Paper name
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
Paper Reading Note
URL: https://arxiv.org/pdf/2005.04259.pdf
TL;DR
- waymo 出品的 CVPR2020 论文 ,关注在自动驾驶场景(复杂多智能体系统)下的行为预测问题,探索是否能从结构化(矢量化形式)的 HD map 中直接学习场景语义特征,使用 GNN 来从输入的矢量化信息中提取特征实现了上述目标。
Introduction
背景
- 本文关注在自动驾驶场景(复杂多智能体系统)下的行为预测问题。这需要有一个对前置感知系统检测跟踪框及场景信息(HD map)进行结合的统一表达方式。
- 传统的行为预测主要有:
- rule-based:多个车辆的行为在地图约束的假设下进行轨迹预测
- learining-based:提供了对不同行为假设进行概率解释的好处,但需要构建一个表示来编码地图和轨迹信息;将 HD map 渲染为图片,如下左图,这需要人为设定,同时利用 cnn 提取场景语义信息,这种方式受限于 CNN 的感受野
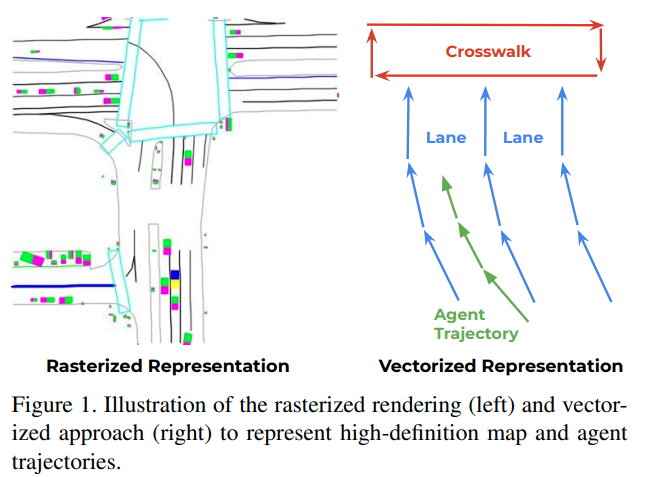
- 本文希望探索是否能从结构化(矢量化形式)的 HD map 中直接学习场景语义特征
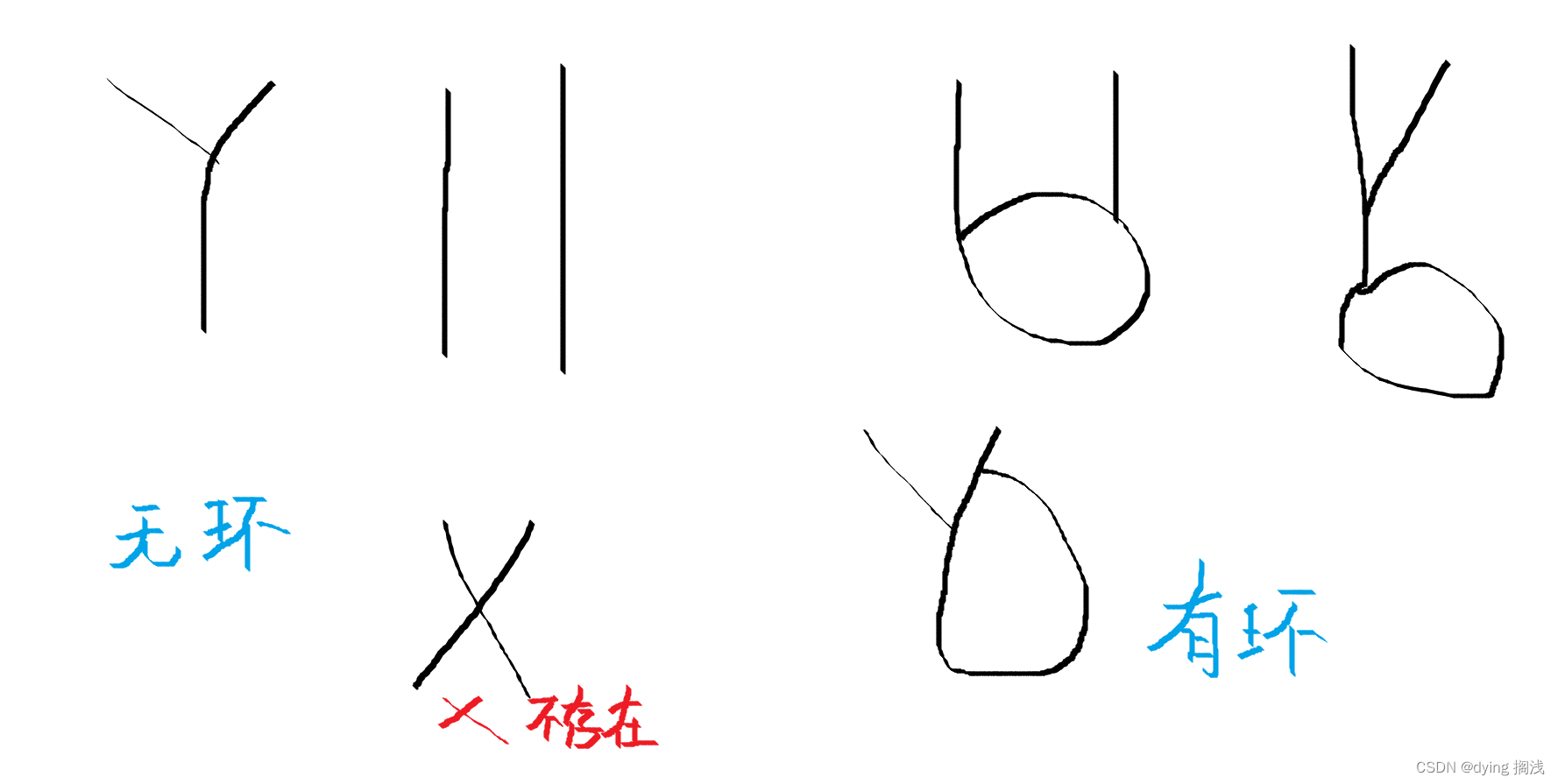
