https://github.com/Yuezhengrong/Implement-Attention-TinyLLaMa-from-scratch
1. Attention
1.1 Attention 灵魂10问
- 你怎么理解Attention?
Scaled Dot-Product Attention中的Scaled:
1
d
k
\frac{1}{\sqrt{d_k}}
dk1 的目的是调节内积,使其结果不至于太大(太大的话softmax后就非0即1了,不够“soft”了)。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
Multi-Head可以理解为多个注意力模块,期望不同注意力模块“注意”到不一样的地方,类似于CNN的Kernel。(注意:concat多头输出后需要再经过
W
O
W^O
WO)
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
W
O
u
t
where head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\begin{aligned} \operatorname{MultiHead}(Q, K, V) & =\operatorname{Concat}\left(\operatorname{head}_1, \ldots, \text { head }_{\mathrm{h}}\right) W^{Out} \\ \text { where head }_{\mathrm{i}} & =\operatorname{Attention}\left(Q W_i^Q, K W_i^K, V W_i^V\right) \end{aligned}
MultiHead(Q,K,V) where head i=Concat(head1,…, head h)WOut=Attention(QWiQ,KWiK,VWiV)
- 乘性Attention和加性Attention有什么不同?
- 乘性Attention使用
点积(dot product)来计算attention_score。具体而言,给定查询(query)Q、键(key)K和值(value)V,乘性Attention通过计算内积来度量查询和键之间的相似性,并使用softmax函数将得分归一化为概率分布。计算公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ∗ K T ) ∗ V Attention(Q, K, V) = softmax(Q * K^T) * V Attention(Q,K,V)=softmax(Q∗KT)∗V
乘性注意力的计算复杂度较低,因为它不需要引入额外的参数或矩阵运算。然而,由于点积的缩放问题,当查询和键的维度较大时,乘性Attention可能会导致注意力权重过小或过大。
- 加性Attention使用
额外的矩阵权重 和 非线性激活函数来计算attention_score。具体而言,给定查询Q、键K和值V,加性Attention首先将Q和K通过一个矩阵W进行线性变换,然后应用激活函数(如tanh或ReLU),最后通过另一个矩阵U进行线性变换并使用softmax函数进行归一化。计算公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( U ∗ t a n h ( W Q ∗ Q + W K ∗ K ) ) ∗ V Attention(Q, K, V) = softmax(U * tanh(W_Q * Q + W_K * K)) * V Attention(Q,K,V)=softmax(U∗tanh(WQ∗Q+WK∗K))∗V
加性Attention引入了额外的线性变换和非线性激活函数,因此计算复杂度较高。但它能够更好地处理维度较大的查询和键,并且具有更强的表示能力。
- Self-Attention中的Scaled因子有什么作用?必须是 d k \sqrt{d_k} dk 吗?
在Self-Attention机制中,为了缓解点积计算可能导致的数值不稳定性和梯度消失或爆炸的问题,通常会引入一个缩放因子(scaling factor)。这个缩放因子通常是根号下key向量的维度(即
d
k
\sqrt{d_k}
dk)。
但并不是绝对必须使用
d
k
\sqrt{d_k}
dk。在实践中,也可以根据具体情况调整缩放因子,例如使用1/d_k或其他系数来代替
d
k
\sqrt{d_k}
dk。这取决于模型的架构设计、数据集特征以及训练过程中的表现情况,可以根据实验结果选择合适的缩放因子。
- Multi-Head Self-Attention,Multi越多越好吗,为什么?
