目录
- Throughput/Latency
- Serial Computing
- Parallel Computing
- Types of parallel computers
- Simple 4-width SIMD
- Amdahl's law
- Types of parallelism
- **Data Parallel Model**
- Task parallel
- Partitioning
- Domain Decomposition
- Functional Decomposition
- Communications
- Example that does not need communication
- Example that need communication
- Synchronization
- Barrier
- Granularity
- Fine-grain Parallelism
- Coarse-grain Parallelism
- How expensive is memory I/O
- Solving the problem
- Just add more stuff for the GPU to do
- Latency Hiding
- Coalesced Global memory access
- Host/Device Transfers and Data Movement
- Avoid transfers
- Pinned Host Memory
在本章中,我们将回顾一些有关并行计算的概念。但更加强调 GPU。
Throughput/Latency
在讨论性能之前,我们先回顾一下一些概念。
- 吞吐量:单位时间内计算任务的数量。即:一分钟内 1000 笔信用卡付款。
- 延迟:调用操作和获得响应之间的延迟。即:处理信用卡交易所需的最长时间为 25 毫秒。
在优化性能时,一个因素(例如吞吐量)的改进可能会导致另一因素(例如延迟)的恶化。
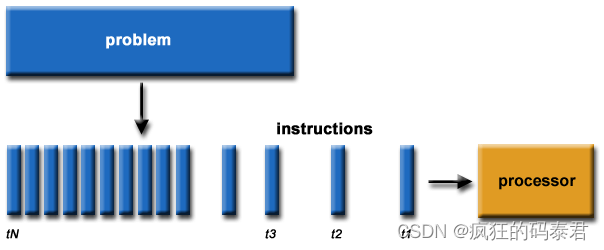
Serial Computing
这是老办法,我们遇到一个问题,我们把它们分解成一个个小块,然后一个接一个地解决。
Parallel Computing
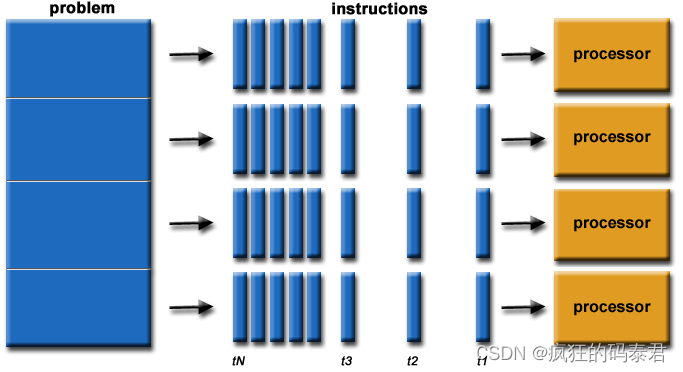
从最简单的意义上来说,并行计算是同时使用多个计算资源来解决计算问题。
Types of parallel computers
根据弗林分类法,并行计算机有 4 种不同的分类方法。
下面是一些经典的例子
- SISD:非常旧的计算机(PDP1)
- MIMD:超级计算机
- SIMD:Intel 处理器、Nvidia Gpus
- MISD:确实很少见。
对于 GPU,它们通常是 SIMD 类型的处理器。不同的处理单元执行相同的指令,但在共享内存的不同部分。
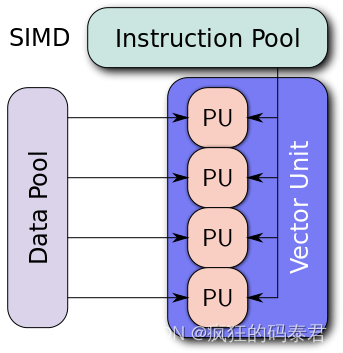
Simple 4-width SIMD
下面我们有一个 4 宽度的 SIMD。这里的所有处理器都在同时执行“add”指令。
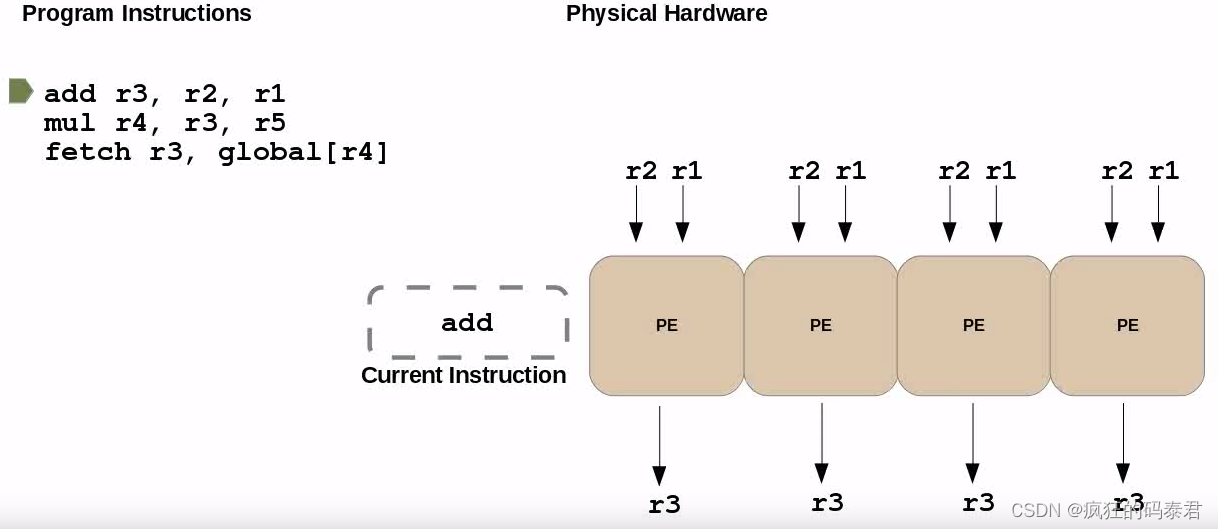 当您听说 GPU 有 5000 个核心时,请不要被愚弄,它可能只是说它有 5000 个 ALU(算术逻辑单元)。 GPU 可同时执行的最大任务数通常在 Nvidia 上称为“warp size”,在 AMD 上称为“wavefront”,通常是按块/网格组织的 32 宽 SIMD 单元。
当您听说 GPU 有 5000 个核心时,请不要被愚弄,它可能只是说它有 5000 个 ALU(算术逻辑单元)。 GPU 可同时执行的最大任务数通常在 Nvidia 上称为“warp size”,在 AMD 上称为“wavefront”,通常是按块/网格组织的 32 宽 SIMD 单元。
