一、Adaboost算法
1.1 Adaboost分类算法
adaboost_discrete_c.py
import numpy as np
import copy
from ch4.decision_tree_C import DecisionTreeClassifier
class AdaBoostClassifier:
"""
adaboost分类算法:既可以做二分类、也可以做多分类,取决于基本分类器
1. 同质学习器:非列表形式,按同种类型的基学习器构造
2. 异质学习器:列表传递[logisticsregression, svm, cart, ...]
"""
def __init__(self, base_estimator=None, n_estimators=10, learning_rate=1.0):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param learning_rate: 学习率,降低后续训练的基分类器的权重,避免过拟合
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.learning_rate = learning_rate
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
self.base_estimator = DecisionTreeClassifier(max_depth=2)
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
self.estimator_weights = [] # 每个基学习器的权重系数
def fit(self, x_train, y_train):
"""
训练AdaBoost每个基学习器,计算权重分布,每个基学习器的误差率和权重系数α,
:param x_train: 训练集,二维数组:m * k
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
n_samples, n_class = x_train.shape[0], len(set(y_train)) # 样本量,类别数
sample_weight = np.ones(n_samples) # 为适应自写的基学习器,设置样本均匀权重为1.0
# 针对每一个基学习器,根据带有权重分布的训练集训练基学习器,计算相关参数
for idx in range(self.n_estimators):
# 1. 使用具有权重分布的Dm的训练数据集学习,并预测
self.base_estimator[idx].fit(x_train, y_train, sample_weight=sample_weight)
# 只关心分类错误的,如果分类错误,则为0,正确则为1
y_hat_0 = (self.base_estimator[idx].predict(x_train) == y_train).astype(int)
# 2. 计算分类误差率
error_rate = sample_weight.dot(1.0 - y_hat_0) / n_samples
if error_rate > 0.5:
self.estimator_weights.append(0) # 当前基分类器不起作用
continue
# 3. 计算基分类器的权重系数,考虑溢出
alpha_rate = 0.5 * np.log((1 - error_rate) / error_rate + 1e-8) + np.log(n_class - 1)
alpha_rate = min(10.0, alpha_rate) # 避免权重系数过大
self.estimator_weights.append(alpha_rate)
# 4. 更新样本权重,为了适应多分类,yi*Gm(xi)计算np.power(-1.0, 1 - y_hat_0)
sample_weight *= np.exp(-1.0 * alpha_rate * np.power(-1.0, 1 - y_hat_0))
sample_weight = sample_weight / np.sum(sample_weight) * n_samples
# 5. 更新estimator的权重系数,按照学习率
for i in range(self.n_estimators):
self.estimator_weights[i] *= np.power(self.learning_rate, i)
def predict_proba(self, x_test):
"""
预测测试样本所属类别概率,软投票
:param x_test: 测试样本集
:return:
"""
x_test = np.asarray(x_test)
# 按照加法模型,线性组合基学习器
# 每个测试样本,每个基学习器预测概率(10,[(0.68, 0.32),(0.55, 0.45)]...)
y_hat_prob = np.sum([self.base_estimator[i].predict_proba(x_test) *
self.estimator_weights[i] for i in range(self.n_estimators)], axis=0)
return y_hat_prob / y_hat_prob.sum(axis=1, keepdims=True)
def predict(self, x_test):
"""
预测测试样本所属类别
:param x_test: 测试样本集
:return:
"""
return np.argmax(self.predict_proba(x_test), axis=1)
1.2 Adaboost回归算法
adaboost_regressor.py
import numpy as np
import copy
from ch4.decision_tree_R import DecisionTreeRegression # CART
class AdaBoostRegressior:
"""
adaboost回归算法:结合(集成)策略:加权中位数、预测值的平均加权
1. 同质学习器,异质学习器
2. 回归误差率依赖于相对误差:平方误差、线性误差、指数误差
"""
def __init__(self, base_estimator=None, n_estimators=10, learning_rate=1.0,
loss="square", comb_strategy="weight_median"):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param learning_rate: 学习率,降低后续训练的基分类器的权重,避免过拟合
:param loss: 损失函数:linear、square、exp
:param comb_strategy: weight_median、weight_mean
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.learning_rate = learning_rate
self.loss = loss # 相对误差的损失函数
self.comb_strategy = comb_strategy # 结合策略
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
self.base_estimator = DecisionTreeRegression(max_depth=2)
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
self.estimator_weights = [] # 每个基学习器的权重系数
def _cal_loss(self, y_true, y_hat):
"""
根据损失函数计算相对误差
:param y_true: 真值
:param y_hat: 预测值
:return:
"""
errors = np.abs(y_true - y_hat) # 绝对值误差
if self.loss.lower() == "linear": # 线性
return errors / np.max(errors)
elif self.loss.lower() == "square": # 平方
errors_s = (y_true - y_hat) ** 2
return errors_s / np.max(errors) ** 2
elif self.loss.lower() == "exp": # 指数
return 1 - np.exp(-errors / np.max(errors))
else:
raise ValueError("仅支持linear、square和exp...")
def fit(self, x_train, y_train):
"""
Adaboost回归算法,T个基学习器的训练:
1. 基学习器基于权重分布Dt的训练集训练
2. 计算最大绝对误差、相对误差、回归误差率
3. 计算当前ht的置信度
4. 更新下一轮的权重分布
:param x_train:
:param y_train:
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
n_samples, n_class = x_train.shape[0], len(set(y_train)) # 样本量,类别数
sample_weight = np.ones(n_samples) # 为适应自写的基学习器,设置样本均匀权重为1.0
for idx in range(self.n_estimators):
# 1. 基学习器基于权重分布Dt的训练集训练以及预测
self.base_estimator[idx].fit(x_train, y_train, sample_weight=sample_weight)
y_hat = self.base_estimator[idx].predict(x_train) # 当前训练集的预测值
# 2. 计算最大绝对误差、相对误差、回归误差率
errors = self._cal_loss(y_train, y_hat) # 相对误差
error_rate = np.dot(errors, sample_weight / n_samples) # 回归误差率
# 3. 计算当前ht的置信度,基学习器的权重参数
alpha_rate = error_rate / (1 - error_rate)
self.estimator_weights.append(alpha_rate)
# 4. 更新下一轮的权重分布
sample_weight *= np.power(alpha_rate, 1 - errors)
sample_weight = sample_weight / np.sum(sample_weight) * n_samples
# 5. 计算基学习器的权重系数以及考虑学习率
self.estimator_weights = np.log(1 / np.asarray(self.estimator_weights))
for i in range(self.n_estimators):
self.estimator_weights[i] *= np.power(self.learning_rate, i)
def predict(self, x_test):
"""
Adaboost回归算法预测,按照加权中位数以及加权平均两种结合策略