多头注意力的优势:
-
增加表示能力: 每个注意头可以关注输入序列中不同位置的信息,学习到不同的特征表示。通过多个注意头并行计算,模型能够综合利用多个子空间的信息,提高模型的表示能力。
-
提高泛化能力: 多头注意力有助于模型学习更丰富和复杂的特征表示,从而提高模型在各种任务上的泛化能力,减少过拟合的风险。
多头注意力的限制:
-
计算复杂度增加: 随着注意头数量的增加,计算复杂度会线性增加。更多的头数意味着更多的参数和计算量,可能导致训练和推理过程变得更加耗时。
-
过拟合风险: 过多的注意头可能导致模型过度拟合训练数据,特别是在数据集较小或任务较简单的情况下。过多的参数会增加模型的复杂度,增加过拟合的风险。
因此,并非多头注意力中头数越多越好,需要在表示能力和计算效率之间进行权衡。通常在实践中,头数的选择是一种超参数,需要通过实验和验证集的性能来确定最佳的头数。
- Multi-Head Self-Attention,固定
hidden_dim(即token_dim)时,你认为增加head_dim(需要缩小num_heads)和减少head_dim会对结果有什么影响?
在Multi-Head Self-Attention中,固定hidden_dim(隐藏层维度, 即token_dim)时,增加head_dim(每个注意头的维度)和减少head_dim会对模型的表示能力和计算效率产生影响。这两种调整会影响每个注意头学习到的特征表示的维度,进而对模型整体的性能产生影响。
增加 head_dim(需要缩小 num_heads):
-
增强每个注意头的表达能力: 增加
head_dim会增加每个注意头学习到的特征表示的维度,使得每个注意头能够捕获更丰富和复杂的特征信息,从而提高模型的表示能力。 -
减少注意头的数量可能减少计算复杂度: 随着
head_dim的增加,为了保持总体隐藏层维度hidden_dim不变,可能需要减少注意头的数量num_heads。减少注意头的数量可以降低计算复杂度,因为每个注意头的计算量随着维度的增加而增加。 -
可能增加模型训练的稳定性: 增加
head_dim可以提高每个注意头学习到的特征表示的丰富度,可能使得模型更容易学习到复杂的关系和模式,从而提高训练的稳定性。
减少 head_dim:
-
降低每个注意头的表达能力: 减少
head_dim会降低每个注意头学习到的特征表示的维度,可能限制每个注意头捕获和表示输入序列的能力,导致模型的表示能力下降。 -
增加注意头的数量可能提高模型的多样性: 为了保持总体隐藏层维度
hidden_dim不变,减少head_dim可能需要增加注意头的数量num_heads。增加注意头的数量可以增加模型学习不同方面信息的多样性,有助于提高模型的泛化能力。 -
可能降低模型训练的稳定性: 减少
head_dim可能限制模型学习复杂关系的能力,使得模型更容易受到梯度消失或爆炸的影响,降低训练的稳定性。
总体来说,增加head_dim可以提高每个注意头的表达能力,而减少head_dim可能降低每个注意头的表达能力。在选择head_dim时,需要权衡模型的表示能力、计算效率以及训练的稳定性,通常需要通过实验来确定最佳的超参数设置。
- 为什么我们一般需要对 Attention weights 应用Dropout?哪些地方一般需要Dropout?Dropout在推理时是怎么执行的?你怎么理解Dropout?
在深度学习训练中,对 Attention weights 应用 Dropout 的主要原因是为了减少过拟合。Attention机制通常用于提取输入序列中的相关信息,但如果模型过度依赖某些输入信息,就容易导致过拟合。通过引入 Dropout,可以随机地将一部分 Attention weights 设置为零,从而减少模型依赖于特定输入的情况,有助于提高模型的泛化能力。
一般来说,除了在 Attention weights 中使用 Dropout 外,还有一些情况下需要使用 Dropout,包括在全连接层、卷积层、循环神经网络(RNN)等网络结构中,都可以考虑使用 Dropout 来减少过拟合。
在推理时,Dropout 通常不会执行,因为在推理阶段我们希望获得稳定的预测结果,不需要随机丢弃神经元。因此,在推理时,Dropout 层通常会被关闭,或者将每个神经元的输出值按照训练时的概率进行缩放。
- Self-Attention的qkv初始化时,bias怎么设置,为什么?