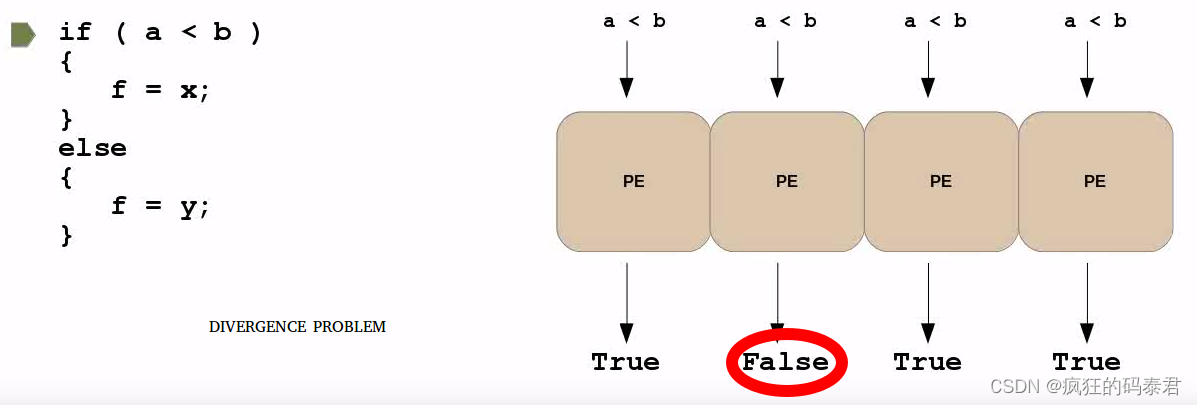
可能发生的一个有趣的问题是,如果您有一条分支(if)指令,并且每个处理元素决定不同的事情。如果发生这种情况,您将受到处理处罚。这种效应称为发散。为了解决这个问题,您必须尝试尽量减少波动前(cuda 中的wrap)上分支指令的使用。
如果您需要这种分支分配,您可以使用 opencl 中的“select”来编译为单个指令(原子),这样就不会发生发散问题。
Amdahl’s law
Amdahl’s Law指出潜在的程序加速(理论延迟)由可以并行化的代码 p 的比例定义:
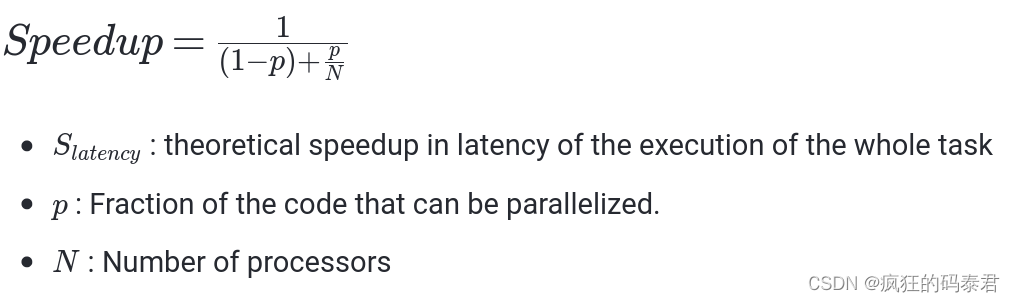
- S : 整个任务执行延迟的理论加速
- p: 可以并行化的代码的一部分。
- 处理器数量
从该定律可以得到:加速受到不可并行工作部分的限制,即使使用无限数量的处理器,速度也不会提高,因为串行部分会受到限制。
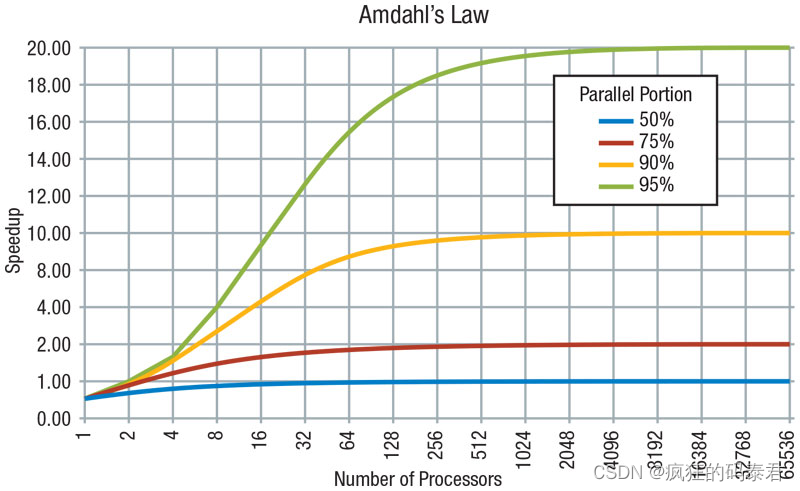
程序的总执行时间T分为两类: - 执行不可并行串行工作所花费的时间
- 进行可并行工作所花费的时间
这里还缺少一些重要的东西。阿姆达尔定律没有考虑内存延迟等其他因素。
Types of parallelism
Data Parallel Model
在此模型上,共享内存对所有节点都是可见的,但每个节点都处理该共享内存的部分内容。这就是我们通常使用 GPU 要做的事情
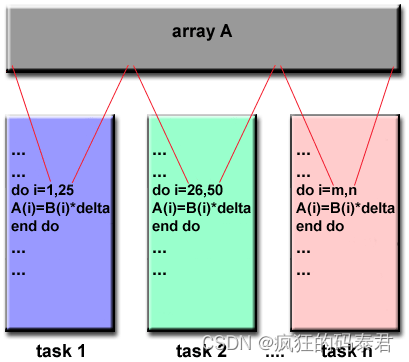
数据并行方法的主要特点是编程相对简单,因为多个处理器都运行相同的程序,并且所有处理器大约在同一时间完成其任务。当每个处理器正在处理的数据之间的依赖性最小时,此方法是有效的。例如,向量加法可以从这种方法中受益匪浅。
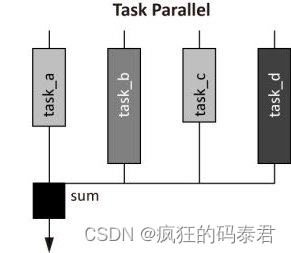
Task parallel