- 道路要素的地理范围可以是地理坐标中的点、多边形或曲线:车道可以表示成由多个控制点构成的样条曲线;人形横道是一个由几个点构成的多边形;路标是一个点
- 以上所有元素都可以由多个控制点构成的多段线(polylines)表示
本文方案
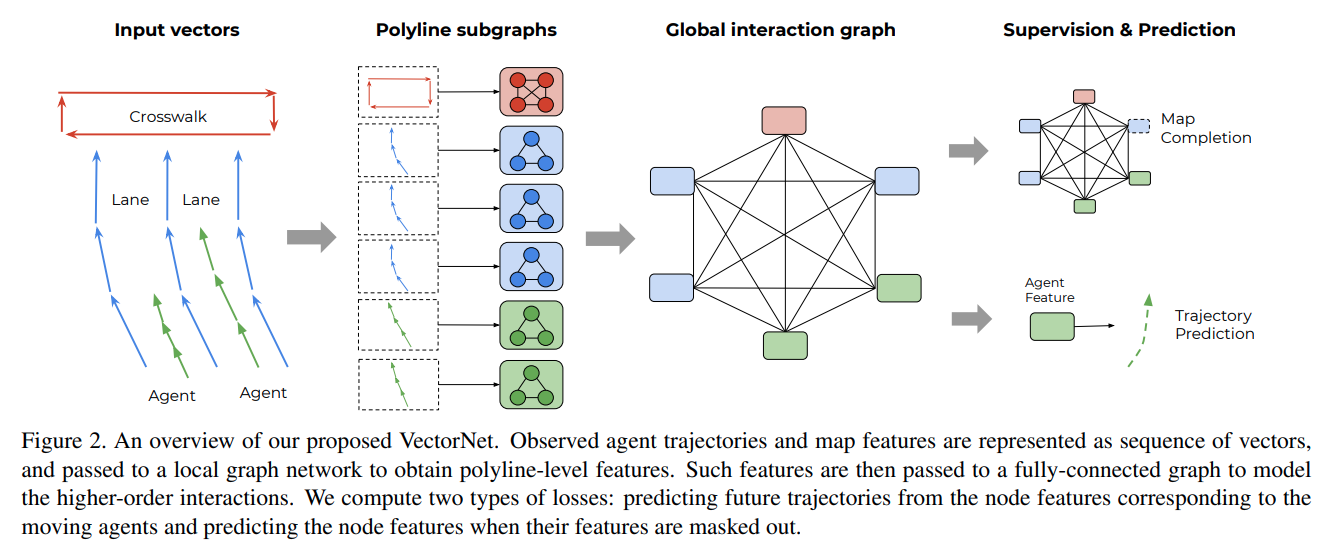
- 使用 GNN 来从输入的矢量化信息中提取特征:
- 将每个 vector 作为图中的节点,节点的特征是 vector 的起始和位置、终止位置和其他属性(polylin group id 和语义标注)
- 来自HD地图的上下文信息以及其他 agent 的轨迹通过 GNN 传播到目标节点
- 将目标节点的输出特征 decode 为未来轨迹
Dataset/Algorithm/Model/Experiment Detail
实现方式
轨迹和地图的 vector 表示
- vector 提取
- map feature:挑选一个起点和方向,在样条曲线上等空间间隔采样,将各个点连成 vector
- trajectories:等时间间隔采样,从t=0开始往后连成 vector
- polyline 中的每个点在 graph 中作为一个 node(with feature),其具体表示为
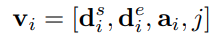