在初始化 q、k、v 时,一般不会设置 bias (0)。
这是因为在 Self-Attention 中,Query、Key 和 Value 的计算通常是通过矩阵乘法来实现的,而不像全连接层那样需要使用偏置项(bias)。对于 Self-Attention 的计算过程来说,没有必要引入额外的偏置项,因为 Self-Attention 是通过计算 Query 和 Key 的点积得到 Attention weights,然后再将这些权重应用到 Value 上,不需要额外的偏置项来影响这个计算过程。
- 你认为Attention的缺点和不足是什么?
-
计算复杂度高: Attention 机制需要计算 Query 和 Key 之间的相似度,这通常需要进行矩阵乘法操作,导致计算复杂度较高,特别是在处理长序列时,计算量会进一步增加。
-
内存占用大: 对于较长的序列,Attention 机制需要存储大量的注意力权重,会占用大量内存,限制了模型能够处理的序列长度。
-
缺乏位置信息: 原始的 Self-Attention 没有直接建模位置信息,虽然可以通过添加位置编码来解决这个问题,但仍然存在局部关系建模不足的情况。
-
注意力偏向性: 在处理长序列时,注意力容易偏向于关注距离较近的位置,难以捕捉长距离依赖关系,可能导致信息传递不及时或不完整。
-
对噪声敏感: Attention 机制对输入序列中的噪声和异常值比较敏感,可能会影响模型的性能和鲁棒性。
-
训练过程中的稳定性: 在训练过程中,Attention 机制可能出现注意力集中或分散不均匀的情况,需要一定的技巧和调节来保持稳定的训练效果。
- 你怎么理解Deep Learning的Deep?现在代码里只有一个Attention,多叠加几个效果会好吗?
在深度学习中,“Deep” 指的是模型具有多层(深层)结构,通过堆叠多个隐藏层来提取数据的高级特征表示。深度神经网络之所以称为 “Deep Learning”,是因为相比于传统浅层模型,它可以学习到更加抽象、复杂的特征表示,从而提高模型的表征能力。
在使用 Attention 机制时,通过堆叠多个 Attention 层,可以增加模型对输入序列的建模能力和表示能力。这种多层 Attention 的堆叠通常被称为 Multi-layer Attention,它可以让模型在不同抽象层次上学习到更加复杂和深入的语义信息。
然而,需要注意的是,多层 Attention 的堆叠也会增加模型的复杂度和计算量,可能导致训练过程变得更加困难和耗时。因此,在实际应用中,需要权衡模型性能和计算资源之间的关系,选择合适的模型深度和结构来平衡精度和效率。
1.2 小项目:Self-Attention模型实现文本情感2分类
单层Attention Model:没有实现W_out,反而加了Dropout。
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
where head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
Attention
(
Q
,
K
,
V
)
=
D
r
o
p
o
u
t
(
softmax
(
Q
K
T
d
k
)
)
V
\begin{aligned} \operatorname{MultiHead}(Q, K, V) & =\operatorname{Concat}\left(\operatorname{head}_1, \ldots, \text { head }_{\mathrm{h}}\right) \\ \text { where head }_{\mathrm{i}} & =\operatorname{Attention}\left(Q W_i^Q, K W_i^K, V W_i^V\right) \end{aligned} \\ \operatorname{Attention}(Q, K, V)=Dropout(\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right)) V
MultiHead(Q,K,V) where head i=Concat(head1,…, head h)=Attention(QWiQ,KWiK,VWiV)Attention(Q,K,V)=Dropout(softmax(dkQKT))V
class SelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
assert config.hidden_dim % config.num_heads == 0
self.wq = nn.Linear(config.hidden_dim, config.hidden_dim, bias=False)
self.wk = nn.Linear(config.hidden_dim, config.hidden_dim, bias=False)
self.wv = nn.Linear(config.hidden_dim, config.hidden_dim, bias=False)
self.att_dropout = nn.Dropout(config.dropout)
def forward(self, x):
batch_size, seq_len, hidden_dim = x.shape
q = self.wq(x)
k = self.wk(x)
v = self.wv(x)
q = q.view(batch_size, seq_len, self.config.num_heads, self.config.head_dim)
k = k.view(batch_size, seq_len, self.config.num_heads, self.config.head_dim)
v = v.view(batch_size, seq_len, self.config.num_heads, self.config.head_dim)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
# (b, nh, ql, hd) @ (b, nh, hd, kl) => b, nh, ql, kl
att = torch.matmul(q, k.transpose(2, 3))
att /= math.sqrt(self.config.head_dim)
score = F.softmax(att.float(), dim=-1)
score = self.att_dropout(score)
# (b, nh, ql, kl) @ (b, nh, kl, hd) => b, nh, ql, hd
attv = torch.matmul(score, v)
attv = attv.view(batch_size, seq_len, -1)
return score, attv
利用Attention Model实现NLP二分类模型:(num_labels=2)
- Tokenizer:
words[B,L] -> ids[B,L](在模型外) - Embedding:
ids[B,L] -> vectors[B,L,D] - SelfAttention:
vectors[B,L,D] -> vectors[B,L,D] - Avg_Pooling:
vectors[B,L,D] -> vectors[B,1,D] - Linear:
vectors[B,D] -> vectors[B,num_labels]
class Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.emb = nn.Embedding(config.vocab_size, config.hidden_dim)
self.attn = SelfAttention(config)
self.fc = nn.Linear(config.hidden_dim, config.num_labels)
def forward(self, x):
batch_size, seq_len = x.shape
h = self.emb(x)
attn_score, h = self.attn(h)
h = F.avg_pool1d(h.permute(0, 2, 1), seq_len, 1) # seq_len维度压缩为1
h = h.squeeze(-1)
logits = self.fc(h)
return attn_score, logits
后续代码看github吧
2. LLaMa
