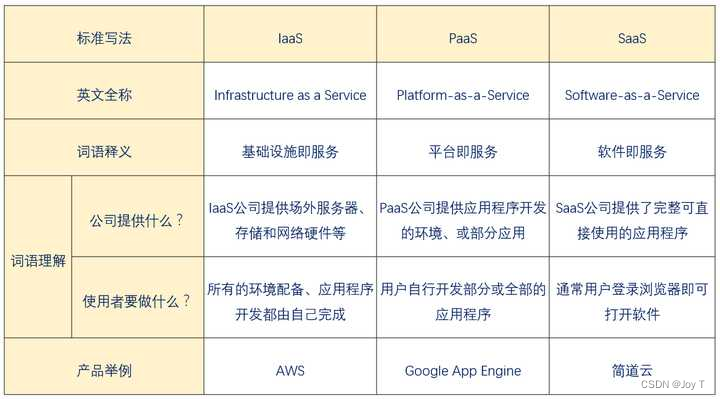
如何实现一个简易搜索引擎?
实现一个简易的搜索引擎可以分为几个基本步骤:数据收集(爬虫)、数据处理(索引)、查询处理和结果呈现。下面是一个概括的实现流程:
1. 数据收集(爬虫)
- 目标:从互联网上收集信息,这通常通过编写爬虫程序实现,爬虫会访问网页,读取内容,然后将这些内容存储起来。(无论是简单还是复杂的搜索引擎,其页面、视频、图片等数据都不是现查现展示的,那样效率非常慢。这就涉及到像页面数据这种半结构化数据的存储问题,数据量越来越大的时候,云计算就发挥出了作用)
- 实现:选择合适的编程语言(如Python),使用爬虫库(如Scrapy或BeautifulSoup)来开发爬虫脚本。爬虫程序会根据预定的规则自动浏览网页,提取有用信息,并将这些信息保存到数据库或文件系统中。
2. 数据处理(索引)
- 目标:对收集到的数据进行处理,生成可以快速查询的索引。索引的目的是加快搜索速度,类似于书的目录。
- 实现:处理包括文本清洗(去除HTML标签等)、分词(将文本分割成关键词)、建立倒排索引等。倒排索引是一种将关键词映射到包含该关键词的文档列表的数据结构。可以使用Elasticsearch、Apache Lucene等工具来实现索引。
3. 查询处理
- 目标:接收用户的查询请求,根据索引快速找到匹配的结果。
- 实现:开发一个简单的查询接口,接收用户的搜索请求,然后根据倒排索引查找相关的文档。这一步可以通过简单的关键词匹配,也可以采用更复杂的算法(如TF-IDF、向量空间模型等)来提高搜索的相关性和准确性。
4. 结果呈现
- 目标:将搜索结果以友好的方式呈现给用户。
- 实现:设计一个简单的网页界面,显示搜索结果。这通常包括结果列表,每个结果有标题、摘要、链接等信息。可以使用HTML、CSS和JavaScript等前端技术来实现界面设计。
谷歌又是如何实现搜索引擎的?