:param x_test: 测试样本集
:return:
"""
x_test = np.asarray(x_test)
if self.comb_strategy == "weight_mean": # 加权平均
self.estimator_weights /= np.sum(self.estimator_weights)
# n * T
y_hat_mat = np.array([self.estimator_weights[i] *
self.base_estimator[i].predict(x_test)
for i in range(self.n_estimators)])
# print(y_hat_mat.shape) (10, 5160)
return np.sum(y_hat_mat, axis=0)
elif self.comb_strategy == "weight_median": # 加权中位数
# T个基学习器的预测结果构成一个二维数组(10, 5160)
y_hat_mat = np.array([self.estimator_weights[i] *
self.base_estimator[i].predict(x_test)
for i in range(self.n_estimators)]).T
sorted_idx = np.argsort(y_hat_mat, axis=1) # 二维数组
# 按照每个样本预测值的升序排列序号,排序权重系数,然后累加计算
weight_cdf = np.cumsum(self.estimator_weights[sorted_idx], axis=1)
# 选择最小的t,如下代码产生二维bool数组
median_or_above = weight_cdf >= 0.5 * weight_cdf[:, -1][:, np.newaxis]
# print(median_idx)
median_idx = np.argmax(median_or_above, axis=1) # 返回每个样本的t索引值
median_estimators = sorted_idx[np.arange(x_test.shape[0]), median_idx]
return y_hat_mat[np.arange(x_test.shape[0]), median_estimators]
1.3 SAMME算法
samme_r_muti_classifier.py
import numpy as np
import copy
from ch4.decision_tree_C import DecisionTreeClassifier
class SAMMERClassifier:
"""
SAMME.R算法是将SAMME拓展到连续数值型的范畴。
基学习器的输出为连续型,一般为类别概率的预测值。
"""
def __init__(self, base_estimator=None, n_estimators=10):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
self.base_estimator = DecisionTreeClassifier(max_depth=2)
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
self.estimator_weights = [] # 每个基学习器的权重系数
self.n_samples, self.n_class = None, None # 样本量和类别数
def _target_encoding(self, y_train):
"""
对目标值进行编码
:param y_train: 训练目标集
:return:
"""
self.n_samples, self.n_class = len(y_train), len(set(y_train))
target = -1 / (self.n_class - 1) * np.ones((self.n_samples, self.n_class))
for i in range(self.n_samples):
target[i, y_train[i]] = 1 # 对应该样本的类别所在编码中的列改为1
return target
def fit(self, x_train, y_train):
"""
训练SAMME.Rt每个基学习器,根据预测类别概率计算权重分布
:param x_train: 训练集,二维数组:m * k
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
target = self._target_encoding(y_train) # 编码
sample_weight = np.ones(self.n_samples) # 为适应自写的基学习器,设置样本均匀权重为1.0
# 针对每一个基学习器,根据带有权重分布的训练集训练基学习器,计算相关参数
c = (self.n_class - 1) / self.n_class
for idx in range(self.n_estimators):
# 1. 使用具有权重分布的Dm的训练数据集学习,并预测
self.base_estimator[idx].fit(x_train, y_train, sample_weight=sample_weight)
# 根据训练的基学习器,获得其样本的预测类别概率
pred_p = self.base_estimator[idx].predict_proba(x_train)
# 针对预测概率,小于eps的值替换为eps,避免log函数溢出
np.clip(pred_p, np.finfo(pred_p.dtype).eps, None, out=pred_p)
# 2. 更新样本权重
sample_weight *= np.exp(-c * (target * np.log(pred_p)).sum(axis=1))
sample_weight = sample_weight / np.sum(sample_weight) * self.n_samples
@staticmethod
def softmax_func(x):
"""
softmax函数,为避免上溢或下溢,对参数x做限制
:param x: 数组: batch_size * n_classes
:return: 1 * n_classes
"""
exps = np.exp(x - np.max(x)) # 避免溢出,每个数减去其最大值
exp_sum = np.sum(exps, axis=1, keepdims=True)
return exps / exp_sum
def predict_proba(self, x_test):
"""
预测测试样本所属类别概率,软投票
:param x_test: 测试样本集
:return:
"""
x_test = np.asarray(x_test)
C_x = np.zeros((x_test.shape[0], self.n_class))
for i in range(self.n_estimators):
y_prob = self.base_estimator[i].predict_proba(x_test)
np.clip(y_prob, np.finfo(y_prob.dtype).eps, None, out=y_prob)
y_ln = np.log(y_prob)
C_x += (self.n_class - 1) * (y_ln - np.sum(y_ln, axis=1, keepdims=True) / self.n_class)
return C_x
def predict(self, x_test):
"""
预测测试样本所属类别
:param x_test: 测试样本集
:return:
"""
return np.argmax(self.predict_proba(x_test), axis=1)1.4 Adaboost分类算法测试
test_adaboost_c.py
from sklearn.datasets import make_classification
from sklearn.metrics import classification_report
from ch4.decision_tree_C import DecisionTreeClassifier # 基学习器,决策树
from ch3.logistic_regression_2class import LogisticRegression # 逻辑回归
from ch6.svm_smo_classifier import SVMClassifier # 支持向量机
from adaboost_discrete_c import AdaBoostClassifier
from ch8.plt_decision_function import plot_decision_function
X, y = make_classification(n_samples=300, n_features=2, n_informative=1, n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1, class_sep=1, random_state=42)
# 同质:同种类型的基学习器
base_tree = DecisionTreeClassifier(max_depth=3, is_feature_all_R=True, max_bins=20)
ada_bc = AdaBoostClassifier(base_estimator=base_tree, n_estimators=10, learning_rate=1.0)
ada_bc.fit(X, y) # adaboost训练
print("基学习器的权重系数:\n", ada_bc.estimator_weights)
y_pred = ada_bc.predict(X) # 预测类别
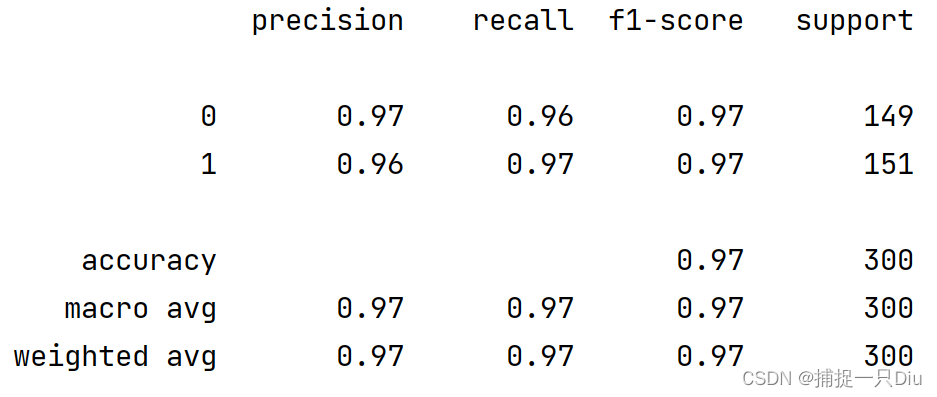
print(classification_report(y, y_pred))
plot_decision_function(X, y, ada_bc)
# 异质:不同类型的基学习器
log_reg = LogisticRegression(batch_size=20, max_epochs=5)
cart = DecisionTreeClassifier(max_depth=4, is_feature_all_R=True)
svm = SVMClassifier(C=5.0, max_epochs=20)
ada_bc2 = AdaBoostClassifier(base_estimator=[log_reg, cart, svm], learning_rate=1.0)
ada_bc2.fit(X, y) # adaboost训练
print("异质基学习器的权重系数:", ada_bc2.estimator_weights)
y_pred = ada_bc2.predict(X) # 预测类别
print(classification_report(y, y_pred))
plot_decision_function(X, y, ada_bc2)

test_adaboost_c2.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