任务并行方法的主要特点是每个处理器执行不同的命令。与数据并行方法相比,这增加了编程难度。由于处理时间可能会根据任务的分割方式而有所不同,因此需要一些同步。如果任务完全不相关,问题就会容易得多。
Partitioning
设计并行程序的第一步是将问题分解为可以分配给多个任务的离散工作“块”。这称为分解或划分。有两种在并行任务之间划分计算工作的基本方法:
- 域分解:
- 功能分解。
Domain Decomposition
在这种类型的分区中,与问题相关的数据被分解。然后,每个并行任务都处理一部分数据。
Functional Decomposition
在这种方法中,重点是要执行的计算,而不是计算所操纵的数据。问题根据必须完成的工作进行分解。然后,每个任务执行整体工作的一部分。
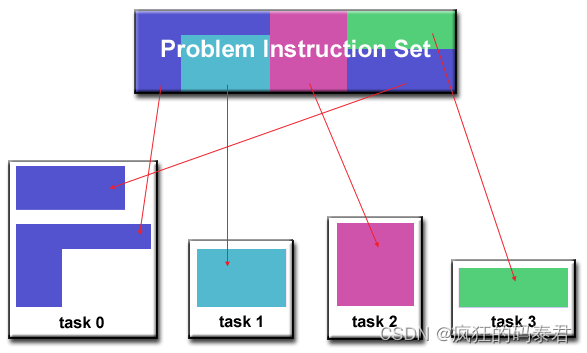
Communications
通常一些并行问题需要节点(任务)之间进行通信。这又是一个与问题相关的问题。需要考虑的一些要点:
- 通信总是意味着开销
- 通信频繁需要节点(任务)同步,需要较大的开销
当您需要将数据发送到 GPU 来执行某些计算,然后将结果传回 CPU 时,就意味着需要进行通信。
Example that does not need communication
某些类型的问题可以分解并并行执行,几乎不需要任务共享数据。例如,想象一下图像处理操作,其中黑白图像中的每个像素都需要反转其颜色。图像数据可以轻松地分配给多个任务,然后这些任务彼此独立地完成各自的工作。这些类型的问题通常被称为“尴尬并行”,因为它们非常简单。需要很少的任务间通信。
Example that need communication
大多数并行应用程序并不是那么简单,并且确实需要任务彼此共享数据。例如,3-D 热扩散问题需要任务了解具有相邻数据的任务计算出的温度。相邻数据的更改会直接影响该任务的数据。
Synchronization