谷歌搜索引擎的实现相比于简易搜索引擎要复杂得多,它涵盖了大规模数据处理、复杂算法、用户行为分析、机器学习等众多领域。谷歌搜索引擎的核心包括以下几个方面:
1. 爬虫系统(Googlebot)
谷歌使用一个高效的网络爬虫(Googlebot)来不断地爬取互联网上的内容。这个过程包括新网页的发现和已知网页的更新。Googlebot高效地处理巨量的网页,使用分布式系统来存储和管理这些数据。
2. 索引构建
谷歌对爬取到的网页内容进行处理,包括解析HTML内容、执行JavaScript(以获取动态生成的内容)、提取文本和关键数据等。然后,谷歌构建一个巨大的倒排索引,将关键词与它们出现的网页相关联,这个索引是分布式存储的,以支持快速查询。
3. 排名算法(PageRank及其他)
谷歌使用PageRank算法及其它多种算法来评估网页的重要性和相关性。PageRank算法基于网页之间的链接结构,给网页一个全球重要性的评分。除了PageRank,谷歌还考虑了数百个其它因素(如网页的相关性、内容质量、用户行为、页面速度等)来综合排名搜索结果。
4. 查询处理
当用户提交查询时,谷歌使用复杂的算法来解析查询意图,可能包括自然语言处理技术来理解查询的真正意图。然后,系统会在倒排索引中查找与查询相关的网页,并使用排名算法对这些结果进行排序。
5. 个性化和上下文相关搜索
谷歌还会考虑用户的搜索历史、地理位置、设备类型等因素来个性化搜索结果。这意味着不同的用户在输入相同查询时可能会看到不同的搜索结果。
6. 用户界面和体验
谷歌不断地优化其搜索界面和用户体验,包括快速的响应时间、清晰的结果展示、以及对移动设备的优化。
7. 安全性和隐私
谷歌还非常重视搜索过程中的安全性和用户隐私,包括使用HTTPS加密搜索请求和结果,以及提供透明的隐私控制选项给用户。
技术和工具
谷歌的搜索引擎背后使用了大量的自研技术和开源工具,涵盖了大数据处理(如Bigtable和MapReduce)、机器学习(如TensorFlow)、高性能网络架构等多个方面。
谷歌搜索引擎的实现涉及广泛的技术栈和复杂的系统设计。它不仅仅是一个简单的文本搜索问题,而是一个涉及大规模数据处理、算法优化、用户体验和隐私保护等多个领域的综合系统。随着互联网技术的发展,谷歌不断地更新和优化其搜索引擎,以提供更快、更准确、更个性化的搜索结果。
云计算背景
大数据一般是半结构化数据和非结构化数据
- 解释:大数据通常包括三种类型的数据:结构化数据、半结构化数据和非结构化数据。
- 结构化数据:指的是可以在关系型数据库中存储、查询和分析的数据,如表格数据。
- 半结构化数据:不符合关系型数据库的结构,但包含标签或其它标记性语言来识别数据的某些元素。例如,JSON和XML文件。
- 非结构化数据:没有预定义数据模型,也不易在传统数据库中存储或管理。如文本文件、图片、视频等。
- 大数据环境下,非结构化和半结构化数据占据了数据总量的大部分,这对数据存储、处理和分析提出了更高的要求。
网页数据修改不频繁,和表的业务特征是不一样的
- 解释:这句话提到了数据的变化频率,特别是指网页数据相比于数据库中表的数据,更新或修改的频率不高。
- 网页数据:往往是静态或半静态的,如公司信息、新闻发布等,这些信息不经常变化。
- 数据库表数据:在业务应用中,如电商平台的订单信息、用户数据等,这些数据变化频繁,需要实时或近实时更新。
- 数据的变化频率直接影响了数据存储和管理系统的设计和优化策略。
现在新兴的很多云原生数据库对传统数据库造成很大冲击
- 解释:随着云计算技术的发展,云原生数据库成为了新兴的数据库解决方案,它们为分布式环境和云平台优化,提供了高可扩展性、高可用性和全球分布式的能力。