from sklearn.datasets import make_blobs
from ch4.decision_tree_C import DecisionTreeClassifier
from ch8.adaboost_discrete_c import AdaBoostClassifier
X, y = make_blobs(n_samples=1000, n_features=10, centers=5, cluster_std=[1.5, 2, 0.9, 3, 2.8], random_state=0)
X = StandardScaler().fit_transform(X)
base_em = DecisionTreeClassifier(max_depth=4, is_feature_all_R=True, max_bins=10)
acc_scores = [] # 存储每次交叉验证的均分
# 用10折交叉验证评估不同基学习器个数T下的分类正确率
for n in range(1, 21):
scores = [] # 一次交叉验证的acc均值
k_fold = KFold(n_splits=10)
for idx_train, idx_test in k_fold.split(X, y):
classifier = AdaBoostClassifier(base_estimator=base_em, n_estimators=n, learning_rate=1)
classifier.fit(X[idx_train, :], y[idx_train])
y_test_pred = classifier.predict(X[idx_test, :])
scores.append(accuracy_score(y[idx_test], y_test_pred))
acc_scores.append(np.mean(scores))
print(n, ":", acc_scores[-1])
plt.figure(figsize=(7, 5))
plt.plot(range(1, 21), acc_scores, "ko-", lw=1)
plt.xlabel("Number of Estimations", fontdict={"fontsize": 12})
plt.ylabel("Accuracy Score", fontdict={"fontsize": 12})
plt.title("Cross Validation Scores of Different Number of Base Learners", fontdict={"fontsize": 14})
plt.grid(ls=":")
plt.show()

1.5 Adaboost回归算法测试
test_adaboost_regressor.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import r2_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from ch4.decision_tree_R import DecisionTreeRegression
from ch8.adaboost_regressor import AdaBoostRegressior
housing = fetch_california_housing()
X, y = housing.data, housing.target
# print(X.shape)
# print(y.shape)
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
base_ht = DecisionTreeRegression(max_bins=50, max_depth=5)
plt.figure(figsize=(14, 15))
def train_plot(cs, loss, i):
abr = AdaBoostRegressior(base_estimator=base_ht, n_estimators=30,
comb_strategy=cs, loss=loss)
abr.fit(X_train, y_train)
y_hat = abr.predict(X_test)
# print(r2_score(y_test, y_hat))
plt.subplots(231 + i)
idx = np.argsort(y_test) # 对真值排序
plt.plot(y_test[idx], "k-", lw=1.5, label="Test True")
plt.plot(y_hat[idx], "r-", lw=1, label="Predict")
plt.legend(frameon=False)
plt.title("%s, %s, R2 = %.5f, MSE = %.5f" %
(cs, loss, r2_score(y_test, y_hat), ((y_test - y_hat) ** 2).mean()))
plt.xlabel("Test Samples Serial Number", fontdict={"fontsize": 12})
plt.ylabel("True VS Predict", fontdict={"fontsize": 12})
plt.grid(ls=":")
print(cs, loss)
loss_func = ["linear", "square", "exp"]
comb_strategy = ["weight_mean", "weight_median"]
i = 0
for loss in loss_func:
for cs in comb_strategy:
train_plot(cs, loss, i)
i += 1
plt.show()
1.6 SAMME算法测试
test_samme_r_c.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
from sklearn.datasets import make_blobs
# from ch4.decision_tree_C import DecisionTreeClassifierR
from sklearn.tree import DecisionTreeClassifier
from ch8.samme_r_muti_classifier import SAMMERClassifier
X, y = make_blobs(n_samples=1000, n_features=10, centers=5, cluster_std=[1.5, 2, 0.9, 3, 2.8], random_state=0)
X = StandardScaler().fit_transform(X)
base_em = DecisionTreeClassifier(max_depth=4)
acc_scores = [] # 存储每次交叉验证的均分
# 用10折交叉验证评估不同基学习器个数T下的分类正确率
for n in range(1, 21):
scores = [] # 一次交叉验证的acc均值
k_fold = KFold(n_splits=10)
for idx_train, idx_test in k_fold.split(X, y):
classifier = SAMMERClassifier(base_estimator=base_em, n_estimators=n)
classifier.fit(X[idx_train, :], y[idx_train])
y_test_pred = classifier.predict(X[idx_test, :])
scores.append(accuracy_score(y[idx_test], y_test_pred))
acc_scores.append(np.mean(scores))
print(n, ":", acc_scores[-1])
plt.figure(figsize=(7, 5))
plt.plot(range(1, 21), acc_scores, "ko-", lw=1)
plt.xlabel("Number of Estimations", fontdict={"fontsize": 12})
plt.ylabel("Accuracy Score", fontdict={"fontsize": 12})
plt.title("Cross Validation Scores of Different Number of Base Learners", fontdict={"fontsize": 14})
plt.grid(ls=":")
plt.show()

1.7 可视化分类边界函数
plt_decision_function.py
import matplotlib.pyplot as plt
import numpy as np
def plot_decision_function(X, y, clf, is_show=True):
"""
可视化分类边界函数
:param X: 测试样本
:param y: 测试样本的类别
:param clf: 分类模型
:param is_show: 是否在当前显示图像,用于父函数绘制子图
:return:
"""
if is_show:
plt.figure(figsize=(7, 5))
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xi, yi = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
y_pred = clf.predict(np.c_[xi.ravel(), yi.ravel()]) # 模型预测值
y_pred = y_pred.reshape(xi.shape)
plt.contourf(xi, yi, y_pred, cmap="winter", alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors="k")
plt.xlabel("Feature 1", fontdict={"fontsize": 12})
plt.ylabel("Feature 2", fontdict={"fontsize": 12})
plt.title("Model Classification Boundary", fontdict={"fontsize": 14})
if is_show:
plt.show()
二、提升树算法boosting tree
2.1 提升树回归算法
boostingtree_r.py
import numpy as np
import copy
from ch4.decision_tree_R import DecisionTreeRegression # CART
class BoostTreeRegressor:
"""
提升树回归算法,采用平方误差损失
"""
def __init__(self, base_estimator=None, n_estimators=10, learning_rate=1.0):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param learning_rate: 学习率,降低后续训练的基分类器的权重,避免过拟合
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.learning_rate = learning_rate