管理工作顺序和执行工作的任务是大多数并行程序的关键设计考虑因素。同步总是会影响性能,但当任务需要通信时总是需要同步。
同步类型
- Barrier(用于 OpenCl)
- Lock/semaphore 锁/信号量
- Synchronous communication operations 同步通讯操作
Barrier
这是一种同步机制,每个任务都执行其工作,直到到达屏障。然后它会停止或“阻塞”,直到所有任务都到达同一点。当最后一个任务到达屏障时,所有任务都会同步。
Granularity
这是关于计算和通信之间的比率。有 2 种粒度
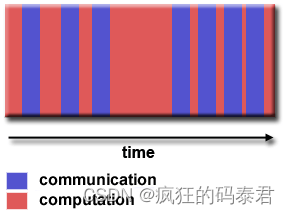
Fine-grain Parallelism
通信多于计算
Coarse-grain Parallelism
计算多于沟通
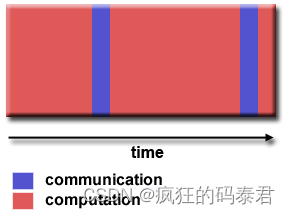
最有效的粒度取决于算法及其运行的硬件环境。但是……通常通信的延迟比计算的延迟更大。例如,将数据复制到 GPU 或从 GPU 复制数据。所以我们更喜欢粗粒度,这意味着大量的计算和很少的 GPU/CPU 通信。
How expensive is memory I/O
正如心理实验一样,想象一个处理元素(节点/任务)在 1 秒内做出语句(即 V:=1+2+3/4)。但如果需要读/写 GPU 全局内存,则需要更多时间。考虑下表。
顺便说一句,我们考虑到数据已经在 GPU 上,将数据发送到 GPU 是另一个问题。
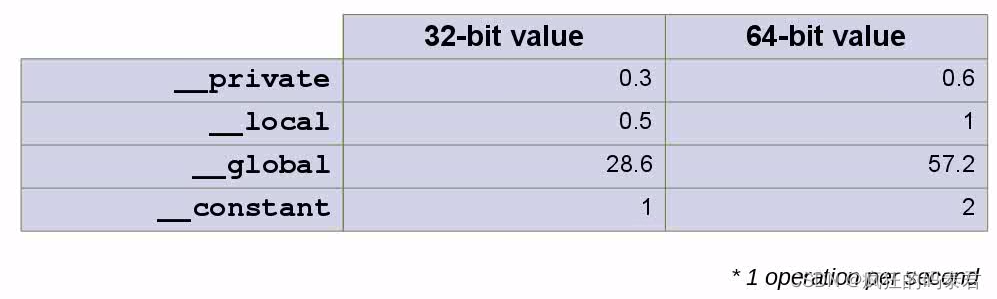 在此表中,我们有不同的内存类型,其中全局内存是 GPU 内存,私有内存和本地内存是位于每个核心内部的内存,常量也是全局内存,但专门用于读取速度更快。现在检查以下示例。
在此表中,我们有不同的内存类型,其中全局内存是 GPU 内存,私有内存和本地内存是位于每个核心内部的内存,常量也是全局内存,但专门用于读取速度更快。现在检查以下示例。