- 云原生数据库:如Amazon DynamoDB、Google Cloud Spanner等,它们天生为云设计,支持弹性伸缩、跨地域复制等功能。
- 传统数据库:如Oracle、MySQL等,虽然也可以部署在云环境中,但它们最初是为单一物理环境设计的,可能在可扩展性、分布式处理方面存在局限。无外乎还是历史和出身变了,时代啊……
- 云原生数据库的兴起对传统数据库市场和使用模式造成了冲击,促使传统数据库不断创新和适应云计算的要求。
大数据价值密度低!06年谷歌公司提出云计算的概念,之前用的是关系型数据库
- 解释:这句话指出大数据的一个特点是“价值密度低”,意味着在大量的数据中,有价值的信息可能只占很小的比例。这个观点在谷歌等公司的实践中得到了体现,它们发现使用传统的关系型数据库处理大数据时面临着效率和成本的挑战。
- 价值密度低:需要通过大规模的数据处理和分析,才能从大量数据中提取有价值的信息。
- 关系型数据库:虽然在事务处理、数据一致性等方面有优势,但在处理非结构化数据、实现高度可扩展的分布式存储和计算时可能不够高效。
- 谷歌等公司的实践促进了NoSQL数据库(如Google Bigtable)和分布式计算平台(如Hadoop)的发展,这些技术更适合处理大数据的特点。
云计算介绍
云计算是一种革命性的技术,它改变了企业和个人获取和使用计算资源的方式。作为一种工业界的导向,云计算提供了一种商业服务,通过大量计算机构成的分布式系统资源,形成了资源池,允许用户按需访问计算力、存储空间和各种服务,而无需关心底层的物理硬件。
云计算资源的本质
云计算背后提供的计算力本质上是物理CPU和GPU等资源的集合。这些资源通过虚拟化技术被封装,使得用户可以灵活地使用它们进行计算任务。虚拟化技术解决了操作系统(OS)和主机之间紧耦合的问题,允许在同一硬件上运行多个虚拟机,每个虚拟机都可以运行不同的操作系统和应用。
云计算的应用场景
云计算的应用场景多样,包括但不限于:
- 定点计算:主要用于处理事务数据和超大规模数据处理。适用于需要高可靠性和一致性的场景,如金融交易、大型数据库管理等。
- 浮点计算:主要用于峰值计算和超速计算机,如科学计算、图形处理和机器学习等领域,其中需要大量的浮点运算来处理复杂的计算任务。
云计算服务的提供商
云计算服务的提供商众多,其中包括阿里云、华为云、亚马逊AWS等。每个提供商根据自身的企业导向和专长,提供不同的云计算服务:
- 阿里云:作为电商巨头,阿里巴巴提供了强大的云计算资源,支持其庞大的电商业务。同时,阿里云也支持其他企业和服务,比如为中国铁路客户服务中心(12306)提供巨大的云计算资源支持,保障其在高峰期的稳定运行。
- 华为云:华为云在政务和企业服务领域有较多应用,提供包括云服务器、云数据库、云安全等全面的服务,帮助政府和企业实现数字化转型。
云计算技术的发展受到了前期研究和实践的启发,其中Hadoop就是一个典型的例子。Hadoop的开发源于雅虎的几位程序员受到谷歌的GFS(Google File System)、MapReduce和BigTable几篇论文的启发。Hadoop成为了处理大数据的一个重要工具,体现了云计算在数据处理方面的能力。
云计算总结
云计算作为一种商业服务,通过虚拟化技术和分布式系统将庞大的计算资源汇集成资源池,为用户提供按需可扩展的服务。它在不同的行业和领域内发挥着重要作用,无论是支持电商平台的大规模运营,还是为政府部门提供云服务,云计算都在推动着数字化转型和技术创新。随着技术的不断进步和应用场景的拓展,云计算将继续在工业界引领新的变革。
云计算相关公司盈利模式
亚马逊、谷歌是一种互连网公司,它们的盈利模式是什么?微软的盈利应该主要靠软件售卖与AI算力支持投入吧?