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
self.base_estimator = DecisionTreeRegression(max_depth=2)
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
def fit(self, x_train, y_train):
"""
提升树的训练,针对每个基决策树算法,拟合上一轮的残差
:param x_train: 训练集
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
# 1. 训练第一棵回归决策树,并预测
self.base_estimator[0].fit(x_train, y_train)
y_hat = self.base_estimator[0].predict(x_train)
y_residual = y_train - y_hat # 残差,MSE的负梯度
# 2. 从第二棵树开始,每一轮拟合上一轮的残差
for idx in range(1, self.n_estimators):
self.base_estimator[idx].fit(x_train, y_residual) # 拟合残差
# 累加第m-1棵树的预测值,当前模型是f_(m-1)
y_hat += self.base_estimator[idx].predict(x_train) * self.learning_rate
y_residual = y_train - y_hat # 当前模型的残差
def predict(self, x_test):
"""
回归提升树的预测
:param x_test: 测试样本集
:return:
"""
x_test = np.asarray(x_test)
y_hat_mat = np.sum([self.base_estimator[0].predict(x_test)] +
[np.power(self.learning_rate, i) * self.base_estimator[i].predict(x_test)
for i in range(1, self.n_estimators - 1)] +
[self.base_estimator[-1].predict(x_test)], axis=0)
return y_hat_mat
2.2 梯度提升树分类算法
gradientboosting_c
import numpy as np
import copy
from ch4.decision_tree_R import DecisionTreeRegression # CART
class GradientBoostClassifier:
"""
梯度提升树多分类算法:多分类也可用回归树来做,即训练与类别数相同的几组回归树,
每一组代表一个类别,然后对所有组的输出进行softmax操作将其转换为概率分布,
再通过交叉熵或者KL一类的损失函数求每棵树相应的负梯度,指导下一轮的训练。
"""
def __init__(self, base_estimator=None, n_estimators=10, learning_rate=1.0):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param learning_rate: 学习率,降低后续训练的基分类器的权重,避免过拟合
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.learning_rate = learning_rate
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
self.base_estimator = DecisionTreeRegression(max_depth=2)
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
self.base_estimators = [] # 扩展到class_num组分类器
@staticmethod
def one_hot_encoding(target):
class_labels = np.unique(target)
target_y = np.zeros((len(target), len(class_labels)), dtype=np.int32)
for i, label in enumerate(target):
target_y[i, label] = 1 # 对应类别所在的列为1
return target_y
@staticmethod
def softmax_func(x):
exps = np.exp(x - np.max(x))
return exps / np.sum(exps, axis=1, keepdims=True)
def fit(self, x_train, y_train):
"""
梯度提升分类算法的训练,共训练M * K个基学习器
:param x_train: 训练集
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
class_num = len(np.unique(y_train)) # 类别数
y_encoded = self.one_hot_encoding(y_train)
# 深拷贝class_num组分类器,每组(每个类别)n_estimators个基学习器
# 假设是三分类:[[0, 1, 2, ..., 9], [10], [10]]
self.base_estimators = [copy.deepcopy(self.base_estimator) for _ in range(class_num)]
# 初始化第一轮基学习器,针对每个类别,分别训练一个基学习器
y_hat_scores = [] # 用于存储每个类别的预测值
for c_idx in range(class_num):
self.base_estimators[c_idx][0].fit(x_train, y_encoded[:, c_idx])
y_hat_scores.append(self.base_estimators[c_idx][0].predict(x_train))
y_hat_scores = np.c_[y_hat_scores].T # 把每个类别的预测值构成一列,(120, 3) (n_samples, class_num)
# print(np.asarray(y_hat_vals).shape)
grad_y = y_encoded - self.softmax_func(y_hat_scores) # 按类别计算样本的负梯度值
# 训练后续基学习器,共M - 1轮,每轮针对每个类别,分别训练一个基学习器
for idx in range(1, self.n_estimators):
y_hat_values = [] # 用于存储每个类别的预测值
for c_idx in range(class_num):
self.base_estimators[c_idx][idx].fit(x_train, grad_y[:, c_idx])
y_hat_values.append(self.base_estimators[c_idx][idx].predict(x_train))
y_hat_scores += np.c_[y_hat_values].T * self.learning_rate
# print(np.asarray(y_hat_vals).shape)
grad_y = y_encoded - self.softmax_func(y_hat_scores) # 按类别计算样本的负梯度值
def predict_proba(self, x_test):
"""
预测测试样本所属类别的概率
:param x_test: 测试样本集
:return:
"""
x_test = np.asarray(x_test)
y_hat_scores = []
for c_idx in range(len(self.base_estimators)):
# 取当前类别的M个基学习器
estimator = self.base_estimators[c_idx]
y_hat_scores.append(np.sum([estimator[0].predict(x_test)] +
[self.learning_rate * estimator[i].predict(x_test)
for i in range(1, self.n_estimators - 1)] +
[estimator[-1].predict(x_test)], axis=0))
# y_hat_scores的维度(3 * 30)
return self.softmax_func(np.c_[y_hat_scores].T)
def predict(self, x_test):
"""
预测测试样本所属类别,概率大的idx标记为类别
:param x_test: 测试样本集
:return:
"""
print(self.predict_proba(x_test))
return np.argmax(self.predict_proba(x_test), axis=1)
2.3 梯度提升树回归算法
gradientboosting_r
import numpy as np
import copy
from ch4.decision_tree_R import DecisionTreeRegression # CART
class GradientBoostRegressor:
"""
梯度提升树回归算法,损失函数:五个,以损失函数在当前模型的负梯度近似为残差
"""
def __init__(self, base_estimator=None, n_estimators=10, learning_rate=1.0,
loss="ls", huber_threshold=0.1, quantile_threshold=0.5):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param learning_rate: 学习率,降低后续训练的基分类器的权重,避免过拟合
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.learning_rate = learning_rate
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
self.base_estimator = DecisionTreeRegression(max_depth=2)
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
self.loss = loss # 损失函数的类型
self.huber_threshold = huber_threshold # 仅对Huber损失有效
self.quantile_threshold = quantile_threshold # 仅对分位数损失函数有效
def _cal_negative_gradient(self, y_true, y_pred):
"""
计算负梯度值
:param y_true: 真值
:param y_pred: 预测值