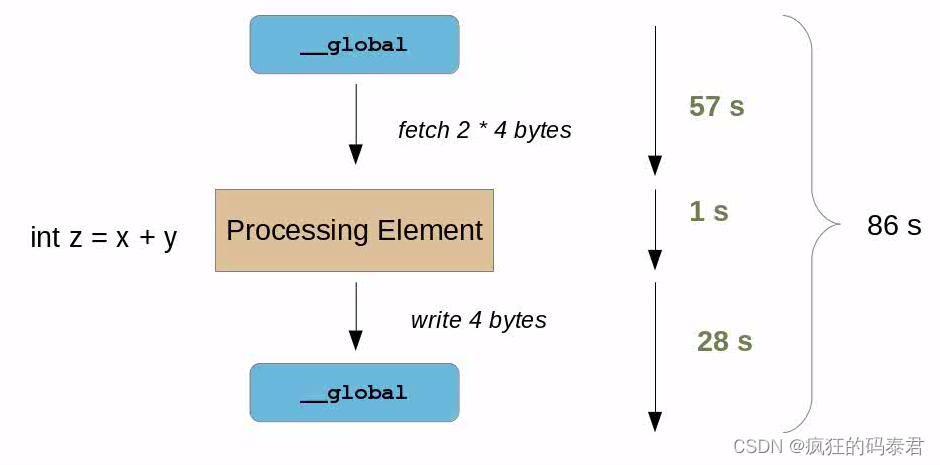
在这种情况下,我们的计算结果是 整个时间的
1
86
\frac{1}{86}
861 。这很糟糕,这意味着我们的 ALU 工作在
A
L
U
e
f
i
c
i
e
n
c
y
ALU_{eficiency}
ALUeficiency=
1
86
∗
100
\frac{1}{86}*100
861∗100 ∴
A
L
U
e
f
i
c
i
e
n
c
y
ALU_{eficiency}
ALUeficiency=1.1%。
现在想象一下,我们需要处理更多的数据,而不是 int(4 字节)x,y 将是 long(8 字节)。
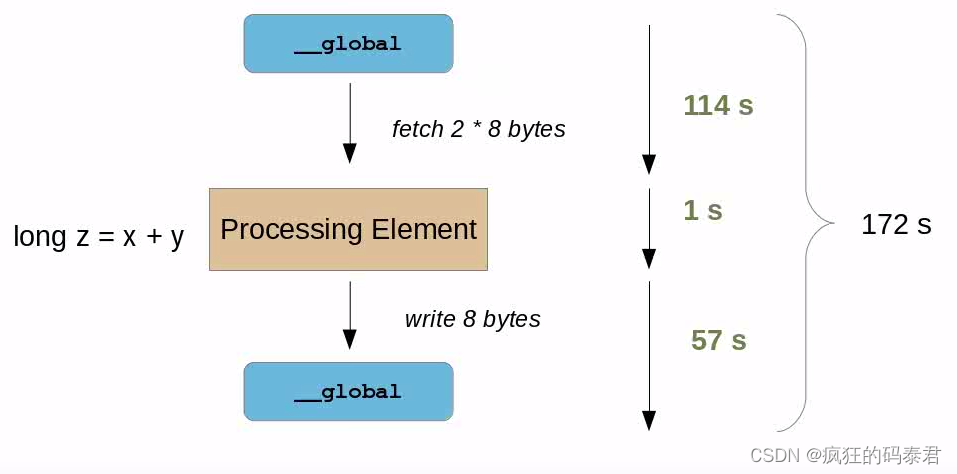
现在情况变得更糟了。我们的计算结果是整个时间的
1
172
\frac{1}{172}
1721 。这很糟糕,这意味着我们的 ALU 工作在
A
L
U
e
f
i
c
i
e
n
c
y
ALU_{eficiency}
ALUeficiency=
1
172
∗
100
\frac{1}{172}*100
1721∗100 ∴
A
L
U
e
f
i
c
i
e
n
c
y
ALU_{eficiency}
ALUeficiency=0.58%。
如果我们想与某些原始顺序算法相比提高性能,这可能意味着两件事:
- 原来的顺序算法一定比这个内存I/O延迟慢很多。
- 您需要在 GPU 内执行更多操作才能稀释该时间。
Solving the problem
Just add more stuff for the GPU to do
我们可能想到的第一件事是添加更多要完成的处理,这实际上会花费比内存延迟更多的时间。同样,如果处理时间加上内存延迟小于原始顺序 CPU 版本,您将获得加速。
