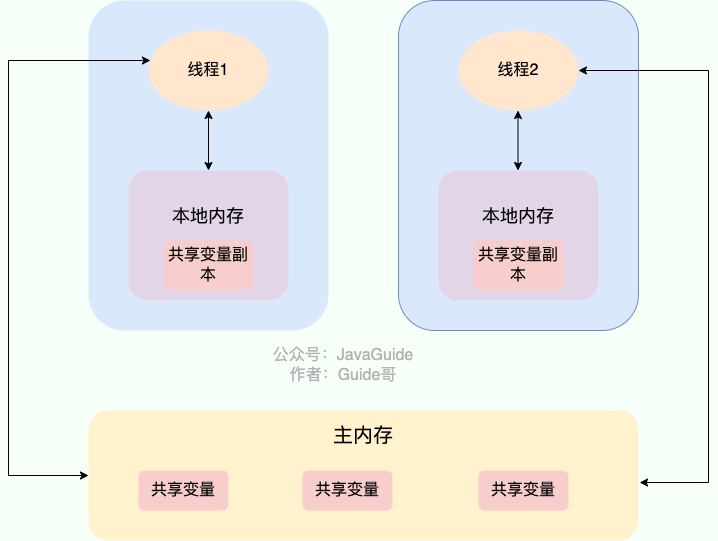
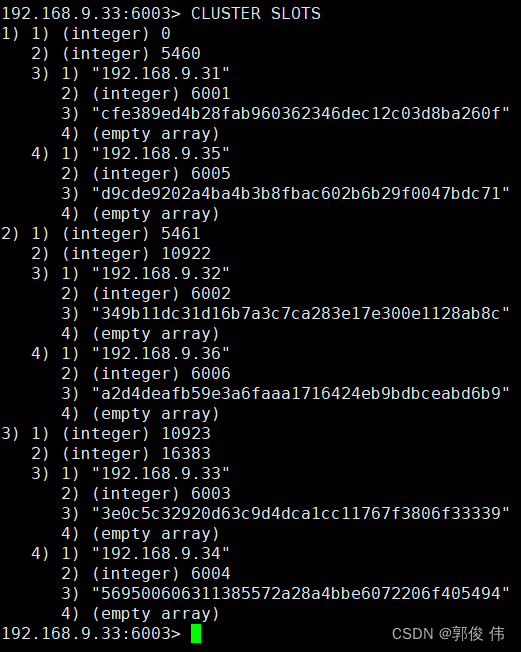
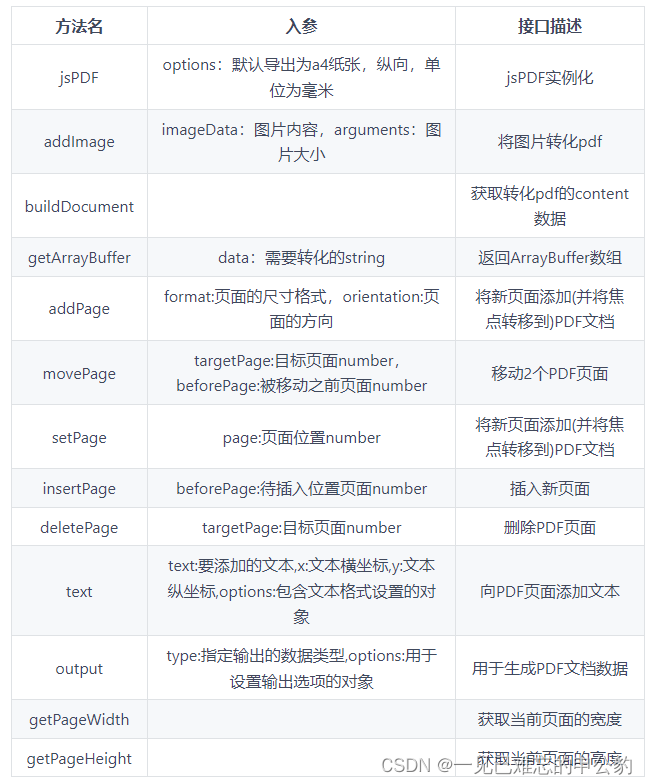
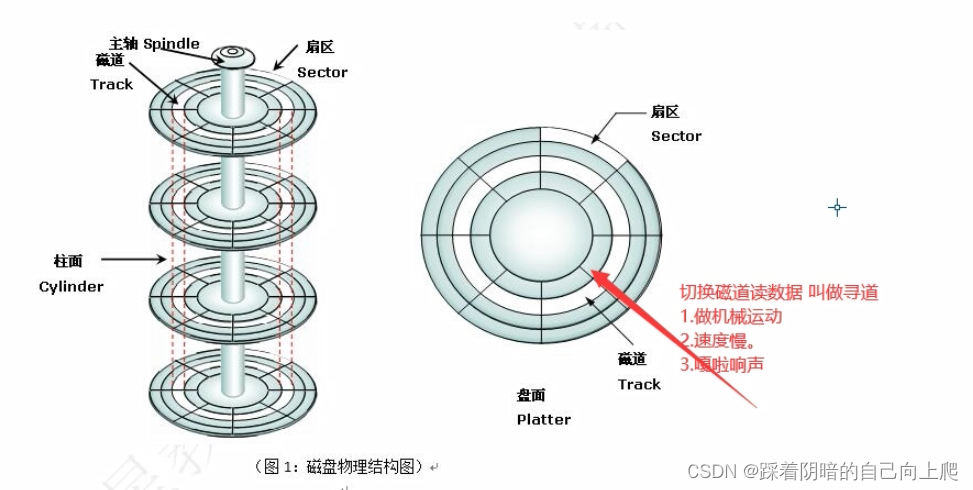
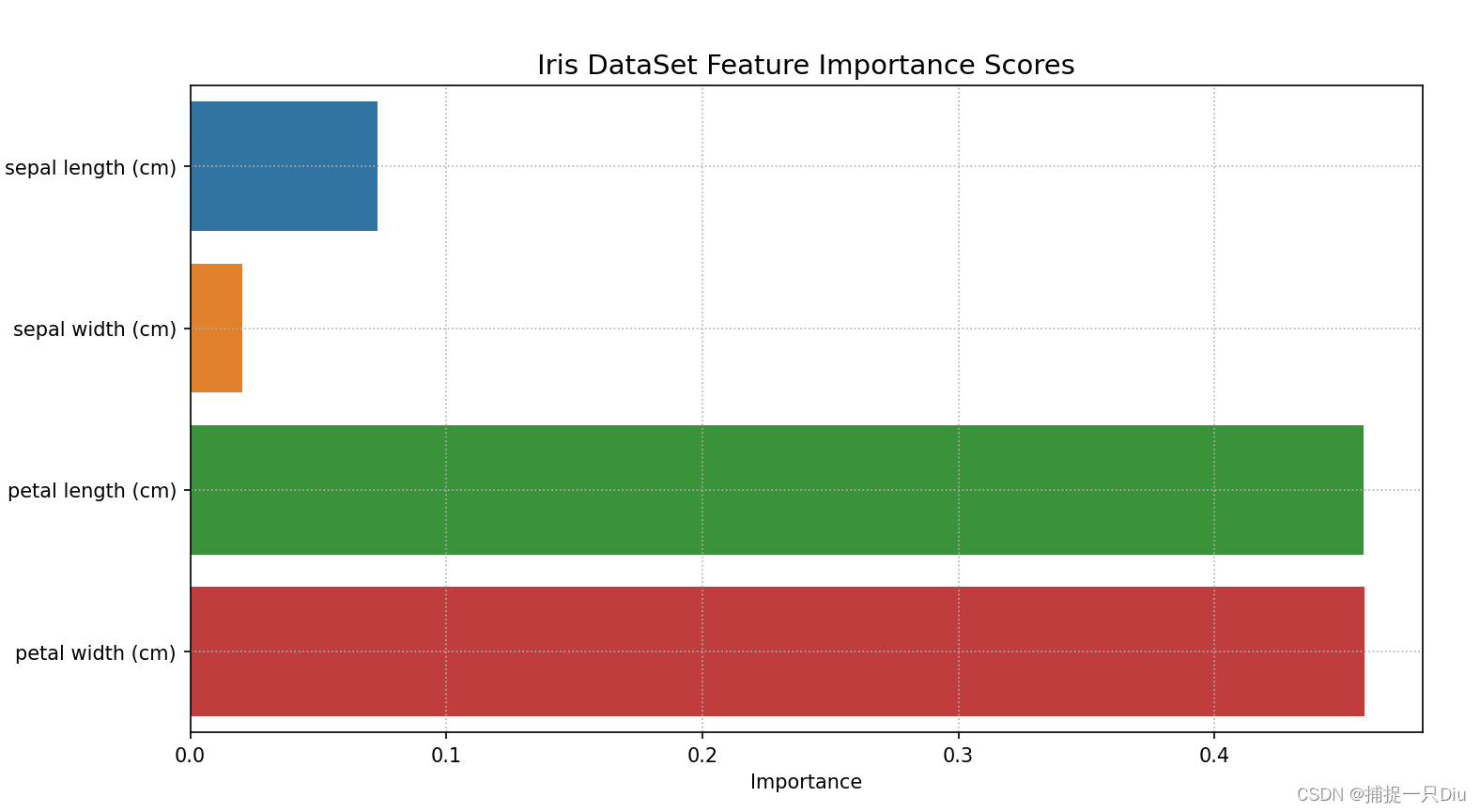