:return:
"""
if self.loss.lower() == "ls": # MSE
return y_true - y_pred
elif self.loss.lower() == "lae": # MAE
return np.sign(y_true - y_pred)
elif self.loss.lower() == "huber": # 平滑平均绝对损失
return np.where(np.abs(y_true - y_pred) > self.huber_threshold,
self.huber_threshold * np.sign(y_true - y_pred),
y_true - y_pred)
elif self.loss.lower() == "quantile": # 分位数损失
return np.where(y_true > y_pred, self.quantile_threshold,
self.quantile_threshold - 1)
elif self.loss.lower() == "logcosh": # 双曲余弦的对数的负梯度
return -np.tanh(y_pred - y_true)
else:
raise ValueError("仅限于ls、lae、huber、quantile和logcosh,选择有误...")
def fit(self, x_train, y_train):
"""
提升树的训练,针对每个基决策树算法,拟合上一轮的残差
1. 假设回归决策树以mse构建的,针对不同的损失函数,计算不同的基尼指数划分标准
2. 预测,集成,也根据不同的损失函数,预测叶子结点的输出...
:param x_train: 训练集
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
# 1. 训练第一棵回归决策树,并预测
self.base_estimator[0].fit(x_train, y_train)
y_hat = self.base_estimator[0].predict(x_train)
y_residual = self._cal_negative_gradient(y_train, y_hat) # 负梯度
# 2. 从第二棵树开始,每一轮拟合上一轮的残差
for idx in range(1, self.n_estimators):
self.base_estimator[idx].fit(x_train, y_residual) # 拟合残差
# 累加第m-1棵树的预测值,当前模型是f_(m-1)
y_hat += self.base_estimator[idx].predict(x_train) * self.learning_rate
y_residual = self._cal_negative_gradient(y_train, y_hat) # 负梯度
def predict(self, x_test):
"""
回归提升树的预测
:param x_test: 测试样本集
:return:
"""
x_test = np.asarray(x_test)
y_hat_mat = np.sum([self.base_estimator[0].predict(x_test)] +
[np.power(self.learning_rate, i) * self.base_estimator[i].predict(x_test)
for i in range(1, self.n_estimators - 1)] +
[self.base_estimator[-1].predict(x_test)], axis=0)
return y_hat_mat
2.4 提升树算法测试
test_boosting_tree_r.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import r2_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from ch4.decision_tree_R import DecisionTreeRegression
from ch8.boostingtree_r import BoostTreeRegressor
from sklearn.tree import DecisionTreeRegressor
# housing = fetch_california_housing()
# X, y = housing.data[0:20000:100, :], housing.target[0:20000:100]
# print(X.shape)
# print(y.shape)
# X = StandardScaler().fit_transform(X)
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X = np.linspace(1, 10, 10).reshape(-1, 1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
# base_ht = DecisionTreeRegression(max_bins=10, max_depth=1)
base_ht = DecisionTreeRegressor(max_depth=1)
# n_estimators = np.linspace(2, 31, 29, dtype=np.int32)
# r2_scores = []
# for n in n_estimators:
# btr = BoostTreeRegressior(base_estimator=base_ht, n_estimators=n)
# btr.fit(X_train, y_train)
# y_hat = btr.predict(X_test)
# # print(r2_score(y_test, y_hat))
# r2_scores.append(r2_score(y_test, y_hat))
# print(n, ":", r2_scores[-1])
r2_scores = []
for n in range(1, 7):
btr = BoostTreeRegressor(base_estimator=base_ht, n_estimators=n)
btr.fit(X, y)
y_hat = btr.predict(X)
# print(r2_score(y_test, y_hat))
r2_scores.append(r2_score(y, y_hat))
print(n, ":", r2_scores[-1], np.sum((y - y_hat) ** 2))
# plt.figure(figsize=(7, 5))
# plt.plot(n_estimators, r2_scores, "ko-", lw=1)
# plt.show()
# idx = np.argsort(y_test) # 对真值排序
#
# plt.figure(figsize=(7, 5))
# plt.plot(y_test[idx], "k-", lw=1.5, label="Test True")
# plt.plot(y_hat[idx], "r-", lw=1, label="Predict")
# plt.legend(frameon=False)
# plt.title("Regression Boosting Tree, R2 = %.5f, MSE = %.5f" %
# (r2_score(y_test, y_hat), ((y_test - y_hat) ** 2).mean()))
# plt.xlabel("Test Samples Serial Number", fontdict={"fontsize": 12})
# plt.ylabel("True VS Predict", fontdict={"fontsize": 12})
# plt.grid(ls=":")
#
# plt.show()

2.5 梯度提升树算法测试
test_gradboost_c1.py
from ch8.gradientboosting_c import GradientBoostClassifier
from sklearn.datasets import load_iris, load_digits, load_breast_cancer
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from ch4.decision_tree_R import DecisionTreeRegression
from sklearn.tree import DecisionTreeRegressor
# iris = load_iris()
# X, y = iris.data, iris.target
digits = load_digits()
X, y = digits.data, digits.target
# bc_data = load_breast_cancer()
# X, y = bc_data.data, bc_data.target
X = PCA(n_components=10).fit_transform(X)
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=42)
# base_es = DecisionTreeRegression(max_bins=50, max_depth=3)
base_es = DecisionTreeRegressor(max_depth=3)
gbc = GradientBoostClassifier(base_estimator=base_es, n_estimators=50)
gbc.fit(X_train, y_train)
y_hat = gbc.predict(X_test)
print(classification_report(y_test, y_hat))
三、Bagging算法
3.1 Bagging算法
bagging_c_r.py
import numpy as np
import copy
from ch4.decision_tree_R import DecisionTreeRegression # CART
from ch4.decision_tree_C import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, r2_score
class BaggingClassifierRegressor:
"""
1. Bagging的基本流程:采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再集成。
2. 预测输出进行结合:Bagging通常对分类任务采用简单投票法,对回归任务使用简单平均法。
3. 把回归任务与分类任务集成到一个算法中,右参数task来控制,包外估计OOB控制
"""
def __init__(self, base_estimator=None, n_estimators=10, task="C", OOB=False):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param task: 任务:C代表分类任务,R代表回归任务
:param OOB: 布尔变量,True表示进行包外估计
