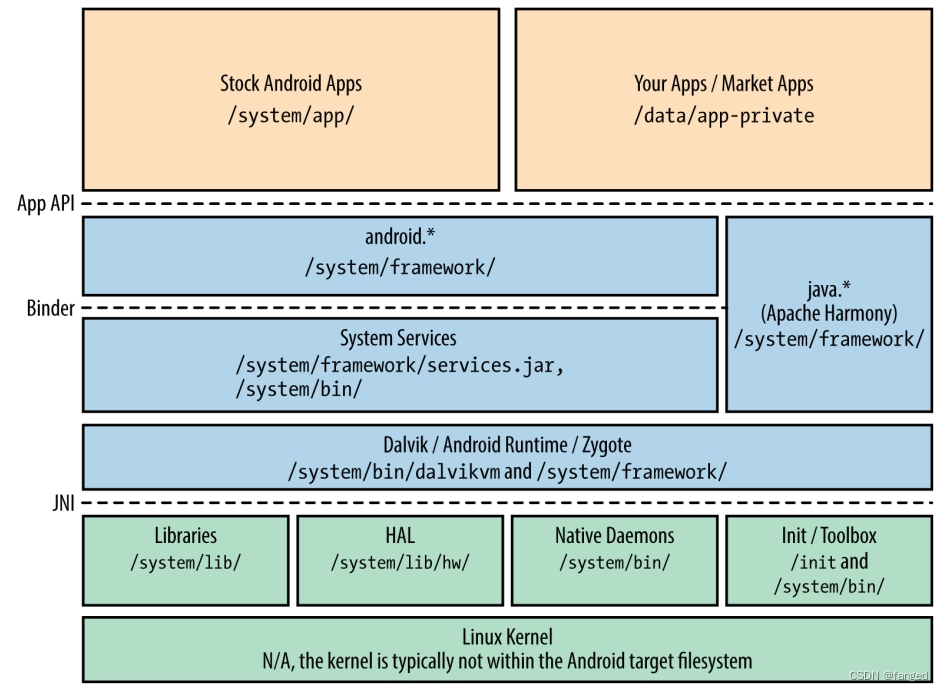
Android和Linux的嵌入式开发差异
最近开始投入Android的怀抱。说来惭愧,08年就听说这东西,当时也有同事投入去看,因为恶心Java,始终对这玩意无感,没想到现在不会这个嵌入式都快要没法搞了。为了不中年失业,所以只能回过头又来学。
首先还是…

MySQL 常用优化方式
MySQL 常用优化方式 sql 书写顺序与执行顺序SQL设计优化使用索引避免索引失效分析慢查询合理使用子查询和临时表列相关使用 日常SQL优化场景limit语句隐式类型转换嵌套子查询混合排序查询重写 sql 书写顺序与执行顺序 (7) SELECT
(8) DISTINCT <select_list>
(1) FROM &…