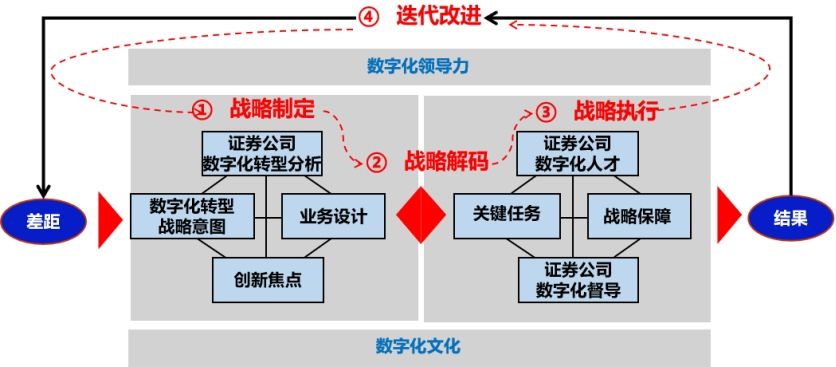
最近 ComfyUI对于Stable Cascade的支持越来越好了一些,官方也放出来一些工作流供参考。
这里简单分享几个比较常用的基础工作流。
(如果还没有下载模型,可以先阅读上一篇Stable Cascade升级,现在只需要两个模型)
🌋文生图