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.task = task
if task.lower() not in ["c", "r"]:
raise ValueError("Bagging任务仅限分类(C/c)、回归(R/r)")
# 如果不提供基学习器,则默认按照深度为2的决策树作为基分类器
if self.base_estimator is None:
if self.task.lower() == "c":
self.base_estimator = DecisionTreeClassifier()
elif self.task.lower() == "r":
self.base_estimator = DecisionTreeRegression()
if type(base_estimator) != list:
# 同质(同种类型)的分类器,深拷贝
self.base_estimator = [copy.deepcopy(self.base_estimator)
for _ in range(self.n_estimators)]
else:
# 异质(不同种类型)的分类器
self.n_estimators = len(self.base_estimator)
self.OOB = OOB # 是否进行包外估计
self.oob_indices = [] # 保存每次有放回采样未被使用的样本索引
self.y_oob_hat = None # 包括估计样本预测值(回归)或预测类别概率(分类)
self.oob_score = None # 包外估计的评分,分类和回归
def fit(self, x_train, y_train):
"""
Bagging算法(包含分类和回归)的训练
:param x_train: 训练集
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
n_samples = x_train.shape[0]
for estimator in self.base_estimator:
# 1. 有放回的随机重采样训练集
indices = np.random.choice(n_samples, n_samples, replace=True) # 采样样本索引
indices = np.unique(indices)
x_bootstrap, y_bootstrap = x_train[indices, :], y_train[indices]
# 2. 基于采样数据,训练基学习器
estimator.fit(x_bootstrap, y_bootstrap)
# 存储每个基学习器未使用的样本索引
n_indices = set(np.arange(n_samples)).difference(set(indices))
self.oob_indices.append(list(n_indices)) # 每个基学习器未参与训练的样本索引
# 3. 包外估计
if self.OOB:
if self.task.lower() == "c":
self._oob_score_classifier(x_train, y_train)
else:
self._oob_score_regressor(x_train, y_train)
def _oob_score_classifier(self, x_train, y_train):
"""
分类任务的包外估计
:param x_train:
:param y_train:
:return:
"""
self.y_oob_hat, y_true = [], []
for i in range(x_train.shape[0]): # 针对每个训练样本
y_hat_i = [] # 当前样本在每个基学习器下的预测概率,个数未必等于self.n_estimators
for idx in range(self.n_estimators): # 针对每个基学习器
if i in self.oob_indices[idx]: # 如果该样本属于包外估计
y_hat = self.base_estimator[idx].predict_proba(x_train[i, np.newaxis])
y_hat_i.append(y_hat[0])
# print(y_hat_i)
if y_hat_i: # 非空,计算各基学习器预测类别概率的均值
self.y_oob_hat.append(np.mean(np.c_[y_hat_i], axis=0))
y_true.append(y_train[i]) # 存储对应的真值
self.y_oob_hat = np.asarray(self.y_oob_hat)
self.oob_score = accuracy_score(y_true, np.argmax(self.y_oob_hat, axis=1))
def _oob_score_regressor(self, x_train, y_train):
"""
回归任务的包外估计
:param x_train:
:param y_train:
:return:
"""
self.y_oob_hat, y_true = [], []
for i in range(x_train.shape[0]): # 针对每个训练样本
y_hat_i = [] # 当前样本在每个基学习器下的预测概率,个数未必等于self.n_estimators
for idx in range(self.n_estimators): # 针对每个基学习器
if i in self.oob_indices[idx]: # 如果该样本属于包外估计
y_hat = self.base_estimator[idx].predict(x_train[i, np.newaxis])
y_hat_i.append(y_hat[0])
# print(y_hat_i)
if y_hat_i: # 非空,计算各基学习器预测类别概率的均值
self.y_oob_hat.append(np.mean(y_hat_i))
y_true.append(y_train[i]) # 存储对应的真值
self.y_oob_hat = np.asarray(self.y_oob_hat)
self.oob_score = r2_score(y_true, self.y_oob_hat)
def predict_proba(self, x_test):
"""
分类任务中测试样本所属类别的概率预测
:param x_test:
:return:
"""
if self.task.lower() != "c":
raise ValueError("predict_proba()仅适用于分类任务。")
x_test = np.asarray(x_test)
y_test_hat = [] # 用于存储测试样本所属类别概率
for estimator in self.base_estimator:
y_test_hat.append(estimator.predict_proba(x_test))
# print(y_test_hat)
return np.mean(y_test_hat, axis=0)
def predict(self, x_test):
"""
分类任务:预测测试样本所属类别,类别概率大者索引为所属类别
回归任务:预测测试样本,对每个基学习器预测值简单平均
:param x_test:
:return:
"""
if self.task.lower() == "c":
return np.argmax(self.predict_proba(x_test), axis=1)
elif self.task.lower() == "r":
y_hat = [] # 预测值
for estimator in self.base_estimator:
y_hat.append(estimator.predict(x_test))
return np.mean(y_hat, axis=0)
3.2 Bagging算法测试
test_bagging_c1.py
from sklearn.datasets import load_iris
from ch8.bagging_c_r import BaggingClassifierRegressor
from ch4.decision_tree_C import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
iris = load_iris()
X, y = iris.data, iris.target
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, shuffle=True, random_state=42)
base_es = DecisionTreeClassifier(max_depth=10, max_bins=50, is_feature_all_R=True)
bagcr = BaggingClassifierRegressor(base_estimator=base_es, n_estimators=20, task="c", OOB=True)
bagcr.fit(X_train, y_train)
y_hat = bagcr.predict(X_test)
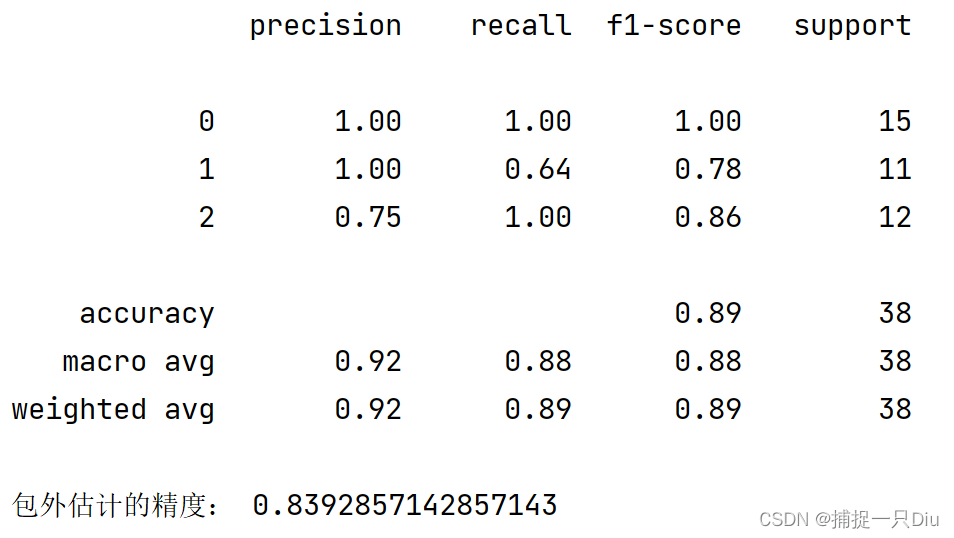
print(classification_report(y_test, y_hat))
print("包外估计的精度:", bagcr.oob_score)
test_bagging_c2.py
from sklearn.datasets import load_iris
from ch8.bagging_c_r import BaggingClassifierRegressor
from ch4.decision_tree_C import DecisionTreeClassifier
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
nursery = pd.read_csv("../ch4/data/nursery.csv").dropna()
X, y = np.asarray(nursery.iloc[:, :-1]), np.asarray(nursery.iloc[:, -1])
y = LabelEncoder().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, shuffle=True, random_state=42)
base_es = DecisionTreeClassifier(max_depth=10)
bagcr = BaggingClassifierRegressor(base_estimator=base_es, n_estimators=30, task="c")
bagcr.fit(X_train, y_train)
y_hat = bagcr.predict(X_test)
print(classification_report(y_test, y_hat))
# print("包外估计的精度:", bagcr.oob_score)
y_test_scores = []
for i in range(30):
bagcr = BaggingClassifierRegressor(base_estimator=base_es, n_estimators=1, task="c")