2.1 LLaMa 灵魂10问
Tokenizer:words[B,L] -> ids[B,L]
Embedding:ids[B,L] -> vectors[B,L,D]
Transformer:vectors[B,L,D] -> vectors[B,L,D]
Sotfmax:vectors[B,L,D] -> logits[B,1,VS]
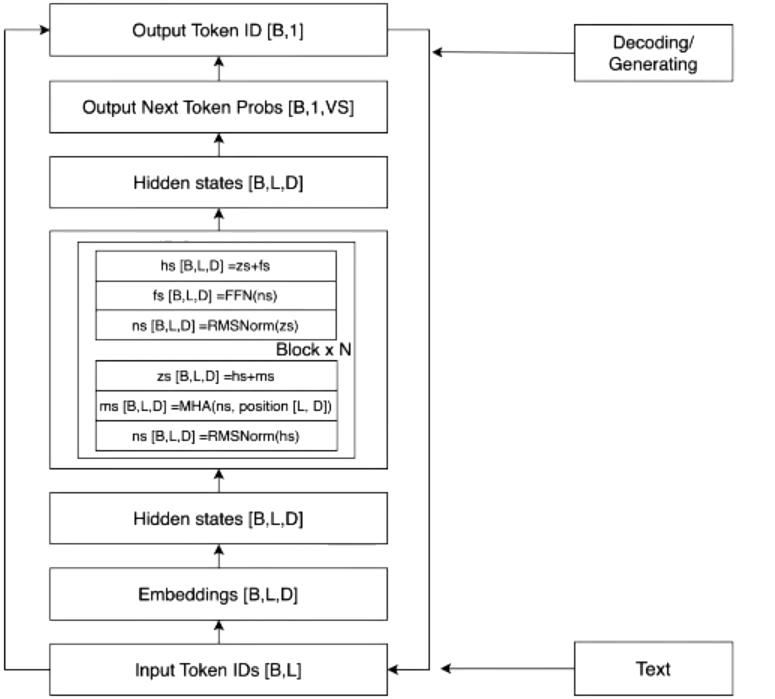
这是一个相当深入和技术性的问题,我将依次回答你提出的每个问题。
-
Tokenize理解和方式区别
- Tokenize是将原始文本分割成标记(token)的过程,其中标记可以是单词、子词或字符。常见的Tokenize方式包括基于空格的分词、基于规则的分词、基于词根的分词(如WordPiece、Byte Pair Encoding)和字符级别的分词。它们的区别在于分割粒度和表示能力,不同的Tokenize方式会影响模型对文本的理解和表示能力。
-
理想的Tokenizer模型特点
- 灵活性:能够适应不同语言和文本类型的Tokenize需求。
- 高效性:快速处理大规模文本数据。
- 统一性:能够生成统一的标记表示,以便模型统一处理。
-
特殊Token的作用和模型自动学习
- 特殊Token如开始和结束标记用于指示序列的起始和结束,使得模型能够正确处理输入序列。模型不能自动学习这些标记,因为在训练中需要有明确的序列起始和结束的指示,而自动学习可能导致模糊性和不确定性。
-
LLM为何是Decoder-Only
- LLM是Decoder-Only是因为语言模型任务中,需要根据之前的文本预测下一个标记,这种顺序建模的任务适合使用Decoder-Only结构。
-
RMSNorm和LayerNorm的区别
- LayerNorm(层归一化):LayerNorm是一种常见的归一化技术,它在每个层的特征维度上进行归一化处理。具体来说,对于每个样本,在特定层的所有隐藏单元特征维度上进行均值和方差的计算,然后将每个隐藏单元的输出减去均值并除以标准差以实现归一化。LayerNorm有助于加速训练过程,并提高模型的泛化能力。
- RMSNorm(根均方归一化):RMSNorm是另一种归一化技术,它采用了不同的方式来计算归一化的均值和方差。与LayerNorm不同,RMSNorm使用平方根均方(root mean square)来代替标准差。这意味着RMSNorm更侧重于考虑样本中的大值,从而更好地适应于序列数据,并能够更好地处理长序列的梯度传播问题。
总的来说,RMSNorm相比于LayerNorm更适用于序列数据,尤其是处理长序列时的效果更好。
-
LLM中的残差连接和作用
- 残差连接在LLM中用于保留输入信息,有助于减少梯度消失和加速训练。
-
PreNormalization和PostNormalization的影响
- PreNormalization:在PreNormalization中,每个子层的输入会先经过Layer Normalization(LN),然后是残差连接(Residual Connection)和子层结构(比如Self-Attention或FFN)。这种顺序能够让模型更好地传递信息和梯度,有利于减少梯度消失和加速训练。因此,PreNormalization更利于信息传递和梯度传播,有助于训练深层模型。
- PostNormalization:在PostNormalization中,每个子层的输出会先经过子层结构,然后再经过LN和残差连接。这种方式可能会导致梯度传播时出现一些问题,因为LN的位置会影响到梯度的传播路径。相比之下,PostNormalization可能会导致一些梯度传播上的困难,尤其是在深层网络中。
-
FFN先扩大后缩小的作用
- 先扩大后缩小有利于模型学习复杂的非线性映射关系,提高模型的表达能力。
-
LLM为何需要位置编码和编码方案
- LLM需要位置编码是因为自注意力机制无法直接捕捉位置信息。编码方案有绝对位置编码、相对位置编码等。
-
设计位置编码方案考虑因素
- 位置信息的表达能力
- 对不同长度序列的适应能力
- 计算效率
2.2 np实现TinyLLaMa
看GitHub吧
改良Attention
将RMSNorm、RoPE等加入Attention模型,重新训练提升点数。看GitHub吧