StageC阶段:
首先是使用基础的模型加载节点,把stage_c模型加载进来,然后正常输入正向提示词和负向提示词,稍微需要注意的是采样里边的参数和latentimage生成节点要使用StableCascade_EmptyLatentImage,这里边的42,指的是1024分辨率需要压缩42倍率去生成一个小的latent,用于后续Stage_c模型继续采样;
StageB阶段:
将第一步生成的latent进行二次采样和放大;这里需要将StageC阶段的condition和stageC生成的latent作为控制条件进行输入,然后继续在空白噪声上进行采样;
最后通过VAE,也就是之前提到的三段式里边的StageA,将图像从潜空间还原为像素空间,就生成图像了,这里的VAE是从StageB的模型中直接调取的。


测试用的提示词为:A fashionably dressed anthropomorphic cat struts down the runway,3d,disney studio,cartoon,cute,
🚠图生图

输入图像为:
提示词为:super man, close-up, walking in the desert, oasis in the background, nighttime, with a moon in the sky,
输出图像为:

效果部分,可以看到会参考输入图像画风和构图,并将画面主体根据提示词做了替换。
图生图部分,比较特别的是stabelcascade_stageC_vaeencode这个节点,通过这个节点将像素空间的图像转化为潜空间,类似之前的vae encoder,只是这里要将输出的latent分别发给stageC阶段的采样器和StageB阶段的采样器,另外,StageC阶段的采样器,降噪不要太高,0.6左右比较合适,否则就跟图像关系不大了。
🚀多图融合

提示词留空,输入图像为两张,分别是:


输出图像为:

嗯,水母被巧妙的放在海边的盒子中了,语义上是合理的。
CLIP Vision Encode节点可用于加载特定的CLIP视觉模型,类似于CLIP模型用于对文本提示进行编码,CLIP视觉模型用于对图像进行编码。
注意这里的图片是可以多级串联的,只是串联的太多,每张图片的影响力理论上也会降低。

🎈工作流地址:
comfyui官方示例:Stable Cascade Examples | ComfyUI_examples
当然你也可以到网盘下载:https://pan.quark.cn/s/9b155ffd02ca

🎉写在最后~
去年的时候写了两门比较基础的Stable Diffuison WebUI的基础文字课程,大家如果喜欢的话,可以按需购买,在这里首先感谢各位老板的支持和厚爱~
✨StableDiffusion系统基础课(适合啥也不会的朋友,但是得有块Nvidia显卡):
https://blog.csdn.net/jumengxiaoketang/category_12477471.html
 🎆综合案例课程(适合有一点基础的朋友):
🎆综合案例课程(适合有一点基础的朋友):
https://blog.csdn.net/jumengxiaoketang/category_12526584.html
这里是聚梦小课堂,就算不买课也没关系,点个关注,交个朋友😄