bagcr.fit(X_train, y_train)
y_hat = bagcr.predict(X_test)
y_test_scores.append(accuracy_score(y_test, y_hat))
plt.figure(figsize=(7, 5))
plt.plot(range(1, 31), y_test_scores, "ko-", lw=1.5)
plt.xlabel("Training Times", fontsize=12)
plt.ylabel("Test Accuracy", fontsize=12)
plt.grid(ls=":")
plt.show()
test_bagging_r.py
import numpy as np
import matplotlib.pyplot as plt
from ch4.decision_tree_R import DecisionTreeRegression
from ch8.bagging_c_r import BaggingClassifierRegressor
from sklearn.metrics import r2_score
f = lambda x: 0.5 * np.exp(-(x + 3) ** 2) + np.exp(-x ** 2) + 1.5 * np.exp(-(x - 3) ** 2)
np.random.seed(0)
N = 200
X = np.random.rand(N) * 10 - 5
X = np.sort(X)
y = f(X) + 0.05 * np.random.randn(N)
X = X.reshape(-1, 1)
# print(X)
base_estimator = DecisionTreeRegression(max_bins=30, max_depth=8)
model = BaggingClassifierRegressor(base_estimator=base_estimator, n_estimators=100, task="r")
model.fit(X, y)
X_test = np.linspace(1.1 * X.min(axis=0), 1.1 * X.max(axis=0), 1000).reshape(-1, 1)
y_bagging_hat = model.predict(X_test)
base_estimator.fit(X, y)
y_cart_hat = base_estimator.predict(X_test)
plt.figure(figsize=(7, 5))
plt.scatter(X, y, s=10, c="k", label="Raw Data")
plt.plot(X_test, f(X_test), "k-", lw=1.5, label="True F(x)")
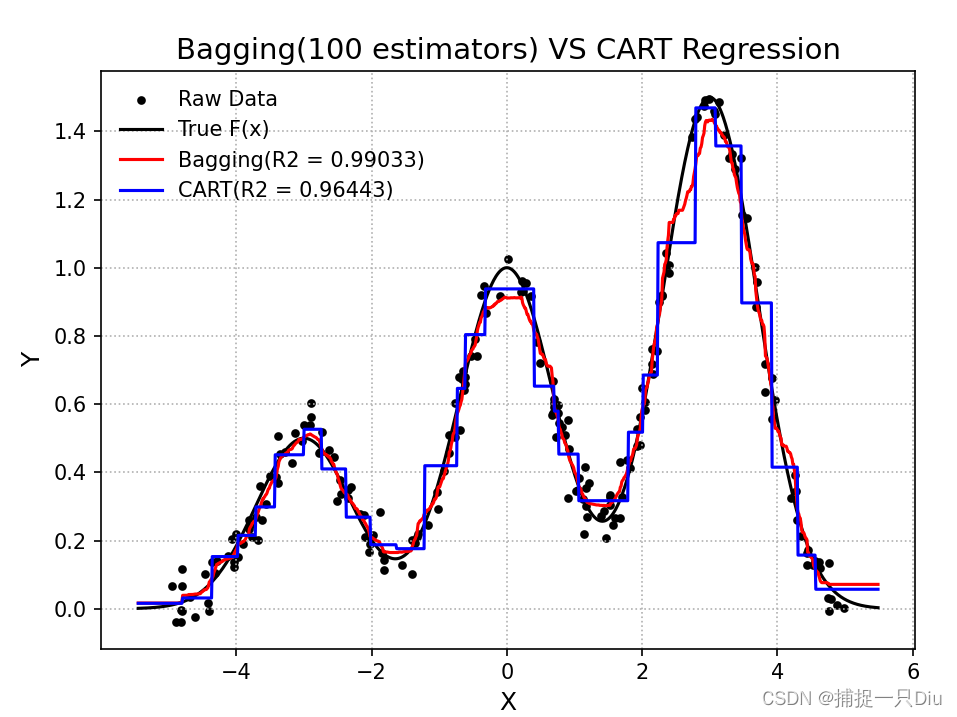
plt.plot(X_test, y_bagging_hat, "r-", label="Bagging(R2 = %.5f)" % r2_score(f(X_test), y_bagging_hat))
plt.plot(X_test, y_cart_hat, "b-", label="CART(R2 = %.5f)" % r2_score(f(X_test), y_cart_hat))
plt.legend(frameon=False)
plt.xlabel("X", fontsize=12)
plt.ylabel("Y", fontsize=12)
plt.grid(ls=":")
plt.title("Bagging(100 estimators) VS CART Regression", fontsize=14)
plt.show()
四、随机森林算法
4.1 随机森林算法
rf_classifier_regressor.py
import numpy as np
import copy
from ch4.decision_tree_R import DecisionTreeRegression # CART
from ch4.decision_tree_C import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, r2_score
class RandomForestClassifierRegressor:
"""
随机森林RF是Bagging的一个扩展变体。 RF在以决策树为基学习器构建Bagging集成的基础上,
进一步在决策树的训练过程中引入了随机属性选择, 即对训练样本和输入变量增加随机扰动。
"""
def __init__(self, base_estimator=None, n_estimators=10, feature_sampling_rate=0.5,
task="C", OOB=False, feature_importance=False):
"""
:param base_estimator: 基学习器
:param n_estimators: 基学习器的个数T
:param task: 任务:C代表分类任务,R代表回归任务
:param OOB: 布尔变量,True表示进行包外估计
:param feature_sampling_rate: 特征变量的抽样率
:param feature_importance: 布尔变量,表示是否进行特征重要性的评估
"""
self.base_estimator = base_estimator
self.n_estimators = n_estimators
self.feature_sampling_rate = feature_sampling_rate
if task.lower() not in ["c", "r"]:
raise ValueError("Bagging任务仅限分类(C/c)、回归(R/r)")
self.task = task
# 如果不提供基学习器,则默认决策树作为基分类器
if self.base_estimator is None:
if self.task.lower() == "c":
base_estimator = DecisionTreeClassifier()
elif self.task.lower() == "r":
base_estimator = DecisionTreeRegression()
self.base_estimator = [copy.deepcopy(base_estimator)
for _ in range(self.n_estimators)]
self.OOB = OOB # 是否进行包外估计
self.oob_indices = [] # 保存每次有放回采样未被使用的样本索引
self.y_oob_hat = None # 包括估计样本预测值(回归)或预测类别概率(分类)
self.oob_score = None # 包外估计的评分,分类和回归
self.feature_importance = feature_importance
self.feature_importance_scores = None # 特征变量的重要性评分
self.feature_importance_indices = [] # 针对每个基学习器,存储特征变量的抽样索引
def fit(self, x_train, y_train):
"""
随机森林算法(包含分类和回归)的训练
:param x_train: 训练集
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
n_samples, n_features = x_train.shape
for estimator in self.base_estimator:
# 1. 有放回的随机重采样训练集
indices = np.random.choice(n_samples, n_samples, replace=True) # 采样样本索引
indices = np.unique(indices)
x_bootstrap, y_bootstrap = x_train[indices, :], y_train[indices]
# 2. 对特征属性变量进行抽样
fb_num = int(self.feature_sampling_rate * n_features) # 抽样特征数
feature_idx = np.random.choice(n_features, fb_num, replace=False) # 不放回
self.feature_importance_indices.append(feature_idx)
x_bootstrap = x_bootstrap[:, feature_idx] # 获取特征变量抽样后的训练样本
# 3. 基于采样数据,训练基学习器
estimator.fit(x_bootstrap, y_bootstrap)
# 存储每个基学习器未使用的样本索引
n_indices = set(np.arange(n_samples)).difference(set(indices))
self.oob_indices.append(list(n_indices)) # 每个基学习器未参与训练的样本索引
# 4. 包外估计
if self.OOB:
if self.task.lower() == "c":
self._oob_score_classifier(x_train, y_train)
else:
self._oob_score_regressor(x_train, y_train)
# 5. 特征重要性估计
if self.feature_importance:
if self.task.lower() == "c":
self._feature_importance_score_classifier(x_train, y_train)
else:
self._feature_importance_score_regressor(x_train, y_train)
def _oob_score_classifier(self, x_train, y_train):
"""
分类任务的包外估计
:param x_train:
:param y_train:
:return:
"""
self.y_oob_hat, y_true = [], []
for i in range(x_train.shape[0]): # 针对每个训练样本
y_hat_i = [] # 当前样本在每个基学习器下的预测概率,个数未必等于self.n_estimators
for idx in range(self.n_estimators): # 针对每个基学习器
if i in self.oob_indices[idx]: # 如果该样本属于包外估计
x_sample = x_train[i, self.feature_importance_indices[idx]]
y_hat = self.base_estimator[idx].predict_proba(x_sample.reshape(1, -1))
y_hat_i.append(y_hat[0])
# print(y_hat_i)
if y_hat_i: # 非空,计算各基学习器预测类别概率的均值
self.y_oob_hat.append(np.mean(np.c_[y_hat_i], axis=0))
y_true.append(y_train[i]) # 存储对应的真值