亚马逊、谷歌和微软是互联网时代的三大巨头,它们的盈利模式覆盖了广泛的领域,包括但不限于电子商务、广告、云计算、软件销售和人工智能。下面是对它们各自盈利模式的简要分析:
亚马逊
亚马逊的盈利模式多元化,包括:
- 电子商务:亚马逊通过在线销售商品赚取收入,包括自营和第三方卖家的产品。
- 云计算:亚马逊云计算服务(Amazon Web Services, AWS)是全球最大的云服务提供商之一,为企业提供服务器、存储、数据库、分析、机器学习、和其他云服务。
- 订阅服务:包括Amazon Prime会员服务、音乐和视频流媒体服务等。
- 广告业务:通过其庞大的电商平台,亚马逊还提供广告服务给卖家和品牌。
- 其他服务:包括Kindle电子书、Alexa智能家居设备等。
谷歌
谷歌(Alphabet Inc.的一部分)的盈利模式主要基于广告,同时也涉及其他多个领域:
- 广告:谷歌搜索引擎、YouTube视频平台、Google Maps等服务通过广告赚取大部分收入。
- 云计算:Google Cloud Platform提供各种云服务,包括计算、数据存储、机器学习等。
- 软件和服务:包括Android操作系统、Google Play应用商店、G Suite办公软件等。
- 硬件:包括Pixel手机、Nest智能家居产品等。
微软
微软的盈利模式也是多元化的,并不仅限于软件销售和AI算力支持,它的云计算服务、订阅服务和硬件销售也是重要的收入来源。
主要包括:
- 软件销售:Windows操作系统、Office办公软件套件是微软的传统盈利来源。
- 订阅服务:Office 365、Microsoft 365等订阅服务为微软提供了稳定的收入流。
- 云计算:通过Azure提供的云服务,微软在全球云计算市场中占据重要地位。
- 硬件:包括Surface系列设备、Xbox游戏机等。
- 人工智能和其他技术投入:微软在人工智能领域有大量投入,包括云AI服务、GitHub等开发者服务。
另一种分布式计算形式——网格计算
网格计算(Grid Computing)是一种分布式计算形式,它涉及将计算任务分解成更小的部分,然后在跨越多个计算资源(如个人计算机、服务器或者数据中心内的服务器)的网络上并行处理这些部分。网格计算的目的是通过利用网络连接的不同计算资源来解决大规模的计算问题,特别是那些对单个计算机或本地网络资源来说过于复杂的任务。
网格计算与云计算的区别
网格计算和云计算虽然都是分布式计算的形式,但它们在目标、架构和应用场景上有所不同:
目标和用途:网格计算主要关注于大规模科学、工程和企业级计算任务的处理,特别是那些需要大量计算资源但不一定需要存储资源的任务。云计算则提供了一种更为通用的计算模型,支持各种类型的应用,包括数据存储、处理、分析和托管服务。
资源管理:网格计算通常涉及将任务分配给网络中的多个计算资源,这些资源可能属于不同的组织,并由各自独立管理。云计算则由单一的服务提供商提供资源,用户可以通过网络按需获取计算资源,无需关心资源的物理位置或底层架构。
使用模式:网格计算的用户通常是科研机构和大学等,它们需要处理复杂的计算任务,如气候模拟、基因序列分析等。而云计算服务面向更广泛的用户群体,从个人到企业,覆盖了从简单的网站托管到复杂的企业应用。
计费模式:云计算通常基于用户实际使用的资源(如计算时间、存储空间)来计费,提供弹性伸缩的服务模型。网格计算则更多关注于资源共享和合作,计费模式不是主要考虑的因素。(我觉得这种高尚的初衷最后导致的成本问题也是网格计算不能很好落地实施的主要原因之一)
网格计算的应用
网格计算被用于解决一系列需要巨大计算能力的问题,包括:
- 科学研究:如蛋白质折叠、宇宙学研究、气候变化模拟等。
- 工程问题:如大型结构分析、流体动力学模拟等。
- 金融建模:如风险分析、复杂的金融衍生品定价等。
网格计算是一种旨在通过网络连接的多个计算资源来解决复杂计算问题的技术。与云计算相比,网格计算更注重于计算能力的共享,特别适用于科学研究和复杂工程计算等领域。随着云计算的发展,一些原本网格计算的应用场景已经开始转向更为灵活和易于管理的云计算平台,但网格计算在某些特定领域仍然有其独特的价值和应用。




![[c++] c++ 中的顺序(构造,析构,初始化列表,继承)](https://img-blog.csdnimg.cn/direct/839bf38b9a014664b66372bed6ef34a6.png)