其中 d i s d_{i}^{s} dis , d i e d_{i}^{e} die 分别是 vector 的起始点和终止点;a 是属性特征(比如目标类别、时间戳、轨迹、路面属性、车道限速);j 是 polyline 的 id,即代表这个 node 属于哪个 polyline - 为了使输入节点特征不随着目标 agents 的位置有变化,规范化了所有向量的坐标,使其以目标 agents 最后一个观察到的时间步长的位置为中心
- 未来的工作是共享所有交互 agents 的坐标中心,以便可以并行预测它们的轨迹
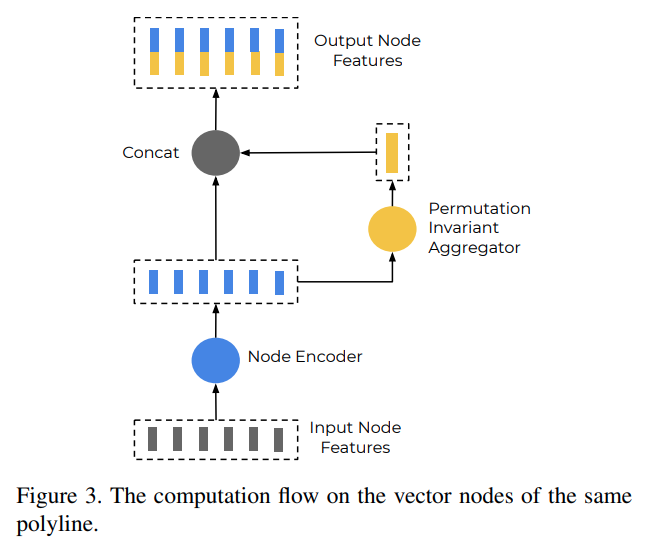
polyline 子图构造
-
对于每个 polyline 构造一个 vector 级别的子图,然后提取每个 node 的特征
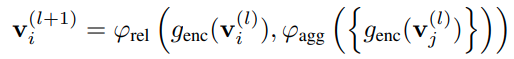
这代表 l 层特征得到 l+1 层特征的方式。genc 得到每个 node 的特征,用 MLP 实现;agg 是用于聚合所有临接节点的特征,用 maxpooling 实现;rel 用于连接各节点的关系,用 concat 实现 -
基于提取得到的各个 node 的特征,聚合得到 polyline 的特征
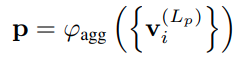
agg 是 maxpooling 实现 -
与 PointNet 关系:
- 可以看成是 PointNet 更通用的形式
- ds = de 并且 a 和 l 是空的情况下等同于 PointNet
- 作者认为这种实现更利于结构化的地图表示和 agent 轨迹的特征提取
全局图构造
-
基于 global interaction graph 提取 polyline 的特征
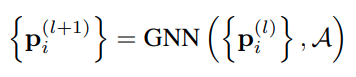
GNN 是图网络的一层,A 代表 polyline node 的邻接矩阵,可以提供启发,比如利用节点间的空间距离;GNN 基于自注意力实现
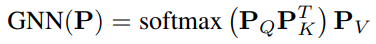
-
基于 GNN 输入的 polyline 的特征 decode 得到预测轨迹
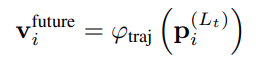
traj 是轨迹 decoder,基于 MLP 实现 -
参考 BERT 等自监督训练思路提出一个辅助的自监督训练损失:随机对 polyline 进行mask操作,然后基于一个额外的 decoder 来对 mask 后的 polyline 进行补全
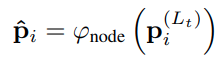
node 就是补全的decoder,测试时不用
整体训练框架
- 多任务训练损失
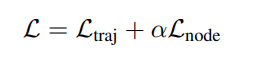
其中 traj 是与 gt 轨迹的负高斯对数似然;node 是补全的 node 特征与gt node 特征的 huber loss;为了防止 node 特征越来越小的 trival 解,polyline node 输入 global graph 网络之前进行 l2 norm - 预测的轨迹被参数化为与最后时刻位置的坐标偏移量
- 根据目标车辆在最后观察位置的方向旋转坐标系
实验结果
Argoverse 数据集
- 333k 个轨迹,211k 训练,41k验证,80k测试
- 每个轨迹 5s,基于前 2s 预测后 3s,10Hz采样
- 感知模型得到跟踪预测框
In-house 数据集
- HD map、bbox、tracks 信息由感知算法得到,人工标注车辆轨迹
- 2.2M 训练数据,0.55 M 测试数据
- 每个轨迹 4s,基于前 1s 预测后 3s
- 标注类别
- 车辆:包含静止、直行、转向、换道、倒车
- 地图:车道线、停车/让行标志、人行横道、减速带
评价指标
- Average Displacement Error (ADE)
- 轨迹误差, t ∈ {1.0, 2.0, 3.0},单位为米
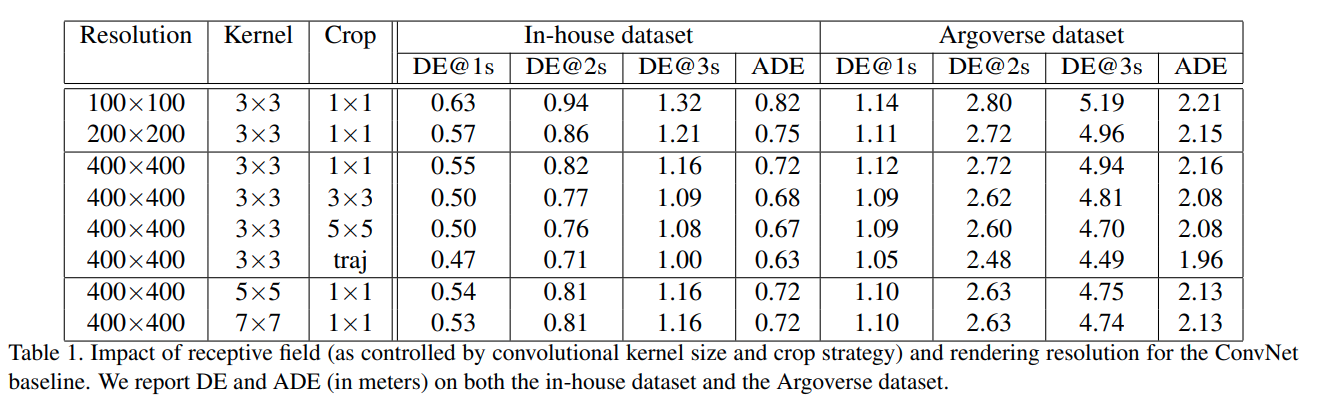
基于地图渲染方法的实验
- 受卷积感受野的影响大
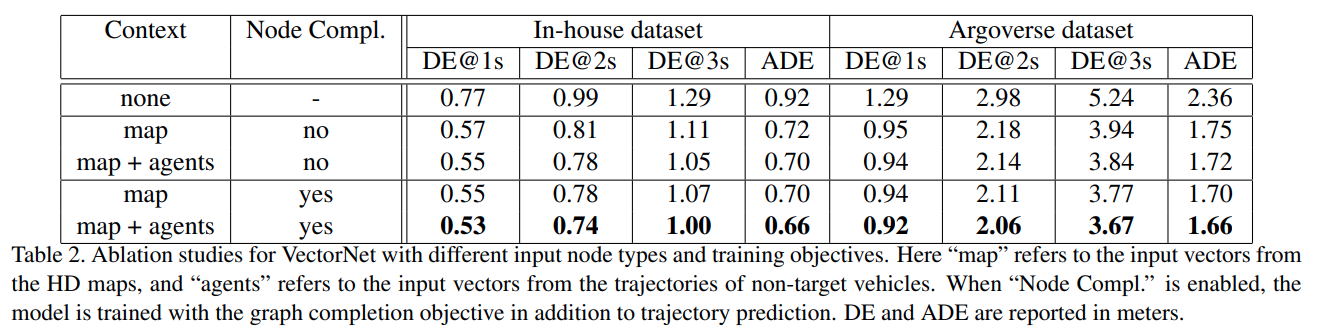