self.y_oob_hat = np.asarray(self.y_oob_hat)
self.oob_score = accuracy_score(y_true, np.argmax(self.y_oob_hat, axis=1))
def _oob_score_regressor(self, x_train, y_train):
"""
回归任务的包外估计
:param x_train:
:param y_train:
:return:
"""
self.y_oob_hat, y_true = [], []
for i in range(x_train.shape[0]): # 针对每个训练样本
y_hat_i = [] # 当前样本在每个基学习器下的预测概率,个数未必等于self.n_estimators
for idx in range(self.n_estimators): # 针对每个基学习器
if i in self.oob_indices[idx]: # 如果该样本属于包外估计
x_sample = x_train[i, self.feature_importance_indices[idx]]
y_hat = self.base_estimator[idx].predict(x_sample.reshape(1, -1))
y_hat_i.append(y_hat[0])
# print(y_hat_i)
if y_hat_i: # 非空,计算各基学习器预测类别概率的均值
self.y_oob_hat.append(np.mean(y_hat_i))
y_true.append(y_train[i]) # 存储对应的真值
self.y_oob_hat = np.asarray(self.y_oob_hat)
self.oob_score = r2_score(y_true, self.y_oob_hat)
def _feature_importance_score_classifier(self, x_train, y_train):
"""
分类问题的特征变量重要性评估计算
:param x_train:
:param y_train:
:return:
"""
n_feature = x_train.shape[1]
self.feature_importance_scores = np.zeros(n_feature) # 特征变量重要性评分
for f_j in range(n_feature): # 针对每个特征变量
f_j_scores = [] # 当前第j个特征变量在所有基学习器预测的OOB误差变化
for idx, estimator in enumerate(self.base_estimator):
f_s_indices = list(self.feature_importance_indices[idx]) # 获取当前基学习器的特征变量索引
if f_j in f_s_indices: # 表示当前基学习器中存在第j个特征变量
# 1. 计算基于OOB的测试误差error
x_samples = x_train[self.oob_indices[idx], :][:, f_s_indices] # OOB样本以及特征抽样
y_hat = estimator.predict(x_samples)
error = 1 - accuracy_score(y_train[self.oob_indices[idx]], y_hat)
# 2. 计算第j个特征随机打乱顺序后的测试误差
np.random.shuffle(x_samples[:, f_s_indices.index(f_j)]) # 原地打乱第j个特征变量取值,其他特征取值不变
y_hat_j = estimator.predict(x_samples)
error_j = 1 - accuracy_score(y_train[self.oob_indices[idx]], y_hat_j)
f_j_scores.append(error_j - error)
# 3. 计算所有基学习器对当前第j个特征评分的均值
self.feature_importance_scores[f_j] = np.mean(f_j_scores)
return self.feature_importance_scores
def _feature_importance_score_regressor(self, x_train, y_train):
"""
回归任务的特征变量重要性评估计算
:param x_train:
:param y_train:
:return:
"""
n_feature = x_train.shape[1]
self.feature_importance_scores = np.zeros(n_feature) # 特征变量重要性评分
for f_j in range(n_feature): # 针对每个特征变量
f_j_scores = [] # 当前第j个特征变量在所有基学习器预测的OOB误差变化
for idx, estimator in enumerate(self.base_estimator):
f_s_indices = list(self.feature_importance_indices[idx]) # 获取当前基学习器的特征变量索引
if f_j in f_s_indices: # 表示当前基学习器中存在第j个特征变量
# 1. 计算基于OOB的测试误差error
x_samples = x_train[self.oob_indices[idx], :][:, f_s_indices] # OOB样本以及特征抽样
y_hat = estimator.predict[x_samples]
error = 1 - r2_score(y_train[self.oob_indices[idx]], y_hat)
# 2. 计算第j个特征随机打乱顺序后的测试误差
np.random.shuffle(x_samples[:, f_s_indices.index(f_j)]) # 原地打乱第j个特征变量取值,其他特征取值不变
y_hat_j = estimator.predict[x_samples]
error_j = 1 - r2_score(y_train[self.oob_indices[idx]], y_hat_j)
f_j_scores.append(error_j - error)
# 3. 计算所有基学习器对当前第j个特征评分的均值
self.feature_importance_scores[f_j] = np.mean(f_j_scores)
return self.feature_importance_scores
def predict_proba(self, x_test):
"""
分类任务中测试样本所属类别的概率预测
:param x_test:
:return:
"""
if self.task.lower() != "c":
raise ValueError("predict_proba()仅适用于分类任务。")
x_test = np.asarray(x_test)
y_test_hat = [] # 用于存储测试样本所属类别概率
for idx, estimator in enumerate(self.base_estimator):
x_test_bootstrap = x_test[:, self.feature_importance_indices[idx]]
y_test_hat.append(estimator.predict_proba(x_test_bootstrap))
# print(y_test_hat)
return np.mean(y_test_hat, axis=0)
def predict(self, x_test):
"""
分类任务:预测测试样本所属类别,类别概率大者索引为所属类别
回归任务:预测测试样本,对每个基学习器预测值简单平均
:param x_test:
:return:
"""
if self.task.lower() == "c":
return np.argmax(self.predict_proba(x_test), axis=1)
elif self.task.lower() == "r":
y_hat = [] # 预测值
for idx, estimator in enumerate(self.base_estimator):
x_test_bootstrap = x_test[:, self.feature_importance_indices[idx]]
y_hat.append(estimator.predict(x_test_bootstrap))
return np.mean(y_hat, axis=0)
4.2 随机森林算法测试
test_rf_c1.py
from sklearn.datasets import load_iris, load_wine, load_digits
from ch8.randomforest.rf_classifier_regressor import RandomForestClassifierRegressor
# from ch4.decision_tree_C import DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
iris = load_iris()
X, y = iris.data, iris.target
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, shuffle=True, random_state=42)
# base_es = DecisionTreeClassifier(max_depth=10, max_bins=50, is_feature_all_R=True)
base_es = DecisionTreeClassifier(max_depth=10)
rf_model = RandomForestClassifierRegressor(base_estimator=base_es, n_estimators=30,
task="c", OOB=True, feature_importance=True)
rf_model.fit(X_train, y_train)
y_hat = rf_model.predict(X_test)
print(classification_report(y_test, y_hat))
print("包外估计的精度:", rf_model.oob_score)
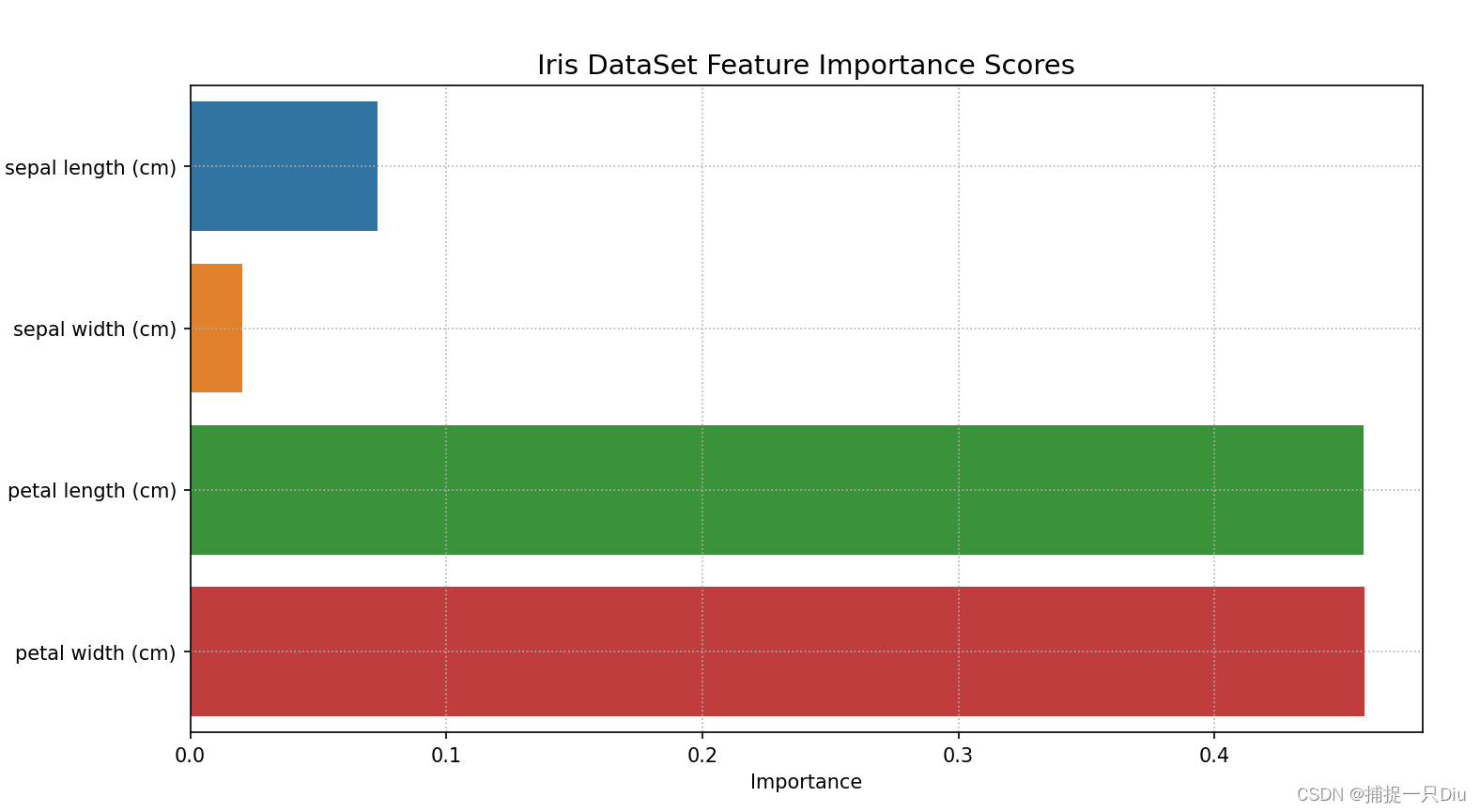
print("特征重要性评分:", rf_model.feature_importance_scores)
plt.figure(figsize=(9, 5))
data_pd = pd.DataFrame([iris.feature_names, rf_model.feature_importance_scores]).T
data_pd.columns = ["Feature Names", "Importance"]
sns.barplot(x="Importance", y="Feature Names", data=data_pd)
plt.title("Iris DataSet Feature Importance Scores", fontdict={"fontsize": 14})
plt.grid(ls=":")
print(data_pd)
plt.show()