1. 反向传播
计算当前张量的梯度
Tensor.backward(gradient=None, retain_graph=None, create_graph=False, inputs=None)
计算当前张量相对于图中叶子节点的梯度。
使用反向传播,每个节点的梯度,根据梯度进行参数优化,最后使得损失最小化
代码:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('data',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super().__init__()
# 另一种写法
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self,x):
# sequential方式
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs,target = data
outputs= tudui(imgs)
result_loss = loss(outputs,target)
result_loss.backward() # 梯度
print(result_loss)
2.优化器 (以随机梯度下降算法为例)
将上一步的梯度清零
params ,lr(学习率)
随机梯度下降SGD
torch.optim.SGD(params,
lr=,
momentum=0, dampening=0, weight_decay=0, nesterov=False, *, maximize=False, foreach=None, differentiable=False)
代码:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('data',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super().__init__()
# 另一种写法
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self,x):
# sequential方式
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # params,lr
for epoch in range(5):# 在整个数据集上训练5次
running_loss = 0
#对数据进行一轮学习
for data in dataloader:
imgs,target = data
outputs= tudui(imgs)
result_loss = loss(outputs,target)
optim.zero_grad() # 将上一步的梯度清零
result_loss.backward() # 梯度
optim.step() # 根据梯度修改参数
# print(result_loss)
running_loss = running_loss + result_loss
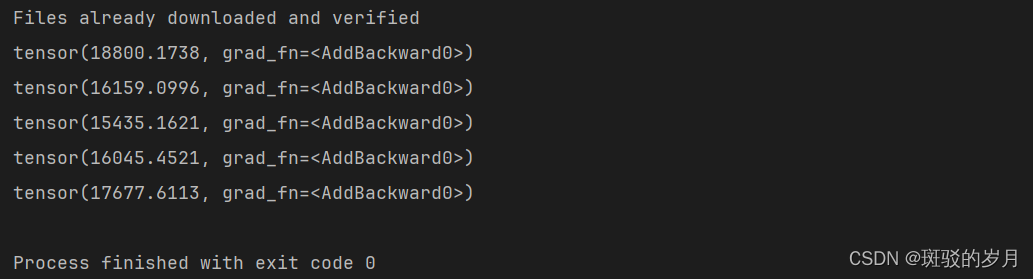
print(running_loss)
输出