vectornet 实验
- 增加 node 补全有涨点、增加其他 egent 交互有涨点
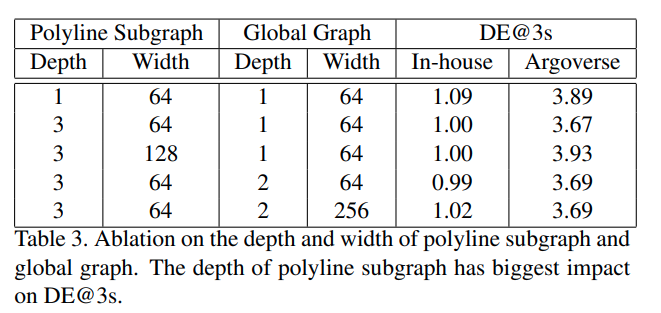
网络深度影响
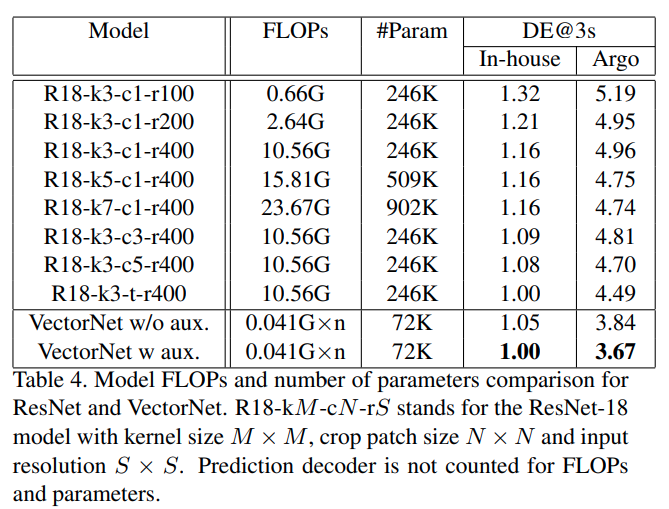
网络参数对比
argoverse leaderboard
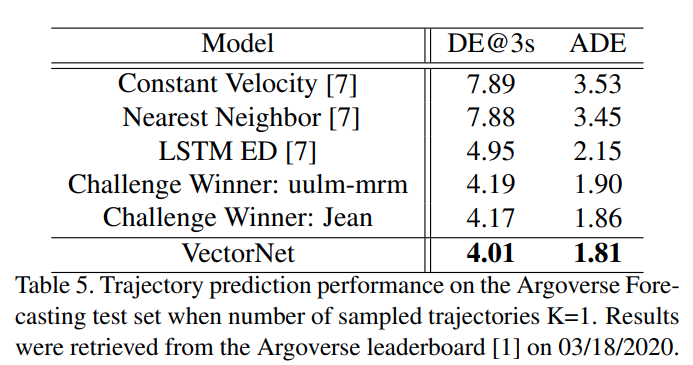
可视化
- 左图是预测,右图是 attention 可视化,显示了在两个可能的车道中选择了正确的车道
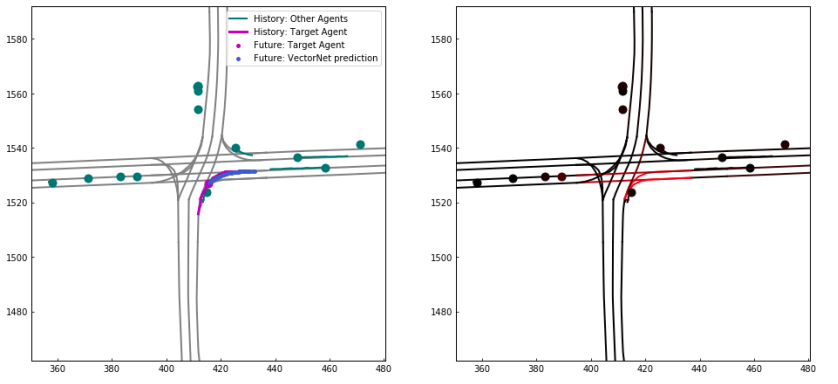
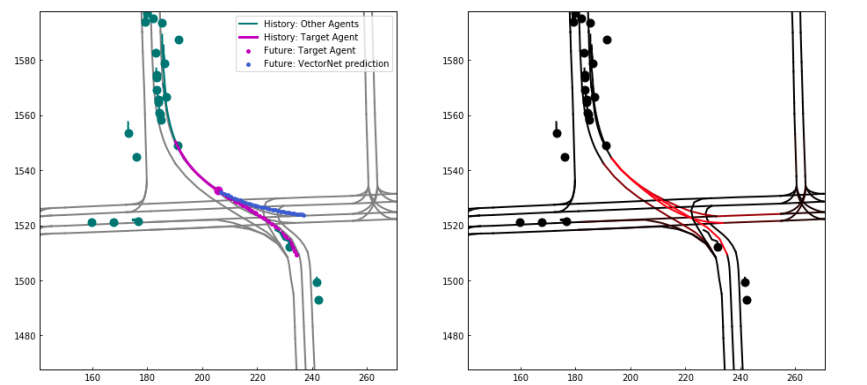
- 显示了即便没有选择到正确的车道,但正确的车道在 attention 结果中也有较好的分数
Thoughts
- 只有轨迹点,不连接成 vector 应该是不行的,文章中介绍了如果不连接成 vector 并且没有额外属性的话就退化为了 PointNet,想象中丢弃了轨迹随时间变化的信息和结构化地图结构的信息也不太科学
- 对于每个目标 agent 需要进行坐标规范化及坐标系对齐操作
- 为了使输入节点特征不随着目标 agents 的位置有变化,规范化了所有向量的坐标,使其以目标 agents 最后一个观察到的时间步长的位置为中心
- 根据目标车辆在最后观察位置的方向旋转坐标系