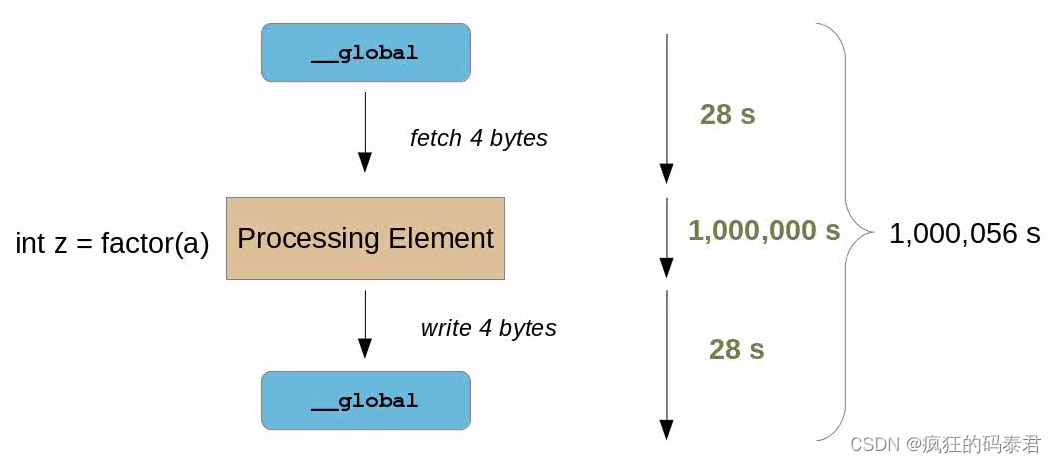 在这种情况下,您现在拥有 100% 的 Alu 效率,但这仅在现实生活中当您处理令人尴尬的并行问题时才会发生。例如大矩阵乘法、密码分析等…
在这种情况下,您现在拥有 100% 的 Alu 效率,但这仅在现实生活中当您处理令人尴尬的并行问题时才会发生。例如大矩阵乘法、密码分析等…
Latency Hiding
更好的技术是使用 GPU 上下文切换机制来隐藏此延迟。这是通过向 GPU 发出并行代码标志来实现的,表明它正在等待可用的内存请求。当这种情况发生时,等待可用内存的处理元素组将进入池。与此同时,GPU 可以启动另一个工作组来执行,但最终会暂时停止。这个想法是,当这种情况发生时,一些工作项将具有可用的内存,这将具有最小化整个延迟的效果。
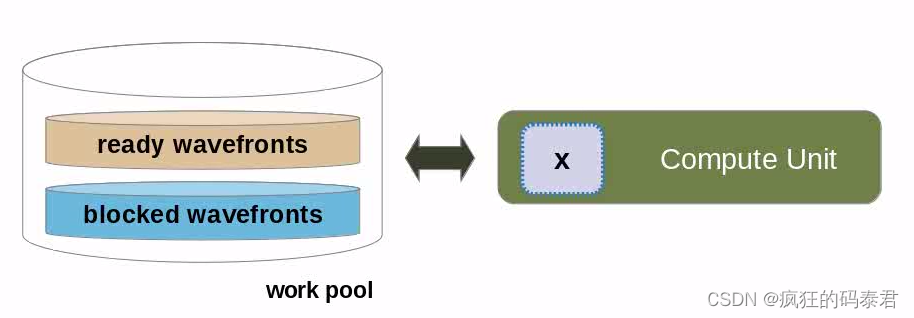
所以我们用工作组(work group)来溢出我们的计算单元
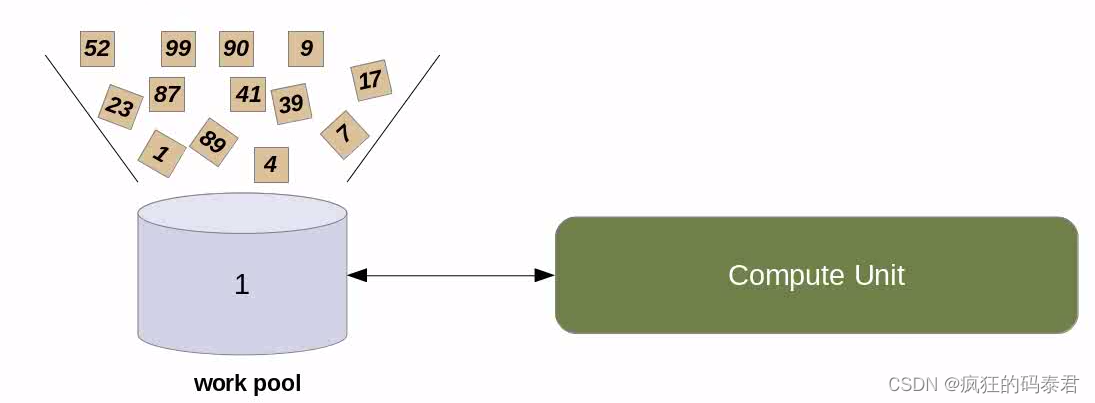
然后,我们隐藏内核访问全局内存的长内存延迟时间,因为当 GPU 分配要执行的工作组时,有些工作组可能是可用的。顺便说一句,当您的工作组位于波前(或warp)内时,这将起作用.
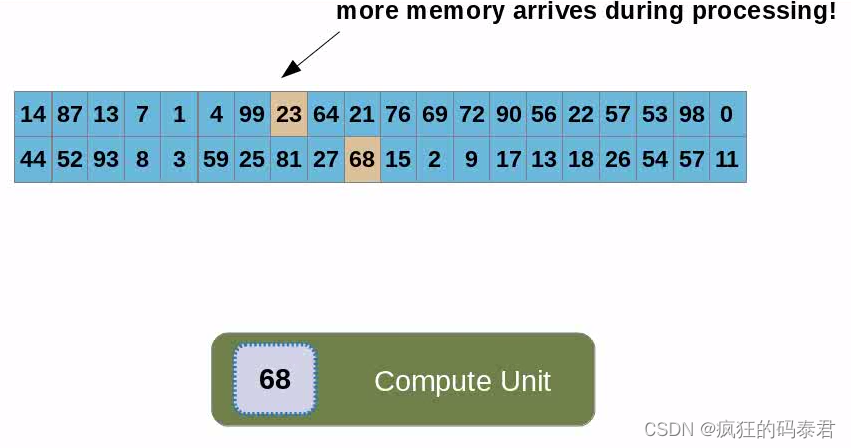
Coalesced Global memory access
主机向GPU发送数据后,内存将位于全局内存上,每个线程(计算单元)都会访问数据。我们已经讨论过这很慢,但有时您需要这样做。每次内核在全局内存上读/写时,它实际上是在访问一块内存。合并访问是指访问相邻地址上的数据。
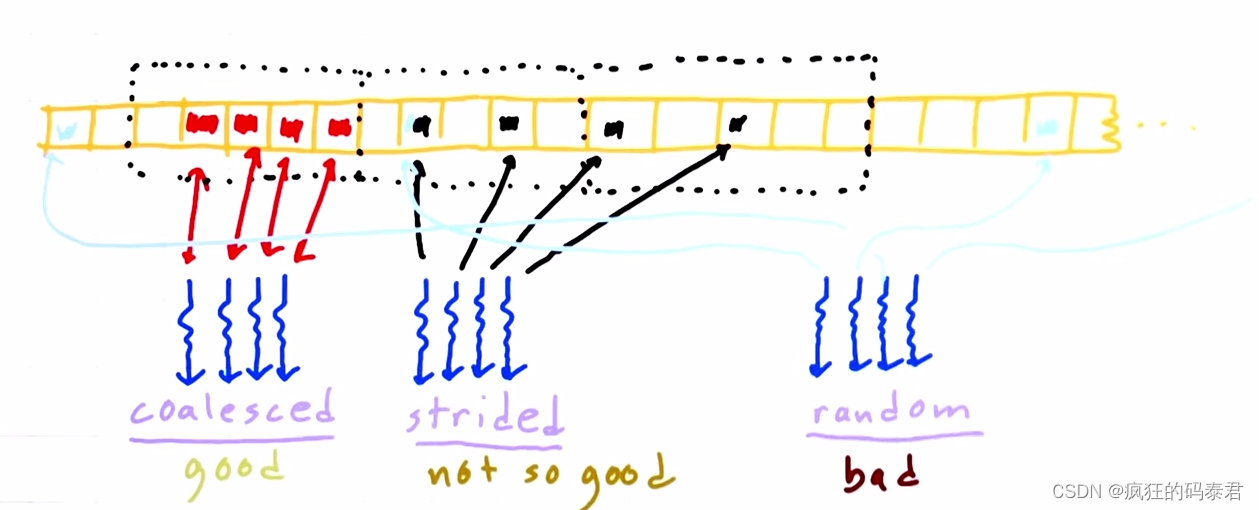
因此,这意味着使用较少的线程消耗相邻内存块来访问内存比使用大量的线程消耗随机地址更快。
Host/Device Transfers and Data Movement
到目前为止,我们仅考虑数据已位于 GPU(全局内存)上时的性能。这忽略了 GPU 编程中最慢的部分,即从 GPU 获取数据和从 GPU 取出数据。
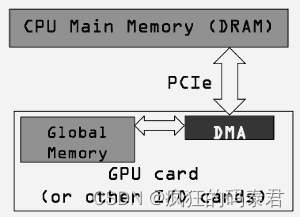
我们不应该仅使用内核的 GPU 执行时间相对于其 CPU 实现的执行时间来决定是运行 GPU 还是 CPU 版本。当我们最初将代码移植到 GPU 时,我们还需要考虑通过 PCI-e 总线移动数据的成本。
因为 GPU 是插入 PCI-e 总线的,所以这很大程度上取决于 PCI 总线的速度以及有多少其他东西正在使用它。
host/device transfer latency 是尝试在 GPU 上加速算法时的主要困难。
发生这种情况是因为,如果您的顺序算法计算的时间小于此主机/设备传输的时间,则无需做太多事情。但有一些…
Avoid transfers
这是最明显的一个,但您至少需要一个,对吗?因此,宁愿进行一次大传输,也不愿进行多次小传输,特别是在程序循环中。
Pinned Host Memory
默认情况下,主机 (CPU) 数据分配是可分页的。 GPU 无法直接从可分页主机内存访问数据,因此当调用从可分页主机内存到设备内存的数据传输时。发生这种情况是因为操作系统为其所有设备提供了虚拟地址,并且您的驱动程序需要使用这些页面来获取真实地址。 GPU 驱动程序必须首先分配一个临时页面锁定或“固定”主机数组,将主机数据复制到固定数组,然后将数据从固定数组传输到设备内存,如下所示。
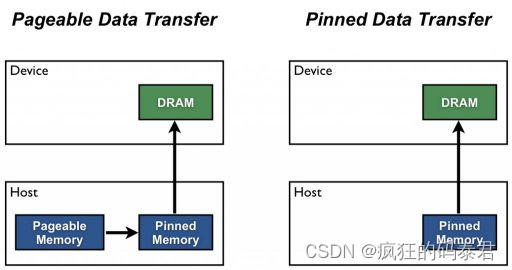
如图所示,固定内存用作从设备到主机传输的暂存区域。我们可以通过直接在固定内存中分配主机阵列来避免可分页和固定主机阵列之间的传输成本。
您不应该过度分配固定内存。这样做会降低整体系统性能,因为它会减少操作系统和其他程序可用的物理内存量。很难提前判断多少才算是太多,因此与所有优化一样,测试您的应用程序及其运行的系统以获得最佳性能参数。